2025年,AI 技术迎来了以自主行动、目标导向和环境交互为特征的 Agentic AI 时代 ,与此同时,透过机器人、辅助驾驶等前沿探索,复杂 AI Agent 系统也正迅速从数字世界迈向物理世界 。在2025云栖大会上,阿里云智能集团计算平台负责人汪军华发表 《大数据 AI 平台:构筑 Agentic AI 核心基石》 主题演讲,并带来阿里云大数据AI平台多款产品升级发布。
汪军华表示,模型、AI基础设施、数据基础设施、端到端搭建工具是落地 Agentic AI 的关键四要素 ,阿里云大数据 AI 平台围绕这四大要素提供有力的技术支撑。 
阿里云智能集团计算平台负责人汪军华现场演讲
加速世界模型研发,PAI 与 NVIDIA Physical AI 软件栈合作
在大模型能力加速进化的今天,除了推理模型和各类 Agentic 能力增强模型,世界模型同样备受关注。世界模型能够理解和遵循物理规律,具备因果推理、时间推演等能力,是大模型真正深入现实物理世界的关键。
构建"全知全感"的世界模型,对基础设施和开发平台提出了全新要求。一方面,世界模型依赖的数据处理工程更加复杂,需要进行符合物理规律的多模态数据合成、进行图片视频向点云轨迹等半结构化数据的转换、以及深层次数据理内容理解等;另一方面,由于极端场景无法在现实中全面测试,仿真平台重要性尤为凸显;此外,多种模型需要云、边、端多种服务平台支持。
为此,阿里云与 NVIDIA 正式宣布在 Physical AI 方向达成产品合作。PAI 将集成 NVIDIA Isaac Sim、Isaac Lab、NVIDIA Cosmos、Physical AI 数据集 在内的 NVIDIA Phsyical AI 软件栈,并结合阿里云在规模化数据计算、高性能AI训练推理、大数据AI一体化开发等领域的体系化能力,形成覆盖数据预处理、仿真数据生成、模型训练评估、机器人强化学习、仿真测试在内的全链路平台支撑,让 Physical AI 领域开发者充分享受云的弹性与灵活,全面加速 Physical AI 创新落地。
目前,PAI 平台内已经上架了遥操数据采集、数据合成、数据增强、机器人模仿学习、验证测试全环节五大场景的最佳实践,以 Notebook 形式供开发者开箱即用。 
阿里云 x NVIDIA合作发布
预训练、后训练、推理全流程优化,AI 基础设施再升级
作为全栈人工智能服务商,阿里云兼具领先的自研大模型、活跃的开源模型生态与强大的 AI Infra 体系。应对新的模型架构和计算特点,阿里云人工智能平台PAI与通义大模型联合优化,印证了全栈AI"1+1>2"的效果。
针对 MoE 架构模型,PAI 推出大规模 MoE 训练引擎 paiMoE, 采用统一调度机制、自适应计算通信掩盖、EP 计算负载均衡和计算显存分离式并行等优化手段,有效解决工作负载不同、稀疏 MoE 通信占比高等问题,在 Qwen3 训练过程中实现端到端加速比提效 3 倍,训练 MFU 超过 61%。 
目前,paiMoE 引擎两项核心技术 Tangram 和 ChunkFlow 已在 Qwen 全系模型的 CPT/SFT 阶段作为默认方案 ,Tangram 支持支持多样化细粒度 MoE 训练任务,一套机制支持不同的计算、通信、显存与负载均衡需求。ChunkFlow 针对处理变长和超长序列数据的性能问题,提出了以 Chunk 为中心的训练机制。变长序列数据重新组织为等长 Chunk 并且结合调度,有效提升训练效率,研究成果被 ICML 2025 收录。 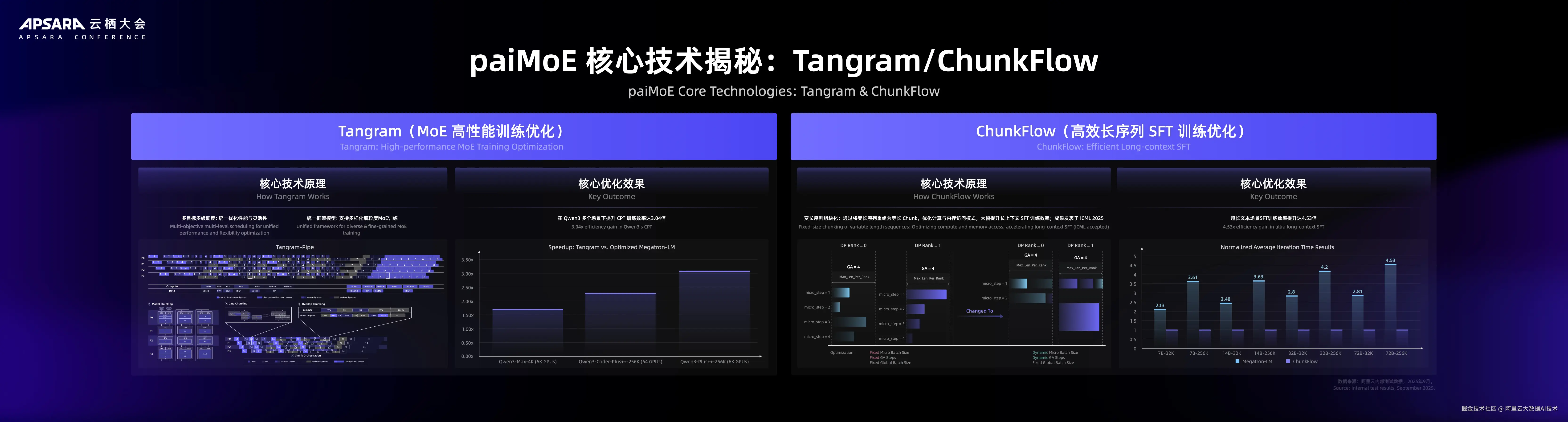
针对 DiT 架构模型 ,PAI 推出训练推理一体化加速引擎 paiFuser,通过计算图优化、显存复用、通信压缩、动态调度等手段,显著降低资源消耗,提升系统吞吐。在8卡并行推理场景下,视频生成耗时最高减少80%以上,在保障画质前提下实现"分钟级"甚至"秒级"输出,为短视频生产、沉浸式VR、AIGC创意工具等时效敏感型业务提供坚实底座。
在推理层, 通过大规模EP、PD/AF分离、权重优化、LLM智能路由在内的全链路优化,实现推理效率显著提升:推理吞吐TPS增加71%,时延TPOT降低70.6%,扩容时长降低97.6%。此外,PAI-EAS 重磅推出企业级 EP 解决方案 ,助力千亿参数 MoE 模型以更低的成本、更高的效率服务于线上业务。 
大数据平台全面支持 AI 计算和服务
无论是模型训练还是推理,都离不开数据的支撑。阿里云大数据平台宣布面向 AI 产品进行全新升级,全面支持AI计算和服务。 
大数据平台 MaxCompute、Hologres、EMR、Flink 等产品数据处理全面支持 AI Function,将AI能力深度集成至传统数据处理流程。 在SQL或Python作业中,调用AI模型如同调用普通函数,实现数据处理与AI推理的无缝融合。MaxFrame推出面向AI场景的新一代原生分布式Python引擎DPE,数据处理性价比提升1倍,支持数据预处理,ML训练推理,异构资源计算,Python原生UDF以及AI Function等计算场景。
各行各业都广泛需要多模分析检索,大数据平台致力于打造AI应用的知识检索系统,让数据发挥更大的价值。EMR-Starrocks 全新支持全文检索,OpenSearch GPU实例驱动向量索引构建,整体性价比提升10倍,Milvus、ElasticSearch、Hologres支持向量+全文混合检索,其中Hologres 发布全新向量索引 HGraph,登顶 VectorDBBench 性价比榜单 QPS、Recall、Latency、Load 四项第一。
在数据运维方面,大数据平台DataWorks、MaxCompute、Hologres、EMR等产品推出通过自然语言交互即可实现数据开发、运维等操作的智能化交互式产品能力,发布 Data Agent 组件,全面实现 Agentic化。
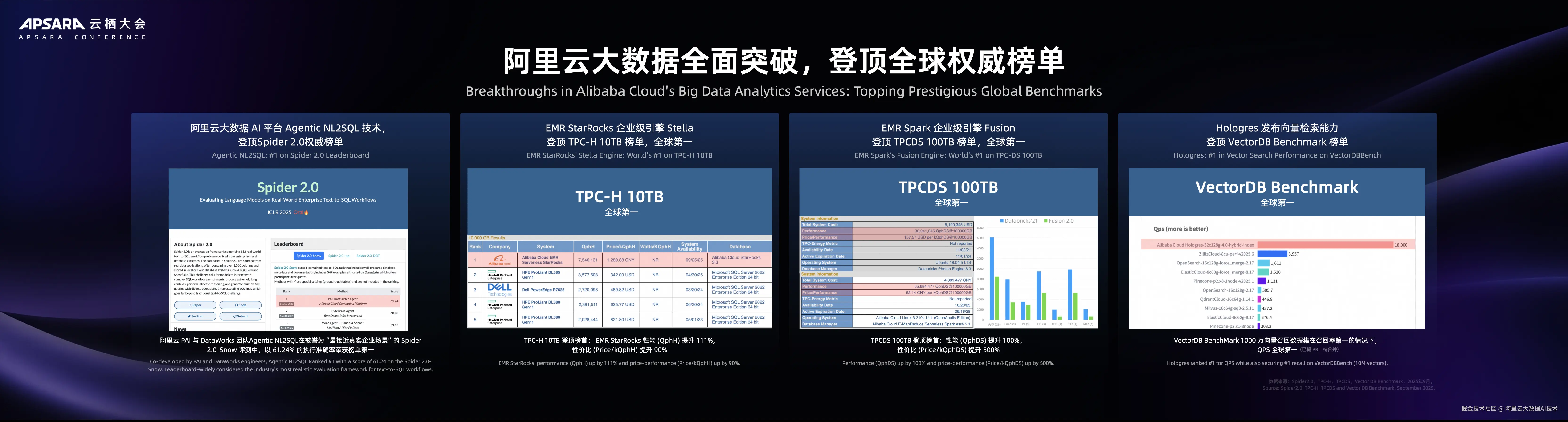
大数据平台在多项国际评测中登顶榜单。
-
阿里云 PAI 与 DataWorks 团队Agentic 在NL2SQL的 Spider 2.0-Snow 评测中,以 61.24%的执行准确率荣获榜单第一。
-
EMR 荣获两项国际榜首, Fusion (企业级 Spark 内核) 和 Stella (企业级 StarRocks 内核) 技术登顶 TPC 全球榜单。其中EMR Serverless Spark在TPC-DS 100TB测试中,以 QphDS 性能提升100%的成绩夺冠。
-
Hologres 全新向量索引 HGraph 登顶 VectorDB Benchmark 榜单,1000 万向量召回数据集在召回率第一的情况下,QPS 亦全球第一。
构建 AI 数据底座,OpenLake 面向全模态数据量身定制
在 Agentic AI 时代,阿里云OpenLake同样进行了全方位升级,满足客户面对物理世界全模态数据时所需的一体化数据存储和管理系统。
DLF 3.0 拓展全模态数据支持,湖仓目录服务(DLF)作为湖仓存储层统一管理核心,将存储格式从传统结构化数据,拓展至全模态数据场景,支持面向 AI 场景的 Lance、Iceberg以及文件数据、格式化表格数据等全类型。
计算生态方面,OpenLake 通过多引擎平权联合计算架构,可实现数据无需搬家、多引擎协同处理,湖仓存储层(DLF+Managed Storage)作为单一份数据源,向上对接全链路大数据&AI 引擎。OpenLake同时 推出 OpenLake Studio 多模态 Data&AI 一体化开发平台,实现一站式数据开发-治理-运维闭环,降低多模态数据+AI 的开发门槛。
淘天集团在面临数据孤岛、多引擎协同、运维成本高等问题上,采用OpenLake "存储层统一→计算层整合→湖流一体化"的技术路径,最终实现"实时化、一体化、低成本、高效率"的数据湖仓升级目标 ,为业务创新与降本提效提供了坚实数据基础。 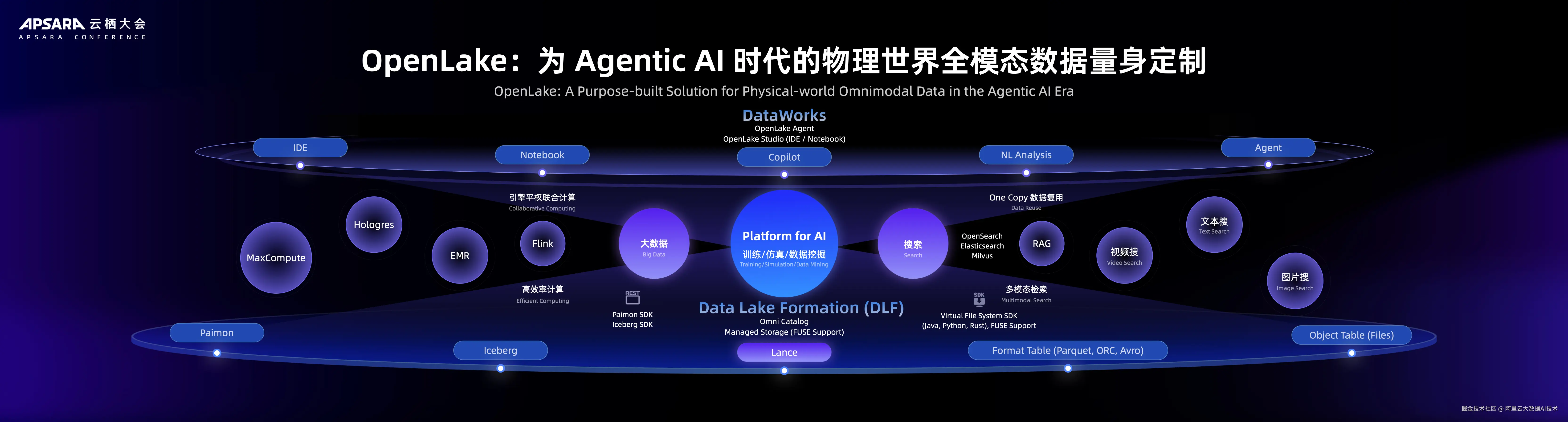
Agentic Search 发布:AI 搜索迈入自主协作时代
大模型的爆发式发展,传统搜索流量逐渐转向AI驱动的搜索工具,这一转变背后将重构用户搜索的交互逻辑、数据形态与技术架构。为此,阿里云正式发布 Agentic Search架构 ,该架构通过多Agent协同、多模态数据处理与任务自主规划,构建了从"问题提出"到"方案自主生成"的智能闭环,补齐实现 Agentic t AI 的最后一公里。 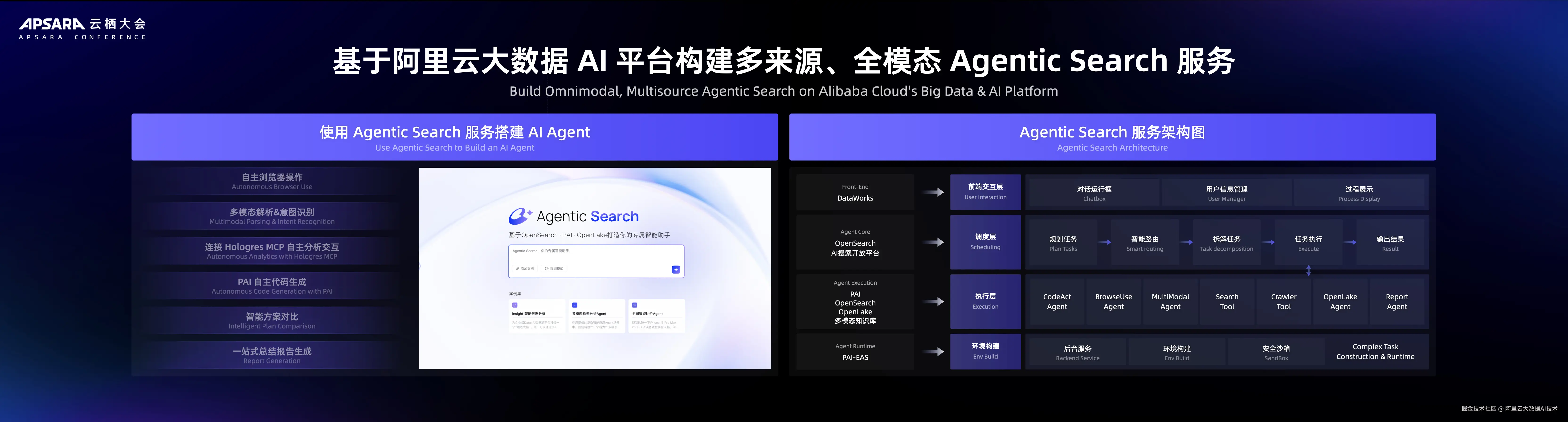
多模态数据处理:支持文档、图像、代码、视频等内容的解析、实体抽取与向量化,覆盖向量引擎、数据库、知识图谱等多引擎协同;
自主任务规划:依托Qwen3大模型与短期/长期记忆能力,主Agent可动态调用Code Agent、Browser Agent等工具,实现复杂问答与多跳推理;
权威测试领先:在OpenAI的BrowseComp与Deep Research评测集中,Agentic Search检索与推理能力超越Gemini、OpenAI等国际主流方案,复杂任务准确率提升超40%。
智能辅助驾驶&机器人数据预处理与模型训推解决方案发布
根据相关预测,2025年 L2+ 车型销量将从100万辆飙升至1000万辆。智能辅助驾驶的广泛应用带来了海量数据,在技术架构层面,也正经历从传统分阶段小模型架构向端到端多模态大模型的技术范式迁移,当前智驾系统实现了感知、决策、控制模块的深度耦合。这也推动底层的大数据AI工程架构不断升级,促使数据收集、数据处理、模型训练、模仿学习、仿真验证在内的工程链路进一步融合。同时,我们在机器人研发落地的场景中,也发现了相似的趋势与需求。
阿里云与客户在共建智能产线的过程中,总结并发布了面向智能辅助驾驶和机器人研发的数据处理与模型训推解决方案。 
方案底层统一的元数据管理(DLF)实现对百PB级数据的高效管控,显著降低因数据备份、流动和处理带来的成本,并提升处理效率。数据仅需存储一份,即可被多种计算引擎调用,结合缓存加速与全模态压缩技术,进一步优化研发流程。
数据处理依托MaxFrame/Spark/Ray等分布式计算引擎,在CPU/GPU异构集群中实现高效调度与资源复用,并借助Data Juicer算子框架加速预处理。经预处理生成的训练样本,通过大模型数据挖掘产生新标签与Embedding。方案提供自研与开源两套检索引擎,支持在百PB数据中快速检索所需样本。
在模型训练与推理阶段,人工智能平台 PAI 及 paiTurboX 加速框架通过多系统联合优化,实现至高3倍性能提升,最大化硬件资源利用率,提升研发效益。
卓驭是国际领先的智能辅助驾驶供应商,提供行业一流的量产辅助驾驶和高级别智能辅助驾驶系统(覆盖L2~L4),已与大众汽车、上汽通用五菱、比亚迪、奇瑞汽车、长城汽车等十余汽车品牌达成深度合作,联合推出 30 余款量产新车型,还有 30 多款车型即将量产落地。在智驾系统最核心的算法方面,卓驭创新性地采用端到端世界模型和VLA方案,基于自回归架构和强化学习,实现智驾系统的Scaling Law,不仅实现安心拟人的驾驶体验,也为用户提供驾驶Agent的智能化交互体验。
卓驭 AI 首席技术官陈晓智表示,依托阿里云,卓驭搭建了超过 3 EFLOPS 的 AI 智算平台和大数据平台,支撑十亿级别的场景数据处理、全维度的业务洞察、以及端到端世界模型及VLA模型的高效训练。未来,卓驭将携手阿里云,持续打造全球领先、全球共享的智能辅助驾驶系统。

卓驭 AI 首席技术官陈晓智现场演讲
自变量机器人是国内最早采用完全端到端路径实现通用具身智能大模型的机器人公司之一,其自研的具身智能大模型 WALL-A 具备自主感知、推理、长程决策交互、世界模型与高精度复杂操作能力,多个维度能力处于全球领先水平。基于自研的基础模型,自变量推出全自研高自由度灵巧手、轮式双臂仿人形机器人"量子2号(Quanta X2)等硬件,已在多步骤复杂任务场景中逐步落地应用。
机器人是高度分散式的终端,但又需要和云紧密结合。自变量创始人&CEO 王潜表示,"我们需要算力、大数据、人工智能平台三位一体的、适用于具身智能的云上AI基础设施架构。阿里云灵活、高性能的大数据 AI 平台,能够完美符合并满足机器人数据预处理、分布式部署、分布式训练、数据大规模远程回传等各方面的需求,极大提升研发及模型迭代效率。"  自变量创始人&CEO 王潜现场演讲
自变量创始人&CEO 王潜现场演讲