还记得那个曾经风光无两的 TensorFlow 吗?
曾经,它是深度学习的代名词;而今天,它却被 PyTorch 全面取代。
与此同时,DeepSeek-R1论文登上Nature封面,Nature 还盛赞 DeepSeek-R1 的这种开放模式。

有人感叹"一代王朝落幕",也有人说"新的时代已经来临"。那么,TensorFlow 的退场究竟意味着什么?这背后,其实折射出整个开源世界的范式转移。
开源全景2.0
蚂蚁集团王旭和团队近期发布了 开源全景图 2.0,用数据给我们揭示了开源世界的流变。

和一年前的 1.0 相比,几百个项目已经"出局",很多耳熟能详的名字------Theano、TensorFlow、Caffe------都成为历史。
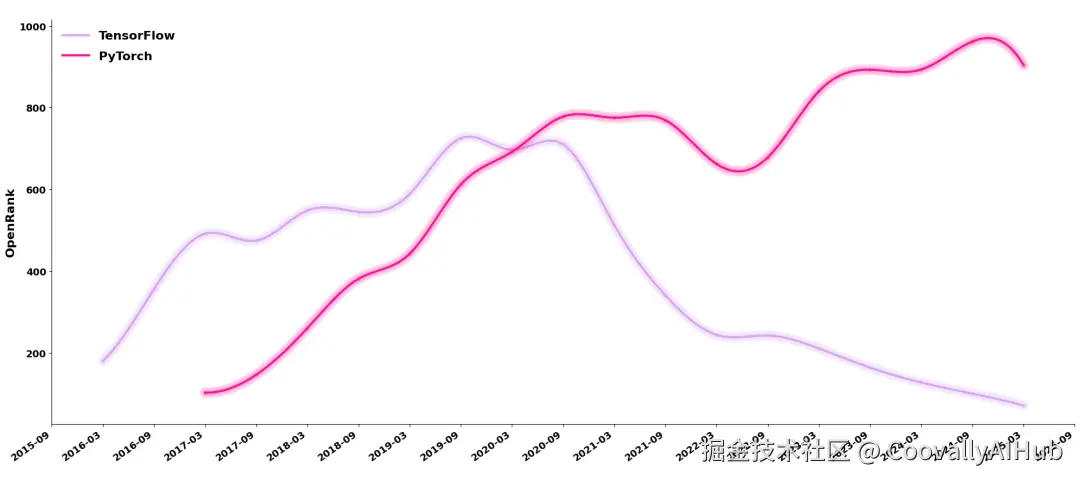
其中最引人注目的当属是 TensorFlow 的退场,这个在深度学习早期辉煌万分的平台,然而,仅仅几年后,其地位就被 PyTorch 蚕食并最终取代,从 TensorFlow 与 PyTorch 的社区活跃度就可以看出,一个在走上坡路一个已经跌至谷底。
2.0已经完全进入智能体的时代,包括词云图都是以LLM、Agent、Data为核心围绕。

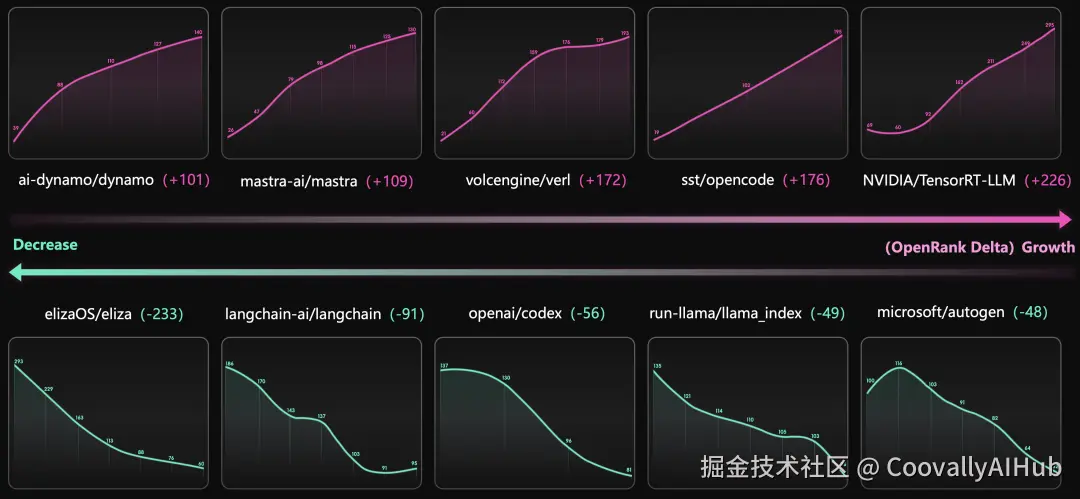
从全景图也反映出,我们真正进入了AI纪元的大爆发时代,算上被淘汰的项目,整个大模型生态的「中位年龄」只有 30 个月,平均寿命不足三年,其中 12 个甚至是 2025 年的新面孔。也就是说,几乎每个季度都能看到新人登场、旧人退场。
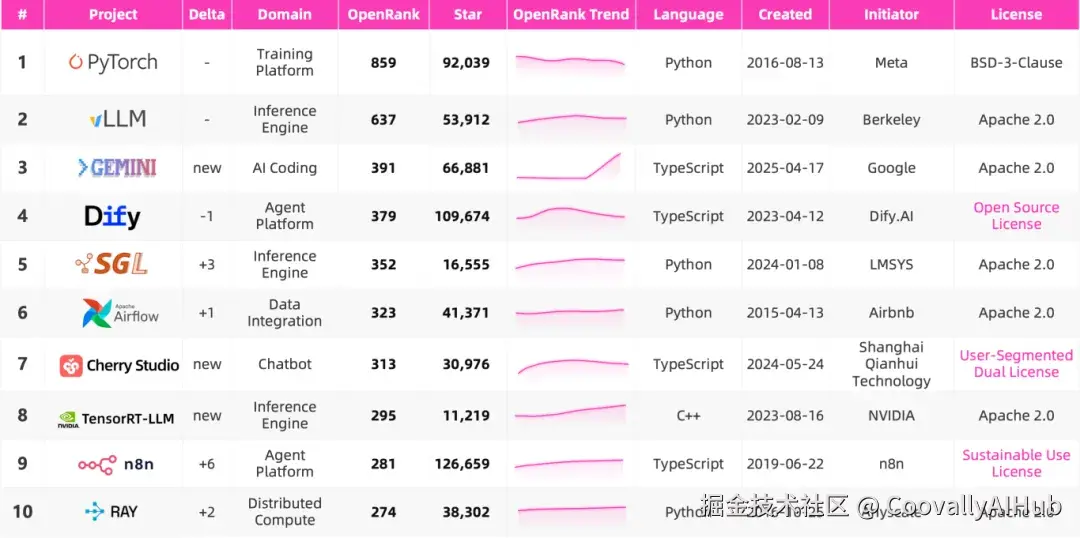
头部的这 10 个项目,代表了当下大模型开发生态里最活跃、最具代表性的社区力量。它们几乎覆盖了模型生态的完整链路。
图上展示的是他们从 2 月到 8 月的 OpenRank 绝对值变化。
如何定义这个时代的开源?
熟悉开源许可证历史的朋友,在看到最新全景图里不少顶尖项目的 License 时,或许已经心生警觉。
是的,虽然多数大模型开发生态仍沿用 Apache 2.0 或 MIT 这样宽松的许可,但也有不少项目选择了"特别版本":
- Dify 的 Open Source License
基于 Apache 2.0 修改,新增两条限制:
- 未经许可,不能在多租户环境中运营。
- 使用前端时,不得移除或修改 LOGO 与版权信息。
- n8n 的 Sustainable Use License
源于 Fair-code 主张,允许免费使用、修改、分发,但附带限制:
- 仅限企业内部或非商业、个人用途。
- 二次分发必须免费且非商业。
- 不能修改软件的许可、版权或作者信息。
- Cherry Studio 的 User-Segmented Dual Licensing
根据用户规模分级:
- 个人或 ≤10 人组织,可用 AGPLv3,修改分发必须同样开源。
- 超过 10 人的组织,则需商业授权。
这些条款大多出于 保护商业利益 的考虑。也因此,它们难以获得 OSI(开放源代码促进会)的正式认可,从"开源原教旨主义"的角度来看,甚至未必算得上真正的开源。
模糊边界:开源还是不算开源?
在大模型浪潮下,"开源"的定义愈发模糊:
- 模型层面: 开源大模型与开放权重大模型之间,始终争议不断。
- 软件层面: 传统许可证之外,越来越多团队选择自拟协议 (Open-Source License Agreement) ,在"开放"与"控制"之间划出灰色地带。
这些新式协议往往赋予许可方更多干预权:
传统协议下,一旦开源便不可撤销;
新协议中,常常取消这一限制,方便后续商业操作。
有的项目甚至按用户规模设限:月活超出某阈值,必须另行付费授权。
Dify 采用的BSL(Business Source License)变体,就是典型案例:代码先开放,几年后再切换为宽松协议,以保护商业利益。
n8n 强调"防止大厂白嫖",Cherry Studio 明确规定大规模商用需要额外授权。
另一层模糊来自 GitHub 本身。
许多项目------例如 Cursor、Claude-Code------甚至连源代码都闭源,却依然在 GitHub 上火爆异常。
这些仓库 star 数一骑绝尘,但它们的真正功能其实只是厂商的用户反馈与社区运营窗口,而非真正的开源项目。久而久之,用户也常常产生"它们属于开源社区"的错觉。
技术趋势的影响
从全景图 2.0 的数据来看,不同领域的热度正在分化:
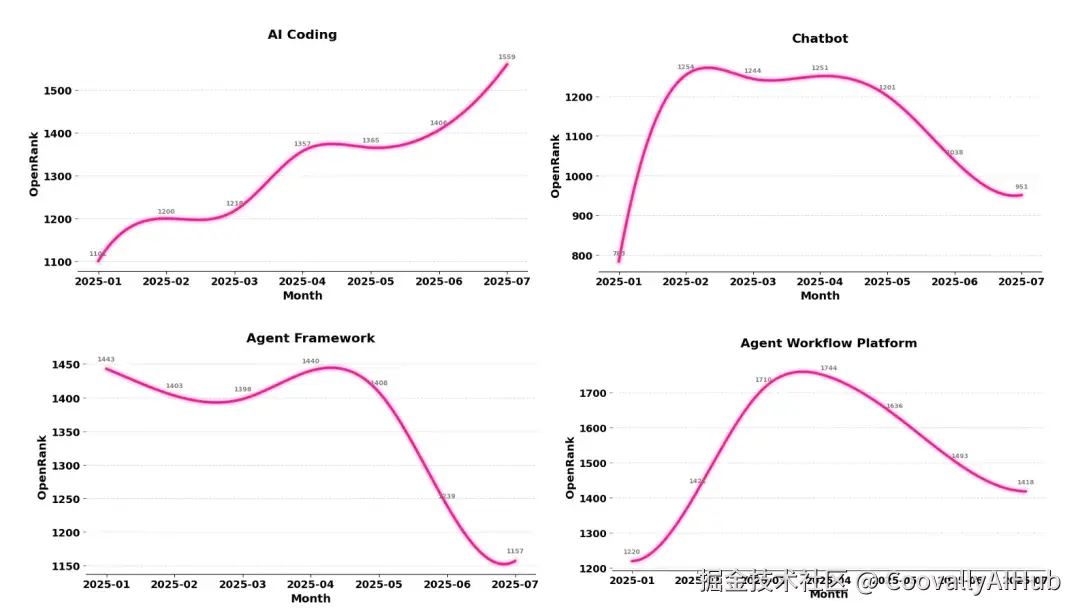
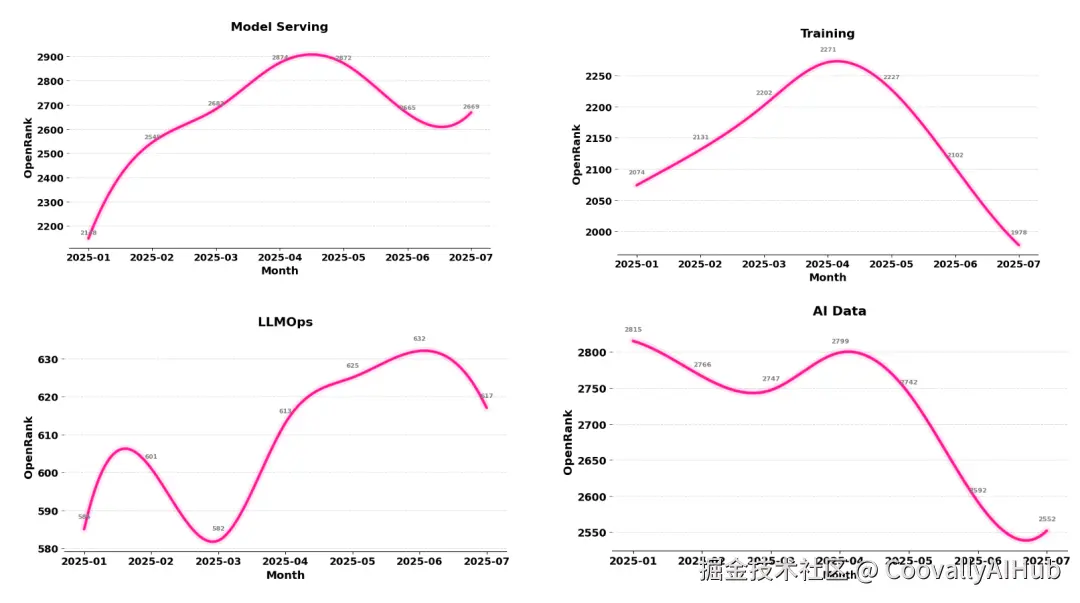
增长显著: AI Coding、Model Serving、LLMOps。其中,AI Coding 在过去两个月的增长斜率依然陡峭,进一步验证了 AI 研发提效 是 2025 年最落地的应用场景。
下滑明显: Agent Framework 与 AI Data。前者的衰退与 LangChain、LlamaIndex、AutoGen 等项目在社区投入的下降密切相关;后者则在向量存储、数据集成、数据治理等维度中呈现缓慢回落趋势。
这背后折射出一个事实:当"开源"越来越与商业挂钩时,它所承载的理想主义色彩,正在被现实重塑。
生态全景
在开源生态之外,大模型的更新同样迅速。官方还梳理了 2025 年 1 月至今国内外主流厂商的大模型发布时间线,覆盖开放参数与闭源模型,并标注了参数规模、模态类型等信息,以便直观了解各家竞争重点。
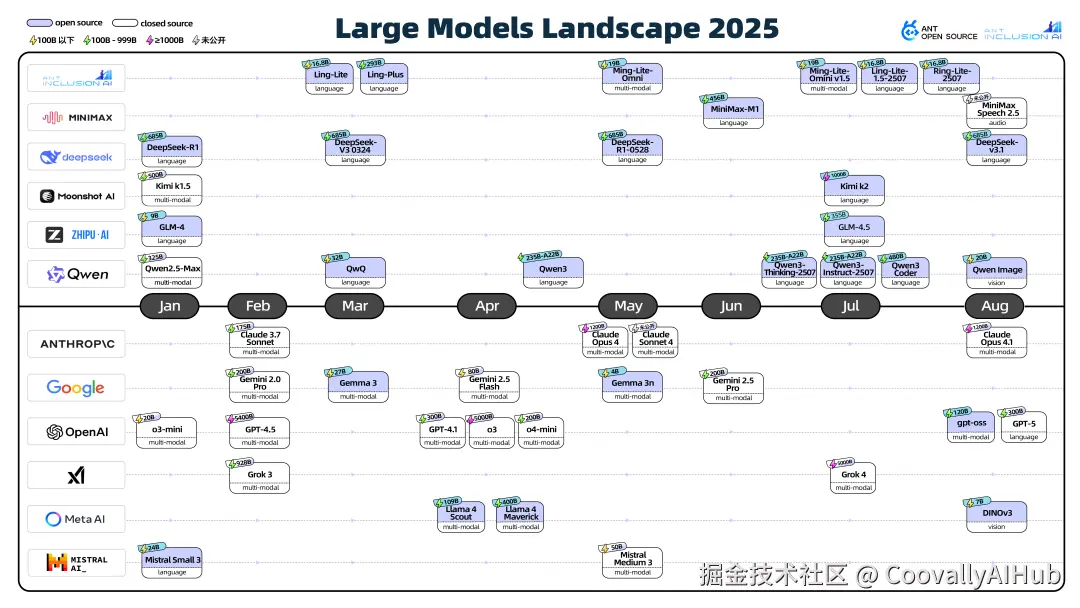
几个观察点:
- 中美开源与闭源分化
中国开源大模型百花齐放,而国外顶尖厂商依旧闭源。曾经开源的 Meta 也趋于谨慎:7 月 31 日扎克伯格在公开信中表示"我们会更谨慎地选择开源什么"。Llama 系列今年影响力下降,Llama 4 发布时甚至引发"效果差""造假"争议。
- MoE 架构与超大参数
DeepSeek、Qwen、Kimi 等旗舰模型采用 Mixture of Experts (MoE) 架构,实现"稀疏激活",让万亿参数模型在推理时只用部分参数,从而兼顾性能与效率。
- Reasoning 能力提升
DeepSeek R1 结合强化学习后训与大规模预训练,显著增强自动化推理与复杂决策能力。Qwen、Claude、Gemini 等也在尝试 混合推理模式,用户可在"快思考"和"深思考"之间切换。
- 多模态逐渐主流
多模态模型以语言、图像、语音交互为主,垂直视觉或语音模型也不断涌现。语音工具链如 Pipecat、LiveKit Agents、CosyVoice 等逐渐完善。尽管 OpenAI 的 Sora 展示了视频模态潜力,但视频和 AGI 的真正落地仍需时间。
总体来看,当下的大模型开源生态呈现出两极分化:一方面,核心基础设施和工具链仍以开源驱动创新 ;另一方面,带有限制条款的"新式开源"或闭源项目不断涌现,使得"真正的开源"定义在实践中面临挑战。未来,开源项目能否保持开放性和社区活跃度,将直接影响整个大模型生态的可持续发展。