Python函数与数据容器
一、函数
1、语法及定义
函数:是组织好的,可重复使用的,用来实现特定功能的代码段,
##语法
def 函数名(入参):
函数体
return 返回值
调用
函数名(参数)
##如果函数没有使用return语句返回数据,那么函数有返回值吗?
实际上是:有的。Python中有一个特殊的字面量:None,其类型是:<class'NoneType'>无返回值的函数,实际上就是返回了:None这个字面量
## 在if判断中 None等同于False
## None可以用于声明一些无初始值的变量
eg:
def my_str(str):
count = 0;
for i in str:
count = count + 1;
return count;
str_1 = "我是一个字符串";
str_2 = "我是另一个字符串";
print(f"我的长度是{my_str(str_1)}");
print(f"我的长度是{my_str(str_2)}");
##函数说明
"""
函数说明
:param x: 参数x的说明
:param y: 参数y的说明
:return: 返回值的说明
"""
eg:
def my_add(x,y):
"""
计算两个数的和
:param x: 第一个数
:param y: 第二个数
:return: 两个数的和
"""
return x + y;
print(my_add(1,2))
2、函数的多返回值
"""
函数的多返回值
"""
def multReturn():
return 1,"hello";
x,y = multReturn();
print(f"函数的第一个返回值是:{x},第二个返回值是:{y}")
3、函数的多中传参方式
##位置参数
位置参数:调用函数时根据函数定义的参数位置来传递参数
def userInfo1(name,age,email):
print(f"姓名:{name},年龄:{age},邮箱{email}")
userInfo1("张三",18,"张三@126.com")
##关键字参数
关键字参数:函数调用时通过 键=值 形式传递参数.
作用:可以让函数更加清晰、容易使用,同时也清除了参数的顺序需求
def userInfo1(name,age,email):
print(f"姓名:{name},年龄:{age},邮箱{email}")
userInfo1(email="lisi@126.com",name="李四",age=20)
userInfo1("王五",email="wangwu@126.com",age=30)
##缺省参数
缺省参数:缺省参数也叫默认参数,用于定义函数,为参数提供默认值,调用函数时可不传该默认参数的值
(注意:所有位置参数必须出现在默认参数前,包括函数定义和调用)
(带默认值的参数必须定义在所有无默认值参数的后面)
作用:当调用函数时没有传递参数,就会使用默认是用缺省参数对应的值
def userInfo2(name,email,age=20):
print(f"姓名:{name},年龄:{age},邮箱{email}")
userInfo2("刘六","liuliu@126.com")
userInfo2("赵七","zhaoqi@126.com",17)
##不定长参数
不定长参数:不定长参数也叫可变参数,用于不确定调用的时候会传递多少个参数(不传参也可以)的场景
作用:当调用函数时不确定参数个数时,可以使用不定长参数
·位置传递
传进的所有参数都会被args变量收集,它会根据传进参数的位置合并为一元组(tuple)
args是元组类型,这就是位置传递
def userInfo3(*args):
print(f"位置不定长的参数{args}")
userInfo3("张三",99,"male")
·关键字传递
参数是"键=值"形式的形式的情况下,所有的"键=值"都会被kwargs接受,同时会根据"键=值"组成字典
def userInfo4(**args):
print(args)
userInfo4(name="Tom",age="18",id="99")
4、匿名函数
·函数也可以作为另一个函数的参数传递
·将函数传入的作用:传入计算逻辑,而非传入数据
def test_func(calculate):
result = calculate(5,2)
return result;
def add(x,y):
return x+y;
def sub(x,y):
return x-y;
res = test_func(add)
print(f"函数计算结果{res}");
5、lambda匿名函数
##语法
lambda 传入参数:函数体(一行代码)
·lambda是关键字表示匿名函数
def test_func(calculate):
result = calculate(5,2)
return result;
res = test_func(lambda x,y:x*y);
print(f"函数的计算结果{res}");
二、变量的作用域
变量作用域指的是变量的作用范围(变量在哪里可用,在哪里不可用).
主要分为两类:局部变量和全局变量
局部变量的作用:在函数体内部,临时保存数据,即当函数调用完成后,则销毁局部变量
全局变量,指的是在函数体内、外都能生效的变量
eg:
num = 0;
def my_print1():
print(f"我是my_print1,num={num}")
def my_print2():
print(f"我是my_print2,num={num}")
my_print1();
my_print2();
print(num);
##global关键字
设置内部定义的变量为全局变量
"""
全局变量2
"""
num = 0;
def my_add1():
global num;
num = +1;
print(f"我是my_add1,num={num}")
print(num)
def my_add2():
global num;
num=+2;
print(f"我是my_add2,num={num}")
my_add1();
my_add2();
print(num);
"""
全局变量2
"""
num = 0;
def my_add1():
global num;
num += 1;
print(f"我是my_add1,num={num}")
print(num)
def my_add2():
global num;
num+=2;
print(f"我是my_add2,num={num}")
my_add1();
my_add2();
print(num);
##理解上面两个例子 num=+1 和num+=1的区别
num += 1 的意思是:把 num 的值加 1
num = +1 的意思是:把 num 设置为 +1(也就是正数 1)
三、数据容器
一种可以容纳多份数据的数据类型,容纳的每一份数据称之为1个元素每一个元素,可以是任意类型的数据,如字符串、数字、布尔等.
##数据容器包含5类
列表-list 元组-tuple 字符串-str 集合-set 字典-dict
1、list列表
##语法
# 字面量
[元素1,元素2,元素3,元素4,...]
# 定义变量
变量名称 =[元素1,元素2,元素3,元素4,...]
# 定义空列表
变量名称 =[]
变量名称 = 1ist()
##注意:
列表可以一次存储多个数据,且可以为不同的数据类型,支持嵌套
嵌套: [[元素1,元素2],[元素a,元素b]]
正向索引:从0开始数
负向索引:从-1开始数
##属性
·列表容纳上线2**63 - 1
·可以容纳不同类型的元素
·有序存储(有脚标)
·允许重复数据的存在
·可以修改(增加、修改、删除元素等)
eg:
province = ['北京', '上海', '广州', '深圳']
print(province)
print(type(province))
print("=================")
other = [1, "你好", 3.1, True, None]
print(other)
print(type(other))
print("=================")
##常用操作
##1、查询功能
列表.index(元素) 查询指定元素在列表的下标(找不到报错ValueError)
##2、修改功能
列表[下标] = 新值
##3、插入功能
列表.insert(下标、元素) 在指定的下标位置,插入指定的元素
##4、追加功能
列表.append(元素) 将指定的元素,追加到列表的尾部
列表.extend(其他容器) 将指定容器里的内容,批量增加到列表的尾部
##5、删除元素
del 列表[下标] 删除指定下标位置的元素
列表.pop(下标) 删除指定下标位置的元素
##6、删除第一个匹配项
列表.remove(元素) 删除列表中对指定元素的第一个匹配项
##7、清空列表
列表.clear()
##8、统计元素数量
列表.count(元素)
##9、统计列表的元素总数
len(列表)
| 编号 |
使用方式 |
作用 |
| 1 |
列表.append(元素) |
向列表中追加一个元素 |
| 2 |
列表.extend(容器) |
将数据容器的内容依次取出,追加到列表尾部 |
| 3 |
列表.insert(下标, 元素) |
在指定下标处,插入指定的元素 |
| 4 |
del 列表下标 |
删除列表指定下标元素 |
| 5 |
列表.pop(下标) |
删除列表指定下标元素 |
| 6 |
列表.remove(元素) |
从前向后,删除此元素第一个匹配项 |
| 7 |
列表.clear() |
清空列表 |
| 8 |
列表.count(元素) |
统计此元素在列表中出现的次数 |
| 9 |
列表.index(元素) |
查找指定元素在列表的下标 找不到报错ValueError |
| 10 |
len(列表) |
统计容器内有多少元素 |
"""
列表-常用操作
"""
mylist = [1,2,3,4,5,6];
#1、查询
second = mylist[1];
print(f"列表的第二个元素是:{second}")
##2、修改
mylist[1] = 100;
print(f"修改后的列表是:{mylist}")
##3、插入
mylist.insert(1,"t2");
print(f"插入后的列表是:{mylist}")
#4、追加
mylist.append("t7");
print(f"追加后的列表是:{mylist}")
extendList = [7,8,9];
mylist.extend(extendList);
print(f"追加后的列表是:{mylist}")
##5、删除元素
del mylist[1];
print(f"删除后的列表是:{mylist}")
del mylist[1];
print(f"删除后的列表是:{mylist}")
popEle = mylist.pop(1);
print(f"删除后的列表是:{mylist},弹出的元素是:{popEle}")
##6、统计指定元素数量
count = mylist.count("t7");
print(f"列表中100的数量是:{count}")
##7、统计元素总数
length = len(mylist);
##列表的遍历
"""
while循环遍历列表
"""
##定义一个函数
def whilePrintList(tmplist):
##判断是否是列表
if type(tmplist) != list:
print("参数不是列表")
else:
index = 0;
while index < len(tmplist):
print(f"第{index}个元素是:{tmplist[index]}");
index += 1;
myList1 = [1,2,3,4,5,6];
whilePrintList(myList1);
print("=========================================")
"""
for循环遍历列表
"""
def forPrintList(tmplist):
#判断是否是列表
if type(tmplist) != list:
print("参数不是列表")
else:
index =0;
for ele in tmplist:
print(f"第{index}个元素是:{ele}")
index += 1;
myList2 = ["a1","a2","a3","a4","a5","a6"];
forPrintList(myList2);
2、tuple元组
##定义
# 定义元组字面量
(元素,元素,.....元素)
#定义元组变量
变量名称 = (元素,元素,......元素)
#定义空元组
变量名称 = ()
变量名称 = tuple()
# 方式1# 方式2
##属性
·元组同列表一样,都可以封装多个、不同类型的元素
·列表使用[]中括号定义,元组使用()小括号定义
·元组一旦定义完成,就不可以修改(但是可以修改内部list的内部元素)
##注意
如果元组内定义了一个list,那么元组里的list是可以修改的
eg:
##元组的定义
t1 = (1,2,3,4,5,6);
t2 = ();
t3 = tuple();
print(f"t1的类型是:{type(t1)},内容是:{t1}")
print(f"t2的类型是:{type(t2)},内容是:{t2}")
print(f"t4的类型是:{type(t3)},内容是:{t3}")
##定义单个元组
t4 = ("元素1"); #它的类型其实是字符串
print(f"t4的类型是:{type(t4)},内容是:{t4}")
t5 = ("元素2",);#定义单个元组时,必须要在元素后面添加逗号
print(f"t5的类型是:{type(t5)},内容是:{t5}")
##嵌套元组
t6 =((1,2,3),("a","b","c"));
print(f"t6的类型是:{type(t6)},内容是:{t6}")
##从嵌套元组中获取元素
num = t6[1][2]
print(f"t6中嵌套的元组的[1][2]元素是:{num}")
| 编号 |
方法 |
作用 |
| 1 |
index() |
查找某个数据,如果数据存在返回对应的下标,否则报错 |
| 2 |
count() |
统计某个数据在当前元组出现的次数 |
| 3 |
len(元组) |
统计元组内的元素个数 |
##元组的长度
print(f"t6的长度是:{len(t6)}")
##元组的指定元素下标
indexNum = t1.index(3);
print(f"t1中元素3的下标是:{indexNum}")
##元组的数量
countNum = t1.count(2);
print(f"t1中元素3的数量是:{countNum}")
"""
tuple的例外修改
"""
##元组里的list是可以修改的
t7 = (1,2,3,["A","B"]);
print(f"t7的类型是:{type(t7)},内容是:{t7}")
t7[3][0] = "C";
print(f"t7的类型是:{type(t7)},内容是:{t7}")
3、str字符串
字符串是字符的容器,一个字符串可以存放任意数量的字符.
##属性
·字符串是一个不可修改的数据容器 myStr[1]="xx" 这样写会报错
##字符串的下标索引
·从前向后,下标从0开始
·从后向前,下标从-1开始
##元组的定义
t1 = (1,2,3,4,5,6);
t2 = ();
t3 = tuple();
print(f"t1的类型是:{type(t1)},内容是:{t1}")
print(f"t2的类型是:{type(t2)},内容是:{t2}")
print(f"t4的类型是:{type(t3)},内容是:{t3}")
##定义单个元组
t4 = ("元素1"); #它的类型其实是字符串
print(f"t4的类型是:{type(t4)},内容是:{t4}")
t5 = ("元素2",);#定义单个元组时,必须要在元素后面添加逗号
print(f"t5的类型是:{type(t5)},内容是:{t5}")
##嵌套元组
t6 =((1,2,3),("a","b","c"));
print(f"t6的类型是:{type(t6)},内容是:{t6}")
##从嵌套元组中获取元素
num = t6[1][2]
print(f"t6中嵌套的元组的[1][2]元素是:{num}")
"""
tuple常用操作
"""
##元组的长度
print(f"t6的长度是:{len(t6)}")
##元组的指定元素下标
indexNum = t1.index(3);
print(f"t1中元素3的下标是:{indexNum}")
##元组的数量
countNum = t1.count(2);
print(f"t1中元素3的数量是:{countNum}")
"""
tuple的例外修改
"""
##元组里的list是可以修改的
t7 = (1,2,3,["A","B"]);
print(f"t7的类型是:{type(t7)},内容是:{t7}")
t7[3][0] = "C";
print(f"t7的类型是:{type(t7)},内容是:{t7}")
##常用方法
1、查询位置
字符串.index()
2、替换指定字符 (得到的是一个新的字符串而不是在原来的基础上修改)
新的字符串 = 字符串.replace("xxx")
3、字符串分割 (得到的是一个新的字符串而不是在原来的基础上修改)
列表 = 字符串.split("xxx")
4、字符串的规整操作
新字符串 = 字符串.trip() #去除字符串的前后空格
新字符串 = 字符串.trop(字符串2) #按照字符串2中的单个字符一处 字符串中存在的(只针对开始和结束)
5、统计次数
字符串.count(内容)
6、字符串长度
len(字符串)
#1、修改(不可修改)
# str = "hello world";
# str[1] = "a";
# print(f"str的类型是:{type(str)},内容是:{str}")
#2、查找
str = "hello world";
num = str.index("l");
print(f"str中元素l的下标是:{num}")
##替换
newStr = str.replace("lo","a");
print(f"str替换后的内容是:{newStr},替换前的内容是:{str}")
##字符串分割
newStrList = str.split(" ");
print(f"str分割后的内容是:{newStrList},类型是:{type(newStrList)}")
##字符串规整
str = " hello world ";
str = str.strip();
print(f"str规整后的内容是:{str}")
str = "12 hello 12 world 21";
str = str.strip("12");
print(f"str规整后的内容是:{str}")
##统计出现次数
num = str.count("l");
print(f"str中元素l的出现次数是:{num}")
##统计长度
num = len(str);
print(f"str的长度是:{num}")
4、数据容器(序列)切片
序列是指:内容连续、有序,可使用下标索引的一类数据容器
列表、元组、字符串,均可以可以视为序列。
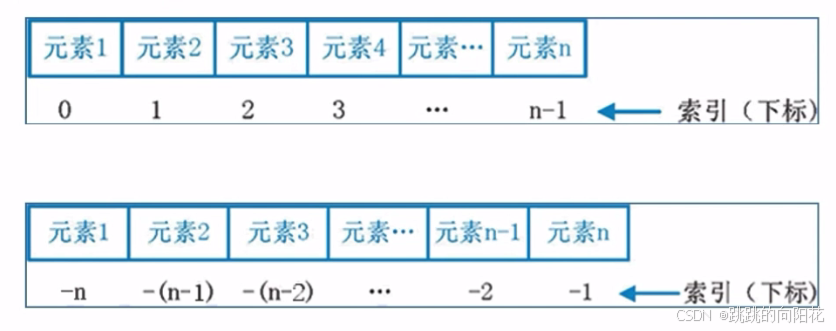
语法:序列[起始下标:结束下标:步长]
表示从序列中,从指定位置开始,依次取出元素,到指定位置结束,得到一个新序列:
·起始下标表示从何处开始,可以留空,留空视作从头开始
·结束下标(不含)表示何处结束,可以留空,留空视作截取到结尾
·步长表示,依次取元素的间隔
··步长1表示,一个个取元素
··步长2表示,每次跳过1个元素取
··步长N表示,每次跳过N-1个元素取
··步长为负数表示,反向取(注意,起始下标和结束下标也要反向标记)
##注意
对序列的切片不会影响到序列本身,而会产生一个新的序列
#1、list切片
my_list = [1,2,3,4,5,6,7,8,9];
result= my_list[1:5];
print(f"my_list[1:5]的结果是:{result}")
#2、元组切片
my_list = (1,2,3,4,5,6,7,8,9);
result= my_list[1:5:2];
print(f"my_list[1:5:2]的结果是:{result}")
#3、字符串切片
str = "hello world";
result = str[0:10:3];
print(f"str[0:10:3]的结果是:{result}")
###结果打印:
my_list[1:5]的结果是:[2, 3, 4, 5]
my_list[1:5:2]的结果是:(2, 4)
str[0:10:3]的结果是:hlwl
5、Set集合
##语法
# 定义集合字面量
{元素,元素,元素}
# 定义集合变量
变量名称 ={元素,元素,......元素}
#定义空集合
变量名称 = set()
##属性
·不支持元素的重复
·内容无序
·不允许下标索引访问
#1、集合的创建
my_set1 = {1,2,3,4,5,6,7,8,9};
print(f"my_set1的类型是:{type(my_set1)},内容是:{my_set1}")
my_set2 = set();
print(f"my_set2的类型是:{type(my_set2)},内容是:{my_set2}")
##常用操作
1、添加元素
集合.add(元素)
2、移除元素
集合.remove(元素)
3、随机移除一个元素
集合.pop()
4、清空集合
集合.clear()
5、取两个集合的差集
(集合1有 而 集合2 没有的,集合1和集合2不变 得到一个新集合)(即去除公共部分的元素)
集合 = 集合1.difference(集合2)
6、消除两个集合的差集
(从集合1中 删除 集合2 中包含的元素)(集合1变化、集合2不变)
集合1.difference_update(集合2)
7、合并集合
(合并两个集合的数据,得到一个新集合,集合1和集合2不变)
集合 = 集合1.union(集合2)
8、两个集合的交集
集合 = 集合1.intersection(集合2)
集合 = 集合1 & 集合2
#1、集合的添加
my_set3 = {"语文","数学","英语"};
my_set3.add("物理");
print(f"my_set3添加物理后的结果是:{my_set3}")
my_set3.add("语文")
print(f"my_set3添加语文后的结果是:{my_set3}")
#2、集合的删除
my_set3.remove("语文")
print(f"my_set2删除语文后的结果是:{my_set3}")
##3、随机删除一个集合
my_set3.pop()
print(f"my_set3随机删除一个元素后的结果是:{my_set3}")
##4、清空集合
my_set3.clear()
print(f"my_set3清空后的结果是:{my_set3}")
##5、集合的长度
print(f"my_set3的长度是:{len(my_set3)}")
##6、取两个集合的差集
my_set5 = {1,2,3}
my_set6 = {2,3,4}
newset = my_set5.difference(my_set6);
print(f"my_set5和my_set6的差集是:{newset},my_set5的内容是:{my_set5},my_set6的内容是:{my_set6}")
##7、消除两个集合的差集
my_set5.difference_update(my_set6);
print(f"my_set5和my_set6的差集消除后的结果是:{my_set5},my_set6的内容是:{my_set6}")
##8、取两个集合的并集
my_set5 = {1,2,3}
my_set6 = {2,3,4}
newset = my_set5.union(my_set6);
print(f"my_set5和my_set6的并集是:{newset},my_set5的内容是:{my_set5},my_set6的内容是:{my_set6}")
##9、取两个集合的交集
newset = my_set5.intersection(my_set6);
print(f"my_set5和my_set6的交集是:{newset},my_set5的内容是:{my_set5},my_set6的内容是:{my_set6}")
newset = my_set5 & my_set6;
print(f"my_set5和my_set6的交集是:{newset},my_set5的内容是:{my_set5},my_set6的内容是:{my_set6}")
##10、集合遍历
my_set3 = {"语文","数学","英语"};
for ele in my_set3:
print(f"集合my_set3的元素是:{ele}")
####结果打印:
my_set3添加物理后的结果是:{'英语', '物理', '语文', '数学'}
my_set3添加语文后的结果是:{'英语', '物理', '语文', '数学'}
my_set2删除语文后的结果是:{'英语', '物理', '数学'}
my_set3随机删除一个元素后的结果是:{'物理', '数学'}
my_set3清空后的结果是:set()
my_set3的长度是:0
my_set5和my_set6的差集是:{1},my_set5的内容是:{1, 2, 3},my_set6的内容是:{2, 3, 4}
my_set5和my_set6的差集消除后的结果是:{1},my_set6的内容是:{2, 3, 4}
my_set5和my_set6的并集是:{1, 2, 3, 4},my_set5的内容是:{1, 2, 3},my_set6的内容是:{2, 3, 4}
my_set5和my_set6的交集是:{2, 3},my_set5的内容是:{1, 2, 3},my_set6的内容是:{2, 3, 4}
my_set5和my_set6的交集是:{2, 3},my_set5的内容是:{1, 2, 3},my_set6的内容是:{2, 3, 4}
集合my_set3的元素是:语文
集合my_set3的元素是:英语
集合my_set3的元素是:数学
6、dict字典
##语法
#定义字典字面量
{key:value, key:value,......,key: value}
# 定义字典变量
my_dict = {key: value, key: value,key: value...}
# 定义空字典
my_dict ={}
my_dict = dict()
##属性
·字典的key不可以重复
·字典的key和value可以是任意数据类型(key不可以是字典)
eg:
##1、字典的定义
my_dict1 = {"name":"张三","age":18,"gender":"男"};
my_dict2 = {};
my_dict3 = dict();
print(f"字典my_dict1的内容是:{my_dict1},类型是{type(my_dict1)}");
print(f"字典my_dict2的内容是:{my_dict2},类型是{type(my_dict2)}");
print(f"字典my_dict3的内容是:{my_dict3},类型是{type(my_dict3)}");
##2、嵌套的字典
my_dict4 = {
"张三":{
"语文":90,
"数学":80,
"英语":70
},
"李四":{
"语文":80,
"数学":90,
"英语":85
}
}
print(f"字典my_dict4的内容是:{my_dict4},类型是{type(my_dict4)}");
##常用的操作
1、字典值的获取
字典[key]
2、新增元素
字典[key] = value
3、修改元素 (key是不可以重复的)
字典[key] = value
4、删除元素
字典.pop(key)
del 字典[key]
5、清空
字典.clear()
6、获取全部key
字典.keys()
7、获取全部value
字典.values()
8、计算字典中元素数量
len(字典)
"""
字典常用操作
"""
##1、获取字典的值
name = my_dict1["name"];
print(f"字典my_dict1的name值是:{name}");
score = my_dict4["张三"]["语文"];
print(f"字典my_dict4的张三的语文成绩是:{score}");
##2、获取字典的所有键
keys = my_dict1.keys();
print(f"字典my_dict1的所有键是:{keys},类型是{type(keys)}");
##3、新增
my_dict1["email"] = "zhangsan@qq.com";
print(f"字典my_dict1的内容是:{my_dict1}");
##4、修改
my_dict1["name"] = "张三三";
print(f"字典my_dict1的内容是:{my_dict1}");
##5、删除
del my_dict1["email"];
print(f"字典my_dict1的内容是:{my_dict1}");
my_dict1.pop("gender");
print(f"字典my_dict1的内容是:{my_dict1}");
##6、清空字典
my_dict1.clear();
print(f"字典my_dict1的内容是:{my_dict1}");
##7、遍历字典
my_dict5 = {"语文":90,"数学":80,"英语":70};
for key in my_dict5.keys():
print(f"字典my_dict5的键是:{key},值是:{my_dict5[key]}");
for key in my_dict5:
print(f"字典my_dict5的键是:{key},值是:{my_dict5[key]}");
##8、获取字典的所有值
values = my_dict5.values();
print(f"字典my_dict5的所有值是:{values},类型是{type(values)}");
##9、获取字典的元素数量
num = len(my_dict5);
print(f"字典my_dict5的元素数量是:{num}");
7、容器对比
| 特性/数据结构 |
列表 |
元组 |
字符串 |
集合 |
字典 |
| 元素数量 |
支持多个 |
支持多个 |
支持多个 |
支持多个 |
支持多个 |
| 元素类型 |
任意 |
任意 |
仅字符 |
任意 |
Key: Value Key:除字典外任意类型 Value:任意类型 |
| 下标索引 |
支持 |
支持 |
支持 |
不支持 |
不支持 |
| 重复元素 |
支持 |
支持 |
支持 |
不支持 |
不支持 |
| 可修改性 |
支持 |
不支持 |
不支持 |
支持 |
支持 |
| 数据有序 |
是 |
是 |
是 |
否 |
否 |
| 使用场景 |
可修改、可重复的一批数据记录场景 |
不可修改、可重复的一批数据记录场景 |
一串字符的记录场景 |
不可重复的数据记录场景 |
以Key检索Value的数据记录场景 |
8、容器的通用操作
1、统计容器的元素个数
len(容器)
2、统计容器的最大元素
max(容器)
3、统计容器的最小元素
min(容器)
4、容器转列表
list(容器)
5、容器转元组
tuple(容器)
6、容器转字符串
str(容器)
7、容器转集合
set(容器)
8、排序功能 (排完序后都是列表)
sorted(容器,[reverse=True]) reverse默认False从小到大,True为从大到小