在 AI 技术飞速发展的当下,数据作为 AI 的 "燃料",其形态与处理方式正发生深刻变革。本篇文章来自火山引擎LAS团队琚克俭在"2025AICon 全球人工智能开发与应用大会"分享,主要围绕 "AI 场景下多模态数据处理" 主题,介绍LAS团队基于 Daft+ Lance打造的多模态数据湖方案,为 AI 时代数据湖的建设提供全新思路。
AI 驱动下,数据湖场景的变革与挑战
传统数据湖更多聚焦于大数据领域的结构化数据处理,而 AI 场景的繁荣,正从存储、计算、数据管理等多个维度,对数据湖提出全新要求。
在存储侧,AI 场景下的数据来源愈发多元,多模态数据(如图片、视频等)大量涌现,同时还需满足结构化与非结构化数据统一存储的需求。不同于大数据场景对 "降低存储成本" 的追求,AI 场景更看重 "数据读取 IO 速度",以支撑高效的模型训练与推理。
计算侧的变化同样显著。过去大数据场景以纯 CPU 处理为主,而 AI 场景下,模型的引入催生了 CPU 与 GPU 异构的计算需求。此外,业务主导权向 AI 倾斜,数据处理范式也从大数据时代的 SQL,逐渐转向 AI 算法团队更熟悉的 Dataframe。
数据管理与应用层面也在迭代。数据源管理不再局限于 Database、table等,文件模型、函数等均需纳入管理范畴;上层应用也不断迎来爆发,未来还将向 agent、具身智能等场景延伸。
基于 湖计算Daft+湖存储Lance的AI数据湖方案
LAS(LakeHouse AI Service)
传统数据处理技术栈难以应对这些新变化。多模态数据用传统方式存储,易引发 IO 放大等问题;将完整多模态数据直接导入计算侧,又会带来巨大的 IO 与内存压力。
正是基于这些痛点,火山引擎LAS团队沉淀出了面向 AI 场景的数据湖解决方案 ------LakeHouse AI Service。
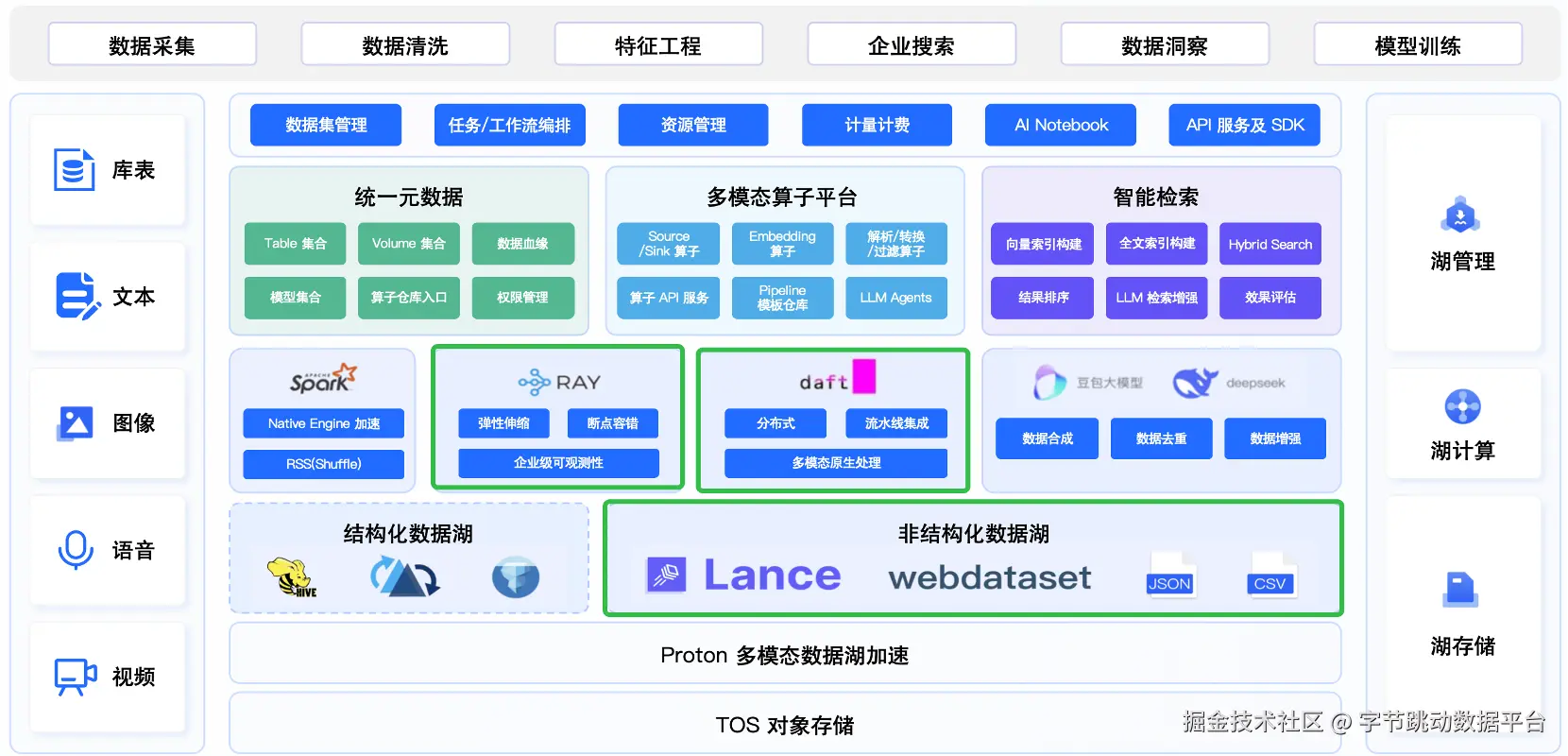
LAS产品全景图 (LakeHouse AI Service)
LAS 核心框架可概括为 "AI 数据湖",包含数据湖计算、湖存储与湖管理三大模块。此次分享重点聚焦 "湖计算" 与 "湖存储",分别对应 Daft 与 Lance 两大核心组件。
Daft:多模态数据的 "湖计算" 引擎
Daft 是基于 Ray 构建的计算框架,旨在解决 AI 场景下多模态数据处理的四大核心需求:
- 快速实现单机到分布式扩展:AI 场景中,数据量往往庞大,单机调试完成后,需快速扩展为分布式处理以提升效率。Daft 依托 Ray 的 Runtime 优势,可轻松实现这一扩展,满足客户对大规模数据处理的诉求。
- 统一多模态与结构化数据处理:无需在不同框架间切换,Daft 能在同一框架内完成多模态数据与结构化数据的统一存储与计算,简化数据处理流程。
- 支持 CPU 与 GPU 异构调度:AI 数据处理常需加载模型,Daft 可在同一工作流中统筹 CPU 算子与 GPU 算子,充分发挥硬件性能,适配复杂的计算需求。
- 打通大数据与 AI 团队协作壁垒:大数据团队习惯 SQL 开发,AI 算法团队擅长 Dataframe 数据加工。Daft 在接入层适配 Python 与 SQL 两种方式,让两类团队能在同一技术栈下高效协作,同时避免因技术差异导致的组织协作问题。
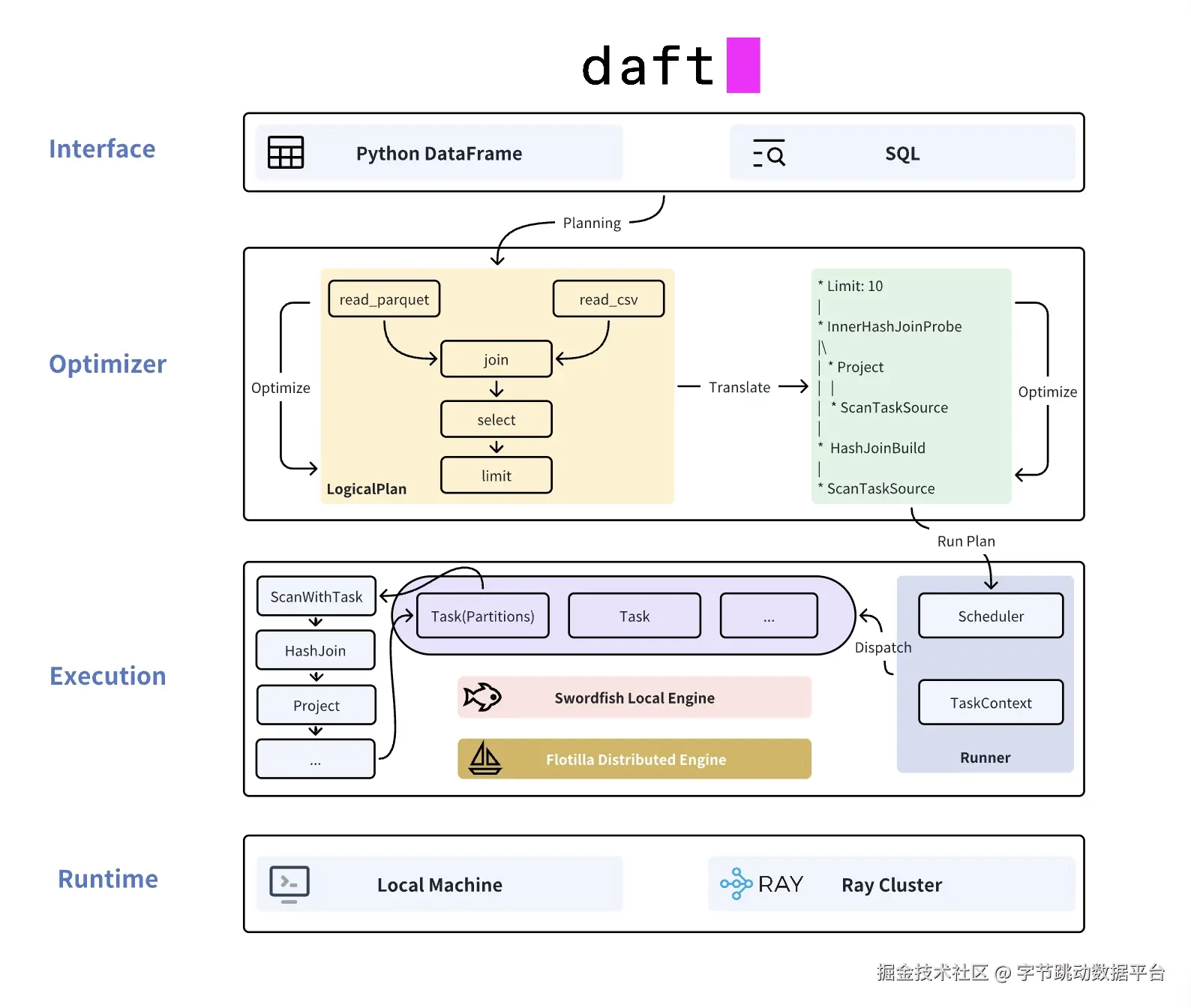
从架构来看,Daft 的设计逻辑清晰且高效。其底层基于 Ray 实现分布式扩展,中间层整合了大数据场景的优化经验,优化器与执行器均采用 Rust 编写,打造 native 执行引擎 ------ 既保留了 Python 生态(如 Pandas、Polars)的数据预处理习惯,又大幅提升了执行效率。
在核心应用场景上,Daft 展现出强大能力:
- Python 脚本分布式转化:针对基于模型或 Python UDF 的单机执行逻辑,Daft 提供无状态(task)与有状态(class)两种分布式 UDF。有状态 UDF 可实现模型一次加载、反复使用,降低模型加载成本,尤其适用于推理场景。
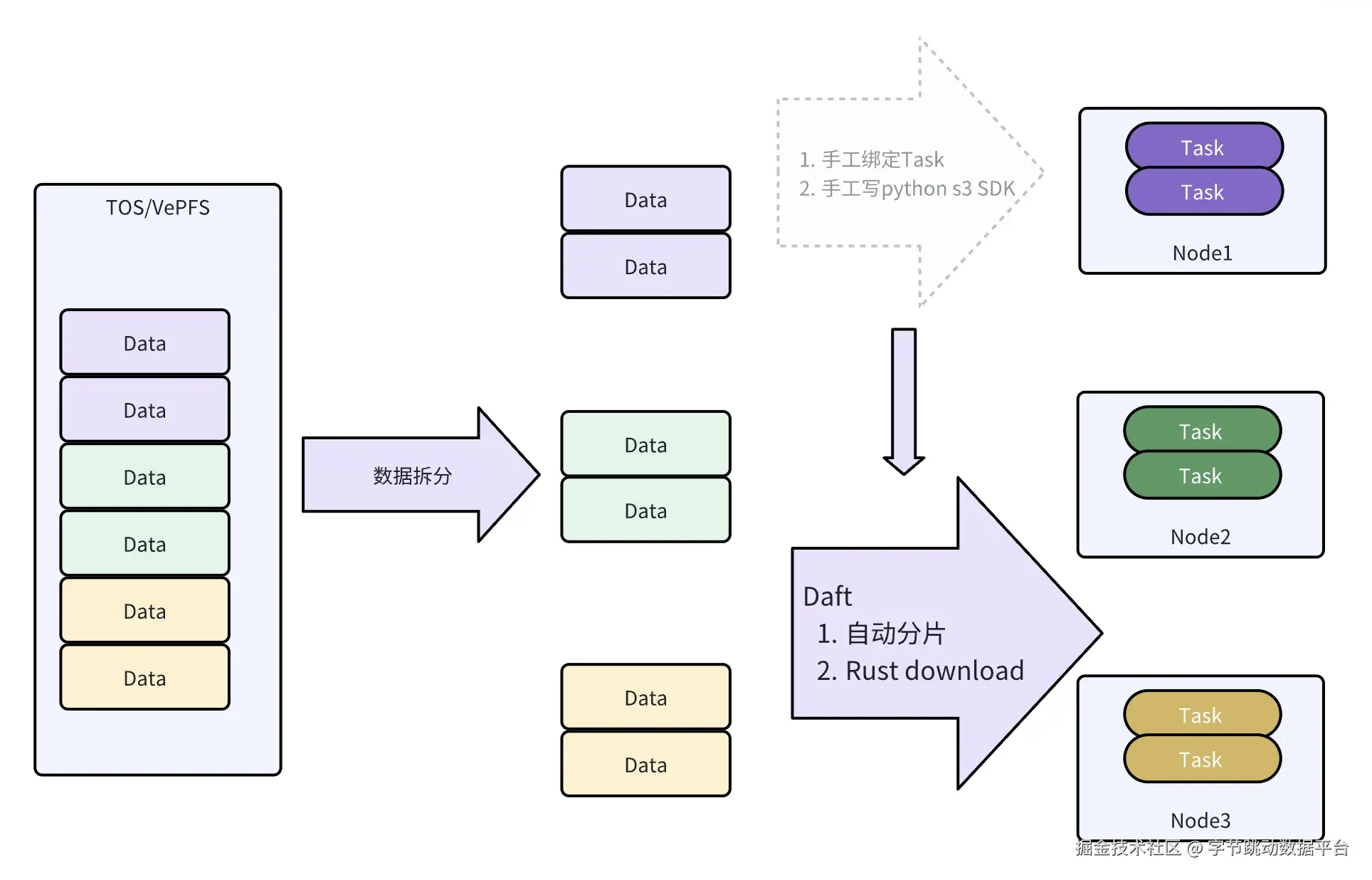
- CPU 与 GPU 异构调度:借助 Ray 的能力,Daft 可实现 CPU 数据准备与 Python 训练框架的流式衔接,提升数据处理与模型训练的协同效率。
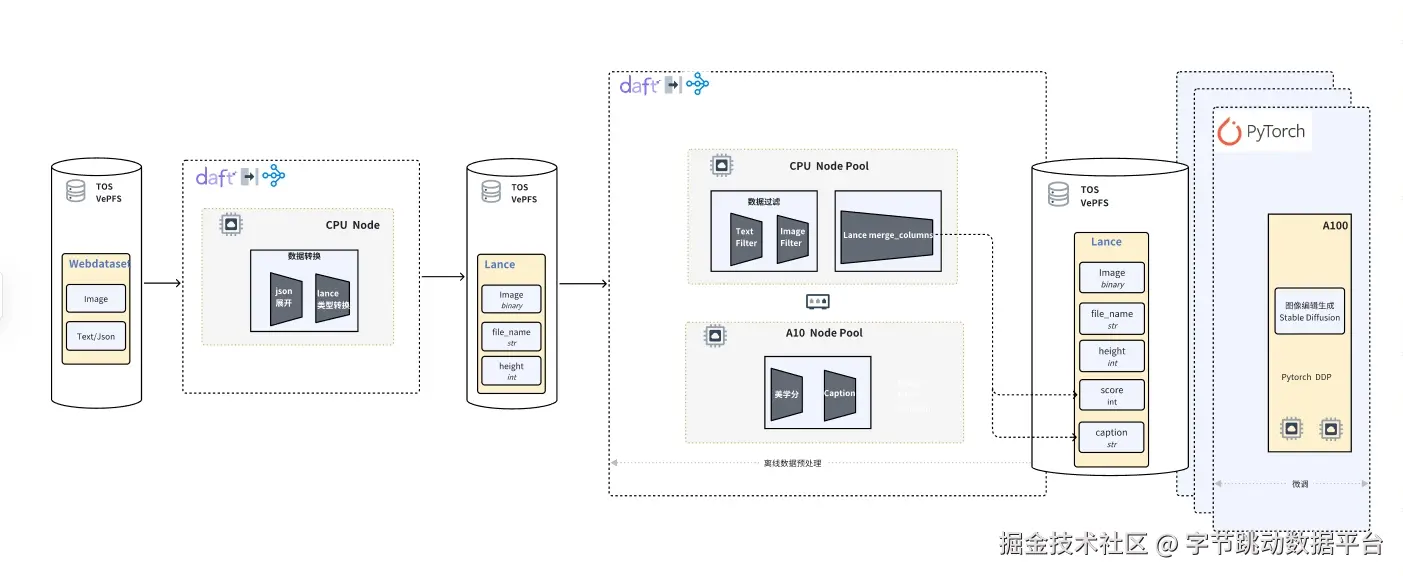
- 多模态数据延迟计算:以图文混排场景为例,Daft 无需将图片与文本全部读取后再进行 shuffle 和 join,而是通过 URL(或后续的 Row Id)关联数据,在需要时才进行下载与处理,大幅减少不必要的 IO 与内存消耗。同时,Daft 支持多模数据类型定义,如视频抽帧可仅读取关键帧、图片 resize 无需加载完整图片,进一步优化处理效率。
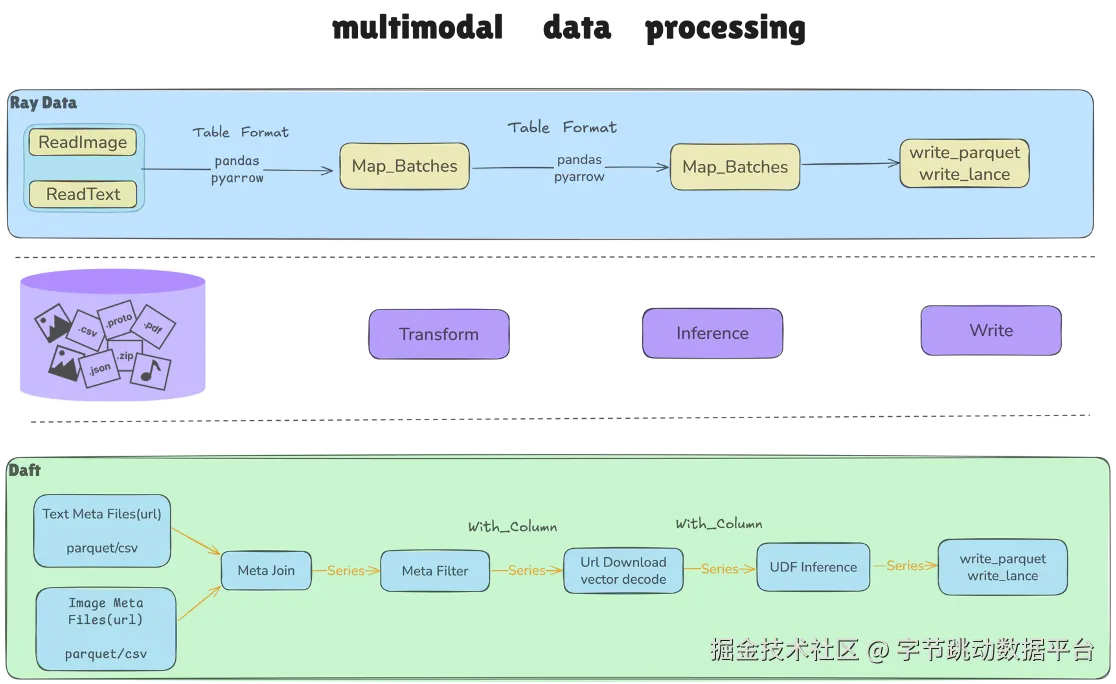
此外,Daft 还能实现数据处理与训练的无缝衔接。通过将数据加载过程部署到异构 CPU 集群,以远端队列作为数据缓存,流式供给训练框架,从软件层面解决了数据加载性能差导致的 GPU 训练效率低问题,同时支持训练状态存储,便于后续快速恢复训练。
Lance:多模态数据的 "湖存储" 方案
Lance 作为配套的存储格式,主要解决多模态数据存储的三大核心问题:
- 多模态数据列式存储:借鉴大数据场景下列式存储的优势,Lance 可对多模态数据进行列式存储,实现高压缩比。在实际生产中,100G 的 Tensor 数据经 Lance 压缩后可降至 2G,大幅节省存储成本。
- 大小列数据统一存储:针对多模态数据(如图片)及其标签信息(如描述等),Lance 能将两者统一存储在同一系统中,降低数据管理成本,同时支持高性能点查,满足 AI 训练对数据快速访问的需求。
- schema 变更 Zero copy:多模数据常需基于标签列或模型打标,Lance 支持 schema 变更时的 Zero copy,避免数据反复拷贝带来的效率损耗。
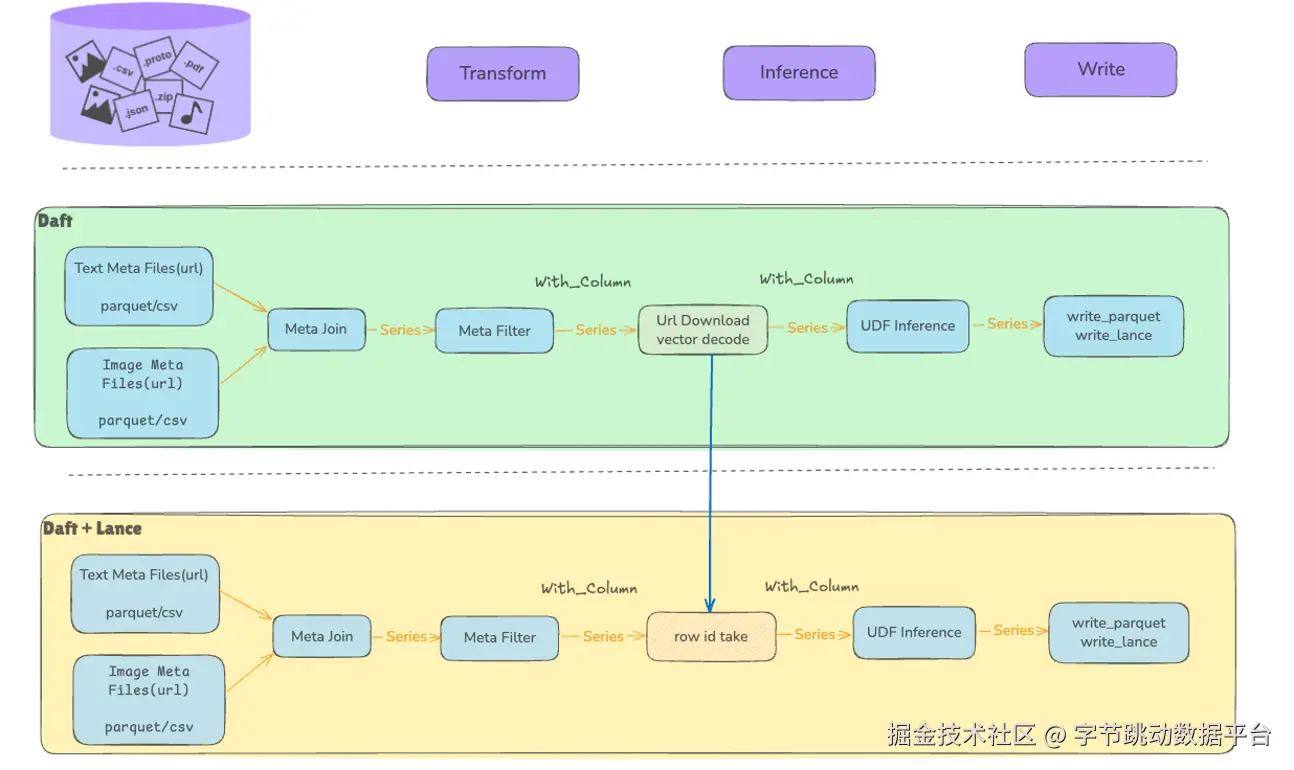
值得注意的是,Lance 与 Daft 并非矛盾关系,而是相辅相成。Daft 初期通过 URL 关联多模态数据,实现延迟计算;Lance 则将多模态数据以列式存储,并以 row ID 替代 URL 作为数据标识。两者通过 Arow 类型接口对接,既保留了 Daft 延迟计算的优势,又能享受 Lance 列式存储的高压缩比,完美统一多模态数据处理与存储流程。
实践验证:Daft+Lance 方案的落地成效
在实际落地中,Daft 与 Lance 的组合方案已在多个场景中展现出显著价值,为客户带来效率提升与成本优化。
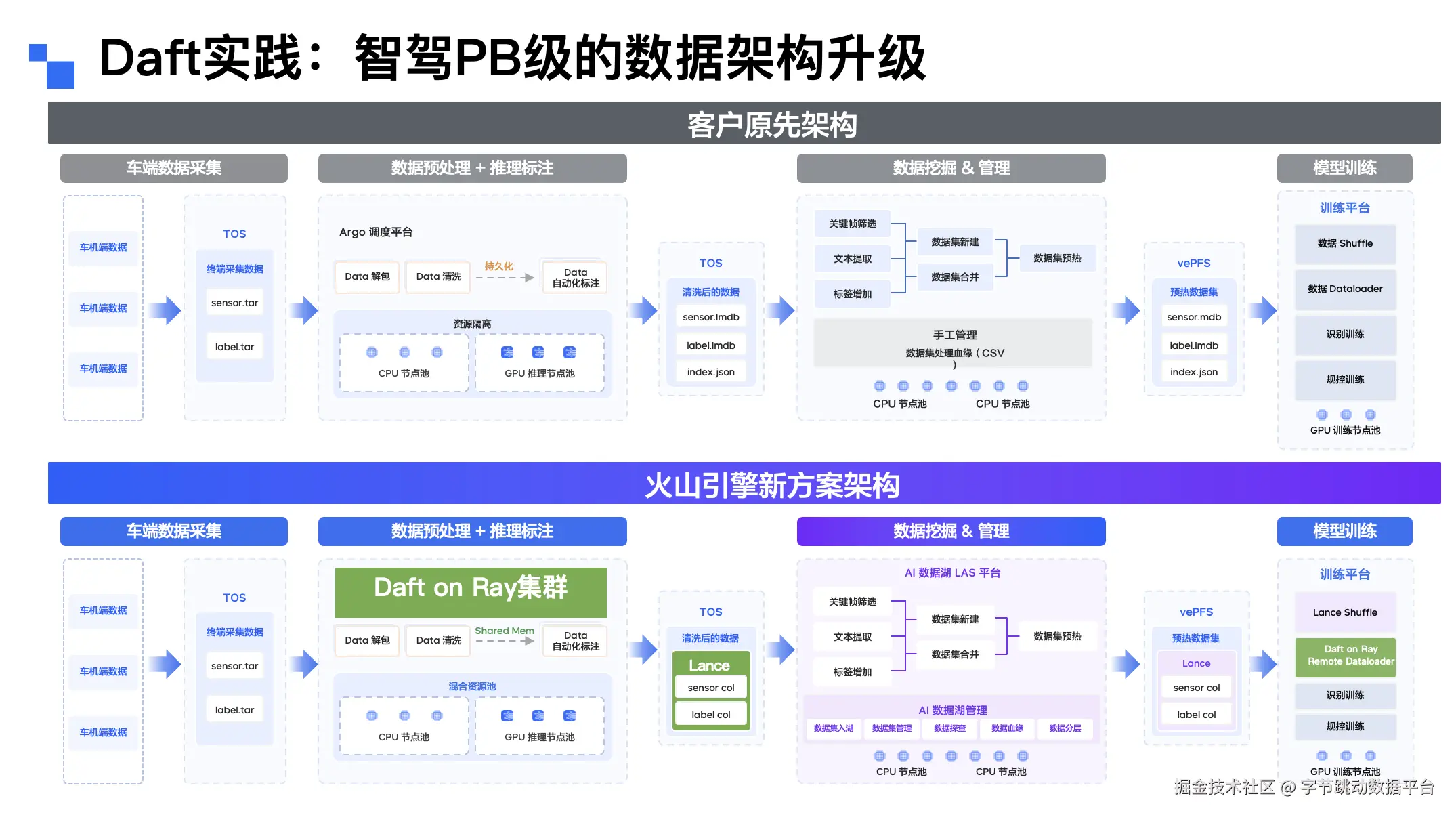
自动驾驶场景:端到端效率提升 70%
此前,某自动驾驶客户采用 Argo+K8S 调度 + LMDB 的方案,Python 分布式处理依赖 Argo+K8S,数据存储通过 LMDB 加 index 文件组织。
该方案存在明显短板:K8S 调度无法支持 CPU 与 GPU 异构,需将中间结果落盘,导致效率低下;同时,GPU使用率超95%之后会Block GPU指令调用,进而影响数据训练。
引入 Daft+Lance 方案后,客户将调度流程替换为 Daft on Ray,存储方式升级为 Lance。新方案通过 Daft on Ray 实现数据在内存中的流式处理,可分别扩展 CPU 与 GPU 资源,避免中间结果落盘的效率损耗;Lance 则将源数据与原始数据统一管理,支持高性能点查,实现数据预处理与训练的无缝衔接。最终,该客户端到端处理时间缩短 70%,大幅提升自动驾驶数据处理与模型迭代效率。
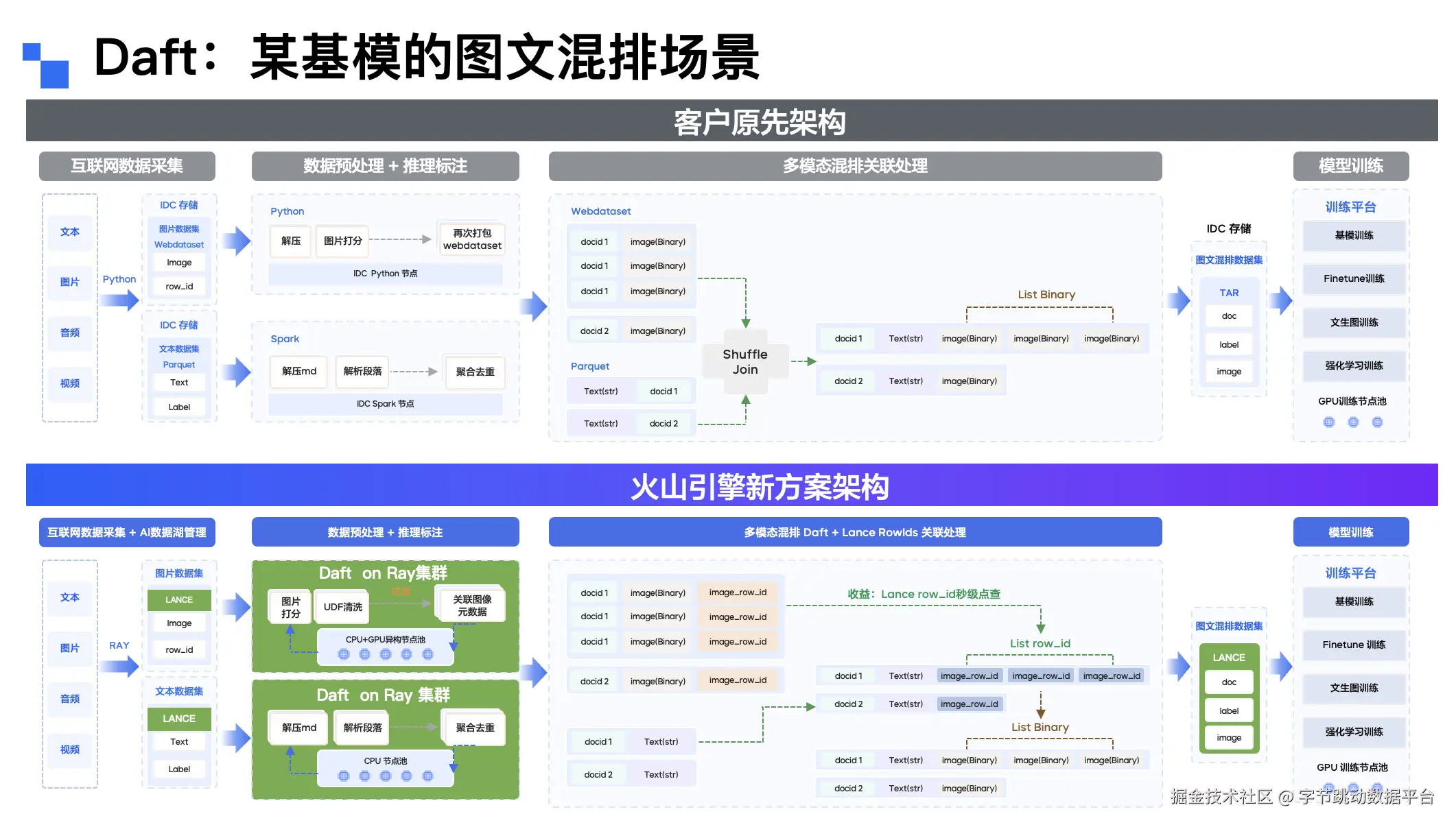
LLM图文混排场景:解决大 join 稳定性难题
某LLM客户需处理爬虫获取的图文混排数据,原始方案采用 Webdataset 存储,通过 Spark 读取数据后进行大 join。尽管尝试了 remote shuffle 等优化手段,但仍面临稳定性差、处理效率低的问题。
采用 Daft+Lance 方案后,客户无需基于图片与文本内容进行大 join,而是通过 row ID 关联源数据,在需要时再加载具体数据。这一优化彻底解决了大 join 的稳定性问题,同时显著提升了数据处理速度,为LLM 场景的内容处理提供了可靠支撑。
未来规划:完善多模态生态,推动开源协作
展望未来,火山引擎LAS团队将持续深化 Daft 与 Lance 的能力。在 Daft 方面,将补全多模态数据类型支持,重点加入视频处理能力(满足自动驾驶等场景的视频抽帧、训练需求),同时拓展 LeRobot、MCP 等行业特定数据类型;在生态融合上,将进一步加强与 Lance 的对接,打造更高效的 "计算 + 存储" 协同方案。
我们也欢迎感兴趣的开发者们加入Daft和Lance中文社区!