文章首发于微信公众号《itThinking》, 原文链接:mp.weixin.qq.com/s/sP7s9yHte...
Mapping也叫映射,是elasticsearch中定义文档极其包含的字段如何存储和如何索引的流程。类似于Mysql中的表结构中字段定义(字段名、字段类型等)以及索引。在Mapping中,定义字段名,字段类型,字段所用分词器、索引等属性。
映射基础操作
下面有一个简单的设置和查看mapping的例子。
创建映射
perl
PUT /my-index //对my-index显示建立映射
{
"mappings": {
"properties": {
"age": { "type": "integer" }, //包含字段age, 类型为integer
"email": { "type": "keyword" }, //包含字段email, 类型为keyword, 不进行分词
"name": { "type": "text" } //包含字段name, 类型为text
}
}
}更新映射
支持新增映射字段。
perl
PUT /my-index/_mapping
{
"properties": {
"employee-id": { //新增employee-id
"type": "keyword",
"index": false
}
}
}因为更新现有字段可能导致索引无效,所以不支持更新现有字段。如果只是想要更改字段名,可以使用alias参数设置别名指向原始字段。
perl
PUT /my-index/_mapping
{
"properties": {
"name_alias": {
"type": "alias",
"path": "name"
}
}
}如果确实需要更改现有字段,需要新建索引设置映射,使用reindex指令在新索引上进行重建。
json
POST _reindex
{
"source": {
"index": "twitter"
},
"dest": {
"index": "new_twitter"
}
}查看映射
perl
GET /my-index/_mapping返回映射配置
json
{"my-index":{"mappings":{"properties":{"age":{"type":"integer"},"email":{"type":"keyword"},"employee-id":{"type":"keyword","index":false},"name":{"type":"text"},"name_alias":{"type":"alias","path":"name"}}}}}查看指定字段
perl
GET /my-index/_mapping/field/employee-id返回
json
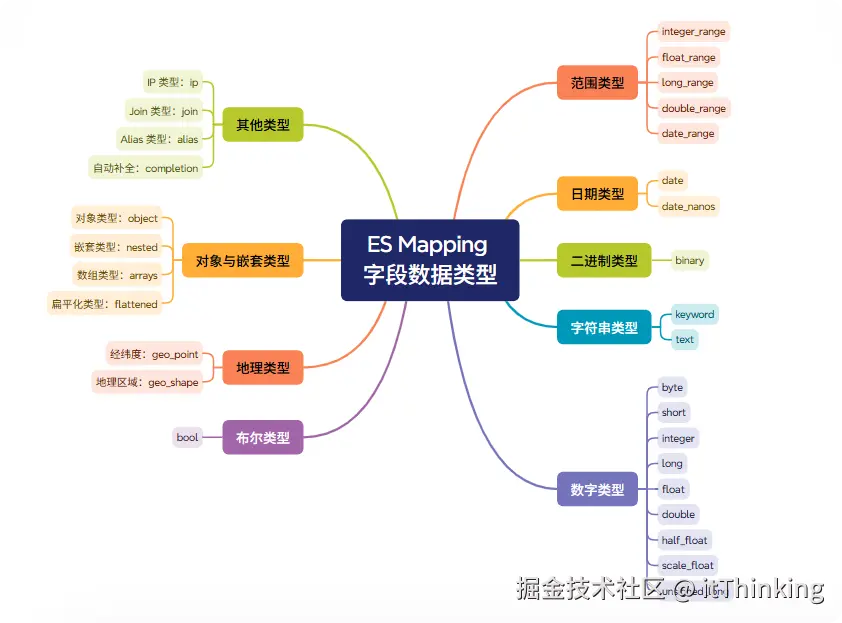
{"my-index":{"mappings":{"employee-id":{"full_name":"employee-id","mapping":{"employee-id":{"type":"keyword","index":false}}}}}}字段数据类型
在映射配置中,type定义了字段的类型。elasticsearch定义了数字类型,布尔,字符串、时间类型,json对象,除此之外还定义空间数据、文档排名、文本搜索类型。对于字符串类型,有一个点需要注意,,eleasticsearch会进行分词建立索引。
| 大类 | 类型名称 | 说明 | 对应java类型 |
|--------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------|----------|---------------|---|
| 字符串 | text | 字段内容会被分词,适合match模糊搜索 | String |
| keyword | 跟text的区别是keyword保留完整字段,适合term精确查找 | String | |
| 数值 | long | 64 位有符号整形 | long |
| integer | 32 位有符号整形 | int | |
| short | 16 位有符号整形 | short | |
| byte | 8 位有符号整形。 | byte | |
| double | 双精度 64位浮点类型 | double | |
| float | 单精度 32位浮点类型 | float | |
| half_float | 半精度16位浮点类型, 范围从2-24~65504 | float | |
| scaled_float | 缩放类型浮点数, 配合缩放因子scaling_factor一起使用。ES索引时,原始值会乘以该缩放因子并四舍五入得到新整形值,ES内部储存的是这个新值,但返回结果仍是原始值,好处是整型比浮点型更易压缩,节省磁盘空间。比如:假设scale_factor为100, scaled_float = 10.25, 在es内部存储时为1025 | float | |
| 日期 | date | 存储最高精度为毫秒。配合format使用:strict_date_optional_time | | epoch_millis。 | |
| date_nanos | date的补充,最高精度是纳秒,高精度意味着可存储的日期范围小,即:从大约 1970 到 2262。 | | |
| 布尔类型 | boolean | 布尔类型。 | boolean |
| 二进制 | binary | 存储二级制数据。 | |
| 对象类型 | object | 简单json类型。 | json对象 |
| nested | 嵌套类型,解决object下数组内部对象之间没有关联的问题。比如:{"user":{"first":"John","last":"Smith"},{"first":"Alice","last":"White"}}在object下转换成:{"user.first":"alice","john","user.last":"smith","white"},丢失了John和Smith, Alice和White是配套的关系。 | json对象 | |
| 地理类型 | geo_point | 纬度和经度点。 | |
| geo_shape | 复杂的形状,例如多边形 | | |
| | ip | ipv4或者ipv6地址 | |
字符串类型
从 ES 7.x 之后的版本中,字符串类型只有 keyword 和 text 两种了,旧版本的 string 类型已不再支持。为什么要区分两者?这源于我们处理字符串数据时的两种最基本的需求:
- 全文检索:需要将一段文本(如产品描述、文章内容)进行分词,拆分成一个个独立的单词(或词元),然后建立倒排索引。这样用户才能通过搜索某个单词,找到所有包含该单词的文档。这个过程关注的是"内容是否相关"。
- 精确匹配:需要将字符串作为一个完整的、不可分割的整体来处理。常用于过滤(如查询城市是否为"北京")、排序、聚合(如按产品类型分组统计)。这个过程关注的是"值是否完全相等"。
Elasticsearch 通过 text和 keyword两种类型来完美满足这两种截然不同的需求。
Text 类型
设计目标:用于全文检索。
特点:
- 分词:
-
- 这是 text类型最核心的特征。在创建索引(入库)时,一个text字段的值会被传递给一个分词器。
- 分词器会做一系列处理:如拆分文本("Quick brown fox" -> "quick", "brown", "fox")、转换小写、移除停用词(a, the, is)和标点符号等。
- 最终,被索引的是这些拆分后的词元,而不是原始文本。
- 倒排索引:
-
- 分词后的词元会被存入倒排索引结构中。这使得 Elasticsearch 能够高效地查找包含某个词元的所有文档。
- 不支持精确匹配和排序/聚合:
-
- 因为你搜索的是被分词的词元,所以无法精确匹配整个原始字符串。
- 同样,基于分好词的词元进行排序或聚合通常没有意义(例如,你对文章内容字段做terms聚合,会得到一堆单词,而不是有意义的类别)。
使用场景:
- 产品描述、文章正文、邮件内容、日志消息等任何需要被用户搜索的文本内容。
perl
PUT /my-index/_mapping
// 映射定义
{
"mappings": {
"properties": {
"product_description": {
"type": "text" // 定义为 text 类型
}
}
}
// 存入数据: "This is an amazing coffee grinder!"
// 索引中存储的可能是: ["amazing", "coffee", "grinder"]
// 查询: 搜索 "coffee"
// 可以匹配到该文档,因为 "coffee" 存在于倒排索引中。
// 查询: 搜索 "This is a grinder"
// 也可能匹配到,因为 "grinder" 存在,其他词是停用词被忽略。
// 查询: 精确匹配 "This is an amazing coffee grinder!"
// 无法匹配,因为原始句子已经被拆分处理了。Keyword 类型
设计目标:用于精确值匹配、过滤、排序和聚合。
特点:
- 不分词:
-
- 字段值会被视为一个完整的、不可分割的整体。
- 它会将整个字符串(包括空格和标点)原封不动地存入索引。
- Doc Values:
-
- keyword类型默认使用 Doc Values 数据结构,这是一种按列式存储的、磁盘友好的格式。
- Doc Values 使得对字段进行排序、聚合和脚本访问非常高效。
- 支持精确匹配:
-
- 可以精确查找与输入值完全一致的文档。
使用场景:
- 身份证号、邮箱地址、主机名、状态码、邮政编码、标签(tags)、业务状态(如"paid", "shipped")、用于排序的字段等。
json
// 映射定义
{
"mappings": {
"properties": {
"order_status": {
"type": "keyword" // 定义为 keyword 类型
}
}
}
}
// 存入数据: "shipped"
// 索引中完整存储为: "shipped"
// 查询: 精确匹配 "shipped"
// 可以成功找到该文档。
// 查询: 搜索 "ship"
// 无法找到,因为索引中是完整的 "shipped",不会进行部分匹配。
// 聚合: 对 `order_status` 字段做 `terms` 聚合,可以清晰地得到每个状态的数量(如 "paid": 100, "shipped": 50)。总结
- 全文搜索用 text + match 查询。
- 精确匹配用 keyword 子字段 + term 查询。
- 中文场景必用 ik 分词器。
- 重要字段同时定义 text 和 keyword 类型。
数值类型
ES 中,数值类型分为 byte、short、integer、long、float、double、half_float、scaled_float、unsigned_long。在满足需求的前提下,应当选择尽可能小的数据类型,除了可能会减少存储空间外,也会提高索引数据和检索数据的效率。
日期类型
类似于Mysql, Elasticsearch 会将其转换为自 Unix 纪元(1970-01-01 00:00:00 UTC)以来的毫秒数。
perl
PUT /my-index/_mapping
//映射定义
{
"properties": {
"create_timestamp": {
"type": "date",
"format": "strict_date_optional_time ||epoch_millis"
},
"create_time": {
"type": "date",
"format": [
"yyyy-MM-dd HH:mm:ss"
]
}
}
}
//存入数据{"create_time":"2025-09-19 15:20:22","create_timestamp":"2025-09-19T07:20:22.645Z"}对象类型
对象类型用于表示一个拥有层次结构的 JSON 对象。它允许你将一个文档中的一组相关属性逻辑上分组在一起,形成嵌套结构。这非常符合现实世界数据的模型。
其内部存储非 Json 格式,通过分隔符 "." 建立层级关系。默认情况下,业务字段强烈不建议使用 "." 分隔符, 最简单有效的方法是使用下划线等替代符号。
json
//映射定义
{
"properties": {
"user": {
"properties": {
"first": { "type": "keyword" },
"last": { "type": "keyword" },
"age": { "type": "integer" }
}
}
}
}
//插入数据
{
"user": {
"first": "John",
"last": "Smith",
"age": 25
}
}
//在底层,这个文档实际上会被存储为类似这样的结构:
{
"user.first": "John",
"user.last": "Smith",
"user.age": 25
}
//查询
{
"query": {
"match": {
"user.first_name": "John" // 使用 user.first_name 路径
}
}
}这种扁平化带来的好处和限制:
- 好处:查询和过滤时可以像访问顶级字段一样使用点号路径(例如 user.first),非常方便高效。
- 限制:对象内部字段之间的关联性在底层丢失了。这会导致一些问题(我们将在与nested类型对比时详细说明)。
动态映射
eleasticsearch支持动态mapping, 当插入文档时,不必先创建mapping, 只需建好索引,系统会根据字段自动映射。
| 字段类型 | 自动映射类型 |
|---|---|
| true/false | boolean |
| 小数 | float |
| 数字 | long |
| object | object |
| 数组 | 取决于数组中的第一个非空元素的类型 |
| 日期格式字符串 | date |
| 数字类型字符串 | float/long |
| 其他字符串 | text + keyword |
除了上述字段类型之外,其他类型都必须显式映射,在映射配置中对字段显示申明要映射的类型。如果希望对符合某类要求的特定字段制定映射,就需要用到动态映射模板。
动态映射模板语法
rust
"dynamic_templates": [
{
"my_template_name": { //模板名
... match conditions ... //匹配参数,支持match_mapping_type, match, match_pattern, unmatch, path_match, path_unmatch
"mapping": { ... } //字段被映射配置
}
},
...
]动态映射模板参数:
- match_mapping_type:数据类型匹配字段
- match和unmatch:名称匹配字段,支持正则表达式, 支持数组。
- path_match和path_unmatch :路径匹配字段, 支持数组
示例:
perl
PUT my-index-000001
{
"mappings": {
"dynamic_templates": [
{
"integers": {
"match_mapping_type": "long",
"mapping": {
"type": "integer"
}
}
},
{
"strings": {
"match_mapping_type": "string",
"match": "num_*",
"unmatch": "*_text",
"mapping": {
"type": "text",
"fields": {
"raw": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
{
"full_name": {
"path_match": "name.*",
"path_unmatch": "*.middle",
"mapping": {
"type": "text",
"copy_to": "full_name"
}
}
}
]
}
}
//插入数据
PUT my-index-000001/_doc/1
{
"long_num": "5",
"long_text": "foo"
}
//插入数据
PUT my-index/_doc/2
{
"one_ip": "will not match",
"ip_two": "will not match",
"three_ip": "12.12.12.12",
"ip_four": "13.13.13.13"
}
//插入数据
PUT my-index-000001/_doc/3
{
"name": {
"first": "John",
"middle": "Winston",
"last": "Lennon"
}
}以上代码会产生以下效果:
- 所有 long 类型字段会默认映射为 integer。
- 所有文本字段,如果是以 num_ 开头,并且不以 _text 结尾,会自动映射为 keyword 类型。
- name json对象内的字段,除掉middle之外,其他 都会被映射为text类型。
ES 索引 Mapping 字段限制
关于 ES 索引 Mapping 字段限制如下:
- 索引字段数量限制
- 映射爆炸限制
- 索引字段长度与深度限制
- 数据类型相关限制
- 动态映射的潜在风险
- 硬性资源限制
索引字段数量限制
这是最直接、最常见的限制。Elasticsearch 并非不能处理大量字段,但字段过多会带来显著的开销。
问题根源:
- 内存开销:Lucene(ES 的底层引擎)的核心数据结构是"倒排索引"。每个字段都有自己的倒排索引、字典(Term Dictionary)和文档值(Doc Values)。这些结构都需要加载到内存(文件系统缓存)中以实现高效搜索和聚合。字段越多,内存消耗越大。
- 性能下降:大量的字段会导致映射(Mapping)元数据变得非常庞大。在创建新文档、执行搜索或聚合时,处理这些元数据会增加 CPU 和内存的开销。
- 熔断器风险:容易触发下一节要提到的"映射爆炸"熔断器。
实际限制:
- 没有绝对的硬性数字:官方从未规定一个确切的数字(如 1000 个字段)。性能拐点取决于你的硬件资源(特别是内存)、文档大小和查询复杂度。
- 经验值:通常,建议将字段数量控制在 几百到一千 以内。一旦超过几千个,就需要非常小心地评估和优化。
- 默认熔断器:ES 默认设置了一个索引最大字段数为 1000。这是一个软限制,旨在防止意外创建过多字段。
映射爆炸限制
这是字段数量限制的延伸和强化,旨在防止一个恶意或错误的请求摧毁整个集群。
问题场景:
想象一个场景,你的索引启用了动态映射("dynamic": true)。如果有一个包含大量随机键值对(例如,HTTP 请求头、随机生成的用户数据)的文档被写入,它会瞬间创建成百上千个新字段,耗尽节点内存,导致节点崩溃。
相关设置:
- index.mapping.total_fields.limit:单个索引中的最大字段数,默认 1000。
- index.mapping.depth.limit:字段的最大深度(防止过于复杂的嵌套 JSON),默认 20。
- index.mapping.nested_fields.limit:嵌套类型(nested)字段的最大数量,默认 50。因为每个嵌套对象都被索引为一个独立的隐藏文档,开销很大。
- index.mapping.nested_objects.limit:单个文档中所有嵌套类型字段所能包含的最大嵌套对象总数,默认 10000。
- index.mapping.field_name_length.limit:字段名称的最大长度限制,默认 Long.MAX_VALUE(实际上非常长,但设置太长的名称不推荐)。
- index.mapping.dimension_fields.limit:它是 Elasticsearch 7.13+ 版本引入的关键特性限制,专为 时间序列数据(如指标和日志) 设计的。
索引字段长度与深度限制
- 字段名长度:虽然限制很高,但过长的字段名(如 very_long_and_descriptive_field_name_that_is_self_explanatory)会显著增加映射和传输数据的开销。建议使用简短、清晰的字段名。
- 字段深度:指的是 JSON 结构的嵌套层级。
json
{
"level1": {
"level2": {
"level3": { // 深度为 3
"value": "data"
}
}
}
}- 过深的嵌套会让查询和聚合变得复杂且低效。默认深度限制为 20,通常足够了。
数据类型相关限制
某些特定的数据类型有其自身的限制。
- keyword 类型:
- 长度限制:ignore_above 参数。默认情况下,超过 256 个 UTF-8 编码字节的字符串不会被索引(即无法被搜索或聚合),但原始数据仍然会存储在 _source 中。
json
"my_field":{
"type":"keyword",
"ignore_above":512// 可以自定义调整
}- 影响:这可以防止极其长的字符串(如文件内容、大段 Base64)被加入倒排索引,从而节省大量内存。
- text 类型:
- 分析器限制:text 字段会被分词,分词后的词项(terms)数量受限于分析器(Analyzer)和原始文本长度。一个非常长的句子可能会产生成千上万个词项,增加索引大小。
- Term 长度限制:Lucene 内部对单个 Term 的长度也有限制(约 32KB)。
动态映射潜在风险
这本身不是一个"限制",但如果不加管理,它是导致触发上述所有限制的最主要原因。
风险:默认的动态映射行为会自动为每个新出现的字段创建映射并推断其类型。这非常方便,但也非常危险,容易导致"映射污染"(Mapping Pollution)或"映射爆炸"(Mapping Explosion)。
解决方案:
- 显式映射:在创建索引时,为核心业务字段预定义好映射。这是最佳实践。
- 严格控制动态映射:
- 设置为 "dynamic": "false":忽略未映射的新字段(不索引,但存储在 _source 中)。
- 设置为 "dynamic": "strict":遇到未映射的新字段时,直接抛出异常,拒绝写入文档。这是最严格、最安全的方式。
- 使用 flattened 数据类型:如果你确实需要存储大量不可预知的键值对(例如标签、HTTP 头、自定义属性),flattened 类型是完美的解决方案。它将整个子对象的所有值索引为一个"超级"字段,极大地节省内存并避免映射爆炸。
硬性资源限制
最终,所有限制都归结为硬件的限制。
- 堆内存:ES 节点的堆内存主要用于管理映射元数据、查询计算等。映射越大,可用堆内存就越少。
- 文件系统缓存:Lucene 依赖文件系统缓存来高效访问索引数据。字段越多,索引文件越大,对文件系统缓存的需求就越高。如果缓存不足,搜索性能会急剧下降(产生磁盘 I/O)。
参考:
1.zhuanlan.zhihu.com/p/433879838
2.blog.csdn.net/qq_39706570...
3.www.codebaoku.com/es/es-docum...
4.www.elastic.co/guide/en/el...
mp.weixin.qq.com/s?__biz=Mzg...
5.【ES 入门实战第五篇】ES 索引 Mapping 常用字段类型、 高级字段类型、字段限制深度实战