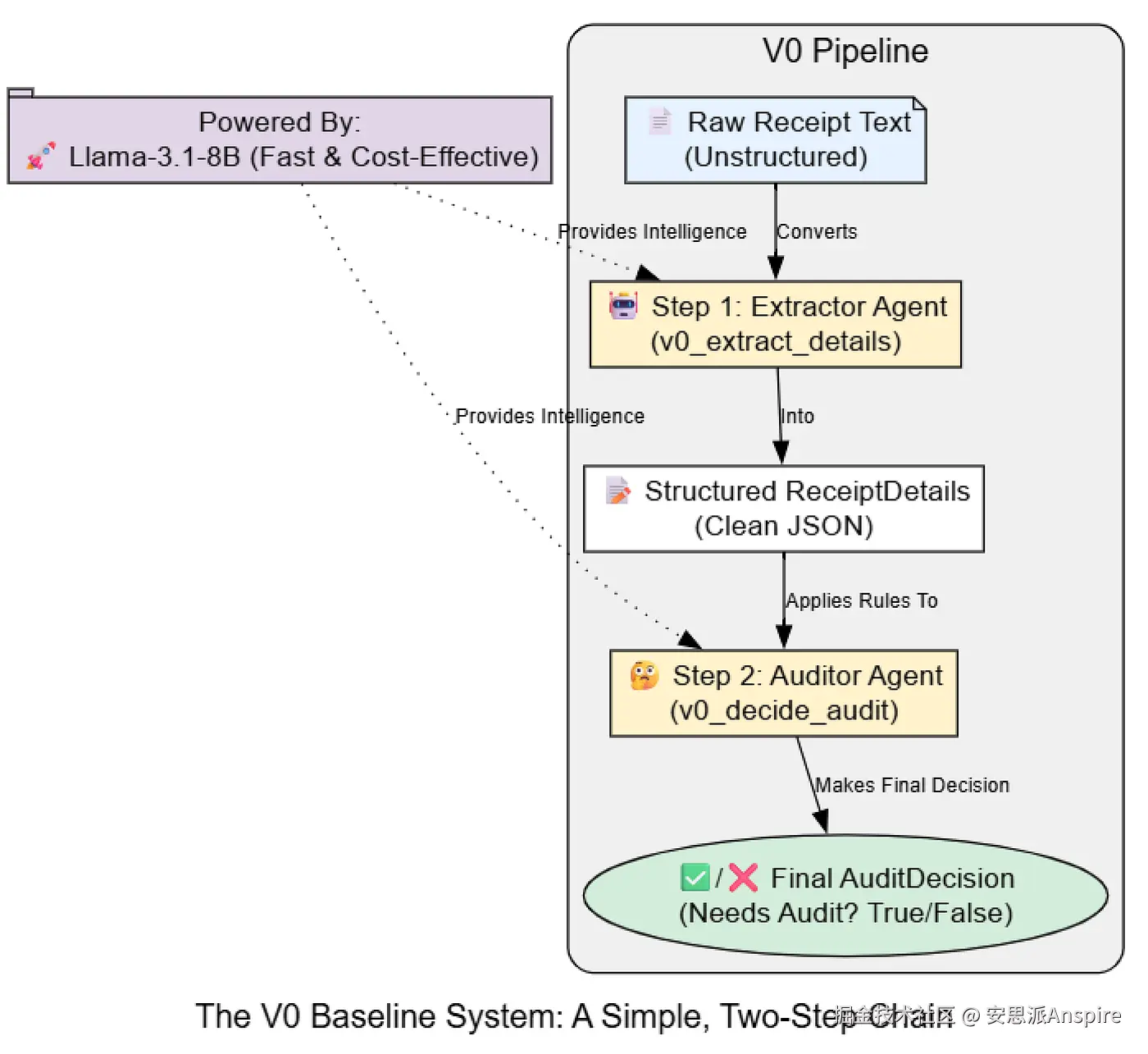
创建V0基线
在明确了问题并准备好数据之后,是时候构建我们的第一个系统了。在评估驱动开发中,初始版本,即 V0,遵循一个核心原则:
-
我们的第一个版本(V0)应该是可能有效的最简单的东西。目标不是构建一个完美的系统,而是建立一个基线。
-
这个基线使我们能够进行初步评估,发现最显著的弱点,进而指导我们未来更有针对性的开发工作。
我们将创建一个简单的线性链,原始收据文本将被输入到一个提取器 代理中,其结构化输出将被传递给一个审核器代理,审核器将做出最终决策。对于这个V0系统,我们将使用我们快速且经济高效的meta/Meta-Llama-3.1-8B-Instruct模型。
让我们把这个简单的流程转化为代码。我们的V0系统将有两个主要组件:一个用于提取细节的代理和一个用于做出审计决策的代理。
创建V0提取器代理
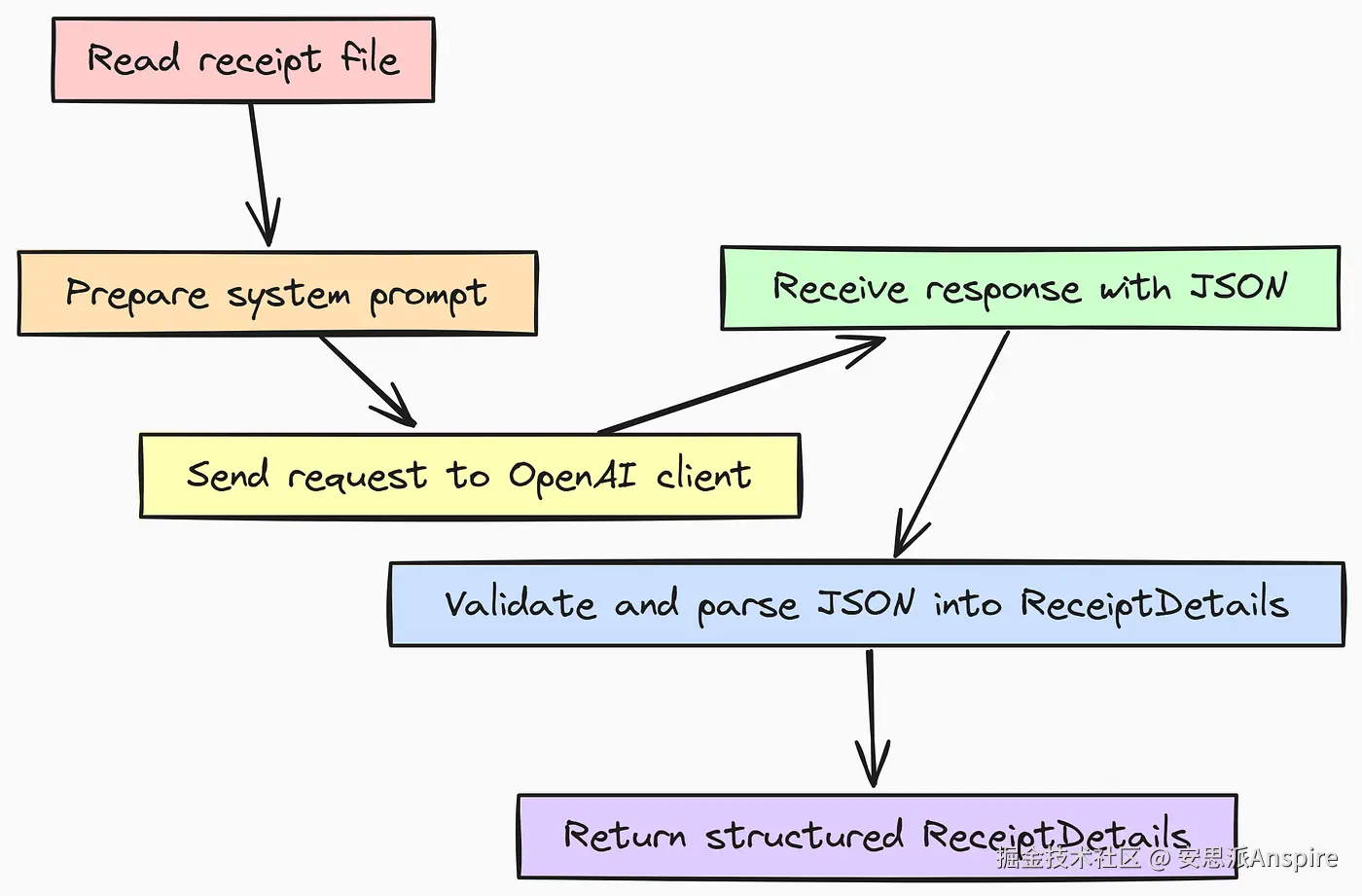
首先,我们将创建v0_extract_details函数。该代理的唯一任务是从模拟的收据图像中提取原始文本,并将其转换为我们之前定义的结构化ReceiptDetails Pydantic模型。
python
async def v0_extract_details(image_path: Path, model: str = "meta/Meta-Llama-3.1-8B-Instruct") -> ReceiptDetails:
"""V0提取器:一个简单的提示,用于从文本中获取结构化数据。"""
# 从模拟的图像文件中读取内容。
image_content = image_path.read_text()
system_prompt = (
"你是一位专业的收据处理助手。 "
"从提供的收据文本中提取关键细节,并将其格式化为JSON。"
)
# 'openai'库可与任何兼容OpenAI的API一起使用。# 通过使用`response_model`,我们指示客户端根据我们的Pydantic模式处理JSON解析和验证。# 这是一种"输出解析"或"受限解码"形式。response = await client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": f"这是收据内容:\n\n{image_content}"}
],
response_model=ReceiptDetails # 这确保输出是有效的 ReceiptDetails 对象。
)
return response这里的逻辑故意设计得很直接。我们提供一个简单的系统提示,明确说明代理的角色。此函数最重要的部分是response_model=ReceiptDetails参数。通过将我们的 Pydantic 类直接传递给客户端,我们将解析可能格式错误的 JSON 这一复杂且容易出错的任务卸载掉了。
客户端库负责验证,即确保函数要么返回有效的ReceiptDetails对象,要么抛出错误,从而使我们的系统更加健壮。
构建V0审计代理
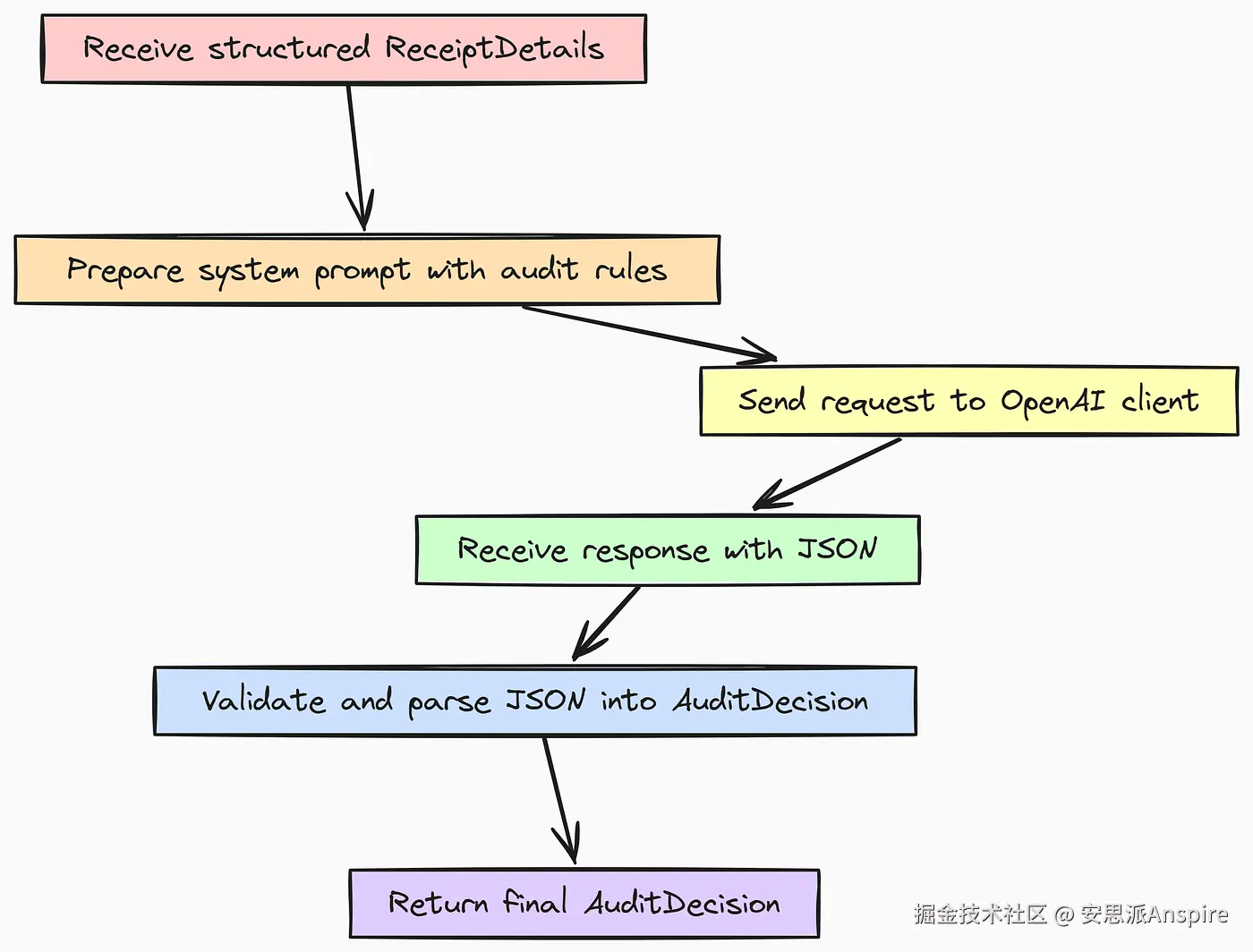
接下来,我们创建v0_decide_audit函数。此代理从提取器接收结构化的ReceiptDetails对象,并负责应用我们的业务规则来做出最终的AuditDecision。
python
async def v0_decide_audit(receipt_details: ReceiptDetails, model: str = "meta/Meta-Llama-3.1-8B-Instruct") -> AuditDecision:
"""V0审计员:一个基于结构化数据做出决策的简单提示。"""
system_prompt = (
"你是一位专业的费用审计员。根据提供的收据详情, "
"依据以下规则确定是否需要进行审计:\n"
"1. 非差旅相关:费用是否用于差旅以外的事项(汽油、酒店、航班、差旅期间的餐饮)?"2. 金额超限:总金额是否超过75美元?"3. 计算错误:各项小计 + 税费是否不等于最终总额?"4. 手写X:是否有手写的'X'表示作废项目?"如果上述任何一项为真,则收据需要审计。请说明理由。 response = await client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": system_prompt},
# 我们将 Pydantic 对象重新序列化为 JSON 字符串,作为模型的输入。
{"role": "user", "content": receipt_details.model_dump_json(indent=2)}
],
response_model=AuditDecision # 确保输出符合我们的 AuditDecision 模式。
)
return response在这个函数中,我们直接在system_prompt中明确提供所有业务规则。这是将逻辑注入大语言模型(LLM)的最简单方法。我们获取ReceiptDetails对象,使用.model_dump_json()将其重新序列化为简洁的JSON字符串,然后将其传递给模型。同样,我们使用response_model=AuditDecision来确保输出有效且结构化。
在测试用例上运行V0管道
现在,让我们将这两个智能体连接起来,并在数据集中一个有趣的示例上运行它们:receipt_4.txt,即那个已知存在数学错误的示例。这将让我们快速直观地检查系统是否能够处理非平凡的情况。
python
async def run_v0_pipeline(image_path: Path):
"""执行完整的 V0 管道:先提取再审核。"""
extracted_details = await v0_extract_details(image_path)
audit_decision = await v0_decide_audit(extracted_details)
return extracted_details, audit_decision
# 在单个示例上运行 V0 以查看其实际效果。
# 我们选择一个已知存在数学错误的收据,以查看简单系统是否能够捕捉到该错误。
example_path = IMAGE_DIR / "receipt_4.txt"
print(f"在 {example_path.name} 上运行 V0 管道(即那个有数学错误的)...")
# 等待异步管道。
v0_example_details, v0_example_audit = await run_v0_pipeline(example_path)
print("\nV0 提取的详细信息:")
print(v0_example_details)
print("\nV0 审计决策:")
print(v0_example_audit)run_v0_pipeline函数只是对我们的两步流程进行编排。我们在选定的示例上调用它并打印结果。
ini
######## 输出 ##########
正在对 receipt_4.txt(那个有数学错误的文件)运行 V0 管道...
V0 提取的详细信息:
ReceiptDetails(
merchant='Corner Cafe',
location=Location(city='San Francisco', state='CA'),
items=[
LineItem(description='三明治', quantity=1.0, price=10.0, total=10.0),
LineItem(description='咖啡', quantity=1.0, price=4.0, total=4.0),
],
subtotal=None,
tax=1.0,
total=16.0,
handwritten_notes=[],
)
V0 审计决策:
AuditDecision(
not_travel_related=False,
amount_over_limit=False,
math_error=True,
handwritten_x=False,
reasoning='The sum of the items ($10.00 + $4.00) plus tax ($1.00) is $15.00, which does not match the total of $16.00. A math error is present.',
needs_audit=True,
)V0系统在这个单一示例中似乎运行良好!Llama 8B模型正确地从文本中提取了所有数据,更令人印象深刻的是,审计代理正确地识别出了数学错误,并标记该收据进行审计。
然而,我们不能只相信单一的数据点。这次的成功可能只是幸运的巧合。为了真正了解我们系统的性能,我们必须构建一个正式的评估套件,并针对整个数据集进行测试,以系统地找出系统出现问题的地方。现在是时候让我们的 V0 系统接受首次考验了。
运行我们的基础评估套件
我们的V0系统通过了一次单点检查,但这给了我们一种虚假的安全感。为了真正了解其能力和局限性,我们必须从轶事证据转向系统测试。这就是我们构建基础评估套件的地方。
一个稳健的评估由几个关键要素组成:
-
一个输入(我们的收据文本)
-
预测(代理的输出)
-
参考(专家标注的地面实况)
评估的核心在于评分器的功能,即把预测结果与参考标准进行比较并得出分数。
我们的评分员将分为两类:
-
**确定性:**简单的、基于规则的逻辑,如prediction.total == reference.total。这些方法快速、成本低,非常适合检查客观事实。
-
**基于模型:**使用强大的大语言模型(我们的Qwen-235B模型)作为公正的评判者,对复杂、细微的方面进行评分,如生成推理的质量。
首先,我们需要在所有测试样本上运行我们的V0管道,以便将输入、预测和地面实况参考收集到一个单一、统一的结构中进行评估。
为评估数据集生成预测
我们将首先创建一个EvaluationRecord类,用于保存单个测试用例的所有数据。这样可以使我们的评估逻辑保持清晰和有条理。
yaml
# 这个类将包含单个评估点所需的所有数据。
class EvaluationRecord(BaseModel):
sample_id: str
input_content: str
predicted_details: ReceiptDetails
predicted_audit: AuditDecision
reference_details: ReceiptDetails
reference_audit: AuditDecision现在,我们将创建一个异步函数generate_predictions_for_eval,用于遍历整个数据集,对每个样本运行 V0 管道,并将结果打包成一个包含这些EvaluationRecord对象的列表。
ini
async def generate_predictions_for_eval(image_dir: Path, ground_truth_dir: Path) -> List[EvaluationRecord]:
"""运行 V0 管道处理整个数据集,为评估做准备。"""
records = []
# 获取所有样本文件,排序以确保顺序一致。
image_paths = sorted(list(image_dir.glob("*.txt")))
print(f"正在为 {len(image_paths)} 个样本生成预测...")
# 我们可以并行运行这些操作,但为了在笔记本中保持清晰,我们将按顺序运行。
对于 image_path 在 image_paths中:
sample_id = image_path.stem
gt_path = ground_truth_dir / f"{sample_id}.json"
# 从JSON文件中加载地面实况。
with open(gt_path, "r") as f:
ground_truth_data = json.load(f)
reference_details = ReceiptDetails(**ground_truth_data["details"])
reference_audit = AuditDecision(**ground_truth_data["audit"])
# Obtain prediction results by running the V0 pipeline.
predicted_details, predicted_audit = await run_v0_pipeline(image_path)
records.append(EvaluationRecord(
sample_id=sample_id,
input_content=image_path.read_text(),
predicted_details=predicted_details,
predicted_audit=predicted_audit,
reference_details=reference_details,
reference_audit=reference_audit
))
print(f"已处理 {image_path.name}")
print("预测生成完成。")
返回记录# 此步骤涉及 API 调用,可能需要一些时间。# 我们将把结果存储在一个变量中,用于我们的评估运行。eval_dataset = await generate_predictions_for_eval(IMAGE_DIR, GROUND_TRUTH_DIR)此函数是我们评估设置的核心。它系统地处理每张收据,将 V0 代理的预测详情和预测审计与专家标注的参考详情和参考审计进行配对。
shell
######### 输出 ##########
正在为 5 个样本生成预测...
已处理 receipt_1.txt
已处理 receipt_2.txt
已处理 receipt_3.txt
已处理 receipt_4.txt
已处理 receipt_5.txt
预测生成完成。现在我们的评估数据集已经填充完毕,我们现在完全有能力创建评分器并运行完整的评估。
定义V0评分器套件
在实际项目中,这可能是一个类似OpenAI Evals这样的平台的配置文件。在这里,我们将它们定义为Python函数,以便在本地模拟运行,这清晰地展示了核心逻辑。
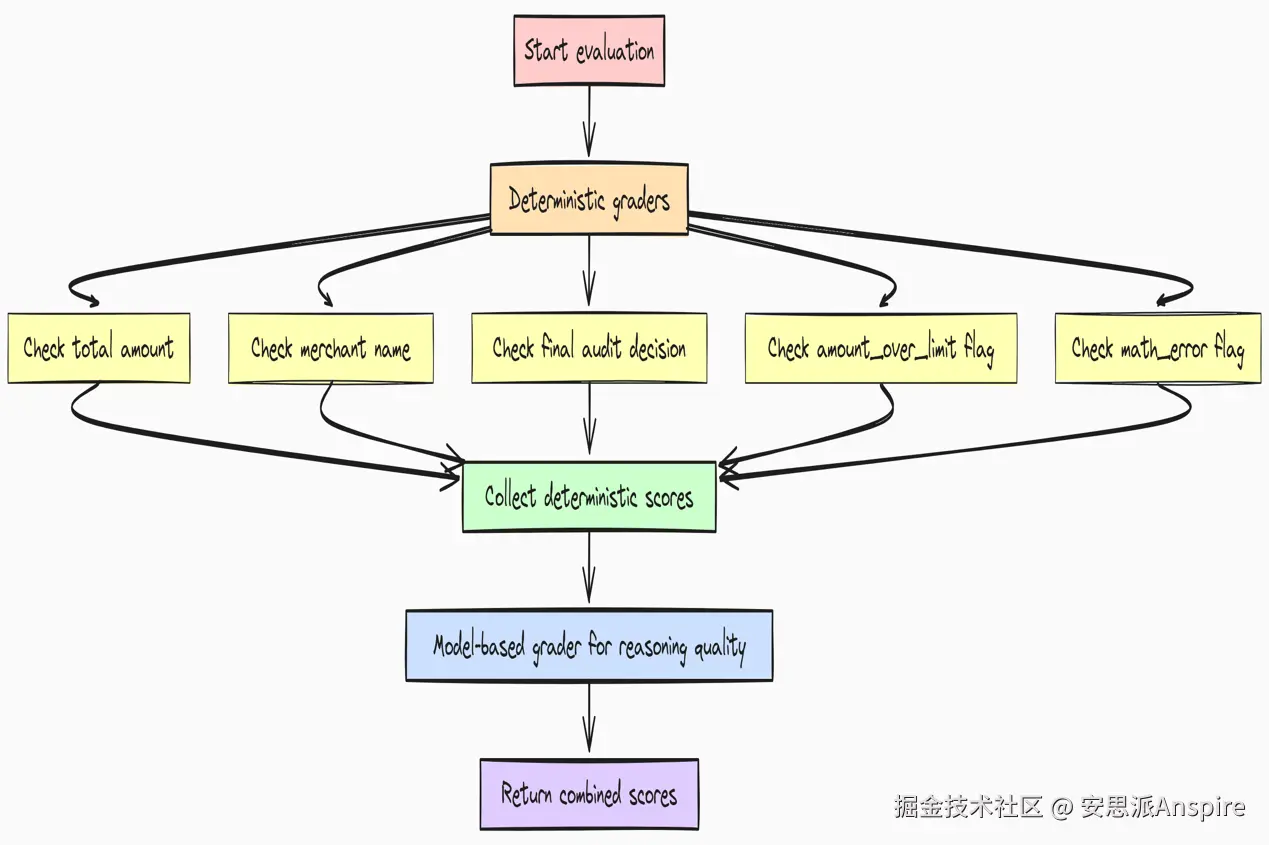
我们将从针对客观事实的简单、确定性评分器开始。
python
# --- 确定性评分函数 ---
def grade_total_amount(record: EvaluationRecord) -> float:
"""检查预测的总金额是否与参考值匹配。"""
# 对于财务数据,期望完全匹配。
return 1.0 if record.predicted_details.total == record.reference_details.total else 0.0
def grade_merchant_name(record: EvaluationRecord) -> float:
"""检查商户名称是否不区分大小写且去除空白后匹配。"""
# 对字符串进行规范化处理,可使检查对大语言模型(LLM)的细微格式差异具有鲁棒性。
pred = record.predicted_details.merchant.lower().strip()
ref = record.reference_details.merchant.lower().strip()
返回 1.0 如果 pred == ref 否则 0.0
定义 grade_final_audit_decision(record: EvaluationRecord) -> float:
"""检查最重要的最终输出 needs_audit 是否正确。"""
返回 1.0 如果 record.predicted_audit.needs_audit == record.reference_audit.needs_audit 否则 0.0
定义 grade_audit_reason_amount(record: EvaluationRecord) -> float:
"""检查 'amount_over_limit' 标志是否被正确识别。"""
返回 1.0 如果 record.predicted_audit.amount_over_limit == record.reference_audit.amount_over_limit 否则 0.0
def grade_audit_reason_math_error(record: EvaluationRecord) -> float:
"""检查 'math_error' 标志是否被正确识别。"""
return 1.0 if record.predicted_audit.math_error == record.reference_audit.math_error else 0.0现在,如果您查看每个功能,每个功能都针对代理性能的一个特定、可衡量的方面,从提取字段(如总计和商家)的准确性到最终审计标志的正确性。
现在来处理一项更复杂的任务,即对推理质量进行评分。这是主观的,需要一个更强大的评判者。
ini
# ---基于模型的评分器函数---
async def grade_reasoning_quality(record: EvaluationRecord, model: str = "Qwen/Qwen3-235B-A22B-Instruct-2507") -> float:
"""使用强大的大语言模型来判断推理字符串的质量。"""
prompt = f"""
你是一个评估助手。将审计决策的预测推理与地面实况推理进行比较。
如果预测的推理在逻辑上正确地证明了审计决策的合理性,即使表述不同,也得1分。
如果推理存在缺陷、不相关或遗漏了关键点,则得0分。
真实推理:
{record.reference_audit.reasoning}
预测推理:
{record.predicted_audit.reasoning}
预测的推理是否正确地证明了决策的合理性?回答"1"表示是,"0"表示否。
"""
response = await client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=1, # 我们只需要一个标记 '1' 或 '0'
temperature=0 # 使用温度 0 进行确定性评分
)
score_str = response.choices[0].message.content
try:
return float(score_str.strip())
except (ValueError, TypeError):
return 0.0 # 如果输出不是有效数字,则判定为不及格。这是我们的第一个大语言模型裁判。对于这项任务,使用一个能力强大的模型(在我们的案例中是Qwen-235B)至关重要,以确保评估本身的准确性。我们使用低温和受限输出(max_tokens=1),以使评分尽可能具有确定性。
运行评估
最后,我们将创建一个编排器函数,在整个数据集上运行我们的评分器套件,并以简洁的DataFrame形式呈现结果。
python
# --- 评估运行器 ---
async def run_simulated_eval(dataset: List[EvaluationRecord]):
"""协调所有评分器对数据集的运行。"""
grader_suite = {
"提取/总金额": grade_total_amount,
"提取/商家名称": grade_merchant_name,
"审核/最终决策是否正确": grade_final_audit_decision,
"审核/原因:超限额": grade_audit_reason_amount,
"审核/原因:数学错误": grade_audit_reason_math_error,
"审计/推理质量(模型评分)": grade_reasoning_quality,
}
results = []
for record in dataset:
sample_scores = {"sample_id": record.sample_id}for name, func in grader_suite.items():
if asyncio.iscoroutinefunction(func):
score = await func(record)
else:
score = func(record)
sample_scores[name] = score
results.append(sample_scores)
return pd.DataFrame(results).set_index("sample_id")
# Run the evaluation and obtain detailed results for each sample.
v0_results_df = await run_simulated_eval(eval_dataset)
# Calculate summary statistics (pass rate) for each grader.
v0_summary = pd.DataFrame(v0_results_df.mean(), columns=["通过率"])
display(v0_results_df)
display(v0_summary)这个最终模块执行评估。让我们看看结果。
评估结果为我们的V0系统性能提供了清晰、量化的评判。详细的逐样本DataFrame立即将receipt_3和receipt_5标记为故障点。
-
在receipt_3上,系统在0.0的提取/商家名称项上得分,表明在解析商家"办公用品公司"时出现了特定错误
-
在receipt_5上,故障是系统性的。0.0在提取/总金额上表明初始数据解析是错误的。这个错误级联,导致0.0在审计/最终决策正确性上,以及0.0在审计/推理质量(模型评分)上。
有了这些结果,我们现在可以进入EDD周期中最重要的部分,即分析故障。
分析V0故障
在进行分析时,我们基本上是用确凿的数据取代主观感受,迫使我们正视系统中真正的弱点。
我们的全量表显示,在几个关键指标上的通过率为80%。虽然这并非彻底的失败,但对于处理财务数据的生产系统而言,80%的成功率是不可接受的。
详细的逐样本结果表立刻让我们找到了问题所在:receipt_3在简单的商户名称提取上失败了,但最严重的问题源于receipt_5,它引发了一连串的失败。
高层次的总结是不够的。我们需要进行根本原因分析。
要从
失败的事情
转向
失败的原因
,我们必须深入研究问题案例
评估记录
,即
收据_5
,并将其预测输出直接与我们的地面实况进行比较。
让我们编写一小段代码来隔离这条特定的记录,并打印一份清晰的诊断报告。
python
# 找出多次测试失败的特定记录。
failure_record = next(r for r in eval_dataset if r.sample_id == "receipt_5")
print("receipt_5的归因分析")
print("---------------------------------")
print(f"预测总计: {failure_record.predicted_details.total}")
print(f"参考总计: {failure_record.reference_details.total}")
print(f"\n预测最终审计: {failure_record.predicted_audit.needs_audit}")
print(f"参考最终审核: {failure_record.reference_audit.needs_audit}")
print("\n预测推理:")
print(failure_record.predicted_audit.reasoning)
print("\n参考推理:")
print(failure_record.reference_audit.reasoning)这段代码片段是我们的诊断工具。我们遍历评估数据集,以找到样本ID为"receipt_5"的记录。然后,我们打印出最关键的预测字段与其参考(地面实况)值的并排比较结果。这使得我们能够直接、明确地分析代理的错误。
bash
########### 输出 ###########归因分析针对收据_5
---------------------------------
预测总计:20.0
参考总计:21.6
预测最终审计:否
参考最终审计:是
预测原因:这张收据是用于一家五金店的,它不属于与差旅相关的费用。总金额为20.00美元,在75美元限额之内。没有计算错误。手写备注中包含一个'X',表示该项目已作废。由于该费用与差旅无关且备注中有一个'X'',这张收据需要审计。
参考理由:
与差旅无关且包含一个作废的'X''备注。这份详细的输出为我们提供了精确诊断所需的一切信息。V0系统在两个不同且关键的方面出现了故障:
-
**严重的提取失败:**前两行揭示了初始错误。代理预测的总数为20.00美元,而正确的总数是21.60美元。回顾原始收据文本,我们可以看到V0提取器完全遗漏了1.60美元的税行。它盲目地提取了在主要项目列表中看到的最后一个数字。这是简单提取系统的典型失败模式。
-
**批判性推理失败:**这是一种更为微妙且危险的错误。如果我们查看预测推理,代理正确地识别出需要进行审计的两个原因("非差旅相关费用"和"手写笔记包含'X'")。然而,尽管其推理正确,但最终得出的预测最终审计结果为否。代理的最终决策与其自身的分析相矛盾。这表明小型Llama 8B模型虽然速度快,但缺乏深入的推理能力,无法始终如一地遵循复杂的逻辑链得出结论。
我们的诊断显示,线性V0系统存在数据提取不可靠和推理有缺陷的问题,尤其是在处理复杂、多问题的收据时。
最后,我们必须将此与我们的业务案例联系起来。最终审计决策的20%失败率(5个样本中有1个)意味着我们的系统将有高得令人无法接受的误报率和漏报率,导致重大财务损失,并抵消任何潜在的节省。
添加用于构建V1代理的工具
我们的V0系统是一个线性管道。第一步(提取)中的错误会级联到下游,污染第二步(审核)的输入,导致整个系统完全失败。为了构建一个更强大的系统,我们需要从简单的链式结构转向更智能、更具自主性的架构。
更强大的系统表现出类代理行为。它们不只是盲目地处理数据,还可以使用工具来卸载复杂任务并验证信息。通过给我们的代理配备计算器,我们可以指示它主动验证收据上的数学计算,而不是被动地提取信息。
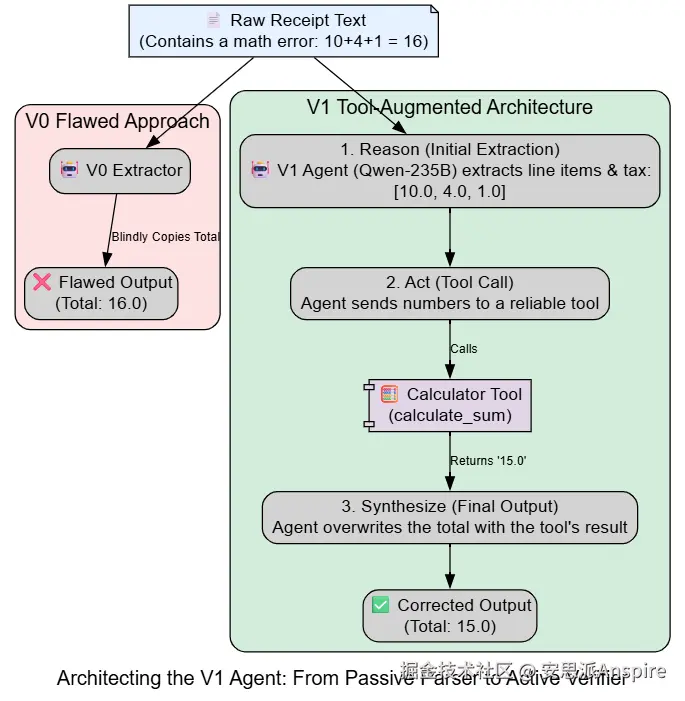
我们的V1系统将专门针对我们在V0中诊断出的故障进行设计。我们将升级到功能强大的Qwen-235B模型,最重要的是,我们将为提取器代理配备一个新工具:计算器。这将提取器从简单的解析器转变为主动验证器。
V1工具增强提取器架构(创建)
首先,让我们定义一下我们的工具。对于这个笔记本,一个简单的 Python 函数就足够了。在实际的生产系统中,这可能是对一个专用的、高度可靠的计算微服务的调用。
python
# 这是一个模拟函数,代表我们的计算器工具。
# 在实际系统中,这可能是对强大计算库或单独微服务的调用。
def calculate_sum(numbers: List[float]) -> float:
"""一个简单、可靠的工具,用于计算数字列表的总和。"""
# 我们打印到控制台,以便在执行期间使工具调用可见。
print(f"[工具调用]: 正在计算 {numbers} 的总和")
return sum(numbers)现在,我们将构建我们的v1_extract_details代理。核心变化在于系统提示。我们不再只是要求代理提取数据,而是给它一组多步骤的指令,这些指令
要求
它使用计算器工具来验证总数。
ini
async def v1_extract_details(image_path: Path, model: str = "Qwen/Qwen3-235B-A22B-Instruct-2507") -> ReceiptDetails:
"""V1提取器:使用函数调用模型来验证数学计算。
这模拟了与模型的多轮对话,其中模型决定使用工具。
"""
image_content = image_path.read_text()
# 系统提示被更新,以明确指示模型使用工具。
# 这是工具使用提示的关键部分。
system_prompt = (
"你是一位专业的收据处理助手。 "
"1. 从收据文本中提取所有细节,包括所有行项目和税费。\n"
"2. 重要提示:在确定总计之前,使用 `calculate_sum` 工具将行项目总计和税费相加。\n"
"3. 该工具的输出即为正确的总计。在最终回复中使用该结果。"
)
# 为简单起见,我们将模拟真实代理在循环中执行的工具使用逻辑。
# 实际的实现会使用 client.chat.completions.create(tools=...) 并检查响应中的 tool_calls。
# 步骤 1:对模型进行初始调用,以提取工具所需的组件。
initial_extraction_response = await client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "从以下收据中,提取所有单个行项目总计和税额。忽略列出的总计。"},
{"role": "user", "content": image_content}
],
response_model=ReceiptDetails # 我们仍然可以使用这个模式;模型只会填充它能填充的内容。
)
# 步骤2:使用提取的数字调用工具。
numbers_to_sum = [item.total for item in initial_extraction_response.items]
if initial_extraction_response.tax:
numbers_to_sum.append(initial_extraction_response.tax)
calculated_total = calculate_sum(numbers_to_sum)
# 步骤 3:创建最终的、修正后的对象。
# 我们相信工具的计算结果,而不是可能存在缺陷的 OCR 识别总数。
final_details = initial_extraction_response.model_copy()
final_details.total = round(calculated_total, 2)
return final_details我们基本上是在模拟**ReAct(推理、行动)**循环,这是真正使用工具的智能体将执行的循环。
-
**原因:**模型首先进行初始提取响应,以识别需要求和的数字(行项目总计和税金)。
-
**操作:**然后,我们使用这些数字调用calculate_sum工具。
-
**综合:**最后,我们创建final_details对象,用可靠工具的结果覆盖total。这确保最终提取的数据在数学上是一致的。
让我们在receipt_5.txt上测试这个新的、更智能的提取器,正是这个样本导致我们的V0系统失败。
python
# 让我们在之前失败的样本上测试 V1 提取器。
failed_path = IMAGE_DIR / "receipt_5.txt"
print(f"在 {failed_path.name} 上运行 V1 提取器...")
v1_extracted_details = await v1_extract_details(failed_path)
print("\nV1 提取的详细信息:")
print(v1_extracted_details)我们在有问题的收据上执行该函数并观察输出。
ini
####### 输出 #######
正在对 receipt_5.txt 运行 V1 提取器...
[工具调用]: 计算 总和[20.0, 1.6]
V1 提取的详细信息:
ReceiptDetails(
merchant='五金店',
location=Location(city='奥斯汀', state='TX'),
items=[LineItem(description='锤子', quantity=1.0, price=20.0, total=20.0)],
subtotal=None,
tax=1.6,
total=21.6,
handwritten_notes=['用于办公室维修', 'X 请勿使用此收据'],
)输出展示了V1代理的运行情况。工具调用日志证实,它正确识别了各项组成部分(20.00美元的商品总价和1.60美元的税费),并使用我们的calculate_sum工具得出了正确的最终总价21.60美元。它不再盲目地从收据文本中复制总价。
通过为我们的智能体配备一个简单的工具,我们已经彻底解决了V0系统中的关键提取故障。这展示了从被动解析转向主动的、工具驱动的验证的强大力量。
提取问题解决后,我们现在将注意力转向第二个主要故障点:推理缺陷。我们也需要让审计代理变得更智能。
用检索增强生成(RAG)增强我们的审计员
我们已经解决了提取问题,但我们的V0系统也遭遇了严重的推理故障。小模型自相矛盾,虽然正确识别了审计的原因,但却未能做出正确的最终决策。为了解决这个问题,我们需要给审计代理提供更多的上下文和指导。
标准大语言模型的推理仅基于其提示中的信息及其预训练知识。
我们不会仅仅在提示中给审计员列出一系列规则,而是会构建一个小型的模拟RAG系统。在做出决策之前,审计员将查询"政策文件"知识库,以检索与正在分析的收据相关的具体公司政策。这将其决策建立在外部真实来源的基础上,使其推理更加明确和可靠。
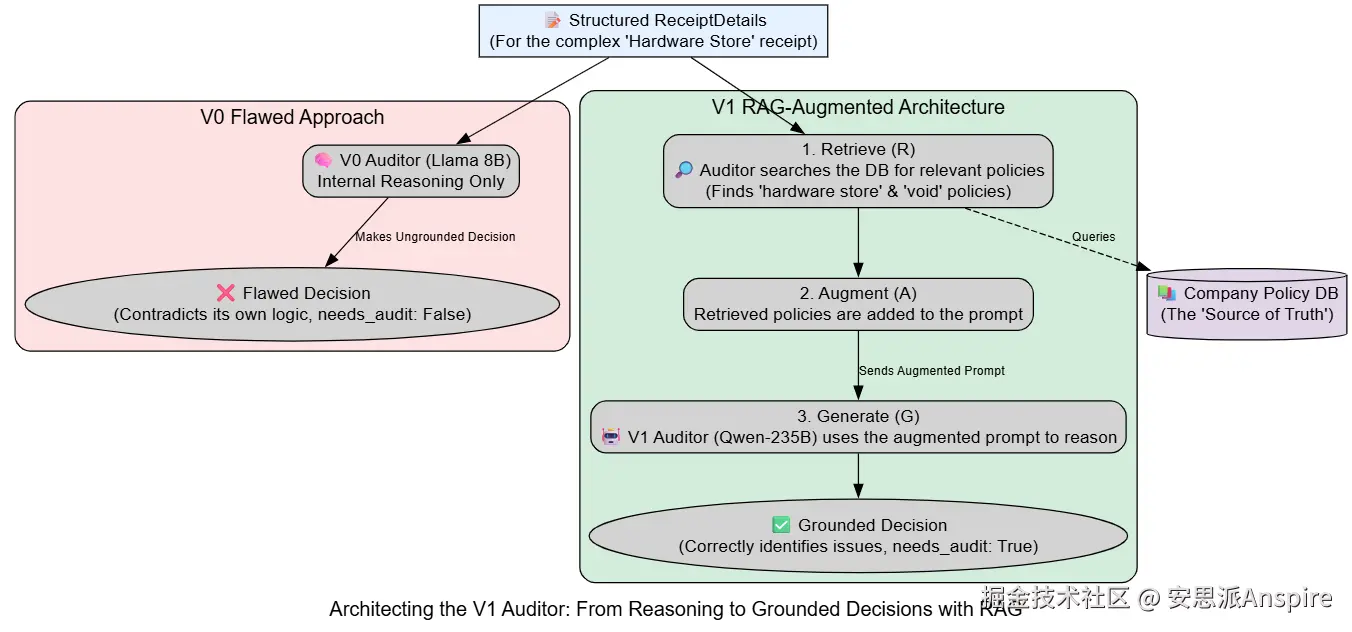
构建RAG知识库
首先,我们将创建我们的知识库。在实际的生产系统中,这将是一个复杂的向量数据库,如 ChromaDB 或 Pinecone,在其中政策文档被分块、嵌入并索引,以进行语义搜索。对于我们的笔记本来说,一个简单的模拟基于关键字检索的字典就足以演示核心概念。
makefile
# 在实际系统中,这将是一个向量数据库,如 ChromaDB 或 Pinecone。
# 我们将对查询和策略文档进行嵌入,以进行语义搜索。
# 对于我们的模拟,一个简单的关键字匹配字典就足以演示这个概念。
POLICY_VECTOR_DB = {
"办公用品": "政策 3.1:标准办公用品(如纸张、笔)的采购不被视为差旅费,需要审计。",
"五金店": "政策3.2:五金店的物品通常不属于差旅费,除非明确用于商务旅行期间的车辆维修。需要进行审计核实。",
"汽油": "政策1.1:商务旅行用车的燃油属于有效差旅费。",
"酒店": "政策1.2:商务旅行期间的住宿费用属于有效差旅费。",
"无效": "政策5.4:任何带有手写'X'或'VOID'字样的收据都应标记为待审计,因为该交易可能已被取消。"
}我们的POLICY_VECTOR_DB是我们的事实来源。每个键代表一个概念,值是公司的官方政策。
接下来,我们需要一个检索器函数来搜索这个知识库。我们的retrieve_relevant_policies函数将获取提取的ReceiptDetails,根据其内容形成查询,并执行简单的关键字搜索以查找匹配的策略。
python
def retrieve_relevant_policies(receipt_details: ReceiptDetails) -> List[str]:
"""模拟一个RAG检索器。根据关键词查找相关策略。"""
# 汇总收据中的所有文本以形成搜索查询。
content = receipt_details.merchant.lower()
for item in receipt_details.items:
content += " " + item.description.lower()
for note in receipt_details.handwritten_notes:
content += " " + note.lower()
print(f"[RAG Retriever]: Searching for policies related to: '{content[:50]}...'")
found_policies = []
# 针对我们的模拟DB进行简单的关键词搜索。
for keyword, policy in POLICY_VECTOR_DB.items():
if keyword in content:
found_policies.append(policy)
print(f"[RAG Retriever]: 找到与 '{keyword}' 相关的策略")
return found_policiesV1 RAG增强审计员
有了我们的检索器,现在我们可以构建我们的v1_decide_audit代理了。这个代理将遵循RAG模式的三个核心步骤:
-
**检索:**它将首先调用retrieve_relevant_policies来获取上下文信息。
-
**增强:**然后它会将检索到的上下文直接注入到其系统提示中。
-
**生成:**最后,它将使用这个增强的提示来生成最终的、具有上下文感知能力的审计决策。
async def v1_decide_audit(receipt_details: ReceiptDetails, model: str = "Qwen/Qwen3-235B-A22B-Instruct-2507") -> AuditDecision: """V1审计员:在做出决定前检索上下文。"""
ini# 步骤1:检索相关上下文(RAG中的'R')。 retrieved_context = retrieve_relevant_policies(receipt_details) context_str = "\n".join(retrieved_context) # 步骤2:用检索到的上下文增强提示(RAG中的'A')。 system_prompt = ( "你是一位专业的费用审计员。请根据提供的政策做出最终决定。规则:1. NOT_TRAVEL_RELATED:如果费用与旅行无关,则为真。2. AMOUNT_OVER_LIMIT:如果总金额超过75美元,则为真。3. MATH_ERROR:此问题在提取过程中处理;除非另有说明,否则假定为假。4. HANDWRITTEN_X:如果有手写的"X",则为真。 "如果有任何一项为真,则需要进行审计。请明确依据所提供的政策进行推理。" ) user_prompt = f""" 相关政策: {context_str} 收据详情: {receipt_details.model_dump_json(indent=2)} """ # 步骤3:生成最终响应(RAG中的'G')。 response = await client.chat.completions.create( model=model, messages=[ {"role": "system", "content": system_prompt}, {"role": "user", "content": user_prompt} ], response_model=AuditDecision ) 返回 response
这里的关键在于用户提示的结构。现在,我们不再仅仅发送收据详情,而是提供了一个专门的相关政策部分。指令"明确依据所提供的政策进行推理"促使强大的Qwen模型以其输出为基础,使其推理过程透明且可直接追溯到我们的知识库。
运行完整的V1管道
让我们将新的工具使用提取器和RAG增强审核器整合到一个完整的V1管道中,并在我们的对手receipt_5.txt上进行测试。
python
async def run_v1_pipeline(image_path: Path):
"""运行完整的V1代理管道。"""
extracted_details = await v1_extract_details(image_path)
audit_decision = await v1_decide_audit(extracted_details)
return extracted_details, audit_decision
print(f"在 {failed_path.name} 上运行V1管道...")
_, v1_final_audit = await run_v1_pipeline(failed_path)
print("\nV1最终审计决策:")
print(v1_final_audit)我们执行完整的V1流程,并检查最终的审计决定。
ini
######## 输出 #########
正在对 receipt_5.txt 运行 V1 管道...
[工具调用]:计算 总和[20.0, 1.6]
[RAG 检索器]:查找与以下内容相关的策略:'五金店锤子用于办公室维修 x 请勿使用...'
[RAG 检索器]:找到与'五金店'相关的策略
[RAG 检索器]:找到与'无效'相关的策略
V1 最终审计决定:
AuditDecision(
not_travel_related=True,
amount_over_limit=False,
math_error=False,
handwritten_x=True,
reasoning='需要审计。根据政策3.2,五金店采购需要进行审计以核实业务用途。此外,根据政策5.4,手写的X'需要进行审计。',
needs_audit=True,
)日志显示我们的V1代理运行正常。
-
使用工具的提取器正确计算了总数(工具调用:计算20.0, 1.6的总和)。
-
RAG检索器正确识别并获取了两项相关政策(五金店的政策3.2和撤销"X"的政策5.4)。
-
审计代理随后利用检索到的上下文生成了一个高质量、有依据的推理字符串,最重要的是,得出了正确的最终决策(needs_audit=True)。
我们的V1系统似乎已经解决了V0中存在的提取
和
推理失败问题。但这个更复杂、更强大的系统是否引入了新问题,比如成本增加或延迟?为了弄清楚,我们必须重新运行评估,这次要使用更高级的测试套件。