
「【新智元导读】阿里昨晚放大招,正式开源通义 DeepResearch,一举登顶碾压 OpenAI、DeepSeek。模型、框架、方案全部开源,背后核心技术报告一同公开了。」
阿里又双叒叕上大分了!

就在昨天,阿里旗下首个深度研究 Agent 模型------通义 DeepResearch 正式开源。
在多项权威基准上,通义 DeepResearch 狂飙 SOTA,仅依靠 30B 参数(激活 3B)就能大杀四方!
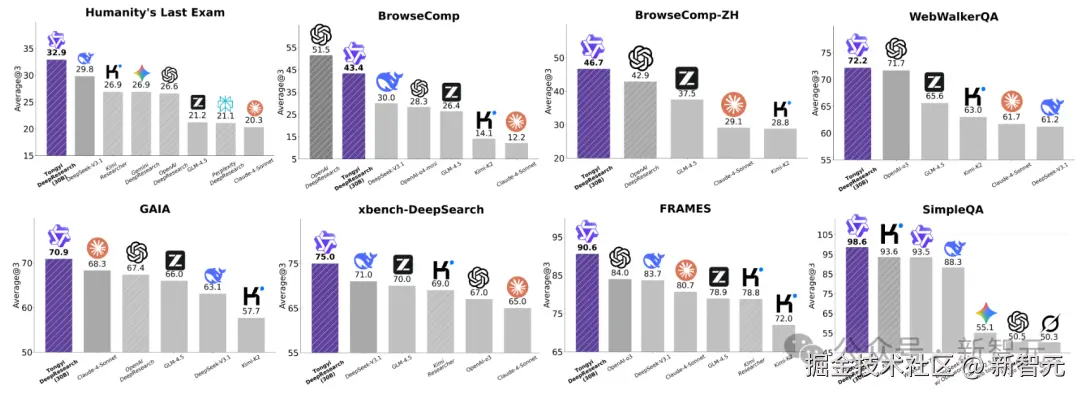
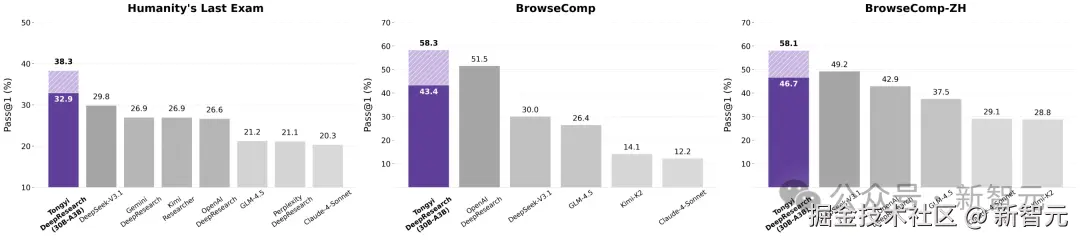
在号称人类最后的考试榜单 HLE(Humanity's Last Exam)中,通义 DeepResearch 更是拿下了 「32.9%」 的最高分,超越 DeepSeek-V3.1(29.8%)和 OpenAI DeepResearch(26.6%),霸榜全球第一!
在 OpenAI 提出的超高难度 BrowseComp 榜单上,通义 DeepResearch 以 「43.4%」 的准确率领跑开源榜单。

值得一提的是,模型、框架、方案全面开源,开发者即可在 Hugging Face、GitHub 下载。
目前,GitHub 项目已狂揽 「7.2****k」 星。
项目地址:github.com/Alibaba-NLP...
Hugging Face 模型地址:huggingface.co/Alibaba-NLP...
ModelScope 模型地址: modelscope.cn/models/iic/...
技术博客: tongyi-agent.github.io/blog/introd...
这波充满了诚意的开源操作和出色性能,直接点燃了 AI 圈!
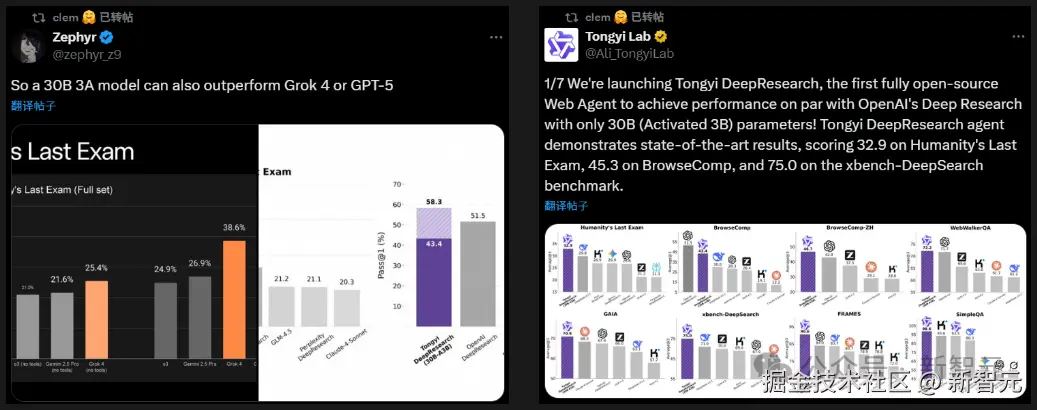
不仅引来广大网友们纷纷致谢,甚至 「Hugging Face 联合创始人兼」 「CEO」 Clem Delangue 和斯坦福 NLP 实验室等科技大 V 在第一时间进行转发关注。

「不止于问答:AI 的「研究员」时代」
我们已经习惯了 AI 的有问必答,但如果问题本身就无比复杂呢?
AI Deep Research 给出了答案。它彻底告别了「一问一答」的模式,进化为一位真正的「研究员」。面对一个棘手的问题,它会自主规划一条完整的研究路径,像人类专家一样工作:
深度搜寻---多源交叉---结构化归纳---报告生成
你得到的,将是一份真正能解决问题的方案:论据有源可溯,过程清晰可复现,结论掷地有声。

通义 DeepResearch 既可以是你的资深研究员,也能是你的高效私人助手,其首要任务便是将宏大问题精巧地拆解为一系列逻辑清晰的子任务。
随后,它为每个环节自主调用**「代码分析」、「论文检索」****、****网页访问**等工具,以层层递进、自主循环的方式完成整个研究链路。
说多无用,不如看一些直观的演示。
假设你正在考虑出售房子,想要了解所在地区最近楼盘的销售情况,直接找通义 DeepResearch------
我住在夏威夷的珍珠城,位于瓦胡岛上。
我知道附近有两处房产于 2022 年售出,分别是 Akaikai Loop 2072 号和 Komo Mai Drive 2017 号。
请找出这两处房产中 2022 年售价更高的那套,并告诉我其成交金额。
通义 DeepResearch 分了四步思考:
想要完成任务,第一步就是拆解指令,然后「联网」抓取数据,查询 2022 年房产销售记录,并提取相应的销售价格。
搜索之后,并非一下得出结果,而是在多个来源中,反复核查确认。

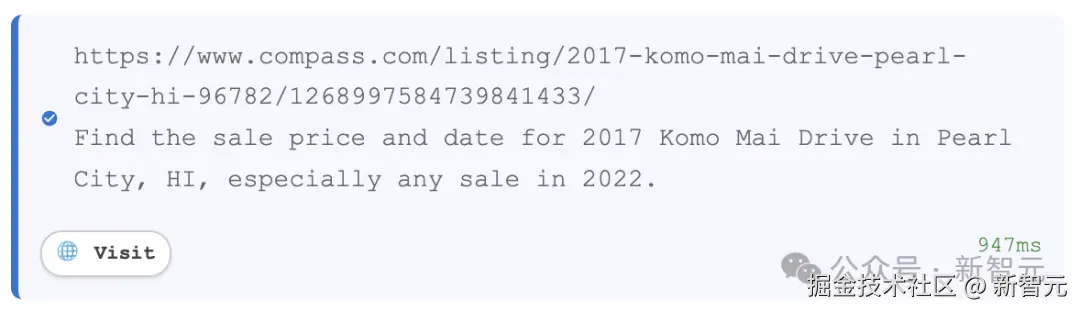

在生活规划和日常决策过程中,通义 DeepResearch 主要调用「联网搜索」工具,准确完成了任务。

过程
(上下滑动查看)

回答
(上下滑动查看)
再来看一个比较专的领域------法律,通义 DeepResearch 的表现又如何?
举个栗子,生活中的法律纠纷经常见,自己又不懂法,想要解决难题扔给 AI 就好了。
假设一个人恰好遇到了「原告要求退还出资,但自己又欠了一屁股债,还有很多债权人」的难题,那么原告是否违反资本维持原则?
在行动之前,通义 DeepResearch 大脑已经有了完整的构思,从问题拆解到工具使用。

接下来,就会看到通义用上了各种工具,获取法条、案例,并查找学术观点,最终收集所有可靠信息。




可以看到,通义执行任务的整个过程非常缜密,方便后期回溯。

过程
(上下滑动查看)

回答
(上下滑动查看)
再比如,有一个博士级跨学科的难题,自己拿不准,可以请教通义。
考虑这样一个「星座」的数学模型:在一小片天区内,每颗亮于某一特定星等的恒星,都与其最近的邻居(按二维欧几里得距离计算)连接一条边。
假设恒星在天空中均匀分布,那么平均每个星座(即连通子图)包含多少颗恒星?
此处,思考过程省略亿字......
但从通义的表现中,看得出每一步的计算和思考,都是建立在深度搜索、查询,反复验证的过程之上。
除了常用的搜索、浏览工具,它还借用「Python 解释器」、「谷歌学术」等工具帮自己理解,最后给出详细的报告。
那么,通义 DeepResearch 团队是如何炼成「超级研究大脑」?深入技术细节,让我们一一拆解。
「从零开始的数据炼金术」
「高质量数据」,是大模型的核心,也仍然是智能体的生命之源。
通义 DeepResearch 团队在反复试错和探索下,构建出一套完备的「智能体合成数据」体系,贯穿预训练与后训练的完整训练链路。
这个策略的终极目标,是摆脱对昂贵且稀缺的人工标注数据的依赖,用「机器生产」的方式,源源不断地创造出比人类标注质量更高、规模更庞大的训练「教材」。
「 」
」
「第一步:智能体增量预训练数据合成」
在预训练过程中,传统模型更像是一次性填鸭式教学,仍然是「记住知识」。
团队首次引入了「Agentic CPT」(增量预训练) 的概念,教会模型「使用知识」,并且构造了一个能够持续进化和扩展的智能体预训练数据合成方法 AgentFounder。
- 构建开放世界记忆
团队首先将海量知识文档、网页爬虫数据、知识图谱,以及模型后训练产生的思考轨迹和工具使用记录,全部汇集起来,构建了一个庞大的、以实体为核心的「开放世界知识记忆库」。
接着,从这个记忆库中抽取知识点,模拟真实世界中千奇百怪的场景,自动生成无数「问题 - 答案」对。
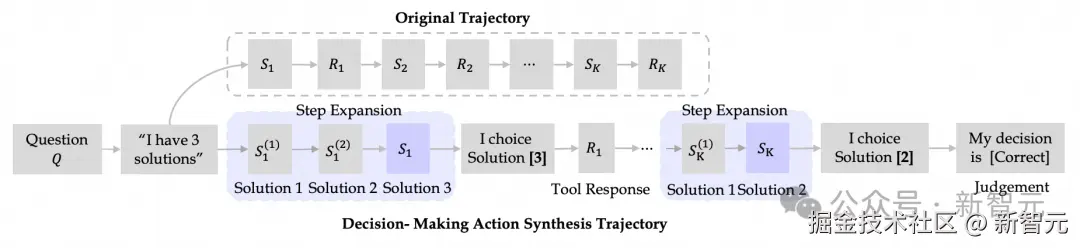
- 动作合成
更近一步,他们构建了三种类型的「动作数据」,具体包含规划、推理和决策动作。
这种方法让模型在离线状态下,就能探索海量的推理路径,而无需昂贵的在线 API 调用,大大提升了训练效率和深度。
尤其是,对于「决策动作」合成,会将轨迹重构为多步骤决策过程,充分探索有效的问题解决路径,让模型决策能力大幅提升。
「」
「第二步:全自动高质量数据合成」
基础打好后,如何让模型「百尺竿头,更进一步」?
在后训练阶段,团队又开发了一套全自动的合成数据生成方案,直接产出比人工标注质量还高的数据集。
从最早的 WebWalker,到后来更系统的 WebSailor,WebShaper,最后的 WebSailor V2 这一方案不断迭代。
每一步,都 Scaling 了数据的质量和规模。
为了生成复杂的问答对数据,他们开创了一个全新流程:
- 确保数据真实
从真实网站数据中提取信息,用上随机游走构建知识图谱、表格数据融合等方式,保证了问题的「原汁原味」。
- 人为制造「迷雾」
接着,策略性地隐藏或模糊问题中的关键信息,或以其他方式增加问题的不确定性,来提升问题的难度。
团队甚至将回答难度,建模为一系列可控的「原子操作」,由此一来,可以精准控制问题的复杂度。
- 杜绝「抄近道」
为了防止模型「偷懒」找捷径,团队还基于集合论把信息搜索问题形式化建模。
这不仅能生成更高质量的问题,还解决了合成数据难以验证答案正确性的行业难题。
- 打造「博士级」难题
此外,还开发了一个专用于生成跨科学知识、多步推理的「博士级」研究难题的自动化数据流程。
它让一个配备网络搜索、学术检索等工具的 Agent,在一个循环中不断深化和扩展问题,像滚雪球一样让任务难度可控升级。
「两种推理模式,征服长任务」
拥有了顶级的「教材」,还需要高效的学习和思考方式。
通义 DeepResearch 模型同时支持两种推理模式:一个是原生的 ReAct Mode,另一个是基于上下文管理的 Heavy Mode。
「」
「经典模式:ReAct Mode」
在标准任务中,模型采用经典的 ReAct(思考 - 行动 - 观察)模式,性能超乎想象。
它就像一个直觉敏锐的行动派,凭借 128K 的超长上下文,可以进行多轮次的快速交互,高效解决问题。
这种通用、可拓展的推理模式,尽管简单,但其是原生模型 Agentic 能力的直接体现。
「」
「深度模式:Heavy Mode」
放眼全世界,谷歌、OpenAI、xAI 等大厂都在「深度研究」上展开布局,紧追当前 Agent 热点。
但是,他们大都采用了「单窗口、线性累加」信息处理模式,弊端就是信息一多,「AI 大脑」就不够用了。
因为,所有中间思路和检索到的信息,都堆积在了单一的上下文中。
在处理长程任务中,这种模式下的 Agent 就会面临「认知空间窒息」和「不可逆的噪声污染」挑战。
最终,AI 推理能力下降,难以完成长程、复杂的研究任务。
当面对极端复杂、需要长远规划的研究任务时,「深度模式」(Heavy Mode)便会启动。
具体来说,模型会将一个庞大任务分解为一系列「研究轮次」:
- 在每一轮开始,Agent 仅从上一轮的信息中提取最精华的结论,构建一个全新的、精简的工作空间。
- 在这个专注的工作空间里,Agent 分析问题,将关键发现整合进一个不断演变的核心报告中。
- 最后,它决定下一步是继续收集信息,还是给出最终答案。
这种「综合 - 重构」的迭代过程,让 Agent 在执行超长期任务时,始终能保持清晰的「认知焦点」和高质量的推理能力。
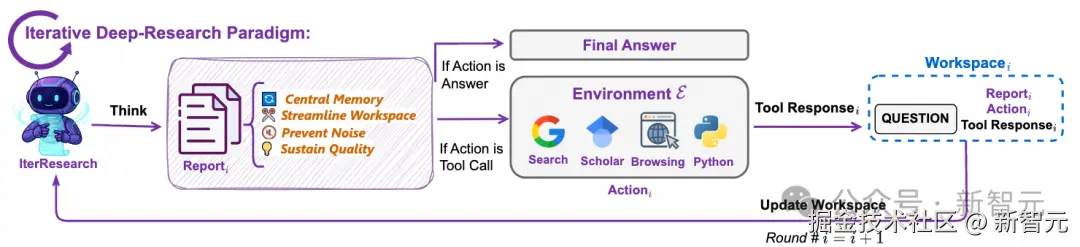
更进一步,团队还提出了 Research-Synthesis 框架:
让多个 IterResearch Agent 并行研究同一问题,最后将其报告和结论整合,从而获得更全面、更准确的答案。
这一模式下,通义 30B-A3B 模型在 HLE、BrowseComp、BrowseComp-ZH 基准上,性能再破纪录。
「AI 智能体自我进化」
「端到端训练技术革新」
如果说数据和推理模式是「招式」,那么训练流程就是「心法」。
团队打通了「Agentic CPT→ SFT→ Agentic RL」端到端全链路,首次提出了两阶段的智能体增量预训练,引领了智能体训练的新范式。
此外,其基于 ReAct 框架的强化学习环节,最能体现其深厚的系统工程能力。

团队坦言,「通过 「「强化学习」 」构建高质量 Agent,是一项复杂的系统工程挑战。」
如果将开发过程视为一个「强化学习」循环,其组件中任何不稳定,或是鲁棒性不足之处,都可能导致错误的「奖励」信号。
那么,在强化学习过程中,团队如何在算法和基础设施上取得突破?
- 「算法是核心」
针对算法,基于 GRPO 定制优化,严格遵循 on-policy 训练范式,确保信号匹配模型能力。
与此同时,采取一个 token 级策略梯度损失函数,以优化训练目标。结合留一法 (leave-one-out) 策略,降低优势估计方差。
为了避免「格式崩溃」现象,团队还进行多种策略的负样本筛选,比如排除过长未能生成答案的样本。
此外,通过增大批次(batch size)和组规模(group size),维持较小方差,提供充足监督信号。
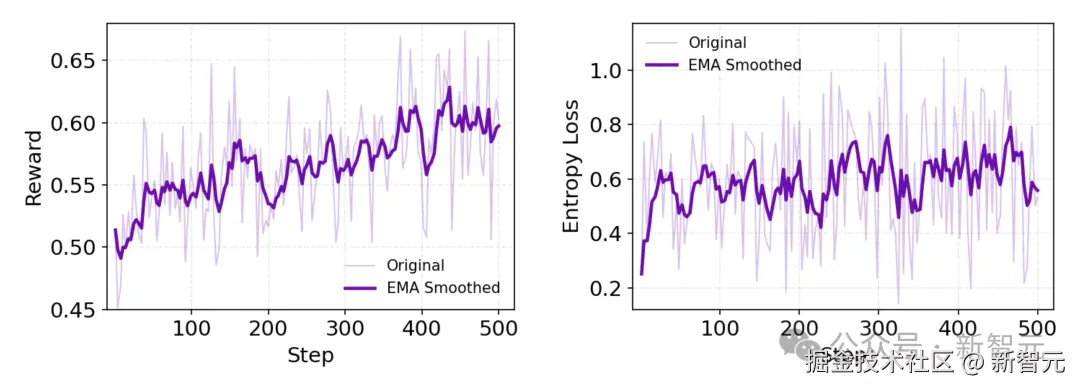
如上图动态指标显示,奖励持续震荡上升。同时,策略熵(policy entropy)保持较高水平,说明模型在持续探索进化,避免了过早收敛。
这得益于 Web 环境的非平稳性,形成了鲁棒自适应策略,无需额外正则化。
算法稳定搞定了,就一切万事大吉了吗?显然不是。
- 基础设施更关键
团队分享了一个至关重要的洞见:
算法固然重要,但并非成功的唯一决定因素。数据质量和训练环境的稳定性,可能是决定强化学习项目成败的更关键一环。
一个极具说服力的现象是,团队曾尝试直接在人工标注的 BrowseComp 测试集上训练模型来验证算法,结果其表现远不如使用自研合成数据训练的效果。
由此,他们推测,这是因为合成数据提供了一致性更高的潜在分布,使模型能进行更有效的学习和拟合。
相较之下,规模有限、含有更多噪声的人工数据,反而让模型难以提炼和泛化。
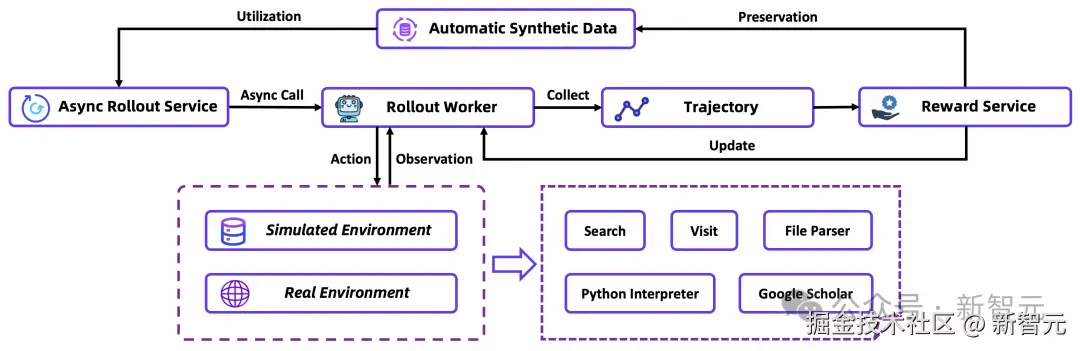
为了实现稳定、高效的强化学习,他们构建了一套全栈式的基础设施「护城河」:
- 仿真训练环境:利用离线维基百科和自定义工具套件,创建了一个经济高效、快速可控的模拟训练平台,摆脱了对昂贵且不稳定的实时 Web API 的依赖。
- 工具沙盒:通过缓存结果、失败重试、饱和式响应等机制,为智能体提供了快速鲁棒的交互环境,防止工具的偶然错误破坏其学习轨迹。
- 自动数据管理:在训练动态的指导下实时优化数据集,通过全自动数据合成和数据漏斗,形成「数据生成」与「模型训练」之间的正向循环。
- On-policy 的异步框架:基于 rLLM 实现,让多个智能体实例并行与环境交互,独立生成轨迹,极大提升了训练效率。
通过这一系列措施,阿里团队实现了智能体强化训练的「闭环」,让模型从一个基座模型开始,通过预训练、微调,最终在强化学习中实现自我进化。
这套全栈方案,恰恰为解决复杂任务的 AI 智能体训练树立了全新范式。
「「高德行程规划」」
「和「律师小助理」双开花」
过去半年,通义 DeepResearch 团队在 Deep Research 研发中不断深耕,每月一篇新作,全部斩获 SOTA。

通义 DeepResearch 团队技术报告矩阵
除了技术报告诚意满满,通义 DeepResearch 团队一口气连发六篇技术报告,除了延续 Web 系列的 WebResearcher、WebWeaver、WebResummer、WebSailor V2 的四篇工作之外,更是全新推出 Agent 系列的 AgentFounder 和 AgentScaler!
「这些重磅研究,并非是实验室的「花瓶」,它们早已走向 「「落地」 」,赋能阿里旗下多个产品。」
比如,每个人都能感知的案例------高德「小高老师」。可能你还不知道的是,其背后就是通义 DeepResearch 提供的加持。

前段时间,高德暑期大版本 V16,重点全面推出「地图导航 + 本地生活」场景。
通义团队和高德深度合作,在上述导航和本地生活场景中构建集成 Deep Research 能力的垂类智能体。
在规划决策中,通义团队基于 Qwen 模型微调构建精通地图领域的复杂「POI 推理 Agent」,一个超懂地图的智能助手。
它能一键 get 各种复杂需求,比如地理区域、参与者约束、交通约束、时间约束、POI 属性等多维度信息。
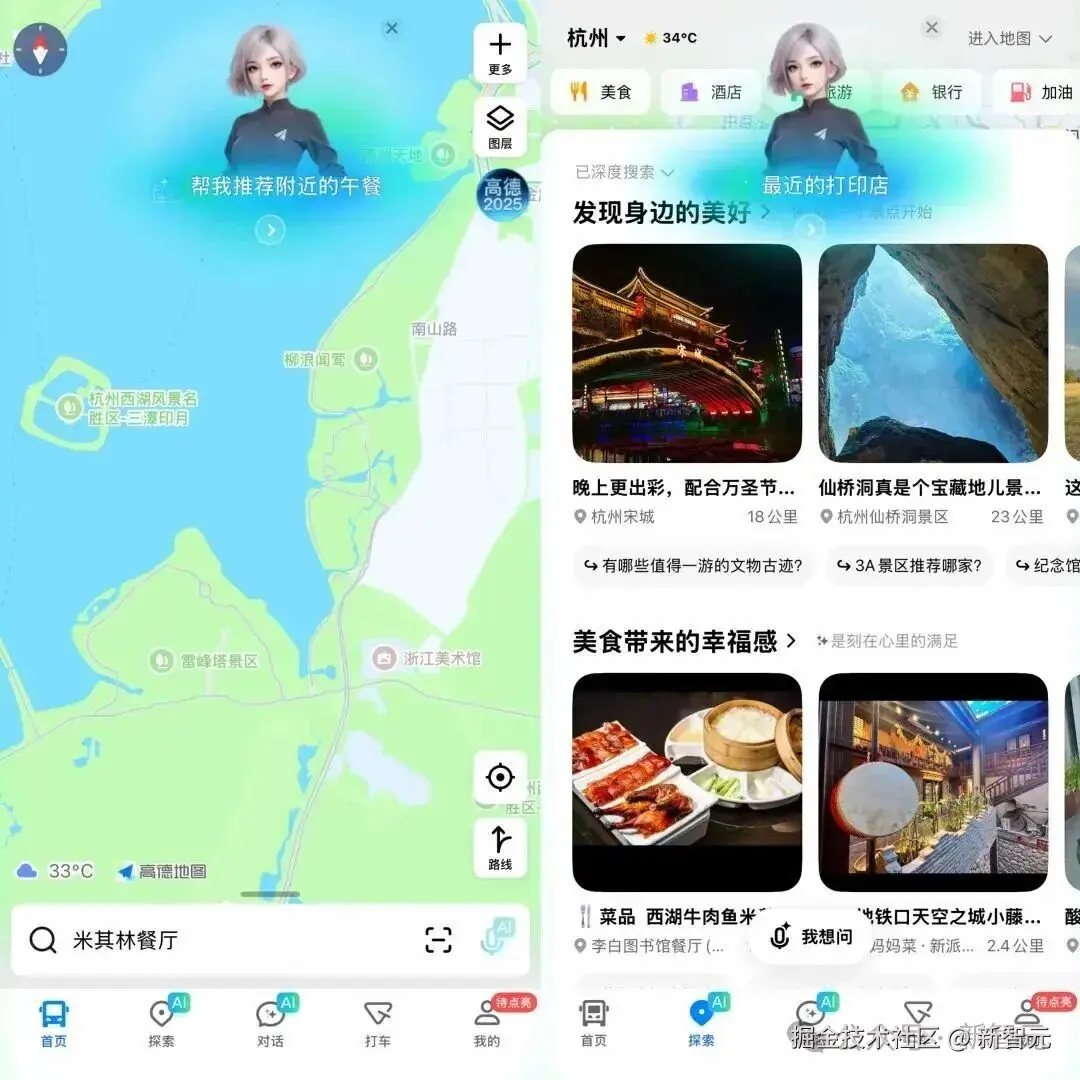
举个例子,当你输入一长串要求------
我想在西湖边上找家评分 4.5 以上的浙菜馆,得有儿童餐,而且从地铁站走过去不能超过 1 公里。
AI 能够立即挑出最合适的点,连怎么走都可以安排得明明白白。
再比如,假设想去奥森 Citywalk,高德 AI 瞬间就能制定出三种攻略。
打开每一种攻略,可以看到,它会帮你做出详细的时间规划,贴心地推荐餐饮、游玩景点等。
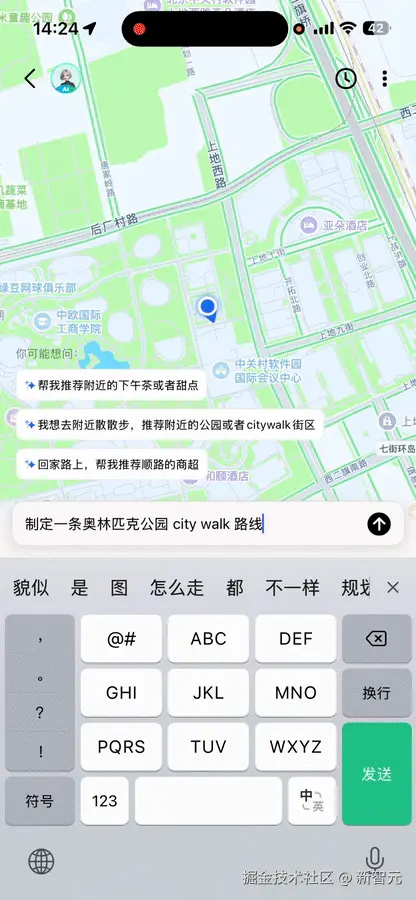
通义出模型,高德出工具和 Agent 链路,由此打造出了「小德助手」惊艳的体验。
在法律领域,通义 DeepResearch 能力也深度融合到了「通义法睿」中,一个原生法律智能体。
它集问答、案例检索、合同审查、文书起草于一身,可以满足法律用户的需求。
升级后,基于创新性 Agentic 架构和迭代式规划(Iterative Planning),「通义法睿」DeepResearch 大幅升级。
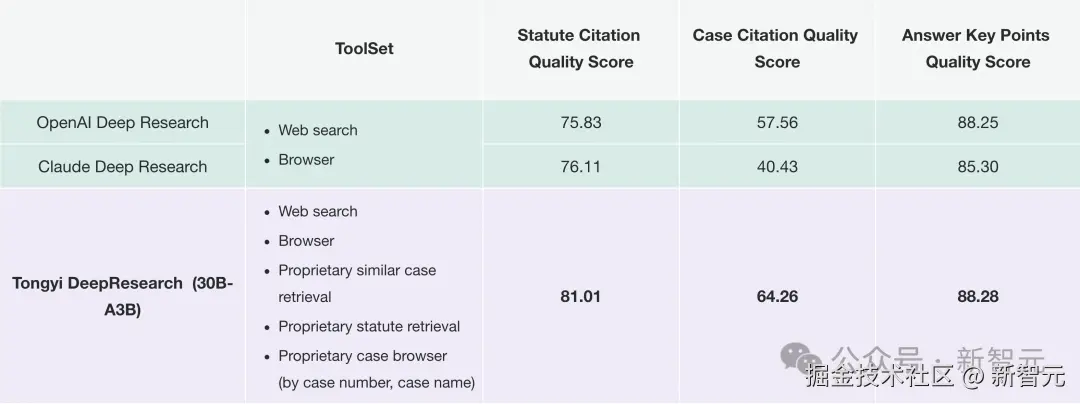
如今,它能够执行多步查询,依托真实判例、法规和解读,提供可追溯分析。
通过 PK,「通义法睿」在三大核心维度------答案要点质量、案例引用质量、法条引用质量上,超越了 OpenAI、Claude 家的 Deep Research。
「总结」
总而言之,通义 DeepResearch 的开源,无疑是 AI 社区的一大福音,人人可构建专属的深度研究智能体。
它证明了,轻量模型在「深度研究」领域中也能称霸。
它很慷慨,大方分享其背后技术秘方------合成数据 + 强化学习是训练模型的未来。
下一个爆款 APP,或许有天,正是通义 DeepResearch 打造的。