一、术语解释
1. 弹性分布式数据集(RDD)
RDD(Resilient Distributed Dataset)是Spark的核心抽象,是不可变的、可分区的、支持并行计算的分布式数据集合。
- 弹性:支持数据容错(基于血统Lineage恢复丢失数据)、动态调整分区数;
- 分布式:数据分散存储在集群多个节点;
- 核心特性:不可变(修改会生成新RDD)、分区机制、血统依赖、支持丰富的转换(Transformation)和行动(Action)操作。
2. Spark Streaming
Spark Streaming是Spark用于处理实时流式数据的模块,基于微批处理(Micro-Batch)思想:将连续的流数据切分成小的批次,交给Spark Core处理,最终输出批量结果。
- 核心抽象:DStream(离散流),本质是一系列连续的RDD;
- 特点:与Spark Core/MLlib/GraphX无缝集成,支持容错、高吞吐量、可扩展。
3. PageRank
PageRank是谷歌提出的网页重要性排序算法,核心思想是"链接投票":
- 一个网页的重要性 = 所有指向它的网页的重要性之和,且权重与指向它的网页的出链数成反比;
- Spark中可通过GraphX实现分布式PageRank计算,迭代收敛后得到各节点(网页)的重要性得分。
4. Spark MLlib
MLlib是Spark的机器学习库,提供了可扩展的机器学习算法和工具,支持分类、回归、聚类、推荐系统、特征工程等常见机器学习任务。
- 分为两个API:基于RDD的传统MLlib API(维护状态)、基于DataFrame的Spark ML API(推荐使用,更易用、支持流水线);
- 特点:分布式实现,适配Spark的分布式计算框架,可处理大规模机器学习任务。
二、环境配置
1. 单机伪分布式集群
概念
单机伪分布式集群是指在单台物理机器上模拟分布式集群的运行模式:所有Spark进程(Master、Worker、Executor)都运行在同一台机器上,但逻辑上分为不同的角色,模拟分布式环境的核心流程(如资源调度、任务分发)。
搭建步骤(以Linux为例)
-
前置准备:安装JDK(1.8+)、配置SSH免密登录(本地回环)、安装Hadoop(伪分布式,可选,若需HDFS支持);
-
下载并解压Spark :
bashwget https://archive.apache.org/dist/spark/spark-3.3.0/spark-3.3.0-bin-hadoop3.tgz tar -zxvf spark-3.3.0-bin-hadoop3.tgz -C /usr/local/ mv /usr/local/spark-3.3.0-bin-hadoop3 /usr/local/spark -
配置环境变量 (
/etc/profile):bashexport SPARK_HOME=/usr/local/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin执行
source /etc/profile生效; -
修改Spark配置文件 :
-
复制模板:
cp $SPARK_HOME/conf/spark-env.sh.template $SPARK_HOME/conf/spark-env.sh; -
编辑
spark-env.sh,添加:bashexport JAVA_HOME=/usr/local/jdk1.8.0_291 export SPARK_MASTER_HOST=localhost export SPARK_MASTER_PORT=7077 export SPARK_WORKER_CORES=2 # 单机核心数 export SPARK_WORKER_MEMORY=2g # 分配内存
-
-
启动集群 :
bashstart-master.sh # 启动Master start-worker.sh spark://localhost:7077 # 启动Worker -
验证 :访问
http://localhost:8080查看Spark集群状态。
2. Spark完全伪分布式集群
完全伪分布式集群是单机伪分布式的进阶版 :在单台机器上启动多个Worker进程,模拟多节点Worker的集群环境,更贴近真实分布式集群的资源调度逻辑(如多Worker竞争资源、任务分发到不同Worker)。
- 与普通单机伪分布式的核心区别:Worker数量>1,模拟多节点的资源隔离和调度。
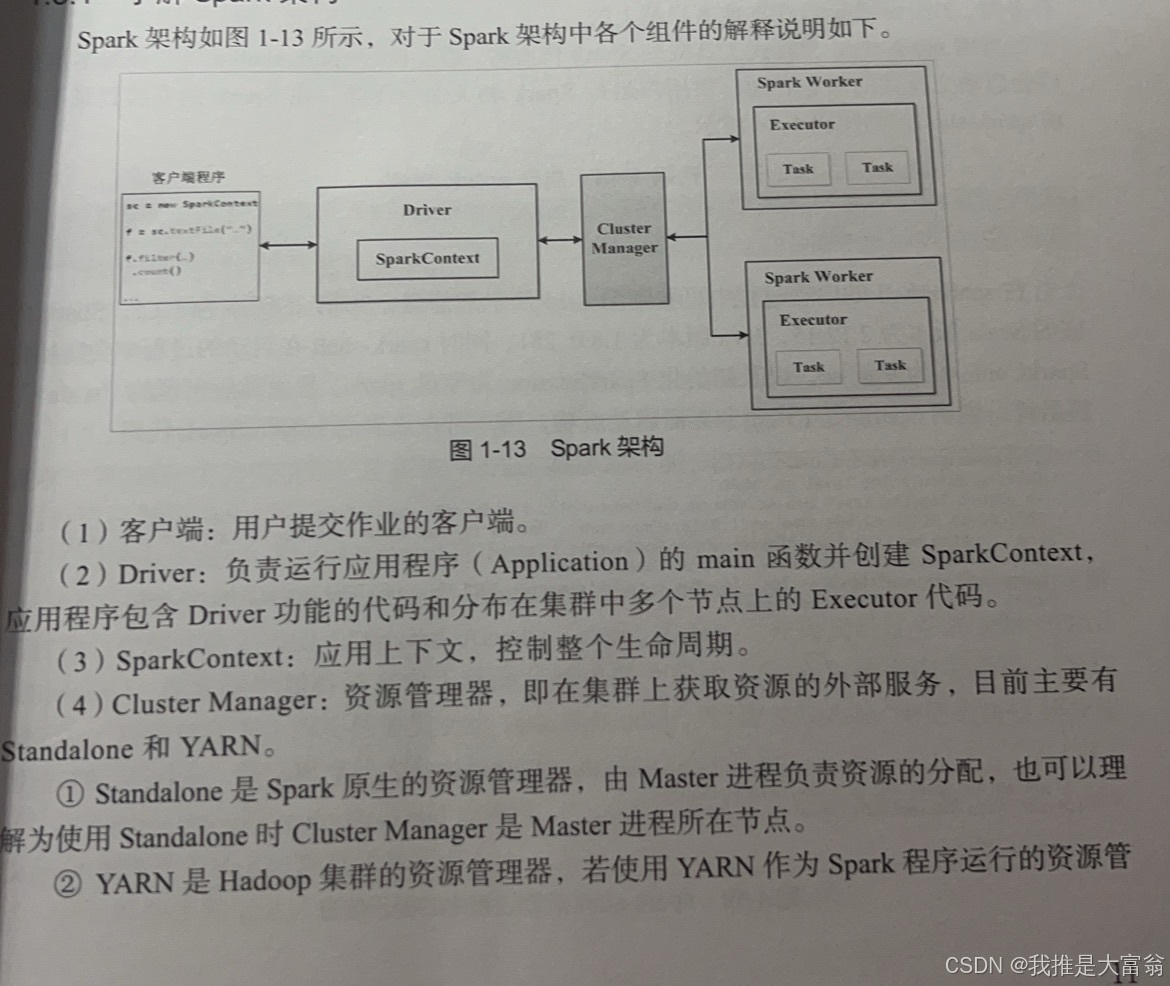
3. Spark架构的组件名称和作用
Spark采用主从(Master/Slave)架构(Standalone模式),核心组件如下:
| 组件 | 作用 |
|---|---|
| Driver | 驱动程序,运行应用的main函数,负责创建SparkContext、提交任务、解析逻辑 |
| Master | 主节点,负责管理集群资源,接收Worker注册,分配任务给Worker |
| Worker | 从节点,管理本机资源(CPU/内存),启动Executor进程 |
| Executor | 运行在Worker上的进程,负责执行具体的Task,存储计算数据 |
| SparkContext | Spark应用的核心入口,负责与Master通信,创建RDD、调度任务 |
| Cluster Manager | 集群资源管理器(Standalone/YARN/Mesos),负责分配集群资源 |

三、脚本代码
1. 启动spark-shell
spark-shell是Spark的交互式Scala命令行工具,核心启动命令:
bash
# 本地模式(单机,核数为*表示使用所有可用核)
spark-shell --master local[*]
# 连接Standalone集群模式
spark-shell --master spark://localhost:7077 --executor-memory 1g --total-executor-cores 22. 数据上传HDFS并创建RDD
步骤1:上传本地文件到HDFS
bash
# 创建HDFS目录
hdfs dfs -mkdir /spark_data
# 上传本地文件(如data.txt)到HDFS
hdfs dfs -put /local/path/data.txt /spark_data/步骤2:在spark-shell中创建RDD
scala
// 从HDFS文件创建RDD
val hdfsRDD = sc.textFile("hdfs://localhost:9000/spark_data/data.txt")
// 验证:打印前5行
hdfsRDD.take(5).foreach(println)3. 读取文本文件和查看文本文件内容
读取本地/HDFS文本文件
scala
// 读取本地文件
val localRDD = sc.textFile("file:///local/path/data.txt")
// 读取HDFS文件
val hdfsRDD = sc.textFile("hdfs://localhost:9000/spark_data/data.txt")查看文本内容的常用操作
scala
// 查看所有内容(小文件适用)
hdfsRDD.collect().foreach(println)
// 查看前N行
hdfsRDD.take(10).foreach(println)
// 查看行数
println(s"文件总行数:${hdfsRDD.count()}")
// 过滤后查看内容(如包含"spark"的行)
hdfsRDD.filter(_.contains("spark")).foreach(println)4. HiveQL语句创建学生表
hiveql
-- 创建数据库(可选)
CREATE DATABASE IF NOT EXISTS student_db;
USE student_db;
-- 创建学生表(结构化)
CREATE TABLE IF NOT EXISTS student (
id INT COMMENT '学生ID',
name STRING COMMENT '学生姓名',
age INT COMMENT '年龄',
gender STRING COMMENT '性别',
score DOUBLE COMMENT '平均分'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',' -- 字段分隔符为逗号
STORED AS TEXTFILE -- 存储格式为文本文件
LOCATION '/hive/student'; -- 存储路径(可选)
-- 验证表结构
DESC student;5. where()/filter()/select()查询user对象数据
假设已有DataFrame userDF,结构为id: Int, name: String, age: Int, city: String:
scala
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder()
.appName("UserQuery")
.master("local[*]")
.getOrCreate()
// 模拟创建userDF
val data = Seq(
(1, "张三", 20, "北京"),
(2, "李四", 25, "上海"),
(3, "王五", 22, "北京"),
(4, "赵六", 30, "广州")
)
val userDF = spark.createDataFrame(data).toDF("id", "name", "age", "city")
// 1. where():查询北京的用户,年龄>20
val whereResult = userDF.where("city = '北京' and age > 20")
println("where()查询结果:")
whereResult.show()
// 2. filter():功能与where()等价(别名),查询上海的用户
val filterResult = userDF.filter($"city" === "上海") // 用列对象语法
println("filter()查询结果:")
filterResult.show()
// 3. select():只查询id、name、city列
val selectResult = userDF.select("id", "name", "city")
println("select()查询结果:")
selectResult.show()
// 组合使用:筛选年龄>20,只显示name和age
val comboResult = userDF.filter($"age" > 20).select("name", "age")
println("组合查询结果:")
comboResult.show()四、问题回答
1. 窄依赖和宽依赖的区别
| 维度 | 窄依赖(Narrow Dependency) | 宽依赖(Wide Dependency) |
|---|---|---|
| 数据分区 | 子RDD的一个分区仅依赖父RDD的一个分区 | 子RDD的一个分区依赖父RDD的多个/所有分区 |
| 数据洗牌 | 无Shuffle,无需跨节点传输数据 | 有Shuffle,需要跨节点传输数据 |
| 容错成本 | 低,仅需重新计算父RDD对应的单个分区 | 高,需重新计算父RDD的多个分区 |
| 示例操作 | map、filter、union、join(等值且分区键相同) | groupByKey、reduceByKey、sortByKey、distinct |
2. JSON文件和CSV文件的概念及异同
概念
- JSON(JavaScript Object Notation):轻量级的数据交换格式,基于键值对的嵌套结构,支持字符串、数字、数组、对象等类型;
- CSV(Comma Separated Values):逗号分隔值文件,纯文本格式,每行是一条记录,列之间用逗号(或其他分隔符)分隔,无嵌套结构。
相同点
- 都是文本格式,易读易写;
- 都可被Spark/大数据工具解析;
- 都适用于结构化数据存储。
不同点
| 维度 | JSON | CSV |
|---|---|---|
| 结构 | 支持嵌套/复杂结构(数组、对象) | 仅二维表结构,无嵌套 |
| 数据类型 | 自带类型(字符串/数字/布尔) | 纯文本,需手动指定类型 |
| 可读性 | 层级清晰,适合复杂数据 | 简洁,适合简单结构化数据 |
| 解析成本 | 较高(需解析嵌套) | 较低(仅分割列) |
| 大小 | 冗余度高(键重复) | 冗余度低(无键) |
3. Spark大数据技术的发展和挑战
发展
- 版本迭代:从1.x(核心RDD)→2.x(引入DataFrame/DataSet、SparkSession)→3.x(优化性能、支持Python/Pandas API);
- 生态扩展:集成Streaming/MLlib/GraphX,支持多数据源(HDFS/Hive/Redis)、多部署模式(Standalone/YARN/K8s);
- 场景深化:从批处理→流批一体(Structured Streaming)→湖仓一体(与Delta Lake集成);
- 语言支持:完善Scala/Java/Python/R API,降低使用门槛。
挑战
- 性能优化:超大规模数据下的Shuffle、内存管理、GC问题;
- 实时性:传统微批Streaming实时性不足(毫秒级需Flink补充);
- 易用性:分布式调试困难,新手学习曲线陡;
- 资源调度:与YARN/K8s集成的资源隔离、动态扩缩容问题;
- 兼容性:不同版本/生态组件的兼容,老旧代码迁移成本。
4. DataFrame的作用及4种创建方法
DataFrame作用
DataFrame是Spark的结构化数据抽象(类似关系型数据库的表),兼具RDD的分布式特性和SQL的结构化查询能力,比RDD更易用(支持SQL、列操作)、性能更优(优化器Catalyst)。
4种创建方法
scala
import org.apache.spark.sql.{SparkSession, Row}
import org.apache.spark.sql.types.{StructType, StructField, StringType, IntType}
val spark = SparkSession.builder().appName("CreateDF").master("local[*]").getOrCreate()
// 方法1:从RDD创建(指定Schema)
val rdd = sc.parallelize(Seq((1, "张三"), (2, "李四")))
val schema = StructType(Seq(
StructField("id", IntType, nullable = false),
StructField("name", StringType, nullable = true)
))
val df1 = spark.createDataFrame(rdd.map(Row.fromTuple(_)), schema)
// 方法2:从集合(Seq/List)创建(自动推断Schema)
val data = Seq((1, "张三", 20), (2, "李四", 25))
val df2 = spark.createDataFrame(data).toDF("id", "name", "age")
// 方法3:从文件(JSON/CSV/Parquet)创建
// 写入测试文件
df2.write.json("/tmp/user.json")
// 读取JSON文件创建DF
val df3 = spark.read.json("/tmp/user.json")
// 方法4:从Hive表创建
// 先创建Hive表(见前文),再读取
val df4 = spark.sql("SELECT * FROM student_db.student")5. DStream窗口操作
计算逻辑
DStream窗口操作基于滑动窗口:将多个连续的微批数据(RDD)合并成一个"窗口",对窗口内的所有RDD统一计算,窗口会随时间滑动(丢弃过期批次,加入新批次)。
必须的两个参数
- 窗口时长(window duration):窗口包含的微批数据的时间长度(必须是批处理间隔的整数倍);
- 滑动步长(slide duration):窗口滑动的时间间隔(必须是批处理间隔的整数倍)。
示例
scala
import org.apache.spark.streaming.{StreamingContext, Seconds}
import org.apache.spark.SparkConf
val conf = new SparkConf().setAppName("WindowOperation").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(5)) // 批处理间隔5秒
// 模拟流数据(从端口读取)
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map((_, 1)).reduceByKey(_ + _)
// 窗口操作:窗口时长10秒,滑动步长5秒
val windowedWordCounts = wordCounts.window(Seconds(10), Seconds(5))
windowedWordCounts.print()
ssc.start()
ssc.awaitTermination()6. Spark GraphX
概念
GraphX是Spark的分布式图计算库 ,用于处理大规模图数据(如社交网络、网页链接),核心抽象是Graph(由顶点RDD和边RDD组成),支持图的遍历、分区、转换、算法(PageRank、最短路径)。
分布式并行计算方式
- 图数据分区:将顶点和边分散存储在集群节点,支持多种分区策略(如EdgePartition、VertexPartition);
- Pregel API:基于"顶点中心"的并行计算模型,通过迭代执行顶点的消息传递(发送→接收→更新),实现分布式图计算;
- 复用Spark Core:基于RDD实现,利用Spark的分布式调度和容错机制,图操作最终转化为RDD的转换/行动操作。
7. 绘制用户关系网络图(基于顶点/边数据表)
步骤
- 准备数据 :
- 顶点表(user_id, name):存储用户ID和名称;
- 边表(src_id, dst_id, relation):存储用户间的关系(如好友、关注)。
- 创建Graph对象:加载顶点和边数据为RDD,构建Graph;
- 可视化(可选):将Graph数据导出为CSV/JSON,用Python(NetworkX/Matplotlib)或Gephi绘制。
示例代码
scala
import org.apache.spark.graphx.{Graph, VertexRDD, Edge}
import org.apache.spark.rdd.RDD
// 步骤1:加载顶点和边数据
val vertices: RDD[(Long, String)] = sc.parallelize(Seq(
(1L, "张三"),
(2L, "李四"),
(3L, "王五"),
(4L, "赵六")
))
val edges: RDD[Edge[String]] = sc.parallelize(Seq(
Edge(1L, 2L, "好友"),
Edge(1L, 3L, "好友"),
Edge(2L, 4L, "关注"),
Edge(3L, 2L, "好友")
))
// 步骤2:创建Graph
val userGraph = Graph(vertices, edges)
// 步骤3:导出数据用于可视化
// 导出顶点
userGraph.vertices.saveAsTextFile("/tmp/vertices")
// 导出边
userGraph.edges.saveAsTextFile("/tmp/edges")
// 步骤4:Python可视化(NetworkX)
"""
import networkx as nx
import matplotlib.pyplot as plt
# 读取顶点和边
vertices = {}
with open("/tmp/vertices/part-00000") as f:
for line in f:
line = line.strip().replace("(", "").replace(")", "").split(",")
vertices[int(line[0])] = line[1].strip()
edges = []
with open("/tmp/edges/part-00000") as f:
for line in f:
line = line.strip().replace("Edge(", "").replace(")", "").split(",")
edges.append((int(line[0]), int(line[1])))
# 绘制网络图
G = nx.Graph()
G.add_nodes_from(vertices.keys())
G.add_edges_from(edges)
nx.draw(G, labels=vertices, with_labels=True, node_size=2000, font_size=12)
plt.show()
"""8. 创建图的3种方法
scala
import org.apache.spark.graphx.{Graph, VertexRDD, Edge, EdgeRDD}
// 方法1:从顶点RDD和边RDD创建(最常用)
val vertices = sc.parallelize(Seq((1L, "A"), (2L, "B")))
val edges = sc.parallelize(Seq(Edge(1L, 2L, "link")))
val graph1 = Graph(vertices, edges)
// 方法2:从EdgeRDD创建(自动生成顶点,顶点属性为默认值)
val edgeRDD = EdgeRDD.fromEdges(edges)
val graph2 = Graph.fromEdges(edgeRDD, defaultValue = "default")
// 方法3:从顶点对(Tuple)创建(自动生成边,边属性为默认值)
val vertexPairs = sc.parallelize(Seq((1L, 2L), (2L, 3L)))
val graph3 = Graph.fromEdgeTuples(vertexPairs, defaultValue = "user")9. Spark GraphX的3种基本视图
- 顶点视图(Vertex View) :
graph.vertices,返回顶点RDD(RDD[(VertexId, VD)]),存储顶点ID和顶点属性; - 边视图(Edge View) :
graph.edges,返回边RDD(RDD[Edge[ED]]),存储边的源顶点、目标顶点、边属性; - 三元组视图(Triplet View) :
graph.triplets,返回三元组RDD(RDD[EdgeTriplet[VD, ED]]),整合顶点和边信息(源顶点属性+边属性+目标顶点属性),方便关联查询。
10. PageRank的基本思想
PageRank的核心是**"链接投票"+"随机游走"**:
- 链接投票:一个网页的重要性由所有指向它的网页(入链)的重要性决定,若网页A有kkk个出链,则A给每个出链网页投1/k1/k1/k的票;
- 随机游走:模拟用户随机点击网页链接的行为,引入"阻尼系数"(通常0.85),表示用户有85%的概率点击链接,15%的概率随机跳转到任意网页,避免"死节点"(无出链)导致的计算异常;
- 迭代收敛:通过多次迭代计算,直到各网页的PageRank值趋于稳定。
11. 机器学习相关概念
机器学习概念
机器学习是让计算机从数据中学习规律,无需显式编程即可完成任务的技术,核心是"数据→模型→预测/决策"。
三大类别
| 类别 | 特点 | 典型算法 |
|---|---|---|
| 监督学习 | 数据有标签(输入+输出) | 分类、回归 |
| 无监督学习 | 数据无标签,挖掘内在规律 | 聚类、降维 |
| 强化学习 | 通过与环境交互学习,最大化奖励 | Q-Learning、DQN |
分类vs聚类
- 分类算法:监督学习,核心是学习"特征→标签"的映射规则,用于将数据划分到预定义的类别(如垃圾邮件识别:是/否);
- 聚类算法:无监督学习,核心是根据数据的相似性,将数据划分到若干个"自然簇",无预定义类别(如用户分群)。
12. 推荐算法
特征
- 基于用户/物品的相似性;
- 处理大规模稀疏数据;
- 兼顾精准性和多样性。
两大类别
- 协同过滤:基于用户的行为相似性(如用户A和B都喜欢物品X,则推荐B喜欢的Y给A),分为用户基协同过滤、物品基协同过滤;
- 内容推荐:基于物品的内容特征(如电影的类型、演员),推荐与用户历史喜欢的物品内容相似的物品。
13. 回归算法
两大类别及原理
-
线性回归:
- 原理:假设特征与目标值之间存在线性关系,拟合出y=w1x1+w2x2+...+wnxn+by = w_1x_1 + w_2x_2 + ... + w_nx_n + by=w1x1+w2x2+...+wnxn+b,最小化预测值与真实值的平方误差(最小二乘法);
- 适用:目标值为连续值(如房价预测、销量预测)。
-
逻辑回归:
- 原理:基于线性回归,通过Sigmoid函数将输出映射到0,1区间,表示属于某一类别的概率,阈值划分类别(如>0.5为正类);
- 适用:二分类任务(如疾病诊断:患病/未患病),本质是监督学习的分类算法,但命名带"回归"。
14. 模型评估
作用
模型评估用于衡量模型的性能,判断模型的泛化能力(对新数据的预测效果),指导模型调优(如调整参数、选择特征),避免过拟合/欠拟合。
MLlib Metrics支持的常用指标
| 评估场景 | 指标 | Metrics方法 |
|---|---|---|
| 分类任务 | 准确率(Accuracy) | MulticlassMetrics.accuracy |
| 分类任务 | 精确率(Precision) | BinaryClassificationMetrics.precisionByThreshold |
| 分类任务 | 召回率(Recall) | BinaryClassificationMetrics.recallByThreshold |
| 分类任务 | F1值 | BinaryClassificationMetrics.f1MeasureByThreshold |
| 回归任务 | 均方误差(MSE) | RegressionMetrics.meanSquaredError |
| 回归任务 | 决定系数(R²) | RegressionMetrics.r2 |
| 聚类任务 | 轮廓系数(Silhouette) | ClusteringMetrics.silhouette |
15. 数据归一化
作用
数据归一化(标准化)是将不同量纲的特征(如身高:170cm、体重:60kg)映射到同一数值范围(如0,1或均值0、方差1),核心作用:
- 避免数值大的特征主导模型训练;
- 加速模型收敛(如梯度下降);
- 提升模型精度。
Spark MLlib归一化方法
- 向量类型数据归一化可使用
StandardScaler(标准化:均值0、方差1)或MinMaxScaler(归一化:0,1),属于org.apache.spark.ml.feature包。
示例
scala
import org.apache.spark.ml.feature.{StandardScaler, VectorAssembler}
import org.apache.spark.sql.DataFrame
// 假设df有特征列col1、col2
val assembler = new VectorAssembler()
.setInputCols(Array("col1", "col2"))
.setOutputCol("features")
val featureDF = assembler.transform(df)
// 标准化
val scaler = new StandardScaler()
.setInputCol("features")
.setOutputCol("scaledFeatures")
.setWithMean(true) // 中心化(均值0)
.setWithStd(true) // 标准化(方差1)
val scalerModel = scaler.fit(featureDF)
val scaledDF = scalerModel.transform(featureDF)五、程序阅读及设计
1. Scala数据统计(数量)
需求:统计多条数据记录的数量
scala
// 模拟数据(如学生成绩记录)
val data = Seq(
"张三,85",
"李四,90",
"王五,78",
"赵六,92"
)
val rdd = sc.parallelize(data)
// 统计数量
val count = rdd.count()
println(s"数据记录总数:$count") // 输出:42. reduceByKey()合并键值相同的键值对
需求:合并相同Key的Value(如单词计数)
scala
val pairRDD = sc.parallelize(Seq(
("apple", 1),
("banana", 1),
("apple", 1),
("orange", 1),
("banana", 1)
))
// 合并相同Key的Value(求和)
val mergedRDD = pairRDD.reduceByKey(_ + _)
mergedRDD.collect().foreach(println)
// 输出:(apple,2)、(banana,2)、(orange,1)3. zip()生成键值对
需求:组合独立的键和值RDD生成键值对
scala
// 键RDD(用户ID)
val keys = sc.parallelize(Seq(1, 2, 3, 4))
// 值RDD(用户名)
val values = sc.parallelize(Seq("张三", "李四", "王五", "赵六"))
// zip()组合成键值对
val kvRDD = keys.zip(values)
kvRDD.collect().foreach(println)
// 输出:(1,张三)、(2,李四)、(3,王五)、(4,赵六)
// 注意:两个RDD的分区数和元素数量必须相同,否则报错4. Scala计算分数(平均分/最高分/最低分)
scala
// 模拟分数数据
val scores = sc.parallelize(Seq(85.0, 90.0, 78.0, 92.0, 88.0))
// 计算统计值
val total = scores.sum()
val count = scores.count()
val avg = total / count
val max = scores.max()
val min = scores.min()
println(s"平均分:$avg") // 86.6
println(s"最高分:$max") // 92.0
println(s"最低分:$min") // 78.05. Spark计算各城市平均气温(思路+步骤+代码)
实现思路
- 加载温度数据,解析为(城市名,温度)的键值对;
- 按城市分组,计算每组的温度总和和记录数;
- 用总和/记录数得到平均气温;
- 输出结果。
步骤+关键代码
scala
// 步骤1:模拟城市温度数据(格式:城市,温度)
val tempData = Seq(
"北京,25",
"北京,27",
"上海,28",
"上海,26",
"广州,30",
"广州,32",
"广州,31"
)
val tempRDD = sc.parallelize(tempData)
// 步骤2:解析数据为(城市,温度)键值对(温度转Double)
val cityTempRDD = tempRDD.map { line =>
val parts = line.split(",")
(parts(0), parts(1).toDouble)
}
// 步骤3:按城市分组,计算(温度总和,记录数)
val citySumCountRDD = cityTempRDD.reduceByKey((a, b) => a + b) // 温度总和
val cityCountRDD = cityTempRDD.mapValues(_ => 1).reduceByKey(_ + _) // 记录数
val cityJoinRDD = citySumCountRDD.join(cityCountRDD) // (城市, (总和, 数量))
// 步骤4:计算平均气温
val cityAvgTempRDD = cityJoinRDD.mapValues { case (sum, count) =>
sum / count
}
// 步骤5:输出结果
cityAvgTempRDD.collect().foreach { case (city, avg) =>
println(s"$city 平均气温:$avg ℃")
}输出结果
北京 平均气温:26.0 ℃
上海 平均气温:27.0 ℃
广州 平均气温:31.0 ℃6. Spark单词计数(words.txt)
完整代码
scala
import org.apache.spark.sql.SparkSession
object WordCount {
def main(args: Array[String]): Unit = {
// 1. 创建SparkSession
val spark = SparkSession.builder()
.appName("WordCount")
.master("local[*]")
.getOrCreate()
val sc = spark.sparkContext
// 2. 加载文本文件
val lines = sc.textFile("file:///local/path/words.txt") // 本地文件
// 或HDFS文件:sc.textFile("hdfs://localhost:9000/words.txt")
// 3. 单词计数核心逻辑
val wordCounts = lines
.flatMap(_.split(" ")) // 按空格分词,扁平化
.filter(_.nonEmpty) // 过滤空字符串
.map((_, 1)) // 转为(单词,1)
.reduceByKey(_ + _) // 按单词聚合,计数
// 4. 输出结果
wordCounts.collect().foreach { case (word, count) =>
println(s"$word: $count")
}
// 5. 停止SparkContext
sc.stop()
spark.stop()
}
}测试数据(words.txt)
hello spark
hello scala
spark scala java
hello java输出结果
hello: 3
spark: 2
scala: 2
java: 27. GraphX图结构转换方法及代码分析
方法作用
| 方法 | 作用 |
|---|---|
| reverse() | 反转边的方向(源顶点↔目标顶点) |
| subgraph() | 过滤图的顶点和边,返回子图(可指定顶点过滤条件、边过滤条件) |
| mask() | 保留当前图中与另一个图的顶点/边重叠的部分,其余删除 |
| groupEdges() | 将相同源顶点和目标顶点的多条边合并为一条(需指定合并规则,如求和) |
社交网络图代码分析
scala
import org.apache.spark.graphx.{Graph, Edge, VertexId}
// 顶点数据:(用户ID, 用户名)
val vertices = sc.parallelize(Seq(
(1L, "张三"),
(2L, "李四"),
(3L, "王五"),
(4L, "赵六")
))
// 边数据:(源ID, 目标ID, 互动次数)
val edges = sc.parallelize(Seq(
Edge(1L, 2L, 5),
Edge(1L, 3L, 3),
Edge(2L, 1L, 2),
Edge(2L, 3L, 1),
Edge(1L, 2L, 4) // 张三→李四的另一条边(重复边)
))
// 创建图
val socialGraph = Graph(vertices, edges)
// 1. 合并重复边(求和互动次数)
val groupedGraph = socialGraph.groupEdges((a, b) => a + b)
// 2. 反转边方向
val reversedGraph = groupedGraph.reverse()
// 3. 过滤子图(只保留互动次数>3的边)
val subGraph = groupedGraph.subgraph(
epred = e => e.attr > 3 // 边过滤条件:互动次数>3
)
// 输出结果
println("合并重复边后的边:")
groupedGraph.edges.collect().foreach(println)
println("反转边后的边:")
reversedGraph.edges.collect().foreach(println)
println("过滤后的子图边:")
subGraph.edges.collect().foreach(println)运行结果
合并重复边后的边:
Edge(1,2,9) // 5+4=9
Edge(1,3,3)
Edge(2,1,2)
Edge(2,3,1)
反转边后的边:
Edge(2,1,9)
Edge(3,1,3)
Edge(1,2,2)
Edge(3,2,1)
过滤后的子图边:
Edge(1,2,9) // 仅互动次数>3的边六、项目案例设计:广告流量作弊检测
核心流程
数据采集
数据预处理
特征工程
模型训练
模型评估
在线检测
结果输出/告警
1. 数据采集
- 数据源:广告曝光日志、点击日志、用户行为日志(IP、设备ID、时间、广告ID、点击位置、停留时长等);
- 采集工具:Flume(实时采集)、Kafka(消息队列)、Spark Streaming(实时处理)。
2. 数据预处理
- 清洗:过滤缺失值、异常值(如点击时间<曝光时间)、重复日志;
- 格式转换:将非结构化日志转为结构化DataFrame;
- 关联:关联曝光和点击日志,匹配用户-广告的完整行为。
3. 特征工程
提取作弊检测核心特征:
- 单用户特征:单位时间点击次数、点击广告数、IP点击频率、设备ID点击频率;
- 单广告特征:点击率(CTR)、异常IP占比、设备重复率;
- 行为特征:点击停留时长、点击位置分布、是否连续点击。
4. 模型选择与设计
核心模型:监督学习(分类)+ 规则引擎
-
规则引擎(基础过滤):
- 规则1:单IP 1分钟内点击同一广告>10次 → 判定作弊;
- 规则2:点击停留时长<0.1秒 → 判定作弊;
- 规则3:设备ID无曝光直接点击 → 判定作弊。
-
机器学习模型(精准检测):
- 算法选择:逻辑回归、随机森林、XGBoost(处理非线性特征,抗过拟合);
- 标签定义:正例(作弊流量)、负例(正常流量);
- 训练流程:
- 划分训练集/测试集(7:3);
- 特征归一化(StandardScaler);
- 模型训练,调优参数(如随机森林的树深度、棵数)。
5. 模型评估与部署
- 评估指标:精确率(减少误判正常流量)、召回率(尽可能识别作弊流量)、F1值;
- 部署:将模型序列化,集成到Spark Streaming实时处理流程,对实时流量进行评分,作弊流量触发告警。
6. 迭代优化
- 定期更新训练数据(新增作弊模式);
- 监控模型效果,调整规则和模型参数;
- 新增特征(如用户行为序列特征)。
总结
核心知识点回顾
- Spark核心抽象:RDD(不可变、分布式)、DataFrame(结构化)、DStream(流式)、Graph(图数据)是Spark各模块的基础;
- 核心操作:RDD的转换/行动操作、DataFrame的SQL/DSL查询、窗口操作的两个关键参数(窗口时长、滑动步长)是实操重点;
- 机器学习:监督/无监督/强化学习的分类、回归/分类/聚类的区别、模型评估和数据归一化是MLlib的核心;
- 项目落地:广告作弊检测等案例需遵循"数据采集→预处理→特征工程→模型训练→部署优化"的流程,结合规则和机器学习提升效果。
实操关键点
- 环境配置:伪分布式集群搭建需重点配置
spark-env.sh,验证集群状态; - 代码编写:Spark程序需遵循"创建上下文→加载数据→处理数据→输出结果"的流程,注意RDD的分区、Shuffle优化;
- 调试技巧:优先本地模式调试,再部署到集群,利用
take()/show()查看中间结果。