1前言
Qwen 3‑VL 是阿里巴巴通义实验室在 2025 年云栖大会上发布的下一代视觉‑语言大模型,属于 Qwen 3 系列的多模态分支。它在"看懂世界、理解事件、做出行动"方面实现了显著突破。

那么这模型的能力到底有多强呢? 今天就带大家实际体验感受一下。
2.Qwen 3‑VL模型能力测试
模型的权重目前已经在HuggingFace、ModelScope 上找到。
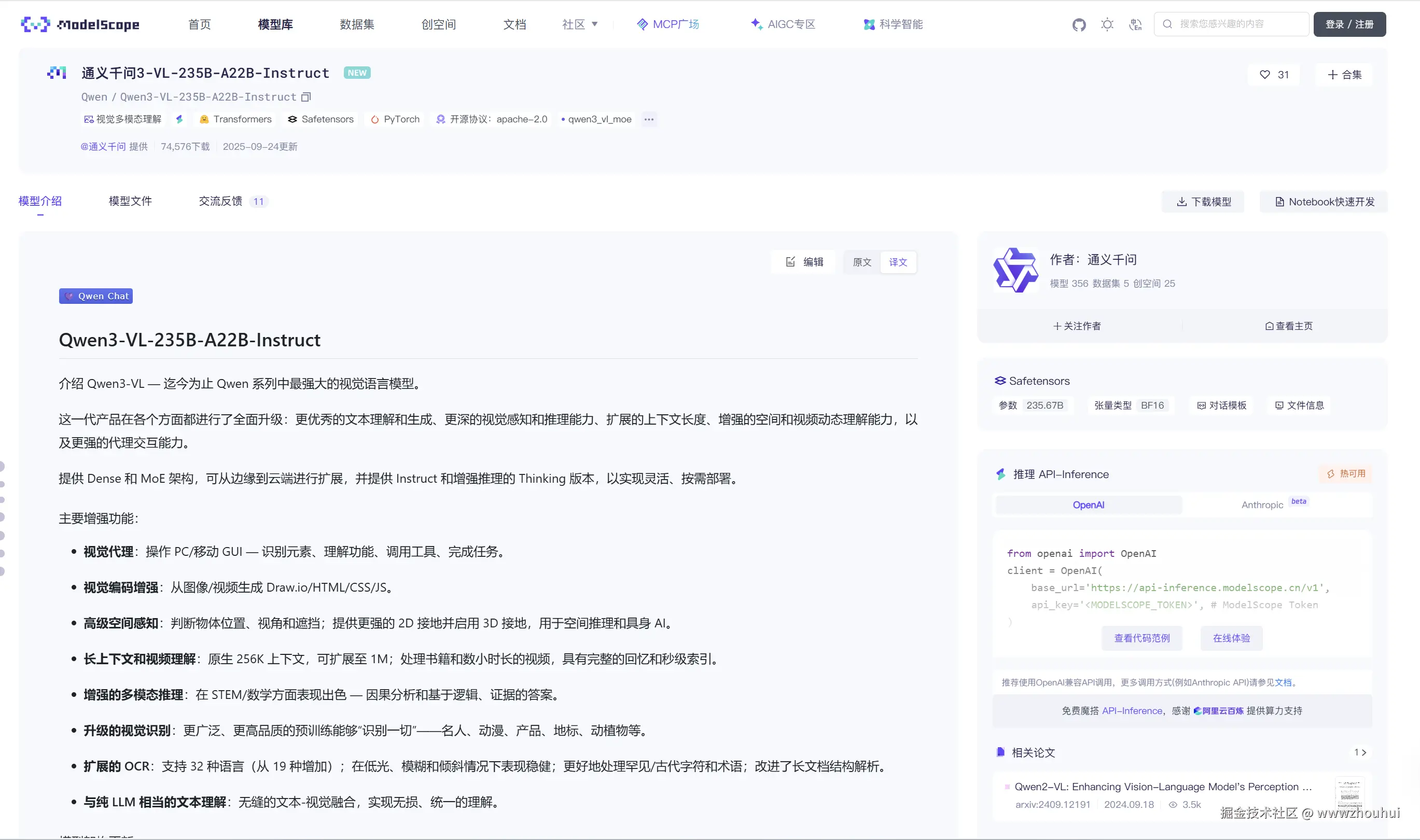
由于模型权重比较大,普通电脑是很难运行这个参数尺寸的模型。所以我们可以使用chat.qwen.ai/ 在线网页版来体验。
登录平台后我们可以在做上角找到这个模型。
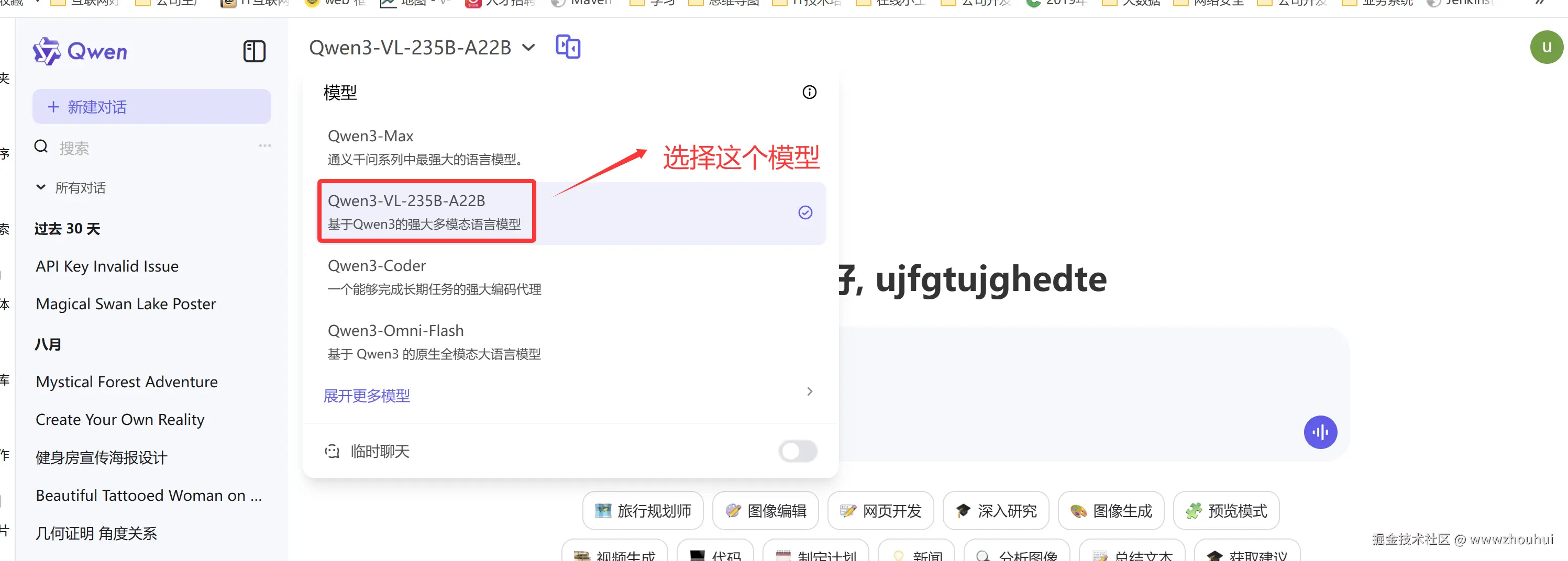
图片生成代码
我们平时经常会遇到这样一个问题。一个网站的截图,然后我们希望通过复刻一个一样的网站。我们今天就带着这问题给它测试一下。
我们把上面的这个系统的截图发给它。
提示词
json
请基于我给你上传的图片,使用HTML+CSS+JS 100% 复刻这个网站页面。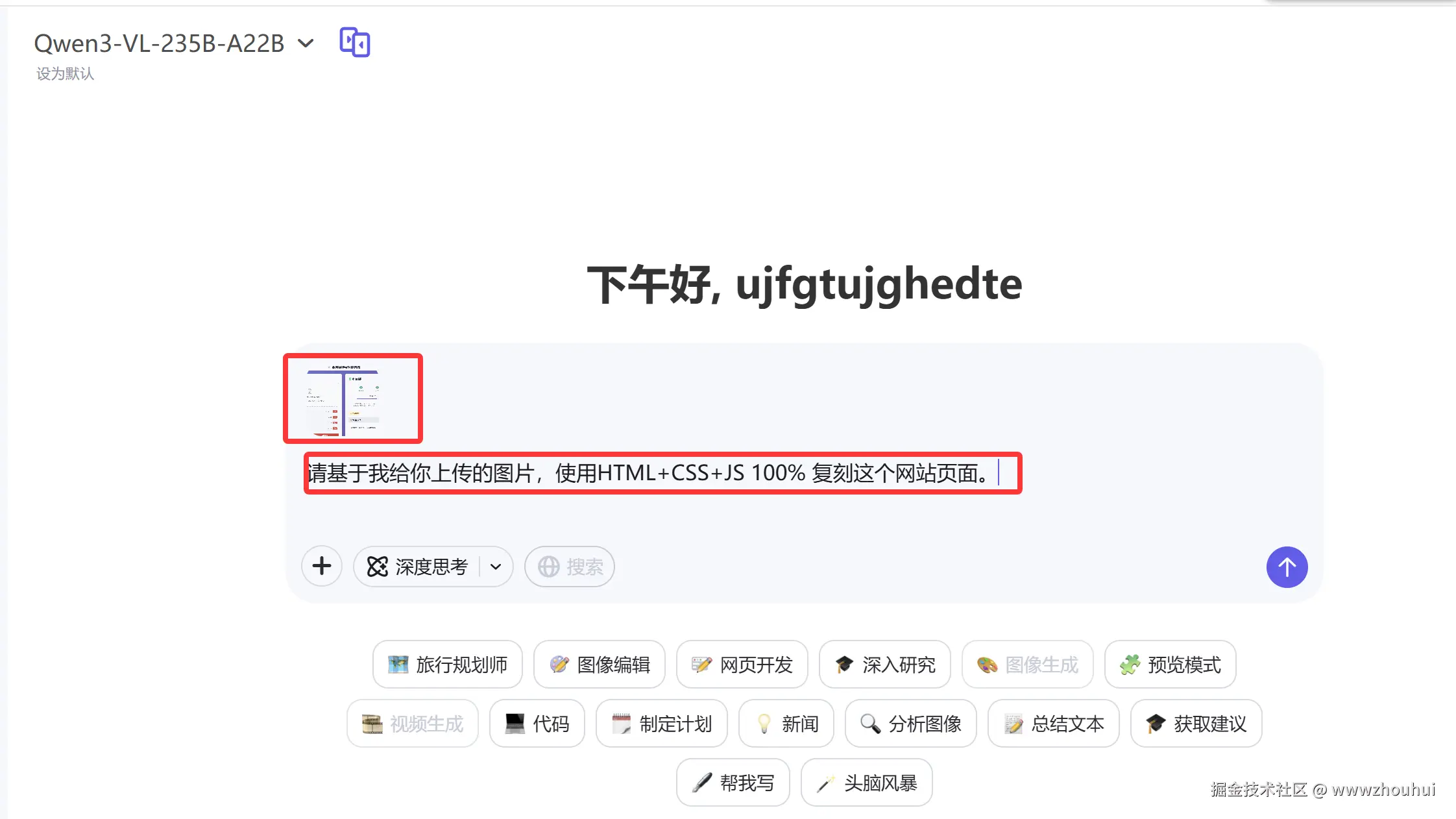
模型经过深度思考后生成下面的代码
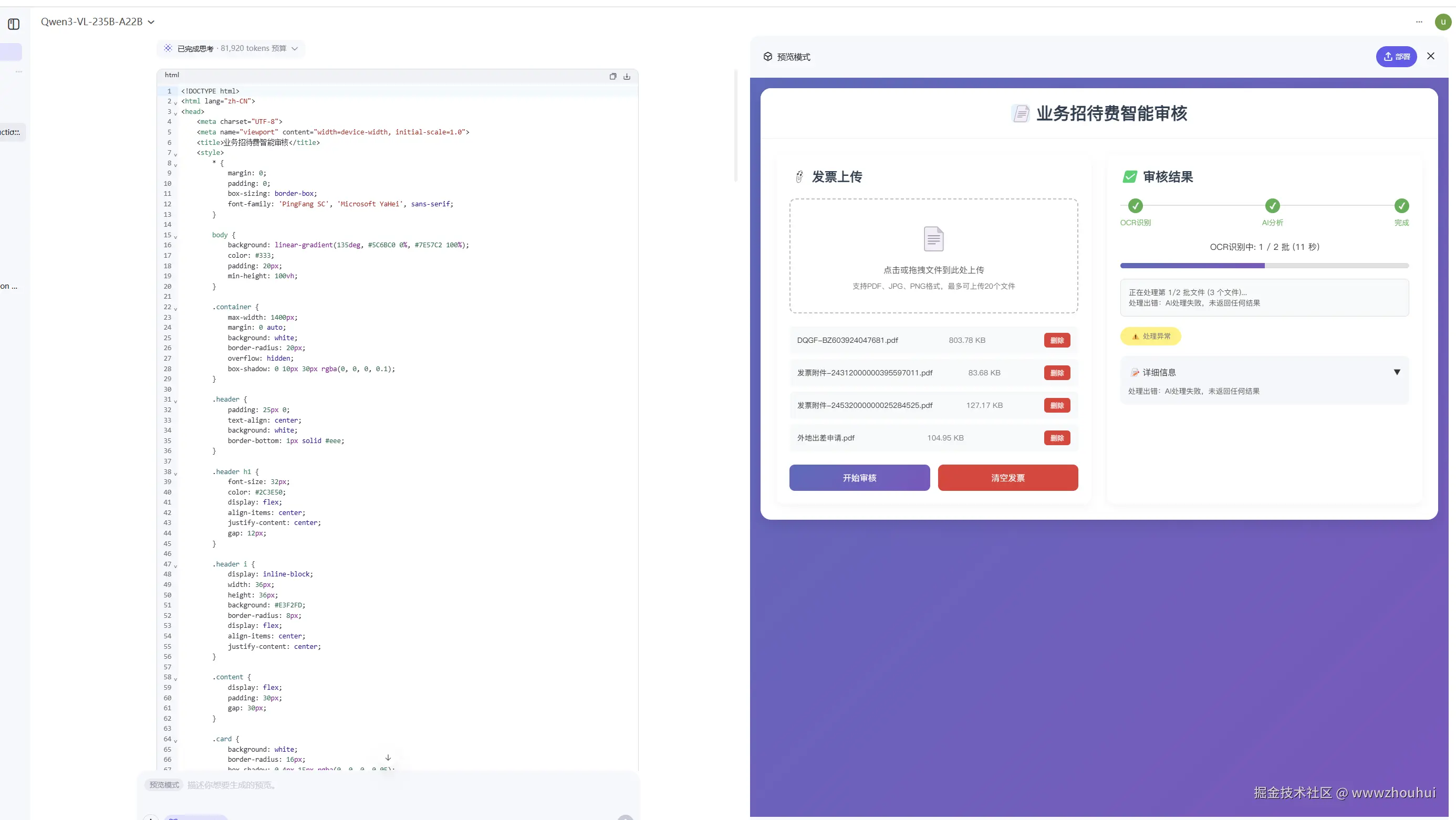
完美复刻我上传的网站照片信息。 这个Qwen 3‑VL模型确实强啊 。
发票识别
我们在给他上传一个5连号的发票,看看这个模型是否可以识别出来。
提示词
json
请帮我把照片上面5张出租车发票的信息全部识别出来
为了数据隐私我们特意把发票号码打上马赛克。
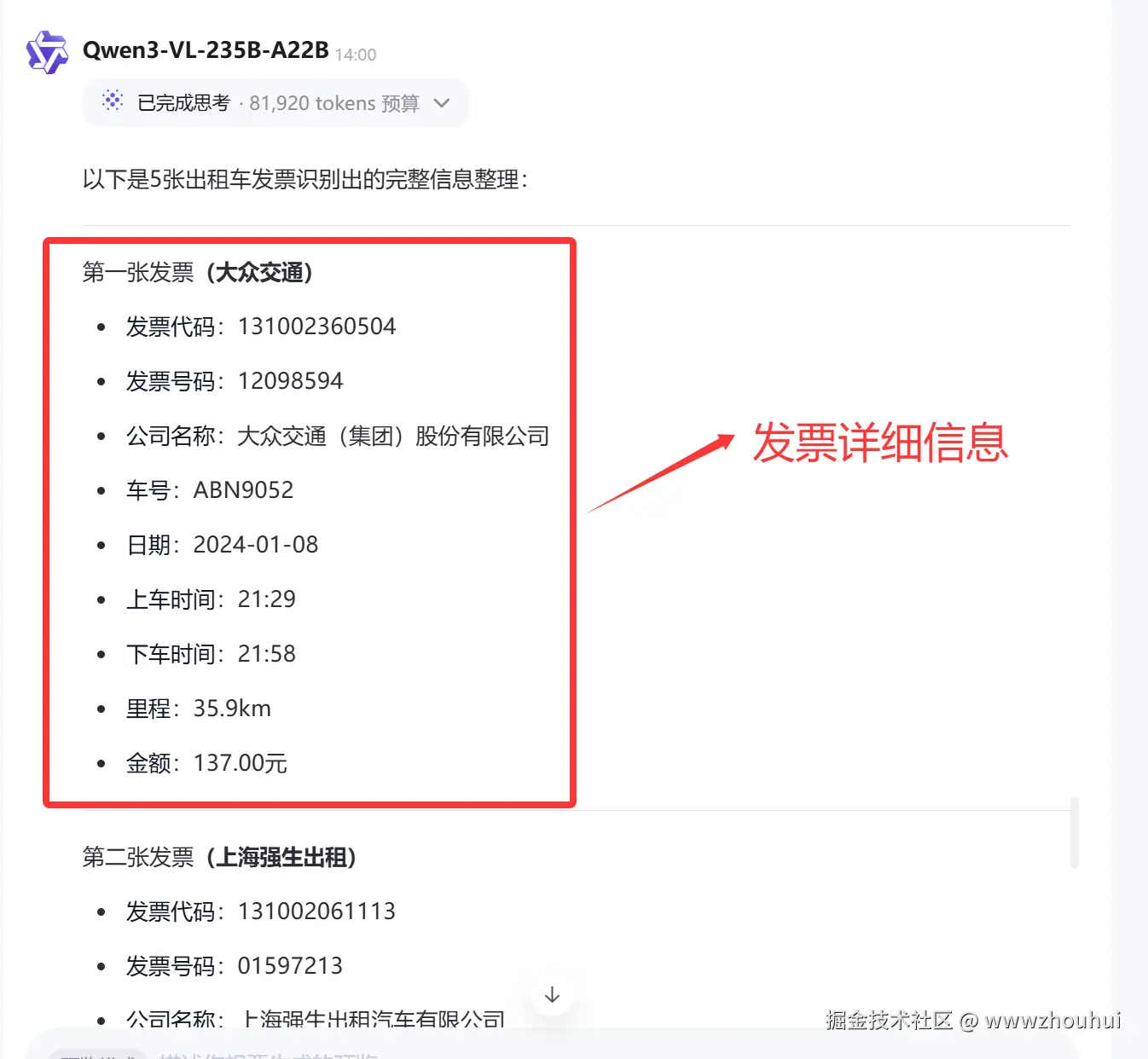
五张合并在一起的发票报销单全部识别出来。
增值税小规模申报表识别
接下来我们给他上传一张电子税务局下载下来的PDF格式的增值税小规模申报表,让他帮我识别出来。
提示词如下
json
请帮我把上面上传的PDF格式的增值税小规模申报表4张表识别出来,并使用HTML+CSS+JS生成静态页面方便展示。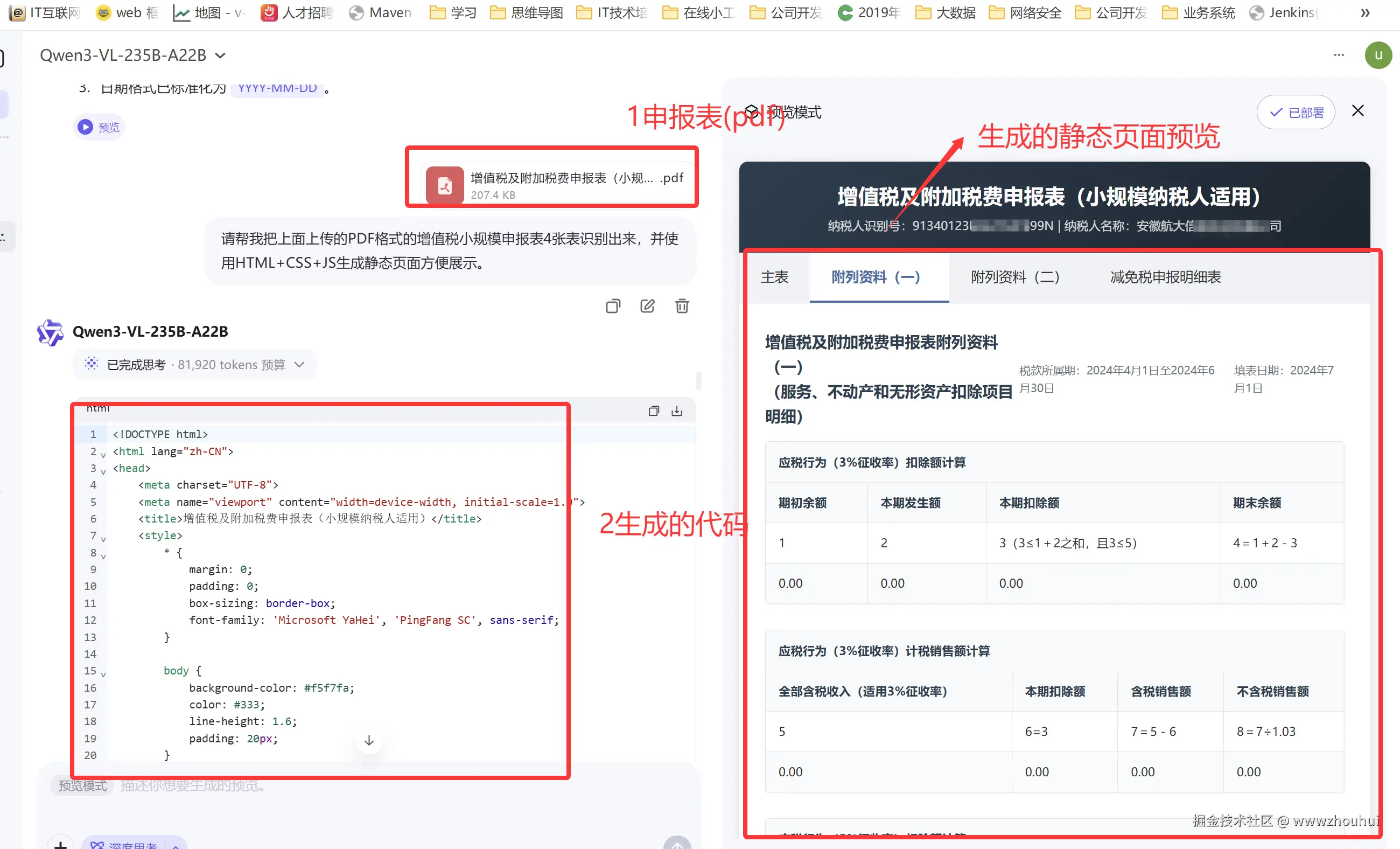
另外生成的html页面它还支持一键部署,我们可以分享链接给小伙伴。
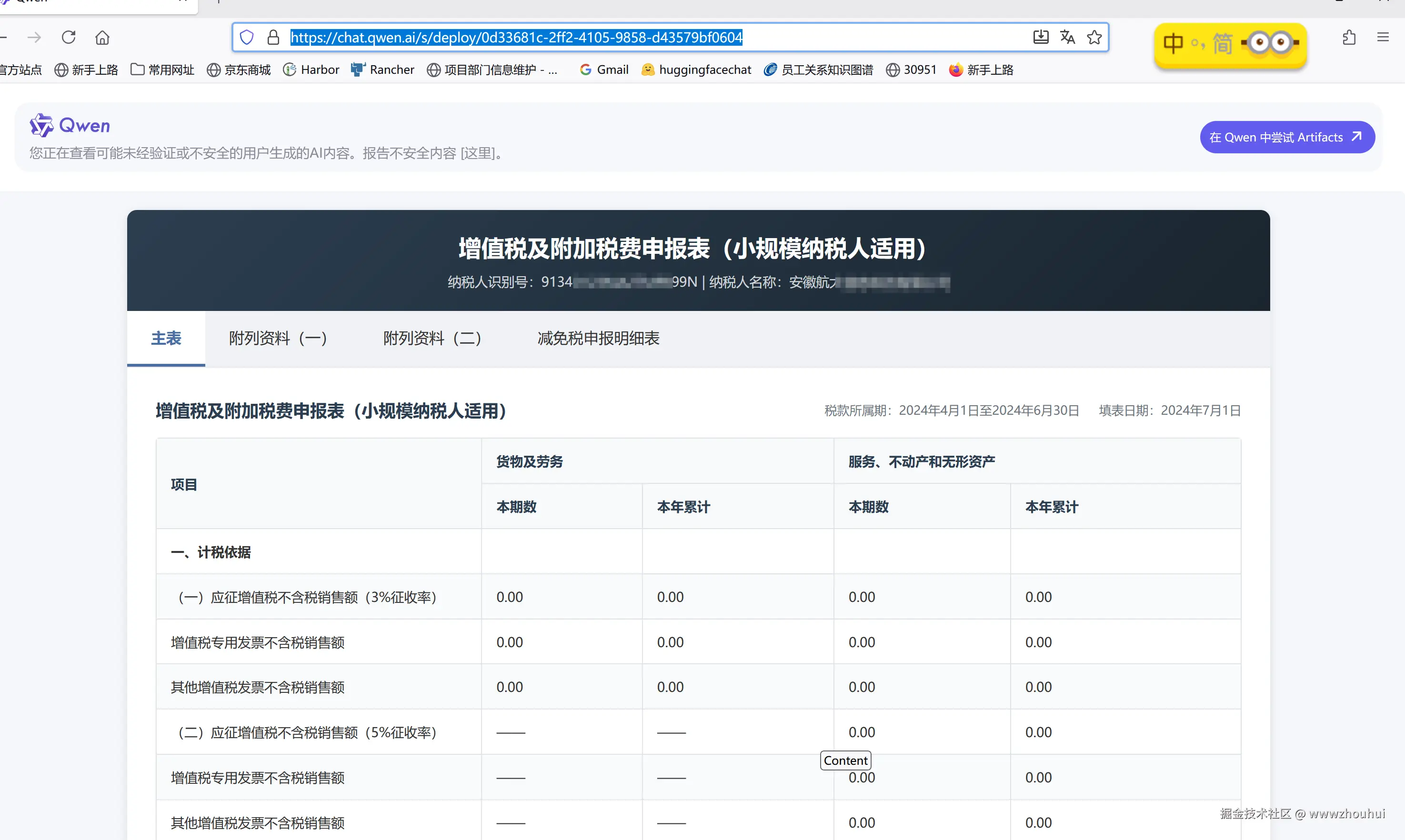
蝌蚪体文字识别
我们在网上找到一个蝌蚪体文字的图片信息

我们把这个比较难认的图片甩给大模型,看看它的识别能力。
提示词
请帮我把这个照片里面的字识别出来。识别的内容是简体中文。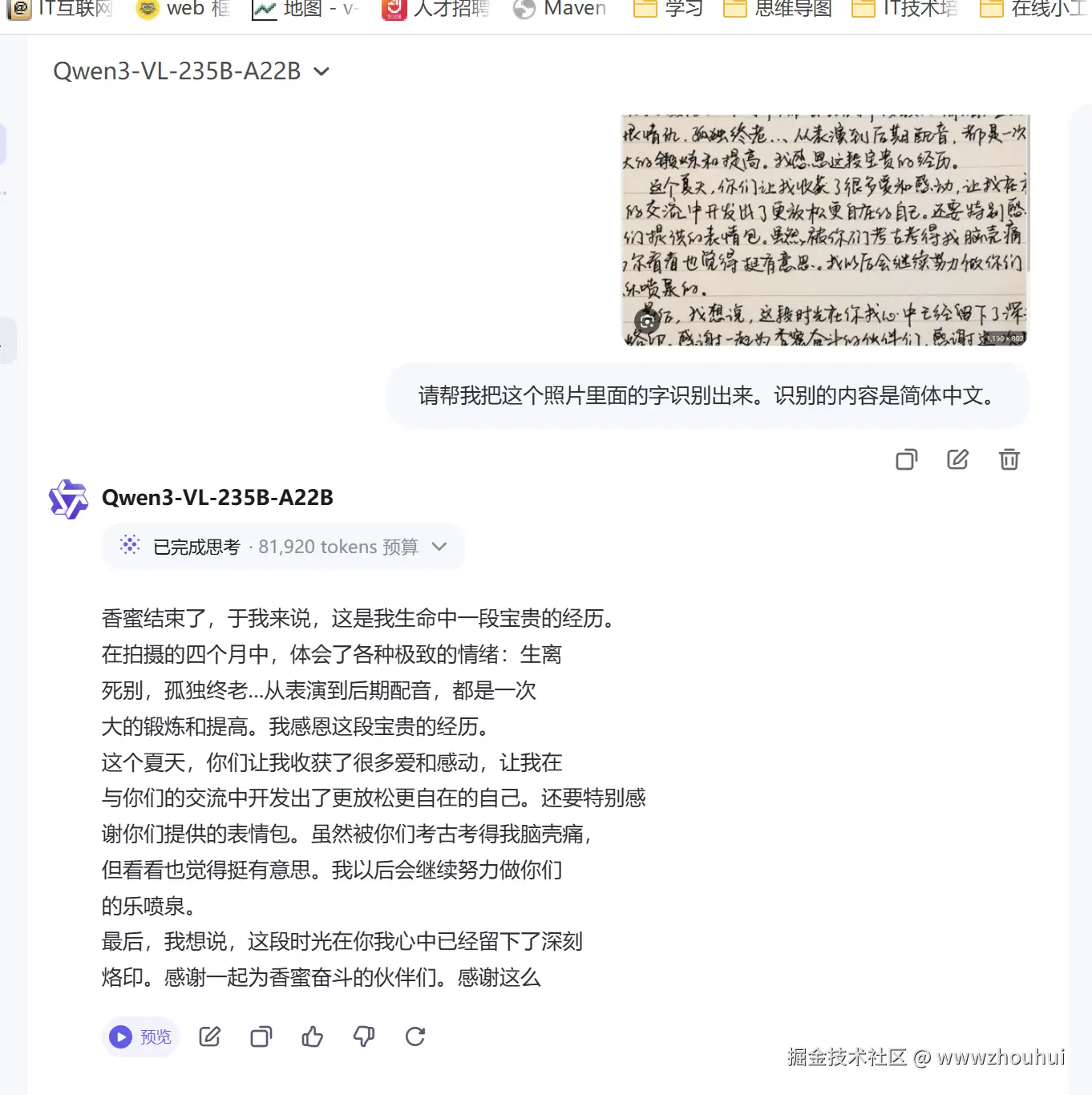
看起来这个识别也是没有问题的。
视频内容识别
接下来我这里有一段视频内容,这个视频主要是基于一份发票前端原型设计,我让AI 帮我识别一下视频里面的内容。
提示词
json
请帮我识别一下这个视频主要讲述的哪些内容,请提取视频主要内容总结归纳一下。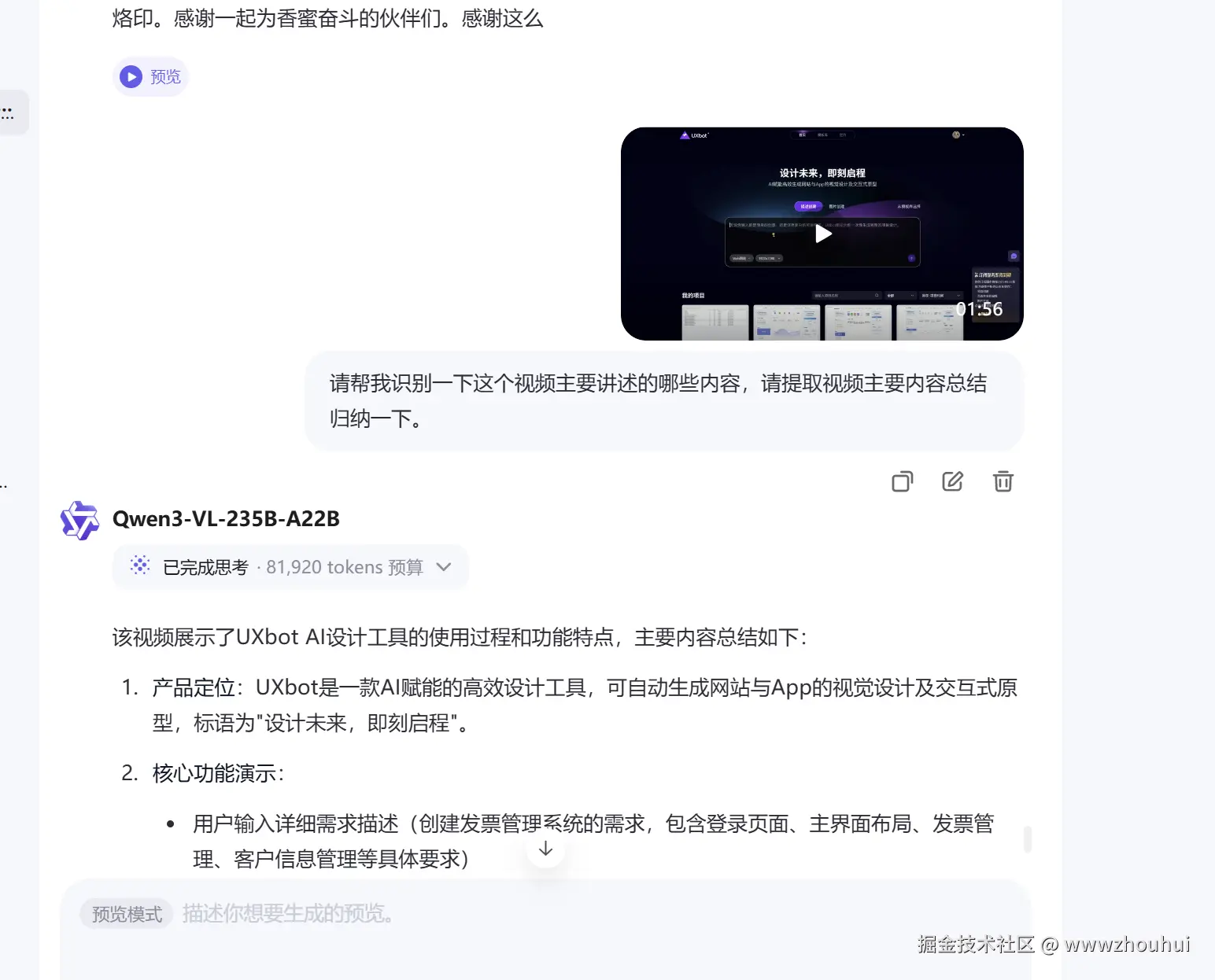
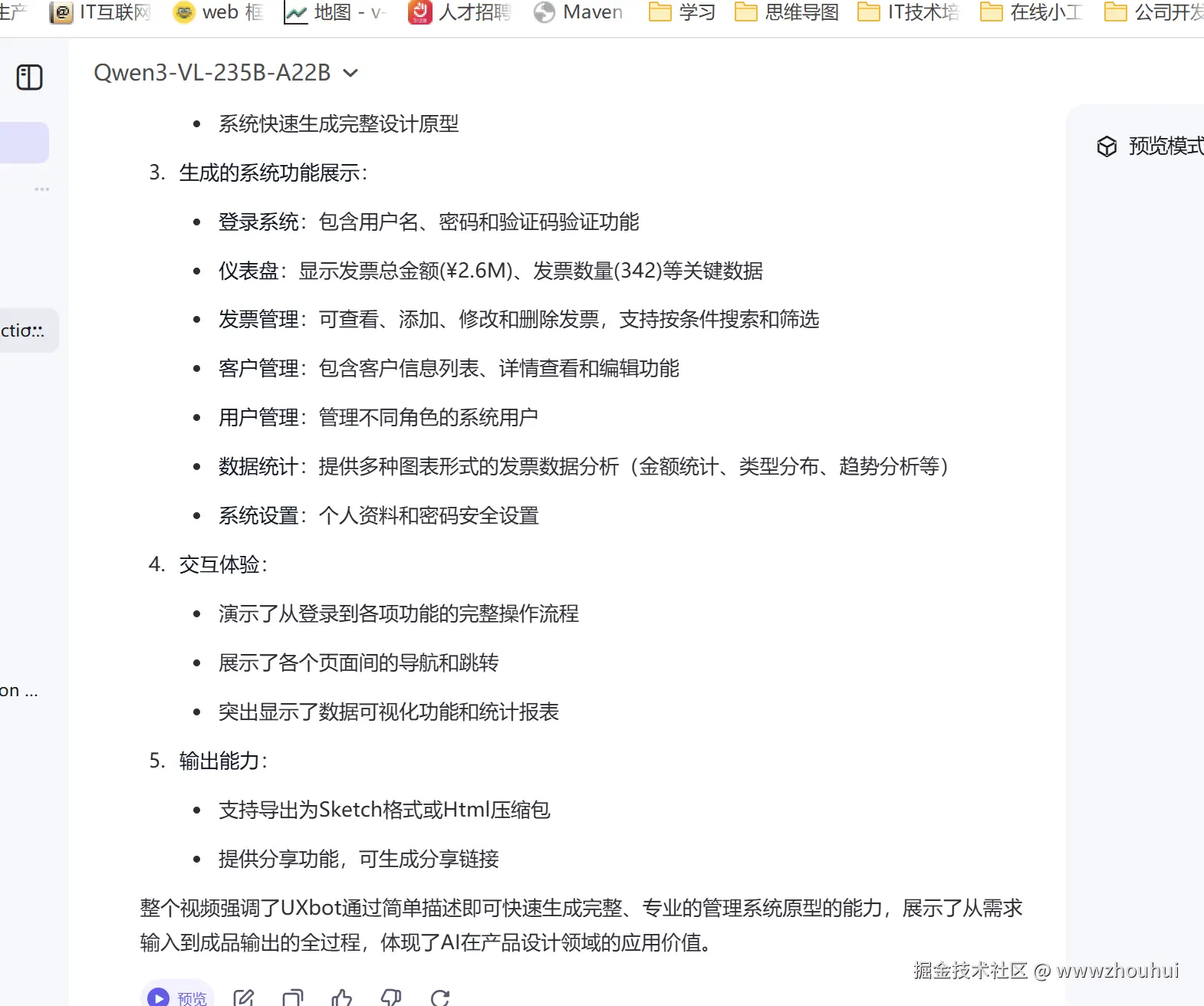
我们通过输出的文字内容判断 这个模型是可以把我视频的内容识别出来的。
视频识别字幕提取
接下来 我在上传一个带有字幕的视频,我希望通过模型帮我提取视频中的字幕srt文件。
提示词如下:
json
请帮我请帮我识别一下这个视频,把视频里面的字幕提取输出,生成带有时间轴的字幕文件srt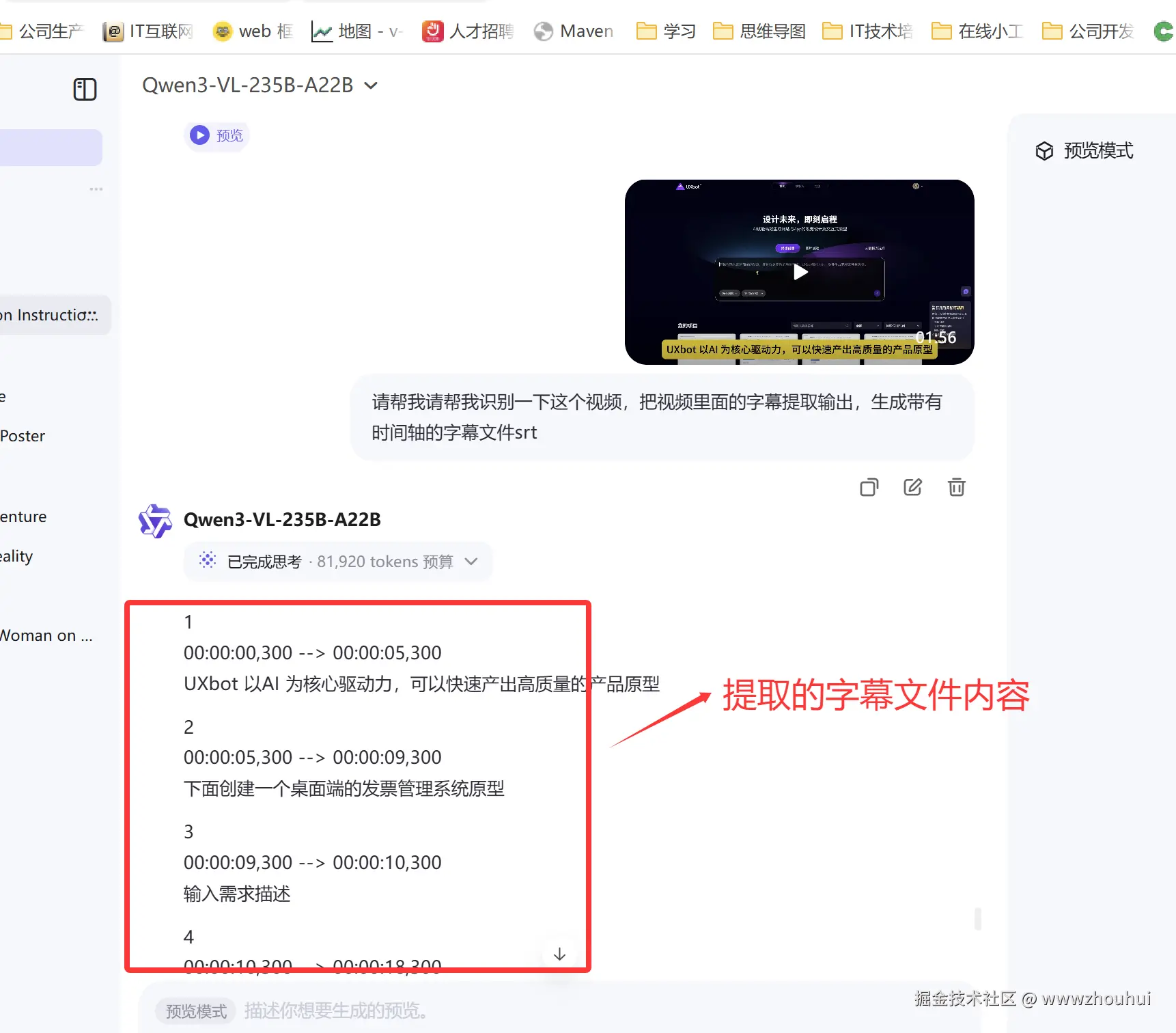
接下来我们把这个2个字幕发给大模型让它帮我判断2个字幕相似度有多高,从而判断出qwen3-vl模型识别字幕的准确性是多少?
提示词
以上2个文件是2个字幕文件,请帮我通过文字的内容对比一下他们两个相似度是多少,有哪些差异性。只比对中文内容部分
AI 模型给我反馈的信息
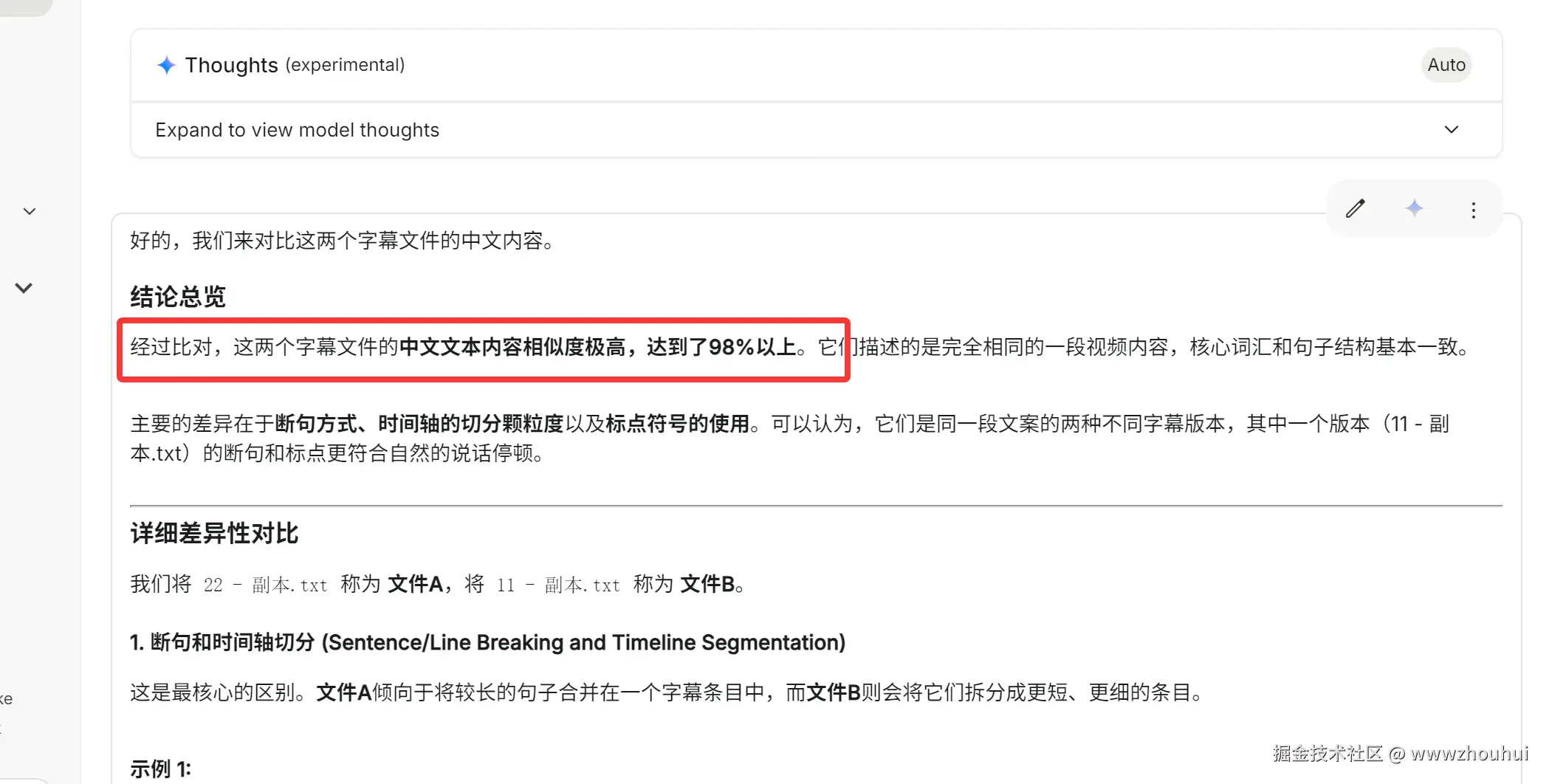
这样我们就非常容易的实行了视频字幕的OCR 识别并提取。
3.总结
今天主要带大家实际体验了 Qwen 3-VL 模型在多模态处理方面的强大能力,重点测试了它在图片生成代码(复刻网站页面)、发票识别、增值税小规模申报表识别与静态页面生成、蝌蚪体文字识别、视频内容理解以及视频字幕提取等场景下的表现。
通过这些测试可以看出,Qwen 3-VL 模型凭借出色的视觉 - 语言理解能力,能够轻松应对从图片到视频、从常规文字到特殊字体、从简单识别到复杂内容生成的多样化需求。对于开发者而言,无需本地部署大模型,通过在线平台即可低成本使用其功能,有效解决了传统多模态处理中工具繁琐、识别精度不足、跨场景适配难等问题,极大降低了视觉信息处理的技术门槛。
感兴趣的小伙伴可以按照文中的指引,前往chat.qwen.ai/ 亲自体验 Qwen 3-VL 的各项功能,根据自身需求探索更多实用场景。今天的分享就到这里结束了,我们下一篇文章见。