前言
在新项目中,我们需要存储和分析大量的埋点数据。很多同事第一反应是使用 Elasticsearch ------ 这并不奇怪,毕竟在不少团队里,ES 被当成"万能数据库",既能存储数据,又能提供查询能力。
然而,ES 并不是一遇到大数据量就能一刀切的解决方案 。它真正擅长的是全文检索、分词和高亮搜索,核心是为"查得快、搜得准"而设计。但在埋点场景下,我们更关心的是高并发写入、长时间存储和大规模聚合统计。这类需求在 ES 中往往带来高存储成本、索引膨胀和查询性能瓶颈。
相比之下,ClickHouse 作为一款列式 OLAP 数据库,天然适合处理埋点数据:批量写入快、压缩比高、聚合查询性能强 ,能以更低的资源消耗支撑埋点分析需求。正所谓------
👉 ES 是搜索的利器,而 ClickHouse 才是埋点的归宿。
所以,这里并不是说 ES 不好,而是要明确:工具没有好坏,只有适不适合。搜索场景用 ES,埋点分析就该交给 ClickHouse。基于这样的判断,我决定亲自落地搭建 ClickHouse,这也是我第一次从零开始实操,借此机会把过程和经验整理成一篇博客,和大家一起探索。
实践
准备
本文是在linux 环境中通过docker容器部署clickhouse数据库。所以开始的前提得有台linux服务器以及服务器中安装了docker环境。还有你得熟悉docker的基本命令。
安装clickhouse镜像
从去年2024年开始国内许多的商业服务器都不能直接通过命令拉去docker镜像了,通过docker命令访问远程镜像都会报请求超时错误,如下:

所以要想构建docker官方仓库中的镜像,得自己手动去下载到本地,然后上传到自己服务器进行命令加载。接下来就是具体实现步骤
1.使用DockerTarBuilder下载镜像
首先我们fork GitHub开源项目github.com/wukongdaily... 到自己仓库中(详细步骤作者也在文档中提供了,可自行访问查看)
2.查看clickhouse镜像版本
这里直接访问docker镜像仓库,dockerhub网站进行搜索即可:
hub.docker.com/search?q=cl...
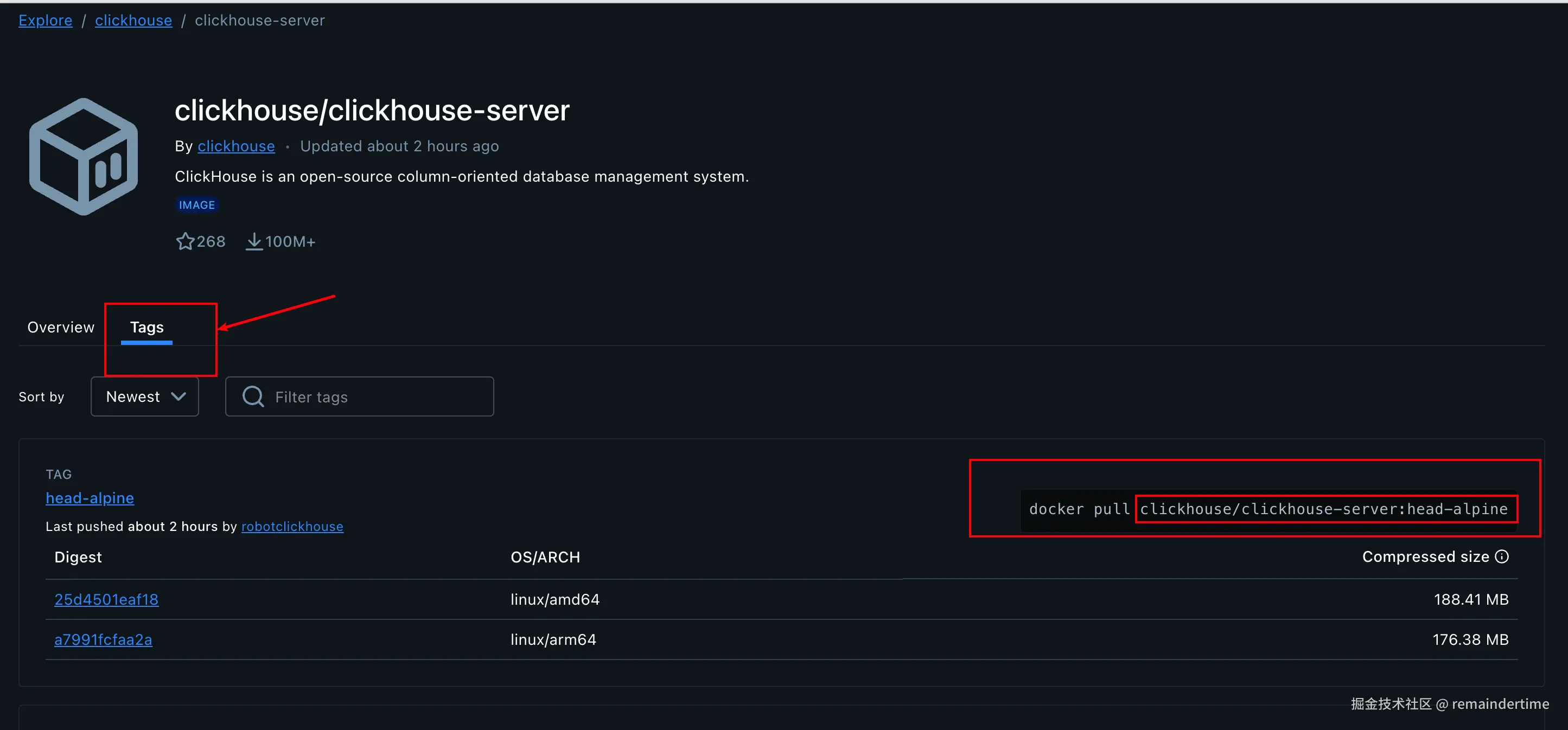
找到对应的版本,这里博主选择的是最新稳定版本:clickhouse/clickhouse-server:25.8
3.构建clickhouse镜像
按照DockerTarBuilder官方的文档步骤将镜像包下载到本地,然后上传到自己的服务器的文件夹中,然后只想命令:
css
docker load -i 镜像包名称
执行完成后查看已有的镜像:docker images
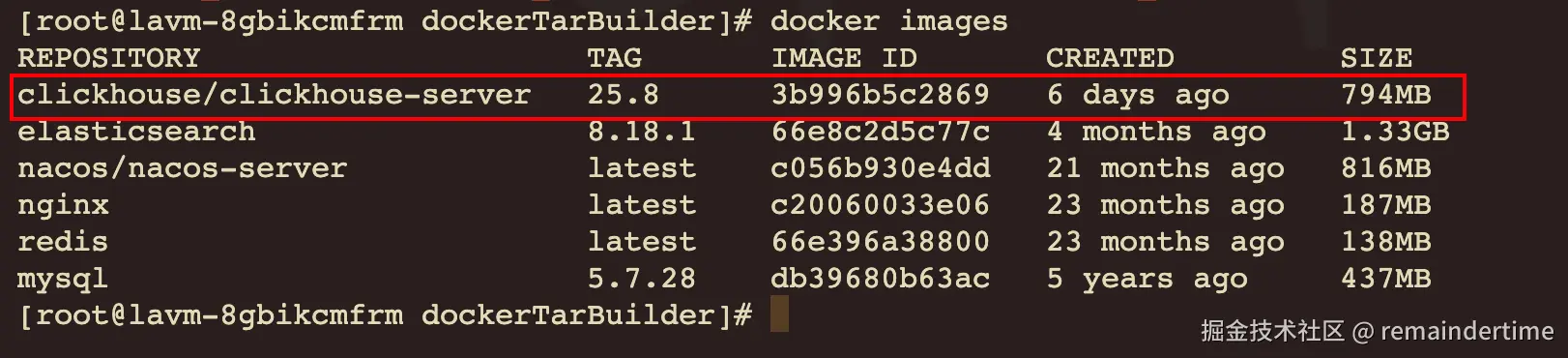
部署clickhouse容器
1. 创建clickhouse文件夹
博主是在服务器的opt文件夹下面进行创建的
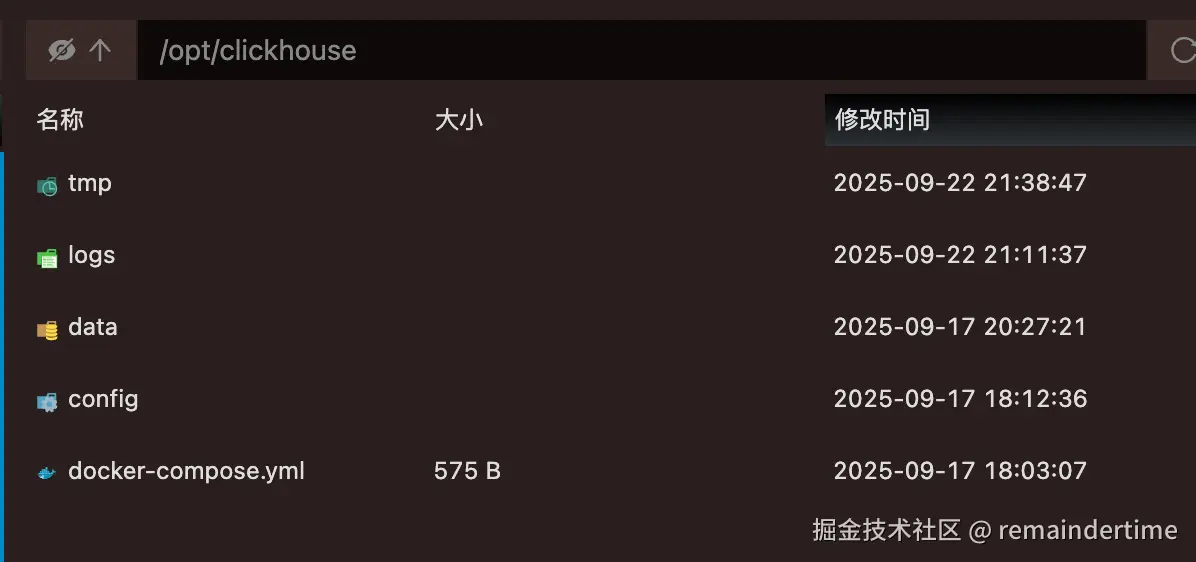
创建对于文件夹和文件的作用就是将clickhouse容器中的配置和数据映射到宿主机中,方便我们管理。
在config文件夹中还需要创建2个配置文件(内容可以先空着)
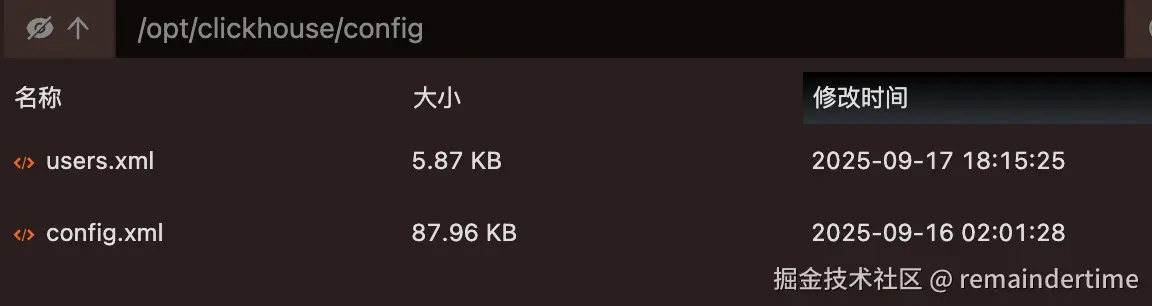
2. 设置配置文件
编辑docker-compose.yml文件内容
yml
services:
clickhouse:
image: clickhouse/clickhouse-server:25.8
container_name: clickhouse-server
restart: unless-stopped
ports:
- "8123:8123" # HTTP 接口
- "9000:9000" # TCP 接口
ulimits:
nofile:
soft: 262144
hard: 262144
volumes:
- ./data:/var/lib/clickhouse # 数据持久化
- ./logs:/var/log/clickhouse-server
- ./tmp:/var/lib/clickhouse/tmp
- ./config/config.xml:/etc/clickhouse-server/config.xml
- ./config/users.xml:/etc/clickhouse-server/users.xml先临时简单构建一个clickhouse容器
bash
docker run -d --name ch-test -p 9000:9000 -p 8123:8123 clickhouse/clickhouse-server:25.8查看镜像已经构建成功

拷贝镜像中的配置文件到自定义config文件夹中
bash
docker cp 镜像id:/etc/clickhouse-server/config.xml ./config/config.xml
docker cp 镜像id:/etc/clickhouse-server/users.xml ./config/users.xml然后再去查看对于自定义的文件就已经有内容了。
- 1.config.xml中的内容不用改动,保持官方一样
- 2.clickhouse默认没有密码,如果你的clickhouse要设置账号密码,则需要改动users.xml文件,设置账号密码,找到对应标签修改即可
xml
<users>
<admin>
<password>123456</password>
<networks>
<ip>::/0</ip> <!-- 允许所有IP访问,可改成指定IP或网段 -->
</networks>
<profile>default</profile>
<quota>default</quota>
</admin>
</users>最后就是暂停并且删除临时构建的clickhouse容器
3.构建clickhouse容器
进入clickhouse文件夹,执行命令:docker compose up -d

容器构建成功
4.验证clickhouse容器
如果你是在自己购买的商用服务器中,则需要先在安全组中开放端口8123和9000
然后访问:http://ip:8123/
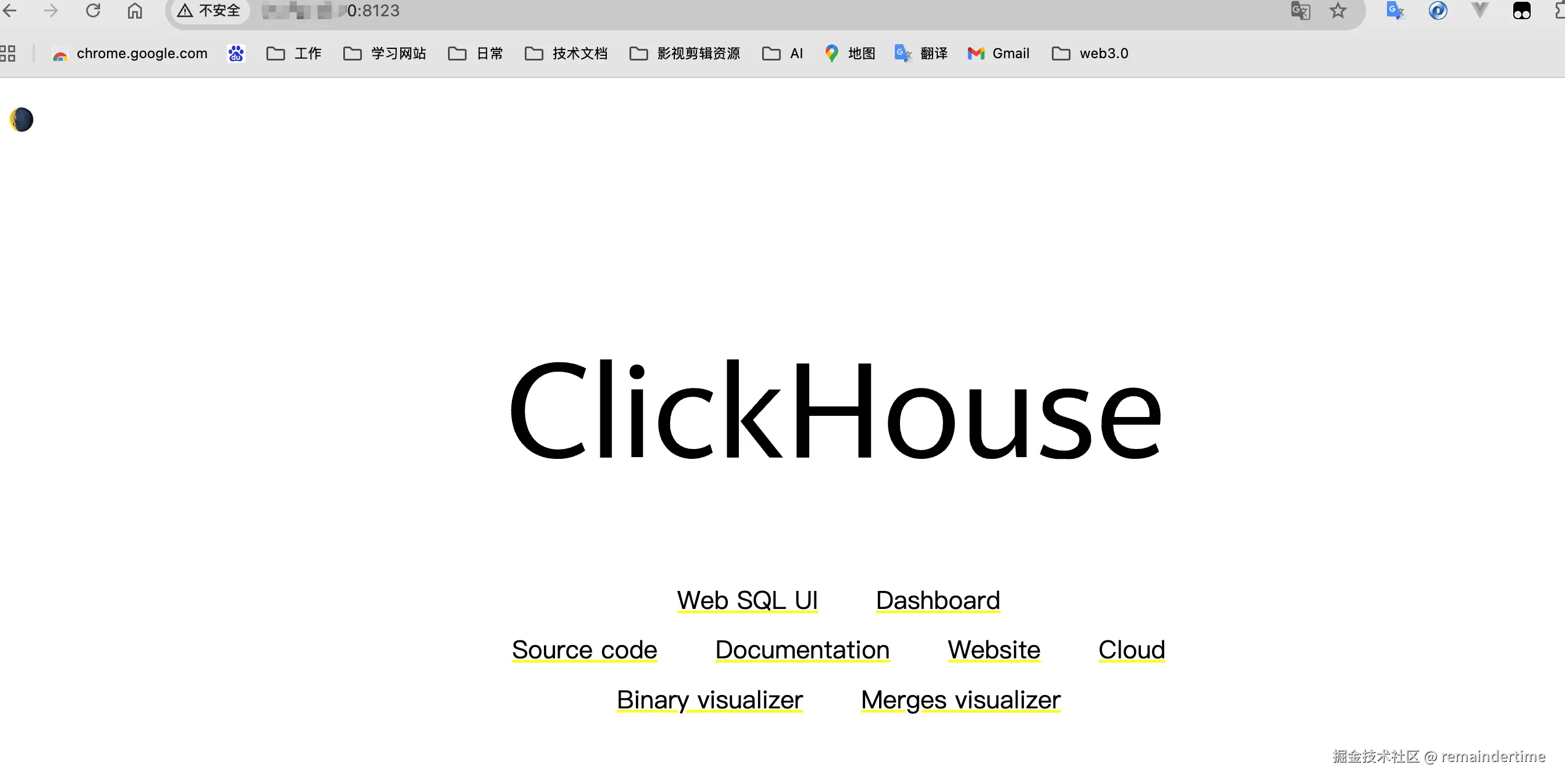
连接clickhouse
1.下载安装DBeaver工具
clickhouse和mysql一样是数据库,所以也有GUI工具,但是navcat并没有支持连接clickhouse,因此我们选择强大的DBeaver工具
选择对应系统版本下载傻瓜式安装就行
2.连接clickhouse
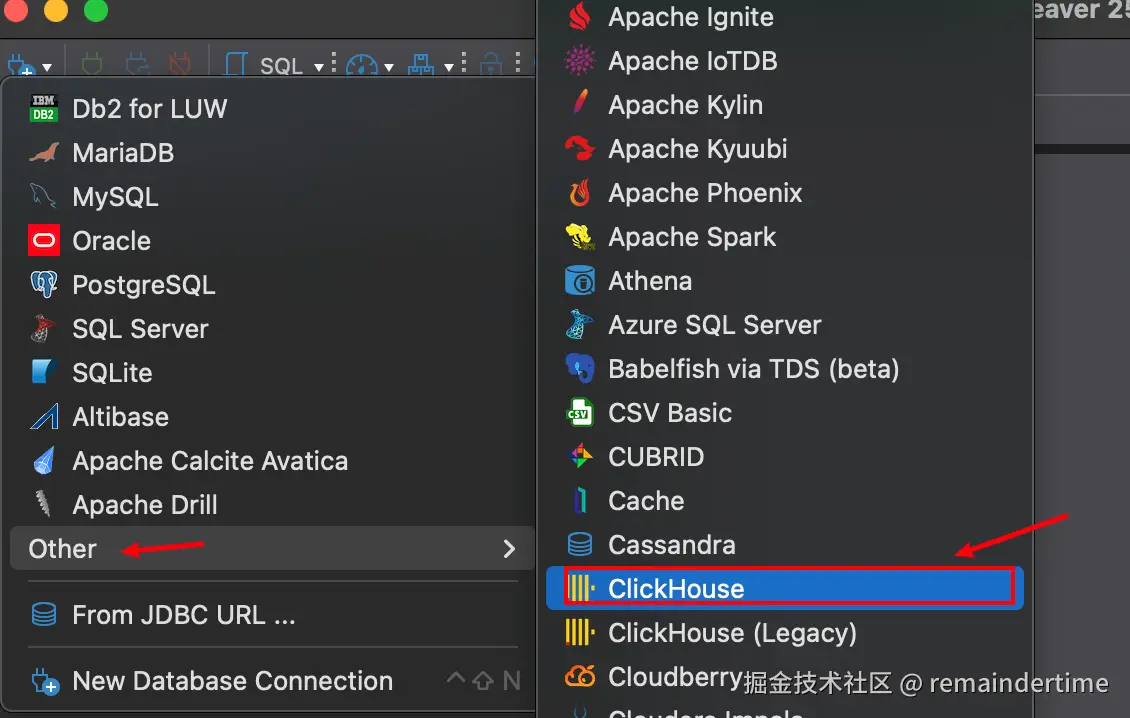
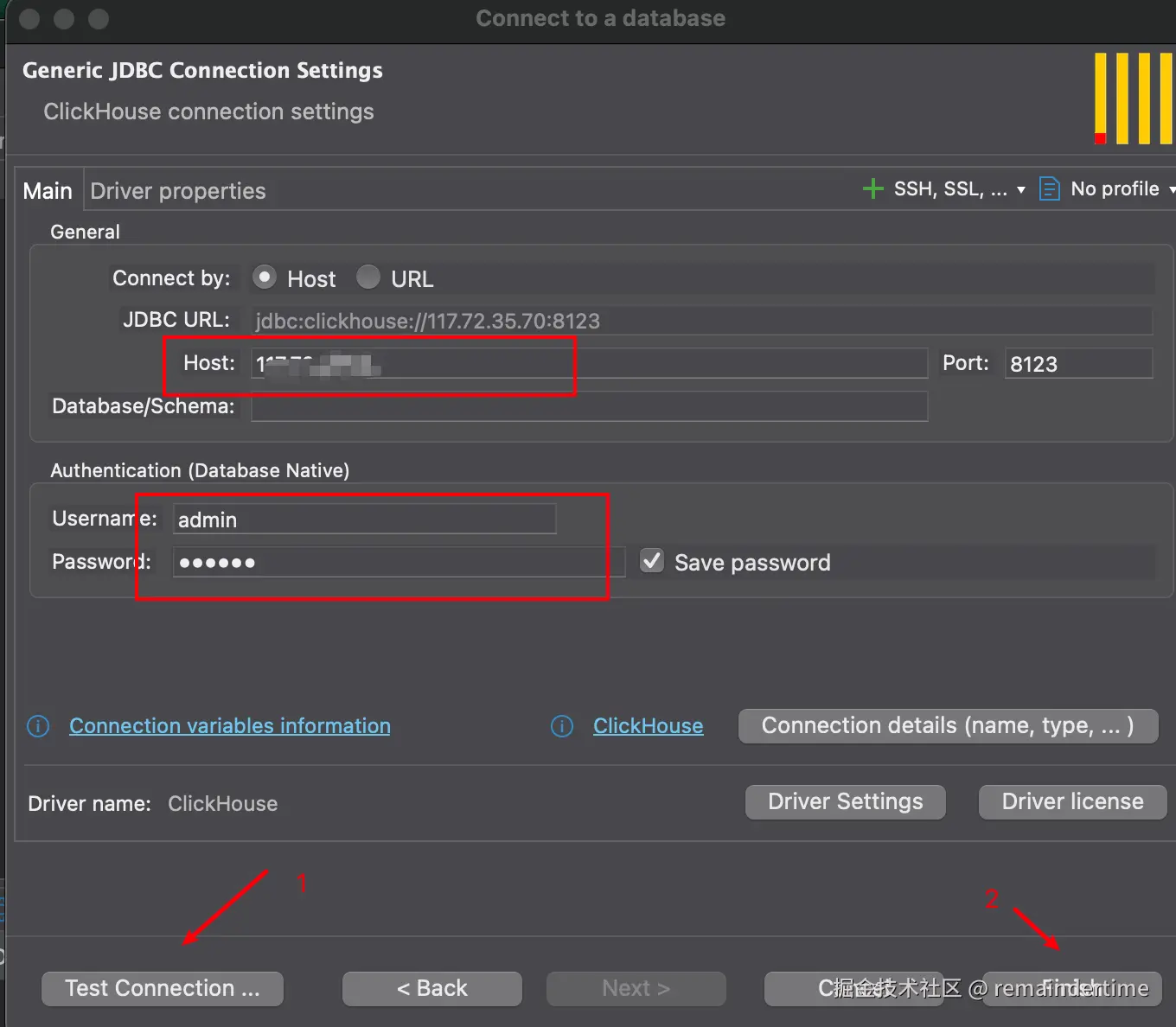
展望
说到底,还是得熟悉 ClickHouse 的语法。别看它和 MySQL 有点像,但细节上差异挺大,哪怕一个小错误都会卡住。把这些坑趟过去,才能让 ClickHouse 真正展现出它的实力。