上次了解了__getattribute__和__getattr__,了解它的过程中,因为__getattributr__的内置函数的逻辑是: 当访问 obj.attr 时,Python 底层的 object.__getattribute__ 会这样查找:
- 先查实例字典
obj.__dict__(对象自己的属性) - 如果没找到,按 MRO 顺序 依次查每个类的
__dict__ - 如果还是没找到,调用
__getattr__(如果类里定义了) - 最后找不到就抛
AttributeError
于是接触到了两个概念,一个是__dict__,第二个是MRO,所以今天又来继续总结这两个概念。在总结这两个概念前,我需要先总结一下python中的一些关键分类。
内置函数、特殊属性、魔术方法
在Python中内置了很多东西,其中和__getattr_、getattr、__module__、 _dict__等等这些有关的分类,我暂时把他们归类为内置函数、类中内置方法、类中特殊属性。python当然还有其他的很多内置的东西,这里先暂时不讨论。
- 内置函数,比如
getattr就是内置函数,是python已经写好的,只要运行了python就可以随意使用,导出都可以用,不需要在文件中导入什么东西。python共有71个内置函数,可以看这里python中71个内置函数。 - 类中内置方法,类中内置方法就是
object中已经默认定义好的一些方法。除了object类中的一些默认方法以外,一些内置的类,比如list、dict、str也内置了很多的方法。 - 类中特殊属性:像
__module__、__dict__就是一些在类中的特殊属性,这两个属性是在python的type类构建每个类时默认给加上的属性,是属于类的元数据,也就是说每个类都有这些属性。
上面并没有说到像__len__、__getattr__这样的魔术方法。这里只单独举例说一下魔术方法和内置函数的关系。比如__len__是一个魔术方法,这个魔术方法在object中没有定义,而是在object的子类中,比如list中由python默认去定义了。其实可以说这个魔术方法的内容是人为进行定义的,只是方法名称是固定的。如果一个类中定义了__len__方法,那么就以通过内置的函数len()去调用类中的这个__len__方法。这也是内置函数和一些魔术方法相联系的地方,通过这样一些python中的默认的协议来进行关联调用。
__dict__
__dict__是一个特殊属性,它是一个存在普遍存在于类、对象实例中的一个特殊属性,是type类在构建类的时候给加上去的。
说到这里,就不得不先理解一下type构建类的过程。我最初使用type是用来查看对象的类型,比如type(5),得到的是<class int>,而如果type(int),就会得到<class 'type'>,所以我先来了解一下type。
type是python中的元类,是所有类的创建者,注意不是继承,而是创建。所有类都是继承自object,而所有类都是被type创建的。我们在使用关键字class定义类的时候,实际上就是type在工作。
python
class A:
stark = '123'
def get_stark(self):
return 'stark'当我们像上面这样定义一个类的时候,实际上python就在用type做下面四个步骤:
- 确定元类、类名和它的基类。实际上
class A:等同于class A(classmeta=type):所以这一步就是在确认,正在定义的这个类,它的classmeta是什么。类名就是A,基类就是object,元类就是type。 - 为存储类的属性准备一块存储区域,也叫做准备类的命名空间。这个存储一般用字典(dict)来存储。
- 执行类的主体代码,就是把
class A:中的主体代码用python解释器读一遍,把独到的属性、方法都写到第2步准备的存储空间里面去,给这些键值对放到一个叫做attrs的字典中。注意 ,__module__、__dict__这类type构建类的时候写入的类的元数据,就是在这一步写入的。 - 创建类,就是调用type里面的一个方法
__new__把第一步中的确认的类名、基类和第三步中读完类主体代码后得到的一个attrs的字字典一起传给__new__,就完成了类的创建的了。
所以上面的class A:的定义约等于python干了下面这个
python
A = type(
'A', # 类名
(object,), # 基类 bases
{
'__module':'__main__',
'__dict__':<attribute '__dict__' of 'A' objects>,
'stark':123,
'get_stark':<function A.speak>, # attrs,存储类中全部的成员键值对
'__doc__': None
}
)所以在类中的__dict__实际上就是第3步执行完类的主体代码后得到的attrs,两个的核心几乎是一样的。只不过attrs得到的是一个临时的,而__dict__得到的是这个临时的attrs传给type后最后构建出来实际的,经过type构建后的__dict__会比attrs多一些内容,多的这些就是type构建给加上的,比如说__dict__。
而在对象中的__dict__实际上就只是对象实例中具体成员了,不再有__module__、__dict__这类元数据了。比如下面这个:
python
class B:
def __init__(self, name, age):
self.name = name
self.age =age
def __len__(self):
return '42'
b = B('Bob', 10)
print(B.__dict__)
# --> {
# --> '__module__': '__main__',
# --> '__init__': <function B.__init__ at 0x0000019ACE004A40>,
# --> '__len__': <function B.__len__ at 0x0000019ACE004B80>,
# --> '__dict__': <attribute '__dict__' of 'B' objects>,
# --> '__weakref__': <attribute '__weakref__' of 'B' objects>,
# --> '__doc__': None
# --> }
print(b.__dict__)
# --> {'name': 'Bob', 'age': 10}__class__
上面提到的是type构建类的用法,但我们最常用的是type(5)这种用法。
实际上这个type(5)只是在调用类的__class__属性,这个__class__属性存储的就是对象的类型,它是对象一个特殊属性。
而这个__class__就是type构建的类的基本结构中的特殊属性,属于类的基本结构,它这个属性想要表达的是这个对象是由哪个类创建的。所以才有
python
class A:
pass
a = A()
print(type(a))
# --> <class '__main__.A'>
print(type(A))
# --> <class 'type'>MRO
MRO(method Resolution Order)方法解析顺序,用来指明python中类在继承的过程中,如何找到某个对象的方法是继承自哪一个类。实际上,它也是对象的一个特殊属性__mro__,而这个__mro__和__class__一样也是在type构建类时就创建好的特殊属性。
在类的继承过程中,__mro__中的值是通过一个叫做C3线性化的算法算出来的元组,当在对象中去调用super().XX方法的时候,就是去__mro__中去找到下一个对象。
和这个文章开头提到的对象的属性查找过程的MRO顺序,实际上就是用到了__mro__:
- 先查实例的
__dict__是否有这个属性 - 如果没找到,就按照
__mro__中的顺序依次去查询每个类的__dict__ - 如果一直没找到,就去调用
__getattr__,如果类中定义了这个__getattr__的话 - 如果都没有,就抛出
AttributeError
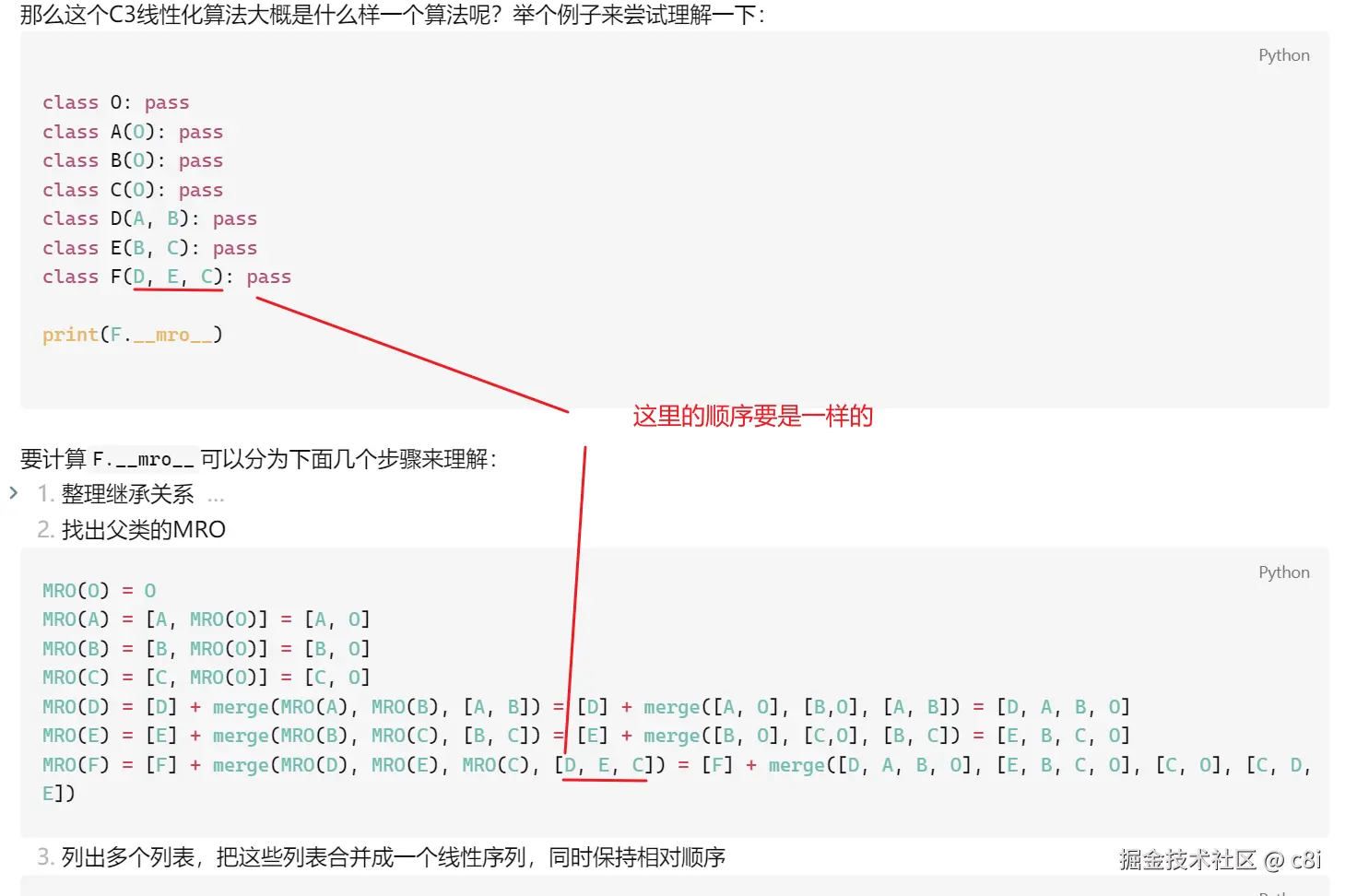
那么这个C3线性化算法大概是什么样一个算法呢?举个例子来尝试理解一下:
python
class O: pass
class A(O): pass
class B(O): pass
class C(O): pass
class D(A, B): pass
class E(B, C): pass
class F(D, E, C): pass
print(F.__mro__)要计算F.__mro__可以分为下面几个步骤来理解:
- 整理继承关系
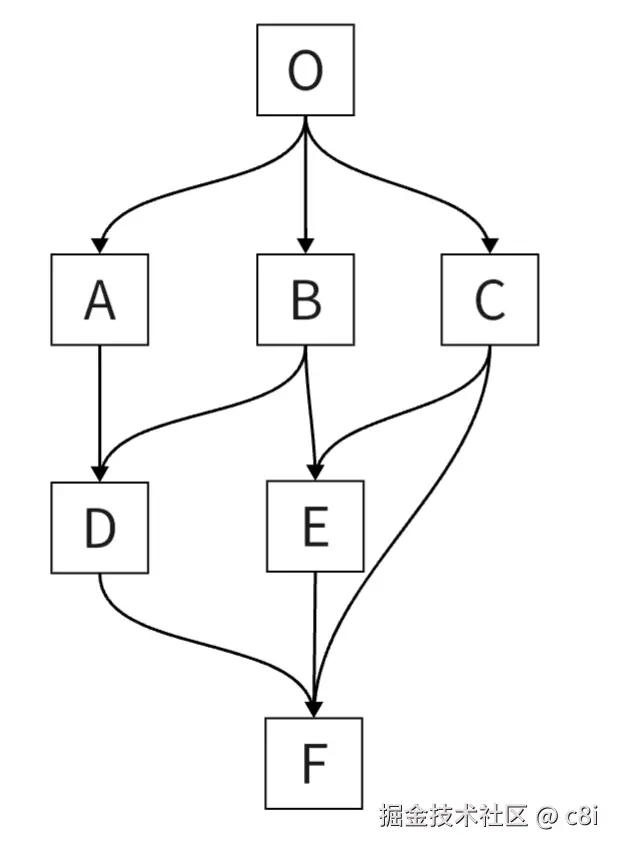
- 找出父类的MRO
python
MRO(O) = O
MRO(A) = [A, MRO(O)] = [A, O]
MRO(B) = [B, MRO(O)] = [B, O]
MRO(C) = [C, MRO(O)] = [C, O]
MRO(D) = [D] + merge(MRO(A), MRO(B), [A, B]) = [D] + merge([A, O], [B,O], [A, B]) = [D, A, B, O]
MRO(E) = [E] + merge(MRO(B), MRO(C), [B, C]) = [E] + merge([B, O], [C,O], [B, C]) = [E, B, C, O]
MRO(F) = [F] + merge(MRO(D), MRO(E), MRO(C), [D, E, C]) = [F] + merge([D, A, B, O], [E, B, C, O], [C, O], [C, D, E]) - 列出多个列表,把这些列表合并成一个线性序列,同时保持相对顺序
python
MRO(F) = [
[F]
[D, A, B, O]
[E, B, C, O]
[C, O]
[D, E, C]
]-
合并操作,合并操作就是从第一个列表的第一个元素开始看。、
- 首先看F元素,F没有在剩下的任何一个列表的非队首,那么就把F放到MRO(F)元组的第一个中去,去掉所有列表中的F
- 第一个列表已经没有,就看第二个列表的第一个元素D,D也不在剩下的任何一个列表中非队首,所有就放到MRO(F)中第二个去,去掉所有列表中的D
- 再看第二个列表的第二个元素A,同样不在剩下的任何一个列表的非队首 ,放到MRO(F)中第三个去,去掉所有列表中的A
- 再看第二个列表中第三个元素B,B在第第三个列表中排在第2位,所以不选B
- 再看第三个列表中的第一个E,E已经不在任何一个列表的非队首了,所有第四个元素选E,去除所有列表中的E
- 再看第二个列表中的B,B也不已经不再任何一个列表的非队首了,所以第五个元素选D
- 再看第三个列表中的C,C也已经不再任何一个列表的非队首了,所以第六个元素选C
- 现在只剩O了,所有第六个元素选O
- MRO(F)就是(F, D, A, E, B, C, O)
-
所有
F.__mro__打印出来就是
python
(
<class '__main__.F'>,
<class '__main__.D'>,
<class '__main__.A'>,
<class '__main__.E'>,
<class '__main__.B'>,
<class '__main__.C'>,
<class '__main__.O'>,
<class 'object'>
)注意:在定义类的时候,如果继承了多个类,那么在定义的时候父类的写的顺序,就是计算MRO的要写的顺序。
python中类的数据结构
实际上上面我们所说的都是python中的类的基本的数据结构,也就是说任何一个类在电脑中存储,都是按照下面的结构来存储的。
python
ClassObject (type instance)
├─ __dict__ → 用户定义的属性/方法
├─ __mro__ → 方法解析顺序
├─ __bases__ → 父类元组
├─ __class__ → type
├─ __weakref__ → 支持弱引用
└─ __module__, __doc__, __qualname__ → 其它元信息上面我们也只是看了__dict__、__mro__、__class__三个类的基本机构中的特殊属性。
最后再提一下__base__、__bases__这两个特殊属性,__bases__是取对象的全部直接基类 ,形成一个元组,而__base__是对象的第一个父类,类似于是__bases__[0],
python
class O: pass
class A(O): pass
class D(A, O): pass
print(O.__base__)
# --> <class 'object'>
print(A.__base__)
# --> <class '__main__.O'>
print(D.__base__)
print(D.__bases__)
# --> <class '__main__.A'>
# --> (<class '__main__.A'>, <class '__main__.O'>)