变分自编码(Variational Autoencoder,VAE)
VAE 是一种基于概率图模型 的生成模型,它通过学习**数据的潜在分布(Latent Distribution)**来进行生成。它本质上是传统自编码器(AE)的一个概率化、正则化版本。
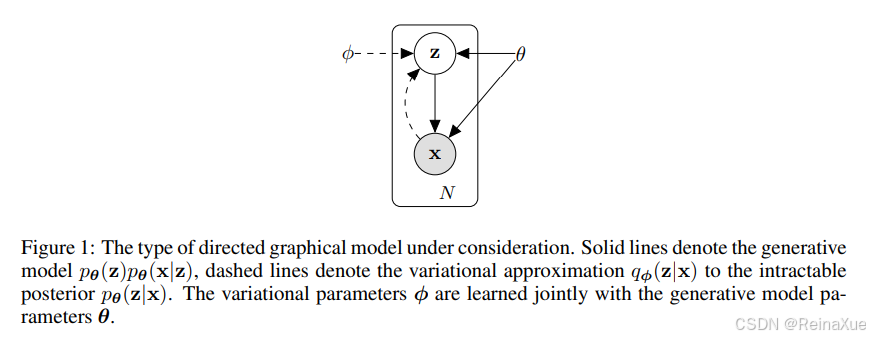
核心原理:概率分布
VAE 包含两个主要部分:编码器(Encoder)和解码器(Decoder)。
-
编码器 (Inference Model,
)
-
输入 :真实数据样本
-
输出 :不是一个确定的潜在向量
-
功能 :将输入数据
-
-
解码器 (Generative Model,
-
输入 :从潜在分布
-
输出 :重构的样本
-
功能 :将潜在向量
-
训练目标:变分下界(Evidence Lower Bound, ELBO)
VAE 的损失函数由两部分组成:
1. 重构损失 (Reconstruction Loss)
-
项 :
-
目标 :确保解码器能够忠实地重构 输入数据。它衡量了重构样本
2. KL 散度损失 (Kullback-Leibler Divergence Loss)
-
项 :
-
目标 :正则化 潜在空间。它强制编码器输出的潜在分布
-
作用:
-
平滑化:确保潜在空间是连续且平滑的,这样我们在其中任意采样 z 都能生成有意义的样本。
-
泛化:防止编码器将数据简单地记住,迫使它学习到数据的内在、解耦的特征表示。
-
核心技巧:Reparameterization Trick(重参数化技巧)
由于采样操作是不可导的,无法进行梯度回传,VAE 使用重参数化技巧:
这样,采样的随机性来自于 ,而
和
只是参数,使得整个计算图可以进行端到端的梯度下降。
| 特点 | 描述 |
|---|---|
| 可训练 | 通过最大化 ELBO 进行端到端训练。 |
| 生成方式 | 从先验分布 |
| 优点 | 潜在空间结构清晰、可解释性强;易于训练(相比 GAN)。 |
| 缺点 | 生成的样本细节通常比较模糊(这是由于使用了均方误差等基于像素的重构损失)。 |
生成对抗网络(Generative Adversarial Network, GAN)
GAN 是一种基于博弈论 的生成模型,它通过两个网络的对抗性训练来学习数据分布。

核心原理:极小极大博弈(Minimax Game)
GAN 由两个互相竞争的网络组成:生成器学习生成合理数据,如图像生成器给定一个向量会生成一张图片,其生成的数据作为判别器的负样本。判别器判别输入的是生成数据还是真实数据,网络输出越接近于0,生成数据的可能性越大;反之,真实数据的可能性越大。
-
生成器 (Generator,
-
输入 :一个随机噪声向量
-
输出 :一个合成的假样本
-
目标 :欺骗判别器,使判别器错误地认为生成的样本是真实的。
-
-
判别器 (Discriminator,
-
输入 :一个样本
-
输出 :一个标量,表示输入样本是真实样本的概率(接近 1 表示真实,接近 0 表示虚假)。
-
目标 :准确地分辨出输入样本是真实的还是虚假的。
-
训练目标:价值函数(Value Function)
GAN 的训练被形式化为一个二人零和博弈,其价值函数(Value Function)为:
-
最大化
-
让
-
让
-
-
最小化
- 让
- 让
在最优状态下,生成器 成功地学习到数据的真实分布
,此时对于任何输入,判别器
的输出都是
(完全无法分辨)。
| 特点 | 描述 |
|---|---|
| 可训练 | 两个网络交替训练,达到纳什均衡。 |
| 生成方式 | 从随机噪声 |
| 优点 | 生成样本质量高,细节清晰锐利(因为判别器直接关注样本的真实性)。 |
| 缺点 | 训练难度大 :容易出现模式崩溃(Mode Collapse),即生成器只专注于生成几个能骗过判别器的样本,而无法覆盖整个真实数据分布;对超参数敏感。 |
| 变体 | WGAN (稳定训练)、DCGAN (用于图像)、CycleGAN (非配对图像转换)。 |
扩散模型(Diffusion Models)
扩散是受非平衡热力学的启发,定义一个扩散步骤的马尔科夫链,并逐渐向数据中添加噪声,然后学习逆扩散过程,从噪声中构建出所需要的样本。
扩散模型的最初设计是用于去除图像中的噪声,随着降噪系统的训练时间越来越长且越来越好,可以把纯噪声作为输入,生成逼真的图片。
扩散模型是一类近年来非常流行的生成模型,它通过模拟一个逐步去噪过程来生成数据。
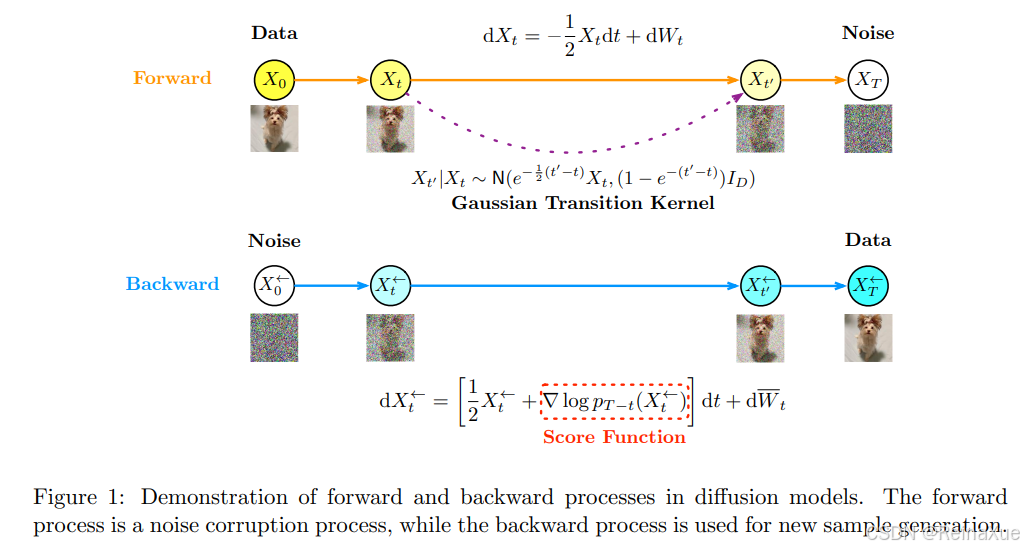
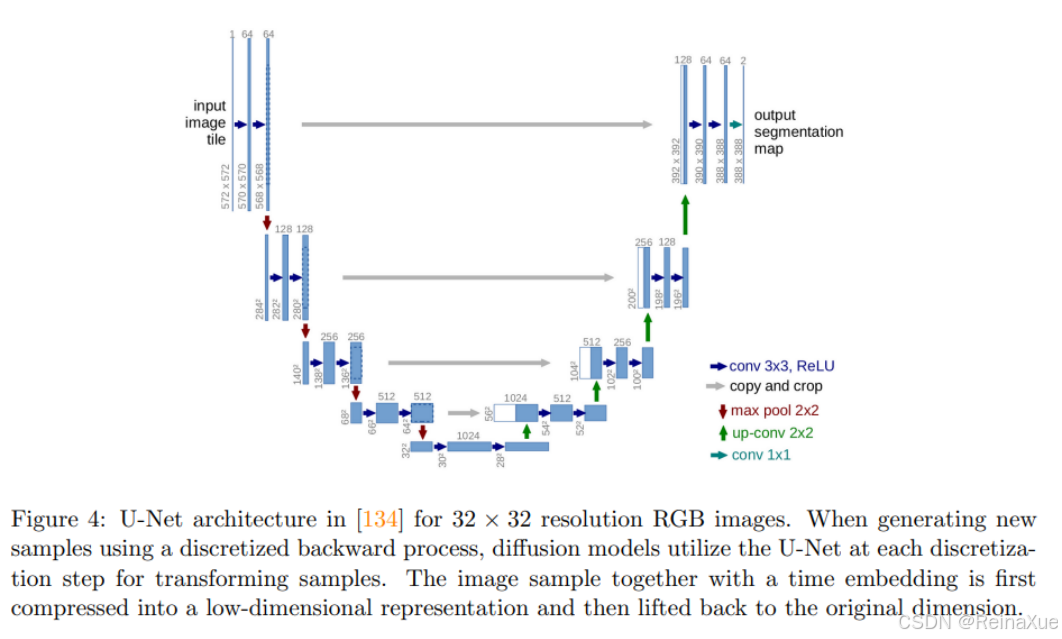
核心原理:前向过程与反向过程
扩散模型将生成过程分为两个阶段:
-
前向扩散过程(Forward Diffusion Process)
-
定义 :一个固定的马尔可夫链,逐步地向数据中添加高斯噪声。
-
过程 :从原始数据
-
结果 :最终,数据
-
目标 :这个过程是可解析的 (可以得到任意时间步
-
- 反向去噪过程 (Reverse Diffusion Process)
-
定义 :训练一个深度神经网络(通常是 U-Net 结构)来学习并逆转前向过程。
-
过程 :从纯噪声
-
目标 :学习每一步的噪声均值
-
训练 :模型的训练目标是最小化 每一步真实噪声
-
其中 。
核心技巧:噪声预测
通过预测每一步应该去除的噪声 (而不是直接预测样本
),模型可以更稳定和高效地学习去噪过程。
生成过程
-
从标准高斯分布中采样纯噪声
-
从
-
在每一步
-
最终得到的
| 特点 | 描述 |
|---|---|
| 可训练 | 通过最小化噪声预测的均方误差进行端到端训练。 |
| 生成方式 | 迭代去噪。 |
| 优点 | 生成样本质量极高 ,在图像和视频生成上效果超越 GAN;训练稳定,不易模式崩溃。 |
| 缺点 | 生成速度慢(需要数百甚至数千步迭代);计算资源要求高。 |
| 变体 | DDPM、DDIM (加速采样)、Classifier Guidance/CFG (条件生成)。 |
三大模型对比总结
| 特征 | 变分自编码器 (VAE) | 生成对抗网络 (GAN) | 扩散模型 (Diffusion) |
|---|---|---|---|
| 核心机制 | 概率建模 (ELBO) | 极小极大博弈 (对抗) | 迭代去噪 (马尔可夫链) |
| 模型数量 | 1个 (AE 结构) | 2个 (G 和 D) | 1个 (噪声预测器 U-Net) |
| 生成质量 | 一般 (细节模糊) | 优 (细节锐利) | 最优 (目前 SOTA) |
| 训练稳定性 | 高 (易于收敛) | 低 (模式崩溃,难收敛) | 高 (均方误差稳定) |
| 潜在空间 | 结构化,可解释 | 非结构化 (不易直接操作 z) | 结构化 (每个 x_t 都是一个潜在表示) |
| 生成速度 | 快 (一步到位) | 快 (一步到位) | 慢 (需要多步迭代去噪) |
| 主要应用 | 降维、半监督学习、图像属性操作。 | 图像/视频生成、风格迁移、超分辨率。 | 图像/视频生成、音频生成、文生图 (Stable Diffusion)。 |
参考论文
VAE:https://arxiv.org/abs/1312.6114
GAN:https://arxiv.org/abs/1406.2661
Diffusion Models:https://arxiv.org/abs/2404.07771
LDM:https://arxiv.org/abs/2112.10752