import cv2
# 读取输入图像
image = cv2.imread('img_1.png')
image = cv2.resize(image, (450, 600))
# 显示输入图像
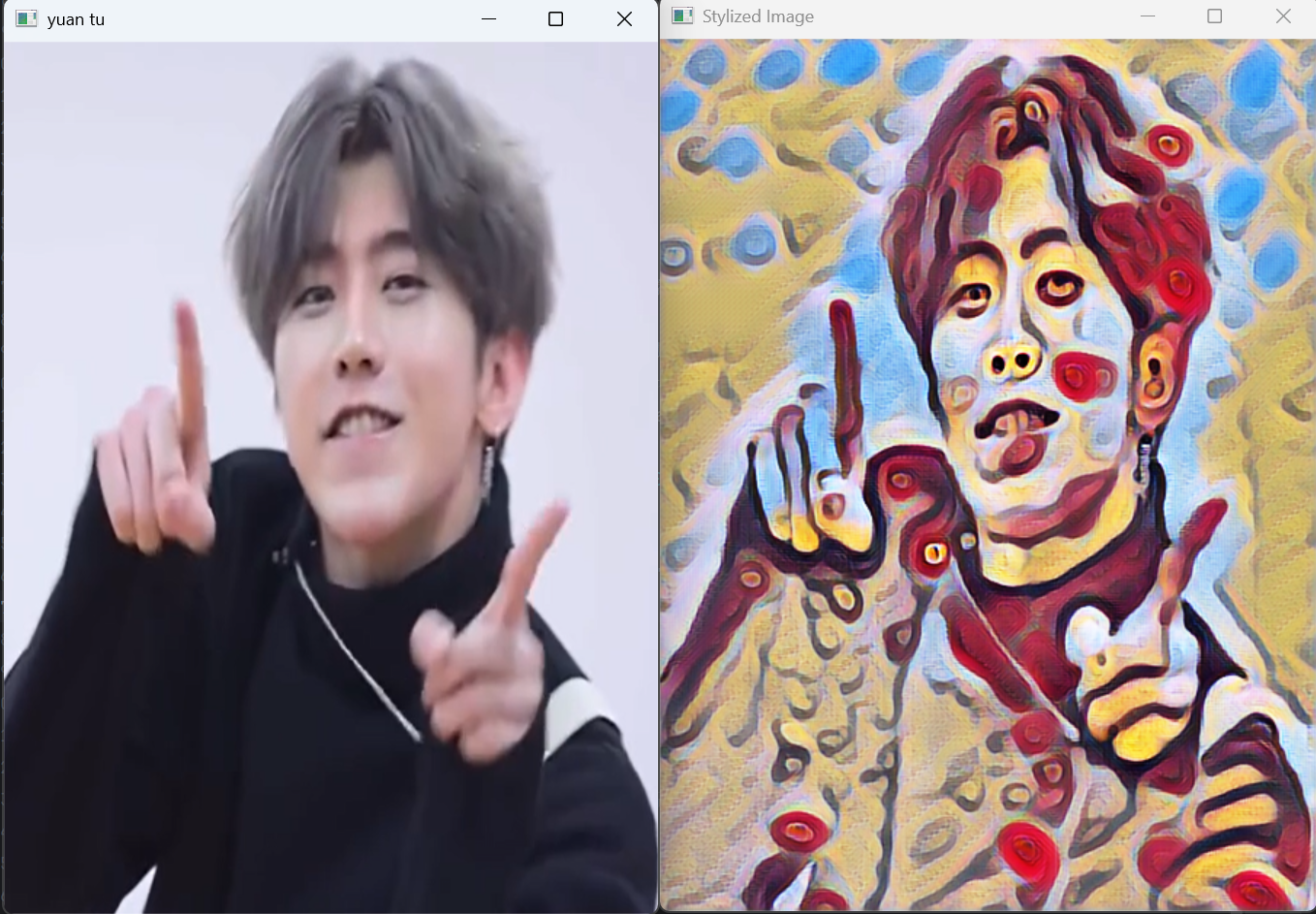
cv2.imshow('yuan tu', image)
cv2.waitKey(0)
# ------图片预处理------
# 获取图像尺寸
(h, w) = image.shape[:2]
# 从原始图像构建一个符合人工神经网络输入格式的四维块 (blob)
# 参数:
# image: 输入图像
# scalefactor: 对图像内的数据进行缩放的比例因子 (每个像素值 * scalefactor),默认为1
# size: 控制blob的宽度和高度,这里设置为原图的尺寸 (w, h)
# mean: 从每个通道减去的均值。(0, 0, 0)表示不进行均值减法
# swapRB: OpenCV默认使用BGR通道,而模型通常使用RGB。此处设为False不交换通道,请根据模型要求调整
# crop: 如果为True,则在调整大小后进行居中裁剪。此处为False
# 返回值 blob: 一个四维数据,布局为 [N, C, H, W] (批大小, 通道数, 高度, 宽度)
blob = cv2.dnn.blobFromImage(image, scalefactor=1.0, size=(w, h), mean=(0, 0, 0), swapRB=False, crop=False)
# 加载模型
# 使用 readNetFromTorch 加载 PyTorch 格式的模型文件 (.t7)
net = cv2.dnn.readNetFromTorch(r'candy.t7')
# 将预处理后的blob设置为网络的输入
net.setInput(blob)
# 对输入图像进行前向传播,得到输出结果
# 输出out是四维的,形状为 [1, C, H, W] (1张图片, 通道数, 高度, 宽度)
out = net.forward()
# 输出处理
# 重塑形状(忽略第1维的batch size),4维[B, C, H, W]变3维[C, H, W]
out_new = out.reshape(out.shape[1], out.shape[2], out.shape[3])
# 对输出的数组进行归一化处理,将其值范围缩放到0-1之间 (使用MIN-MAX归一化)
cv2.normalize(out_new, out_new, alpha=0, beta=1, norm_type=cv2.NORM_MINMAX)
# 转置输出结果的维度,从 [C, H, W] 转换为 [H, W, C] 以便OpenCV显示
result = out_new.transpose(1, 2, 0)
# 显示转换后的风格迁移图像
cv2.imshow('Stylized Image', result)
cv2.waitKey(0)
cv2.destroyAllWindows()代码概述
这段代码实现了基于深度学习的图像风格迁移功能,使用OpenCV的dnn模块加载预训练的PyTorch模型,将艺术风格应用到输入图像上。
代码逐段解析
1. 图像读取与预处理
import cv2
# 读取输入图像
image = cv2.imread('img_1.png')
image = cv2.resize(image, (450, 600))
# 显示输入图像
cv2.imshow('yuan tu', image)
cv2.waitKey(0)cv2.imread()读取图像文件cv2.resize()调整图像尺寸为450×600像素,统一输入尺寸有助于处理cv2.imshow()和cv2.waitKey(0)显示原始图像并等待按键继续
2. 构建神经网络输入Blob
# 获取图像尺寸
(h, w) = image.shape[:2]
# 从原始图像构建一个符合人工神经网络输入格式的四维块 (blob)
blob = cv2.dnn.blobFromImage(image, scalefactor=1.0, size=(w, h),
mean=(0, 0, 0), swapRB=False, crop=False)cv2.dnn.blobFromImage() 是关键函数,参数详解:
image: 输入图像scalefactor=1.0: 像素值缩放因子(1.0表示不缩放)size=(w, h): 输出blob的尺寸,此处保持原图尺寸mean=(0, 0, 0): 各通道的均值减法值(0表示不进行均值减法)swapRB=False: 是否交换红蓝通道(False表示保持BGR格式)crop=False: 是否进行中心裁剪(False表示不裁剪)
此函数生成的blob维度为1, 3, H, W,符合深度学习模型的输入要求。
3. 加载与配置模型
# 使用 readNetFromTorch 加载 PyTorch 格式的模型文件 (.t7)
net = cv2.dnn.readNetFromTorch(r'candy.t7')
# 将预处理后的blob设置为网络的输入
net.setInput(blob)cv2.dnn.readNetFromTorch()加载PyTorch格式的预训练模型net.setInput(blob)将预处理后的数据设置为网络输入
4. 前向传播与输出处理
# 对输入图像进行前向传播,得到输出结果
out = net.forward()
# 输出处理:重塑形状(忽略第1维的batch size)
out_new = out.reshape(out.shape[1], out.shape[2], out.shape[3])
# 对输出的数组进行归一化处理
cv2.normalize(out_new, out_new, alpha=0, beta=1, norm_type=cv2.NORM_MINMAX)
# 转置输出结果的维度,从 [C, H, W] 转换为 [H, W, C] 以便OpenCV显示
result = out_new.transpose(1, 2, 0)net.forward()执行前向传播,得到风格迁移结果reshape()操作将4维输出B, C, H, W转换为3维C, H, Wcv2.normalize()使用MIN-MAX归一化将值范围缩放到0,1区间transpose()将维度从通道优先C, H, W转换为OpenCV显示格式H, W, C
5. 结果显示
# 显示转换后的风格迁移图像
cv2.imshow('Stylized Image', result)
cv2.waitKey(0)
cv2.destroyAllWindows()显示最终的风格迁移结果,并等待用户按键后关闭所有窗口。