一、穿透问题
1、什么是缓存穿透?
访问缓存中没有,数据库中也没有的数据,感觉像穿透了缓存层,直达数据库,每次请求都会访问到数据库,当同时存在大量发送这类请求,遭受到恶意攻击,可能直接压垮数据库。
2、如何解决缓存穿透?
2.1、对查询结果为 null 的数据,也在缓存中存储一个空值(如null或""),并设置较短的过期时间(如 5 分钟),避免同个无效请求反复穿透。
2.2、使用布隆过滤器
在缓存前加一层布隆过滤器,预先存储所有可能存在的有效 key(如数据库中所有用户 ID)。请求来时先过过滤器,不存在的 key 直接拦截,不进入缓存和数据库。 查询缓存前,先判断当前key在布隆过滤器中是否存在,一定不存在则直接返回,有可能存在则查询缓存
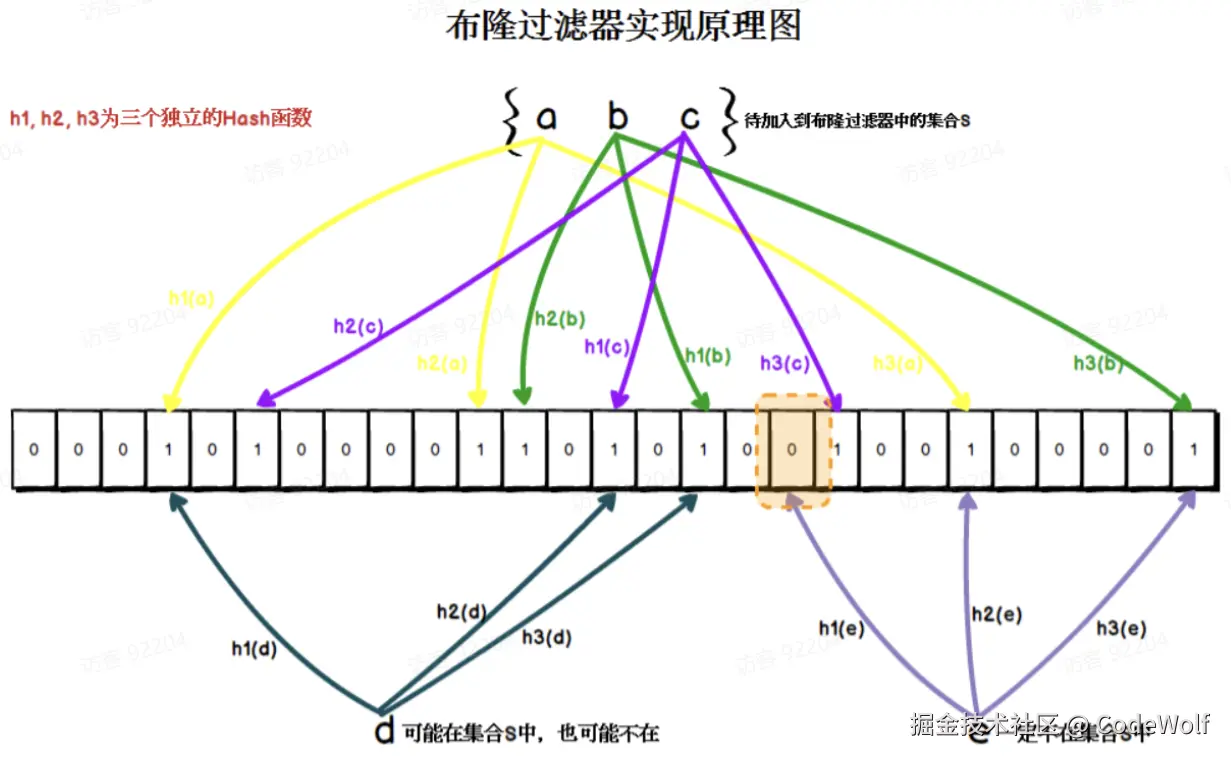 步骤:1、在将数据存入Redis时,会同时存储一个Redis的键到布隆过滤器中,会通过布隆过滤器提供的多个Hash函数对Key进行Hash运算,再对位数组长度进行取余,得到一个下标,将该下标值设置为1
步骤:1、在将数据存入Redis时,会同时存储一个Redis的键到布隆过滤器中,会通过布隆过滤器提供的多个Hash函数对Key进行Hash运算,再对位数组长度进行取余,得到一个下标,将该下标值设置为1
2、在查询时,会先按存储Redis到布隆过滤器中的方法,去判断当前的Key是否在布隆过滤器中,结果有两种: 一定不存在【位数组对应的下标上有一个或多个是0】,直接返回 有可能存在【位数组对应的下标上每个对应值都1】,查Redis
二、击穿问题
1、什么是缓存击穿?
某个 "热点 key" 突然失效(过期或被删除),而此时恰好有大量并发请求访问该 key,瞬间所有请求都穿透到数据库,造成数据库压力骤增。
场景 :比如电商大促时,某个热门商品的缓存突然过期,瞬间 thousands 级请求同时查询该商品,直接冲击数据库。
2、如何解决缓存雪崩?
-
分布式锁 :当缓存失效时,不是所有请求都去查数据库,而是用分布式锁(如 Redis 的
setnx)控制,只让一个请求去数据库查询并更新缓存,其他请求等待重试。例:请求发现缓存失效 → 尝试
setnx lock:product:100 1 EX 5→ 拿到锁的请求查库更新缓存 → 释放锁 → 其他请求重试时命中缓存。 -
热点 key 永不过期:
- 从缓存层面:不设置过期时间(但需业务层定期主动更新,避免数据陈旧)。
- 从逻辑层面:设置过期时间,但另起线程在过期前主动更新缓存(如过期前 10 分钟刷新)。
-
接口限流或者降级
三、缓存雪崩(Cache Avalanche)
本质 :大量缓存 key 在同一时间集体失效 (如缓存服务宕机,或大量 key 设置了相同过期时间),导致海量请求瞬间全部打到数据库,数据库无法承受压力而崩溃。场景:比如凌晨 3 点对所有商品缓存设置了 24 小时过期,次日凌晨 3 点所有商品缓存同时失效,恰逢用户高峰期,数据库被瞬间压垮。
解决方案:
- 过期时间随机化 :给不同 key 的过期时间加一个随机值(如
EX 3600 + Math.random()*1000),避免大量 key 同时过期。 - 缓存集群高可用:部署 Redis 集群(主从 + 哨兵或 Redis Cluster),避免单节点宕机导致整个缓存服务不可用。
- 服务熔断与限流:用 Sentinel、Hystrix 等组件对数据库请求限流,当请求量超过阈值时,直接返回降级结果(如 "系统繁忙"),保护数据库。
- 多级缓存:增加本地缓存(如 Caffeine),即使分布式缓存失效,本地缓存也能承接部分请求,减少对数据库的冲击。