本文译自「How to architect Android apps: a deep dive into principles, not rules」,原文链接proandroiddev.com/how-to-arch...,由Tom Colvin发布于2023年5月25日。

大多数 Android 开发者都经历过这样的场景......你被要求为应用添加一个简单的功能,但这样做会迫使你修改其他部分,然后又修改其他部分,直到你的修改变得非常繁琐,无法测试。
你可能也开发过这样的应用,用一些不靠谱的方式进行修改比弄清楚如何正确地做某件事要容易得多。或者,应用某个部分的修改会导致数百个完全不相关的 bug 突然出现。
这些都是糟糕架构的标志。
因此,本文基于我的演讲《别跟架构作对》探讨如何构建优秀的应用架构。
正确的方法
因为当你构建了优秀的应用架构后,你会发现它安全可靠、可测试且易于维护。你将能够推迟诸如使用哪个后端之类的决策,并在之后相对轻松地撤销这些决策。对我们开发者来说,最重要的是,有一个明确的"正确方法",可以正确地隔离需要隔离的部分,这意味着即使是最初级的开发者也能在团队中发挥作用。
关于构建软件架构的"正确"方法有很多建议,其中很多都相互矛盾。因此,在本文中,我将为你提供架构背后的"原则",以便你能够自行决定什么架构适合你自己的应用。所以,本文探讨的是原则,而不是规则。
要成为一名优秀的架构师,学习原则,而不是规则。这样,你就可以根据你的软件和团队定制合适的架构。
SOLID 规则
SOLID 规则是许多架构框架的基础,因此必须完全理解。我不会深入探讨这些规则,因为其他人已经在这方面做得很好。不过,我们先简单回顾一下:
S = 责任分离
该原则规定,一个类或模块_应该只有一个更改理由_。或者说,它应该只对一个_参与者_负责。这本质上意味着:将那些将单独演进的事物隔离开来。
O = 开放-封闭
你的代码应该允许你通过添加代码而不是修改现有代码来添加新功能。
L = 里氏替换
以麻省理工学院计算机科学家 Barbara Liskov 的名字命名。该原则规定,你应该能够使用任何派生类来替换基类。最重要的是,在派生基类时,不应尝试更改其含义。
I = 接口隔离
不应强迫客户端使用不适合他们的接口。拥有多个包含一两个方法的小型接口,而不是一个大型接口,这并没有什么坏处。
D = 依赖倒置
高级类不应依赖于低级类。相反,它们应该都依赖于抽象。
正确应用依赖倒置原则可以正确形成架构边界。让我们更深入地了解其工作原理。
架构边界和依赖倒置
假设我们有一个应用允许用户创建和保存个人资料。我们使用 Firebase 来实现这一点。以下是一个简单的实现:

这里,User 类调用了 FirebaseProfileSaver 类中的方法,该方法使用 Firebase 保存个人资料。User 类被称为_高级_类,因为它包含业务逻辑(即,它是纯逻辑,而不是关于数据如何读写到系统的具体细节)。相比之下,"FirebaseProfileSaver"是一个_低级_类,之所以这样称呼是因为它包含实现细节,即为特定技术编写的代码。
这种布局违反了依赖倒置原则,因为高级的东西依赖于低级的东西。我所说的依赖,是指严格的源代码含义:在"User"类中,有一行代码写着"import x.y.FirebaseProfileSaver"或类似的代码。也许依赖关系被移除了几层------比如"User"导入了"X",而"X"又导入了"Y",而"Y"又导入了"FirebaseProfileSaver"------但关键在于,你可以沿着依赖关系的方向画一组箭头,最终从"User"指向"FirebaseProfileSaver"。
为什么这会是个问题?一个问题是Firebase的变更并不是孤立的。如果Firebase SDK有一天发生了变化,那么显然"FirebaseProfileSaver"也需要随之改变;但没有什么可以阻止这种情况发生,因为它会影响"User"及其依赖的任何内容。测试更改意味着测试所有内容。
而且它也不太灵活。如果我们想从 Firebase 迁移到其他远程存储提供商,我们最终可能不得不重写应用程序的大部分内容。
依赖倒置:"插头插座"解决方案
解决方案是将"FirebaseProfileSaver"设置为一种"插头",将"User"类设置为一种"插座"。"User"类必须对"FirebaseProfileSaver"一无所知;但它可以在抽象中了解保存配置文件的过程。无论我们将什么"插头"插入"User"的"套接字"(可以是"FirebaseProfileSaver"、"RoomDatabaseProfileSaver"或"MyProprietaryAPIProfileSaver"),"套接字"都知道如何与之通信,因为从"套接字"的角度来看,它们的操作方式都相同。
因此,"FirebaseProfileSaver"被重构为适合该套接字的插头。
它看起来像这样:
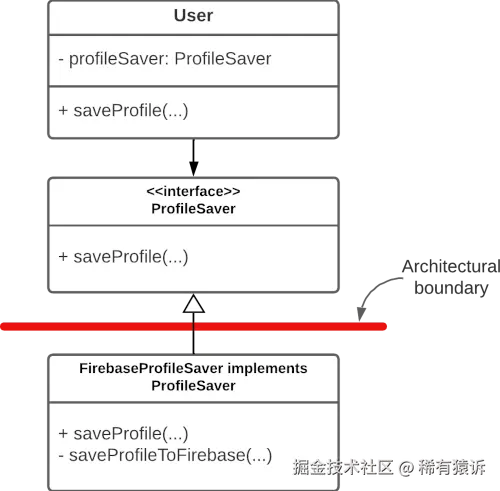
这里,User 类只知道如何抽象地与"ProfileSaver"交互。重要的是,它没有提及任何与 Firebase 相关的内容。
然后,FirebaseProfileSaver 实现了 ProfileSaver 接口。User 类对此一无所知,因此,至关重要的是,它的任何逻辑都不基于 Firebase 的工作方式。
这隔离了 Firebase 逻辑。我们可以像上图一样在低级代码和高级代码之间画一条红线。这条红线就是架构边界。
注意依赖关系箭头现在是如何从低级指向高级的。不再存在任何可以遵循的从"User"类开始到 Firebase 结束的依赖箭头序列。
架构边界应该放在哪里?
显然,正确设置架构边界对于良好的架构至关重要。从上文来看,边界似乎越多越好------但事实并非如此。
架构边界会带来维护开销。它们会产生更多代码,而且一旦设置了边界,每个未来的开发人员都必须遵守它。
而且,带有边界的代码可读性会大大降低。从上文来看,User 类的 profileSaver.saveProfile() 调用实际上触发了 Firebase 逻辑,这一点并不明显。因此,新开发人员的入职培训会变得更加棘手,代码审查也会更加困难。
整洁架构 (Clean Architecture) 是合理化架构边界的一种尝试。
Android 应用的整洁架构怎么样?
整洁架构是由资深架构师 Robert C Martin 整理的一套原则,它在一定程度上提供了一种将软件合理化为一组选定层级的方法,这些层级由架构边界划分。
其著名的图表如下所示:
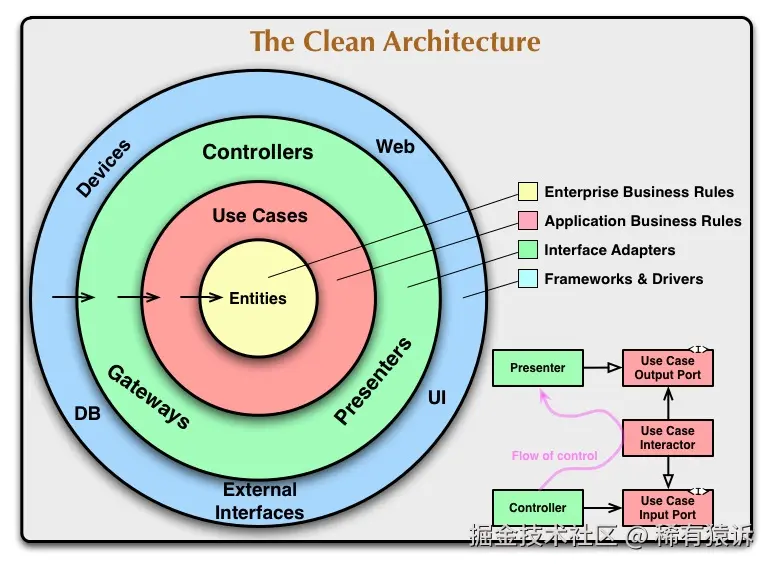
这张分层图的中心是高级代码(即纯逻辑),外围是低级代码。它遵循依赖规则(本质上是 SOLID 依赖倒置原则的产物),该规则规定低级代码可以依赖于高级代码,但反过来则不行。因此,上图中表示依赖关系的箭头始终指向内部。
那么,这些层级由什么组成呢?
用例和实体(黄色和红色圆圈)
在清晰架构图的正中央,我们可以看到用例层和实体层。它们包含应用的业务逻辑。这些逻辑是控制应用行为的纯逻辑,与具体的实现细节无关。
这种区别可能会造成混淆,因此我们来举个例子。
一个保存用户个人资料的用例会执行以下操作:
- 运行一些安全性/一致性检查。确保正在保存的个人资料包含有效数据,并且用户有权执行此操作。
- 远程保存数据
- 在本地缓存新的个人资料
- 通知 UI 需要更新
你可以说这些都是业务逻辑,因为它们与"我们在做什么"有关,而不是"我们如何做"。例如,在步骤 2 中,我们不会说明使用哪个远程 API 来保存数据;在步骤 4 中,我们也不关心要更新的 UI 是 Android 手机屏幕、网页还是 PDF。
一个用例代表来自单个参与者的单一需求(请参阅上文 SOLID 的单一职责原则)。它也是一个完整的步骤列表------你无需执行任何其他操作即可保存配置文件,并且尝试仅运行其中的一部分步骤毫无意义。
接口适配器(绿色圆圈)
这是用例细节的体现。例如,当一个用例要求在本地缓存一些数据时,我们可以在这里讨论 SQL 数据库。我们仍然不会讨论特定品牌的 SQL 数据库------任何专有技术都应放在后面讨论。如果有多个数据源,则接口适配器层应该对它们进行整理并管理差异。
几乎所有 MVVM、MVC、MVP 等拓扑结构都应该放在这里。同样,这里不涉及专有技术------所以我们这里不讨论 Jetpack Compose 或 Android XML------但我们确实保存了这些部分将要使用的状态。
框架和驱动程序(蓝色圆圈)
所有使用专有技术的内容都放在这里。这些是_实现细节_。
Jetpack Compose 的 @Composable 代码也放在这里。HTML 代码也放在这里。此外,Firebase 代码、任何 API 的具体细节、SQL 命令以及任何标有 Room 注解(例如 @Entity)的内容也放在这里......
此层的代码很难测试,因为它通常依赖于专有技术。例如,Jetpack Compose 测试依赖于专门为 Jetpack Compose 编写的工具(或者可能是为 Android 编写的工具,但重点依然存在)。因此,请尽可能精简此层。逻辑应该放在更高的层级。这只是将接口适配器的要求"翻译"到你正在使用的特定技术所需的最低限度。
这一层也是_易失性的_。它可能会在没有你输入的情况下发生变化和中断。例如,如果你正在使用的 API 突然需要不同类型的身份验证,你将不得不修改代码以适应,无论时机是否合适或你是否愿意接受这种变化。同样,尽可能精简这一层可以减少此类更改对代码库其余部分的影响。
Android 专用代码在 Clean Architecture 中位于何处?
根据 Clean Architecture 的官方定义,Android 是一项专有技术,因此应将其限制在框架和驱动程序(蓝色)层。任何带有"import android.x.y"或"import androidx.x.y"的代码都不应超出此层。
这在实践中可能非常难以实现。
一个例子是权限请求,有时在视图模型(即接口适配器区域)中提及会更方便(且更具可读性)。
因此,这完美地诠释了为什么我希望本文关注的是"原则"而非"规则"。如果你为了遵循某条规则而费尽心思,那么请考虑其背后的原则------它们可能与你的情况相关,也可能不相关。
就此示例而言,我个人认为允许在接口适配器中提及 Android 是可以接受的。毕竟,你正在构建一款 Android 应用,除非你未来有相当大的可能性会与 iOS 或 Web 应用共享完全相同的代码库,否则你没有必要为了避免 Android 而修改代码。显然,iOS 和 Web 应用通常都有各自独立的代码库。
什么造就了一款优秀的应用?我们如何构建它?
一款应用应该专注于一件事,并且做好它。它的目的不会随着时间的推移而发生太大变化,尽管它在其生命周期中可能会推出许多新功能,但它的目标受众几乎从未改变(根据单一职责原则,它的角色始终相同)。事实上,如果利益相关者开始要求你的应用迎合其他类型的用户,你通常最好为他们创建一个新的应用,以便更好地满足他们的需求。微软并没有单一的 Office 应用;相反,它有独立的 Word、Excel 和 Powerpoint 应用,每个应用都由不同的用户使用,有着不同的需求。
所以你可能会说,整洁架构(Clean Architecture)------其中许多原则旨在保护你免受 Android 应用中不太可能发生的此类更改的影响------对于我们的目的来说实在太过繁琐。在很多情况下,我同意你的观点。
谷歌似乎也同意这一点。它自己的架构建议------称之为"现代应用架构"(Modern App Architecture)------是整洁架构的一个略微宽松的版本。
Google 的现代应用架构
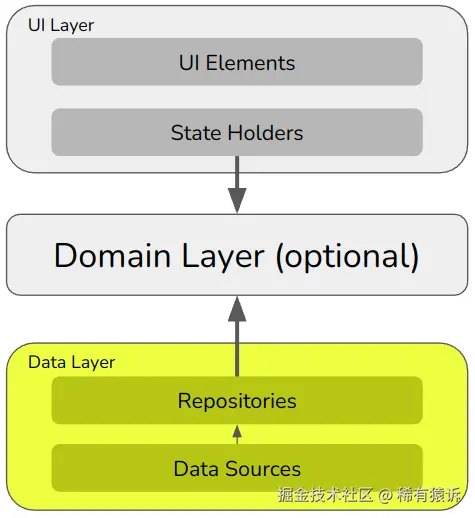
Google 将其架构简化为三层:
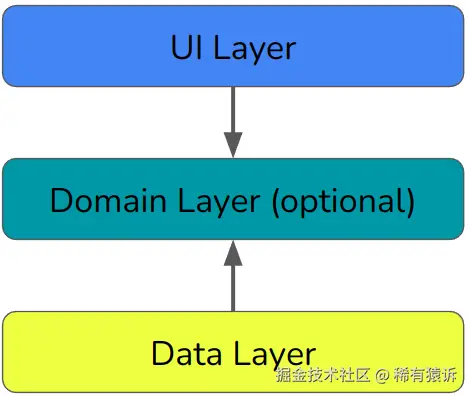
广义上讲,UI 层用于处理用户的输入和输出,并更新显示内容。领域层用于处理业务逻辑------几乎与 Clean Architecture 的用例完全相同。数据层用于从应用的存储机制读取和写入数据。
这是一种单向架构。状态仅向上流动,事件仅向下流动。
让我们更详细地了解这一切的含义。
UI 层:UI 元素和状态持有者
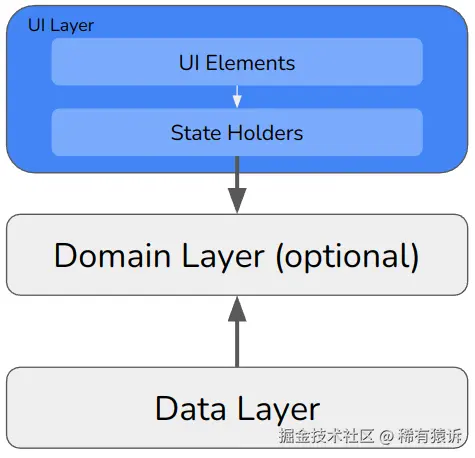
UI 层分为 UI 元素和状态持有者。
UI 元素部分仅包含为专有技术编写的代码。如果你使用的是 Jetpack Compose,请将你的 @Composable 代码放在此处。如果你使用的是 Fragments 和 XML,那么 @Composable 代码也放在此处。除此之外,没有其他内容。没有逻辑,也没有数据。
("无逻辑"规则有时对于 XML 数据绑定的用户来说很困难。例如,数据绑定允许你完全在 XML 代码中实现摄氏度/华氏度切换。不要这样做。)
相比之下,逻辑和数据则放在状态持有者中。它们之所以被称为"领域层",是因为它们保存着 UI 的状态。想想视图控制器。它们包含支持 UI 控件的变量------所以,假设你的 UI 有一个文本字段,那么包含该文本字段内容的变量就放在这里。
一个很好的建议是将这样的状态变量暴露给 Kotlin Flows。这巧妙地封装了它们的动态特性,并提供了一种内置机制来向 UI 发出需要更新的信号。
领域层:用例
领域层包含的用例与"清晰架构"中的用例完全相同。也就是说,它是由单个参与者执行单个任务所需步骤的完整列表。
但在 Google 的架构中,这一层是可选的。这意味着将纯业务逻辑放在状态持有者(比如视图模型)中并没有错。
当业务逻辑在多个状态持有者之间重用时,将业务逻辑提取到领域层中可以避免代码重复。比如说,应用程序的多个部分允许更新用户的个人资料;在这种情况下,你可以创建一个 UpdateUserProfileUseCase 并在需要的地方引用它。
数据层:存储库和数据源
数据层分为存储库和数据源。
存储库负责提供数据和保存数据。它包含 getUserProfile() 和 saveUserProfile(...) 方法。
数据源执行专有工作,例如通过调用 API 或编写 SQL 命令。
通常,一个存储库负责多个数据源。例如,你可能将数据存储在远程存储库和相同的本地缓存中。每个存储库都将作为单独的数据源实现。然后,在读取用户个人资料时,存储库可能会尝试从本地缓存读取,如果缓存为空,则回退到远程数据库。这样,负责多个数据源的存储库必须协调使用哪个数据源以及如何同步它们。
再次强调,使用 Kotlin Flows 向调用者提供数据是一种很好的做法。
比较 Google 的现代应用架构与 Clean Architecture
你可能已经注意到,现代应用架构和 Clean Architecture 各自使用"层"一词来表示略有不同的含义。以下是它们之间的对应关系:
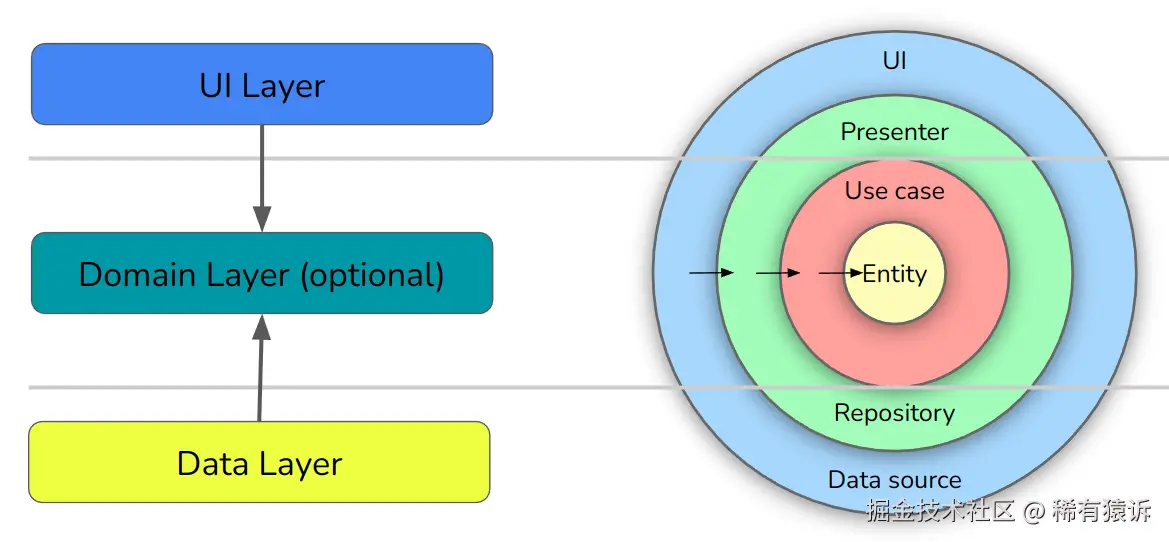
Google 的 UI 层与其数据层一样,位于 Clean Architecture 的外层两层(接口适配器、框架和驱动程序)。它的领域层完全等同于 Clean Architecture 的用例和实体。
其中一些界限比上图显示的要模糊一些。例如,Google 并不反对你将业务逻辑放置在 UI 层,这就是为什么它自己的领域层被标记为可选的原因。
UI 层和数据层都等同于 Clean Architecture 的接口适配器层和框架/驱动程序层。
总结......
本文深入探讨了良好架构背后的原则,并以两种常见范式为灵感:Clean Architecture 和 Google 的现代应用架构。
当然,你需要自行决定哪种架构最适合你的应用程序。我希望通过提供思路而不是僵化的框架,为你提供一个工具包,以便你自行做出决定。
我喜欢回答关于架构的具体问题,所以请随时在这里留下你的答案,我会尽快回复。当没有唯一的"正确"答案,而我们可以进行讨论时,这才是最有趣的。
在以后的文章中,我将使用上述内容逐步指导你使用 Kotlin 和 Compose 创建架构良好的示例应用程序。
欢迎搜索并关注 公众号「稀有猿诉」 获取更多的优质文章!
保护原创,请勿转载!