本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。
在当今的人工智能领域,大模型无疑是最耀眼的明星。而在大模型的众多关键技术中,Embedding(嵌入)技术犹如基石一般,支撑着模型对各种数据的理解与处理。今天,我们就来深入探讨大模型中的 Embedding 技术,以及它的维度等相关知识。
一、Embedding 究竟是什么?
在深入探讨技术细节之前,我们先打个比方来理解 Embedding 的概念。想象一下,人类语言是一座巨大的图书馆,里面的每一本书(每一个文本)都蕴含着丰富的知识。但计算机就像一个不懂人类语言的外星人,它无法直接读懂这些书的内容。这时,Embedding 就像是一本神奇的翻译手册,它能将图书馆里的每一本书(文本)转化为计算机能理解的数字语言 ------ 向量。这样,计算机就能通过处理这些向量,来理解文本所表达的含义。
从技术角度来说,Embedding 是一种将高维稀疏的数据(如文本、图像、音频等)映射到低维稠密向量空间的技术。以文本为例,计算机无法直接对文字进行数学运算,而 Embedding 技术可以将文本中的每个词(token)转化为一个固定长度的向量,这些向量包含了词的语义信息。比如 "苹果" 这个词,经过 Embedding 后会得到一个向量,这个向量与 "水果""香蕉" 等相关词的向量在向量空间中距离较近,而与 "汽车""房子" 等不相关词的向量距离较远。通过这种方式,计算机就能根据向量之间的距离来判断词与词之间的语义关系。
二、Embedding 的工作流程详解
(一)数据预处理
在进行 Embedding 之前,首先需要对原始数据进行预处理。以文本数据为例,这一步通常包括去除特殊字符、转换为统一的大小写形式、分词等操作。比如对于句子 "Hello, world! I love programming.",经过分词后可能会得到 "Hello", "world", "I", "love", "programming" 这样的 token 序列。
(二)构建词表
接下来,需要构建一个词表(vocabulary)。词表是所有可能出现的 token 的集合,每个 token 在词表中都有一个唯一的索引。例如,在上述例子中,"Hello" 可能对应索引 0,"world" 对应索引 1,以此类推。这个索引就像是 token 在向量空间中的 "地址"。
(三)生成 Embedding 向量
有了词表和索引后,就可以通过 Embedding 层来生成向量了。Embedding 层本质上是一个查找表(lookup table),它的行数等于词表的大小,列数就是我们所说的 Embedding 维度。当一个 token 的索引输入到 Embedding 层时,它会从查找表中找到对应的行,从而输出一个固定维度的向量。比如,当索引 0(即 "Hello")输入时,Embedding 层会输出一个如 0.1, 0.2, -0.3, 0.4 这样的向量(这里只是示例,实际的向量值是通过训练学习得到的)。
三、Embedding 维度的奥秘
(一)维度的意义
Embedding 维度的大小直接影响着模型对数据语义信息的表达能力。简单来说,维度越高,模型能够捕捉到的语义细节就越多。例如,在一个低维度的向量空间中,可能只能区分出 "水果" 和 "交通工具" 这样较为宽泛的语义类别;而在高维度的向量空间中,就可以更精细地区分 "苹果""香蕉""橘子" 等不同种类的水果,甚至可以捕捉到它们在口感、颜色等方面的细微差异。
(二)如何选择合适的维度
选择合适的 Embedding 维度是一个复杂的问题,需要综合考虑多个因素。一方面,增加维度可以提高模型的表达能力,但同时也会增加计算成本和训练时间,并且可能导致过拟合。另一方面,维度过低则可能无法充分表达数据的语义信息,影响模型的性能。一般来说,可以通过实验的方法来确定最佳的维度。在实际应用中,常见的 Embedding 维度有 128、256、512、768 等。例如,在一些简单的文本分类任务中,128 或 256 维的 Embedding 可能就足够了;而对于复杂的语言生成任务,如 GPT 系列模型,通常会使用 768 维甚至更高维度的 Embedding。
(三)维度与模型规模的关系
Embedding 维度还与模型的规模密切相关。通常情况下,模型规模越大,需要的 Embedding 维度也越高。这是因为大规模模型能够学习到更复杂的语义关系,需要更高维度的向量来表达这些关系。例如,GPT-3 的小型模型可能使用 768 维的 Embedding,而大型模型则可能使用 12288 维的 Embedding。
四、Embedding 的丰富应用场景
(一)自然语言处理领域
- 语义搜索:传统搜索引擎大多基于关键词匹配,而引入 Embedding 技术后,能将用户查询与文档都转化为向量,通过计算向量之间的相似度来匹配结果。比如在学术文献检索场景中,用户输入一个复杂的研究问题,语义搜索借助 Embedding 可以快速找到内容相关、但关键词可能并不完全一致的文献 ,大大提升检索的精准度和召回率,像谷歌、必应等搜索引擎就在不断探索这方面的应用 。
- 机器翻译:将不同语言的文本映射到同一个向量空间,使得翻译模型能够更好地理解源语言句子的结构和语义含义,从而生成更自然准确的目标语言翻译。例如,在中英互译中,Embedding 帮助模型把握词汇在不同语境下的细微差别,提升翻译质量。
- 情感分析:通过将文本转化为向量,模型可以分析向量特征来判断文本情感是正面、负面还是中性。以电商产品评论分析为例,商家能通过情感分析了解消费者对产品的态度,进而改进产品和服务。
(二)计算机视觉领域
- 图像识别与检索:利用 Embedding 将图像转化为向量,基于向量相似度实现相似图像搜索。在电商商品图库中,用户上传一张图片,就能搜索到相似款式的商品,极大提升购物体验。
- 视频内容理解:对视频中的每一帧提取 Embedding 向量,分析其语义,从而实现视频内容分类、关键事件检测以及视频推荐等功能。比如视频平台根据用户观看历史的视频 Embedding 向量,为用户推荐感兴趣的新视频。
(三)推荐系统
- 商品推荐:在电商平台,将用户的行为数据(浏览、购买记录等)和商品信息分别转化为 Embedding 向量,通过计算两者的匹配度,为用户精准推荐商品。例如,用户经常购买运动装备,系统根据其行为向量匹配到相似的运动新品进行推荐。
- 内容推荐:以新闻、视频、音乐等内容平台为例,根据用户对过往内容的偏好 Embedding 向量,结合新内容的 Embedding 向量,为用户推送符合其兴趣的内容,提高用户留存率和活跃度。
(四)知识图谱与智能问答
- 知识图谱构建:将知识图谱中的实体和关系转化为 Embedding 向量,不仅能更高效地存储和查询知识,还能利用向量运算进行知识推理。比如在 "人物 - 职业 - 成就" 这样的知识图谱关系中,通过 Embedding 可以挖掘出更多潜在联系。
- 智能问答系统:当用户提问时,将问题转化为 Embedding 向量,在已有的知识库向量中进行匹配和检索,从而快速准确地找到答案。例如智能客服,快速响应用户问题,提升服务效率 。
五、结合实例解析 Embedding 的实际应用
我们可以通过一张典型的 Embedding 在大模型中的应用流程图(如图所示)来更直观地理解其实际应用。
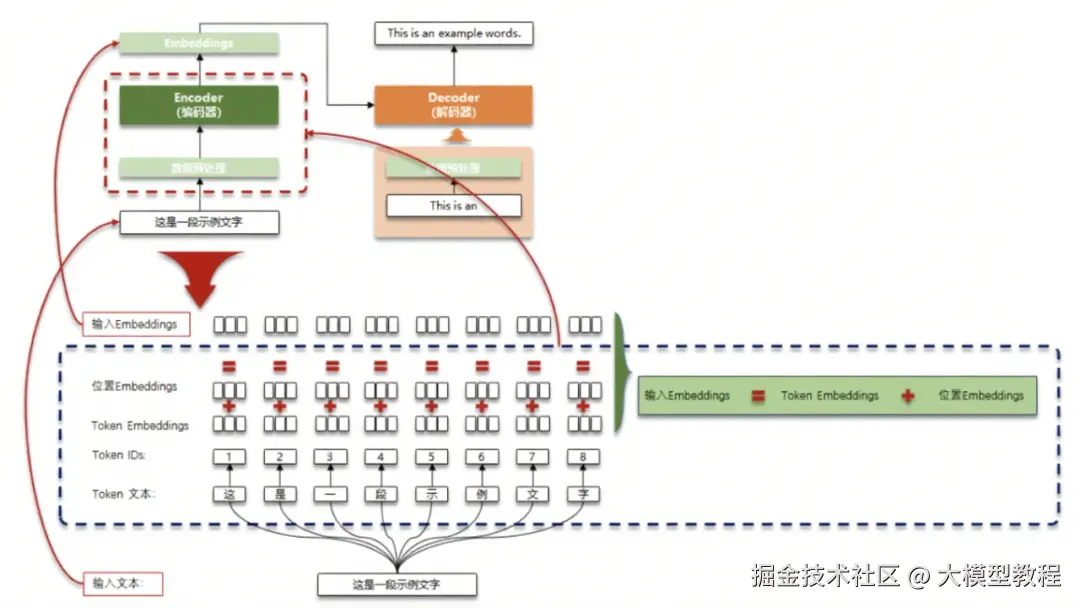
以图中 "这是一段示例文字" 的处理为例,首先进行数据预处理,将文本分词得到 "这""是""一""段""示""例""文""字" 这些 token。接着构建词表,为每个 token 分配唯一的 Token IDs,如 "这" 对应 1,"是" 对应 2 等。然后生成 Token Embeddings,也就是每个 token 对应的语义向量。同时,为了让模型理解文本的顺序信息,还会生成位置 Embeddings,用于表示每个 token 在文本中的位置。最后,将 Token Embeddings 和位置 Embeddings 相加,得到输入 Embeddings,输入到后续的模型中进行处理。
在机器翻译场景中,假设要将 "这是一段示例文字" 翻译成英文 "This is an example words.",编码器(Encoder)会先对中文文本进行上述 Embedding 处理,提取语义和位置信息。解码器(Decoder)则会基于编码器的输出,逐步生成对应的英文翻译。在这个过程中,Embedding 技术使得模型能够精准把握源语言和目标语言之间的语义对应关系,从而生成准确流畅的翻译结果。
在语义搜索场景中,用户输入一个查询词,系统会先将该查询词进行 Embedding 处理,得到对应的向量。然后在已有的文档库中,将每个文档也进行 Embedding 处理,得到文档向量。通过计算查询词向量与文档向量之间的相似度,系统就能快速找到与用户查询最相关的文档,实现高效精准的语义搜索。
六、总结
大模型中的 Embedding 技术是连接人类语言与计算机理解的桥梁,它通过将数据转化为向量,使得计算机能够对各种数据进行有效的处理和分析。Embedding 的工作流程包括数据预处理、构建词表和生成向量等步骤,而 Embedding 维度的选择则直接影响着模型的性能和表达能力。同时,Embedding 在自然语言处理、计算机视觉、推荐系统、知识图谱等众多领域都有着广泛且深入的应用,极大地推动了人工智能技术在实际场景中的落地。
在实际应用中,我们需要根据具体的任务需求和数据特点,合理地选择 Embedding 技术和维度。同时,随着技术的不断发展,Embedding 技术也在不断演进,未来我们有望看到更加高效、强大的 Embedding 方法出现。
对于想要深入研究大模型的技术人员来说,掌握 Embedding 技术的原理和实践是至关重要的。希望通过本文的介绍,能够帮助大家对大模型 Embedding 有更深入的理解,为在人工智能领域的探索提供一些帮助。
这部分先到这~大模型还有不少基础知识点,后续会接着更。觉得有用,欢迎点赞、收藏、转发,也点个「关注」蹲更新~
有不懂的,评论区问我就好,看到会回~😄
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。