本文将简单介绍如何把文本生成 知识图谱 (Knowledge Graph)。具体来说,是使用开源项目 AutoSchemaKG 生成 GraphML 。
GraphML 是 XML(Extensible Markup Language) 格式的文件,可以使用 NetworkX 等框架轻松处理这种格式的文件。下图是一个典型的 GraphML :
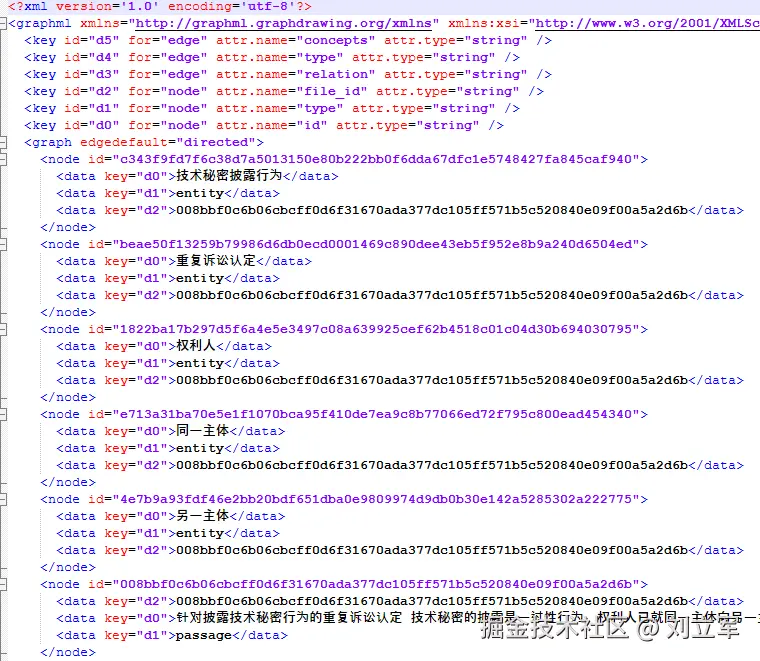
AutoSchemaKG 简介
AutoSchemaKG 用来从大规模的非结构化文本(比如网页、文章)中自动构建知识图谱(KG),而且它有两个关键特点:
-
无需预先定义的 schema(模式)
通常构建知识图谱时,需要先有人设计 ontology/schema:哪些实体、哪些关系、哪些属性、类别等。AutoSchemaKG 的创新是通过自动的 schema induction(模式生发/抽象化),让系统自己从文本中学习这些结构,并组织成概念/类别。
-
同时处理实体、事件与抽象概念
不只是提取"实体-实体关系"(person-born-in-place,company-located_in-city等),还处理事件(events),即文本中不仅有静态事实,还有行为、动词、事件之间的关系;再对这些实体/事件做概念化(conceptualization),把具体实例归类为抽象类别,从而使知识图谱的结构更通用、更能支持跨领域或者零样本推理。
生成知识图谱
下面的代码使用 AutoSchemaKG 生成知识图谱。
python
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '1'
from atlas_rag.kg_construction.triple_extraction import KnowledgeGraphExtractor
from atlas_rag.kg_construction.triple_config import ProcessingConfig
from atlas_rag.llm_generator import LLMGenerator
from openai import OpenAI
from transformers import pipeline
from configparser import ConfigParser
# Load OpenRouter API key from config file
config = ConfigParser()
config.read('config.ini')
'''
client = OpenAI(
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key='xxxxxx',
)
model_name = "qwen-plus"
'''
client = OpenAI(
base_url="http://localhost:11434/v1",
api_key='ollama',
)
model_name = "qwen3"
def generate(filename_pattern,data_directory,output_directory):
"""生成知识图谱"""
output_directory = f'{output_directory}/{filename_pattern}'
triple_generator = LLMGenerator(client, model_name=model_name)
kg_extraction_config = ProcessingConfig(
model_path=model_name,
data_directory=data_directory,
filename_pattern=filename_pattern,
batch_size_triple=3,
batch_size_concept=16,
output_directory=f"{output_directory}",
max_new_tokens=2048,
max_workers=3,
remove_doc_spaces=True, # For removing duplicated spaces in the document text
#debug_mode=True,
)
kg_extractor = KnowledgeGraphExtractor(model=triple_generator, config=kg_extraction_config)
# construct entity&event graph
kg_extractor.run_extraction()
# Convert Triples Json to CSV
kg_extractor.convert_json_to_csv()
# Concept Generation
kwargs = {'language': 'zh-CN'}
kg_extractor.generate_concept_csv_temp(**kwargs)
kg_extractor.create_concept_csv()
# convert csv to graphml for networkx
kg_extractor.convert_to_graphml()
def generate_all():
"""批量生成"""
data_directory = "source"
output_directory = "target"
total = 617
count = 1
for root, dirs, files in os.walk(data_directory):
for file in files:
print(f"===开始处理 {count} of {total} ...\n")
filename_pattern = file[:-5]
dir_target = os.path.join(output_directory,filename_pattern)
if os.path.exists(dir_target):
print(f"{dir_target}已经处理过了.")
else:
generate(filename_pattern=filename_pattern,data_directory=data_directory,output_directory=output_directory)
count += 1
def generate_test():
"""测试生成"""
data_directory = "test_source"
output_directory = "test_target"
filename_pattern = "裁判规则"
generate(filename_pattern=filename_pattern,data_directory=data_directory,output_directory=output_directory) 上述代码既可以生成单个文件的知识图谱,也可以批量生成很多文件的知识图谱;当在 data_directory 中放多个 filename_pattern 的源文件时, AutoSchemaKG 将会把这一批文件生成一个 GraphML 文件。
生成知识图谱的发动机是 大语言模型 ,我是用部署在本地的 ollama 中的 qwen3 8b 生成的,由于 OpanAI 几乎成了所有大模型的规范,所以如果想使用线上的其它大模型,只需要修改一下 base_url 和 api_key 就能直接使用了。
有以下两个问题值得注意:
- 目前 AutoSchemaKG 的提示词以英文为主,改成中文提示词效果可能会更好
- 生成最终的 GraphML 之前,会生成很多中间文件,如果出现错误,大概率是文件格式问题,把代码中关于文件读写的部分指定编码为 utf-8 就可以了
🪐感谢您观看,祝好运🪐