编者按: 当我们谈论训练万亿参数的大语言模型时,除了惊叹于其算力需求,是否曾深入思考过:如何让成千上万甚至数十万块 GPU 高效协同工作,像超级大脑般实时共享信息?
本文以训练大语言模型对海量算力的迫切需求为切入点,深入剖析了大规模 GPU 集群网络设计的核心挑战与解决方案:首先揭示了理想化"全互联"架构的不可行性,进而引入网络交换机及分层"叶脊拓扑"结构。接着系统对比了两种关键扩展策略------通过增加节点实现横向扩展与通过提升单节点算力密度实现纵向扩展,并重点强调节点内通信(如 NVLink/Infinity Fabric)凭借极短物理距离和专用互连技术,其速度与带宽远超节点间通信。最后结合神经网络训练流程(前向/反向传播、梯度更新),点明全归约(AllReduce) 等集合通信操作在梯度同步中的核心地位及其延迟对训练效率的直接影响,并提及软件优化(如通信与计算重叠)的重要性。
作者 | Austin Lyons
编译 | 岳扬
本系列文章将用轻松的方式聊聊网络与 GPU。这个话题很重要,但可能显得有些枯燥或深奥。请耐心听我道来!
01 训练动机
训练大语言模型需要海量的浮点运算(FLOPs):
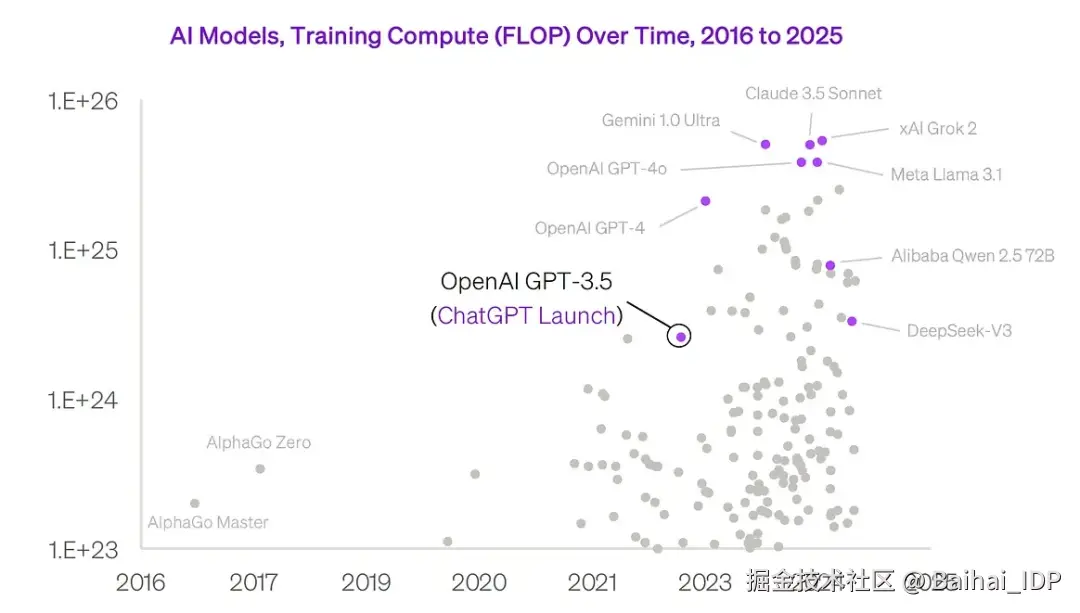
Source: chamath.substack.com/p/deep-dive...
这些模型要训练多久?
假设单个 GPU 每秒能完成 2 PetaFLOP/s(即 2 * 10^15 次浮点运算),而一天共有 86,400 秒,那么单日运算量约为 1.7 x 10^20 FLOPS。在最理想的情况下,使用单个 GPU 训练达到 10^24 FLOPs 需要整整 16 年。
16年!谁等得起啊!
如何才能在数月或数周内完成训练?我们需要让大量 GPU 协同工作。
这些 GPU 还需要相互通信,实时共享训练进度和训练结果。它们如何实现通信?靠网络!

不,不是这种社交网络。

对,这才是我们要说的网络!😅
连接 GPU 其实是个非常有趣的技术难题。想想 xAI 需要协调 20 万个 GPU 之间的通信!
02 网络交换机
以 xAI 的 20 万块 GPU 集群为例:如何实现互联?
在理想状态下,每块 GPU 都能以最高速率与其他所有 GPU 直接通信。
最直接的想法是:能否直接连接所有 GPU?
无需交换机或其他中转设备,理论上这种方案速度最快!
这就是"全互联(full mesh)"网络架构。
但全互联架构在实际的大规模部署中存在诸多问题。
例如:若要实现 GPU 两两直连,每块 GPU 需配备 199,999 个端口,总共需要约 200 亿条线缆!这显然太荒谬。
如果引入网络交换机呢?网络交换机是专门用于在多设备(此处指 GPU)间高效路由数据的硬件设备。
无需将所有 GPU 直接相连,而是让 GPU 连接到交换机,由交换机统一管理通信链路。
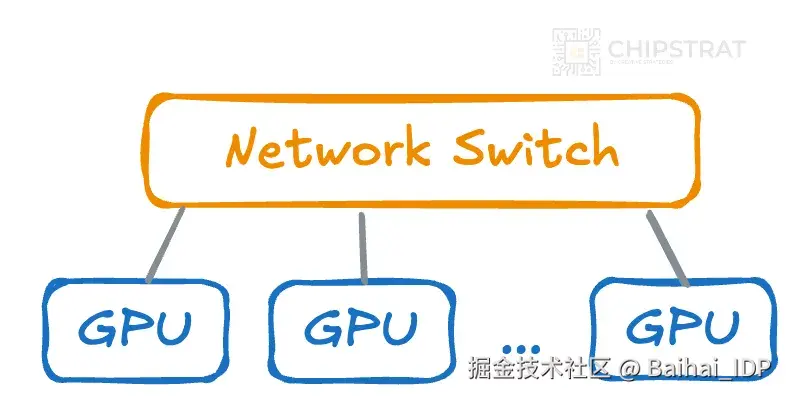
网络交换机连接这些 GPU,使它们能够相互通信
若采用单台交换机连接 20 万块 GPU,线缆数量可降至每块 GPU 1 条,从 200 亿条骤减至 20 万条!
但这样的交换机仍需具备 20 万个端口,显然不可实现。

需要的端口数量相当于这个交换机的 8000 倍 😂
显然单台巨型交换机无法满足需求,这就需要采用分层交换架构(hierarchical switching)。
03 叶脊拓扑结构
无需采用一个巨型交换机连接所有 GPU,我们可以将网络组织为多层级交换机结构:
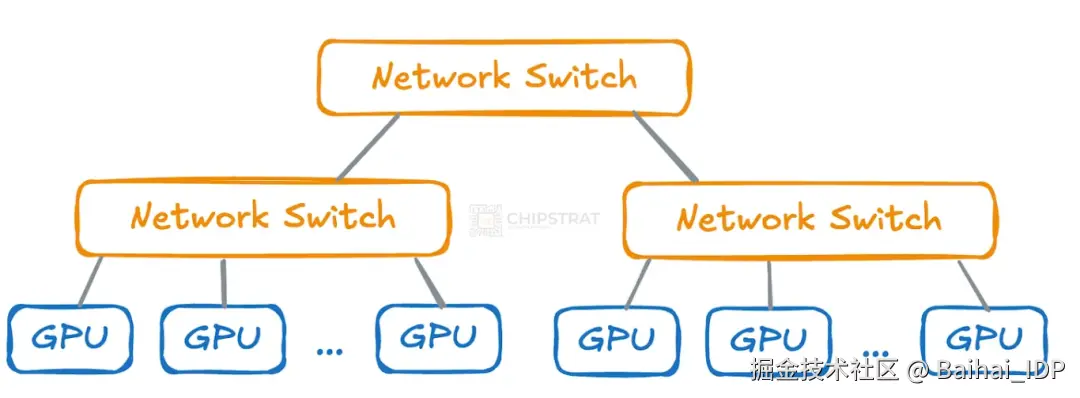
层级结构中的每个交换机只需连接部分 GPU,其尺寸和成本更易管控。
这种方案下,GPU 不再需要成千上万的直连端口,交换机也是如此!
但代价是:当不同分支的 GPU 需要通信时,数据必须经过多个交换机中转,这会增加额外延迟。
举例说明:若两块 GPU 未连接至同一交换机,它们的通信需先上传至高层级的交换机,再下传至目标 GPU 所在的交换机。
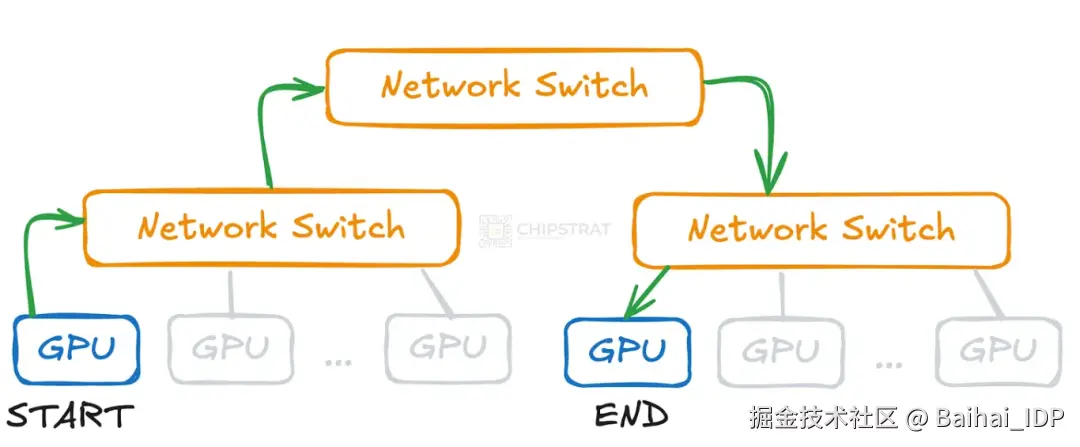
网络跳转会增加数据传输耗时
这种双层架构通常称为叶脊架构或双层 Clos 网络。
叶交换机直接连接计算单元,脊交换机则负责连接叶交换机:
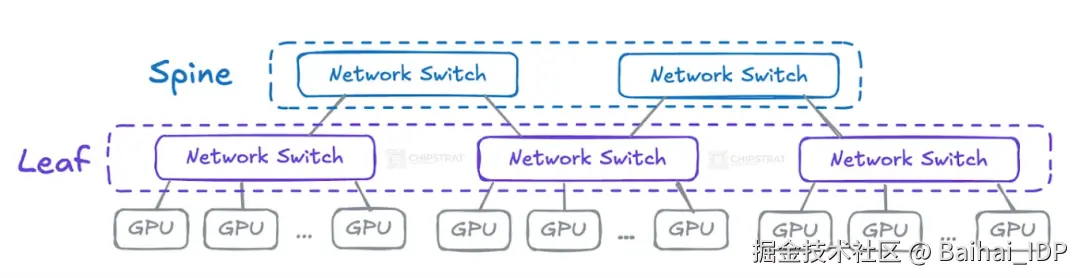
04 横向扩展
如何实现数千块 GPU 的互联?
横向扩展(或称水平扩展)是指通过增加更多 GPU 和网络交换机来扩大集群规模。 这种方式将训练工作负载分摊到更多硬件上,从而缩短大语言模型的训练周期。
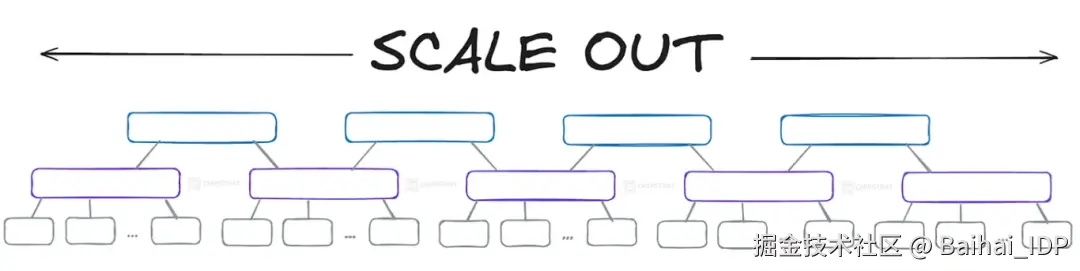
只需不断复制粘贴网络结构......即可实现横向扩展!
这些 GPU 与交换机之间如何通信?横向扩展采用以太网或 InfiniBand 技术,两者都能为 GPU 间通信提供所需的高速网络环境。
InfiniBand 是英伟达的专有技术(通过收购 Mellanox 获得),因其比高性能以太网变体(如 RoCE ------ 基于融合以太网的 RDMA1)具有更低的延迟和更高的带宽,历来被大规模 AI 集群优先选用。

如果您觉得这不像以太网线,那就对了!1.5m (5ft) 英伟达(NVIDIA)/迈络思(Mellanox)MCP4Y10-N01A兼容 800G OSFP NDR InfiniBand 顶部带散热片高速线缆,用于 Quantum-2 交换机。图片来源2
新建的训练集群正越来越倾向于选择以太网。正如黄仁勋在近期英伟达 GTC 主题演讲中所述,埃隆的 xAI 采用英伟达 Spectrum X 以太网构建了全球最大的训练集群(Colossus3)。
05 纵向扩展
横向扩展虽能短期见效,但终究会受到物理定律和经济规律的制约。设备与交换机数量的增加会导致延迟增加、能耗攀升及成本上涨。发展到某个阶段,单纯依靠横向扩展就不再是最优解。
这便引出了另一种方案:纵向扩展(或称垂直扩展)。
纵向扩展是指提升单个节点的算力密度,而非单纯增加节点数量。
叶交换机无需直接连接单块 GPU,而是连接至每台搭载多块 GPU(例如八块)的服务器。此举大大减少了所需直接联网的交换机数量和线缆规模:
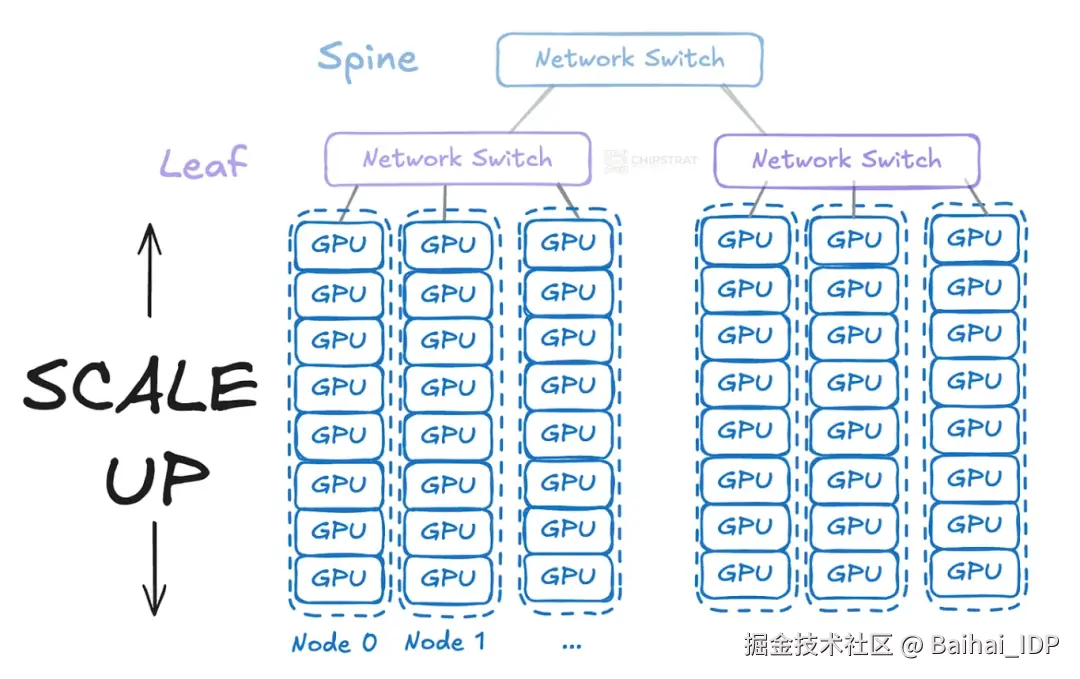
每个服务器节点容纳 8 块 GPU;单台交换机可覆盖更多 GPU
类比早期的网络扩展:快速发展的公司会先通过增加 CPU 核心和内存来升级单台服务器(纵向扩展);当单机性能不足时,再通过添加服务器和负载均衡器分流流量(横向扩展)。
敏锐的读者可能会问:这些纵向扩展的 GPU 如何通信?它们仍需要通过网络交换机连接吗?这与横向扩展有何区别?
问得非常好!
节点内通信 vs 节点间通信
同一服务器节点内的通信称为节点内通信。
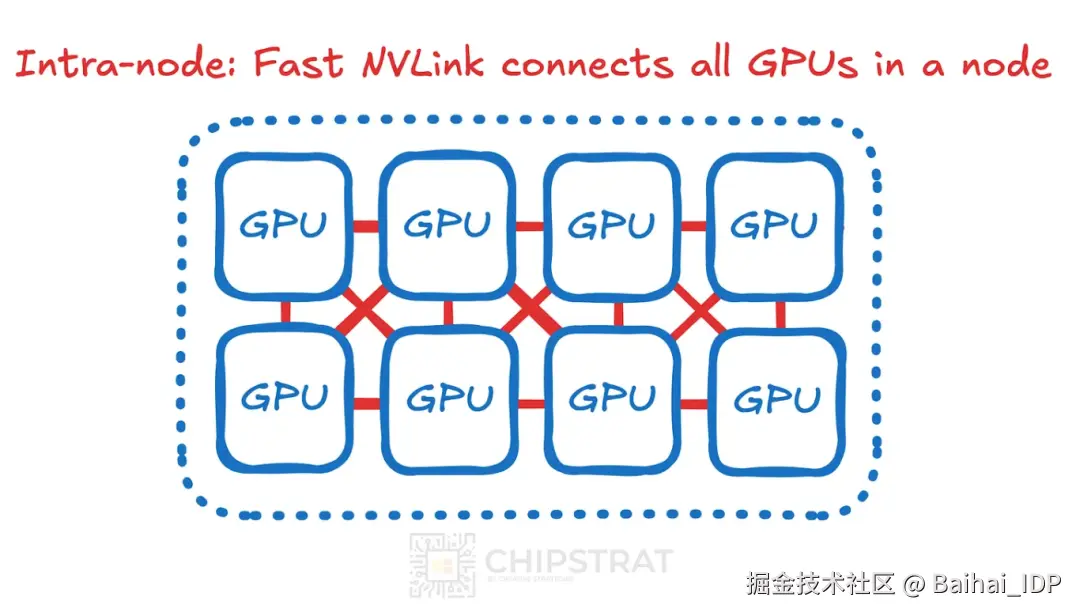
不同服务器间 GPU 的通信称为节点间通信。
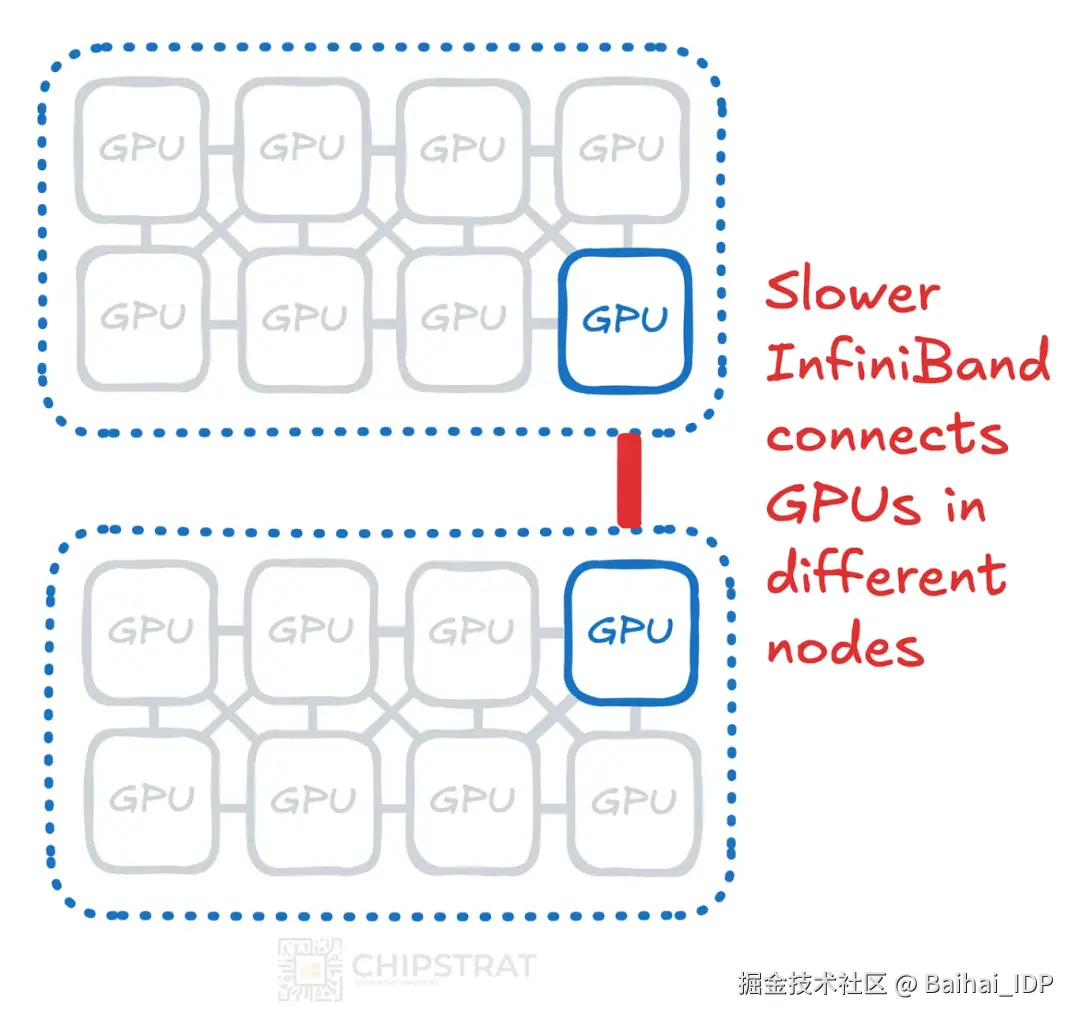
事实证明,相邻 GPU 的节点内通信速度与带宽远胜于使用 Infiniband 或以太网的节点间通信。
为何如此?
这主要归功于 GPU 之间紧密的物理距离以及所采用的专用互连技术。这些技术利用了直接的、短距的且经过优化的信号布线,它们通常直接集成在同一块电路板上或同一个物理封装外壳内,从而缩短信号传输距离并最大限度地降低延迟。
例如 AMD 在 2018 年 IEEE 国际固态电路会议(ISSCC)4公布的 Infinity Fabric 布线方案:

亮色连接线(迹线)表示计算单元间的金属连接,可视为封装基板中的"导线"
由于服务器内 GPU 采用直连方式,可规避大部分节点间通信的开销。封装外壳内布线通过缩短迹线长度、减少传播延迟和信号衰减来提升效率。
而 Infiniband 与以太网等外部连接需依赖中继器、重定时器、纠错机制等信号完整性保障组件来保障远距离传输的可靠性,这些都会增加额外的延迟和功耗。
不妨将 NVLink、InfinityFabric 等节点内通信比作德国高速公路5:专为高速内无中断的通行设计。
节点间通信则像双车道公路:速度更慢、通行量有限,还可能因春耕秋收的拖拉机导致降速(即应对拥堵)。

注意,前方可能有交警蹲守!
06 训练中的通信环节
理解神经网络如何训练,有助于我们了解其中的通信挑战。
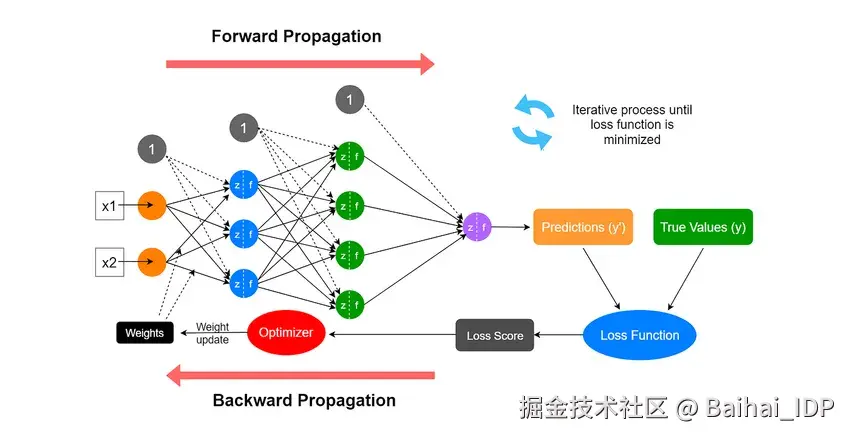
在每个训练周期中,网络首先执行前向传播:输入数据流经网络各层生成预测结果。随后通过损失函数将预测值与正确答案对比,量化误差幅度。
学习的核心发生在反向传播阶段。通过反向传播算法,系统计算网络中每个权重对误差的贡献程度。利用这些信息,梯度下降算法会沿着减少误差的方向调整所有权重 ------ 这本质上就如同转动数十亿个"旋钮",逐步提升网络的预测精度。每次迭代中的细微调整,都让神经网络在新数据上的预测更趋可靠。
Source:www.researchgate.net/figure/The-...
每块 GPU 根据前向传播的误差计算权重更新的梯度,但由于各 GPU 处理不同的数据子集,这些梯度仅是局部结果。为确保所有 GPU 应用相同的参数更新并保持同步,必须跨所有 GPU 对梯度进行聚合与求平均。
这个过程称为全归约通信(all-reduce communication),它使得各 GPU 在更新本地模型前能够交换并分发最终计算值。通过维持全局一致性,该机制可避免模型漂移,确保分布式训练的有效性。
全归约通信的延迟直接影响训练效率。
此外还存在其他集合通信操作,例如英伟达 NCCL 软件库6支持的:全归约(AllReduce)、广播(Broadcast)、归约(Reduce)、全聚合(AllGather)、散射规约(ReduceScatter)。
因此理想情况下,训练集群需采用最高带宽和最低延迟的通信方案。
正如我们在 DeepSeek V3 中所见7,还可通过软件方法实现通信与计算的重叠执行,减少 GPU 空闲时间,降低通信限制的影响。
07 Conclusion
本文的第一部分到此结束。当然还有更多内容可以探讨。实际的大规模集群并非全互联结构,其架构要复杂得多。
Source:www.youtube.com/watch?v=wLW...
该系列文章后续还将涵盖推理的通信需求(及其与训练的差异)、前端网络与后端网络、光通信等主题。
但希望目前的内容已足以让您在看到技术图表(例如英伟达 SuperPOD 计算架构图8)时,能建立基础的认知框架,并通过提问填补知识空白:
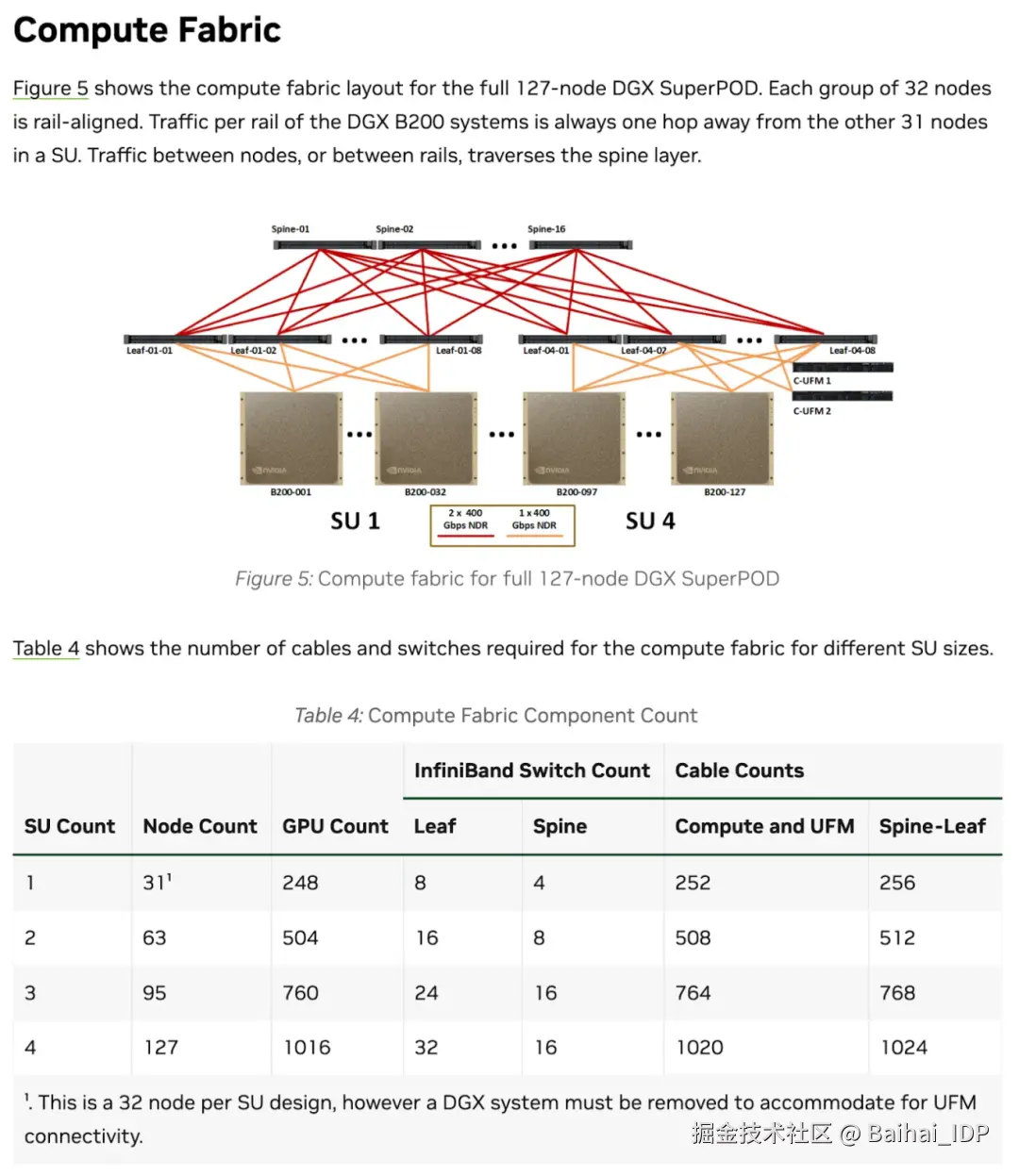
上图中可以看到脊交换机和叶交换机助力实现横向扩展,而 B200 服务器则体现了纵向扩展。
从表格数据可知,每个可扩展单元包含 32 个节点,每个节点配备 8 块 GPU。这正是横向扩展(32 节点)与纵向扩展(单节点 8 GPU)的结合。不必纠结"移除 DGX 以适配 UFM 连接"这类细节 ------ 关键是你现在已经能理解整体框架了!
END
本期互动内容 🍻
❓你觉得在未来,是算力会先遇到天花板,还是网络通信会先成为 AI 发展的最大瓶颈?
文中链接
1techdocs.broadcom.com/us/en/stora...
4ieeexplore.ieee.org/xpl/conhome...
5www.german-way.com/travel-and-...
6docs.nvidia.com/deeplearnin...
7www.chipstrat.com/i/158842573...
8docs.nvidia.com/dgx-superpo...
本文经原作者授权,由 Baihai IDP 编译。如需转载译文,请联系获取授权。
原文链接: