📚AI Infra系列文章
训练好的AI模型如果不能快速、稳定、弹性地部署到生产环境,那么再高的准确率也只是"实验室成果"。在实际工程中,我们需要应对多环境兼容、弹性伸缩、版本迭代、资源调度与监控等挑战。容器化(Docker)与云原生(Kubernetes)正好为AI部署提供了统一打包、跨环境运行与自动扩缩容的能力。
所有相关源码示例、流程图、模型配置与知识库构建技巧,我也将持续更新在Github:LLMHub,欢迎关注收藏!
希望大家带着下面的问题来学习,我会在文末给出答案。
- 为什么AI模型部署更适合使用容器化而不是直接裸机运行?
- 什么是k8s?
- 模型部署时如何同时保证性能与可维护性?
1.容器化部署
容器化的核心思路是把模型运行所需的一切环境打包进镜像,保证"在我的机器上能跑"的结果在任何环境都能重现。
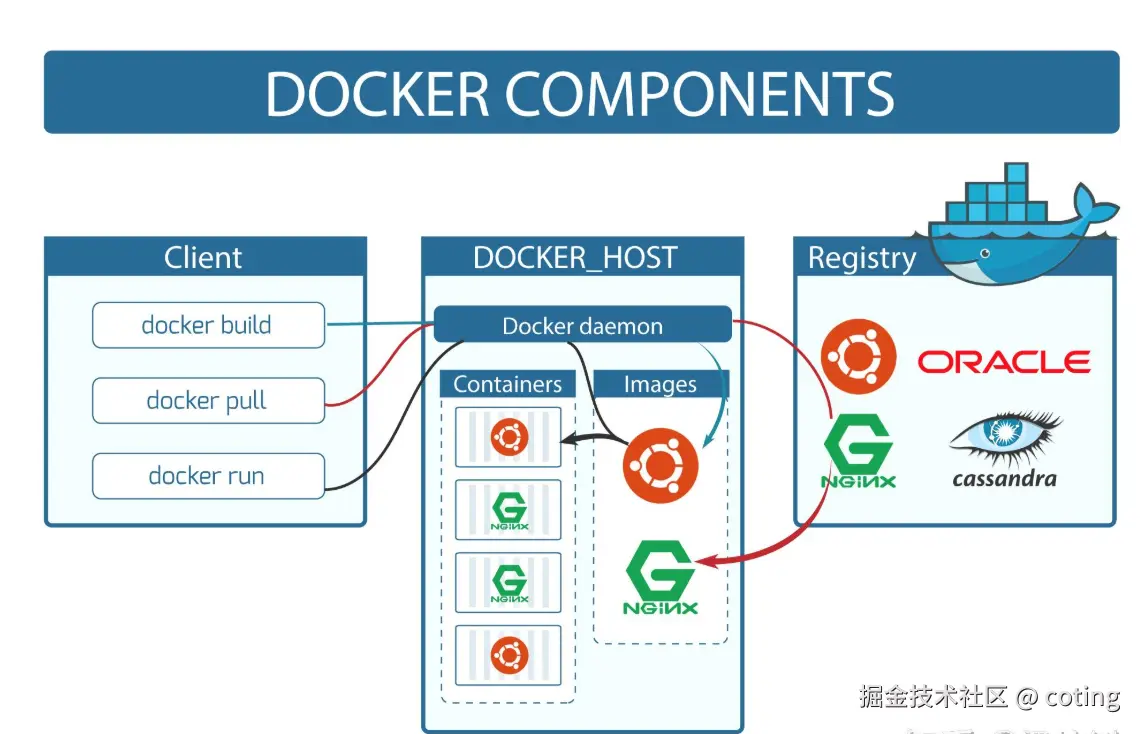
1.1 基础步骤
- 选择基础镜像 :如
nvidia/cuda:11.8-cudnn8-runtime-ubuntu20.04(GPU推理)或python:3.10-slim(CPU轻量化服务)。 - 安装依赖:包括深度学习框架(PyTorch/TensorFlow)、推理引擎(TensorRT/ONNX Runtime)、API框架(FastAPI/Flask/Triton)。
- 拷贝模型文件 :权重(
.pt/.onnx/.engine)与推理脚本。 - 暴露接口:HTTP/gRPC 端口用于接收推理请求。
1.2 示例 Dockerfile
dockerfile
FROM nvidia/cuda:11.8.0-cudnn8-runtime-ubuntu20.04
WORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txt --no-cache-dir
COPY model.onnx inference.py ./
EXPOSE 8080
CMD ["python", "inference.py"]1.3 容器化优势
- 一次构建,到处运行(本地、云、边缘统一环境)。
- 依赖隔离(不同模型互不干扰)。
- 快速回滚与版本管理(镜像即版本)。
2.云原生部署
容器解决了打包和移植的问题,但在多节点、自动扩缩容、滚动升级、资源调度等方面,Kubernetes(K8s)才是AI模型落地的核心基础设施。
Kubernetes(简称 K8s )是一个开源的容器编排平台,用于自动化应用的部署、扩缩、负载均衡和运维管理 。它可以把一组服务器抽象成统一的资源池,将容器化的应用调度到合适的节点上运行,并提供自愈能力(如容器故障自动重启)、滚动更新和服务发现。通过 K8s,开发者和运维人员能更高效地管理大规模分布式应用,提升系统的稳定性与可扩展性。
2.1 核心组件
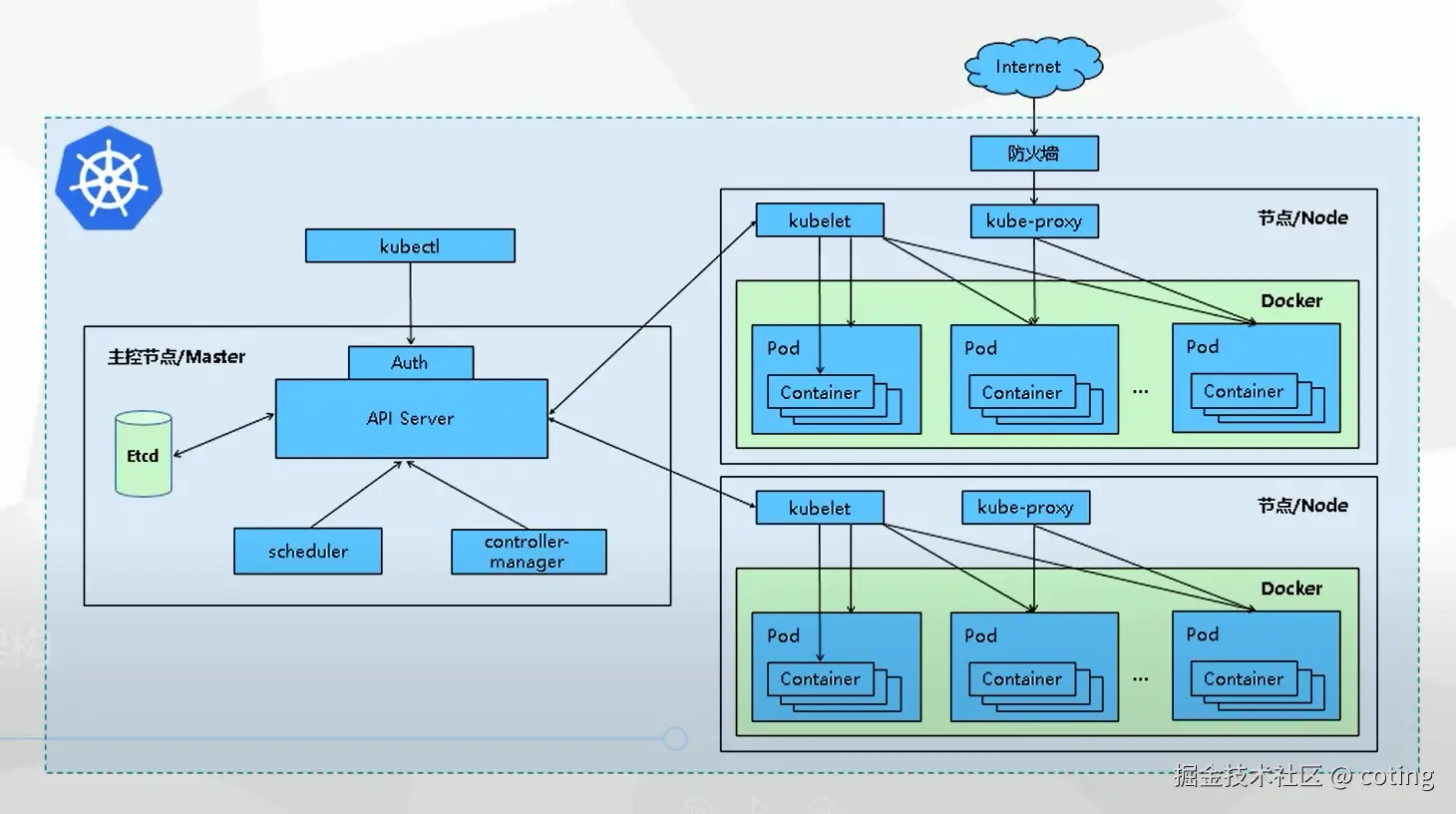
k8s的核心组件包括:
- Pod:运行容器化的推理服务实例。
- Deployment:管理副本数、滚动升级与回滚。
- Service:暴露稳定访问入口(ClusterIP、LoadBalancer)。
- Horizontal Pod Autoscaler (HPA):根据CPU/GPU利用率自动伸缩实例数。
- PersistentVolume (PV):挂载模型文件与缓存。
- Node Selector / Taints:保证AI Pod调度到有GPU的节点。
2.2 GPU推理部署YAML示例
yaml
apiVersion: apps/v1 # 使用的 Kubernetes API 版本,这里是 apps/v1,常用于 Deployment
kind: Deployment # 资源类型,这里是 Deployment,表示要部署一个应用
metadata:
name: ai-inference # 部署的名称,集群内唯一标识
spec:
replicas: 2 # 副本数,表示同时运行 2 个 Pod 实例,保证高可用
selector: # 定义 Deployment 如何找到要管理的 Pod
matchLabels:
app: ai-inference # 通过标签匹配 Pod
template: # Pod 模板,定义 Pod 的具体规格
metadata:
labels:
app: ai-inference # Pod 的标签,用于匹配 selector
spec:
containers: # Pod 内的容器定义
- name: inference # 容器名称
image: myrepo/ai-inference:1.0 # 容器镜像,来自 myrepo 仓库
resources:
limits:
nvidia.com/gpu: 1 # 申请 1 个 GPU 资源(NVIDIA)
ports:
- containerPort: 8080 # 容器内部对外暴露的端口,用于服务访问3.高性能推理平台
NVIDIA Triton 可以直接将模型托管为推理服务,支持多框架(PyTorch/TensorFlow/ONNX/TensorRT),并提供批处理、并行模型加载、动态扩缩容等能力。
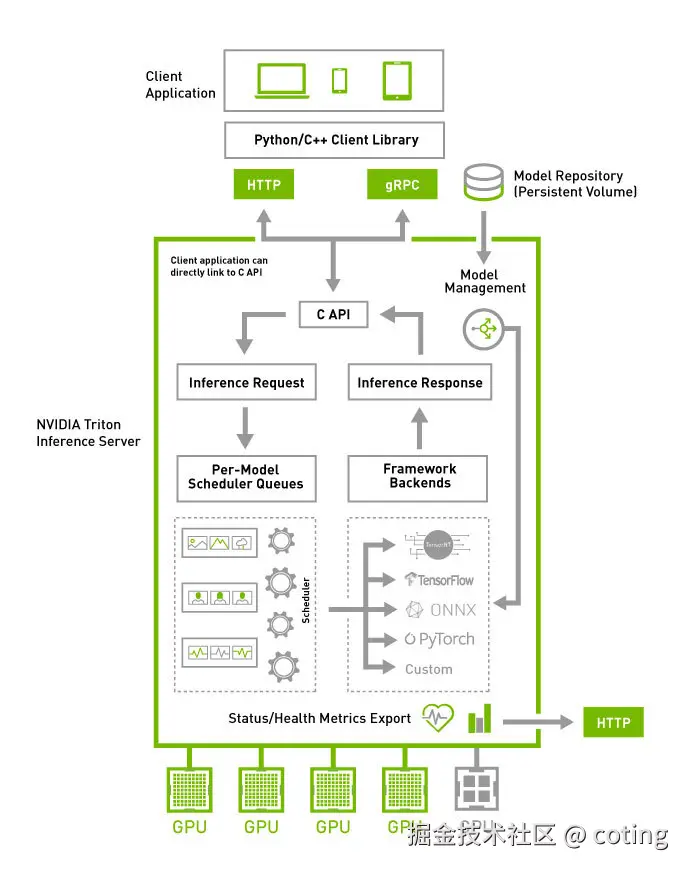
Triton Inference Server 的整体架构和工作流程可以分为以下几个关键部分:
- 客户端接口
- 应用(Client Application)可以通过 HTTP、gRPC 或 C API 与 Triton 通信。
- NVIDIA 还提供了 Python/C++ 客户端库,简化调用。
- 模型管理(Model Management)
- 模型存放在 Model Repository(持久化存储卷) 中,Triton 可动态加载、卸载和热更新模型。
- 请求处理
- 客户端发送 Inference Request(推理请求) ,Triton 经过 调度队列(Per-Model Scheduler Queues) 分配任务。
- 调度器会根据不同模型的需求,将请求交给相应的 框架后端(Framework Backends) 执行,例如 TensorRT、TensorFlow、ONNX Runtime、PyTorch,或自定义后端。
- 推理执行
- Triton 可以在 GPU 或 CPU 上运行推理任务,并且支持多 GPU 并行调度,充分利用硬件资源。
- 结果返回
- 推理完成后,通过 Inference Response(推理响应) 返回结果。
- 监控与状态导出
- Triton 提供 HTTP 接口导出健康检查和性能指标,方便监控与运维。
Triton Inference Server负责管理模型、调度任务、调用底层框架,并高效利用硬件资源,让开发者可以轻松部署和扩展 AI 推理服务。
最后,我们回答一下文章开头提出的问题。
- 为什么AI模型部署更适合容器化?
容器化保证跨环境一致性、依赖隔离、快速部署回滚,并方便在云原生环境中托管。
- 什么是K8s?
K8s是一个开源的容器编排平台,用于自动化应用的部署、扩缩、负载均衡和运维管理 。通过 K8s,开发者和运维人员能更高效地管理大规模分布式应用,提升系统的稳定性与可扩展性。
- 如何兼顾性能与可维护性?
使用推理优化引擎与批处理提高吞吐,配合日志监控、自动化部署和安全扫描保持长期稳定运行。
关于深度学习和大模型相关的知识和前沿技术更新,请关注公众号 coting!
以上内容部分参考了 Kubernetes 官方文档与工程实践,非常感谢,如有侵权请联系删除!
参考链接