因为我们日常开发中用的最多的存储引擎,目前就是InnoDB这个存储引擎了,所以今天主要是探讨一下InnoDB存储引擎中的索引。从物理存储的角度来对索引进行分类,可以分为聚簇索引和二级索引。
下面我们直接来看一下例子:
mysql
create table user_info
(
id bigint auto_increment comment '主键'
primary key,
age int null comment '年龄',
name varchar(50) default '' null comment '姓名',
address varchar(200) default '' null comment '住址'
)
comment '用户信息';
create index idx_name
on user_info (name);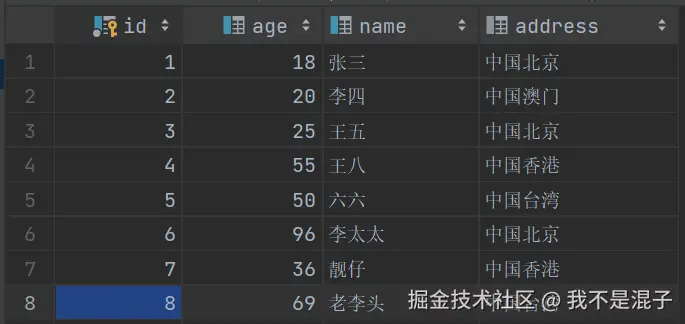
我们建了一张用户信息表,包含id主键、age、name、address四个字段,指定该表所使用的存储引擎为InnoDB,插入了8条数据以供测试。在这个例子中,user_info表的聚簇索引是建立在id字段上的,我们把主键id插入b+tree得到下图:
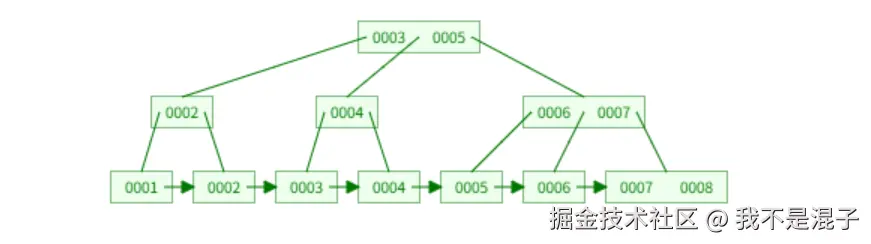
由此,我们可以画出id索引树:
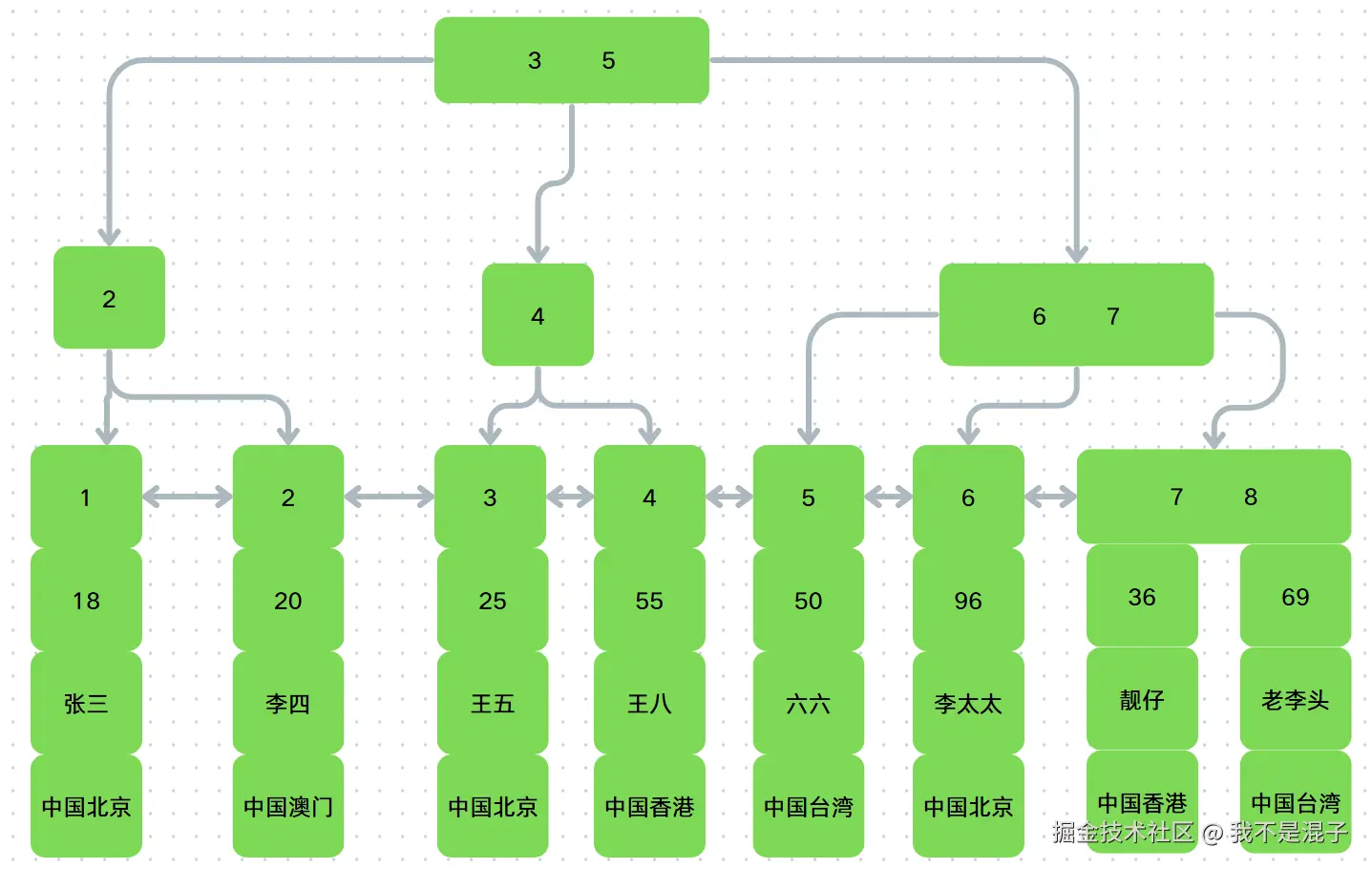
从图中可以看出,聚簇索引的每个叶子节点存储了一行完整的表数据,叶子节点间用双向链表按照id列递增连接起来,可以很方便的进行顺序检索。
InnoDB表是要求必须有聚簇索引的,默认是在主键字段上建立。如果你的表没有主键,那么默认表的第一个not null的唯一索引将被建立为聚簇索引,在前两者都没有的情况下,InnoDB将自动生成一个隐式自增id列并在此列上创建聚簇索引。
然后我们再来看看二级索引,我们是在表中的name字段上加了二级索引idx_name。
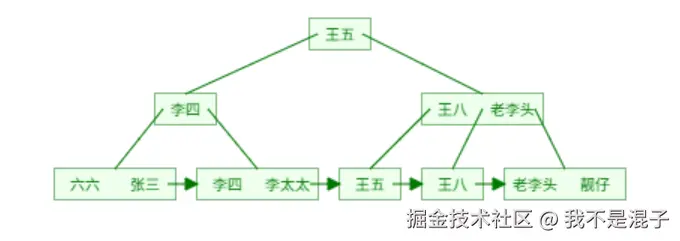
由此,我们可以画出idx_name索引树:
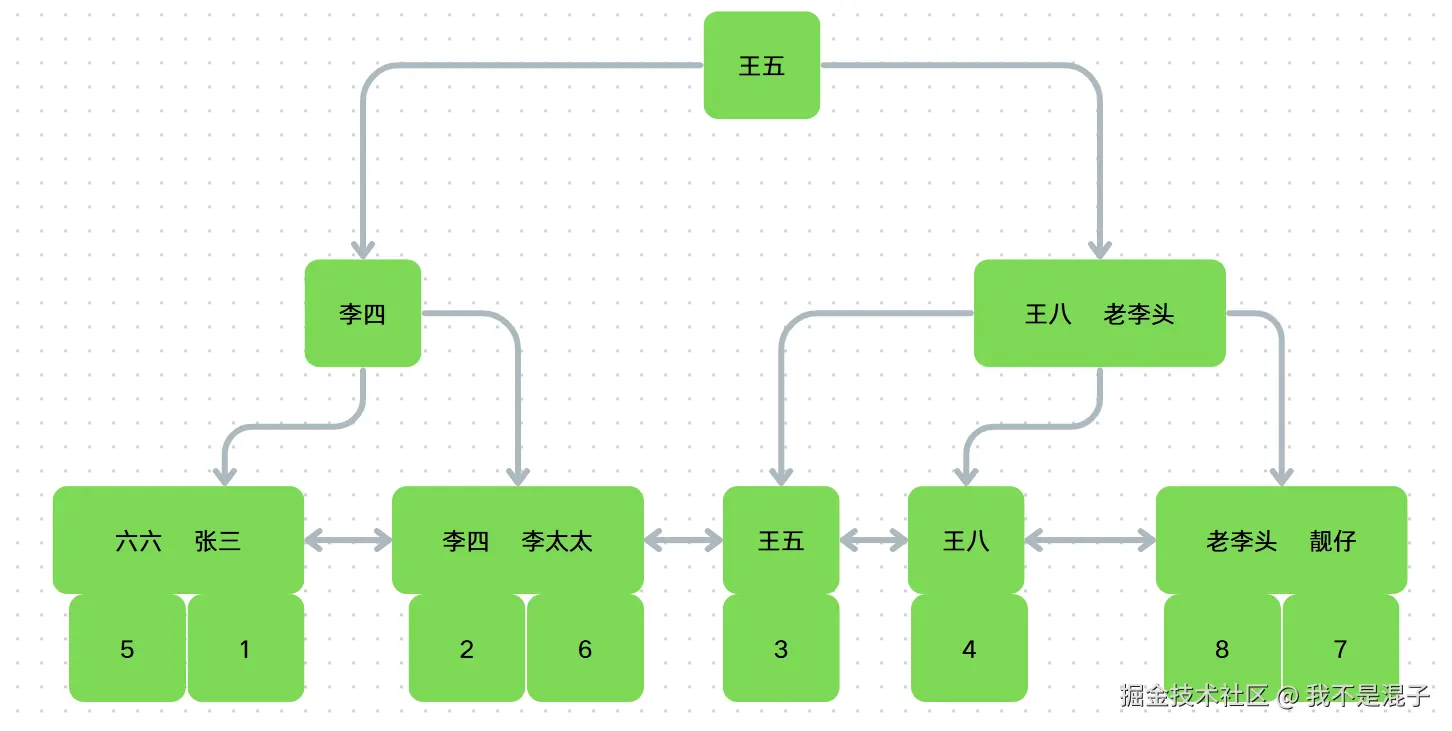
从图中我们可以看出二级索引的叶子节点并不是存储一行完整的表数据,而是存储了索引字段的值和聚簇索引所在列的值,也就是id列的值。
由于二级索引的叶子节点不存储完整的表数据,所以如果你的查询sql有索引字段以外的字段,那么就需要回到聚簇索引中去进一步获取数据。
举个例子:
mysql
select * from user_info where name = '王五';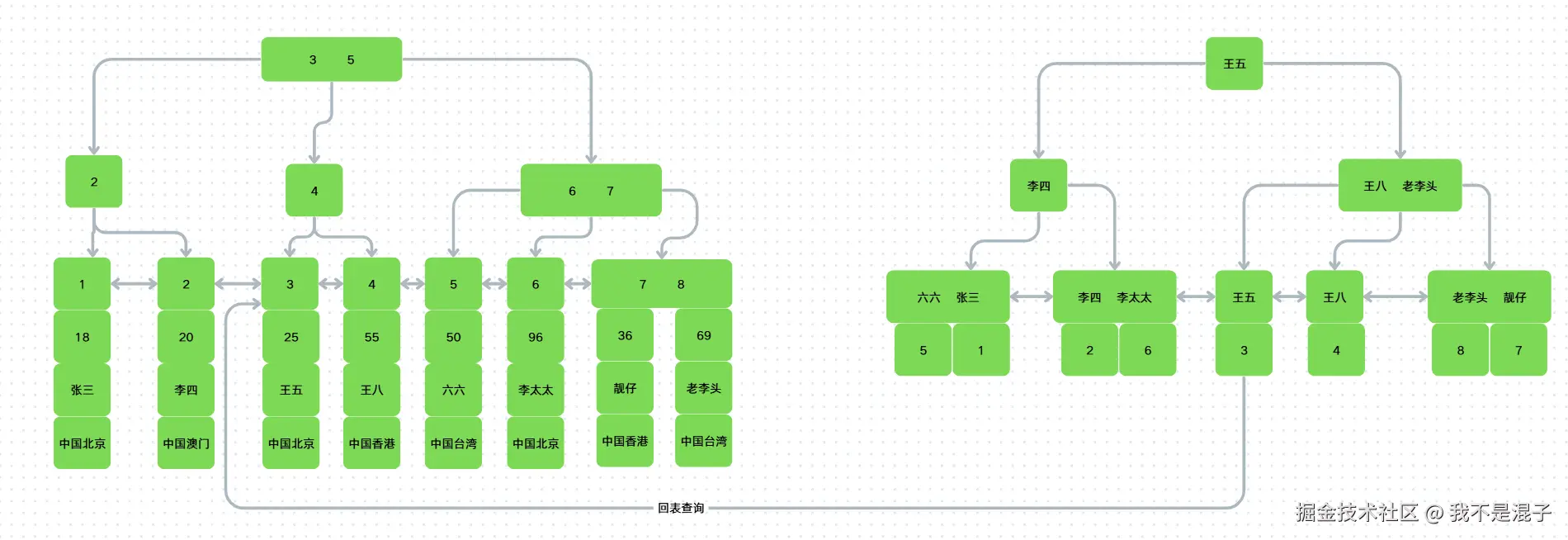
在二级索引idx_name中查询到主键id=3,接着带着id=3这个条件,回到聚簇索引查询剩下的age和address字段,很明显,回表操作需要额外的B+tree搜索过程,会增加查询耗时。当然了,回表这个过程不是必须的,当查询的字段在二级索引中都能找到时,就不需要回表,MySQL称此时的二级索引为覆盖索引或称触发了索引覆盖。
举个例子:
mysql
select id,name from user_info where name = '王五';这条sql只查询了id字段和name字段,二级索引中已经包含了需要查询的所有字段,所以就不用回表了。