当我们服务器只有一台时,可能会出现单点问题,当这台服务器挂了,或者需求量超出主机所支持,那么我们的服务就会受到大的影响
为了解决问题 我们引入了分布式系统
在分布式系统中,在多服务器上部署Redis,存在以下几种方式
1.主从模式
2.主从+哨兵模式
3.集群模式
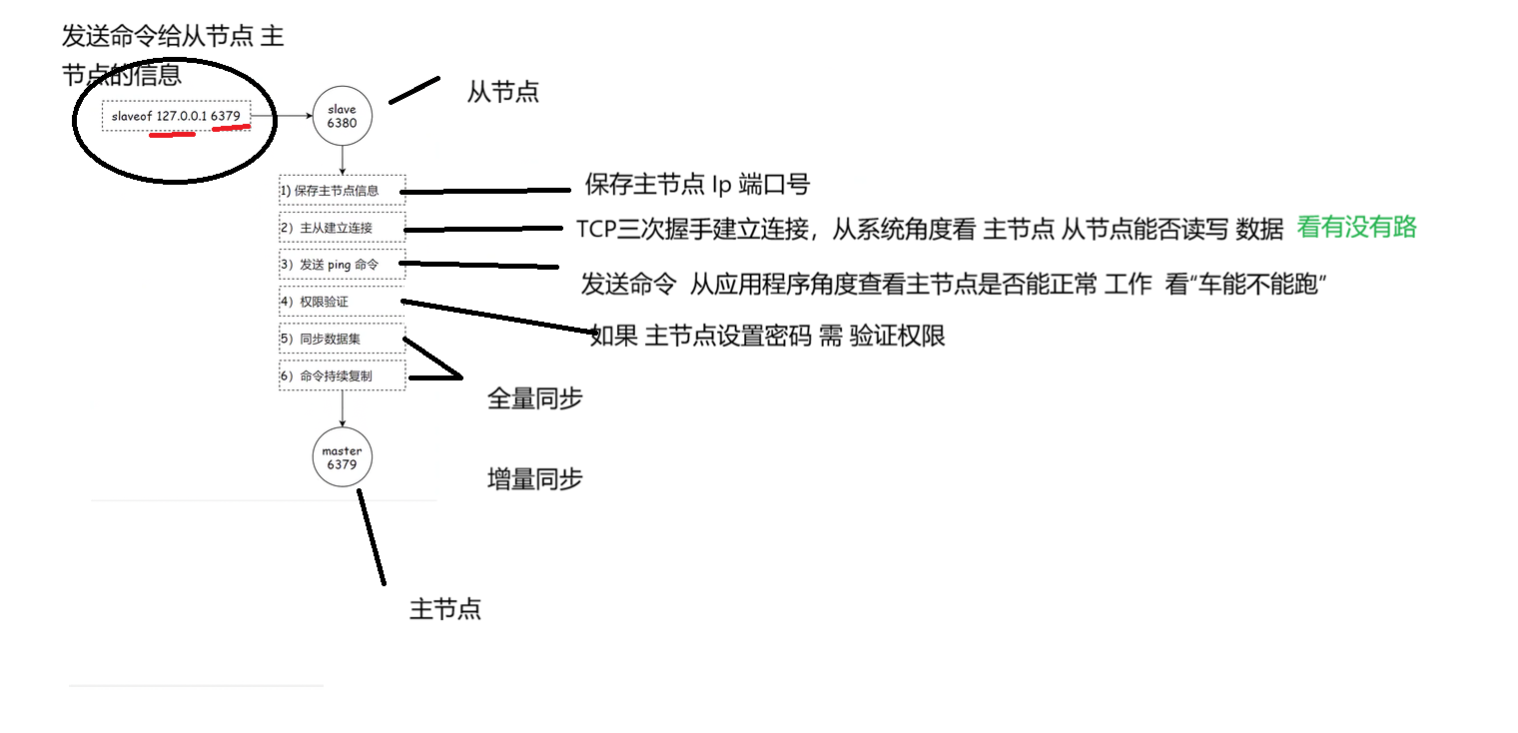
主从模式
我们将服务器区分为 主节点和从节点。
当主节点中存在的数据时,我们引入从节点,就会使主节点将数据拷贝到从节点中,后续主节点的数据修改,会及时同步拷贝到从节点中
当我们修改从节点的数据时 会不会主节点会改变?
不会,从节点顾名思义是主节点的小弟,Redis规定了从节点数据不允许直接修改,从节点只具有读取数据的能力
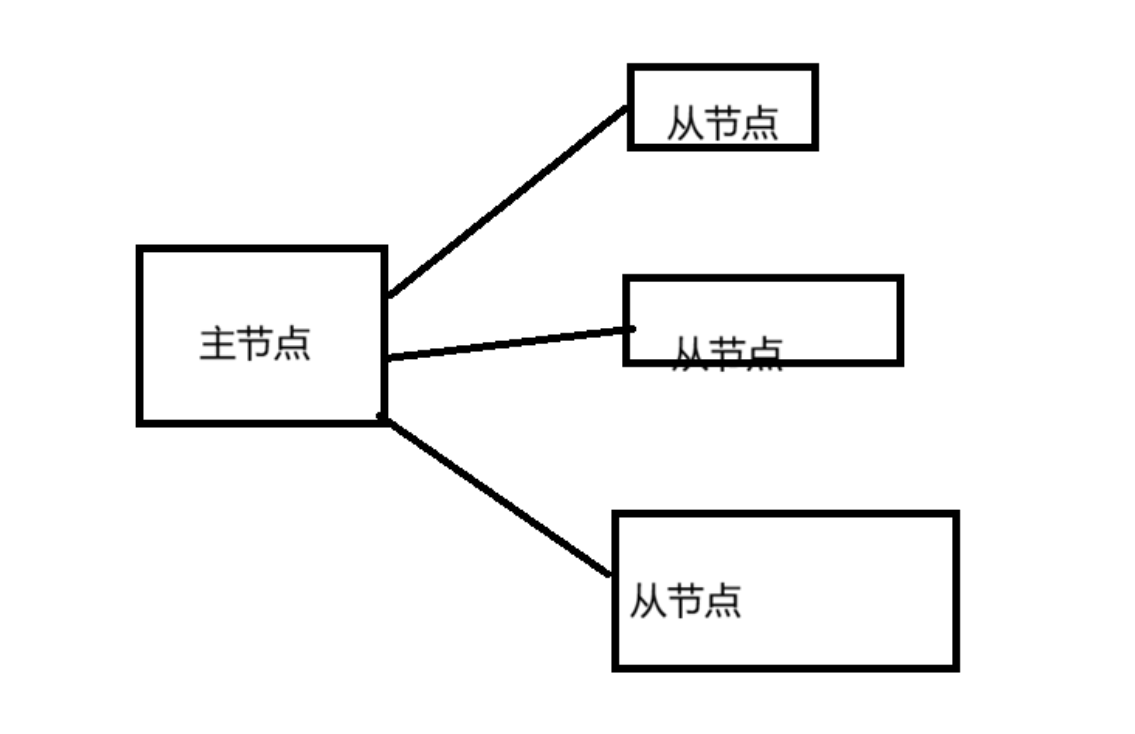
当引入这样的 模式后,主节点和从节点中的数据本身是一样的,所以访问主节点和从节点读取数据都是可以的,这样 引入了更多的 计算资源那么 所能支撑的并发量就大大提升了。
但其实我们不难发现 这样主从模式存在弊端,由于一山不容二虎,主节点不能创建多个,因此呢当主节点挂了,我们是无法进行写操作的,所以主从模式 更多的是针对于读操作的可用性提升,而对于写操作仍会受到限制
主从复制拓扑结构
1.一主一从结构
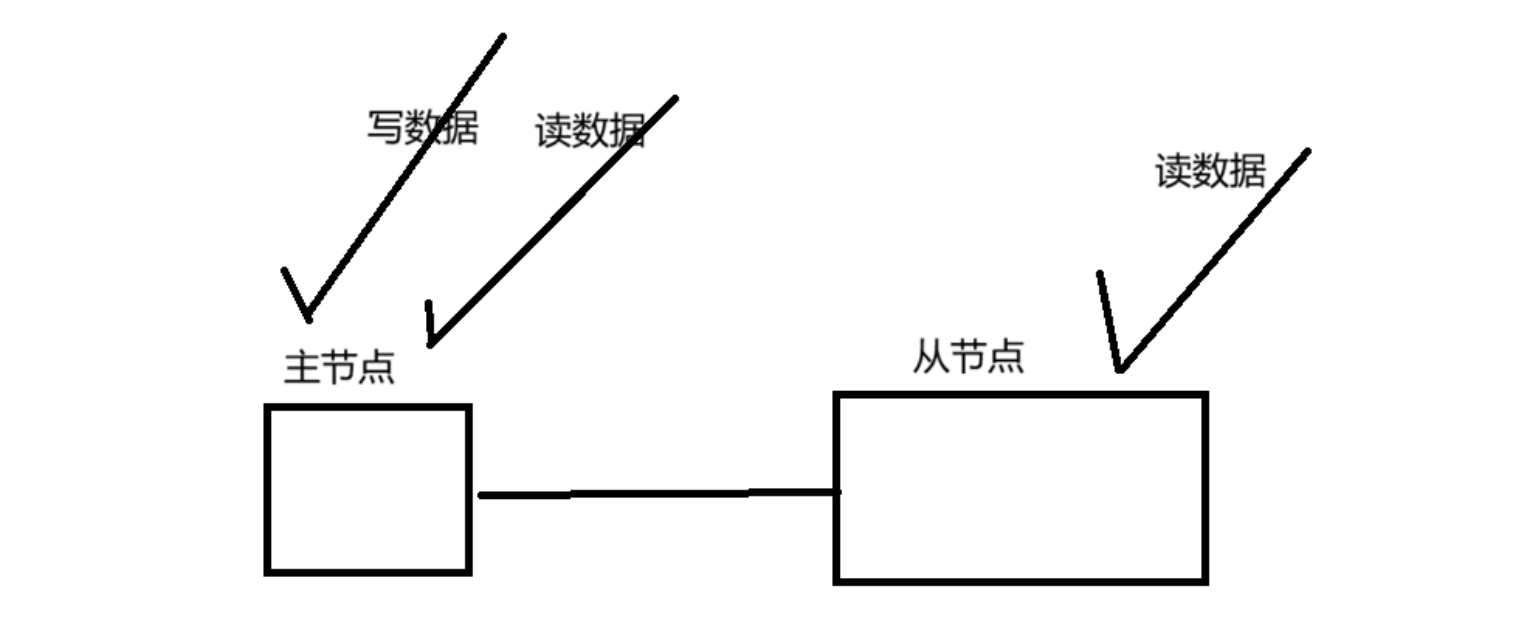
这种结构下只有主节点可以进行写操作,如果写请求 过多,就会给主节点带来压力
可以通过关闭主节点的AOF,只在从节点上开启AOF
但是这种设定有一个严重的缺陷 ,当 主节点挂掉之后,不能让它自动重启,(如果让它自动重启,此时没有 AOF文件,就会丢失数据,进一步的主从复制,就会把从节点上的数据也给删了)
改进方法,就是当主节点挂了之后,需要让主节点从从节点中获取到AOF的文件,在启动~
实际开发 中 读操作多于写操作
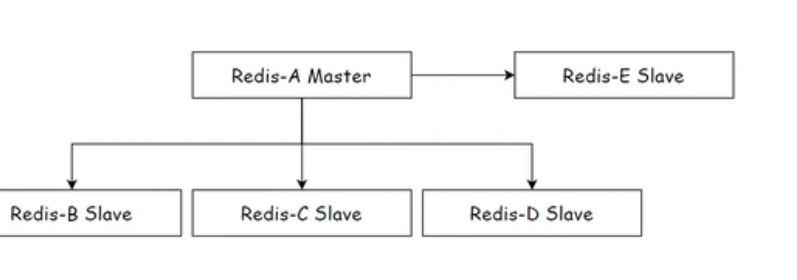
如上图所示 主节点连接四个从节点,但当主节点数据进行修改时**,随着从节点数的增加,数据从主节点同步到从节点就会 给主节点的 带宽造成压力**
2.树形结构
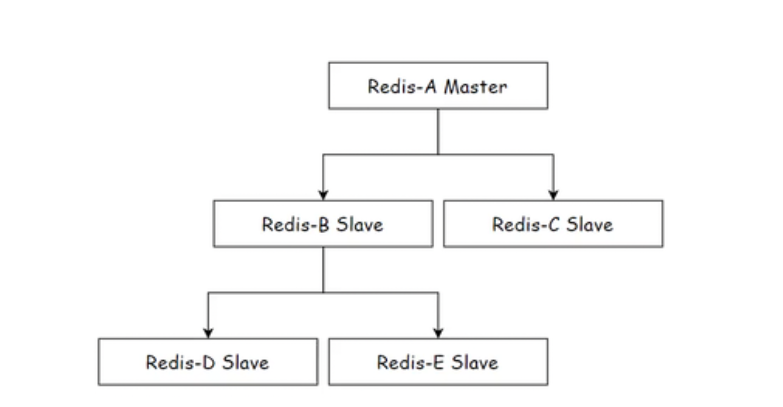
这样的结构呢 就会使主节点数据更新时,数据同步给从节点的网卡带宽就会减轻
但是 它的缺点就是数据同步的延迟要比上面的高
所以我们在 选取时要根据实际情况做出取舍
主从复制的基本流程

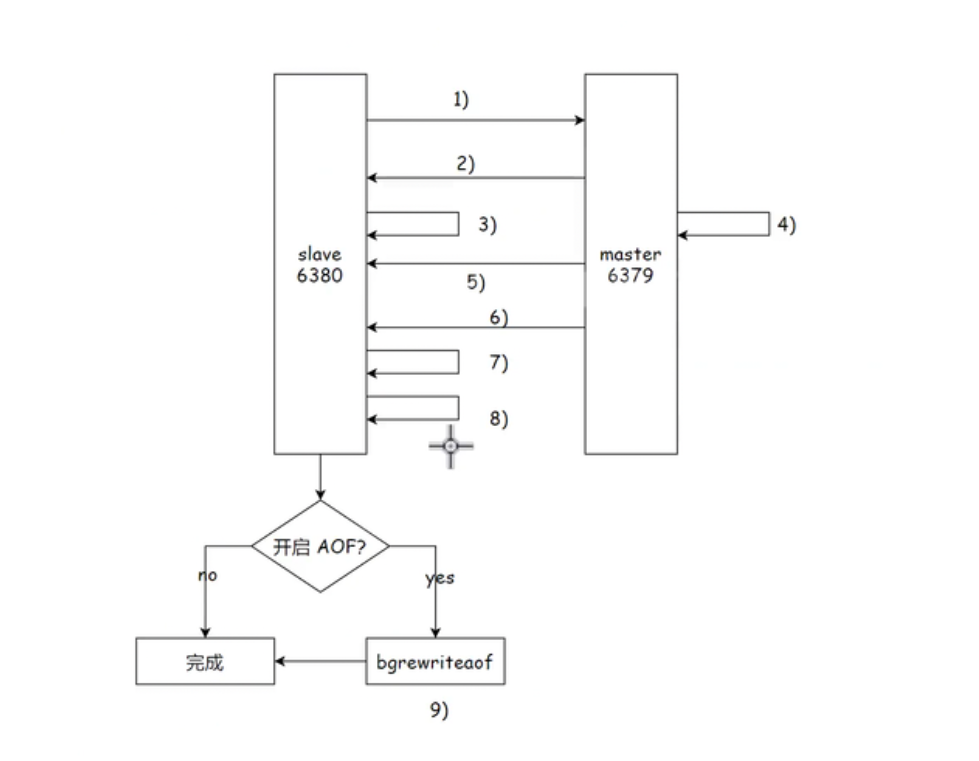
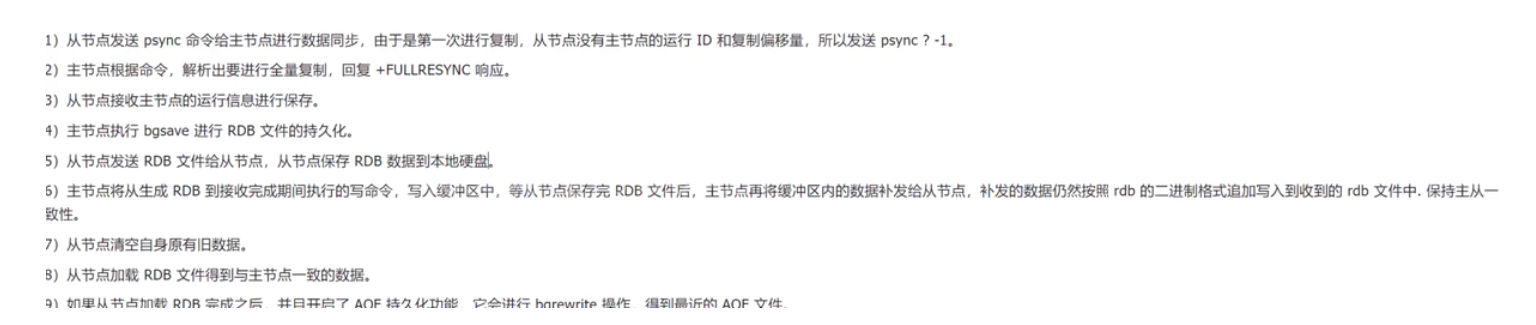
补充一下上图

offset (偏移量 )
主节点和从节点都会维护offset
主节点 会收到数据修改命令 命令转化为 字节数,offset就会累加这些 字节
从节点 offset表示 对主节点数据的同步量
当offset相同时表名 从节点已同步完 主节点数据修改
replication id 和 offset 共同描述了一个"数据集合 "
如果发现两个机器 两者一样,就可以认为两个Redis 机器上存储的数据 是完全一样的
全量复制/增量复制
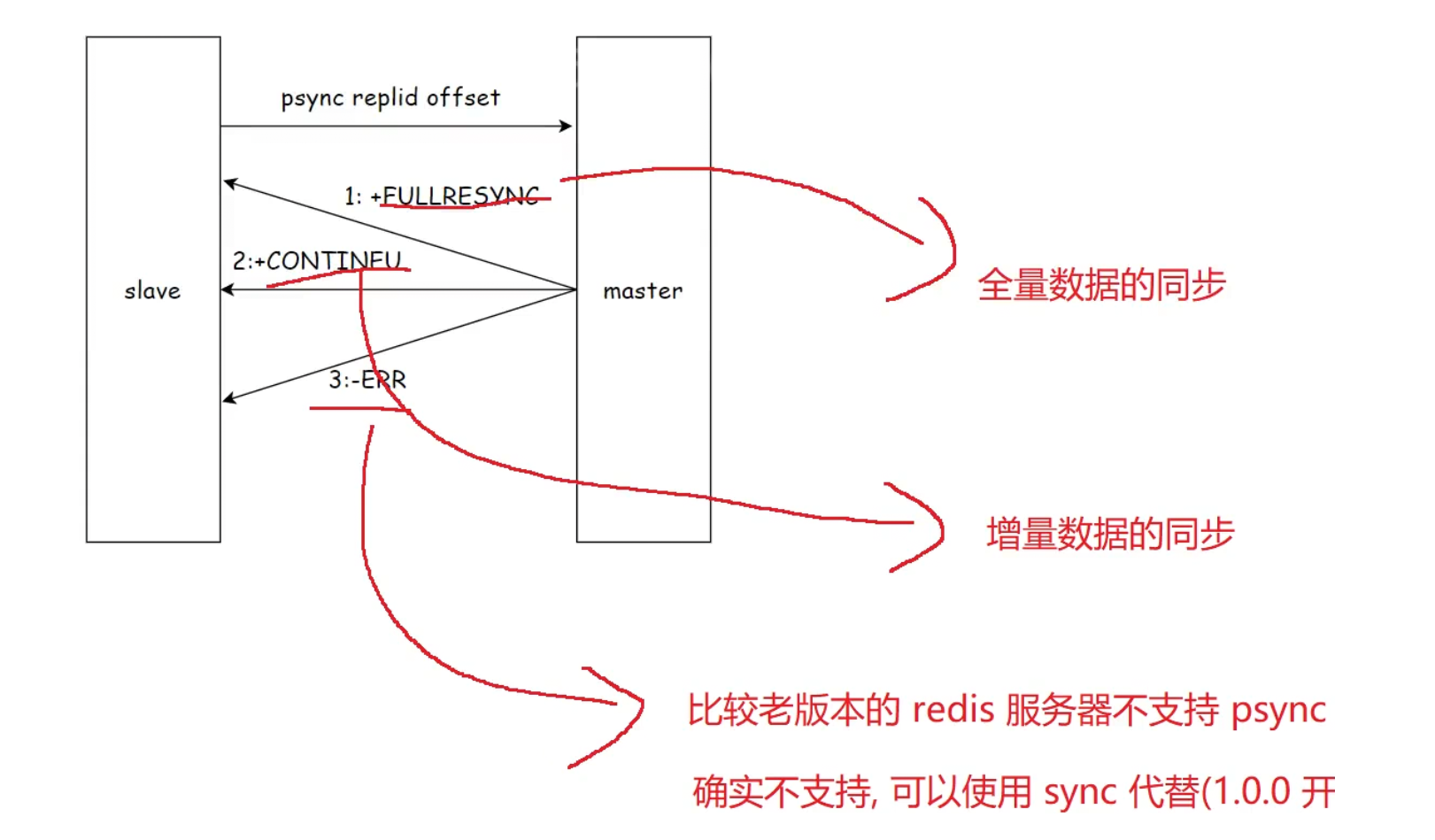

全量复制的流程
全量复制的无硬盘模式
主节点生成的rdb的二进制数据 ,不是直接 保存到文件中,而是直接进行网络传输(省下一系列读硬盘和 写硬盘的操作
从节点 也可以忽略这个过程,直接把收到的数据 进行加载了
即使引入无硬盘模式 仍然整个操作是 比较耗时的 网络传输是 没法省 的相比于网络传输 来说,读写硬盘是小事
所以无硬盘模式能提升效率但效果不大
runid 与replid id
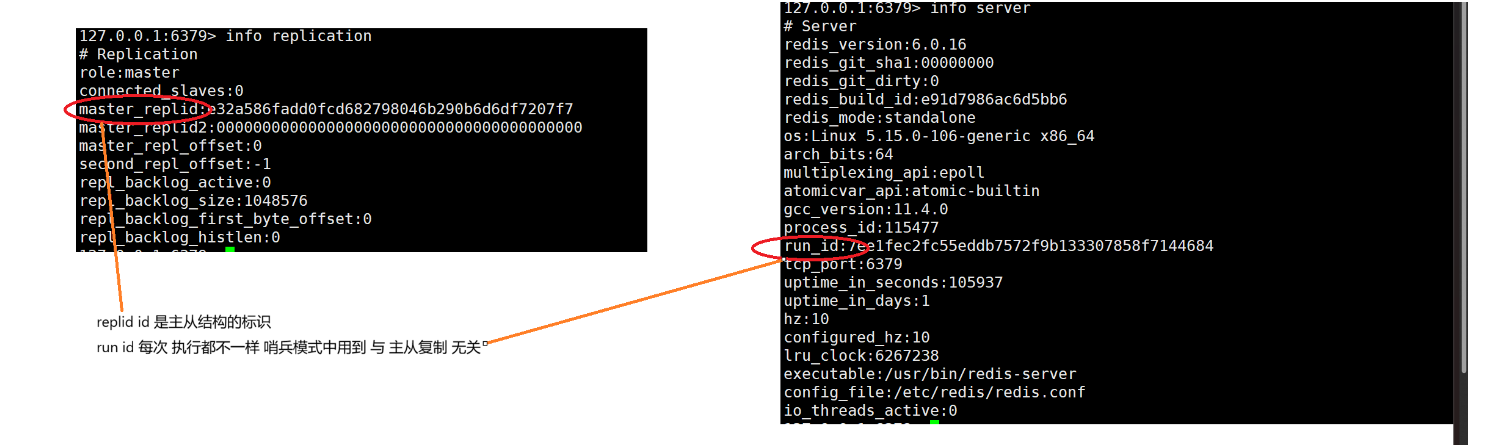
部分复制的流程

replid id 作为"数据来源"依据来看是否从节点是隶属于主节点的 如果 是 那么就可 进行部分复制,否则就进行全量复制
offset 代表数据复制进度
实时复制
当主节点与从节点数据同步好之后,主节点仍会源源不断 收到请求,此时 主节点就会与从节点建立长长的TCP连接
主节点将收到的 请求 同步给从节点 从而进行实时数据的修改
在保持主次 节点的连接中引入了一个机制 心跳包 机制
主节点 每隔一段时间(10s)就会向从节点发送一段ping命令,从节点接受到就会回复一个pong
从节点 每时每刻(1s)向主节点发送一个请求,汇报offset进度
主从复制总结

