深入理解JVM执行引擎
常见的编译型语言如C++,通常会把代码直接编译成CPU所能理解的机器码来运行。而Java为了实现"一次编译,处处运行"的特性,把编译的过程分成两部分,首先它会先由javac编译成通用的中间形式------字节码,然后再由解释器逐条将字节码解释为机器码来执行。所以在性能上,Java通常不如C++这类编译型语言。
为了优化Java的性能 ,JVM在解释器之外引入了即时(Just In Time)编译器:当程序运行时,解释器首先发挥作用,代码可以直接执行。随着时间推移,即时编译器逐渐发挥作用,把越来越多的代码编译优化成本地代码,来获取更高的执行效率。解释器这时可以作为编译运行的降级手段,在一些不可靠的编译优化出现问题时,再切换回解释执行,保证程序可以正常运行。
即时编译器极大地提高了Java程序的运行速度,而且跟静态编译相比,即时编译器可以选择性地编译热点代码,省去了很多编译时间,也节省很多的空间。目前,即时编译器已经非常成熟了,在性能层面甚至可以和编译型语言相比。不过在这个领域,大家依然在不断探索如何结合不同的编译方式,使用更加智能的手段来提升程序的运行速度。
一、Java的执行过程
Java的执行过程整体可以分为两个部分,第一步由javac将源码编译成字节码,在这个过程中会进行词法分析、语法分析、语义分析,编译原理中这部分的编译称为前端编译。接下来无需编译直接逐条将字节码解释执行,在解释执行的过程中,虚拟机同时对程序运行的信息进行收集,在这些信息的基础上,编译器会逐渐发挥作用,它会进行后端编译------把字节码编译成机器码,但不是所有的代码都会被编译,只有被JVM认定为的热点代码,才可能被编译。
怎么样才会被认为是热点代码呢?JVM中会设置一个阈值,当方法或者代码块的在一定时间内的调用次数超过这个阈值时就会被编译,存入codeCache(位于方法区)中。当下次执行时,再遇到这段代码,就会从codeCache中读取机器码,直接执行,以此来提升程序运行的性能。整体的执行过程大致如下图所示:
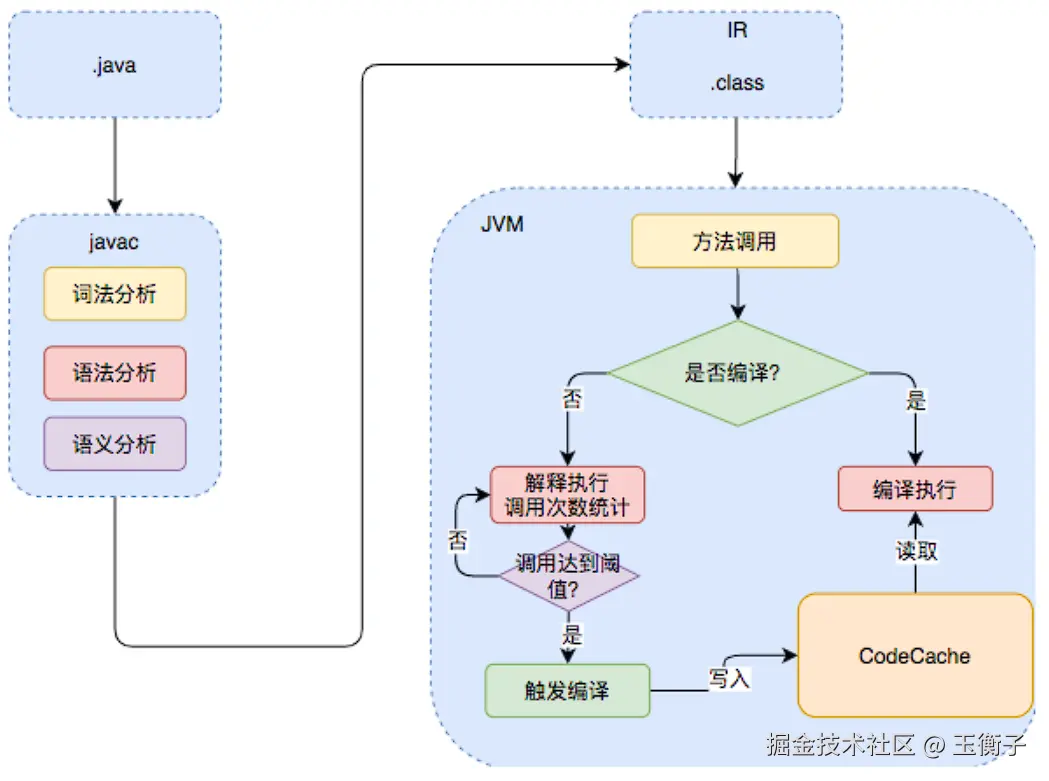
二、前端编译与后端编译
Java 程序的编译过程是分两个部分的。一个部分是从java文件编译成为class文件,这一部分也称为前端编译。另一个部分则是这些class文件,需要进入到JVM虚拟机,将这些字节码指令编译成操作系统识别的具体机器指令。这一部分也称为后端编译。
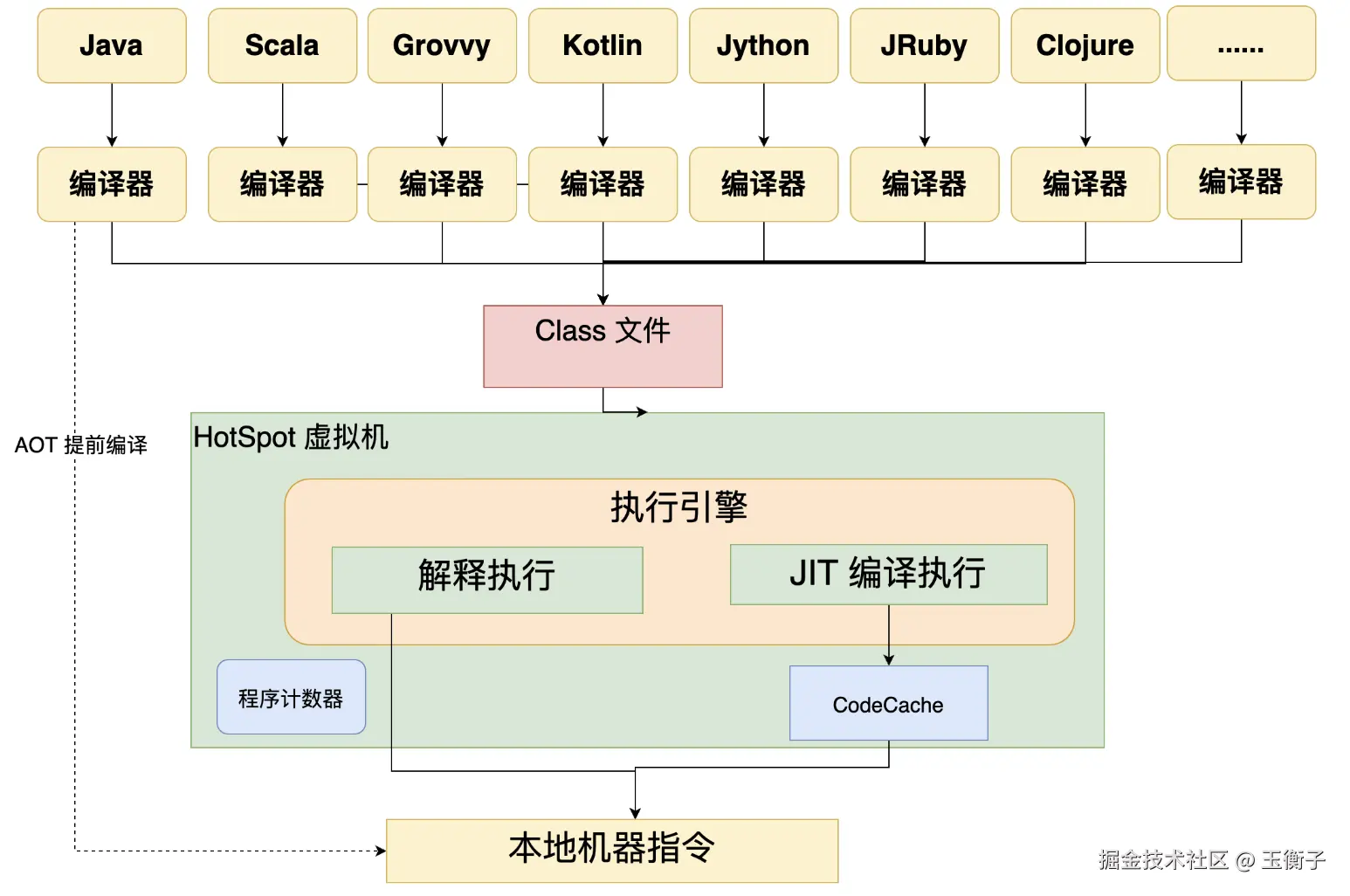
其中前端编译是在JVM虚拟机之外执行,所以与JVM虚拟机没有太大的关系。任何编程语言,只要能够编译出满足JVM规范的Class文件,就可以提交到JVM虚拟机执行。
三、字节码指令是如何执行的
这里就不得不向你介绍解释执行与编译执行。
这一块属于后端编译器工作范畴了,执行引擎要做的事情,其实就是将这些Class文件中的字节码指令翻译成对应操作系统的机器码,然后扔给服务器执行就行了。 本质上,就相当于是一个翻译。

那么怎么做这个翻译工作呢?最简单的方式,当然就是来一个指令就翻译一次。就像是一个无脑的翻译机器,不用管合不合理,按字翻译就是了。没错,早期的JVM执行引擎其实就是这么做的,这种执行方式,就称为解释执行。
起初java就是解释执行的,但后续为了提升性能,引入即时编译器 JIT(Just In Time Compiler),将那些运行频率最高的热点代码提前编译出来,放到缓存CodeCache里。这种先编译,后执行的方式,就称为编译执行。
使用java -version就可以看到当前使用的是哪种执行模式(mixed、interreted、compiled 三种mode)。HotSpot虚拟机并没有直接选择执行效率更快的编译执行,而是默认采用的一种混合执行的方式,哪怕到jdk21亦是如此。
-Xint参数的作用和工作原理
-Xint 参数强制JVM使用纯解释模式运行,所有Java字节码都通过解释器执行,而不会被JIT编译器编译成本地机器码。
- 启动速度快,没有编译时间开销
- 内存占用少,不需要占用codeCache
- 当然缺点就是每次解释执行性能相对低下
-Xcomp参数的作用和工作原理
-Xcomp 参数强制JVM使用纯编译模式运行,它会尝试在方法首次被调用时就将其编译成本地代码,而不是先解释执行。
但需要注意的是, -Xcomp并不会将整个工程项目都编译放入codeCache中。它的工作方式是:
- 当一个类被加载后,其中的方法在首次调用时会被编译
- 只有实际被调用的方法才会被编译,未调用的方法不会被编译
- 编译后的代码会被放入codeCache中
-Xmixed参数的作用和工作原理
-Xmixed 是JVM的默认执行模式,采用混合执行策略:
- 程序启动时先用解释器执行
- 运行过程中监控代码执行情况,识别热点代码
- 只对频繁执行的热点代码进行JIT编译优化
- 其他代码继续使用解释执行
对于为什么JVM不直接采用性能明显更高的编译执行模式呢?
虽然编译执行可以将越来越多的代码编译成本地代码,这样可以减少解释器的中间损耗,获得更高的执行效率。但是,编译执行启动慢,初始编译开销大,内存占用高,一般场景都不需要。
四、热点代码识别
使用JIT实时编译的前提就是需要识别出热点代码。要知道某段代码是不是热点代码,是不是需要触发即时编译,这个行为称为"热点探测"(Hot Spot Code Detection)。热点探测有很多种实现思路,而在HotSpot虚拟机中采用的是一种基于计数器的热点探测方法。HotSpot为每个方法准备了两类计数器:方法调用计数器 (Invocation Counter)和回边计数器(Back Edge Counter)。当虚拟机运行参数确定的前提下,这两个计数器都有一个明确的阈值,计数器阈值一旦溢出,就会触发即时编译。
方法调用计数器
这个计数器就是用于统计方法被调用的次数。每次调用一个方法时,就记录一次这个方法的执行次数。当他的执行次数非常多,超过了某一个阈值,那么这个方法就可以认为是热点方法。这个方法对应的代码,自然也就是热点代码了。这时就可以向JIT提交一个针对该方法的代码编译请求了。
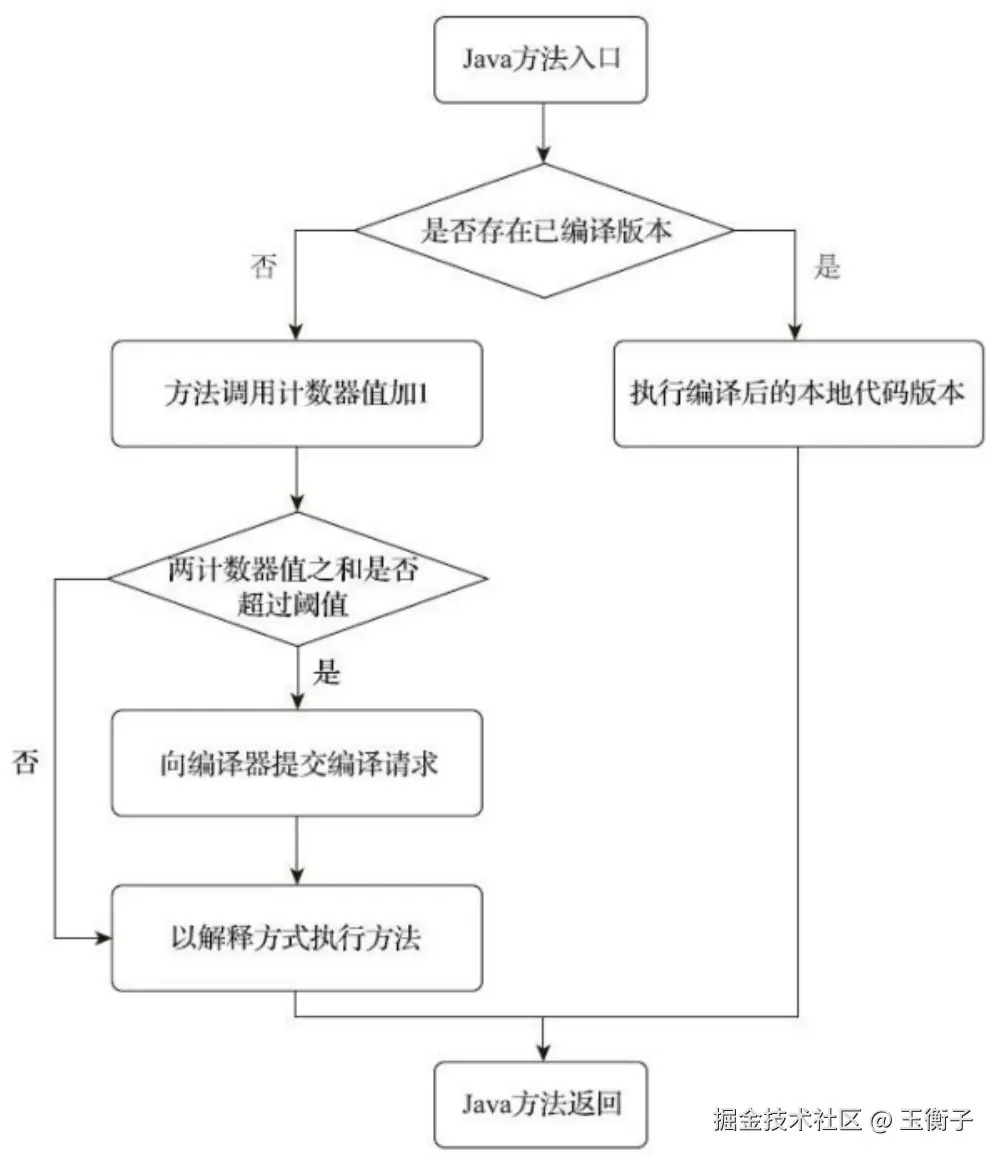
默认阈值是10000,使用java -XX:+PrintFlagsInitial -version可以看到CompileThreshold=10000
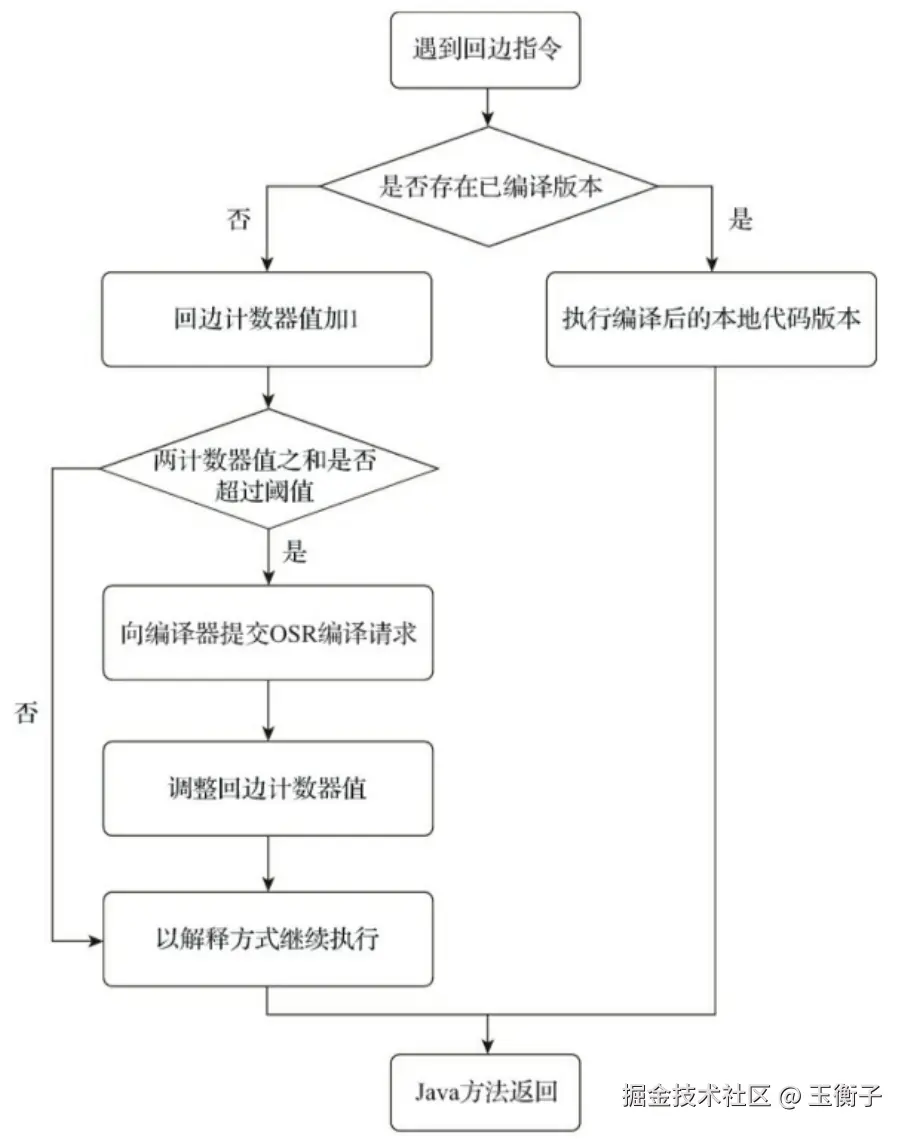
回边计数器
回边计数器,它的作用是统计一个方法中循环体代码执行的次数。在字节码中遇到控制流向后跳转的指令就称为"回边(Back Edge)",很显然建立回边计数器统计的目的是为了发现一个方法内部频繁的循环调用。回边计数器在服务端模式下默认的阈值是10700
回边计数器阈值 =方法调用计数器阈值(CompileThreshold)×(OSR比率(OnStackReplacePercentage)-解释器监控比率(InterpreterProfilePercentage)/100
其中OnStackReplacePercentage默认值为140,InterpreterProfilePercentage默认值为33,如果都取默认值,那Server模式虚拟机回边计数器的阈值为10700。回边计数器阈值 =10000×(140-33)=10700
当解释器遇到回边指令(goto)时的执行流程如下:
五、JVM中的编译器
JVM中集成了两种编译器,Client Compiler和Server Compiler,它们的作用也不同。Client Compiler注重启动速度和局部的优化,Server Compiler则更加关注全局的优化,性能会更好,但由于会进行更多的全局分析,所以启动速度会变慢。两种编译器有着不同的应用场景,在虚拟机中同时发挥作用。
Client Compiler
HotSpot VM带有一个Client Compiler C1编译器。这种编译器启动速度快,但是性能比较Server Compiler来说会差一些。C1会做三件事:
- 局部简单可靠的优化,比如字节码上进行的一些基础优化,方法内联、常量传播等,放弃许多耗时较长的全局优化。
- 将字节码构造成高级中间表示(High-level Intermediate Representation,以下称为HIR),HIR与平台无关,通常采用图结构,更适合JVM对程序进行优化。
- 最后将HIR转换成低级中间表示(Low-level Intermediate Representation,以下称为LIR),在LIR的基础上会进行寄存器分配、窥孔优化(局部的优化方式,编译器在一个基本块或者多个基本块中,针对已经生成的代码,结合CPU自己指令的特点,通过一些认为可能带来性能提升的转换规则或者通过整体的分析,进行指令转换,来提升代码性能)等操作,最终生成机器码。
Server Compiler
Server Compiler主要关注一些编译耗时较长的全局优化,甚至会还会根据程序运行的信息进行一些不可靠的激进优化。这种编译器的启动时间长,适用于长时间运行的后台程序,它的性能通常比Client Compiler高30%以上。目前,Hotspot虚拟机中使用的Server Compiler有两种:C2和Graal。
C2 Compiler
在Hotspot VM中,默认的Server Compiler是C2编译器。
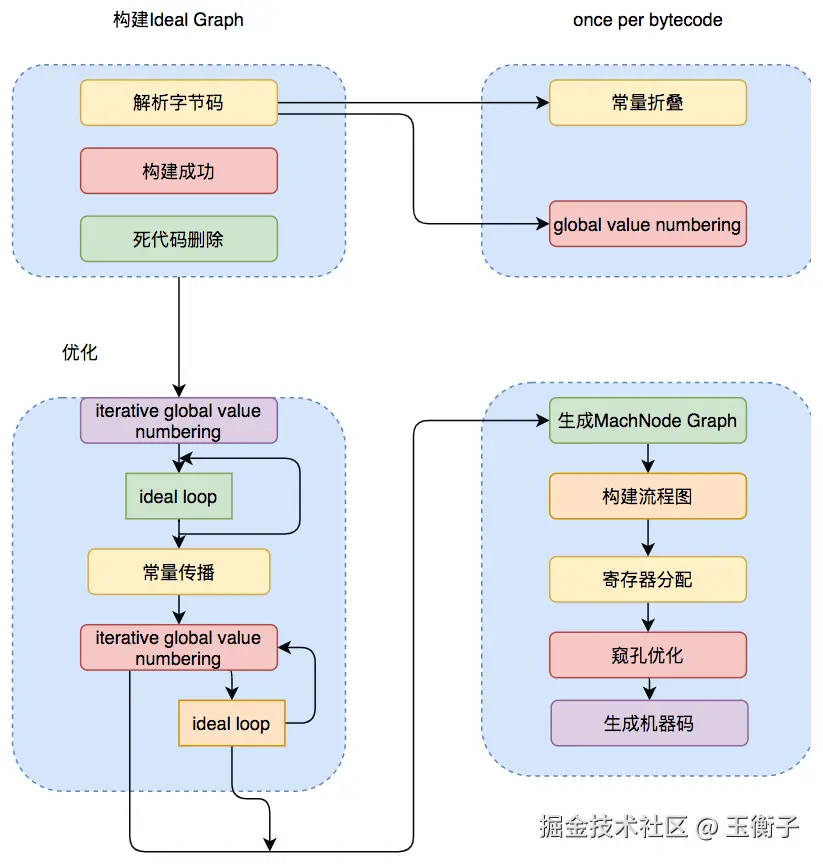
C2编译器在进行编译优化时,会使用一种控制流与数据流结合的图数据结构,称为Ideal Graph。 Ideal Graph表示当前程序的数据流向和指令间的依赖关系,依靠这种图结构,某些优化步骤(尤其是涉及浮动代码块的那些优化步骤)变得不那么复杂。
Ideal Graph的构建是在解析字节码的时候,根据字节码中的指令向一个空的Graph中添加节点,Graph中的节点通常对应一个指令块,每个指令块包含多条相关联的指令,JVM会利用一些优化技术对这些指令进行优化,比如Global Value Numbering、常量折叠等,解析结束后,还会进行一些死代码剔除的操作。生成Ideal Graph后,会在这个基础上结合收集的程序运行信息来进行一些全局的优化,这个阶段如果JVM判断此时没有全局优化的必要,就会跳过这部分优化。
无论是否进行全局优化,Ideal Graph都会被转化为一种更接近机器层面的MachNode Graph,最后编译的机器码就是从MachNode Graph中得的,生成机器码前还会有一些包括寄存器分配、窥孔优化等操作。关于Ideal Graph和各种全局的优化手段会在后面的章节详细介绍。Server Compiler编译优化的过程如下图所示:
Graal Compiler
从JDK 9开始,Hotspot VM中集成了一种新的Server Compiler,Graal编译器。相比C2编译器,Graal有这样几种关键特性:
- 前文有提到,JVM会在解释执行的时候收集程序运行的各种信息,然后编译器会根据这些信息进行一些基于预测的激进优化,比如分支预测,根据程序不同分支的运行概率,选择性地编译一些概率较大的分支。Graal比C2更加青睐这种优化,所以Graal的峰值性能通常要比C2更好。
- 使用Java编写,对于Java语言,尤其是新特性,比如Lambda、Stream等更加友好。
- 更深层次的优化,比如虚函数的内联、部分逃逸分析等。
Graal编译器可以通过Java虚拟机参数-XX:+UnlockExperimentalVMOptions -XX:+UseJVMCICompiler启用。当启用时,它将替换掉HotSpot中的C2编译器,并响应原本由C2负责的编译请求。
六、后端编译优化技术
参考文档:wiki.openjdk.org/
1.常量传播
在编译时分析程序中变量的取值,将已知的常量值直接替换变量引用
java
final int A = 10;
int b = A * 2; // 编译期优化为: int b = 10 * 2; 然后进一步优化为: int b = 20;死代码消除:基于常量传播结果,可能进一步消除不可达的代码分支
2.常量折叠
在编译时计算常量表达式的结果
java
int x = 2 + 3 * 4; // 编译期优化为: int x = 14;
3.方法内联 Inline
方法内联的优化行为就是把目标方法的代码复制到发起调用的方法之中,避免发生真实的方法调用。这样就可以减少频繁创建栈帧的性能开销。
java
public class CompDemo {
private int add1(int x1,int x2,int x3,int x4){
return add2(x1,x2)+ add2(x3,x4);
}
private int add2(int x1, int x2){
return x1+x2;
}
//内联优化
private int add(int x1,int x2,int x3,int x4){
return x1+x2+x3+x4;
}
public static void main(String[] args) {
CompDemo compDemo = new CompDemo();
//超过方法调用计数器的阈值 100000 次,才会进入 JIT 实时编译,进行内联优化。
for (int i = 0; i < 1000000; i++) {
compDemo.add1(1,2,3,4);
}
}
}加入 JVM 参数:-XX:+PrintCompilation -XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining -XX:+PrintCompilation -XX:+UnlockDiagnosticVMOptions 后可以看到以下的执行日志

在JDK8中,提供了多个跟Inline内联相关的参数,可以用来干预内联行为。
-
-XX:+Inline 启用方法内联。默认开启。
-
-XX:InlineSmallCode=size 用来判断是否需要对方法进行内联优化。如果一个方法编译后的字节码大小大于这个值,就无法进行内联。默认值是1000bytes。
-
-XX:MaxInlineSize=size 设定内联方法的最大字节数。如果一个方法编译后的字节码大于这个值,则无法进行内联。默认值是35byt
-
-XX:FreqInlineSize=size 设定热点方法进行内联的最大字节数。如果一个热点方法编译后的字节码大于这个值,则无法进行内联。默认值是325bytes。
-
-XX:MaxTrivialSize=size 设定要进行内联的琐碎方法的最大字节数(Trivial Method:通常指那些只包含一两行语句,并且逻辑非常简单的方法。比如像这样的方法
public int getTrivialValue() { return 42; })。默认值是6bytes。
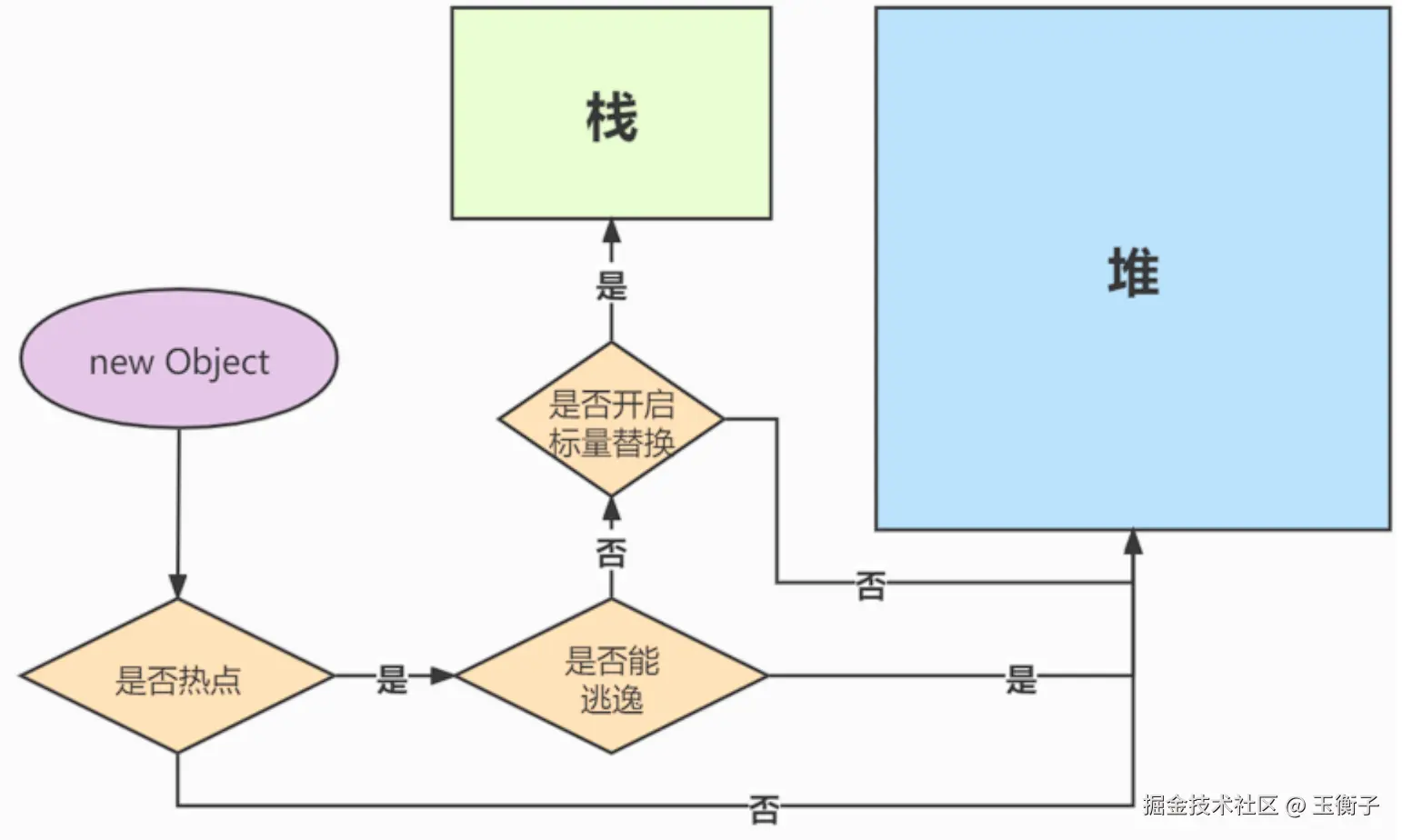
4.逃逸分析 Escape Analysis
如果能证明一个对象不会逃逸到方法或线程之外,那么 JIT 就可以为这个对象实例采取后续一系列的优化措施。
第一个是标量替换(Scalar Replacement)。若一个数据已经无法再分解成更小的数据来表示了,Java虚拟机中的原始数据类型(int、long等数值类型及reference类型等)都不能再进一步分解了,那么这些数据就可以被称为标量。如果把一个Java对象拆散,根据程序访问的情况,将其用到的成员变量恢复为原始类型来访问,这个过程就称为标量替换。假如逃逸分析能够证明一个对象不会被方法外部访问,并且这个对象可以被拆散,那么程序真正执行的时候将可能不去创建这个对象,而改为直接创建它的若干个被这个方法使用的成员变量来代替。将对象拆分后,除了可以让对象的成员变量在栈上分配和读写之外,还可以为后续进一步的优化手段创建条件。标量替换对逃逸程度的要求更高,它不允许对象逃逸出方法范围内。JDK8 中默认开启了标量替换,可以通过添加参数 -XX:-EliminateAllocations 主动关闭标量替换。
第二个是栈上分配( Stack Allocations)。正常情况下,JVM 中所有对象都应该创建在堆上,并由 GC 线程进行回收。如果确定一个对象不会逃逸出线程之外,那让这个对象在栈上分配内存将会是一个很不错的主意,对象所占用的内存空间就可以随栈帧出栈而销毁。在一般应用中,完全不会逃逸的局部对象和不会逃逸出线程的对象所占的比例是很大的,如果能使用栈上分配,那大量的对象就会随着方法的结束而自动销毁了,垃圾收集子系统的压力将会下降很多。栈上分配可以支持方法逃逸,但不能支持线程逃逸(栈帧线程私有的)。
三者关系如下:
java
/**
* 逃逸分析 -》 栈上分配 -》 标量替换
* -XX:-DoEscapeAnalysis 关闭逃逸分析后 29ms gc一次
* -XX:+DoEscapeAnalysis 默认会开启 2ms gc0次
* -XX:-EliminateAllocations 关闭标量替换 27ms gc一次
* -XX:+PrintGC 输出GC信息
*/
public class EscapeAnalysisTest {
public static void main(String[] args) throws InterruptedException {
long start = System.currentTimeMillis();
for (int i = 0; i < 10000000; i++) {
allocate();
}
System.out.println("运行耗时:"+(System.currentTimeMillis()-start));
// Thread.sleep(6000000);
}
static void allocate(){
MyObject myObject = new MyObject(2024,2024.6);
}
static class MyObject {
int a;
double b;
MyObject(int a,double b){
this.a = a;
this.b = b;
}
}
}5.锁消除 lock elision
这个优化措施主要是针对 synchronized 关键字。当 JVM 检测到一个锁的代码不存在多线程竞争时,会对这个对象的锁进行锁消除。
多线程并发资源竞争是一个很复杂的场景,所以通常要检测是否存在多线程竞争是非常麻烦的。但是有一种情况很简单,如果一个方法没有发生逃逸,那么他内部的锁都是不存在竞争的。
java
/**
* -XX:-EliminateLocks 关闭锁消除
*/
public class LockElisionDemo {
public static String BufferString(String s1,String s2){
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
return sb.toString();
}
public static String BuilderString(String s1, String s2){
StringBuilder sb = new StringBuilder();
sb.append(s1);
sb.append(s2);
return sb.toString();
}
public static void main(String[] args) {
System.out.println(">>>>>>>>>>>>>>>>>>>预热用上JIT");
// long preStartTime1 = System.currentTimeMillis();
for (int i = 0; i < 100000000; i++) {
BuilderString("aaaaa","bbbbbb");
}
// System.out.println("StringBuilder耗时:"+(System.currentTimeMillis()-preStartTime1));
// long preStartTime2 = System.currentTimeMillis();
for (int i = 0; i < 100000000; i++) {
BufferString("aaaaa","bbbbbb");
}
// System.out.println("StringBuffer耗时:"+(System.currentTimeMillis()-preStartTime2));
System.out.println(">>>>>>>>>>>>>>>>>>>正式测试");
long startTime = System.currentTimeMillis();
for (int i = 0; i < 100000000; i++) {
BufferString("aaaaa","bbbbbb");
}
System.out.println("StringBuffer耗时:"+(System.currentTimeMillis()-startTime));
long startTime3 = System.currentTimeMillis();
for (int i = 0; i < 100000000; i++) {
BuilderString("aaaaa","bbbbbb");
}
System.out.println("StringBuilder耗时:"+(System.currentTimeMillis()-startTime3));
}
}6.Global Value Numbering
全局值编号是一种编译器优化技术,它为程序中的每个计算值分配唯一的编号,通过比较编号来识别和消除重复计算。
例如:消除冗余计算
java
// 优化前
int a = x + y;
int b = x + y; // 冗余计算
int c = a * 2;
int d = (x + y) * 2; // 冗余计算
// 优化后
int a = x + y;
int b = a; // 直接复用a的值
int c = a * 2;
int d = c; // 直接复用c的值7.窥孔优化
窥孔优化是一种局部优化技术(检查一小段连续指令("窥孔")),通过检查和替换小段机器代码或字节码来提高程序性能。
核心特点:
- 局部性:只关注小段连续的指令
- 模式匹配:识别特定的指令序列模式
- 替换优化:用更高效的等价指令序列替换原有序列
- 简单高效:实现相对简单,执行速度快
例如:机器码层面
c#
// 优化前
mov eax, ebx // eax = ebx
mov ecx, eax // ecx = eax
// 结果: ecx = ebx
// 窥孔优化后
mov ecx, ebx // 直接: ecx = ebx
// 消除中间步骤七、Graal 编译优化
1.虚函数内联优化
虚函数是在面向对象编程中,允许在运行时根据对象的实际类型来决定调用哪个具体实现的函数。
java
// 基础示例
abstract class Animal {
// 虚函数 - 具体实现取决于实际对象类型
public abstract void makeSound();
}
class Dog extends Animal {
public void makeSound() {
System.out.println("汪汪");
}
}
class Cat extends Animal {
public void makeSound() {
System.out.println("喵喵");
}
}
// 使用示例
Animal animal1 = new Dog(); // 实际类型是Dog
Animal animal2 = new Cat(); // 实际类型是Cat
animal1.makeSound(); // 运行时决定调用Dog的makeSound
animal2.makeSound(); // 运行时决定调用Cat的makeSound内联优化
java
// 没有内联的情况
public int processAnimals(Animal[] animals) {
int count = 0;
for (Animal animal : animals) {
animal.makeSound(); // 需要创建额外栈帧
count++;
}
return count;
}
// 内联后的效果(概念上)
public int processAnimals(Animal[] animals) {
int count = 0;
for (Animal animal : animals) {
// 直接执行具体方法
if (animal instanceof Dog) {
System.out.println("汪汪"); // Dog.makeSound()的内容
} else if (animal instanceof Cat) {
System.out.println("喵喵"); // Cat.makeSound()的内容
}
count++;
}
return count;
}2.部分逃逸 (Partial Escape) 分析
先简单介绍一下什么是逃逸? 对象的"逃逸"指的是对象的作用域超出了当前方法或线程,其他方法或线程可以访问到这个对象。
java
// 不逃逸的例子
public void noEscape() {
Point p = new Point(1, 2); // 对象p只在本方法内使用
int x = p.x;
int y = p.y;
System.out.println(x + y);
// p不会"逃逸"出这个方法
}
// 方法逃逸的例子
public Point escape() {
Point p = new Point(1, 2);
return p; // p"逃逸"出了这个方法
}
// 线程逃逸的例子
public void threadEscape() {
Point p = new Point(1, 2);
new Thread(() -> {
System.out.println(p.x); // p被其他线程访问,线程逃逸
}).start();
}部分逃逸指的是对象在某些执行路径上逃逸,但在其他路径上不逃逸。
java
public void partialEscapeExample(boolean condition) {
Point p = new Point(10, 20); // 创建对象
if (condition) {
System.out.println(p.x + p.y); // 在这里使用,没有逃逸
} else {
storeInCache(p); // 假设这个方法让p逃逸了
}
}
// 在上面的例子中:
// - 当condition为true时,p没有逃逸
// - 当condition为false时,p逃逸了
// 这就是"部分逃逸"对部分逃逸的优化
java
// 原始代码
public int example(boolean condition) {
Point p = new Point(10, 20); // 看起来需要分配对象
if (condition) {
return p.x + p.y; // 只在这里使用对象,所以没有部分逃逸
} else {
return 0;
}
}
// Graal的优化:完全避免对象分配 可以减少gc次数
public int example(boolean condition) {
// 不再创建Point对象
int temp_x = 10; // 直接使用值
int temp_y = 20; // 直接使用值
if (condition) {
return temp_x + temp_y; // 直接使用局部变量
} else {
return 0;
}
}总结
核心概念 :Java通过"前端编译"(javac编译成字节码)和"后端编译"(JIT编译成机器码)两阶段实现跨平台执行。
执行模式 :
- 解释执行 (-Xint):逐条翻译字节码,启动快但性能低
- 编译执行 (-Xcomp):首次调用即编译,性能高但启动慢
- 混合执行 (-Xmixed,默认):先解释执行,热点代码再JIT编译 热点代码识别 :通过方法调用计数器(阈值10000)和回边计数器(阈值10700)识别频繁执行的代码进行JIT编译。
编译器类型 :
- C1编译器 (Client):注重启动速度,局部优化
- C2编译器 (Server):关注全局优化,性能提升30%+
- Graal编译器 (JDK9+):Java编写,支持更激进的优化 主要优化技术 :
- 常量传播/折叠 :编译期计算常量表达式
- 方法内联 :避免方法调用开销
- 逃逸分析 :实现栈上分配和标量替换
- 锁消除 :消除无竞争的同步代码
- Global Value Numbering :消除重复计算
- 窥孔优化 :局部指令序列优化
Graal特色优化 :
- 虚函数内联:运行时类型推断实现内联
- 部分逃逸分析:针对条件逃逸的对象进行优化 JVM执行引擎通过这些技术实现了接近编译型语言的性能,同时保持了Java的跨平台特性。