前言
我是[提前退休的java猿](https://juejin.cn/user/465848660928872 "https://juejin.cn/user/465848660928872"),一名7年java开发经验的开发组长,分享工作中的各种问题!(抖音、公众号同号)
昨天在技术群聊中,发现两个震惊的观点今天就分享出来吧
有一个兄弟说 "条件的顺序会影响索引的使用,会按照条件的顺序查询"
 🔈今天就再给大家说一下这个问题吧!首先条件的顺序对执行策略肯定是不会影响的
🔈今天就再给大家说一下这个问题吧!首先条件的顺序对执行策略肯定是不会影响的
SQL优化器
可能上面的兄弟不知道SQL的优化器这个东西吧!我们先看看SQL的执行流程图吧
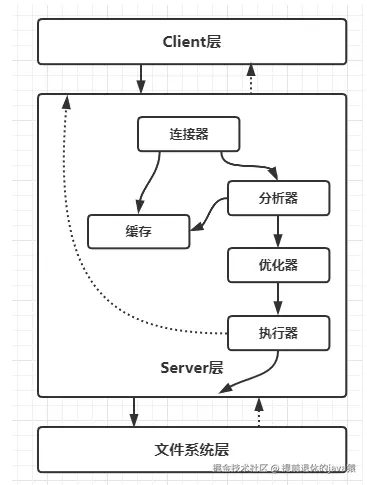
优化器这块作为一名后端还是需要了解的,优化器对SQL的查询优化主要体现在两方面 第一,对SQL的逻辑的优化,在不改变查询结果的前提下,通过重写 SQL 的逻辑结构,减少需要处理的数据量
SQL 逻辑优化
1. 常量折叠与简化(Constant Folding & Simplification)
提前计算SQL中的常量表达式,减少执行时的计算量:
- 原始条件
WHERE age > 20 + 5→ 优化后WHERE age > 25(提前计算20+5的结果); - 原始条件
WHERE 1=1 AND id=10→ 优化后WHERE id=10(移除恒真条件1=1)。
2. 谓词下推(Predicate Pushdown)
将过滤条件(WHERE 子句中的谓词)尽可能 "下推" 到数据读取的最底层(如子查询、JOIN 操作的内层表),提前过滤掉无关数据,减少后续处理的数据量。
- 原始查询:SELECT * FROM (SELECT id, name FROM user) AS t WHERE t.id=10优化后:SELECT id, name FROM user WHERE id=10(将
id=10下推到子查询中,子查询仅返回 1 行数据,而非全表)。
3. 连接顺序调整(Join Order Optimization)
目标 :当查询包含多表 JOIN 时,优化器会选择 "小表先参与连接" 的顺序(因为小表的数据量少,能减少后续连接操作的中间结果集大小)。
原理 :假设 JOIN 操作涉及表 A(100 行)、表 B(1000 行)、表 C(10000 行),最优顺序通常是 (A JOIN B) JOIN C(中间结果集为 1001000=100,000 行),而非 (B JOIN C) JOIN A(中间结果集为 100010000=10,000,000 行)。
4. 子查询优化(Subquery Optimization)
如果存在将低效的子查询(如 IN 子查询)可能转换为更高效的 JOIN 操作,避免多次执行子查询。
- 原始查询:SELECT * FROM order WHERE user_id IN (SELECT id FROM user WHERE age>30)
优化后:SELECT o.* FROM order o JOIN user u ON o.user_id = u.id WHERE u.age>30
具体的算法选择
接下来就需要确定具体的执行策略了,比如:
- 是走索引、还是表扫描
- 连表join 是走
nested loop、还是hash join、merge join - 排序的方式,走内存排序,外部排序、还是利用索引排序
SQL 会对每种算法做成本估算,I/O 代价、CPU 代价、内存代价 三者之和 最小的就采用。
每种执行策略的成本的估算,主要就是基于 数据库自己维护的统计信息。
成本估算不准确
SQL 会对每种算法做成本估算,I/O 代价、CPU 代价、内存代价 三者之和 最小的就采用。
这些成本的计算,数据库肯定不会真实的执行SQL,都是通过数据库内部维护的统计信息。这些信息在某些情况下会发生滞后或者与实际偏差太大。怎么去预防这个事儿呢。
在我们做了数据库迁移,或者大批量的数据导入的时候,我们就需要去关注一下这个信息是否又被刷新过。
sql
-- 查询表统计的预估行数
SELECT reltuples AS estimated_rows
FROM pg_class
WHERE relname = '表名'
AND relnamespace = (SELECT oid FROM pg_namespace WHERE nspname = '模式名');
-- 查询 统计信息更新的 时间last_analyze(手动更新)、last_autoanalyze(自动更新)
SELECT
schemaname,
relname AS table_name,
last_analyze,
last_autoanalyze
FROM pg_stat_user_tables
WHERE schemaname = '模式名' AND relname = '表名';
-- 手动刷新统计信息
ANALYZE your_schema.your_table;博主之前就遇到过由于数据来回迁移,批量导入等操作,导致统计信息和实际数据量差距过大。大表被识别为了小表,导致多表join 走了
Nested Loop的算法,直接导致CPU打满,SQL卡死。(详细见: 一条SQL把数据库服务器干爆了)
总结
首先where 条件的顺序不会影响索引的使用,数据库的优化器会优先使用索引条件查询,会对每种查询方式的成本进行估算。估算的总体逻辑就是I/O 代价、CPU 代价、内存代价 三者之和,估算成本的时候依赖系统内部维护统计信息。这个是十分关键,直接影响数据库的查询算法。