文章目录

每日一句正能量
一个人总有一天会明白,忌妒是无用的,而模仿他人无异于自杀。因为不论好坏,人只有自己才能帮助自己,只有耕种自己的田地,才能收获自家的玉米。上天赋予你的能力是独一无二的,只有当你自己努力尝试和运用时,才知道这份能力到底是什么。
第五章 HBase分布式数据库
章节概要
Spark计算框架是如何在分布式环境下对数据处理后的结果进行随机的、实时的存储呢?HBase数据库正是为了解决这种问题而应用而生。HBase数据库不同于一般的数据库,如MySQL数据库和Oracle数据库是基于行进行数据的存储,而HBase则是基于列进行数据的存储,这样的话,HBase就可以随着存储数据的不断增加而实时动态的增加列,从而满足Spark计算框架可以实时的将处理好的数据存储到HBase数据库中的需求。本章将针对HBase分布式数据库的相关知识进行详细讲解。
5.5 HBase和Hive的整合
在实际业务中,由于HBase不支持使用SQL语法,因此我们操作和计算HBase分布式数据库中的数据是非常不方便的,并且效率也低。由于Hive支持标准的SQL语句,因此,我们可以将HBase和Hive进行整合,通过使用Hive数据仓库操作HBase分布式数据库中的数据,以此来满足实际业务的需求。
通过一个整合Hive和HBase的例子,实现Hive表中插入的数据可以从HBase表中获取的需求,具体步骤如下:
1.环境搭建
首先,需要配置环境变量。在服务器hadoop01上执行命令"vi /ect/profile",配置Hive和HBase的环境变量(若已配置,则可忽略),具体内容如下:
java
#配置HBase的环境变量
export HBASE_HOME=/export/servers/hbase-1.2.1
ecport PATH=$PATH:$HBASE_HOME/bin:
#配置Hive的环境变量
export HIVE_HOME=/export/servers/apache-hive-1.2.1-bin
export PATH=$PATH:$HIVE_HOME/bin:结果如下图所示:
2.导入依赖
将目录/hbase-1.2.1/lib下的相关依赖复制一份到目录/apache-hive-1.2.1-bin/lib下,具体命令如下:
shell
cp /export/servers/hbase-1.2.1/lib/hbase-common-1.2.1.jar \
/export/servers/apache-hive-1.2.1-bin/lib
cp /export/servers/hbase-1.2.1/lib/hbase-server-1.2.1.jar \
/export/servers/apache-hive-1.2.1-bin/lib
cp /export/servers/hbase-1.2.1/lib/hbase-client-1.2.1.jar \
/export/servers/apache-hive-1.2.1-bin/lib
cp /export/servers/hbase-1.2.1/lib/hbase-protocol-1.2.1.jar \
/export/servers/apache-hive-1.2.1-bin/lib
cp /export/servers/hbase-1.2.1/lib/hbase-it-1.2.1 \
/export/servers/apache-hive-1.2.1-bin/lib
cp /export/servers/hbase-1.2.1/lib/htrace-core-3.1.0-incubating.jar \
/export/servers/apache-hive-1.2.1-bin/lib
cp /export/servers/hbase-1.2.1/lib/hbase-hadoop2-compat-1.2.1.jar \
/export/servers/apache-hive-1.2.1-bin/lib/apache-hive-1.2.1-bin/lib
cp /export/servers/hbase-1.2.1/lib/hbase-hadoop-compat-1.2.1.jar \
/export/servers/apache-hive-1.2.1-bin/lib上述导入了很多依赖,具体含义如下:
-
hbase-common-1.2.1.jar是HBase基本包;

-
hbase-server-1.2.1.jar主要用于HBase服务端;
-
hbase-client-1.2.1.jar主要用于HBase客户端;
-
hbase-protocol-1.2.1.jar主要用于HBase的通信;
-
hbase-it-1.2.1主要用于HBase整合其他框架做测试;
-
htrace-core-3.1.0-incubating.jar主要用于其他框架(如Hive或者Spark)连接HBase;
-
hbase-hadoop2-compat-1.2.1.jar和hbase-hadoop-compat-1.2.1.jar主要用于HBase可以兼容hadoop2和其他的hadoop版本。
3.修改相关配置文件
在/apache-hive-1.2.1-bin/conf目录下的hive-site.xml文件中,添加Zookeeper集群的地址并指定Zookeeper客户端的端口号,修改后的hive-site.xml文件内容如下:
xml
<!--指定Zookeeper集群的地址---->
<property>
<name>hive.zookeeper.quorum</name>
<value>hadoop01,hadoop02,hadoop03</value>
</property>
<!--指定Zookeeper客户端的端口号---->
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
<property>结果如下图所示:

执行命令"source /etc/profile",使配置的环境变量生效。
4.启动相关的服务
启动Zookeeper、Hadoop、MySQL、Hive以及HBase服务,具体命令如下:
shell
# 启动Zookeeper
$ zkServer.sh start
# 启动hadoop
$ start-all.sh
#启动MySQL
$ service mysqld start
# 启动Hive
$ bin/hive
# 启动HBase
$ start-hbase.sh运行结果如下:

5.新建Hive表
在Hive数据库创建hive_hbase_emp_tabel表,具体语句如下:
sql
CREATE TABLE hive_hbase_emp_table(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" =
":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno")
TBLPROPERTIES("hbase.table.name" = "hbase_emp_table");在上述语句中,org.apache.hadoop.hive.hbase.HBaseStorageHandler类主要用于将Hive与HBase相关联,在Hive中创建的表会映射到HBase数据库中,并将映射到HBase数据库中的表命名为hbase_emp_table。
执行上述语句后,在Hive中,执行命令"show tables"查看是否出现表hive_hbase_emp_table;在HBase中,执行命令"list"来查看是否出现表hbase_emp_table,具体命令如下:
sql
show tables;
list;结果如下图所示:
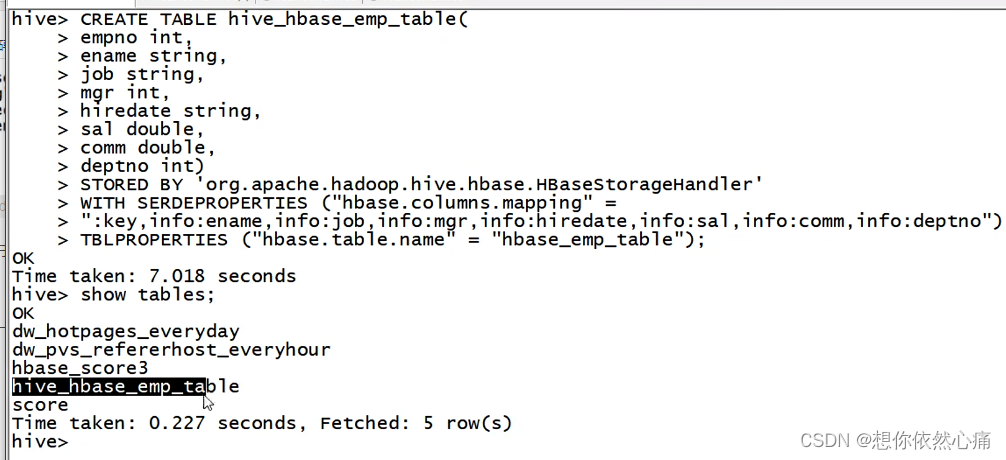
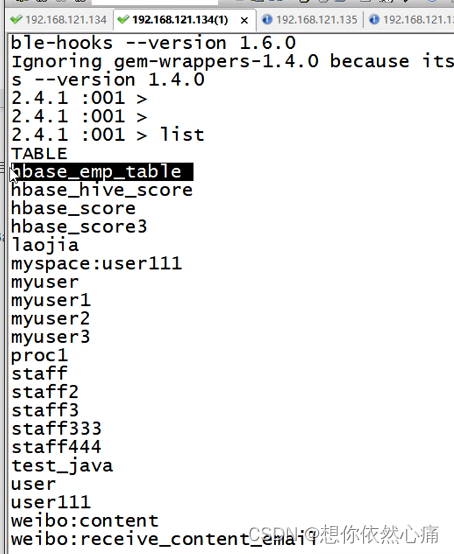
从上述返回结果可看到,Hive中包含hive_hbase_emp_table表,HBase中包含hbase_emp_table表,说明Hive与HBase整合成功后,可以在Hive中创建与HBase相关联的表。
6.创建Hive临时中间表
由于不能将数据直接插入与HBase关联的Hive表hive_hbase_emp_table中,所以需要创建中间表emp,命令如下:
sql
CREATE TABLE emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by '\t';上述命令执行成功后,在Hive中执行语句"show tables"查看Hive中数据表,具体语句如下:
sql
show tables;结果如下图所示:
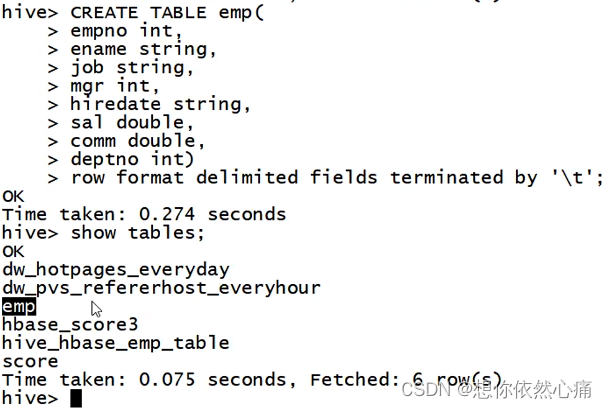
从上述代码中可看出,Hive的临时中间表emp已经创建完成。
下面,我们就往临时中间表插入数据。插入数据之前需要在Linux本地系统上创建文件emp.txt(这里存放在目录/export/data下),且每个字段对应的数据都是勇Tab制表符分隔,若对应的字段没有数据,则用空格表示,具体内容如文件5-2所示。
文件5-1 emp.txt
7369 SMITH CLERK 7902 1980-12-17 800.00 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.00 30000 30
7521 WARD SALESMAN 7698 1981-2-22 1250.00 500.00 30
7566 JONES MANAGER 7839 1981-4-2 2975.00 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.00 1400.00 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.00 30
7782 CLARK MANAGER 7839 1981-6-9 2450.00 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.00 20
7839 KING PRESIDENT 1981-11-17 5000.00 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.00 0.00 30
7876 ADAMS CLERK 7788 1987-5-23 1100.00 20
7900 JAMES CLERK 7698 1981-12-3 950.00 30
7902 FORD ANALYST 7566 1981-12-3 3000.00 20
7934 MILLER CLERK 7782 1982-1-23 1300.00 107.插入数据
向临时中间表emp插入数据,具体语句如下:
sql
hive>load data local inpath '/export/data/emp.txt' into table emp;结果如下图所示:
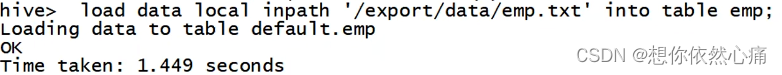
通过insert命令将临时中间表emp中的数据导入到hive_hbase_emp_table表中,具体语句如下:
sql
hive >insert into table hive_hbase_emp_table select * from emp;结果如下图所示:
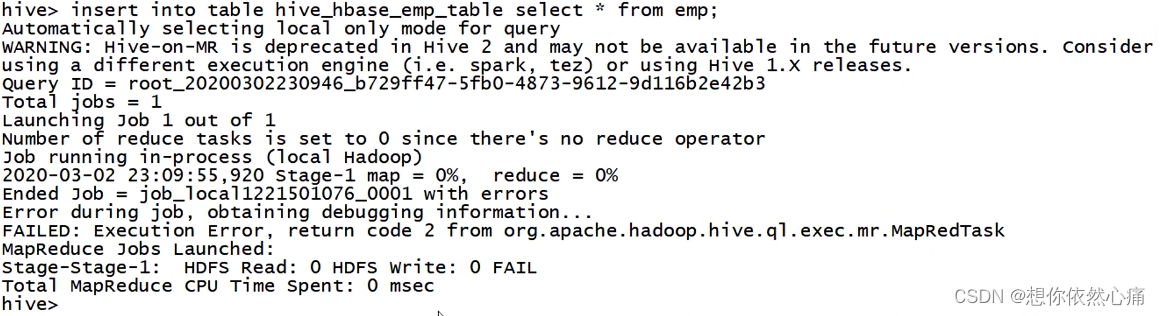
8.测试
通过查看hive_hbase_emp_table表和hbase_emp_table表的数据是否一致,则来判断HBase和Hive是否整合成功,具体语句如下:
sql
hive> select * from hive_hbase_emp_table;
hbase> scan 'hbase_emp_table'结果如下图所示:
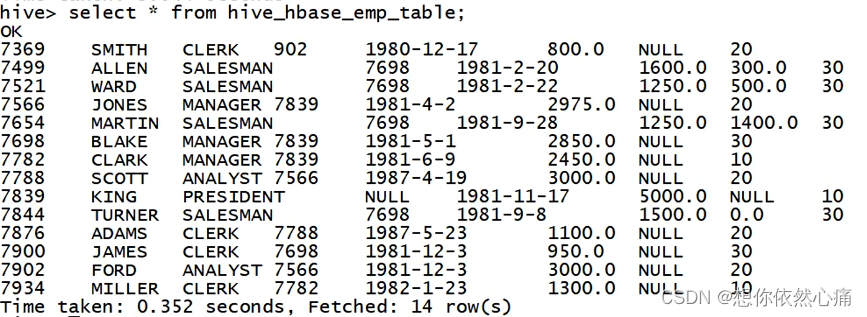

转载自:https://blog.csdn.net/u014727709/article/details/152024580
欢迎 👍点赞✍评论⭐收藏,欢迎指正