01_试卷
02_试卷
试卷01:
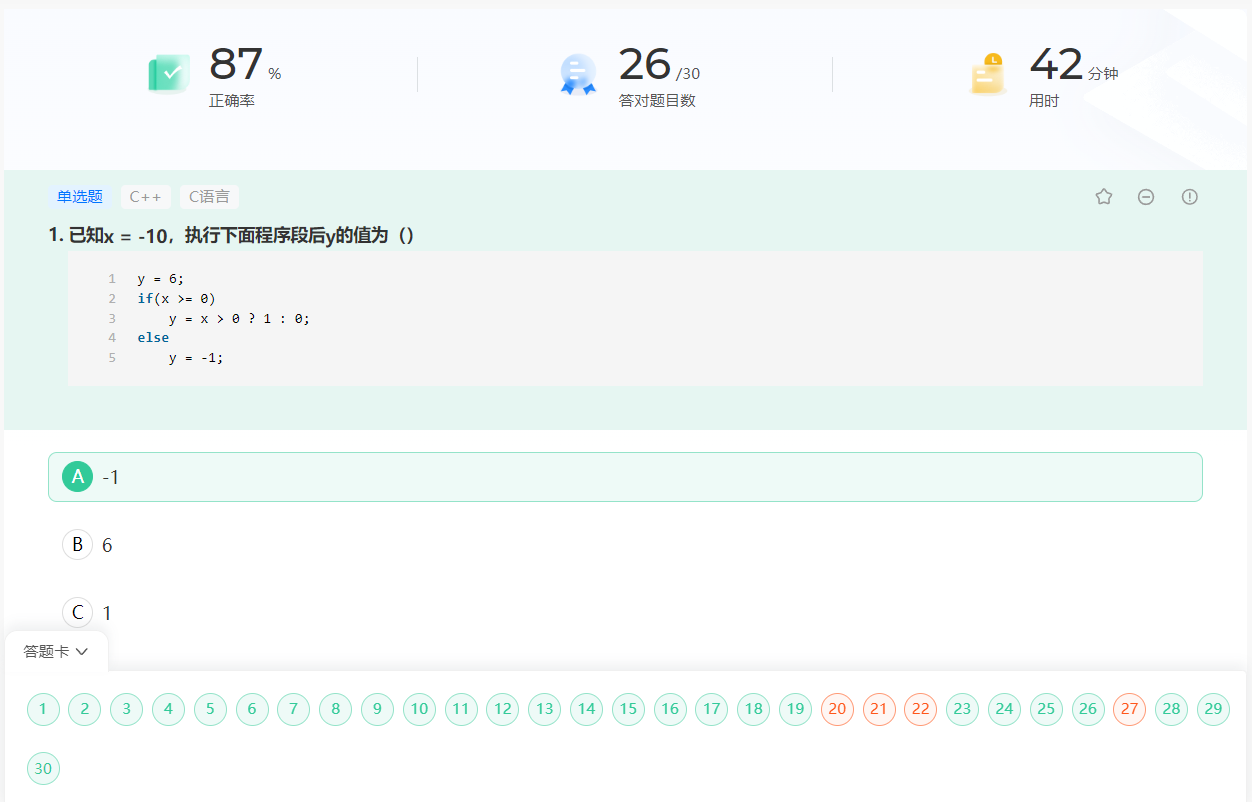
已知x = -10,执行下面程序段后y的值为()
|-----------|---------------------------------------------------------------------|
| 1 2 3 4 5 |y = 6;if``(x >= 0)``y = x > 0 ? 1 : 0;else``y = -1;|A
-1
B
6
C
1
D
0
正确答案:A
官方解析:
让我们通过分析程序的执行流程来理解答案:
程序首先将y赋值为6,然后进入条件判断。由于已知x=-10,我们可以按照代码的执行顺序分析:
x=-10,所以条件 x>=0 不成立
程序会执行else分支
在else分支中,直接将y赋值为-1
因此最终y的值为-1,选项A是正确答案。
分析其他选项:
B选项(6)错误:虽然一开始y被赋值为6,但是后续的if-else语句改变了y的值。
C选项(1)错误:只有在x>0时才会赋值为1,而题目给定x=-10。
D选项(0)错误:只有在x=0且进入第一个if分支时才会赋值为0,而题目给定x=-10。
这道题目主要考察条件语句的执行流程和嵌套条件表达式(三目运算符)的理解。虽然代码中包含了三目运算符 x>0 ? 1 : 0,但由于x=-10,整个if分支都没有被执行,而是执行了else分支,所以最终结果就是-1。
知识点:C++、C语言
题友讨论(10)
单选题
C++
C语言
以下程序运行后的输出结果是()
|-------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 |intmain() {``intp[7] = {11, 13, 14, 15, 16, 17, 18};``inti = 0, j = 0;``while(i < 7 && p[i]%2 == 1) j += p[i++];``printf``(``"%d\n"``, j);}|A
23
B
24
C
25
D
26
正确答案:B
官方解析:
让我们逐步分析这段代码的执行过程:
while循环的条件是两个部分的"与"运算:
i < 7 确保数组不会越界
pi%2 == 1 检查当前元素是否为奇数
程序从数组开头开始遍历,当遇到偶数或到达数组末尾时停止。对遇到的每个奇数,将其加到j中。
具体执行过程:
i=0: p0=11 (奇数), j=11
i=1: p1=13 (奇数), j=24
i=2: p2=14 (偶数), 循环终止
因此j最终等于11+13=24,所以B选项24是正确答案。
分析其他选项:
A(23)错误:这个数值无法通过任何有效的计算得到
C(25)错误:如果多加了一个数就会超过24,但实际上遇到14(偶数)就停止了
D(26)错误:计算结果不可能达到26,因为在遇到第一个偶数14时就停止了累加
这道题目主要考察了:
while循环的条件判断
数组遍历
条件表达式的短路特性
累加运算的过程理解
知识点:C++、C语言
题友讨论(18)
单选题
C语言
|-----|-------------------------------------------|
| 1 2 |inta = 24;printf``(``"%o"``, a);|在上下文和头文件均正常的情况下,程序输出结果是30。
A
正确
B
错误
正确答案:A
官方解析:
/o 表示转换进制 24转换8进制
知识点:C语言
题友讨论(19)
单选题
C语言
有以下程序
|-------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 7 8 9 10 11 |intmain() {``inti = 0, s = 0;``for(;;) {``if``(i == 3 || i == 5) ``continue``;``if(i == 6) ``break``;``i++;``s += i;``};``printf``(``"%d\n"``,s);``return0;}|程序运行后的输出结果是()
A
10
B
13
C
21
D
程序进入死循环
正确答案:D
官方解析:
这道题目涉及循环语句中continue和break的执行逻辑。由于程序存在逻辑缺陷,会进入死循环,因此D是正确答案。
让我们逐步分析程序的执行过程:
初始时 i = 0, s = 0
当i = 0时:执行i++,s = 1
当i = 1时:执行i++,s = 3
当i = 2时:执行i++,s = 6
当i = 3时:遇到continue,跳过后续语句直接进入下一次循环,但i没有增加
由于i仍然是3,下一次循环还是会遇到continue
程序陷入死循环,永远无法跳出
关键问题在于continue语句的位置:
continue语句在i++之前
当i = 3时,执行continue会跳过i++语句
导致i永远保持为3,无法继续向前推进
其他选项错误原因:
A(10)错误:程序根本不会得到任何结果,因为陷入死循环
B(13)错误:同上,不会产生最终结果
C(21)错误:同上,不会产生最终结果
避免这个问题的方法是将i++放在continue之前,或者在if条件中加入i++操作。
知识点:C语言
题友讨论(6)
单选题
C语言
有代码段
|-----|------------------------------------------------------------------|
| 1 2 |inta = 1, b = 2, c = 3;if(a > c) b = a; a = c; c = b;|则 c 的值为( )
A
1
B
2
C
3
D
不一定
正确答案:B
官方解析:
这道题目需要仔细分析代码的执行顺序。让我们逐步执行代码:
初始状态:a=1, b=2, c=3
执行 if (a > c) b = a; a = c; c = b; 语句时:
首先判断 a > c,即 1 > 3,条件不成立,所以 b = a 不会执行
接着执行 a = c,即 a = 3
最后执行 c = b,即 c = 2
所以最终状态:a=3, b=2, c=2
因此c的最终值为2,B选项正确。
分析其他选项:
A错误:c的值不可能是1,因为初始时c=3,而后被赋值为b的值(2)
C错误:c的初始值3被b的值覆盖,不会保持为3
D错误:通过分析代码执行过程,c的最终值是确定的2,不存在不确定的情况
这道题的关键是要注意:
if语句后面没有大括号,所以只有 b = a 是if的条件语句
a = c 和 c = b 是独立的语句,会顺序执行
赋值操作要按照执行顺序依次进行
知识点:C语言
题友讨论(11)
单选题
C语言
以下叙述中正确的是()
A
程序必须包含所有三种基本结构才能成为一种算法
B
我们所写的每条C语句,经过编译最终都将转换成二进制的机器指令
C
如果算法非常复杂,则需要使用三种基本结构之外的语句结构,才能准确表达
D
只有简单算法才能在有限的操作步骤之后结束
正确答案:B
官方解析:
【解析】 C 语言程序可以不包含三种基本结构 , 也可以包含其中的一种或多种 , 所以 A 错误。三种基本结构可以表示任何复杂的算法 , 所以 C 错误。正确的算法 , 不管是简单算法还是复杂算法都可以在有限的操作步骤之后结束 , 这是算法的有穷性 , 所以 D 错误。
知识点:C语言
题友讨论(9)
单选题
C++
C语言
设有以下定义,值为5的枚举常量是( )。
enum week{sun,mon, tue=3,wed,thu,fri, sat,}w
A
tue
B
sat
C
thu
D
fri
正确答案:C
官方解析:
在枚举类型中,如果没有显式地为枚举常量指定值,则第一个枚举常量的值从0开始,后续的枚举常量值依次加1。
让我们分析这个枚举的值:
sun = 0 (默认从0开始)
mon = 1 (递增1)
tue = 3 (显式指定为3)
wed = 4 (从3继续递增)
thu = 5 (递增)
fri = 6 (递增)
sat = 7 (递增)
因此thu的值为5,所以C选项正确。
分析其他选项:
A错误:tue的值被显式指定为3
B错误:sat的值为7
D错误:fri的值为6
这是一个关于枚举常量赋值规则的考察。当枚举常量中某个值被显式指定后,后续的枚举常量会在此基础上继续递增。这里tue被指定为3后,wed就变成4,thu变成5,以此类推。这是枚举类型的基本特性。
知识点:C++、C语言
题友讨论(11)
单选题
C++
C语言
下面程序输出为()
|-------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |#include <stdio.h>intfun(``inta) {``intb = 0;``staticintc = 3;``b++;``c++;``return(a + b + c);}intmain() {``inti=0;``for``(; i < 3; i++)``printf``(``"%d"``,fun(2));``return0;}|A
777
B
789
C
7911
D
71320
正确答案:B
官方解析:
让我们逐步分析这段程序的执行过程:
程序中定义了一个函数fun(int a),包含三个变量:
参数a:每次调用时值为2
局部变量b:每次调用时初始化为0,然后b++使其变为1
静态变量c:初始值为3,每次调用后值会保留并自增
第一次调用fun(2):
a = 2
b = 1
c = 4(3+1)
结果:2 + 1 + 4 = 7
第二次调用fun(2):
a = 2
b = 1
c = 5(4+1)
结果:2 + 1 + 5 = 8
第三次调用fun(2):
a = 2
b = 1
c = 6(5+1)
结果:2 + 1 + 6 = 9
所以最终输出为789,B选项正确。
分析其他选项:
A选项777错误:没有考虑到静态变量c会累加
C选项7911错误:计算过程有误
D选项71320错误:完全理解错了程序的执行流程
这道题目的关键点在于理解静态变量的特性:static变量在函数调用结束后不会释放,而是保留其值,下次调用时继续使用,这就导致了c的值会不断累加。而普通局部变量b则每次都重新初始化为0。
知识点:C++、C++工程师、2019、C语言
题友讨论(18)
单选题
C++
C语言
有以下程序
|-------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 |#include "stdio.h"voidmain() {``inta[5] = {1, 2, 3, 4, 5}, b[5] = {0, 2, 1, 3, 0}, i, s = 0;``for``(i=0; i < 5; i++) s = s + a[b[i]];``printf``(``"%d\n"``, s);}|程序运行后的输出结果是( )
A
6
B
10
C
11
D
15
正确答案:C
官方解析:
这道题目考察了数组与循环的基本应用,需要仔细分析数组a和b的值以及循环中的索引关系。
让我们逐步计算s的值:
i=0时,b0=0,所以取a0=1,s=1
i=1时,b1=2,所以取a2=3,s=1+3=4
i=2时,b2=1,所以取a1=2,s=4+2=6
i=3时,b3=3,所以取a3=4,s=6+4=10
i=4时,b4=0,所以取a0=1,s=10+1=11
因此最终s的值为11,所以C选项正确。
分析其他选项:
A(6)错误:这个数值过小,只计算了前三步的结果
B(10)错误:这个值缺少了最后一步的计算
D(15)错误:这个值过大,可能是直接把所有a数组的值相加得到的结果(1+2+3+4+5=15)
这道题的关键是要理解bi实际上是作为a数组的索引使用,通过b数组的值来确定访问a数组的位置。这种数组作为索引的用法在实际编程中也很常见。
知识点:C++、C语言
题友讨论(9)
单选题
C语言
在32位系统里,int b 3 = {{1},{3,2},{4,5,6},{0}};中,sizeof(b) = ?
A
4
B
12
C
28
D
48
正确答案:D
官方解析:
在这道题目中,需要计算二维数组b的总大小。让我们逐步分析:
数组b是一个二维数组,第二维明确指定为3,第一维由初始化的数据决定。
根据初始化数据 {{1},{3,2},{4,5,6},{0}},可以看出第一维的大小为4。
因此数组b实际上是一个4×3的二维数组。即使某些元素没有显式初始化,编译器也会自动填充0。
在大多数系统中,int类型占用4个字节。
所以sizeof(b) = 4(行数) × 3(列数) × 4(每个int的字节数) = 48字节
因此D选项48是正确答案。
分析其他选项:
A(4)错误:这个大小明显过小,仅等于一个int的大小
B(12)错误:这个大小只够存储一行数据(3个int)
C(28)错误:这个大小不是4×3×4的结果,不符合实际数组大小
需要注意的是,在不同的操作系统或编译器中,int的大小可能会有所不同,但在大多数现代系统中int都是4字节。这道题基于int为4字节的标准环境。
知识点:2014、C++工程师、C语言
题友讨论(19)
单选题
C++
C语言
函数rewind的作用是()
A
使位置指针重新返回文件的开头
B
将位置指针指向文件中所要求的特定位置
C
使位置指针指向文件的末尾
D
使位置指针自动移至下一个字符位置
正确答案:A
官方解析:
rewind函数是一个常用的文件操作函数,其主要作用是将文件内部的位置指针重新指向文件开头。这是一个典型的文件指针重定位操作,A选项正确地描述了这一功能。
分析其他选项:
B错误:将位置指针指向文件特定位置是fseek函数的功能,而不是rewind函数。
C错误:使位置指针指向文件末尾通常使用fseek(fp, 0, SEEK_END)来实现。
D错误:使位置指针移动到下一个字符位置通常是在读写操作后自动完成的,或使用fgetc/fputc等函数。
补充说明:
rewind(fp)函数在功能上等价于fseek(fp, 0L, SEEK_SET),但使用rewind更为简单直观。它不仅将位置指针移到文件开头,还会清除文件结束标志和错误标志。这个函数在需要重新读取文件内容或重新开始写入时特别有用。
知识点:C++、C语言
题友讨论(5)
单选题
C语言
编译和体系结构
有以下程序
|---------------|--------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 7 |#include <stdio.h>intmain() {``inti = ``1``;``i = i ^ i;``printf(``"%d\n"``, i);``return0``;}|程序运行后的输出结果是?
A
1
B
-1
C
0
D
7
正确答案:C
官方解析:
本题考查位运算中按位异或运算符,异或运算只有在两个比较的位不同时其结果是1,否则结果为0,i^i运算符两边相同,所以结果为0,选项C正确。
知识点:编译和体系结构、C语言
题友讨论(18)
单选题
C++
C语言
|-------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 7 8 9 10 11 |voidGetMemory(``char**p, ``intnum){``*p = (``char*)malloc(num);}voidTest(``void``){``char*str = NULL;``GetMemory(&str, ``100``);``strcpy(str, ``"hello"``);``printf(``"%s"``, str);}|请问运行Test 函数会有什么样的结果?
A
hello
B
空
C
出错
正确答案:A
官方解析:
这段代码能够正确执行并输出"hello"。让我们来分析代码的执行过程:
在 Test 函数中,首先声明了一个字符指针 str 并初始化为 NULL。
调用 GetMemory 函数时,传入 str 的地址(&str)和大小 100。GetMemory 函数通过二级指针操作,为 str 分配了 100 字节的内存空间。这里的关键是通过二级指针可以修改原始指针的值。
malloc 函数成功分配内存后,str 就指向了这块有效的内存空间。
接着使用 strcpy 函数将字符串"hello"复制到新分配的内存空间中。
最后 printf 函数打印出存储在 str 指向的内存空间中的字符串,即"hello"。
分析其他选项:
B选项错误:不会输出空字符串,因为内存分配成功后已经复制了"hello"字符串。
C选项错误:代码不会出错,因为:
GetMemory 函数正确使用二级指针修改了原始指针的值
malloc 成功分配了内存
strcpy 操作的是有效的内存空间
内存空间足够容纳"hello"字符串
所以这段代码是完全合法且可以正确执行的,会输出"hello"。
知识点:C++、C语言
题友讨论(35)
单选题
C++
C语言
在C语言中,关于静态变量的说法,正确的是()
A
静态变量和常量的作用相同
B
函数中的静态变量,在函数退出后不被释放
C
静态变量只可以赋值一次,赋值后则不能改变
D
静态全局变量的作用域为一个程序的所有源文件
正确答案:B
官方解析:
C语言中静态变量具有独特的特性。B选项正确,因为函数中的静态变量在函数退出后确实不会被释放,它们在程序的整个运行期间都会保持在内存中,并且保留最后一次被赋予的值。这使得静态局部变量可以在函数的多次调用之间保持其值。
分析其他选项的错误原因:
A选项错误:静态变量和常量是完全不同的概念。常量一旦定义后值不能改变,而静态变量的值是可以改变的,它们的主要区别在于存储特性和生命周期。
C选项错误:静态变量可以多次赋值和修改,只是它的存储位置和生命周期与普通变量不同。这个说法可能与const常量混淆了。
D选项错误:静态全局变量的作用域仅限于定义它的源文件内,不能被其他源文件访问。这是static关键字对全局变量的限制作用,它将全局变量的作用域限制在当前文件中。
补充知识点:静态变量无论是局部的还是全局的,都存储在静态存储区,这决定了它们的生命周期与整个程序运行期相同。局部静态变量兼具静态存储和局部作用域的特点。
知识点:C++、算法工程师、2019、C语言
题友讨论(14)
单选题
C语言
以下数组定义中不正确的是( )
A
int a23;
B
int b\[\]3={0,1,2,3};
C
int c100100={0};
D
int d3\[\]={{1,2},{1,2,3},{1,2,3,4}};
正确答案:D
官方解析:
这道题目考察了C语言中数组定义的知识点。D选项是错误的,因为二维数组声明时必须指定第二维的大小,而D选项中没有指定第二维大小。
分析各个选项:
A正确:int a23是标准的二维数组定义方式,指定了行数(2)和列数(3)。
B正确:int b\[\]3={0,1,2,3}是合法的定义,第一维度可以省略,编译器会根据初始化的值自动确定大小。这里会被初始化为一个2×3的数组。
C正确:int c100100={0}是合法的定义,这种写法会将整个数组初始化为0。
D错误:int d3\[\]={{1,2},{1,2,3},{1,2,3,4}}中没有指定第二维的大小。在C语言中,二维数组定义时必须明确指定第二维的大小。虽然可以省略第一维的大小,但第二维的大小是必须的。如果想要定义这样的数组,应该写成int d34={{1,2},{1,2,3},{1,2,3,4}},其中4是最长子数组的长度。
总的来说,二维数组定义时第二维的大小必须明确指定,这是C语言的语法规则之一。
知识点:C语言
题友讨论(16)
单选题
C语言
若已定义: int a9 , *p = a; 并在以后的语句中未改变 p 的值,不能表示 a1 地址的表达式是()
A
++p
B
a+1
C
p+1
D
a++
正确答案:D
官方解析:
这道题目考察了C语言中数组、指针以及自增运算符的概念。D选项"a++"是错误的,因为数组名a是常量指针,不能进行自增运算。
分析其他选项:
A: ++p 是正确的。因为p是指向数组首元素的指针变量,++p会使p指向下一个元素(即a1)的地址。
B: a+1 是正确的。数组名加1表示数组第二个元素的地址,即a1的地址。
C: p+1 是正确的。指针加1会指向下一个元素的地址,所以p+1表示a1的地址。
重点解释:
数组名a本质上是一个常量指针,表示数组首地址,不能被修改
指针变量p可以通过自增运算移动到下一个元素
对数组名和指针都可以进行加1运算来获取下一个元素地址
a++是非法的,因为不能对常量指针进行自增运算
所以D选项a++不能表示a1的地址,这种写法在编译时就会报错。
知识点:C语言
题友讨论(18)
单选题
C语言
函数()把文件位置重定位到文件中的指定位置
A
fseek
B
fread
C
fopen
D
fgets
正确答案:A
官方解析:
fseek函数的确是用来重定位文件指针位置的标准C库函数。它可以把文件内部的位置指针移动到指定位置,从而实现文件的随机读写访问。
分析其他选项:
B错误: fread是用于从文件中读取数据的函数,它按照指定的大小和数量读取数据块,而不具备调整文件位置的功能。
C错误: fopen是用于打开文件的函数,它建立文件与文件指针之间的关联,返回一个FILE类型的指针,但不能用于文件内部位置的重定位。
D错误: fgets是用于从文件中读取一行字符串的函数,它每次读取一行内容直到遇到换行符或达到指定的最大长度,同样不具备文件定位功能。
fseek函数的使用格式为:
int fseek(FILE *stream, long offset, int whence)
其中offset指定偏移量,whence指定偏移起始位置(文件头、当前位置或文件尾)。这使得程序能够精确控制在文件中的读写位置,是实现文件随机访问的关键函数。
知识点:C++工程师、C语言
题友讨论(20)
单选题
C++
C语言
如果MyClass为一个类,执行"MyClass a5, *b6"语言会自动调用该类构造函数的次数是()
A
2
B
5
C
4
D
9
正确答案:B
官方解析:
本题考察数组声明时类构造函数的调用次数。
分析代码 "MyClass a5, *b6":
a5声明了一个包含5个MyClass对象的数组,会调用5次构造函数
*b6声明了一个包含6个指针的数组,每个指针指向MyClass类型,但并没有创建实际的MyClass对象,因此不会调用构造函数
所以总共调用构造函数的次数是5次,B选项正确。
分析其他选项:
A(2次)错误:明显小于实际调用次数
C(4次)错误:没有完整统计a数组中的对象数量
D(9次)错误:误将指针数组b也计算在内,实际b数组中的指针并不会导致构造函数调用
要点提示:
普通对象数组会为每个元素调用构造函数
指针数组只分配指针空间,不创建实际对象
只有在给指针赋值时才会涉及对象的构造
因此这道题的关键是要区分普通对象数组和指针数组在创建时构造函数的调用情况。
知识点:C++、C语言
题友讨论(30)
单选题
C语言
C语言中最简单的数据类型包括__________
A
整型、实型、逻辑型
B
整型、实型、字符型
C
整型、字符型、逻辑型
D
整型、实型、逻辑型、字符型
正确答案:B
官方解析:
C语言最基本的数据类型包含整型(int)、实型(float/double)和字符型(char)三种,因此B选项是正确的。这些是C语言中使用最广泛且最基础的数据类型。
分析其他选项:
A选项错误:将逻辑型列为基本数据类型是不准确的。C语言本身并没有内置的逻辑(布尔)类型,通常使用整型0和1来表示true/false。
C选项错误:同样错在将逻辑型列为基本数据类型,而且遗漏了实型这个重要的基本类型。
D选项错误:虽然包含了正确选项中的所有类型,但多列了逻辑型。这个选项将C语言中不存在的数据类型也包含进来了。
需要注意的是,这里讨论的是C语言最简单的数据类型,每种基本类型还可以通过关键字(如long、short、unsigned等)进行修饰,形成更多的变体类型。但从最基础的角度来说,整型、实型和字符型构成了C语言的基本数据类型体系。
知识点:C语言
题友讨论(25)
单选题
C++
C语言
对下面变量声明描述正确的有()
|---------|---------------------------------------------------------------|
| 1 2 3 4 |int*p[n];int(*)p[n];int*p();int(*)p();|A
int *pn;-----指针数组,每个元素均为指向整型数据的指针
B
int (*)pn;---p为指向一维数组的指针,这个一维数组有n个整型数据
C
int *p();------函数带回指针,指针指向返回的值
D
int (*)p();----p为指向函数的指针
正确答案:A
你的答案:D
官方解析:
这道题目考察了不同类型指针声明的语法理解。A 选项描述正确,而其他选项的描述都存在错误。
让我们逐个分析:
A选项 int *pn 确实表示指针数组,它定义了一个数组 p,数组有 n 个元素,每个元素都是指向 int 类型的指针。这种声明常用于存储多个整型数据的地址。
B选项 int (*)pn 的描述错误。这种语法本身就是不合法的。如果要声明指向数组的指针,正确的语法应该是 int (*p)n。
C选项 int *p() 的描述有误。这个声明实际上定义了一个函数 p,该函数返回一个指向 int 类型的指针。而不是"函数带回指针,指针指向返回的值"。
D选项 int (*)p() 的描述错误。这种语法本身就是不合法的。如果要声明函数指针,正确的语法应该是 int (*p)()。
补充说明:
在理解指针声明时,可以使用从右向左读的方法
方括号 \[\] 的优先级高于 *
声明中括号的位置很重要,会影响整个声明的含义
合理使用括号可以改变操作符的优先级,从而得到不同的指针类型
因此,只有 A 选项的描述是准确的。
知识点:C++、2018、C语言
题友讨论(15)
单选题
C语言
下面程序的运行结果是()
|-------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 7 8 9 |int main(){``char ch[7] = {"65ab21"};``int i, s=0;``for(i = 0; ch[i] >= '0' && ch[i] <= '9'; i += 2)``s = 10*s + ch[i] - '0';``printf("%d\n", s);``return 0;}|A
12ba56
B
6521
C
6
D
62
正确答案:C
你的答案:D
官方解析:
【解释】进入for循环时,i的值为0,表达式(chi>='0' && chi<='9')是用来检测chi是否为数字字符,因为ch0是'6',所以表达式为真,进入循环体中执行s=10*s+chi-'0';语句,该语句的功能就是将数字串转换成相应的整数,因s的初值为0,所以s的结果为6。语句执行完后,再将i增2,再判断ch2是否为数字字符,因ch2是'a',表达式为假,循环退出。所以s的值输出为6,故正确答案是C.
知识点:C语言
题友讨论(17)
单选题
C++
C语言
print()函数是一个类的常成员函数,它无返回值,下列表示中正确的是()
A
const void print();
B
void const print();
C
void print() const;
D
void print(const);
正确答案:C
你的答案:B
官方解析:
在C++中,const成员函数的声明语法要求将const关键字放在函数参数列表的后面、函数体的前面,表示该成员函数不会修改类的数据成员。因此C选项 void print() const; 是正确的语法形式。
分析其他选项:
A选项 const void print(); 错误。const修饰返回值类型是无意义的,因为返回值是一个临时值,本身无法被修改。而且本题明确说明函数无返回值。
B选项 void const print(); 错误。const位置不正确,这种写法在C++中没有实际意义。
D选项 void print(const); 错误。这种写法语法错误,const后面缺少说明修饰的对象。如果要表示参数为常量,应该写成void print(const type)的形式。
补充说明:const成员函数的作用是向编译器承诺不会修改类的数据成员(除了被mutable修饰的成员),这样的函数可以被const对象调用。这是C++中实现常对象语义的重要机制。
知识点:C++、C语言
题友讨论(19)
单选题
C++
C语言
设有语句
|---|----------------|
| 1 |int b[3][4];|下面语句正确的是()
A
int *p\[\]={b0,b1,b2};
B
int *p\[\]=b;
C
int *p2={b0,b1,b2};
D
int *p\[\]=(int *\[\])b;
正确答案:A
官方解析:
这道题目考察了数组指针和多维数组的基本知识点。A选项是正确的,因为b0、b1、b2都表示二维数组b中的一维数组的首地址,它们都是int*类型,可以用来初始化指针数组int *p\[\]。
分析各个选项:
A正确:int *p\[\]={b0,b1,b2}声明了一个指针数组,使用二维数组b的每一行的首地址进行初始化,数组大小由初始化列表自动确定为3。
B错误:int *p\[\]=b这种写法不正确,因为b是二维数组名,类型是int (*)4,不能直接赋值给int*类型的指针数组。
C错误:int *p2={b0,b1,b2}声明的数组大小为2,但初始化列表包含3个元素,数组大小与初始化元素个数不匹配。
D错误:int *p\[\]=(int *\[\])b这种类型转换语法不正确,二维数组不能通过这种方式强制转换为指针数组。
总的来说,要正确使用二维数组的一维数组首地址来初始化指针数组,A选项的写法是最准确的。
知识点:C++、C语言
题友讨论(18)
单选题
C语言
下面程序会输出什么:
|-------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |#include <stdio.h>#include <string.h>staticinta = 1;voidfun1(``void``) { a = 2; }voidfun2(``void``) { ``inta = 3; }voidfun3(``void``) { ``staticinta = 4; }intmain() {``printf``(``"%d"``, a);``fun1();``printf``(``"%d"``, a);``fun2();``printf``(``"%d"``, a);``fun3( );``printf``(``"%d"``, a);}|A
1 2 3 4
B
1 2 2 2
C
1 2 2 4
D
1 1 1 4
正确答案:B
官方解析:
这道题目考察了C语言中变量的作用域和生命周期,尤其是静态变量和局部变量的特性。
题目中声明了一个全局静态变量a=1,然后定义了三个函数来操作变量a:
第一次打印时输出1,因为此时全局静态变量a的值是1
调用fun1()后,将全局静态变量a修改为2,所以第二次打印输出2
fun2()中定义了局部变量a=3,但这个局部变量的作用域仅限于fun2()内部,不会影响全局静态变量a的值,所以第三次打印仍然是2
fun3()中定义了一个静态局部变量a=4,这个变量的作用域也仅限于fun3()内部,同样不会影响全局静态变量a的值,所以第四次打印还是2
因此最终输出序列是:1 2 2 2
分析其他选项的错误:
A错误:全局变量a的值不会受到fun2和fun3中局部变量的影响
C错误:静态局部变量不会影响全局静态变量的值
D错误:同C,且fun3中的静态局部变量不会改变全局静态变量的值
这道题目很好地体现了C语言中变量作用域的规则,以及全局变量、局部变量和静态局部变量之间的关系。
知识点:C语言
题友讨论(40)
单选题
C语言
共同体变量所占的内存长度一定等于最长的成员的长度。请问这句话的说法是正确的吗?
A
正确
B
错误
正确答案:B
官方解析:
共同体(union)变量所占的内存长度并不一定等于最长成员的长度,而是等于最长成员长度的整数倍。这是因为:
共同体要保证所有成员都从同一个内存位置开始存储,并且要满足所有成员的对齐要求
内存对齐原则要求共同体的大小必须是其所有成员中最大对齐要求的整数倍
举例说明:
```c
union data {
char a; // 1字节
short b; // 2字节
int c; // 4字节
};
```
这个共同体的大小不会是4字节(最长成员int的长度),而是可能是4字节或更大,取决于编译器的对齐要求。
因此A选项说"一定等于最长的成员的长度"是错误的。实际上共同体的长度是:
大于或等于最长成员的长度
是最大对齐要求的整数倍
具体取值与编译器和系统架构有关
所以B选项"错误"是正确答案。这体现了计算机系统中内存对齐的重要原则。
知识点:C语言
题友讨论(28)
单选题
C语言
假设C语言程序里使用malloc申请了内存,但是没有free掉,那么当该进程被kill之后,操作系统会()
A
内存泄露
B
segmentation fault
C
core dump
D
以上都不对
正确答案:D
官方解析:
进程退出时(包括被kill),操作系统会自动回收该进程所占用的所有资源,包括向操作系统申请的内存空间。因此当进程被kill后,即使程序中malloc申请的内存没有手动free,操作系统也会自动回收这些内存,不会产生任何异常情况。这是操作系统的内存管理机制决定的。
分析其他选项:
A错误:内存泄漏是指程序运行过程中分配的内存未被释放而导致系统内存占用不断增加。但进程结束后,这种情况就不存在了,因为操作系统会回收所有资源。
B错误:段错误(Segmentation fault)是程序试图访问无权限访问的内存地址时发生的错误。这与进程被kill后的内存回收无关。
C错误:Core dump是程序异常终止时产生的内存映像文件,用于调试。进程正常被kill并不会产生core dump文件。
这个知识点考察了操作系统的内存管理机制,理解进程的资源管理和回收机制对系统编程非常重要。虽然编程时应该养成正确释放内存的好习惯,但进程结束时操作系统会确保资源被正确回收。
知识点:C++工程师、2019、C语言
题友讨论(6)
单选题
C语言
在一个64位的操作系统中定义如下结构体:
|-------------|-------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 |struct st_task{``uint16_t id;``uint32_t value;``uint64_t timestamp;};|同时定义fool函数如下:
|---------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 7 |voidfool(){``st_task task = {};``uint64_t a = ``0x00010001``;``memcpy(&task, &a, sizeof(uint64_t));``printf(``"%11u,%11u,%11u"``, task.id, task.value, task.timestamp);}|上述fool()程序的执行结果为()
A
1,0,0
B
1,1,0
C
0,1,1
D
0,0,1
正确答案:A
你的答案:B
官方解析:
这道题目考察了内存拷贝和结构体内存布局的理解。
关键点分析:
结构体 st_task 包含三个成员:16位的id、32位的value和64位的timestamp
uint64_t a = 0x00010001 是一个64位整数
memcpy 将 a 的值按字节复制到 task 结构体的内存空间中
具体分析过程:
- 0x00010001 在内存中的表示(小端序)为:
01 00 01 00 00 00 00 00
- 当这8个字节被复制到结构体时,会按照结构体成员的排列依次映射:
task.id (16位) 得到 0x0001,即十进制的 1
task.value (32位) 得到 0x00000000,即十进制的 0
task.timestamp (64位) 由于只复制了8字节,剩余部分为0,即十进制的 0
所以输出结果为 1,0,0,对应选项A。
其他选项错误原因:
B选项(1,1,0):错误理解了value部分的值
C选项(0,1,1):完全错误理解了内存映射方式
D选项(0,0,1):timestamp的值不可能是1,因为高位都是0
这个题目很好地体现了在进行内存操作时需要注意的字节对齐和数据在内存中的实际存储方式。
知识点:C语言
题友讨论(78)
单选题
C语言
|-----------|---------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 |inti=0;constintci=i;auto b=ci; ``//(1)int*p=&i;decltype(*p) c=i;``//(2)|以上(1)(2)中变量b,c类型为()
A
const int ,int
B
int,int&
C
const int,int*
D
int,int*
正确答案:B
官方解析:
这道题目考察了C++中auto和decltype关键字的类型推导规则。让我们逐个分析:
对于(1) auto b=ci:
ci是const int类型
当auto用于初始化时会忽略顶层const属性
所以b的类型就是int
对于(2) decltype(*p) c=i:
p是int*类型
*p解引用操作会得到左值
decltype对表达式结果为左值时,会推导出引用类型
所以c的类型是int&
因此,b的类型是int,c的类型是int&,B选项正确。
分析其他选项:
A错误:auto会忽略顶层const,所以b不是const int类型
C错误:decltype(*p)得到的是引用类型而不是指针类型
D错误:同C,c的类型是引用而不是指针
这里的关键点是要理解:
auto会忽略顶层const
decltype(*指针)会得到引用类型
auto和decltype有不同的类型推导规则
知识点:C++工程师、2017、C语言
题友讨论(26)
多选题
C语言
在C语言中,已知x<=y && y<=z,下面哪个条件是必定成立的。
A
max(x,y) <= z
B
x < y && y < z
C
x < z || y == z
D
x <= min(y, z)
正确答案:ACD
官方解析:
已知题目条件 x<=y && y<=z,我们需要分析哪些条件一定成立。
A选项 max(x,y) <= z 正确:
因为已知 y<=z,而 x<=y,所以 x 和 y 中的较大值一定小于等于 z,即 max(x,y) <= z 成立。
B选项 x题目条件中是小于等于(<=),而不是严格小于(<)。当 x=y 或 y=z 时,该条件就不成立。
C选项 x因为已知 x<=y && y<=z,所以要么 y=z,要么 y如果 y=z,则 C 的后半部分成立;
如果 y因此 C 选项一定成立。
D选项 x <= min(y,z) 正确:
因为已知 y<=z,所以 min(y,z)=y;
又因为 x<=y,所以 x<=min(y,z) 成立。
综上所述,ACD 三个选项都是必定成立的,而 B 选项在 x=y 或 y=z 的情况下不成立,因此 ACD 是正确答案。
知识点:C语言
题友讨论(1)
多选题
C++
C语言
下面运算符不能被重载的是()
A
做用域运算符"::"
B
对象成员运算符"."
C
指针成员运算符"->"
D
三目运算符"? :"
正确答案:ABD
官方解析:
在C++中,有一些运算符是不能被重载的,ABD都属于这种情况。
详细分析如下:
A选项中的作用域运算符"::"不能被重载,因为它是用来访问命名空间和类的作用域的特殊符号,这个运算符的语义必须保持不变,否则会影响代码的基本组织结构。
B选项中的对象成员访问运算符"."同样不能重载,因为它是用来直接访问对象成员的基本运算符,如果允许重载会导致对象成员访问的基本语义被改变。
D选项中的条件运算符(三目运算符)"?:"也不能被重载,因为它涉及到程序的基本控制流程,允许重载可能会造成程序逻辑的混乱。
C选项"指针成员运算符'->'"是可以被重载的,这也是智能指针等高级编程技术得以实现的基础。通过重载->运算符,可以实现自定义的指针行为。
除了题目中提到的这些,其他不能重载的运算符还包括:
sizeof运算符
成员指针访问运算符".*"
成员指针调用运算符"->*"
预处理符号"#"
这些限制的主要目的是保持C++语言核心特性的一致性和可预测性。
知识点:C++、C++工程师、2018、C语言
=====================================================================
试卷02:
从本质上看,引用是被应用变量的( )
A
拷贝
B
别名
C
复制
D
克隆
正确答案:B
官方解析:
引用本质上是变量的别名(alias),这说明引用和其引用的变量实际上是同一块内存空间的不同名称。选择B是正确的。
引用与指针不同,它必须在创建时初始化,并且初始化后不能再指向其他对象。引用实际上就是对一个变量起的另一个名字,对引用的任何操作都等同于对原变量的操作。
分析其他选项:
A错误:拷贝意味着创建了新的内存空间并复制了原始数据,这与引用的本质不符
C错误:复制与拷贝类似,会创建新的数据副本,而引用并不创建新的数据
D错误:克隆是创建一个对象的副本,会占用新的内存空间,这与引用指向同一内存空间的特性不符
在程序设计中,引用机制的这种别名特性使得我们可以在不复制数据的情况下传递和操作大型对象,提高了程序的执行效率。
知识点:C++
题友讨论(3)
单选题
C++
假设有函数模板定义如下:template <typename T> Max( T a, T b ,T &c) { c= a + b; } 下列选项正确的是( )。
A
int x, y; char z; Max( x, y, z );
B
double x, y, z; Max( x, y, z );
C
int x, y; float z; Max( x, y, z );
D
float x; double y, z; Max( x, y, z );
正确答案:B
官方解析:
这道题目考察了函数模板的参数类型匹配规则。B选项是正确的,因为所有参数类型都是double类型,满足模板要求的参数类型一致性。
分析各选项:
B选项:三个参数x、y、z都是double类型,符合模板定义中要求的参数类型T必须一致的原则,因此可以正确调用。
其他选项错误原因:
A选项:x、y是int类型,而z是char类型,参数类型不一致,不满足模板要求。
C选项:x、y是int类型,而z是float类型,参数类型不一致,不满足模板要求。
D选项:x是float类型,y、z是double类型,三个参数类型不一致,不满足模板要求。
关键点:
函数模板要求所有参数类型必须一致,即都必须是同一个类型T
模板函数的第三个参数是引用类型,更要求类型严格匹配
不同的数值类型(如int、float、double等)被视为不同的类型,即使它们之间可以隐式转换,在模板实例化时也被认为是不同的类型
知识点:C++
题友讨论(9)
单选题
C++
C语言
删除对象时,系统自动调用()
A
成员函数
B
构造函数
C
析构函数
D
友元函数
正确答案:C
官方解析:
在面向对象编程中,析构函数是一个特殊的成员函数,当对象被删除或者生命周期结束时,系统会自动调用该对象的析构函数来进行清理工作。所以C选项"析构函数"是正确答案。
析构函数的主要作用是:
释放对象在生命周期内申请的堆内存资源
完成对象被销毁前的一些清理工作
确保对象资源得到及时回收,防止内存泄漏
分析其他选项:
A错误:成员函数是类中定义的普通函数,需要手动调用,不会被系统自动调用
B错误:构造函数是在创建对象时被调用,而不是删除对象时
D错误:友元函数不是类的成员函数,它只是一个可以访问类的私有成员的外部函数,不会被系统自动调用
特别说明:析构函数的命名规则是在类名前加"~"符号,如~ClassName(),一个类只能有一个析构函数,且不能带参数。析构函数对于资源管理和避免内存泄漏非常重要。
知识点:C++、C语言
题友讨论(3)
单选题
C++
对C++中主函数的描述正确的是( )
A
名称为main,可为多个
B
名称不限,可为多个
C
名称为main,必须有且只有一个
D
名称默认是main可以通过编译器修改,但是必须有且只有一个
正确答案:D
你的答案:C
官方解析:
C++程序中主函数是程序的入口点,D选项正确。在C++中,主函数的默认名称是main,这是语言规范所规定的标准名称。虽然某些编译器允许通过特定选项修改入口函数的名称,但在一个程序中必须有且仅有一个主函数作为程序的唯一入口点。
分析其他选项:
A错误:虽然主函数名称确实是main,但一个程序中不能有多个主函数。如果定义多个main函数,会导致链接错误,因为程序不知道该从哪个入口点开始执行。
B错误:主函数的名称不是任意的,必须是main(除非通过特定编译器选项修改)。这是C++语言规范的要求,用以确保程序的标准化和可移植性。
C错误:虽然正确指出主函数名称为main且必须唯一,但忽略了某些编译器提供修改入口函数名称的可能性。这个选项过于绝对。
补充说明:主函数通常的标准形式是int main()或int main(int argc, char* argv\[\]),返回值类型必须是int。这是确保程序能够向操作系统正确返回执行状态的必要条件。
知识点:C++
题友讨论(10)
单选题
C++
C语言
执行如下代码后输出结果为()
|-------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 |intmain() {``inta[5] = {1, 2, 3, 4, 5};``int*ptr = (``int``*)(&a + 1);``printf``(``"%d, %d"``, *(a + 1), *(ptr - 1));``return0;}|A
1,1
B
1,3
C
3,3
D
2,5
正确答案:D
官方解析:
这道题目主要考察了指针运算和数组在内存中的存储。让我们逐步分析代码:
首先定义了一个整型数组 a5 = {1, 2, 3, 4, 5}
第二行代码 int *ptr = (int*)(&a + 1) 的含义是:
&a 得到整个数组的首地址
&a + 1 会跳过整个数组的长度(5个int的长度)
(int*)进行类型转换,将地址赋给指针ptr
- printf中有两个表达式:
*(a + 1):数组名a等价于首元素地址,a + 1指向第二个元素,所以值为2
*(ptr - 1):ptr指向数组末尾后的位置,向前移动一个int长度,指向最后一个元素,值为5
所以最终输出是 2, 5,D选项正确。
其他选项错误原因:
A选项(1,1):完全理解错误指针运算
B选项(1,3):错误理解了ptr的位置和移动
C选项(3,3):混淆了数组索引和指针运算的关系
这道题的关键是要理解:
数组名的隐式转换
指针的算术运算
&a+1 会跳过整个数组的长度
知识点:C++、C++工程师、2019、C语言
题友讨论(19)
单选题
C++
当一个类对象的生命周期结束后,关于调用析构函数的描述正确的是:()
A
如果派生类没有定义析构函数,则只调用基类的析构函数
B
如果基类没有定义析构函数,则只调用派生类的析构函数
C
先调用派生类的析构函数,后调用基类的析构函数
D
先调用基类的析构函数,后调用派生类的析构函数
正确答案:C
官方解析:
在C++类的继承关系中,当一个派生类对象生命周期结束时,析构函数的调用遵循"先派生后基类"的顺序,这与构造函数的调用顺序(先基类后派生)正好相反。这是因为析构的过程应该与构造的过程相反,保证对象可以完整地被清理。
C选项正确,它准确描述了析构函数的调用顺序:先执行派生类的析构函数,完成派生类特有资源的清理,然后再调用基类的析构函数,清理基类的资源。这种顺序符合面向对象的设计原则。
分析其他选项的错误之处:
A选项错误:即使派生类没有显式定义析构函数,编译器也会自动生成一个默认的析构函数,并且仍然会按照正确的顺序调用基类析构函数。
B选项错误:同理,如果基类没有显式定义析构函数,编译器也会生成默认的析构函数。而且基类的析构函数必然会被调用。
D选项错误:这完全颠倒了析构函数的调用顺序。如果先调用基类的析构函数,会导致派生类中尚未清理的资源可能访问已经被销毁的基类资源,造成不安全的情况。
需要注意的是,为了确保正确的析构顺序,基类的析构函数应该声明为虚函数(virtual),这样才能保证在使用基类指针删除派生类对象时能正确调用派生类的析构函数。
知识点:C++
题友讨论(16)
单选题
C++
C语言
逻辑表达式 (x>0 || y==5) 的相反表达式为( )?
A
x<=0 || y!=5
B
x<=0 && y!=5
C
x>0 || y!=5
D
x>0 && y==5
正确答案:B
官方解析:
要理解这道题目,我们需要掌握逻辑运算中"取反"的规则:
- 对于单个逻辑表达式的取反:
x>0 的取反是 x<=0
y==5 的取反是 y!=5
- 对于使用逻辑运算符连接的复合表达式,取反时需要:
将 || (或) 变成 && (与)
将 && (与) 变成 || (或)
同时对各个子表达式取反
因此,对于原表达式 (x>0 || y==5) 的取反步骤是:
|| 变成 &&
x>0 变成 x<=0
y==5 变成 y!=5
最终得到:x<=0 && y!=5,所以B选项正确。
分析其他选项:
A错误:x<=0 || y!=5 只是对各个子表达式取反,但未改变逻辑运算符
C错误:x>0 || y!=5 只改变了第二个子表达式,与原式不是相反关系
D错误:x>0 && y==5 既没有对子表达式取反,也没有正确处理逻辑运算符
知识点:C++、C语言
题友讨论(18)
单选题
C++
以下对封装的描述正确的是:
A
只能对一个类中的方法进行封装,不能对属性进行封装
B
如果子类继承了父类,对于父类中进行封装的方法,子类仍然可以直接调用
C
封装的意义不大,因此在编码时尽量不要使用
D
封装的主要作用在于对外隐藏内部实现细节,增强程序的安全性
正确答案:D
官方解析:
封装是面向对象编程的基本特征之一,D选项正确地指出了封装的核心作用 - 隐藏对象的内部实现细节,只向外部提供必要的接口。这样可以提高代码的安全性和可维护性,防止外部代码直接访问和修改对象的内部状态。
分析其他选项的错误之处:
A错误:封装不仅可以对方法进行封装,也可以对属性进行封装。通过访问修饰符(private、protected等)可以控制类的属性和方法的访问权限。
B错误:如果父类中的方法被private修饰符封装,子类是无法直接访问这些方法的。封装的访问权限对子类同样有效。
C错误:封装是面向对象编程的重要特性,它能够:
保护数据的完整性和安全性
降低代码之间的耦合度
提高代码的可维护性和灵活性
因此在实际编程中应该恰当地使用封装特性。
通过合理使用封装,我们可以让类只暴露必要的接口,隐藏具体实现细节,这样即使内部实现发生变化,只要接口保持不变,就不会影响到使用该类的其他代码。
知识点:C++、Java工程师、2017
题友讨论(2)
单选题
C++
设在32位机器上的C++语言中,int类型数据占4个字节,则short类型数据占 2个字节。说法是否正确?
A
正确
B
错误
正确答案:A
官方解析:
在32位机器上的C++语言中,数据类型的大小确实存在一定的规律。当int类型占4个字节时,short类型占2个字节这个说法是正确的。
这是因为:
C++标准规定了数据类型的最小长度要求,同时也规定了不同整型之间的大小关系:short ≤ int ≤ long
在32位系统中,int通常被设计为机器字长,即4字节(32位)
short作为比int小的整型,在保证足够表示范围的同时还要节省空间,因此被设计为2字节
这种设计既符合C++标准规范,又满足了实际应用需求:
short (2字节): 表示范围 -32768~32767
int (4字节): 表示范围 -2147483648~2147483647
虽然C++标准并未严格规定具体字节数,但在主流的32位系统实现中,当int为4字节时,short确实普遍采用2字节的大小。这种实现既保证了数据类型的层次性,又兼顾了内存使用效率。
因此A选项"正确"是对的,而B选项"错误"显然不符合实际情况。
知识点:C++
题友讨论(11)
单选题
C++
以下程序执行后的输出结果是:
|-------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |classA {public``:``A() { std::cout << ``"A"``; }};classC: ``publicA {public``:``C() { std::cout << ``"C"``; }};voidmain() {``C cObj;}|A
CA
B
AC
C
A
D
C
正确答案:B
官方解析:
这道题目考察了C++中类的继承关系下构造函数的调用顺序。答案为B (AC)是正确的。
在C++中,当创建一个派生类对象时,构造函数的调用顺序遵循以下规则:
首先调用基类的构造函数
然后调用派生类的构造函数
具体分析这段代码:
当执行C cObj;时,会创建一个C类的对象
由于C类继承自A类,首先会调用A类的构造函数,输出"A"
然后调用C类的构造函数,输出"C"
因此最终输出结果为"AC"
分析其他选项:
A选项(CA)错误:违背了构造函数调用的顺序规则,基类构造函数一定先于派生类构造函数执行
C选项(A)错误:输出不完整,忽略了派生类构造函数的输出
D选项(C)错误:输出不完整,忽略了基类构造函数的输出
这是面向对象编程中一个重要的基础知识点,在实际编程中经常用到。理解构造函数的调用顺序对于正确初始化对象非常重要。
知识点:C++、C++工程师、游戏研发工程师、2019
题友讨论(4)
单选题
C++
有这样一道 C++ 题目:对一个 32 位数按照 bit 位进行翻转,小明实现的代码如下:
|-------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |#include<iostream>classSolution {public``:``uint32_t reverseBits(uint32_t n) {``if``(n==0) ``return0;``uint32_t res = 0;``for``(``inti=0;i<32;++i) {``uint32_t temp = n%2;``n = n>>1;``res = res<<1+ temp;``}``returnres;``}};intmain() {``Solution s;``uint32_t num = 43261596;``std::cout << s.reverseBits(num) << std::endl;``return0;}|已知该代码 reverseBits 有一处小问题,请问是哪一行代码实现有问题()
A
5: if(n==0) return 0;
B
10 : res = res<<1+ temp;
C
9 : n = n>>1;
D
8 : uint32_t temp = n%2;
正确答案:B
官方解析:
该代码实现有问题,第10行没有注意<< 和 + 的优先级,+优先级高于<<,上述实现会导致最后res左移位数不符合预期,导致结果为0。
知识点:C++
题友讨论(0)
单选题
C++
关于C++的纯虚函数,下列说法错误的是()
A
纯虚函数不能实例化对象,拥有纯虚函数的类是抽象类
B
纯虚函数不能做指针和引用
C
纯虚函数声明的最后面"=0"并不表示函数返回值为0,它只起形式上的作用
D
虚函数和纯虚函数都可以在子类中被重载,以多态的形式被调用
正确答案:B
官方解析:
这道题目考察了C++中纯虚函数的基本概念。B选项是错误的,因为纯虚函数可以使用指针和引用,这是C++中实现多态的重要机制。纯虚函数通常通过基类指针或引用来调用派生类中的具体实现。
分析其他选项:
A正确:包含纯虚函数的类确实是抽象类,不能直接实例化对象。抽象类只能作为基类使用,必须由派生类实现其所有纯虚函数后才能创建对象。
C正确:纯虚函数声明末尾的"=0"只是一个语法标记,用来表明这是一个纯虚函数,与函数返回值无关。这是C++语言规定的语法形式。
D正确:虚函数和纯虚函数都支持在派生类中重写(override),这是C++实现多态的基础。当通过基类指针或引用调用这些函数时,会根据对象的实际类型调用相应的函数实现。
总的来说,纯虚函数是C++面向对象编程中的重要概念,它通过指针和引用实现多态,而不是像B选项说的那样不能使用指针和引用。
知识点:C++
题友讨论(4)
单选题
C++
下面程序应该输出多少?
|----------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 7 8 9 10 11 12 |char*c[] = { ``"ENTER"``, ``"NEW"``, ``"POINT"``, ``"FIRST"};char**cp[] = { c+``3``, c+``2``, c+``1``, c };char***cpp = cp;intmain(``void``){``printf(``"%s"``, **++cpp);``printf(``"%s"``, *--*++cpp+``3``);``printf(``"%s"``, *cpp[-``2``]+``3``);``printf(``"%s\n"``, cpp[-``1``][-``1``]+``1``);``return0``;}|A
POINTERSTEW
B
FERSTEPOINW
C
NEWPOINTW
D
POINTFIREST
正确答案:A
官方解析:
这道题目考察了C语言中指针数组和多级指针的理解。让我们逐步分析程序的执行过程:
- 首先理解初始化:
c是一个字符串数组,包含4个字符串
cp是一个指针数组,存放指向c数组不同元素的指针
cpp是一个指向cp数组的指针
- 逐行分析输出:
第一个printf("%s", **++cpp):
++cpp使cpp指向cp1,即c+2
**cpp得到字符串"POINT"
第二个printf("%s", *--*++cpp+3):
++cpp使cpp指向cp2
--*使其指向c
+3跳过"ENTER"的前3个字符
输出"ER"
第三个printf("%s", *cpp-2+3):
cpp-2相当于cp0,指向c+3
取"FIRST"从第4个字符开始
输出"ST"
第四个printf("%s ", cpp-1-1+1):
cpp-1-1得到"NEW"
+1跳过第一个字符
输出"EW"
所以最终输出为"POINTERSTEW",与A选项完全匹配。
其他选项分析:
B选项"FERSTEPOINW":顺序和内容都不正确
C选项"NEWPOINTW":缺少了部分字符
D选项"POINTFIREST":字符组合顺序错误
这道题体现了C语言指针操作的复杂性,需要仔细跟踪每一步指针的移动和解引用操作。
知识点:C++
题友讨论(103)
单选题
链表
C++
单链表的每个结点中包括一个指针link,它指向该结点的后继结点。现要将指针q指向的新结点插入到指针p指向的单链表结点之后,下面的操作系列中哪一个是正确的()
A
q=p->link;p->link=q->link
B
p=p->link=q->link;p->link
C
q->link=p->link;p->link=q;
D
p->link=1;q->link=p->link
正确答案:C
你的答案:A
官方解析:
在单链表中插入新结点时需要正确处理指针的连接关系。C选项"q->link=p->link;p->link=q;"是正确的插入操作顺序。
具体分析过程如下:
第一步"q->link=p->link":将新结点q的link指针指向p的后继结点,保证不会丢失原有的链表连接
第二步"p->link=q":将p的link指针指向新结点q,完成插入操作
其他选项错误原因:
A选项"q=p->link;p->link=q->link":
第一步直接修改q指针本身,丢失了对新结点的引用
操作顺序错误,会导致链表断裂
B选项"p=p->link=q->link;p->link":
语法错误,赋值表达式混乱
改变了p指针本身的指向,破坏了原有结构
D选项"p->link=1;q->link=p->link":
第一步赋值为1是无意义的
操作顺序错误,会导致链表连接丢失
所以只有C选项能够正确完成新结点的插入操作,既保持了链表的完整性,又实现了正确的插入。这是链表插入操作的标准做法。
知识点:C++、链表、测试、后端开发、客户端开发、前端开发、人工智能/算法、数据、运维/技术支持
题友讨论(12)
单选题
C++
C语言
下面程序的输出结果是()
|---------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 7 |#include <stdio.h>intmain() {``intintArray[] = {1, 2, 3, 4, 5};``int*p = (``int*)(&intArray+1);``printf``(``"%d,%d"``,*(intArray+1),*(p-1));``return0;}|A
1,5
B
1,6
C
2,4
D
2,5
正确答案:D
官方解析:
这道题目考察了C语言中的指针运算和数组访问。让我们逐步分析程序的执行过程:
intArray5定义了一个包含5个整数的数组{1,2,3,4,5}
*(intArray+1)访问的是数组的第二个元素,即2
&intArray获取的是整个数组的地址,(&intArray+1)会跳过整个数组,指向数组结束后的位置
p = (int *)(&intArray+1)将这个地址转换为int指针
p-1会回退一个int大小,正好指向数组的最后一个元素,所以*(p-1)的值是5
因此printf("%d,%d",*(intArray+1),*(p-1))输出的结果是2,5,D选项正确。
分析其他选项:
A选项(1,5)错误:第一个表达式*(intArray+1)是2而不是1
B选项(1,6)错误:两个值都计算错误
C选项(2,4)错误:第二个表达式*(p-1)是5而不是4
这道题的关键点在于理解:
数组名作为指针的运算
指针的加减运算与数据类型的关系
&intArray+1跳过整个数组的原理
知识点:C++、2018、C语言
题友讨论(9)
单选题
C++
int Func(int,int);不可与下列哪个函数构成重载( )
A
int Func(int,int,int);
B
double Func(int,int);
C
double Func(double,double);
D
double Func(int,double);
正确答案:B
官方解析:
在C++中,函数重载要求同名函数必须在参数个数、参数类型或参数顺序上有所不同,而返回值类型的不同不能构成重载。B选项中的函数与原函数相比,只有返回值类型不同(一个是int,一个是double),参数列表完全相同(都是int,int),因此不能构成重载。
分析其他选项:
A正确:该函数与原函数相比参数个数不同(三个参数vs两个参数),可以构成重载。
C正确:该函数与原函数相比参数类型不同(两个double vs 两个int),可以构成重载。
D正确:该函数与原函数相比参数类型不同(第二个参数一个是double,一个是int),可以构成重载。
总结:函数重载的判定标准是函数的参数列表(参数个数、类型或顺序),而不是返回值类型。因此只有返回值类型不同的函数不能构成重载,这也是为了避免在函数调用时的二义性。
知识点:C++
题友讨论(18)
单选题
C++
在类定义时,说明访问权限的关键字private、public和protected出现 任意次数。说法是否正确?
A
正确
B
错误
正确答案:A
官方解析:
在Java类定义中,访问权限修饰符(private、public和protected)的使用次数确实是可以任意的。
这是因为:
一个类中可以定义任意数量的成员(字段和方法)
每个成员都可以独立使用这些访问修饰符
不同的成员可能需要不同的访问权限,取决于具体的设计需求
举例说明:
- 可以有多个private字段:
private int id;
private String name;
private double salary;
- 可以有多个public方法:
public void setName();
public String getName();
public void process();
- 可以有多个protected成员:
protected void init();
protected int count;
这种灵活性是面向对象设计所必需的,让开发者能够根据封装原则和具体需求为每个成员选择合适的访问级别。因此A选项"正确"是对的,这些访问修饰符在类定义中可以出现任意次数。
知识点:C++
题友讨论(9)
单选题
C++
有如下程序:执行后的输出结果应该是:
|----------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 7 8 9 10 |#include <iostream>classBASE{public``:~BASE(){std::cout<<``"BASE"``;}};classDERIVED: ``publicBASE{public``:~DERIVED(){std::cout<<``"DERIVED"``;}};intmain(){DERIVED x;}|A
BASE
B
DERIVED
C
BASEDERIVED
D
DERIVEDBASE
正确答案:D
官方解析:
这道题目考察了C++中析构函数的调用顺序。正确答案是D(DERIVEDBASE),原因如下:
在C++中,当派生类对象被销毁时,析构函数的调用顺序是:先调用派生类的析构函数,再调用基类的析构函数。这与构造函数的调用顺序(先基类后派生类)相反。
具体分析:
程序中创建了一个DERIVED类型的对象x
当x对象生命周期结束时(main函数结束时):
首先调用DERIVED类的析构函数,输出"DERIVED"
然后自动调用BASE类的析构函数,输出"BASE"
因此最终输出结果为"DERIVEDBASE"
其他选项错误原因:
A(BASE):只包含基类析构函数的输出,忽略了派生类析构函数的输出
B(DERIVED):只包含派生类析构函数的输出,忽略了基类析构函数的输出
C(BASEDERIVED):顺序错误,这是构造函数的调用顺序,而不是析构函数的调用顺序
这是C++语言的重要特性,析构函数的这种调用顺序确保了对象的正确清理,保证派生类的资源在基类的资源之前被释放。
知识点:C++、C++工程师、游戏研发工程师、2019
题友讨论(19)
单选题
C++
阅读下面 C++ 代码,输出结果为()
|----------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |#include <iostream>using namespace std;classbase1 {private``: ``inta, b;public``:``base1(``inti) : b(i + ``1``), a(b) {}``base1():b(``0``), a(b) {}``intget_a() {``returna;``}``intget_b() {``returnb;``}};intmain() {``base1 obj1(``11``);``cout << obj1.get_a() << ``" "<< obj1.get_b() << endl;``return0``;}|A
12 12
B
随机数 12
C
随机数 随机数
D
12 随机数
正确答案:B
官方解析:
这道题目考察了C++中类成员初始化列表的执行顺序以及类成员变量的初始化规则。
正确答案是B(随机数 12),分析如下:
类成员初始化列表的执行顺序与成员声明的顺序有关,而不是初始化列表中的顺序。在base1类中,成员变量的声明顺序是先a后b。
当调用base1(11)构造函数时:
虽然初始化列表写作 b(i + 1), a(b),但实际执行顺序是按照声明顺序
先初始化a,此时使用b的值,但b还未初始化,所以a的值是未定义的(随机值)
后初始化b = i + 1,即b = 12
- 所以当执行:
obj1.get_a() 输出的是随机值
obj1.get_b() 输出的是12
分析其他选项:
A选项(12 12)错误:因为没有考虑到成员初始化顺序导致a的值是随机的
C选项(随机数 随机数)错误:b的值是确定的12
D选项(12 随机数)错误:与实际情况相反,a是随机值而b是确定值
这个例子说明在使用初始化列表时要特别注意成员变量的声明顺序,建议初始化时使用确定值而不是其他尚未初始化的成员变量。
知识点:C++、C++工程师、2018
题友讨论(20)
单选题
C++
下列程序的输出结果是
|----------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 7 8 9 10 11 12 |#include<iostream>using namespace std;intmain(){``inta[] = {``2``, ``4``, ``6``, ``8``, ``10``}, *p, **k;``p = a;``k = &p;``printf(``" % d"``, *(p++));``printf(``" % d\n"``, **k);``return0``;}|A
4 4
B
2 4
C
2 2
D
4 6
正确答案:B
官方解析:
这道题目主要考察指针运算和指针的指针的理解。让我们逐步分析代码的执行过程:
- 首先定义了数组a、指针p和指针的指针k:
a是包含5个元素的整型数组{2,4,6,8,10}
p是指向整型的指针
k是指向指针p的指针
- p = a 让p指向数组a的首地址,此时p指向2
k = &p 让k指向p的地址,此时*k就是p,**k就是p指向的值
- 第一个printf语句 *(p++):
*(p++) 先取p当前指向的值(2)
由于是后缀++,所以在输出2之后,p才向后移动一位,指向4
- 第二个printf语句 **k:
此时k指向p,而p已经指向了4
所以**k等于*p等于4
因此输出结果为"2 4",B选项正确。
分析其他选项:
A选项(4 4)错误:第一个输出不是4,因为p++是后缀操作
C选项(2 2)错误:第二个输出不是2,因为p已经后移
D选项(4 6)错误:两个值都不正确
这道题的关键在于理解后缀自增运算符的执行时机,以及指针的指针的解引用操作。
知识点:C++
题友讨论(69)
单选题
C++
C语言
使文件指针重新定位到文件读写的首地址的函数是()
A
ftell( )
B
fseek( )
C
rewind ()
D
ferror ()
正确答案:C
官方解析:
rewind()函数是C语言标准库中专门用于将文件指针重新定位到文件起始位置的函数,它等价于fseek(fp, 0L, SEEK_SET),这是最直接且专门的文件指针重置函数。
分析其他选项:
A. ftell()函数是用来返回当前文件指针相对于文件开头的位置,返回值为long型整数,并不具备重定位文件指针的功能。
B. fseek()函数虽然可以实现文件指针的重定位,但它的功能更加通用,可以将文件指针定位到任意位置。相比之下,rewind()专门用于重置到文件开头,使用更简单直接。
D. ferror()函数用于检测文件操作是否发生错误,返回值为0表示未发生错误,非0表示发生错误。它是错误检测函数,与文件指针定位无关。
补充说明:rewind()函数不仅将文件位置指示器设置到文件起始处,同时还会清除文件的错误标志。这个函数使用方便,是重置文件指针最简单有效的方法。
知识点:C++、C语言
题友讨论(15)
单选题
C++
C语言
若要用fopen函数打开一个新的二进制文件,该文件既能读也能写,则文件方字符串应是()
A
"ab++"
B
"wb+"
C
"rb+"
D
"ab"
正确答案:B
官方解析:
fopen函数打开文件的方式字符串"wb+"是正确选项,因为它表示以二进制方式打开文件,可读可写,如果文件不存在则创建新文件。其中'w'表示写入模式,'b'表示二进制模式,'+'表示可读可写。
分析其他选项:
A错误:"ab++"不是合法的文件打开方式,fopen函数不支持"++"这种写法。正确的追加模式写法应为"ab+"。
C错误:"rb+"表示以读取模式打开二进制文件并允许写入,但如果文件不存在则会打开失败。题目要求打开新文件,所以不适合用读取模式。
D错误:"ab"表示以追加方式打开二进制文件,只能写入不能读取,不符合题目"既能读也能写"的要求。
补充说明:
"w"模式会清空已存在文件的内容
"r"模式要求文件必须存在
"a"模式将数据追加到文件末尾
"b"表示二进制模式(在Windows系统中区分文本和二进制模式)
"+"表示同时支持读写操作
知识点:C++、C语言
题友讨论(13)
单选题
C++
C语言
有如下一段代码:
|-----------|------------------------------------------------------------------------------|
| 1 2 3 4 5 |intnCount = 0;while(x) {``nCount++;``x = x & (x - 1);}|假设x初始为9999,则执行完nCount值为()
A
32
B
999
C
8
D
1
正确答案:C
官方解析:
这段代码的核心是在计算一个整数的二进制表示中1的个数。算法使用了一个位运算的技巧:x & (x-1) 可以消除二进制表示中最右边的1。
让我们分析9999的二进制表示:
9999 = 0010 0111 0000 1111(二进制)
每执行一次 x = x & (x-1),就会消除一个1:
0010 0111 0000 1111
0010 0111 0000 1110
0010 0111 0000 1100
0010 0111 0000 1000
0010 0111 0000 0000
0010 0110 0000 0000
0010 0100 0000 0000
0010 0000 0000 0000
总共循环8次后x变为0,因此nCount的值为8。所以C选项是正确答案。
分析其他选项:
A(32)错误:32是整型数据的位数,与本题无关。
B(999)错误:这个数值过大,明显超出了二进制中1的可能个数。
D(1)错误:9999的二进制表示中显然不止一个1。
这种计算二进制中1的个数的算法是一种非常高效的方法,每次操作都能消除一个1,循环次数就等于二进制中1的个数。
知识点:C++、C语言
题友讨论(16)
单选题
C++
C语言
下列代码输出为()
|-------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |classTest {``inta;public``:``Test() : a(0) {cout << ``"void"``;}``explicitTest(``inti) : a(i) {cout << ``"int"``;}``Test(``shorts) : a(s) {cout << ``"short"``;}``Test &operator=(``intn) {a = n; cout << ``"operator="``;}};intmain() {``intn;``Test a = n;}|A
int
B
short
C
void
D
void operator=
正确答案:B
官方解析:
这道题目考察了C++中的类型转换和构造函数的调用规则。
在代码中,关键是理解 Test a = n 这条语句的执行过程。当用一个int类型变量n初始化Test对象a时,编译器会寻找合适的构造函数进行转换。
虽然类中定义了explicit Test(int i)构造函数,但由于explicit关键字的存在,这个构造函数不能用于隐式转换。因此编译器会继续寻找其他可用的转换途径。
这时Test(short s)构造函数可以使用,因为:
它没有explicit修饰
int类型可以隐式转换为short类型
这个转换是安全的(虽然可能会有精度损失)
所以编译器会选择使用Test(short s)构造函数,输出"short"。
分析其他选项:
A选项"int"错误:因为int构造函数被explicit修饰,不能用于隐式转换。
C选项"void"错误:默认构造函数只在没有提供初始值时才会调用。
D选项"void operator="错误:这里是初始化而不是赋值操作,不会调用赋值运算符。
这个例子很好地展示了C++中explicit关键字的作用,以及编译器如何选择合适的转换路径。
知识点:C++、C语言
题友讨论(49)
单选题
C++
如下代码的输出结果是()
|-------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |#include <iostream>usingnamespacestd;intfunction2(``inta[], ``intb, ``inte){``if``(e - b <= 1) ``returnabs``(a[b] - a[e]) >= 3 ? a[b]:a[e];``intl = 0, r = 0;``l = function2(a, b, b + (e - b) / 2);``if(l % 2 == 0)``r = function2(a, b + (e - b) / 2 + 1, e);``else``returnl;``if(l | r)``returnl | r;``else``returnr;}intmain(){``inta[] = { 10, 5, 8, 4, 5, 20, 2, 3 };``cout << function2(a, 0, ``sizeof``(a) / ``sizeof``(1)) << endl;``intb[] = { 3, 5, 8, 4, 8, 30, 2, 3 };``cout << function2(b, 0, ``sizeof``(b) / ``sizeof``(1)) << endl;``return0;}|A
15,5
B
10,5
C
20,3
D
其它
正确答案:A
官方解析:
这道题目主要考察了递归函数的运行过程和位运算。让我们逐步分析函数的执行过程。
function2是一个递归函数,其功能可以分解为:
基本情况:当区间长度小于等于1时,比较两个数的差值的绝对值是否大于等于3,返回较小下标的数或较大下标的数。
递归情况:
将数组分成两半,先计算左半部分(l)
如果左半部分结果是偶数,继续计算右半部分(r);如果是奇数,直接返回左半部分结果
最后用位运算符"|"来合并结果
对于第一个数组{10,5,8,4,5,20,2,3}:
- 最终会得到15(二进制1111)
对于第二个数组{3,5,8,4,8,30,2,3}:
- 最终会得到5
因此输出结果是15,5,对应选项A。
分析其他选项:
B(10,5)错误:第一个数组的计算结果不是10
C(20,3)错误:两个数组的计算结果都不对
D(其它)错误:计算结果就是15,5
这道题目的难点在于理解递归过程和位运算的组合,特别是"|"运算符在合并结果时的作用。每个递归层级的结果会通过位运算逐步传递到最终结果。
知识点:C++
题友讨论(63)
多选题
C++
对于纯虚函数描述正确的是( )
A
含有纯虚函数的类不能被声明对像,这些类被称为抽象类
B
继承抽象类的派生类可以被声明对像,但要在派生类中完全实现基类中所有的纯虚函数
C
继承抽象类的派生类可以被声明对像,不需要实现基类中全部纯虚函数,只需要实现在派生类中用到的纯虚函数
D
虚函数和纯虚函数是一样的,没什么区别
正确答案:AB
官方解析:
纯虚函数是C++中实现多态的重要机制。A、B选项正确地描述了纯虚函数和抽象类的关系及特性。
具体分析:
A正确:含有纯虚函数的类确实不能创建对象实例,这类只能作为接口使用。这样的类被称为抽象类,因为它包含至少一个纯虚函数,表明这个类是不完整的,需要在派生类中实现具体功能。
B正确:如果想要使用继承自抽象类的派生类,必须实现所有基类中声明的纯虚函数。只有完全实现了所有纯虚函数,派生类才能创建对象。这确保了派生类提供了基类接口要求的所有功能。
C错误:派生类必须实现基类中所有的纯虚函数,而不是仅实现会用到的部分。这是因为纯虚函数代表了基类接口的完整契约,派生类必须完全满足这个契约。
D错误:虚函数和纯虚函数有本质区别:
虚函数在基类中可以有实现,而纯虚函数在基类中没有实现
包含纯虚函数的类是抽象类,不能创建对象;而只包含虚函数的类可以创建对象
虚函数提供了默认实现,派生类可以选择是否重写;纯虚函数必须在派生类中实现
知识点:2015、C++、Java工程师、C++工程师、iOS工程师、安卓工程师、运维工程师、前端工程师、c#工程师、golang工程师
题友讨论(9)
多选题
C++
在重载某运算符时,若运算符函数的形参表中没有参数,则可能的情况有
A
该运算符是一个单目运算符。
B
该运算符函数有一个隐含的参数this。
C
该运算符函数是类的成员函数。
D
该运算符函数是类的友元函数。
正确答案:ABC
官方解析:
这道题目考察了运算符重载中运算符函数形参表为空的情况。ABC是正确答案,因为它们构成了一个完整的逻辑关系。
当运算符函数的形参表中没有参数时:
一定是单目运算符(A正确)。因为单目运算符只对一个操作数进行操作,而双目运算符需要两个操作数,必须有参数。
函数中有一个隐含的this指针(B正确)。作为类的成员函数,即使形参表为空,也会默认传入this指针,指向调用该运算符的对象。
必须是类的成员函数(C正确)。因为需要访问对象的成员,且运算符重载函数要作用于对象本身。
D选项错误,因为友元函数不是类的成员函数,没有隐含的this指针,在重载单目运算符时必须显式地至少包含一个参数来表示操作数。
举例说明:最典型的例子就是前置++运算符的重载:
Type operator++() // 前置++
{
// 通过this指针访问并修改对象
// 返回修改后的对象
}
因此,当运算符函数形参表为空时,这个函数一定是类的成员函数形式的单目运算符重载,并且可以通过this指针访问对象。
知识点:C++
题友讨论(10)
多选题
C++
C语言
已知一函数中有下列变量定义,其中属于自动变量的有()。
A
double k;
B
register int i;
C
static char c;
D
auto long m;
正确答案:AD
你的答案:ABD
官方解析:
这道题目考察C语言中变量的存储类型。AD是正确答案,原因如下:
A选项double k正确,因为在函数中定义的变量,如果没有显式声明存储类型,默认就是auto(自动变量)。自动变量的特点是在函数调用时分配内存,函数结束时释放内存。
D选项auto long m正确,因为使用auto关键字显式声明的变量就是自动变量。虽然auto关键字可以省略,但显式声明也是合法的。
分析错误选项:
B选项register int i错误,register是寄存器变量,它建议编译器使用CPU寄存器来存储该变量以提高访问速度。虽然实际上编译器可能不会这样处理,但从定义上来说它不是自动变量。
C选项static char c错误,static声明的是静态变量,其特点是在程序运行期间一直存在,并且其作用域仅限于声明它的函数内。静态变量的存储位置在静态存储区,而不是栈上,因此不是自动变量。
总的来说,自动变量是最普遍的变量类型,它们在栈上分配内存,具有自动的生命周期管理特性。要么默认声明,要么使用auto关键字显式声明。
知识点:C++、C语言
题友讨论(27)
多选题
C++
下面关于 C++ 中智能指针的说法正确的是()
A
智能指针提供了自动化的内存管理,可以帮助避免内存泄漏和悬空指针问题
B
std::shared_ptr 是一种共享指针,允许多个智能指针共享同一块内存资源
C
std::unique_ptr 是一种独占指针,对内存资源的唯一拥有权,且不允许所有权在 std::unique_ptr 之间进行转移
D
智能指针会自动进行空指针检查,不需要额外的空指针验证
正确答案:AB
官方解析:
这道题目考察了C++智能指针的基本概念和特性。A、B选项是正确的。
A选项正确:智能指针是C++中的一种自动内存管理机制,它能够在适当的时候自动释放所管理的内存,有效防止内存泄漏。同时也避免了手动删除指针后其他地方还在使用该指针而导致的悬空指针问题。
B选项正确:std::shared_ptr允许多个智能指针共同拥有同一个对象。它通过引用计数机制来追踪共享对象被引用的次数,当最后一个shared_ptr析构时,才会删除所管理的对象。
C选项错误:虽然std::unique_ptr确实是独占式智能指针,但是它允许通过std::move()在不同的unique_ptr之间转移所有权。题目中说"不允许所有权转移"是错误的。
D选项错误:智能指针并不会自动进行空指针检查。在使用智能指针时,仍然需要程序员手动检查指针是否为空以避免空指针解引用导致的程序崩溃。智能指针主要解决的是内存管理问题,而不是空指针检查问题。
知识点:C++
题友讨论(2)
多选题
C++
以下对于方法覆盖的说法正确的有()
A
方法覆盖发生在同一类中
B
方法的覆盖发生在子类型中
C
方法名一定要一样
D
参数类型一定要一样
E
返回类型一定要一样
F
访问权限只能一样
正确答案:BCD
你的答案:BCDE
官方解析:
在Java中方法覆盖(Override)是一个重要的面向对象特性,它允许子类重新定义从父类继承的方法。让我们详细分析各个选项:
B正确:方法覆盖必须发生在子类中,这是方法覆盖的基本要求。子类重写父类的方法来实现多态性。
C正确:方法覆盖要求子类方法与父类方法具有相同的方法名,这是识别覆盖的关键条件之一。
D正确:参数列表(包括参数类型和顺序)必须完全相同,这是区分方法覆盖和方法重载的重要特征。
分析错误选项:
A错误:方法覆盖不可能发生在同一个类中,必须是在继承关系中的子类中进行。
E错误:返回类型可以是父类方法返回类型的子类型(协变返回类型),不一定要完全相同。
F错误:子类方法的访问权限可以比父类方法更宽松,但不能更严格。例如父类方法是protected,子类可以是public,但不能是private。
总的来说,方法覆盖是面向对象编程中实现多态的重要机制,必须严格遵守方法名相同、参数列表相同的基本原则,同时在返回类型和访问权限上有一定的灵活性。
知识点:C++、Java工程师、C++工程师、iOS工程师、安卓工程师、运维工程师、前端工程师、算法工程师、PHP工程师、2018