在寻找比
Celery更轻量的队列方案时,我尝试了ARQ。它依赖简单、部署容易,并且在I/O密集任务下,单机就能跑到万级吞吐,这让我重新思考了"低成本队列"的可能性。
以我为例,我是做人工智能应用开发的。训练完一个模型后,要发布上线提供给广大人民群众来用。
从自己用,到大家用,这中间是有差别的。
首先说,训练个合适的模型很难,但是调用却很简单。比如我训练了一个OCR模型,调用时操作如下。
python
imgs = np.array(imgs)
# 图片转为numpy数组,交给模型推理
predicts = model.predict(imgs)
for predict in predicts:
# 模型得出结果
# ...不同的模型,处理一项的任务时长不一样。尤其是大模型,短则几秒,长则几分钟。
你将一项AI功能开放出来供网友使用,就如同你开了一家餐馆接待食客。有顾客进门点菜,你就要做菜。这时候人流量就是个问题。这在软件服务端称为"并发"。
你的硬件配置,也就是你买的服务器电脑,决定了你的服务端的处理能力。这就如同你的厨房多大,店里多少锅,多少个厨师傅。
和做饭不同,软件需求很少能提供"预制菜"。不像你去店里,同时来了100个人都点一道菜,你有10个微波炉,每个微波炉放入1个料理包,3分钟加热好,只要30分钟就可完成这100道菜。
软件服务则不然,虽然都是同一个功能,比如OCR识别文字。那也很难来100次请求全是同样的图片。如果都是同一张图,之前已经识别过就把结果存下来,后面99次不用识别了,直接返回上一次的结果就行。这在软件处理中叫"命中缓存"。事实上,即便是同样的输入,顾客也不喜欢缓存,他们更喜欢比上一次更精确的结论。有时你反复问大模型同一个问题,也希望得到更多可能性的回答。
好了,到这里,作者仅仅想说你的服务公开到网上,可能会面临一种情况:瞬间来了1000个请求,你的服务能力有限,每处理一个请求得3分钟,最后一个人得等3000分钟,中间没有回应。这可怎么办?
网络服务不同于线下的餐馆。在线下,你看到小餐馆里面没坐了,可以选择排队,也可以选择离开。最起码餐馆不会因为人太多而被撑破,导致钢筋混凝土散落一地。
网络服务不一样。你看不到有多少人同时访问。你也不关心这个。咱就是有需要的时候打APP或者小程序。因此,当春运、双十一购物时,会从新闻看到某某平台宕机了。其实就是人来的太多,10万人同时往一个最大可容纳1千人的门里挤,结果谁也进不去,房塌了。
好了,到这里,作者又想说,你的程序对此类情况得干预。人太多的时候,你得告诉顾客要排队等候,并且顾客一来你就得立马告诉人家"您的等位号码是1001,40分钟后处理您的请求,您可以随时查询等待状态,到时间我们也会叫号"。如果来的人实在太多了,比如要等上三天,这时候再来顾客,就别让人家等了,因为顾客受不了,你也受不了。直接友好地拒绝服务"当前任务过多,暂停服务,请稍后访问"。
那么上面的这些事情,谁来做呢?肯定不是厨子来做,需要前台服务员来做。前台服务员负责接待来访的顾客,讲究一个快速回话,得有八面玲珑的能力,给A顾客下单的同时也能给B顾客取等位码。不能干一件事的时候阻塞流程,无法处理其他任何请求。
我们的开发语言选择Python,应对请求选择FastAPI框架。
这个服务员需要能发出以下操作:

具体解释一下:
- 创建任务:有人点菜了,就创建一个任务,任务里包含了顾客要吃什么(绝对不是他去做菜)。
- 查询任务状态:可以查询顾客的任务状态,排队中、处理中、已完成、发生问题(没菜了)。
- 停止单个任务:如果顾客改变了主意,不要了,得取消(不然厨师依然会做)。
- 停止未完成的任务:紧急情况,厨房要断水断电10分钟(对应服务器维护或重启)。
- 任务重试:厨房水电恢复了,之前没做完的接着做(不能再去问原来顾客要吃什么)。
- 队列统计:当前有多少任务在制作中,多少还在等着(便于监控并决定是否继续接单)。
这是前端接口,接收客户的请求并及时做出响应。哪怕回应处理不了,也是响应,就怕沉默,那是阻塞。
我们再看另一头,那就是实际处理任务的"厨子"。厨子只管低头做任务,别的不管。
我们来模拟一项任务,比如OCR识别图片中的文字,并用50字总结大意。
python
def perform_correction(task_id: str, image_path: str) -> dict:
logger.info(f"开始任务: {task_id}")
# 协作式取消:在耗时操作的间隙检查任务状态
check_cancel(task_id)
time.sleep(random.randint(10, 30))
check_cancel(task_id)
logger.info(f"{task_id} step1 完成")
time.sleep(random.randint(30, 60))
check_cancel(task_id)
logger.info(f"{task_id} step2 完成")
if random.randint(0, 10) > 5:
raise Exception(f"随机异常:模拟发生故障")
logger.info(f"{task_id} 处理完成!")
return {"summary": "本页内容主要讲述了OCR的发展历史,以及OCR的未来发展方向。"}这里面可能会调用图像识别模型、NLP模型,整个过程可能好几步。我们假定分2步,第一步大约10到30秒,第二步大约30到60秒。每一步的前后,都要做一个检测,看一下任务是否被取消了。如果取消了,厨师傅要收尾刷锅。这叫"协作式取消"(对应地还有"强制中断",杀进程,直接把锅扔了)。最后,我们还模拟了成功和失败。在实践中也是,并非每个任务都能完美成功,各种各样的问题会导致异常。
厨子就是个机器,任务很单一,它只管按照命令处理任务。你就算来一亿五千万个订单,他也是一道一道的做,因为人家的承载能力就是这样。
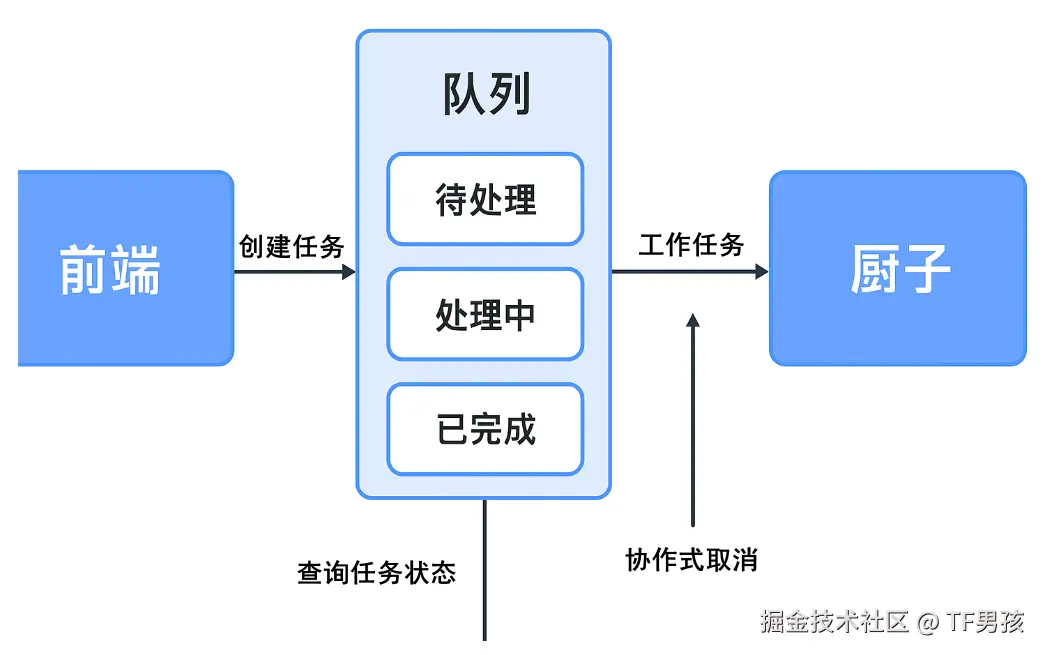
好了,到这里,前面有服务员接待顾客,后面有厨子处理任务。中间还缺一个环节,那就是"任务队列"。它可以是个角色,也可以是个流程,总归得安排好以下的几项任务。
第一,创建的订单如何给到厨子。厨子每次只接受一道菜,做完这个再做下一个。他不管理一摞一摞的订单,只接收下一个要做什么。因为可能有10个服务员,6个厨子,谁先做哪个后做哪个?如果倒立一个大头钉,来了菜单就串上,那么最先点菜的会最后吃上,明显不合理。因此需要一个合理的分发机制,比如先点的先做,再或者5分钟内汇总同一道菜一锅出。
第二,订单的管理和统计。如果有顾客要退掉一个菜,你得先看看这道菜做没做,已经做了就没法退了。如果顾客逃单了,做一半也得停。有的顾客对菜品不满意,这就需要重做。还有,店长会问现在积压的订单有多少,多少订单在制作中,多少还在排队。这些事情谁来协调?成千上万的订单,如何扒拉出来并打上对钩或叉叉。那位说了,服务员从订单系统中点一下就行。各位,我们现在就要做这么一个系统,系统还没出来呢!
因此,需要一个任务队列来处理这些事情。这个队列需要能支持以下功能:
- 任务入队:顾客点菜(创建任务)之后,把任务顺序记录下来,放进队列里等待厨师处理。入队动作必须快速,不阻塞前端服务,让顾客一提交就有响应"好嘞"。
- 任务出队与分发:厨子从队列取下一道菜(任务)开始处理。支持多厨子并行工作,每个厨子只拿自己能处理的任务类型。
- 任务状态管理:每个任务都需要记录状态:排队中、处理中、已完成、已取消、处理失败等。状态随时可查询,服务员前端接口可用来告诉顾客"您的订单排第几、预计多久完成"。
- 协作式取消支持:队列能标记任务为取消状态,厨子在执行任务的间隙检查标记,自愿停止任务。支持单任务取消,也可以批量取消(如服务器维护、紧急情况)。
- 持久化与可靠性:队列状态和任务信息可以持久化到数据库或消息存储,即便服务重启也不会丢失。对任务异常中断、宕机等情况可以自动恢复。
- 异步执行与非阻塞接口:队列与前端服务解耦,前端提交任务立即返回,后台异步处理,避免请求超时。
- 限流与过载保护:当队列任务过多时,可拒绝新任务或返回"稍后再试",防止厨房被压垮。
需要三方这样配合,才能从"一个人用"平滑过渡到"上万人同时用"。
到此处,我们的主角arq(异步任务队列)登场了。为什么选择arq?
先说结论:arq性价比高,简单轻量,高效稳定。
提到队列,在Python中多数人都知道Celery,它是一个分布式任务队列,支持异步任务处理。它的民间基础很牢固。但是,它的配置却很复杂,导致很多人搞不明白。关键是Celery出生的时候在2009年,Python是在2014年才有asyncio(异步 I/O 框架)的概念。而arq 是为asyncio 而生的,又与FastAPI 完美契合,代码风格统一。另外,arq 的配置和使用都非常简单,依赖只需要Redis。并且Redis 本身是一个非常轻量和快速的内存数据库,用作任务代理成本极低。效果还极好,单机Redis的可承受50~100万每秒的访问。加上3台节点,每秒吞吐量轻松过百万级。
下面我们就来实践MySQL+FastAPI+Redis+ARQ的技术方案:
- 数据库 (MySQL):用一张表来存储所有任务的状态、结果等信息。这是我们实现状态查询、任务管理的核心。
- API (FastAPI):接收请求。立即在 MySQL 数据库中创建一个任务记录,推送到
Redis任务队列中。立即返回一个task_id给客户端。 - 任务队列(Redis + ARQ Worker):一个独立的
Python进程持续监听Redis队列。一旦发现新任务,就从队列中取出并执行。在任务开始时,更新MySQL中对应任务的状态为processing(处理中)。任务执行完毕(无论成功或失败),将结果或错误信息写回MySQL,并更新状态为success或failed。
首先建表:
sql
CREATE TABLE `tasks` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键ID,自增',
`task_id` varchar(128) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '任务的唯一标识符,由程序生成 (例如UUID)',
`status` enum('pending','processing','success','failed','cancelled') COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT 'pending' COMMENT '任务当前的状态',
`image_path` varchar(255) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '上传的原始图片在服务器上的存储路径',
`result` text COLLATE utf8mb4_unicode_ci COMMENT '存储结果,可以是JSON字符串或其他文本格式',
`created_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '任务创建时间',
`updated_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '任务最后更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_task_id` (`task_id`) COMMENT '为 task_id 创建唯一索引,保证其不重复,并加快查询速度'
) ENGINE=InnoDB AUTO_INCREMENT=432 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='OCR任务表';我们得写一个对应数据库的模型类:
python
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Text
from sqlalchemy import Column, Integer, String, DateTime, Text, Enum
from sqlalchemy.ext.declarative import declarative_base
from zoneinfo import ZoneInfo
import datetime
import enum
def beijing_now():
"""返回北京时间 datetime"""
return datetime.datetime.now(tz=ZoneInfo("Asia/Shanghai"))
Base = declarative_base()
class TaskStatus(str, enum.Enum):
pending = "pending"
processing = "processing"
success = "success"
failed = "failed"
cancelled = "cancelled" # 用于支持取消任务
class CTask(Base):
__tablename__ = "tasks"
id = Column(Integer, primary_key=True, index=True)
# 这个 task_id 是我们返回给用户的唯一标识符
task_id = Column(String(128), unique=True, index=True, nullable=False)
status = Column(Enum(TaskStatus), default=TaskStatus.pending, nullable=False)
# 存储上传文件的路径
image_path = Column(String(255), nullable=False)
# 存储结果,可以是 JSON 字符串
result = Column(Text, nullable=True)
# 任务创建时间,默认北京时间
created_at = Column(DateTime(timezone=True), default=beijing_now, nullable=False)
# 任务更新时间,自动更新为当前北京时间
updated_at = Column(DateTime(timezone=True), default=beijing_now, onupdate=beijing_now, nullable=False)要走这一套,我们需要sqlalchemy组件的支持,可以通过pip install sqlalchemy安装。这样,我们调用CTask类的方法,就可以操作数据库了。
随后,我们需要安装arq,可以通过pip install arq安装。另外,我们还需要在电脑上安装redis服务。redis主要设计和使用在类Unix系统(Linux、macOS)中,官方本身不支持Windows系统(有非官方版本)。不过,即便是Windows系统,你也可以安装WSL(Windows 的 Linux 子系统)来使用。
接下来,我们就可以创建一个arq的worker了,新建一个worker.py文件。
python
import arq
async def job_process_01(ctx, task_id: str, image_path: str):
"""
这是 ARQ 调用的异步任务函数。
"""
db: Session = SessionLocal() # 数据库的一个会话,需要自己创建
try:
# 更新任务状态为 'processing'
task_db = db.query(CTask).filter(CTask.task_id == task_id).first()
if not task_db:
logger.error(f"错误:找不到任务 {task_id}")
return
# 检查是否已取消
if task_db.status == TaskStatus.cancelled:
db.close()
logger.info(f"任务 {task_id} 已取消,跳过执行")
return
task_db.status = TaskStatus.processing
db.commit()
logger.info(f"任务 {task_id} 开始处理...")
# 执行耗时操作 注意:perform_correction 是一个同步阻塞函数。 arq 会在线程池中运行它,不会阻塞事件循环。
loop = asyncio.get_running_loop()
correction_result = await loop.run_in_executor(None, perform_correction, task_id, image_path)
# 任务成功,更新数据库
task_db.status = TaskStatus.success
task_db.result = str(correction_result) # 存储为字符串,或JSON
db.commit()
logger.info(f"任务 {task_id} 成功完成。")
except asyncio.CancelledError as e:
# 捕获上面我们自己抛出的取消异常
task_db.status = TaskStatus.cancelled
task_db.result = str(e)
db.commit()
logger.info(f"任务 {task_id} 被标记为已取消。")
except Exception as e:
logger.error(f"任务 {task_id} 失败: {e}")
if 'task_db' in locals():
task_db.status = TaskStatus.failed
task_db.result = f"Error: {str(e)}"
db.commit()
finally:
# 确保数据库会话被关闭
db.close()
# ARQ Worker 的配置
class WorkerSettings:
"""
ARQ 的并发量主要由 Worker 的 max_jobs 和线程池大小决定。
默认:
max_jobs = 100(即 ARQ worker 同时最多处理 100 个任务)
默认使用 ThreadPoolExecutor 的默认线程池为 CPU 核心数 × 5(在现代 Python 3.8+)。
没有显式限制线程池,所以会使用默认线程池大小,假如你机器是 8 核 CPU,则线程池约 40 个线程。
"""
functions = [job_process_01] # 注册我们的任务函数
# 使用你的 Redis 连接信息
redis_settings = arq.connections.RedisSettings(host="localhost", port=6379)
max_jobs = 5 # 将并发数设置为 5, 便于测试这样就建好了arq程序。只要我们调用arq worker.WorkerSettings就可以启动这个独立的进程。它会监听redis队列,一旦有新任务入队,他就拉过来执行。
然后是FastAPI部分。我们新建一个main.py文件,内容如下:
python
from fastapi import FastAPI
import uvicorn
from fastapi.middleware.cors import CORSMiddleware
import arq
from arq.connections import RedisSettings
from routes_task import router as task_router
from contextlib import asynccontextmanager
@asynccontextmanager
async def lifespan(app: FastAPI):
REDIS_SETTINGS = RedisSettings(host="localhost", port=6379)
app.state.redis = await arq.create_pool(REDIS_SETTINGS) # 创建时,启动redis连接
yield
await app.state.redis.aclose() # 销毁时,关闭
app = FastAPI(lifespan=lifespan, title='任务接口', description='接口', docs_url='/docs', version="v1.0")
app.add_middleware(CORSMiddleware, allow_origins=["*"], allow_credentials=True, allow_methods=["*"], allow_headers=["*"])
app.include_router(task_router, prefix="/task", tags=["任务管理"]) # 任务管理相关的接口路由
if __name__ == '__main__':
uvicorn.run(app=app, host="0.0.0.0", port=8001)要走这一套,我们需要fastapi、uvicorn组件的支持,可以通过pip install安装。需要在routes_task.py中具体写任务的创建、停止等业务逻辑。
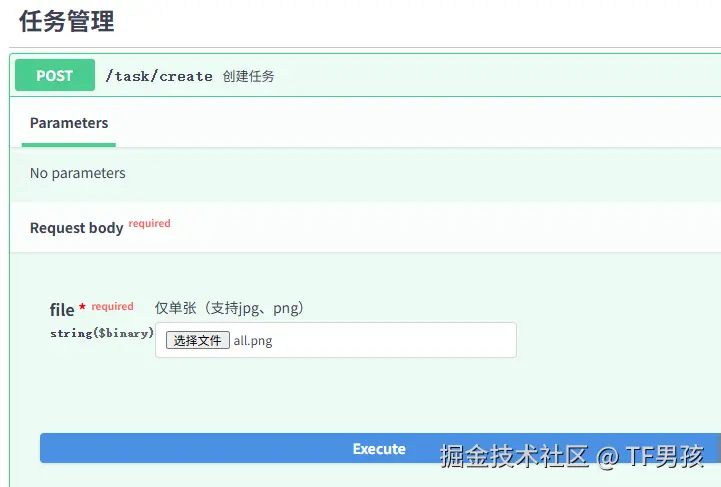
以下以创建任务为例:
python
@router.post("/create", summary="创建任务")
async def create_task(
file: UploadFile = File(..., description="支持jpg、png图片"),
db: Session = Depends(get_db), redis: ArqRedis = Depends(get_redis)):
try:
task_id = str(uuid.uuid4())
file_ext = os.path.splitext(file.filename)[1]
saved_file_path = os.path.join(CACHE_DIR, f"{task_id}{file_ext}")
with open(saved_file_path, "wb") as buffer:
shutil.copyfileobj(file.file, buffer)
new_task = CorrectionTask(
task_id=task_id,
image_path=saved_file_path,
status=TaskStatus.pending)
db.add(new_task)
db.commit()
db.refresh(new_task)
# 加入异步队列
await redis.enqueue_job("job_process_01", task_id, saved_file_path)
except Exception as e:
logger.error(f"create_task error \n{traceback.format_exc()}")
return {"code": 500, "data": "", "msg": "任务创建失败"}
return {"code": 200, "data": task_id, "msg": "任务已创建,正在后台处理中"}这个接口接收一个图片文件,然后生成一个任务id,将数据送入队列,立马返回任务的task_id。
下面我们试验一下效果。首先,分别启动这两个服务。
ruby
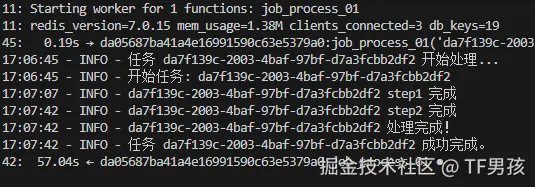
root@localhost:~/projects/arq-task# arq worker.WorkerSettings
17:00:11: Starting worker for 1 functions: job_process_01
17:00:11: redis_version=7.0.15 mem_usage=1.38M clients_connected=3 db_keys=19我们启动arq它提示为job_process_01函数分配一个任务队列。后面输出的是redis的版本以及连接的信息。
接下来启动fastapi。
ruby
root@localhost:~/projects/arq-task# python main.py
INFO: Started server process [12892]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8001 (Press CTRL+C to quit)因为fastapi集成了Swagger,我们也定义了接口文档地址FastAPI(..., docs_url='/docs)。所以可以直接访问 http://0.0.0.0:8001/docs 通过页面创建任务。
创建完成后,结果会返回task_id。
json
{
"code": 200,
"data": "da7f139c-2003-4baf-97bf-d7a3fcbb2df2",
"msg": "任务已创建,正在后台处理中"
}我们在arq的控制台也可以看到任务的接收和执行情况。
单次执行,体现不出来队列的意义。我们试一下并发处理,也就是瞬间创建多个任务。我们之前通过max_jobs=5设置了arq最大并发处理5个。这单纯是为了测试,你也可以设置500、5000或者50000。我们要看看,如果超了最大值,它会怎么样。
我们用程序瞬间创建了16次请求。我们看到MySQL新增了16条数据。
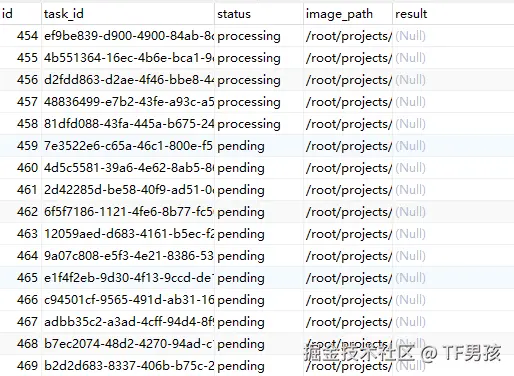
其中5条变为处理中,11条是等待中。几乎同时从arq的控制台开始了5项任务。
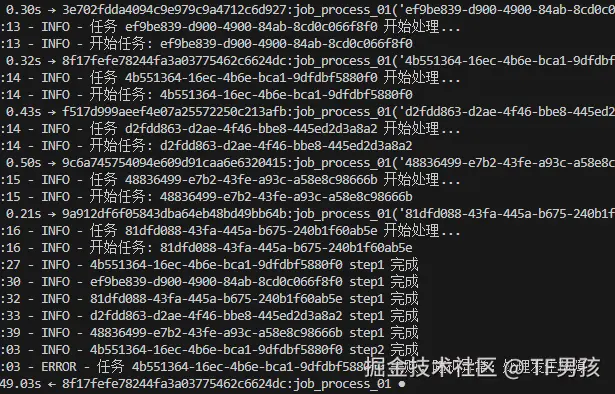
随着时间推移,任务不断地在消耗,有的处理成功,有的处理失败。
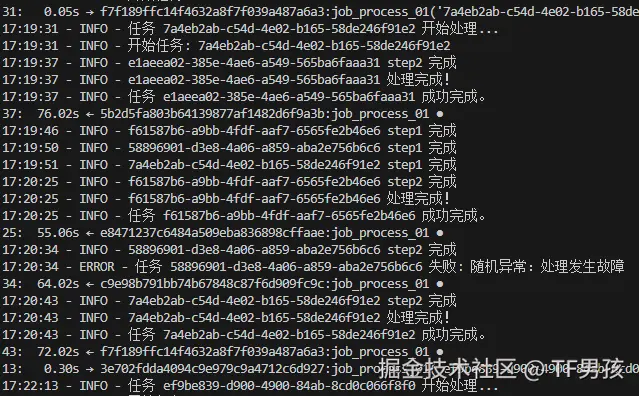
数据库中的状态和结果也在变化。但是processing处理中的数量一直是5个,没有处理完的是pending等待状态。
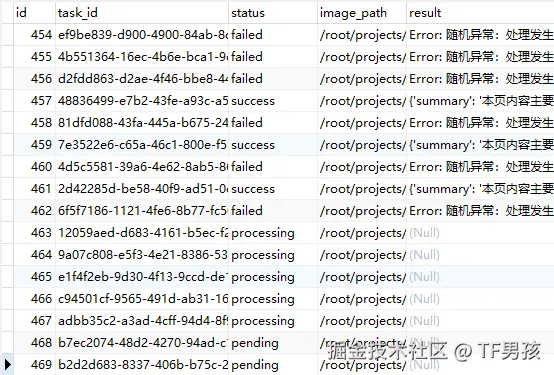
这个过程中,redis中的KEY也在不断变化。
我们也可以通过接口调用redis内实时的队列情况,队列中7个任务,进行中5个,等待中2个。
json
{
"code": 200,
"data": {
"queue_num": 7,
"in_progress": 5,
"wait": 2
}
}借助这个,我们也可以做一个限流,比如等待超过10万的时候,创建任务接口返回"当前服务器压力大,暂不营业"友好提示。
这是正常场景。我们再来测试一下异常场景。比如全面开启了任务后,我们通过队列取消,然后再重试。
我先创建一批任务,他们开始并行5个执行。
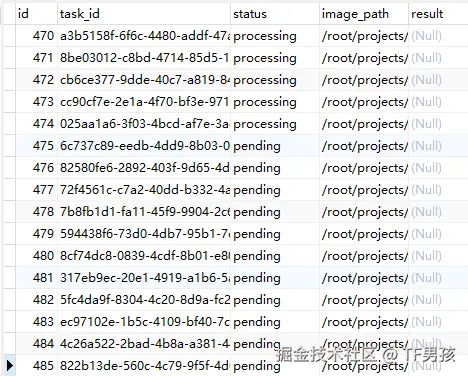
然后我对所有任务执行取消,我们看到前5个任务已经执行完了第一步,后面并没有执行第二步,终止了。
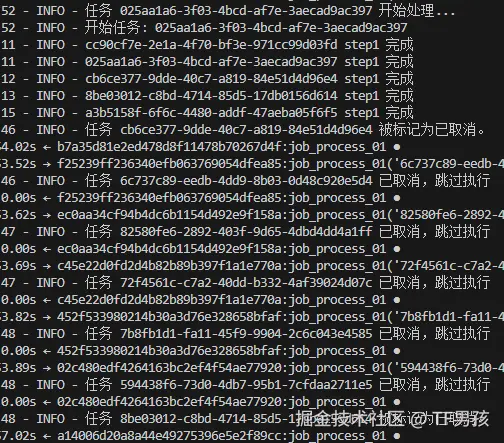
最终是全部未执行完的任务被取消。
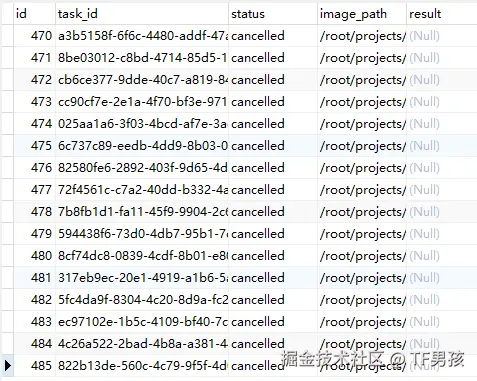
然后我们再重新启动任务。结果任务又开始正常执行了。
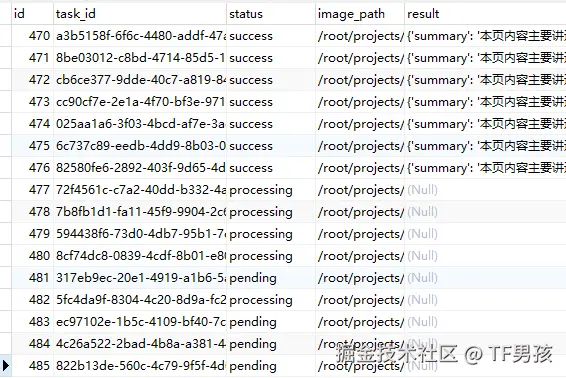
再来一个异常场景。
我先创建一批任务,等他执行到火热的阶段,有成功的,有执行中的,也有等待执行的。
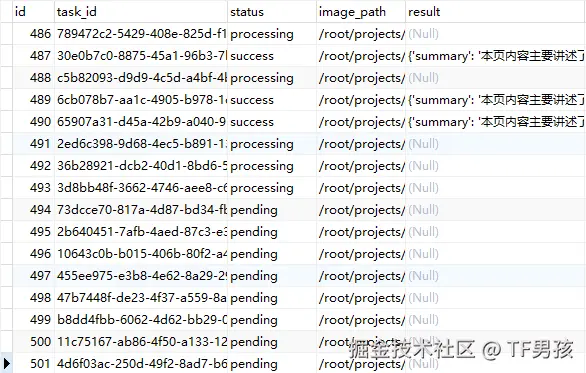
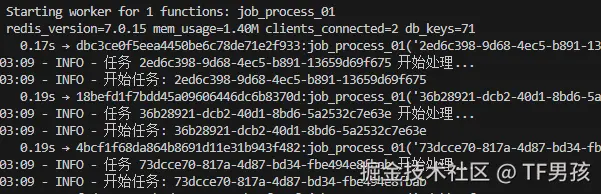
这时候我重启服务,模拟异常中断。结果它标记被打断,以后会继续运行。

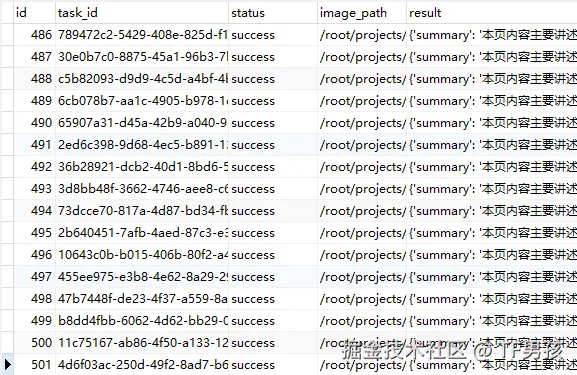
重启之后,继续执行。
最后,所有任务执行完成。
当大家都在追求各类跨平台的通用"预制菜"的时候。我更崇尚深度定制在一个设备上的"私房菜"。因为...穷!只能深度结合自身条件,将仅有的特长发挥到极致,以此实现低成本高效率。缺点就是限定场景。谁都想财大气粗,整套千万元的服务器,但是咱们不行。没有GPU,那就用CPU。没有大平台,就研究小平台。
瞧他这个没出息的样子~