LLVM IR 层次结构基本介绍
下图展示了 LLVM IR 的层次结构:
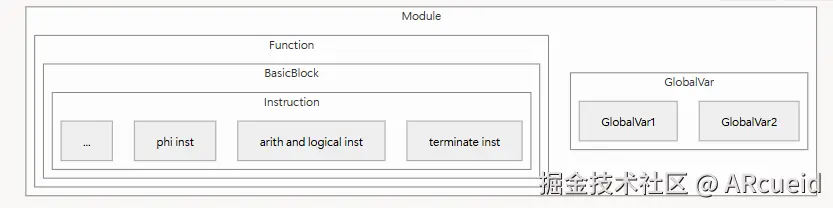
层次结构概述
Module(模块) 是 IR 的最外层结构,作为顶层容器,每个 Module 至少包含一个 Function,是一个完整的编译单元。它通常对应一个源文件或链接后的结果,包含了生成代码所需的所有信息。
Module 的核心作用
- 代码与数据的容器:Module 承载了所有的函数、全局变量和全局元数据,这意味着编写的代码和全局数据最终都会被组织在一个或多个 Module 中。
- 独立的编译单元 :每个 Module 通常对应于源代码的一个翻译单元(如
.c或.cpp文件),包含了生成目标代码所需的全部信息,可以独立进行优化和代码生成。 - 链接的基础 :多个 Module 可以被 LLVM 链接器合并,链接器会处理函数和全局变量的定义与声明,解析外部引用,并合并符号表。Module 中全局变量和函数的链接类型(如
private、internal、external、linkonce、weak等)决定了它们在链接时的行为。 - 优化的单元:许多 LLVM 的优化过程(Pass)以 Module 为粒度进行,优化器会分析 Module 中的 IR,并实施诸如内联、循环优化、死代码消除等变换。
Function(函数) 是 Module 中定义的函数集合,包括函数声明和定义,封装了可重用的代码单元,是优化和代码生成的主要对象。
BasicBlock(基本块) 组成 Function,每个 BasicBlock 包含一系列 LLVM 指令。
Instruction(指令) 是层次结构的最底层,每个 BasicBlock 是线性顺序排列的 Instruction 序列,有一个入口点和一个出口点。
无量表达式编译器实现
测试文件
expr.txt 内容如下:
ini
2 + 3 * 5; 1 + 2 -3;
(2 + 1) * 4 / 6;词法分析器(Lexer)
词法分析器负责将字符流(char stream)转换为标记(token)。token 是源代码经过词法分析后得到的最小语义单元。
文法定义
css
prog : (expr? ";")*
expr : term (("+" | "-") term)* ;
term : factor (("*" | "/") factor)* ;
factor : number | "(" expr ")" ;
number: ([0-9])+ ;实现代码
lexer.h
cpp
#pragma once
#include "llvm/ADT/StringRef.h"
#include "llvm/Support/raw_ostream.h"
enum class TokenType {
unknown, // 未知
number, // [0-9]+
plus, // +
minus, // -
star, // *
slash, // /
l_parent, // (
r_parent, // )
semi, // ;
eof // 文件结束
};
class Token {
public:
Token() {
row = col = -1;
tokenType = TokenType::unknown;
value = -1;
}
void Dump();
public:
int row, col;
TokenType tokenType;
int value;
llvm::StringRef content;
};
class Lexer {
public:
Lexer(llvm::StringRef sourceCode);
void NextToken(Token& token);
public:
const char* BufPtr;
const char* LineHeadPtr;
const char* BufEnd;
int row;
};lexer.cc
cpp
#include "lexer.h"
void Token::Dump() {
llvm::outs() << "{" << content << ", row = " << row << ", col = " << col << "}\n";
}
bool IsWhiteSpace(char ch) {
return ch == ' ' || ch == '\r' || ch == '\n';
}
bool IsDigit(char ch) {
return ch >= '0' && ch <= '9';
}
Lexer::Lexer(llvm::StringRef sourceCode) {
BufPtr = sourceCode.begin();
LineHeadPtr = sourceCode.begin();
BufEnd = sourceCode.end();
row = 1;
}
void Lexer::NextToken(Token &token) {
token.row = row;
while (IsWhiteSpace(*BufPtr)) {
if (*BufPtr == '\n') {
row += 1;
LineHeadPtr = BufPtr + 1;
}
++BufPtr;
}
token.col = BufPtr - LineHeadPtr + 1;
if (BufPtr >= BufEnd) {
token.tokenType = TokenType::eof;
return;
}
const char* start = BufPtr;
if (IsDigit(*BufPtr)) {
int len = 0;
int val = 0;
while (IsDigit(*BufPtr)) {
val = val * 10 + *BufPtr++ - '0';
++len;
}
token.value = val;
token.tokenType = TokenType::number;
token.content = llvm::StringRef(start, len);
} else {
switch (*BufPtr) {
case '+': {
token.tokenType = TokenType::plus;
token.content = llvm::StringRef(start, 1);
BufPtr++;
break;
}
case '-': {
token.tokenType = TokenType::minus;
token.content = llvm::StringRef(start, 1);
BufPtr++;
break;
}
case '*': {
token.tokenType = TokenType::star;
token.content = llvm::StringRef(start, 1);
BufPtr++;
break;
}
case '/': {
token.tokenType = TokenType::slash;
token.content = llvm::StringRef(start, 1);
BufPtr++;
break;
}
case '(': {
token.tokenType = TokenType::l_parent;
token.content = llvm::StringRef(start, 1);
BufPtr++;
break;
}
case ')': {
token.tokenType = TokenType::r_parent;
token.content = llvm::StringRef(start, 1);
BufPtr++;
break;
}
case ';': {
token.tokenType = TokenType::semi;
token.content = llvm::StringRef(start, 1);
BufPtr++;
break;
}
default: {
token.tokenType = TokenType::unknown;
BufPtr++;
break;
}
}
}
}测试结果
输出与测试文件一致,验证了 Lexer 的正确性。
语法分析器(Parser)
语法分析器根据语法规则将 token 组织成抽象语法树(AST)。
实现代码
ast.h
cpp
#pragma once
#include <vector>
#include <memory>
#include "llvm/IR/Value.h"
enum class OpCode { add, sub, mul, div };
class Program;
class Expr;
class BinaryExpr;
class FactorExpr;
class Visitor {
public:
virtual ~Visitor() {}
virtual llvm::Value* VisitProgram(Program* p) = 0;
virtual llvm::Value* VisitBinaryExpr(BinaryExpr* binaryExpr) = 0;
virtual llvm::Value* VisitFactorExpr(FactorExpr* factorExpr) = 0;
};
class Expr {
public:
virtual ~Expr() {}
virtual llvm::Value* Accept(Visitor* v) { return nullptr; }
};
class BinaryExpr : public Expr {
public:
llvm::Value* Accept(Visitor* v) override {
return v->VisitBinaryExpr(this);
}
public:
OpCode op;
std::shared_ptr<Expr> left;
std::shared_ptr<Expr> right;
};
class FactorExpr : public Expr {
public:
llvm::Value* Accept(Visitor* v) override {
return v->VisitFactorExpr(this);
}
public:
int number;
};
class Program {
public:
std::vector<std::shared_ptr<Expr>> ExprVec;
};parser.h
cpp
#pragma once
#include "ast.h"
#include "lexer.h"
class Parser {
public:
Parser(Lexer &lexer) : lexer(lexer) { Advance(); }
std::shared_ptr<Program> ParseProgram();
private:
std::shared_ptr<Expr> ParseExpr();
std::shared_ptr<Expr> ParseTerm();
std::shared_ptr<Expr> ParseFactor();
bool Expect(TokenType tokenType);
bool Consume(TokenType tokenType);
bool Advance();
private:
Lexer &lexer;
Token token;
};parser.cc
cpp
#include "parser.h"
#include <cassert>
std::shared_ptr<Program> Parser::ParseProgram() {
std::vector<std::shared_ptr<Expr>> ExprVec;
while (token.tokenType != TokenType::eof) {
if (token.tokenType == TokenType::semi) {
Advance();
continue;
}
auto expr = ParseExpr();
ExprVec.push_back(expr);
}
auto program = std::make_shared<Program>();
program->ExprVec = std::move(ExprVec);
return program;
}
std::shared_ptr<Expr> Parser::ParseExpr() {
std::shared_ptr<Expr> left = ParseTerm();
while (token.tokenType == TokenType::plus || token.tokenType == TokenType::minus) {
OpCode op = (token.tokenType == TokenType::plus) ? OpCode::add : OpCode::sub;
Advance();
auto binaryExpr = std::make_shared<BinaryExpr>();
binaryExpr->left = left;
binaryExpr->op = op;
binaryExpr->right = ParseTerm();
left = binaryExpr;
}
return left;
}
std::shared_ptr<Expr> Parser::ParseTerm() {
std::shared_ptr<Expr> left = ParseFactor();
while (token.tokenType == TokenType::star || token.tokenType == TokenType::slash) {
OpCode op = (token.tokenType == TokenType::star) ? OpCode::mul : OpCode::div;
Advance();
auto binaryExpr = std::make_shared<BinaryExpr>();
binaryExpr->left = left;
binaryExpr->op = op;
binaryExpr->right = ParseFactor();
left = binaryExpr;
}
return left;
}
std::shared_ptr<Expr> Parser::ParseFactor() {
if (token.tokenType == TokenType::l_parent) {
Advance();
auto expr = ParseExpr();
assert(Expect(TokenType::r_parent));
Advance();
return expr;
} else {
auto factorExpr = std::make_shared<FactorExpr>();
factorExpr->number = token.value;
Advance();
return factorExpr;
}
}
bool Parser::Expect(TokenType tokenType) {
return token.tokenType == tokenType;
}
bool Parser::Consume(TokenType tokenType) {
if (Expect(tokenType)) {
Advance();
return true;
}
return false;
}
bool Parser::Advance() {
lexer.NextToken(token);
return true;
}访问者模式实现
为了验证 AST,实现了 PrintVisitor 来打印表达式。
printVisitor.h
cpp
#pragma once
#include "ast.h"
#include "parser.h"
class PrintVisitor : public Visitor {
public:
PrintVisitor(std::shared_ptr<Program> program);
llvm::Value* VisitProgram(Program* p) override;
llvm::Value* VisitBinaryExpr(BinaryExpr* binaryExpr) override;
llvm::Value* VisitFactorExpr(FactorExpr* factorExpr) override;
};printVisitor.cc
cpp
#include "printVisitor.h"
PrintVisitor::PrintVisitor(std::shared_ptr<Program> program) {
VisitProgram(program.get());
}
llvm::Value* PrintVisitor::VisitProgram(Program* p) {
for (auto &expr : p->ExprVec) {
expr->Accept(this);
llvm::outs() << "\n";
}
return nullptr;
}
llvm::Value* PrintVisitor::VisitBinaryExpr(BinaryExpr* binaryExpr) {
binaryExpr->left->Accept(this);
binaryExpr->right->Accept(this);
switch (binaryExpr->op) {
case OpCode::add: llvm::outs() << " + "; break;
case OpCode::sub: llvm::outs() << " - "; break;
case OpCode::mul: llvm::outs() << " * "; break;
case OpCode::div: llvm::outs() << " / "; break;
}
return nullptr;
}
llvm::Value* PrintVisitor::VisitFactorExpr(FactorExpr* factorExpr) {
llvm::outs() << factorExpr->number;
return nullptr;
}测试结果
输出与预期一致,验证了 Parser 的正确性。
代码生成(CodeGen)
代码生成器将 AST 转换为 LLVM IR。
实现代码
codegen.h
cpp
#pragma once
#include "ast.h"
#include "parser.h"
#include "llvm/IR/LLVMContext.h"
#include "llvm/IR/Module.h"
#include "llvm/IR/IRBuilder.h"
class CodeGen : public Visitor {
public:
CodeGen(std::shared_ptr<Program> program) {
module = std::make_shared<llvm::Module>("expr", context);
VisitProgram(program.get());
}
llvm::Value* VisitProgram(Program* p) override;
llvm::Value* VisitBinaryExpr(BinaryExpr* binaryExpr) override;
llvm::Value* VisitFactorExpr(FactorExpr* factorExpr) override;
private:
llvm::LLVMContext context;
llvm::IRBuilder<> irBuilder{context};
std::shared_ptr<llvm::Module> module;
};codegen.cc
cpp
#include "codegen.h"
#include "llvm/IR/Verifier.h"
llvm::Value* CodeGen::VisitProgram(Program* p) {
auto printFunctionType = llvm::FunctionType::get(irBuilder.getInt32Ty(), {irBuilder.getInt8PtrTy()}, true);
auto printFunction = llvm::Function::Create(printFunctionType, llvm::GlobalValue::ExternalLinkage, "printf", module.get());
auto mainFunctionType = llvm::FunctionType::get(irBuilder.getInt32Ty(), false);
auto mainFunction = llvm::Function::Create(mainFunctionType, llvm::GlobalValue::ExternalLinkage, "main", module.get());
llvm::BasicBlock* entryBlock = llvm::BasicBlock::Create(context, "entry", mainFunction);
irBuilder.SetInsertPoint(entryBlock);
for (auto expr : p->ExprVec) {
llvm::Value* v = expr->Accept(this);
irBuilder.CreateCall(printFunction, {irBuilder.CreateGlobalStringPtr("expr value: %d\n"), v});
}
llvm::Value* ret = irBuilder.CreateRet(irBuilder.getInt32(0));
llvm::verifyFunction(*mainFunction);
module->print(llvm::outs(), nullptr);
return ret;
}
llvm::Value* CodeGen::VisitBinaryExpr(BinaryExpr* binaryExpr) {
auto left = binaryExpr->left->Accept(this);
auto right = binaryExpr->right->Accept(this);
switch (binaryExpr->op) {
case OpCode::add: return irBuilder.CreateNSWAdd(left, right, "add");
case OpCode::sub: return irBuilder.CreateNSWSub(left, right, "sub");
case OpCode::mul: return irBuilder.CreateNSWMul(left, right, "mul");
case OpCode::div: return irBuilder.CreateSDiv(left, right, "div");
}
return nullptr;
}
llvm::Value* CodeGen::VisitFactorExpr(FactorExpr* factorExpr) {
return irBuilder.getInt32(factorExpr->number);
}测试结果
生成的 IR 正确,LLVM 在 IR 层面进行了常量折叠,优化了表达式计算。
测试编译器
生成 IR 文件
bash
bin/expr test/expr.txt > test/expr.ll生成的 IR 内容
llvm
; ModuleID = 'expr'
source_filename = "expr"
@0 = private unnamed_addr constant [16 x i8] c"expr value: %d\0A\00", align 1
@1 = private unnamed_addr constant [16 x i8] c"expr value: %d\0A\00", align 1
@2 = private unnamed_addr constant [16 x i8] c"expr value: %d\0A\00", align 1
declare i32 @printf(ptr, ...)
define i32 @main() {
entry:
%0 = call i32 (ptr, ...) @printf(ptr @0, i32 17)
%1 = call i32 (ptr, ...) @printf(ptr @1, i32 0)
%2 = call i32 (ptr, ...) @printf(ptr @2, i32 2)
ret i32 0
}运行 IR
bash
lli test/expr.ll运行结果
bash
expr value: 17
expr value: 0
expr value: 2结果正确,验证了整个编译器的正确性和功能性。
注意:LLVM 在 IR 层面进行了常量折叠(Constant Folding),即在编译阶段计算常量表达式,减少了运行时的计算量,提高了效率。