近日,计算机视觉顶级会议ICCV 2025论文录用结果公布。本次会议共收到11239篇有效投稿,最终录用2699篇,录用率为24%。中国科学技术大学DSAI Lab团队共有8篇论文被接收,研究成果覆盖三维场景理解、点云处理、恶劣环境感知、跨模态配准等多个前沿方向,展现了团队在泛化场景感知技术方面的深厚积累。
本文将为大家介绍其中5篇,涵盖了三维开集分割、少样本点云分割、恶劣环境语义分割与自适应配准网络等方向。
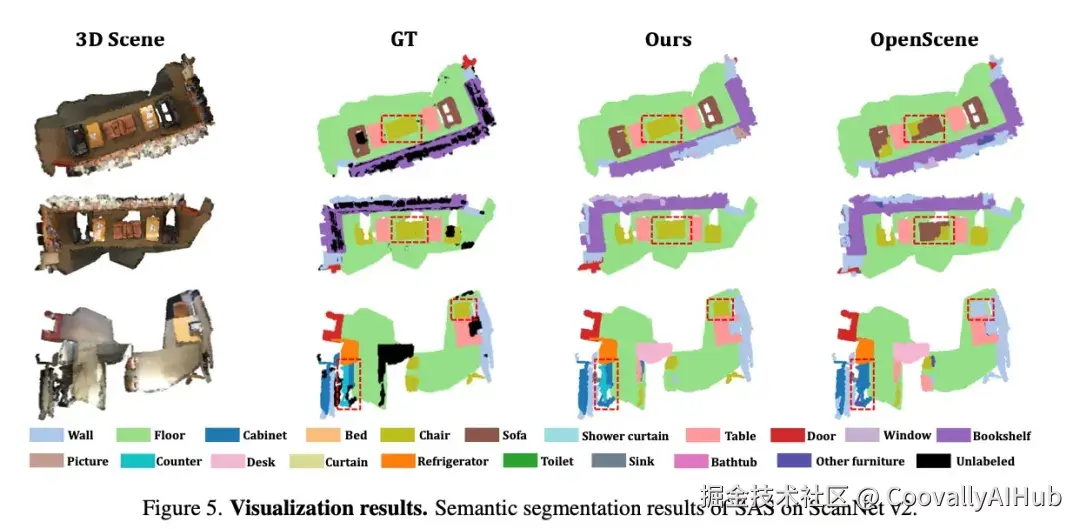
论文一:SAS------融合二维先验的开放词汇三维场景分割
论文标题:
SAS: Segment Any 3D Scene with Integrated 2D Priors
论文 链接 :
- 摘要
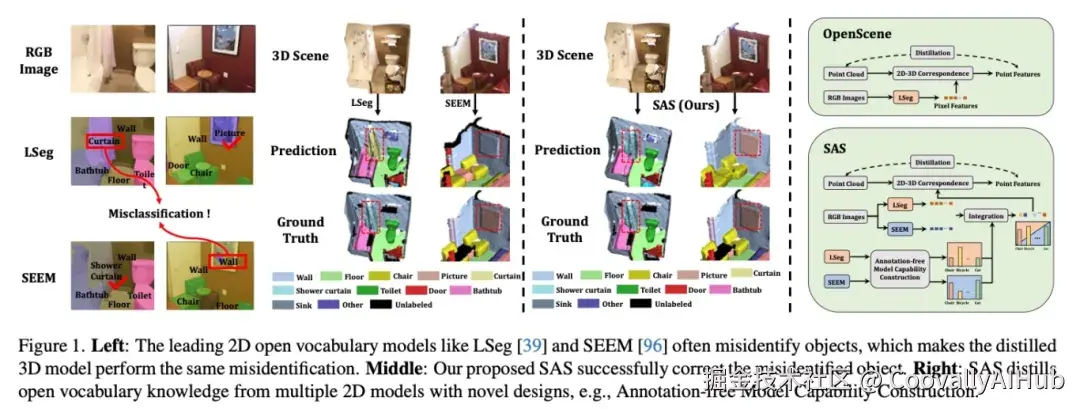
三维模型的开放词汇识别能力日益受到重视,因为传统方法使用固定类别训练的模型难以识别复杂动态三维场景中的未知物体。本文提出了一种简单而有效的方法SAS,通过整合多个二维模型的开放词汇能力并将其迁移至三维领域。具体而言,我们首先提出基于文本的模型对齐方法,以文本为桥梁将不同二维模型映射到同一嵌入空间。随后,我们提出免标注的模型能力构建方案,利用扩散模型显式量化二维模型对不同类别的识别能力。在此基础上,通过构建的模型能力指导融合来自不同二维模型的点云特征。最后,通过特征蒸馏将整合后的二维开放词汇能力迁移至三维领域。SAS在多个数据集(包括ScanNet v2、Matterport3D和nuScenes)上大幅优于现有方法,其泛化能力在下游任务(如高斯分割和实例分割)中得到进一步验证。
论文二:天气感知的恶劣环境语义分割
****
论文标题:
Exploring Weather-aware Aggregation and Adaptation for Semantic Segmentation under Adverse Conditions
- 摘要
在恶劣环境下进行语义分割对于实现可靠的视觉感知至关重要。然而,此类极端天气场景常常伴随着低对比度和可见度下降等图像失真问题,导致传统分割模型的性能大幅下降。此外,这类环境下标注数据的稀缺性也使得直接训练适应性强的模型变得十分困难。为此,研究者提出了无监督域适应(Unsupervised Domain Adaptation, UDA)方法,旨在将来自标注齐全的源域(正常天气)的知识迁移到无标注的目标域(恶劣天气)。然而,现有方法在实际应用中仍面临诸多挑战,主要包括缺乏天气感知能力以及特征异质性问题。许多模型无法充分考虑不同天气条件所呈现出的独特特征,同时源域与目标域之间存在显著的特征分布差异,进一步加剧了迁移学习的难度。为了解决上述问题,我们提出了一种新颖的天气感知聚合与适应网络,充分利用天气特征知识,实现不同天气条件下的特征同质化,从而增强场景感知能力。具体而言,我们引入了幅值提示聚合机制,从傅里叶频域中提取与天气变化密切相关的关键信息,以捕捉不同天气下的典型特征。同时,我们设计了天气异质性适应模块,用于缓解不同天气条件间的跨域特征差异,实现多样环境下的特征对齐与统一。在多个具有挑战性的基准数据集上进行的大量实验结果表明,本方法在恶劣天气条件下的语义分割任务中均取得了稳定且显著的性能提升。
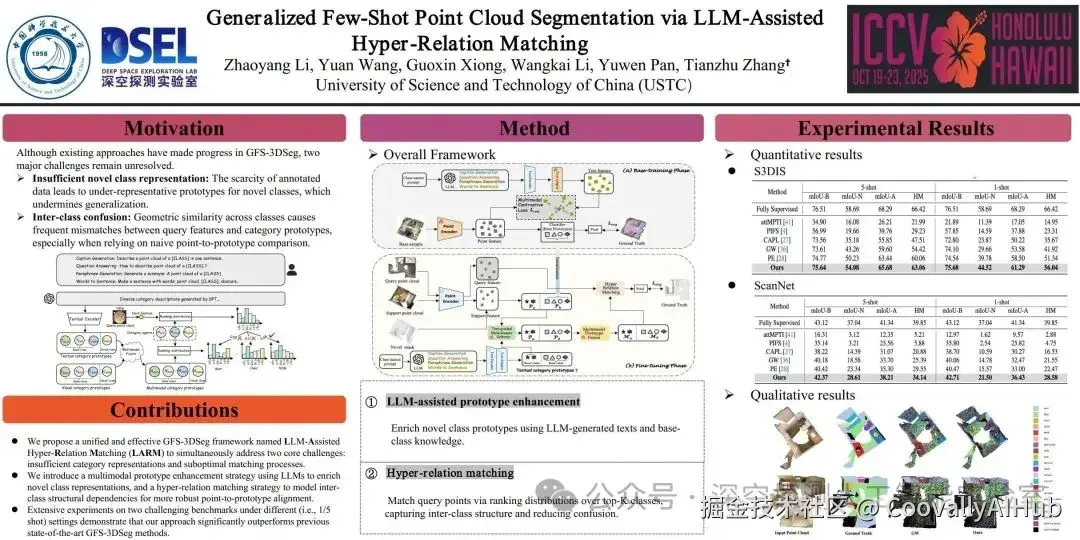
论文三:LARM------大模型辅助的少样本点云分割
论文标题:
Generalized Few-Shot Point Cloud Segmentation via LLM-Assisted Hyper-Relation Matching
- 摘要
可泛化少样本点云分割(Generalized Few-Shot Point Cloud Segmentation, GFS-3DSeg)任务旨在仅有少量类别标注样本的条件下,同时对点云中的基础类别和新类别进行分割,突破传统少样本方法仅限于新类别的限制。然而,现有方法在泛化到新类别时存在显著性能瓶颈,主要源于两个核心挑战:其一,新类别样本稀缺导致原型特征不具代表性,难以支撑鲁棒的分类;其二,点云中类间形状相似性强,在匹配过程中容易发生跨类混淆。这些挑战使得传统的原型匹配方法在GFS-3DSeg设定下效果不佳。针对上述问题,本文提出一个统一的解决方案------LLM辅助的超关系匹配框架(LLM-Assisted Hyper-Relation Matching, LARM),同时优化原型表征与匹配策略,显著提升跨类别泛化能力。具体而言,LARM在表征阶段引入大语言模型辅助模块,通过LLM生成多样化的类别文本描述,结合CLIP获得语义特征,与视觉特征进行多模态融合,从而构建更鲁棒的新类别原型,并通过"文本引导的元特征选择"机制借助基础类隐含模式进一步增强表示力。在匹配阶段,LARM提出超关系匹配策略,用点与多类别原型之间的排序分布来替代传统的点对原型一一比较,建模类别间结构关系,从而显著降低匹配过程对类间形态相似的敏感性。在S3DIS与ScanNet等多个跨域少样本点云分割基准上,LARM均取得优于现有方法的表现,在新类别上的提升尤为显著,验证了所提框架在特征泛化与匹配稳健性方面的有效性。
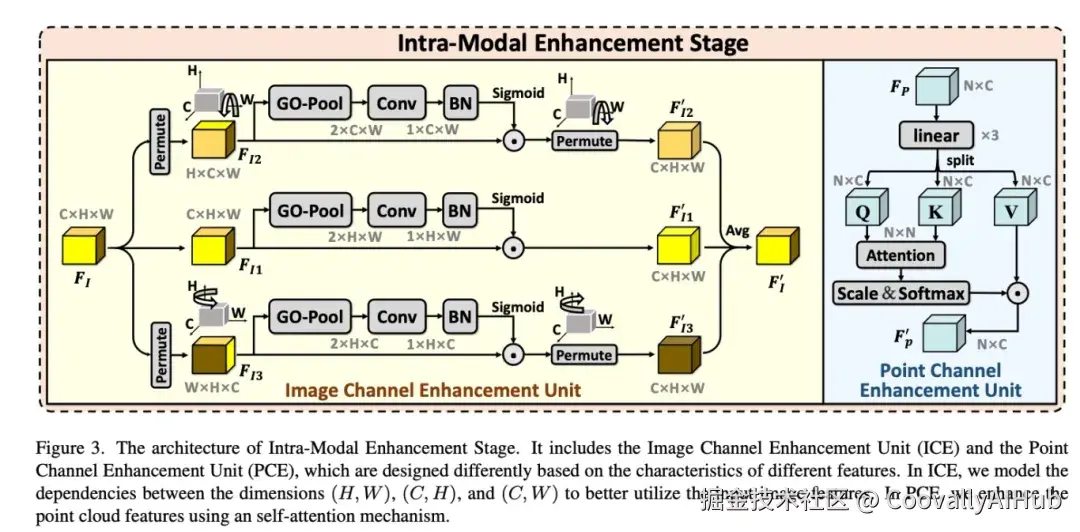
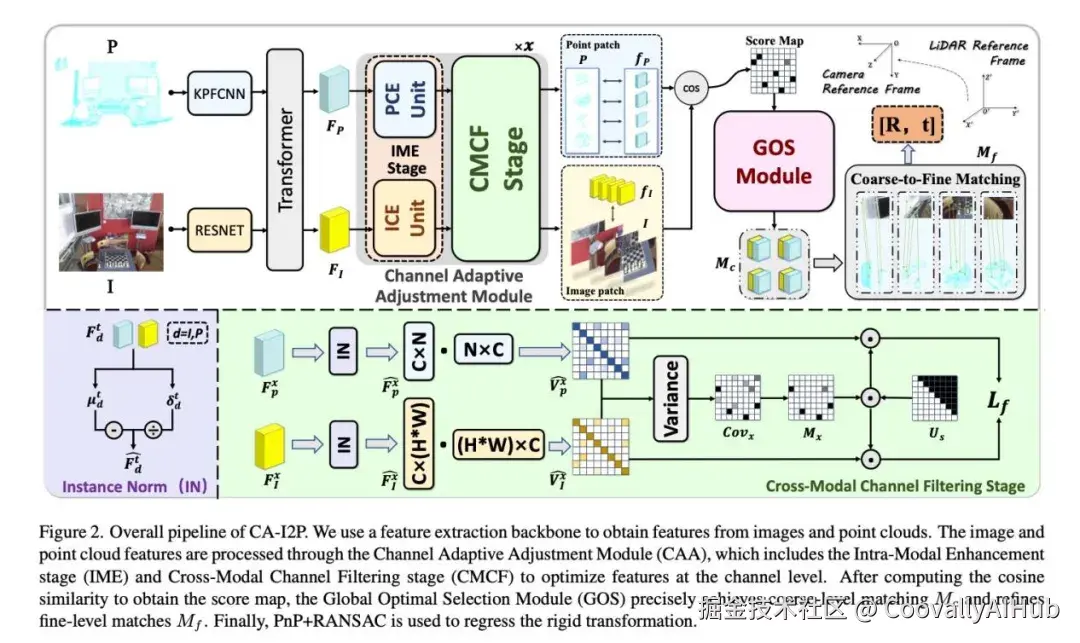
论文四:CA-I2P:具有全局最优选择的通道自适应配准网络
****
论文标题:
CA-I2P: Channel-Adaptive Registration Network with Global Optimal Selection
论文 链接 :
- 摘要
图像与点云配准旨在确定从点云到相机坐标系的刚性变换,涉及图像和点云的跨模态匹配,随后通过姿态估计器计算旋转和平移矩阵。这种配准对于3D重建、SLAM以及视觉定位等任务至关重要。然而,图像是密集的2D网格,而点云是稀疏且不规则的3D数据,2D编码器得到的图像特征与3D编码器得到的点云特征存在显著的域差异,而这种域差异在通道维度如何缩减是跨模态配准领域尚未解决的挑战。在本文中,我们提出了具有全局最优选择的通道自适应配准网络CA-I2P,旨在在模态内和模态间对通道维度的图像点云特征进行增强过滤。具体来说,我们针对两个关键问题进行了创新设计:1)对图像和点云在通道层面进行增强筛选,提升对于匹配区域的表征能力 和 2)全局优化图像点云选取过程,减小跨模态多对一的错误对应。针对特征增强问题,我们设计了通道自适应调节模块(Channel Adaptive Adjustment Module, CAA),在模态内通过差异化设计增强图像和点云特征的通道表达,在模态间基于协方差掩蔽融合原始与增强特征,以同时提升匹配性与保持特征独立性。针对选取优化问题,我们提出了全局最优选择模块(Global Optimal Selection Module, GOS),以全局视角引入最优传输机制替代原先基于余弦相似度的 Top-k 匹配策略,为每个点分配伪标签进行在线优化,从而有效缓解多对一错误匹配,提升图像点云配准的准确性与鲁棒性。在两个数据集的实验结果表明,我们的方法有效提升了图像与点云的配准精度和鲁棒性,并具有良好的泛化能力。

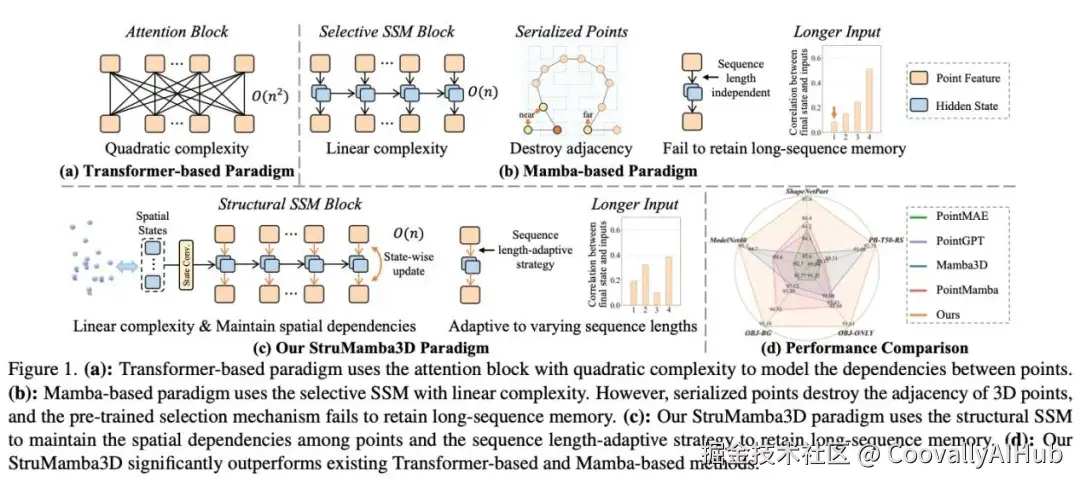
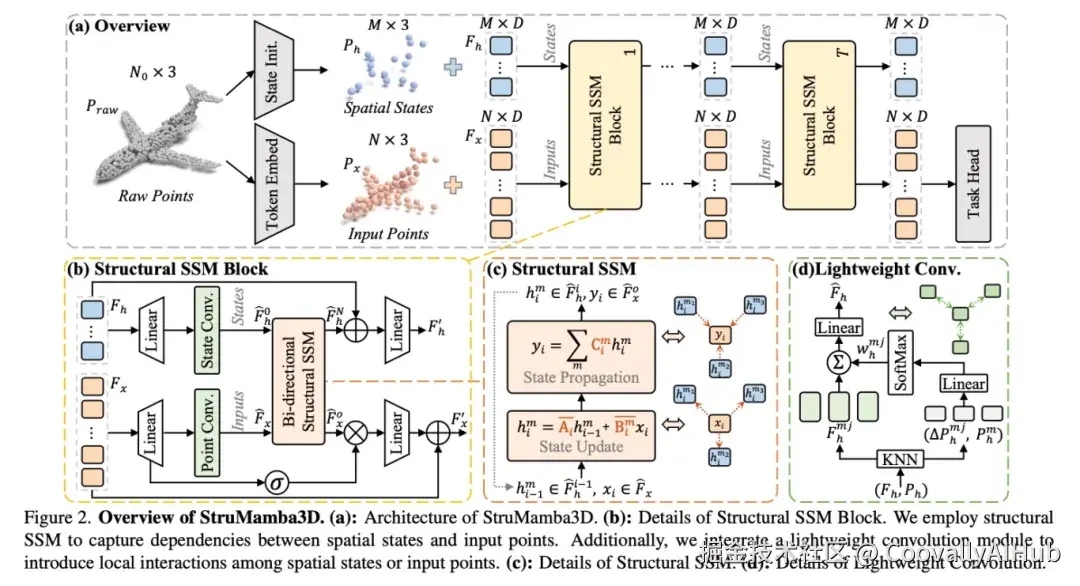
论文五:StruMamba3D------结构保持的自监督点云预训练框架
论文标题:
StruMamba3D: Exploring Structural Mamba for Self-supervised Point Cloud Representation Learning
论文 链接 :
- 摘要
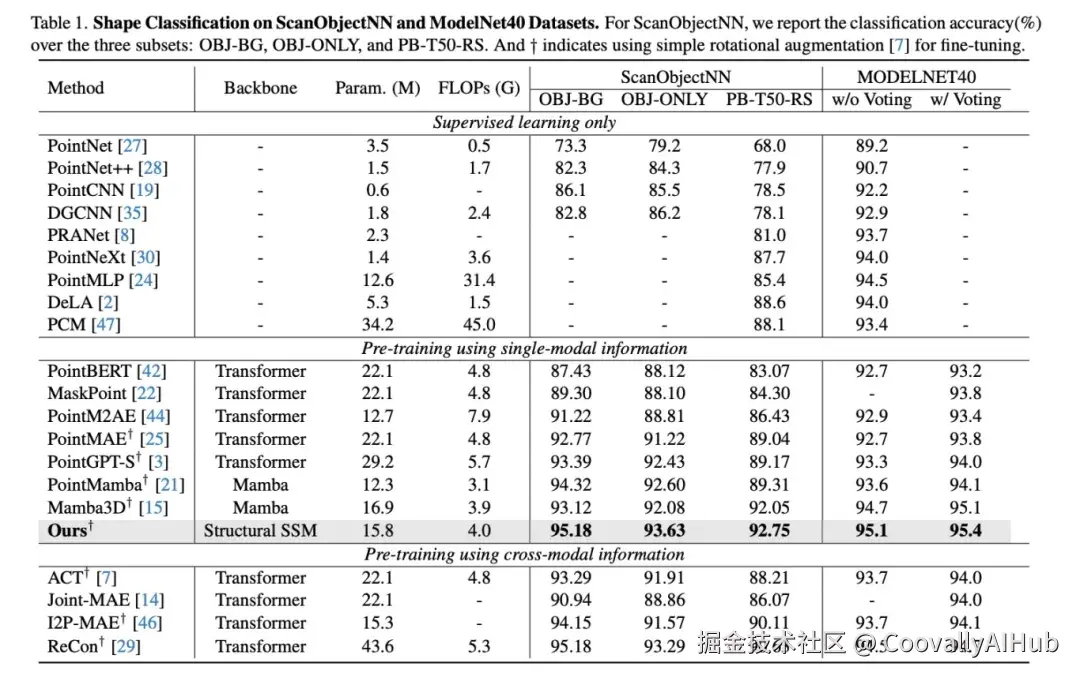
近期,Mamba系列方法通过引入状态空间模型(State Space Model, SSM)在点云表示学习任务中表现出色,依靠其高效的上下文建模能力与线性复杂度,取得了令人瞩目的成果。然而,现有方法仍面临两个关键挑战:其一,SSM在处理过程中破坏了点云原有的三维邻接关系;其二,在处理长序列输入时,模型难以保持稳定的记忆能力,影响了下游任务的性能表现。为了解决上述问题,本文提出了一种新颖的自监督点云表示学习范式------StruMamba3D。如下图所示,StruMamba3D具备以下三大优势。第一,本文设计了空间状态(Spatial States),并将其作为代理用于保持点与点之间的空间依赖。第二,结合状态更新机制与轻量级卷积模块,加强了空间状态之间的结构建模能力。第三,我们引入序列长度自适应策略,有效缓解了Mamba模型在迁移到不同输入长度下的性能波动问题。据我们所知,这是首个系统性引入空间结构建模与长度适应机制的Mamba变体,成功将结构建模能力与状态空间优势结合。在四个典型点云下游任务中,StruMamba3D均取得了显著优于现有方法的效果,并在ModelNet40和ScanObjectNN两个数据集上分别达到了95.1%与92.75%的最新最优性能,且无需使用投票策略。