一、为什么先从"跑起来"开始?
Flink 的强项是高速、低延迟、可扩展 的流式处理。理解概念之前,先把最小闭环跑通:本地起一个小集群、提交一个示例作业、在 Web UI 看看任务是怎么跑的------这比读厚厚的文档更能建立直觉。
二、环境准备
- 系统:Linux / macOS /(Windows 建议 WSL 或 Cygwin 环境)
- Java:Java 11(必需)
- 终端可用
tar、bash
检查 Java 版本:
bash
java -version若不是 11,请先安装或切换到 11(例如 macOS 可用 sdkman 或 brew,Linux 用包管理器,Windows 在 WSL 内安装)。
三、下载并解压 Flink
从官网获取最新稳定版二进制包(也可用镜像站),下载后在终端解压:
bash
tar -xzf flink-*.tgz
cd flink-* && ls -l你会看到三个关键目录:
bin/:可执行脚本,管理集群与作业(start-cluster.sh、flinkCLI 等)conf/:配置文件(flink-conf.yaml等)examples/:官方示例 JAR(含批/流 WordCount 等)
小贴士:第一次使用可以不改配置,直接用默认值跑通全流程。
四、启动本地集群(Standalone)
在解压目录下:
bash
./bin/start-cluster.sh成功后,Flink 的 JobManager 和 TaskManager 将以后台进程运行。可用下列命令确认:
bash
ps aux | grep flink浏览器访问 **http://localhost:8081**,可见 Flink Web UI(Dashboard)。
如果页面打不开,见下文"排错"。
停止集群:
bash
./bin/stop-cluster.sh五、提交你的第一个 Flink 作业(WordCount)
Flink 提供 bin/flink CLI,用来提交 JAR 作业到已运行的集群。
使用内置示例(流式 WordCount):
bash
./bin/flink run examples/streaming/WordCount.jar查看 TaskManager 的输出日志(观察词频统计结果):
bash
tail log/flink-*-taskexecutor-*.out你会看到类似:
(nymph,1)
(in,3)
(thy,1)
(orisons,1)
(be,4)
(all,2)
(my,1)
(sins,1)
(remember,1)
(d,4)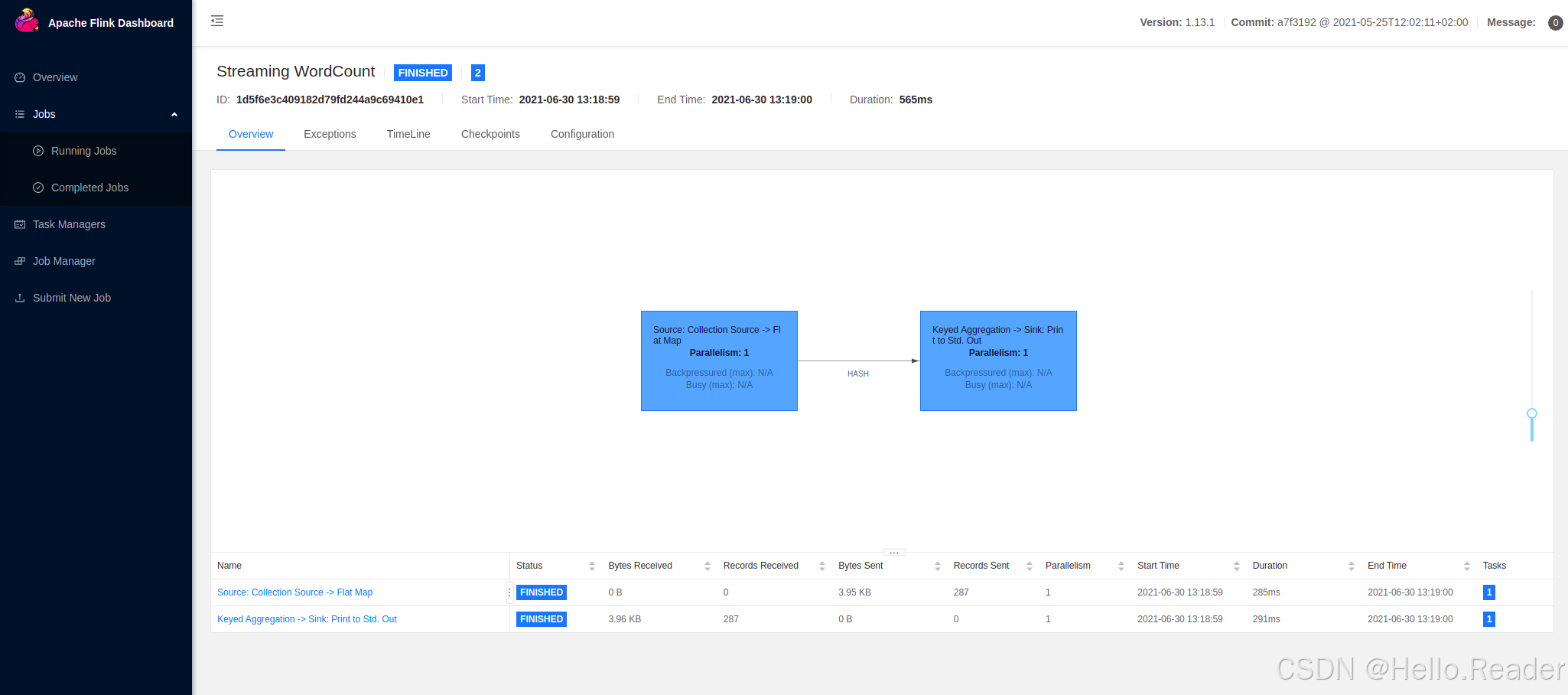
同时在 Web UI:
- 可以看到正在运行的作业 、并行度 、吞吐 、任务拓扑 与时间线;
- 拓扑通常包含Source (数据源)与Transformation (转换/聚合)等算子。
六、(可选)用 Docker 一键起体验环境
不想在本地装 Java?可以用官方 Docker 镜像(以单机体验为例):
bash
# JobManager
docker run -it --rm -p 8081:8081 --name jobmanager \
-e JOB_MANAGER_RPC_ADDRESS=jobmanager \
apache/flink:latest jobmanager
# 另开一个终端启动 TaskManager
docker run -it --rm --link jobmanager:jobmanager --name taskmanager \
apache/flink:latest taskmanager随后将示例 JAR 拷入容器或用 flink run 指向远程提交。入门建议先用压缩包方式,Docker 适合熟悉后做环境隔离或 CI/CD。
七、常见问题与快速排错
1)Web UI 打不开(8081 端口冲突)
- 症状:访问
http://localhost:8081失败 - 处理:检查端口是否被占用(macOS/Linux:
lsof -i :8081;Windows/WSL:netstat -ano | find "8081")。若冲突,修改conf/flink-conf.yaml中rest.port重启集群。
2)Java 版本不对
- 症状:启动脚本报错或
java -version非 11 - 处理:安装或切换到 Java 11,再重启集群。
3)权限问题(macOS Gatekeeper/执行权限)
-
给脚本加执行权限:
bashchmod +x bin/*.sh -
如果被 Gatekeeper 拦截,可在"系统设置 → 隐私与安全性"里允许。
4)日志太多,不知道看哪个
-
重点关注:
log/flink-*-standalonesession-*.log(JobManager)log/flink-*-taskexecutor-*.log(TaskManager)- 观察
.out文件可快速看到示例输出。
5)Windows 环境
- 推荐 WSL2 + Ubuntu ,或在 Windows 上安装 Cygwin;
- 直接用 Docker 也是可行替代方案。
八、把示例换成你的 JAR
假设你用 Maven/Gradle 打包了一个可运行的 Flink 程序(含 main),把 JAR 放到服务器上,提交即可:
bash
./bin/flink run /path/to/your-job.jar \
--yourArg1 v1 --yourArg2 v2小贴士
- 生产环境通常不会用 Standalone 本地集群,而会部署 YARN / Kubernetes / Native Kubernetes / Standalone 集群;
- 但提交 JAR 与观察 Web UI的操作方式是一致的。
九、理解你刚刚看到的"数据流计划"
以 WordCount 为例,拓扑一般由两类算子构成:
- Source:从内置集合(示例)或外部系统(Kafka、文件)读取数据;
- Transformation :
flatMap拆分单词、keyBy分组、sum聚合计数; - 最终输出到
sink(示例中常写日志;生产可写 Kafka、存储、OLAP)。
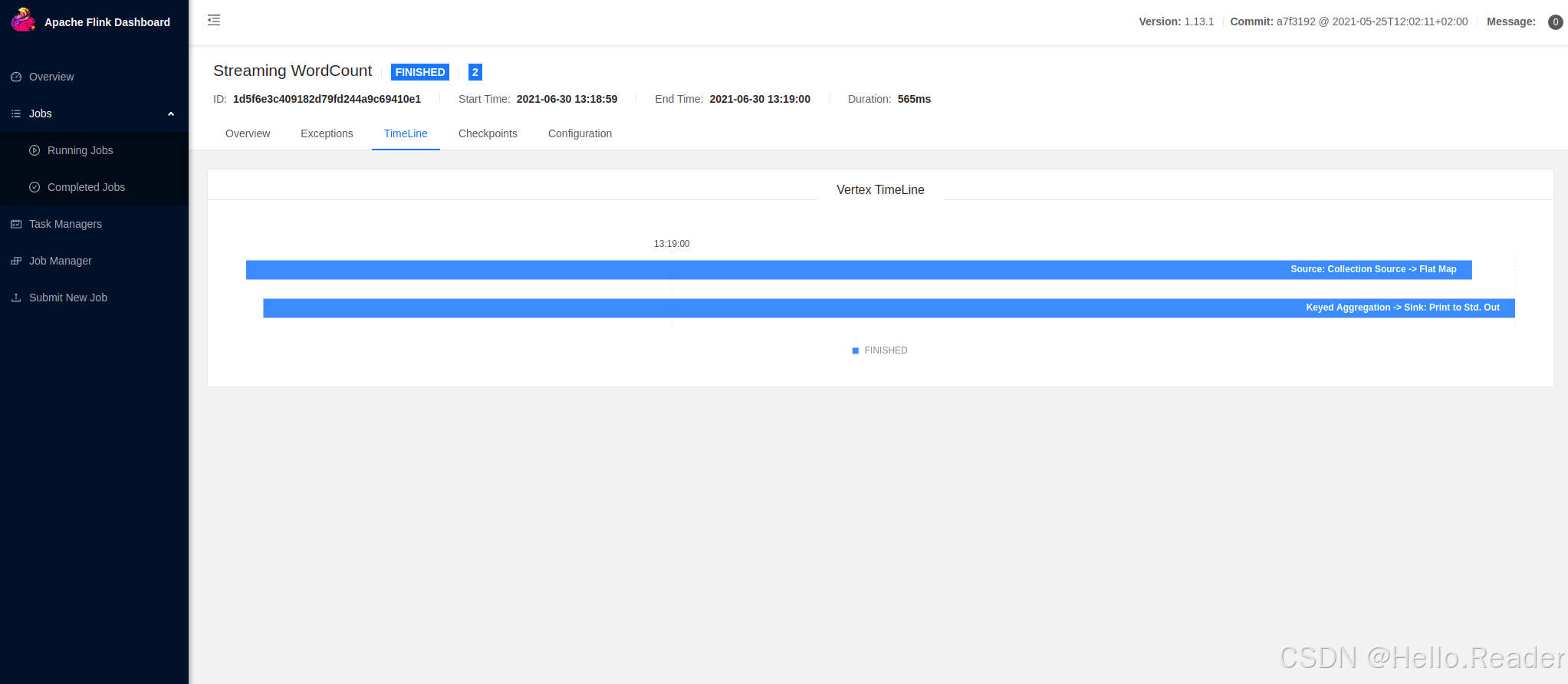
Web UI 的 Graph 能帮助你理解并行度与任务链路;Timeline 则能直观看到各算子的执行时间与状态。
十、下一步学什么?
- 概念:流批一体、事件时间 vs 处理时间、水位线、状态与 Checkpoint、Exactly-Once 语义
- 动手 :官方 tutorials (如 Fraud Detection、CEP)、接入 Kafka、编写你自己的
Source/Sink - 部署:在 Kubernetes 或 Yarn 上提交作业,开启 Checkpoint、监控指标、报警
附录:常用命令速查
bash
# 启动/停止本地集群
./bin/start-cluster.sh
./bin/stop-cluster.sh
# 提交流式 WordCount 示例
./bin/flink run examples/streaming/WordCount.jar
# 查看 TaskManager 输出(示例结果)
tail -f log/flink-*-taskexecutor-*.out
# 查看进程
ps aux | grep flink
# 修改 REST 端口(conf/flink-conf.yaml)
# rest.port: 8081到这里,你已经完成了 Flink 的"下载 → 启动 → 提交作业 → 观察 UI "最小闭环。建议把示例替换为你自己的 JAR,逐步把 Source 换成 Kafka,把 Sink 换成你需要的存储,并开始理解事件时间与状态这些核心概念。等把本地跑顺畅,再上 K8s 或 Yarn,开启 Checkpoint 与监控,向真实生产迈进 🚀