
目录
[struct rqueue_elem](#struct rqueue_elem)
前言
最近这段时间你有排过队吗,最近一次排队是在什么时候呢?是在通勤的时候等红绿灯吗,还是超市结账时呢,亦或是其他什么时候呢。你有没有想过日常生活中先到先得的排队算法,在操作系统中是否适用呢,面对系统中数以万记的进程,系统的设计者是如何确保每个进程都尽可能得到公平的对待?
本文将首先探讨Linux是如何高效切换进程的,之后详细剖析调度器是如何做到O(1)复杂度。
一、进程切换的本质
我们为什么需要进程切换?当一个进程占用CPU时间过长,或者时间片到了就应该将他换下去,让其他的进程上CPU执行,否则我们的电脑、手机等在同一时刻就只能运行一个进程,进程切换当代分时操作系统设计的基本理念。
首先指明进程切换的核心本质是保存当前进程的执行上下文,并恢复下一个进程的执行上下文,而其中 task_struct 是承载这些信息的关键数据结构。
1.进程的"上下文"是什么
软件层面的上下文:
进程状态: R运行态(时间片到了)、S睡眠(I/O操作陷入睡眠)等当时的进程状态。
调度信息: 优先级、调度策略等。
内存管理信息: 进程虚拟地址中的各区域大小等信息,页表等。
文件描述符表: 打开的文件、网络套接字等。
信号处理信息: 待处理的信号、信号处理函数。
进程关系: 父进程、子进程信息。
硬件层面的上下文:
程序计数器: 下一条将要执行的指令地址。(这是最重要的,因为它决定了回来时从哪里继续)
通用寄存器: 里面保存着进程运行时的临时计算结果,需要保存。
栈指针: 指向当前进程的栈顶。
**控制寄存器:**它存储着整个进程的地址空间。
进程切换时,软件层面的数据本来就一直保存在它 task_struct 中,所有不需要额外数据结构保存,但硬件的上下文一般保存在 task_struct -> thread数据结构中。
2.进程切换的步骤
一次较为完整的进程切换包括如下步骤:
①触发系统调度:系统调用、中断、时间片结束,CPU从用户态陷入内核态。
②保存当前CPU上进程的上下文:硬件级数据保存在task_struct -> thread,软件级数据一直都在task_struct。
③选择下一个上CPU的进程:调度器根据算法从运行队列中(Linux中的就绪队列就是运行队列),选择下一个进程。
④切换进程地址空间:若下一个进程与被切换的进程完全不是一个进程,那么需要切换控制寄存器中的内容,换成新进程mm_struct中记录的进程虚拟地址空间信息,这一步代价最大,因为导致TLB(快表)中的大部分或全部失效。
⑤切换栈指针:将栈寄存器指向新进程的栈;
⑥恢复新进程的上下文:从新进程的 task_struct 中恢复软件级数据,与其他硬件寄存器数据。
⑦CPU回到用户态:从程序计数器中读取新进程的下一条指令地址。
由上我们也可以看出,进程切换是"先调度再切换"的步骤:先通过调度器算法选择下一个要运行的进程(即"找到新进程"),然后再进行上下文切换。
而调度算法,正是解决调度器如何找到下一个将要使用CPU的进程方法。

二、大O(1)调度算法的实现
1.O(1)出现背景
在Linux 2.4及更早的版本中,使用的调度器是O(n)复杂度的,这导致每次调度需要遍历整个就绪队列来找到最优进程,而随着进程数增加,调度开销线性增长,而随着OS系统功能的不断丰富和完善操作系统中进程愈来愈多不可避免......
于是由 Ingo Molnar 在2002年,在Linux 2.6中引入了O(1)调度算法,该算法的目标就是:无论系统中有多少个进程,调度决策的时间都是常数时间O(1)。
2.O(1)调度的核心数据结构
首先指出,一个CPU就至少需要一个运行队列,若存在多个CPU那么还要考虑各个CPU的负载信息,这不是本文讨论重点。
其次在分时的Linux操作系统中,由PRI与NI所能标识的进程优先级共有40个等级。
两级数据结构
O(1)调度的核心在于一个CPU运行队列中引入了两个"优先级数组":
cpp
struct runqueue
{
......
// 两个优先级数组
prio_array_t *active; // 活动数组
prio_array_t *expired; // 过期数组
......
};prio_array_t是什么类型的数据?实际上这两个指针分别是一个只有两个元素数组的成员,而这个数组的类型则是struct rqueue_elem类型。

struct rqueue_elem
从上图中我们也可以看出,该类中只有三个成员:nr_active, bitmap5,queue140,下面我们来认识它们的作用:
为方便读者整体理解,这里先介绍queue140:
queue数组 一共有140个元素,而其中每一个下标都代表着一种优先级 ,是的数组下标就是优先级!你可能会问Linux操作系统中进程优先级不是只有40个等级吗,这40优先级其实是Linux内核中负责分时操作系统那部分的优先级。其中前100个元素是时实操作系统占用 ,我们不做过多了解,后40个正好对应上PRI与NI所能标识的进程优先级值得的取值范围。
除去前100个,之后的40个元素,每一个元素都是一个进程队列,相同优先级的进程按照FIFO(先来先到)规则进行排队调度。 queue数组实际上就是个哈希表(桶)。
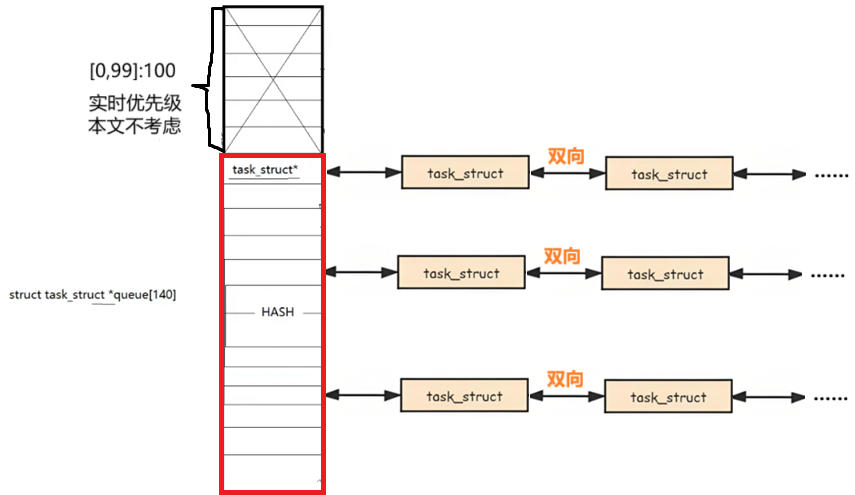
nr_active:它记录queue140的队列数组中一共链着有多少个进程。
bitmap5:每个元素都是无符号32位类型,32 * 5 = 160。前140个比特位,每个比特位与queue140中的每个队列相对应,该队列中有进程则比特位为 1 ,反之为 0 。
双数组交替机制
上面说到struct runqueue中有两个优先级数组,其中active指针和expired指针分别指向它们。而两个指针的类型struct rqueue_elem,我们也已经知道。现在抛出一个疑问:为什么要有两个优先级数组呢?------如果只有一个队列,那么每执行完但优先级又很高的进程下CPU后放在哪合适?所以为防止一个队列中优先级较低的进程始终得不到调度,被饿死,设计出两个优先级数组。
runqueue数组成员active指针,指向的数组被称为活跃进程,第一次被执行的进程都会被放到里面,然后OS按优先级(queue下标),从上往下依次执行,如果时间片到这个进程没执行完?------按优先级下标放到expired过期进程数组中,这样active中的进程越来越少,expired进程越来越多,当active队列执行完后,swap(&active,&expired),继续执行active。如此往复,就既解决了优先级问题,又避免了低优先级进程被饿死的问题!!
所以实际运行过程中,在寻找下一个进程时,操作系统先看nr_active确定里面有没有进程,有,再通过bitmap比特位图快速定位到具体的task_struct队列。nr_active、bitmap、queue140共同维护构成一个理论上的task_struct运行队列。
综上,这就是Linux中O(1)调度算法,不随着进程增多⽽导致时间成本增加,始终是个常数!
三、O(1)算法的优缺点
关于O(1)调度器的优点,正如上述所说实现了真正的O(1)复杂度 :让进程调度与进程数无关;以及出色的可扩展性:每个CPU有自己的运行队列,等等。下面总结O(1)调度算法的核心创新点:
①优先级位图实现O(1)的最高优先级查找
②双数组交替实现O(1)的数组切换
③每个优先级队列中的双向链表实现O(1)的进程选取
下面介绍O(1)算法的缺陷:
①动态优先级调整复杂:O(1)算法除了我们上述说到的核心调度外,还包括优先级调整
机制------根据进程睡眠时间与运行时间比率,动态调整进程的优先级。但这套判断代码十分复杂,大量的启发式代码使得后续程序员难以理解和维护;
**②交互性判断的不准确性:**上面说到O(1)算法会动态调整进程的优先级,其中常交互(常睡眠)的进程获得优先级提升,但是有时候CPU密集型进程会被误判为交互式进程,真正的交互式进程可能得不到足够的优先级提升,这导致了一定的"进程饥饿"现象。
正是由于上述以及未提及的种种问题,Linux在2.6.23版本及之后放弃使用O(1)调度算法,而新引入了**CFS(完全公平调度器)算法。**有趣的是,这两种算法的提出者"似乎是同一个大佬"------Ingo Molnar。
总结
本文探讨了Linux操作系统的进程调度机制。首先分析了进程切换的本质,包括保存/恢复上下文的关键步骤。重点介绍了O(1)调度算法的实现:采用两级数据结构(优先级数组)和双数组交替机制,通过位图快速定位进程队列,实现常数时间的调度决策。文章指出该算法通过哈希表式队列和双数组轮换,既保证优先级调度又避免进程饥饿。最后总结了O(1)算法的优缺点,包括其创新性的位图查找和双数组设计,但也指出其动态优先级调整复杂等问题,为后续CFS调度器的引入做了铺垫。该算法虽已淘汰,但其设计思想仍具参考价值。
尽管如今操作系统内的调度算法已经不再是O(1)算法,但其设计思想(特别是位图的使用)在现代操作系统和算法设计中仍有重要价值。
读完点赞,手留余香~