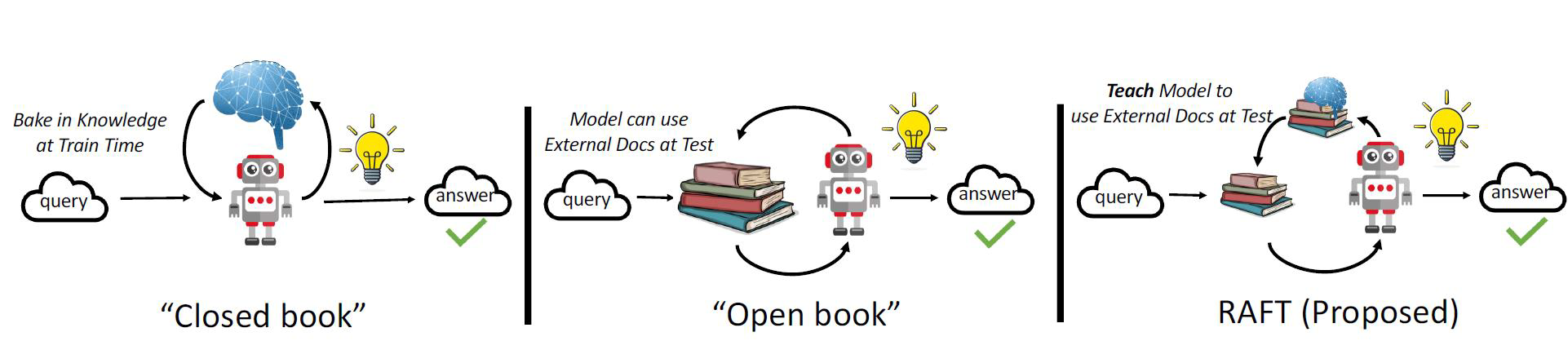
如果把大模型回答问题当做一场考试。微调可以看做闭卷考试,开卷考试则是RAG。
- 闭卷考试 ≈ 微调(Fine-tuning):模型像一个学生,只能依靠自己"背"下来的知识来答题。如果训练数据中没有某个知识,它就答不上来,甚至会"凭感觉"胡说。
- 开卷考试 ≈ RAG(Retrieval-Augmented Generation):模型像一个学生,可以翻书、查资料,根据检索到的信息来回答问题。这样答案更准确、有据可依。
那么,RAFT(Retrieval-Augmented Fine-Tuning) 是什么呢?
一、什么是RAFT?
(1)假设我们要教一个学生准备历史考试
情况1:传统微调(闭卷)
我们只给他一本教科书,让他背下来。考试时不准翻书。
**结果是:**他只能靠记忆答题。如果题目超纲了,他就答不出来。
情况2:RAG(开卷)
考试时允许他带一堆参考书,遇到不会的题就翻书查。
**结果是:**他能答对很多题,但每次都要花时间查资料,效率低,而且如果检索不准,答案也会错。还可能出现"有书不会用"的情况(比如他是个外国人从来没学过中文和中国历史)。
情况3:RAFT(用开卷来训练闭卷)
我们先让他用开卷的方式做大量练习题(比如1000道历史题,每道题都附带从资料书中检索到的正确段落)。但在训练过程中,我们只保留那些"检索到的正确资料 + 正确答案" 的样本,过滤掉检索错误或答案错误的样本。然后,我们用这些高质量的"问题+正确上下文+正确答案"数据,去微调模型。
**结果是:**这个学生最终考试哪怕是闭卷,但他已经"学到了"很多原本不在他知识库里的内容,而且学得更准、更可靠。
(2)RAFT的核心思想
- 先用 RAG 的方式运行一遍:对每个训练样本,检索相关文档,生成答案。
- 筛选高质量的训练样本:只保留那些检索准确、生成答案也准确的样本。
- 用这些"黄金样本"去微调模型。
| 问题 | RAG 的局限 | RAFT 的改进 |
|---|---|---|
| 检索不准 | 检索到错误文档,导致答案错误 | 只用高质量检索结果训练,模型学到更可靠的知识 |
| 推理慢 | 每次都要检索,延迟高 | 微调后模型"内化"了知识,推理更快 |
| 知识固化 | 模型本身没学到新知识 | 模型通过高质量数据真正"学会"了新内容 |
二、如何进行RAFT?
(1)步骤一:准备问答对和外部知识库
你需要一组原始的问答对(可以是用户问题或任务数据)和一个结构化的外部知识库(如维基百科、公司文档、数据库等)
(2)步骤二:使用RAG进行检索增强生成
对每个问题使用检索器(如 BM25、DPR、向量数据库)从知识库中查找最相关的文档片段。然后将问题 + 检索到的上下文输入大模型,生成答案。
(3)步骤三:筛选高质量样本
留那些检索正确、生成也正确的样本。可以通过以下方式筛选:
- 人工标注:专家判断答案是否准确
- 自动评估:使用评分模型(如 BERTScore、ROUGE-L)对比标准答案
- 规则过滤:比如排除包含"可能"、"大概"等不确定词的回答
- 一致性检查:多次生成取共识
(4)步骤四:构造微调数据集
将筛选后的样本构造成标准的监督学习格式:
javascript
{
"input": "原始问题",
"context": "检索正确的文本",
"output": "模型生成正确的回答"
}(5)步骤五:微调大模型
使用上述高质量数据集对预训练语言模型(如 LLaMA、ChatGLM、Qwen)进行监督微调(SFT)。训练完成后,模型就具备了"内化"的知识,即使不联网、不检索,也能准确回答问题。
- 如果允许开卷(RAG模式),它能极其高效、精准地利用提供的参考书(检索到的文档)来组织答案,因为它在"特训"中专门练过这个。
- 即使不允许开卷(纯生成模式),它也能凭借在"特训"和"巩固"中内化的知识和策略,给出比普通闭卷学生(纯微调模型)更准确、更符合领域要求的答案,因为它学过如何"像开卷一样思考"。
- 它对参考书(检索器)的依赖降低了,即使偶尔检索到不太完美的文档,它也能凭借学到的策略更好地处理。