数据标注流程图
- 是否有足够的数据
- 要改善标注还是模型
- 要改善标准,标准是否足够--若足够,可使用半监督学习
- 若标准不足,预算是否足够--若足够,可通过众包标注
- 预算也不足,可使用弱监督学习
半监督学习(SSL)
基于少样本量的有标注的数据和大样本量的无标注的数据
对无标注的数据做以下假设:
- 连续性假设:这个样本与另一个样本有相似的特征,则可能有相同的标注
- 聚类假设:数据有内在的聚类结构,聚类相同的样本可能有相同的标注
- 流形假设:数据是在一个低维的流形上分布,可通过降维获取更干净的数据
自训练
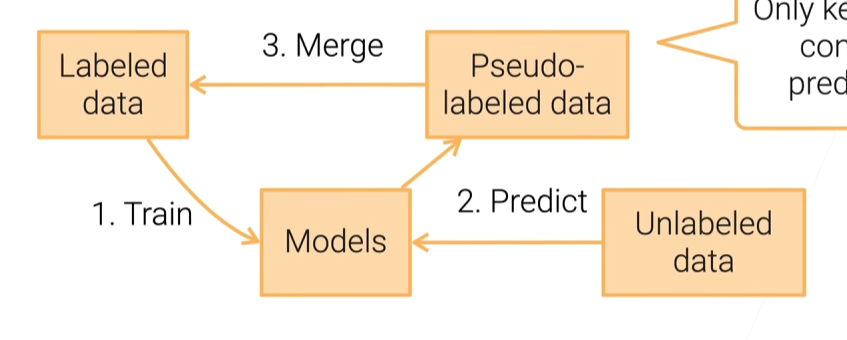
训练模型并预测无标注的数据,保留特别置信的标注数据加入数据集,并进行迭代
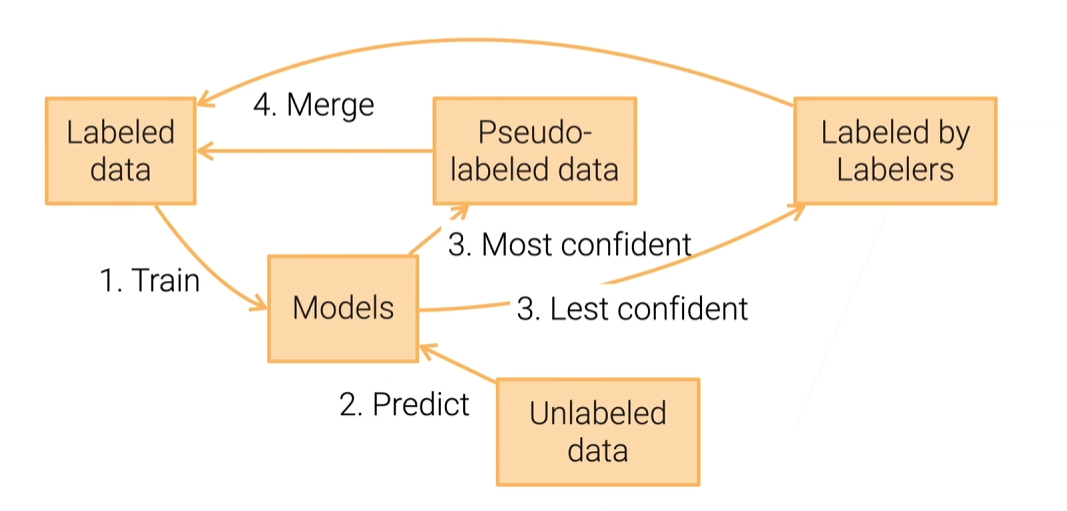
主动学习(一般与自训练配合使用)
不确信采样:
选出不确信的预测,由人工标注后加入数据集
弱监督学习
半自动生成标号
数据编程:
用一些启发式方法(制定一些规律)给数据标号
- 关键词搜索,模式匹配,第三方模型等