本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。
刚刚逛 GitHub 的时候,发现了一个超火的开源项目。
RAGFlow 这个开源 RAG 引擎能让你的知识库活起来,现在已经获得了 60K 的 Star。
它是为个人或企业准备的 RAG 工作流神器。
RAG (检索增强生成) 技术可以让 AI 大模型生成答案之前访问外部知识库,从而提高答案的相关性、准确性和时效性,并减少"幻觉"等问题。
公司里海量的文档、合同、报告堆在网盘或服务器里,想找点关键信息,要么大海捞针,要么问同事也说不清具体在哪份文件的哪一页。
RAGFlow 就是为了解决这些问题而生的。
01 项目简介
RAGFlow 是一个开源的、强大的 RAG 引擎。
简单来说,它能让 AI 大模型变得更懂你公司的内部资料,回答问题时不再是凭空想象,而是基于你上传的真实文件,并且能「有理有据」地告诉你答案是从哪来的。
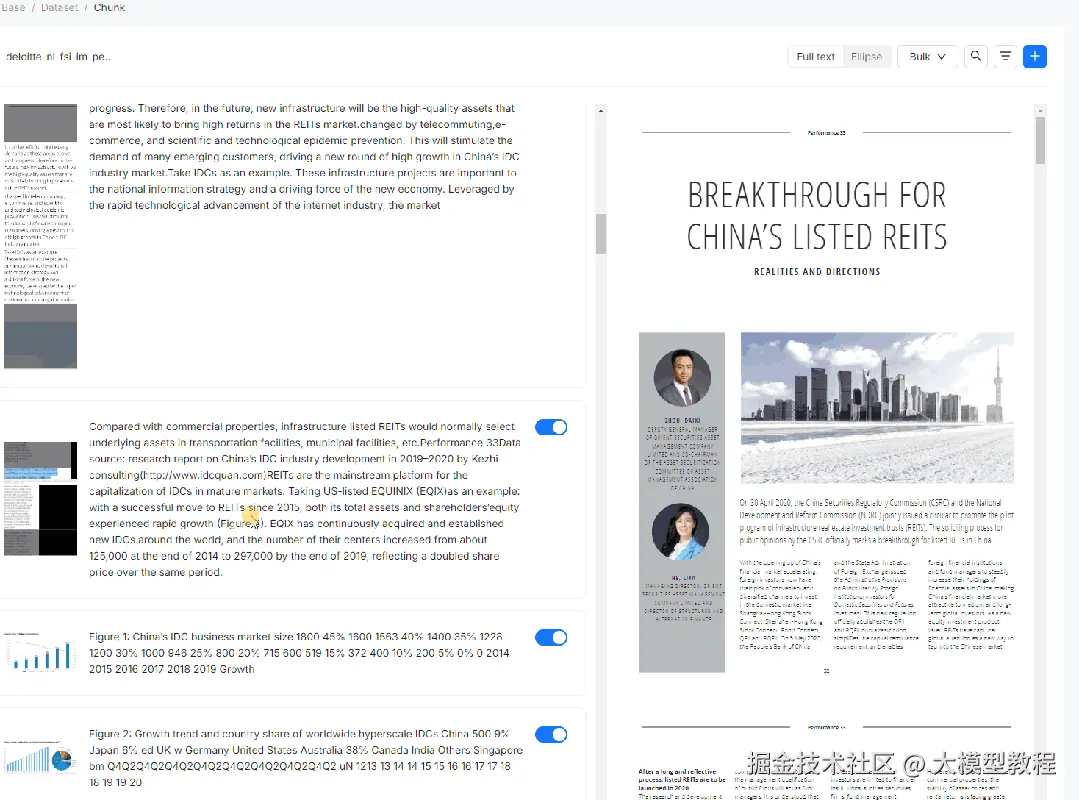
输出准确答案的同时提供关键信息所在的原文,并且支持你点击溯源,直接定位到原始文档的具体位置。
这大大降低了 AI 瞎编乱造问题,让答案更可信。
① 深度理解复杂文档
不只是文本,它能读懂各种格式:Word, PPT, Excel, PDF(包括扫描件)、图片、网页、TXT等。
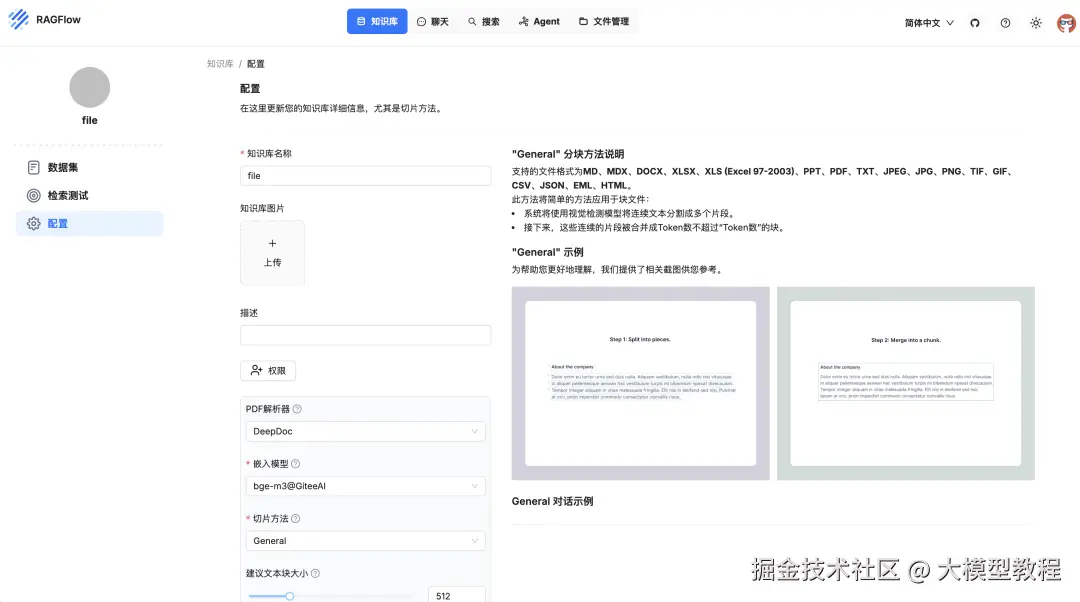
市面上常见的文档格式它都能处理。
就算你上传的是扫描的合同、带表格的报告,它也能努力从中提取有用的信息。这得益于它的「深度文档理解」能力。
而且它能把大文档切成更小的、有逻辑的「知识块」。更棒的是,这个过程你还能看到甚至手动调整,确保切分得合理,让后续的问答更精准。
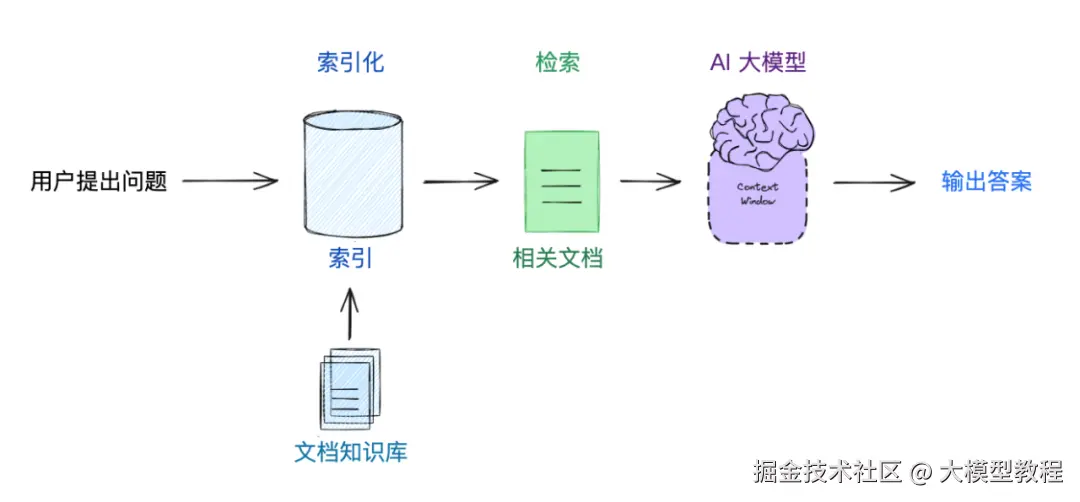
下面这个图,就是 RAGFlow 整个工作流程。
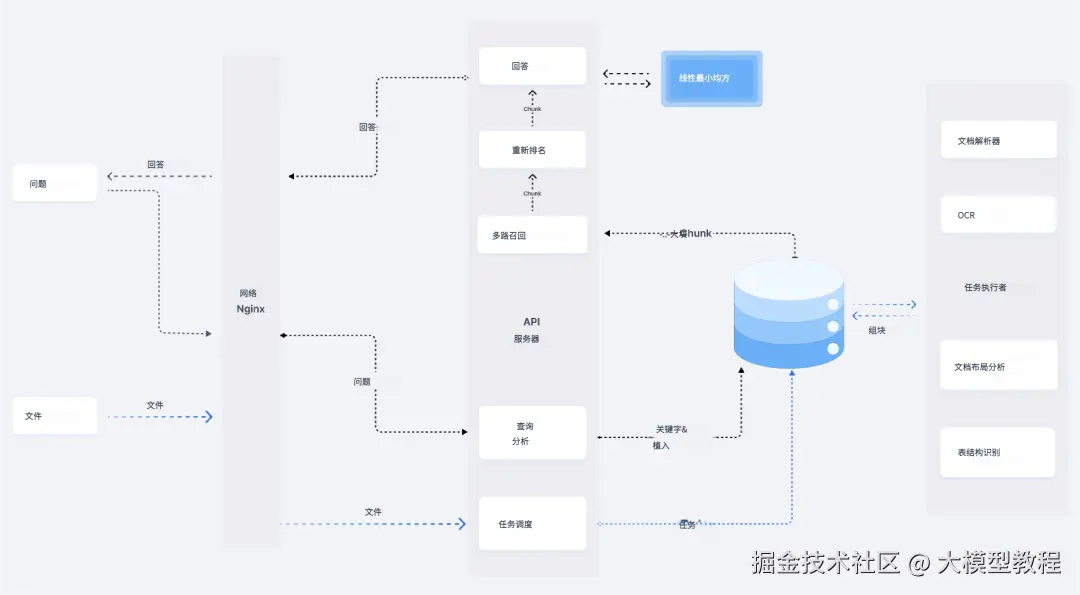
② RAG 工作流
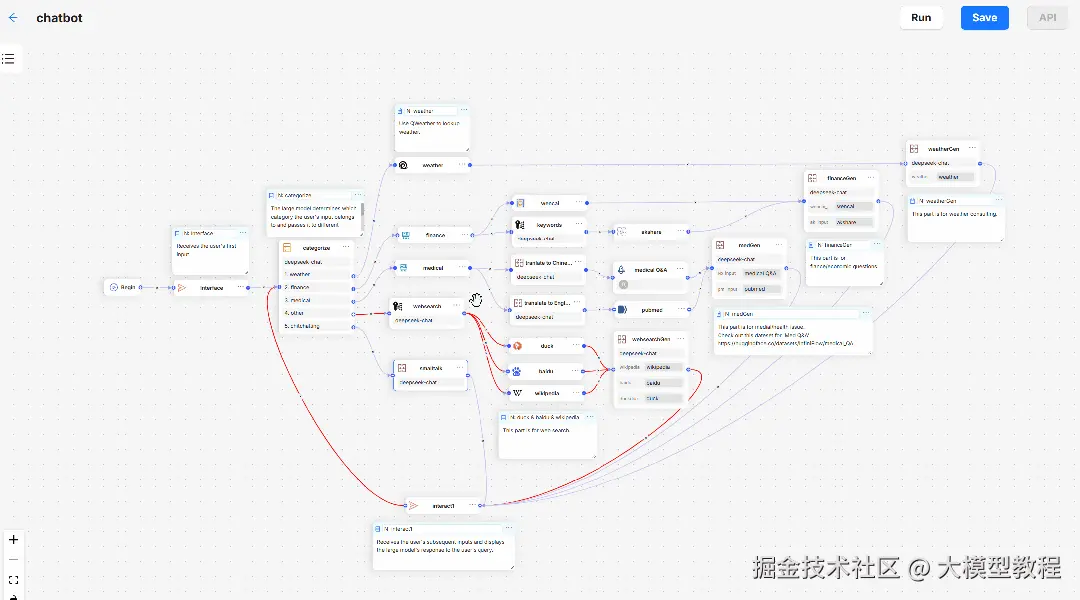
看上面这个图,RAGFlow 提供了一套几乎「全自动」的 RAG 工作流程,从个人使用到大型企业都能支持。
你可以自由选择搭配不同的大语言模型(比如 OpenAI GPT-4o, 百度文心一言,火山方舟,DeepSeek,百川等)和向量模型。
它经过了优化,即使你的知识库非常大(无限上下"),也能快速找到关键信息。
02 如何部署
RAGFlow 推荐使用 Docker 来部署,对硬件要求不算特别高:
CPU:至少 4 核、内存:至少 16 GB、硬盘:至少 50 GB、软件:Docker (>=24.0.0) 和 Docker Compose (>= v2.26.1)
部署步骤在 README 里写得很清楚:
① 确保系统设置:
调整一个叫 vm.max_map_count 的系统参数,不小于 262144:。
② 克隆代码:
bash
git clone https://github.com/infiniflow/ragflow.git③ 一键启动:
进入 docker 目录,运行 docker compose -f docker-compose-CN.yml up -d 命令。
它会自动下载镜像并启动所有需要的服务(包括数据库、向量库等)。
④ 等待启动完成:
用 docker logs 命令查看日志,看到服务器成功启动的提示。

⑤ 登录配置:
在浏览器访问你的服务器 IP,首次登录后,需要在配置文件里填入你选择的大模型(如 OpenAI)的 API Key。
⑥ 开用:上传文档,开始智能问答吧。
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。