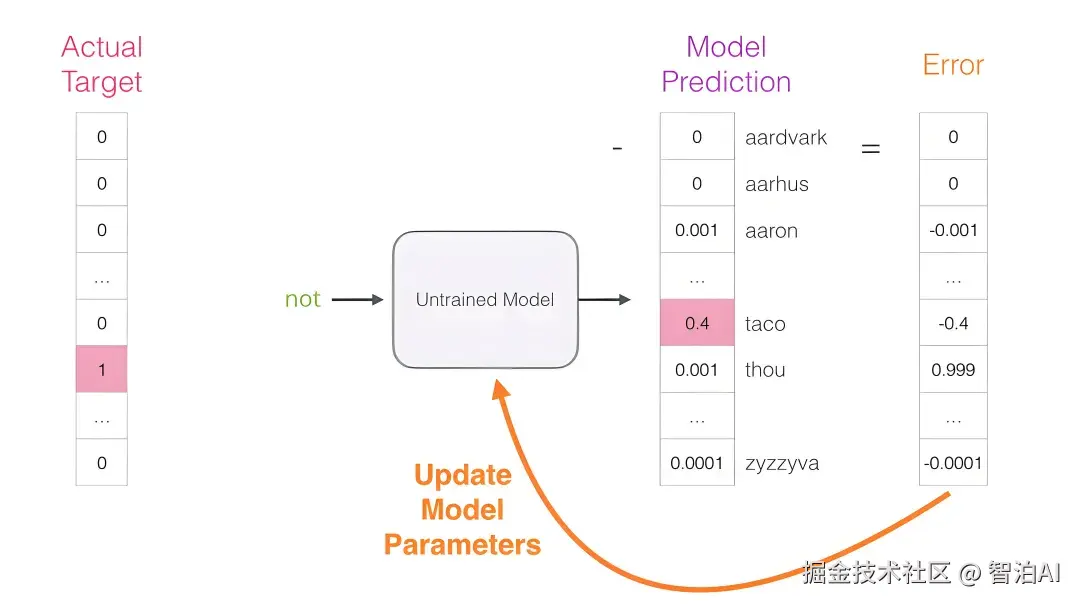
在自然语言处理(NLP)的发展历程中,如何有效地表示词语是构建智能语言系统的关键基础。
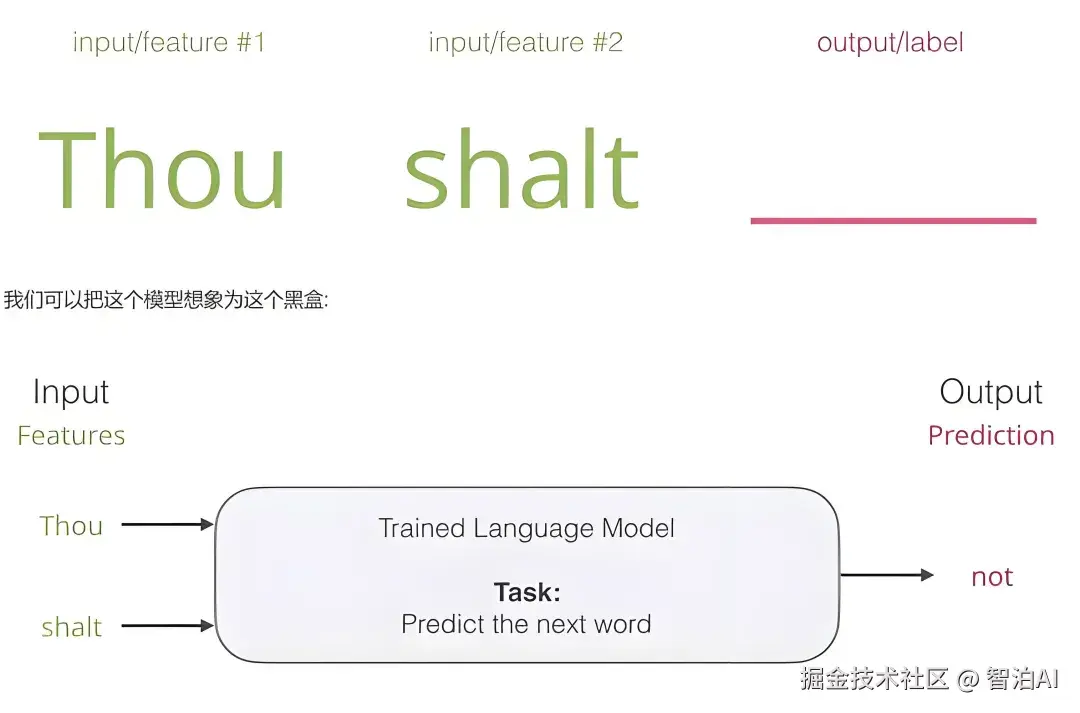
传统的符号化表示方法难以捕捉语义信息,而现代深度学习模型依赖于连续、低维且富含语义的向量表示。
本文围绕"为什么要做词嵌入"这一核心问题,系统阐述One-Hot编码的局限性,介绍词嵌入(Word Embedding)的基本原理与优势。
并进一步探讨位置嵌入(Position Embeding)在序列建模中的必要性,逻辑清晰地呈现词表示技术的演进路径。
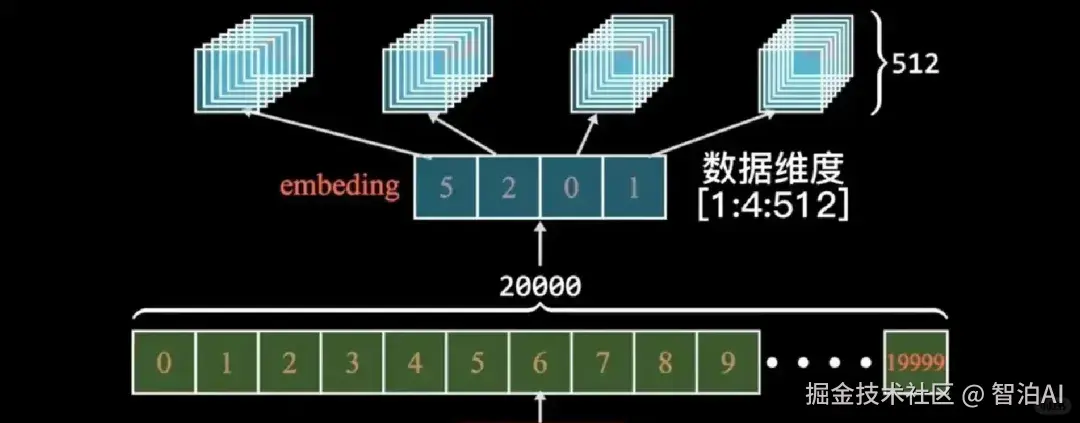
一、为什么要做词嵌入?
语言的本质是意义的传递,而机器理解语言的前提是将文本转化为可计算的数学形式。
早期方法将词语视为离散符号,但这种表示方式无法反映词语之间的语义关系。例如,"医生"和"护士"在语义上相关,但在符号层面彼此孤立。
词嵌入的核心目标就是为了解决这一问题:
实现语义表示:通过将词语映射到连续向量空间,使语义相近的词在向量空间中距离更近(如"国王"与"王后")。
支持泛化能力:模型可通过向量运算捕捉类比关系(如"巴黎 - 法国 + 意大利 ≈ 罗马")。
提升计算效率:相比高维稀疏表示,低维稠密向量显著降低存储与计算开销。
适配深度学习框架:为神经网络提供可微、可学习的输入表示,支持端到端训练。
因此,词嵌入不仅是技术手段,更是连接语言学与机器学习的桥梁,构成了现代 NLP 系统的基石。
二、One-Hot Encoding:简单但低效
One-Hot编码是一种最基础的词表示方法。
1. 原理
给定一个大小为 V 的词汇表,每个词用一个 V 维向量表示,其中仅对应位置为1,其余为0。
例如,词汇表为 "猫", "狗", "鸟",则"狗"的 One-Hot 向量为 0, 1, 0。
2. 优点
实现简单,逻辑清晰。
每个词有唯一、明确的标识。
3. 缺陷
高维稀疏:当词汇表庞大时(如10万词),向量维度极高,99%以上为零值,造成资源浪费。
无语义信息:任意两个不同词的向量正交(余弦相似度为0),无法体现"猫"与"狗"比"猫"与"石头"更相近的事实。
无法泛化:模型难以从已知词推断未知词的语义,缺乏迁移能力。
不支持相似性计算:无法回答"与'快乐'最接近的词是什么"。
由于上述局限,One-Hot 编码仅适用于教学演示或极简系统,无法满足现代 NLP 需求。
三、Word Embedding:语义向量
词嵌入(Word Embedding)将每个词映射为一个低维实数向量(如128或300维),通过在大规模语料上训练获得,使得向量空间能够反映词语的语义和语法特性。
1. 核心思想
"一个词的含义由其上下文决定"------分布假说(Distributional Hypothesis)。
词嵌入正是这一思想的数学实现:频繁共现的词在向量空间中距离更近。
主要方法
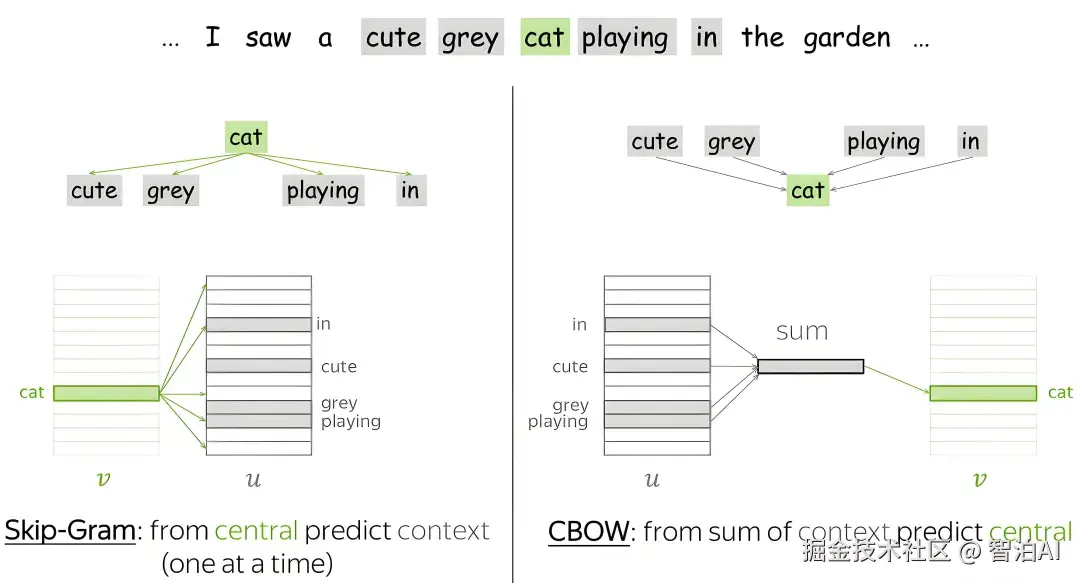
Word2Vec(Mikolov et al., 2013)
包括 CBOW(根据上下文预测中心词)和 Skip-gram(根据中心词预测上下文),通过浅层神经网络学习词向量,高效且效果显著。
GloVe(Pennington et al., 2014)
基于全局词共现统计矩阵进行因子分解,结合了全局统计与局部上下文优势。
FastText(Bojanowski et al., 2017)
将词分解为 n-gram 子词单元,支持未登录词(OOV)的表示,尤其适合形态丰富的语言。
2. 优势
向量稠密、维度低,适合大规模计算。
捕捉语义相似性(如"汽车"≈"轿车")和语法规律(如动词时态、复数形式)。
可预训练、可迁移,广泛用于文本分类、命名实体识别、机器翻译等任务。
3. 局限
静态表示:每个词只有一个固定向量,无法处理一词多义(如"苹果手机" vs "吃苹果")。
对低频词表示效果较差。
注:后续发展如 ELMo、BERT 等动态嵌入模型通过上下文感知解决了多义性问题,但其输入层仍依赖基础词嵌入机制。
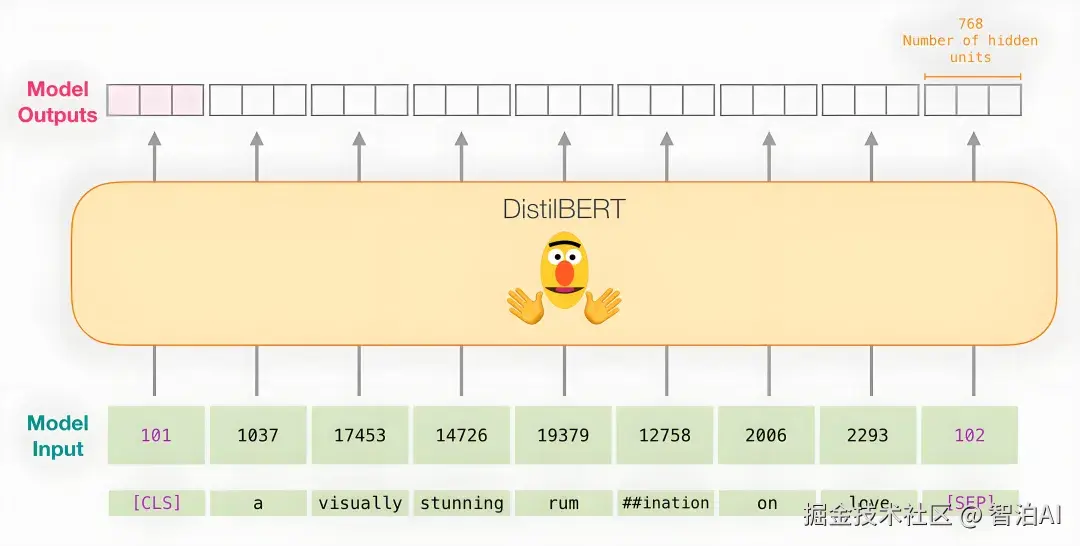
四、Position Embedding:为序列注入顺序信息
尽管词嵌入成功表达了语义,但它本身不包含词序信息。而语言是序列性的,"我爱你"与"你爱我"语义完全不同。
在 RNN、LSTM 等时序模型中,顺序通过时间步隐式建模;但在 Transformer 等并行架构中,必须显式引入位置信息。
1. 为什么需要位置嵌入?
Transformer 模型通过自注意力机制并行处理所有词,失去了天然的顺序感知能力。
若无位置信息,模型将无法区分句子中词的排列顺序,导致语义混乱。
2. 实现方式
(1)学习式位置嵌入(Learned Position Embedding)
为每个位置(如第1位、第2位......)分配一个可训练的向量。
在 BERT、RoBERTa 等模型中采用。
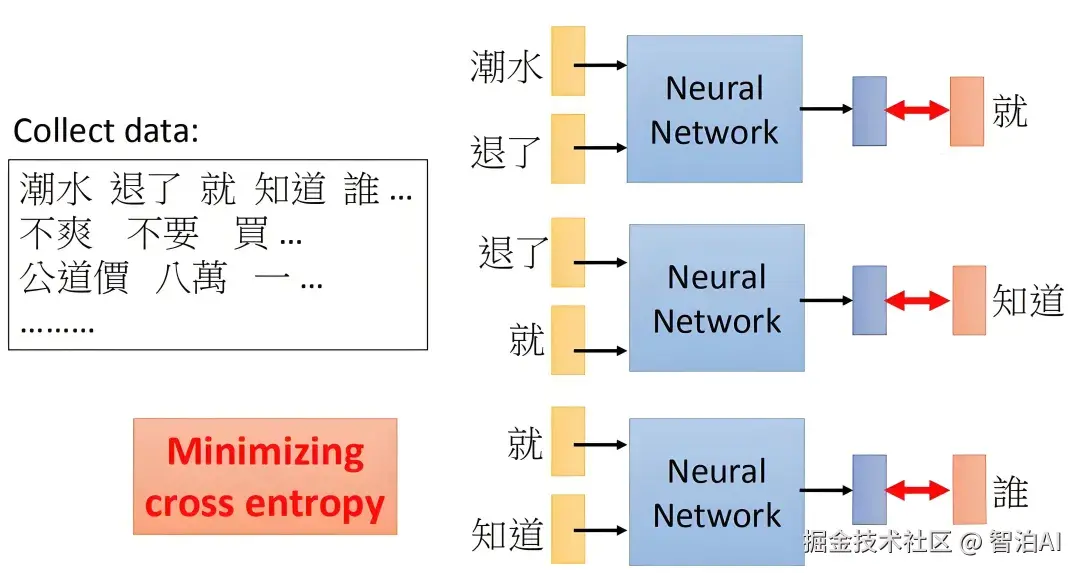
优点:灵活,可适应任务需求。
缺点:受限于训练时的最大长度,难以外推到更长序列。
(2)函数式位置嵌入(Sinusoidal Position Embedding)
使用正弦和余弦函数生成固定位置编码,定义如下:
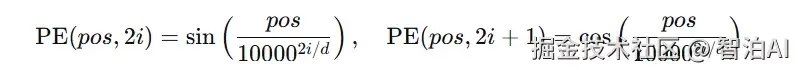
其中 pos 为位置索引,i 为维度索引,d 为嵌入维度。
在原始 Transformer 中使用。
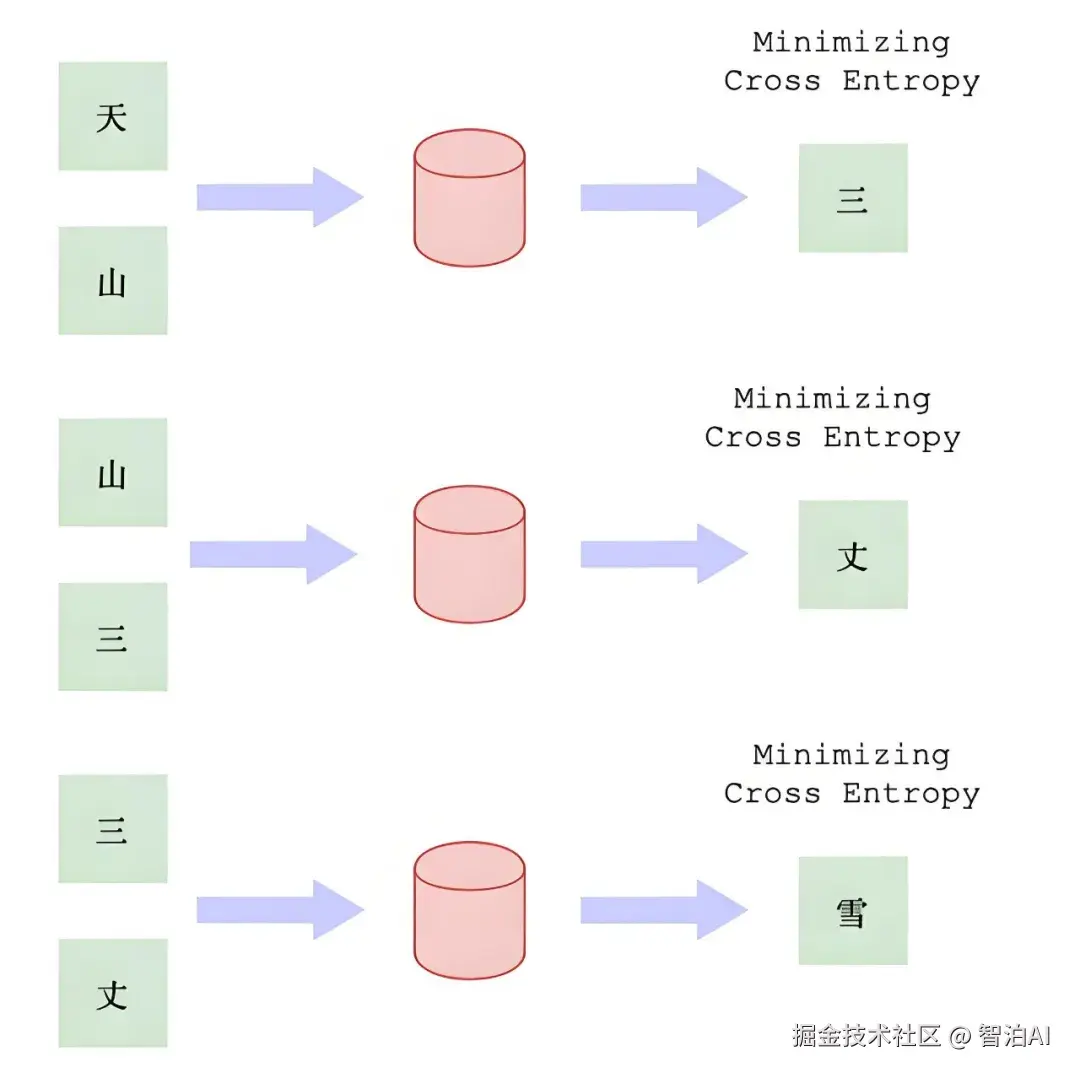
优点:可泛化到比训练更长的序列;能隐式表示相对位置。
3. 与词嵌入的融合
最终输入表示为两者的逐元素相加:
Input Embedding=Word Embedding+Position Embedding
这一设计使得模型既能理解"谁在说什么",也能知道"谁先说、谁后说"。
4. 发展趋势
近年来,相对位置编码(Relative Position Encoding)、旋转位置编码(RoPE)等改进方法被提出,进一步提升了长序列建模能力。
五、总结与对比

词表示技术的演进反映了 NLP 从符号化到分布式、从静态到动态、从局部到全局的发展趋势。
One-Hot 编码是词表示的起点,但因缺乏语义和效率低下而被淘汰。
词嵌入实现了语义的连续化表达,是现代 NLP 的核心组件。
位置嵌入弥补了词嵌入对顺序不敏感的缺陷,使非循环结构也能处理序列数据。
在实际系统中,词嵌入与位置嵌入协同工作,共同构成语言模型的输入表示。