MySQL配置参数优化总结
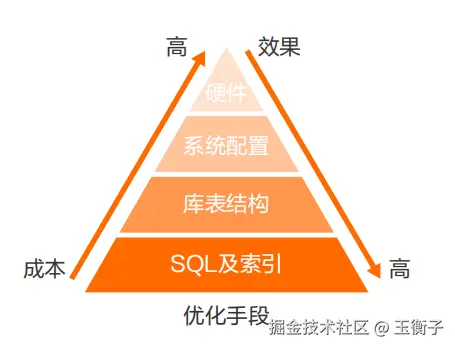
从上图可以看出SQL及索引的优化效果是最好的,而且成本最低,所以工作中我们要在这块花更多时间。关于索引优化可以看我的# 索引选择实践与Explain详解和索引优化实战。本章主要向你介绍参数配置设置。
补充一点配置文件my.ini或my.cnf的全局参数:
假设服务器配置为:
- CPU:32核
- 内存:64G
- DISK:2T SSD 下面参数都是服务端参数,默认在配置文件的 mysqld 标签下
mysql server系统参数
max_connections=3000
连接的创建和销毁都需要系统资源,比如内存、文件句柄,业务说的支持多少并发,指的是每秒请求数,也就是QPS。 一个连接最少占用内存是256K,最大是64M,如果一个连接的请求数据超过64MB(比如排序),就会申请临时空间,放到硬盘上。
如果3000个用户同时连上mysql,最小需要内存3000*256KB=750M,最大需要内存3000*64MB=192G。
如果innodb_buffer_pool_size是40GB,给操作系统分配4G,给连接使用的最大内存不到20G,如果连接过多,使用的内存超过20G,将会产生磁盘SWAP,此时将会影响性能。连接数过高,不一定带来吞吐量的提高,而且可能占用更多的系统资源。
max_user_connections=2980
允许用户连接的最大数量,剩余连接数用作DBA管理。
back_log=300
MySQL能够暂存的连接数量。如果MySQL的连接数达到max_connections时,新的请求将会被存在堆栈中,等待某一连接释放资源,该堆栈数量即back_log,如果等待连接的数量超过back_log,将被拒绝。
wait_timeout=300
指的是app应用通过jdbc连接mysql进行操作完毕后,空闲300秒后断开,默认是28800,单位秒,即8个小时。
interactive_timeout=300
指的是mysql client连接mysql进行操作完毕后,空闲300秒后断开,默认是28800,单位秒,即8个小时。
sort_buffer_size=4M
每个需要排序的线程分配该大小的一个缓冲区。增加该值可以加速ORDER BY 或 GROUP BY操作。
sort_buffer_size是一个connection级的参数,在每个connection(session)第一次需要使用这个buffer的时候,一次性分配设置的内存。
sort_buffer_size:并不是越大越好,由于是connection级的参数,过大的设置+高并发 可能会耗尽系统的内存资源。例如:500个连接将会消耗500*sort_buffer_size(4M)=2G。
join_buffer_size=4M
用于表关联缓存的大小,和sort_buffer_size一样,该参数对应的分配内存也是每个连接独享。
innodb参数
innodb_thread_concurrency=64
此参数用来设置innodb线程的并发数,默认值为0表示不被限制,若要设置则与服务器的CPU核心数相同或是CPU的核心数的2倍,如果超过配置并发数,则需要排队,这个值不宜太大,不然可能会导致线程之间锁争用严重,影响性能。
innodb_buffer_pool_size=40G
innodb存储引擎buffer pool缓存大小,一般为物理内存的60%-70%。
内存大小直接反应数据库的性能。
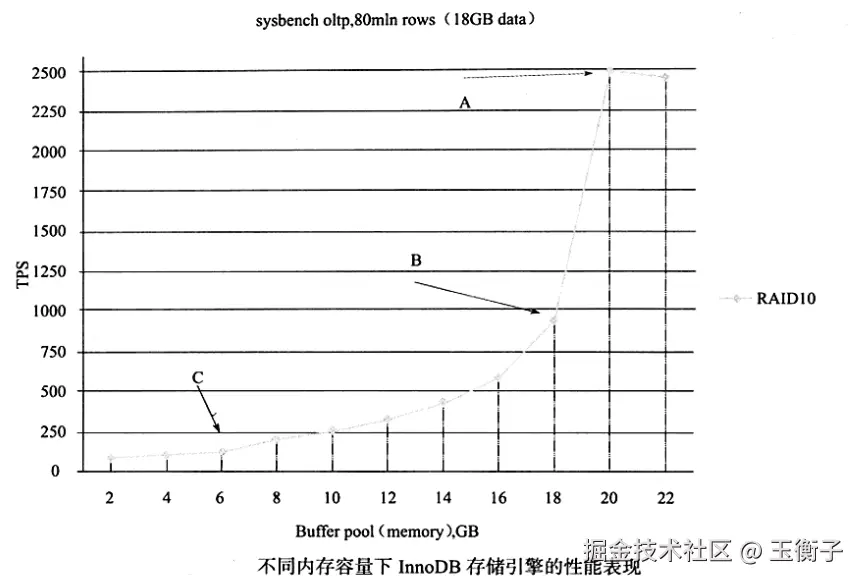
如何判断性能达到了瓶颈呢?
可以通过查看当前服务器的状态,比较物理磁盘的读取和内存读取的比例来判断缓冲池的命中率,通 常InnoDB存储引擎的缓冲池的命中率不应该小于99%,如:show global status like 'innodb%read%'\G;
当前服务器的状态参数:
Innodb_buffer_pool_reads:表示从物理磁盘读取页的次数 Innodb_buffer_pool_read_ahead:预读的次数 Innodb_buffer_pool_read_ahead_evicted:预读的页,但是没有被读取就从缓冲池中被替换的页的数量,一般用 来判断预读的效率 Innodb_buffer_pool_read_requests:从缓冲池中读取页的次数 Innodb_data_readsInnodb_rows_read:总共读入的字节数 Innodb_data_reads:发起读取请求的次数,每次读取可能需要读取多个页
以下公式可以计算各种对缓冲池的操作:

innodb_lock_wait_timeout=10
行锁锁定时间,默认50s,根据公司业务定,没有标准值。
innodb_flush_log_at_trx_commit=1
这个参数控制 redo log 的写入策略,它有三种可能取值:
-
设置为0:表示每次事务提交时都只是把 redo log 留在 redo log buffer 中,数据库宕机可能会丢失数据。
-
设置为1(默认值):表示每次事务提交时都将 redo log 直接持久化到磁盘,数据最安全,不会因为数据库宕机丢失数据,但是效率稍微差一点,线上系统推荐这个设置。
-
设置为2:表示每次事务提交时都只是把 redo log 写到操作系统的缓存page cache里,这种情况如果数据库宕机是不会丢失数据的,但是操作系统如果宕机了,page cache里的数据还没来得及写入磁盘文件的话就会丢失数据
binlog参数
sync_binlog=1 binlog写入磁盘机制主要通过 sync_binlog 参数控制,默认值是 0.
-
为0的时候,表示每次提交事务都只write到page cache,由系统自行判断什么时候执行fsync写入磁盘。虽然性能得到提升,但是机器宕机,page cache里面的binlog会丢失
-
也可以设置为1,表示每次提交事务都会执行fsync写入磁盘,这种方式最安全
-
还有一种折中方式,可以设置为N(N>1),表示每次提交事务都write 到page cache,但累积N个事务后才fsync写入磁盘,这种如果机器宕机会丢失N个事务的binlog