一、为什么要学习K8S
Kubernetes 为你提供了一个可弹性运行分布式系统的框架。 Kubernetes 会满足你的扩展要求、故障转移你的应用、提供部署模式等。
负载均衡
自动部署和回滚
自我修复
**二、**架构图
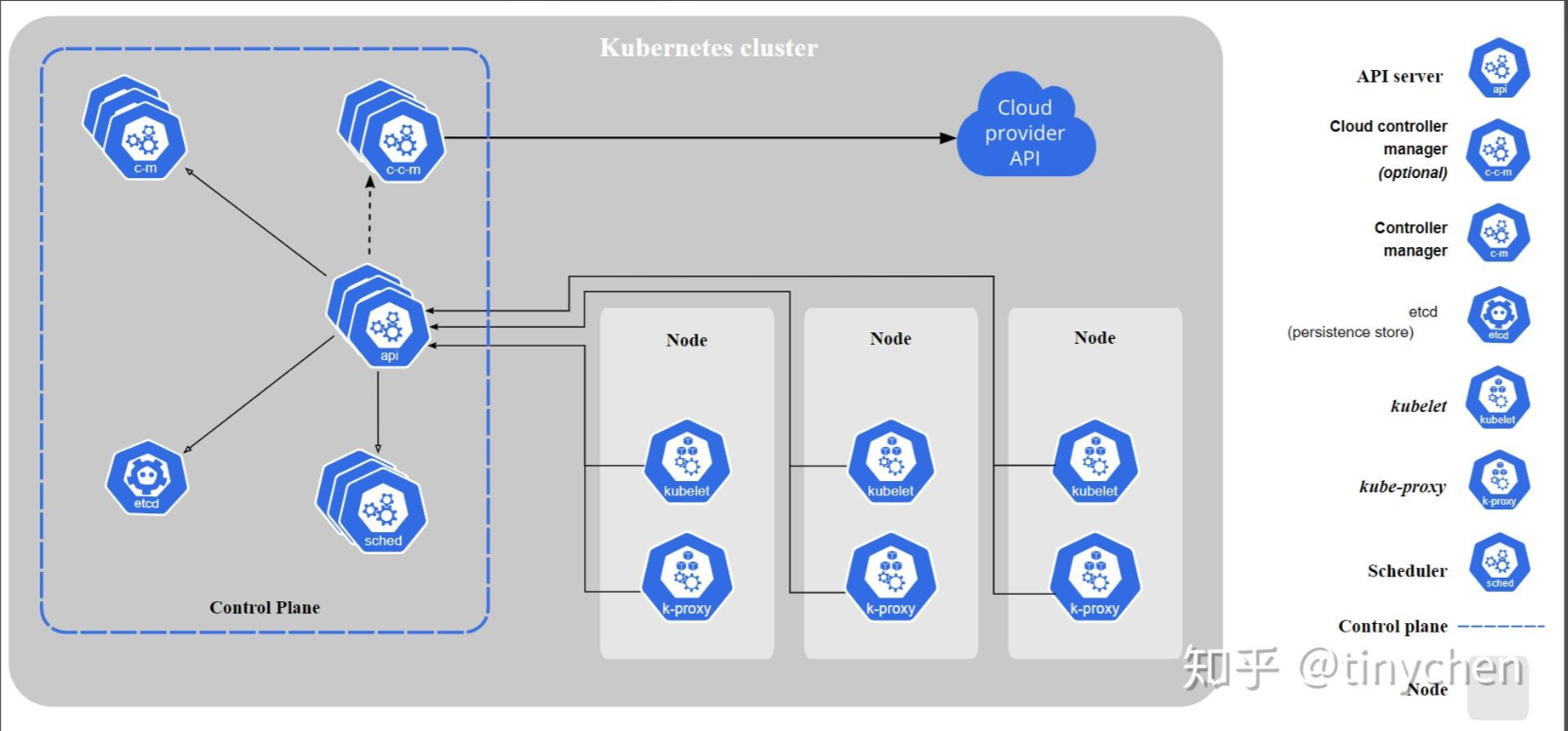
三、如何搭建K8S集群
3.1安装K8S
|----|---------|-----------------|
| 序号 | 节点名称 | IP |
| 1 | master1 | 192.168.200.131 |
| 2 | worker1 | 192.168.200.132 |
| 3 | worker2 | 192.168.200.133 |
bash
# 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
# 第一步:安装ntp服务
yum -y install ntp
# 第二步:开启开机启动服务
systemctl enable ntpd
# 第三步:启动服务
systemctl start ntpd
# 第四步:更改时区
timedatectl set-timezone Asia/Shanghai
# 第五步:启用ntp同步
timedatectl set-ntp yes
# 第六步:同步时间
ntpq -p
# 移除之前版本
sudo yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
# 配置镜像源
sudo yum install -y yum-utils
sudo yum-config-manager \
--add-repo \
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 指定版本安装 docker
yum install -y docker-ce-20.10.7 docker-ce-cli-20.10.7 containerd.io-1.4.6
# 查看 docker 版本
[root@localhost ~]# docker -v
Docker version 20.10.7, build f0df350
# 设置开机自启并启动
systemctl enable docker --now
# 设置镜像加速器
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": [
"https://docker.m.daocloud.io",
"https://docker.1ms.run",
"https://ccr.ccs.tencentyun.com",
"https://hub.xdark.top",
"https://hub.fast360.xyz",
"https://docker-0.unsee.tech",
"https://docker.xuanyuan.me",
"https://docker.tbedu.top",
"https://docker.hlmirror.com",
"https://doublezonline.cloud",
"https://docker.melikeme.cn",
"https://image.cloudlayer.icu",
"https://dislabaiot.xyz",
"https://freeno.xyz",
"https://docker.kejilion.pro"
],
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker3.2 配置三台机器主机名
hostnamectl set-hostname k8s-master
hostnamectl set-hostname k8s-worker1
hostnamectl set-hostname k8s-worker2
3.3 配置预备环境
bash
# 在各个机器上都要设置
# 将 SELinux 设置为 permissive 模式
•enforcing:强制模式,代表 SELinux 运作中,且已经正确的开始限制 domain/type 了;
•permissive:宽容模式:代表 SELinux 运作中,不过仅会有警告讯息并不会实际限制 domain/type 的存取。这种模式可以运来作为 SELinux 的 debug 之用;
•disabled:关闭,SELinux 并没有实际运作。
sudo setenforce 0
sudo sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
#关闭swap 占用
swapoff -a
sed -ri 's/.*swap.*/#&/' /etc/fstab
# 可以使用命令查看是否关闭swap分区
free -m
#允许 iptables 检查桥接流量,也能统计Ip6的数据流量
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
br_netfilter
EOF
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
# 使配置生效
sudo sysctl --system3.4 安装kubelet、kubeadm、kubectl
bash
#配置k8s的yum源地址
cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
#安装 kubelet,kubeadm,kubectl
sudo yum install -y kubelet-1.20.9 kubeadm-1.20.9 kubectl-1.20.9
#启动kubelet
sudo systemctl enable kubelet
sudo systemctl start kubelet
sudo systemctl status kubelet3.5 所有机器,配置域名映射
bash
#所有机器添加master域名映射,以下需要修改为自己的,IP:主节点的IP
echo "192.168.200.131 k8s-master" >> /etc/hosts
# 修改每台主机的hosts 将每个服务器都要写上 master worker1 worker2
vi /etc/hosts
192.168.200.131 k8s-master
192.168.200.132 k8s-worker1
192.168.200.133 k8s-worker2
# 如果添加成功 使用 ping k8s-master 能 ping 通
[root@bogon ~]# ping k8s-master
PING cluster-endpoint (192.168.200.181) 56(84) bytes of data.
64 bytes from cluster-endpoint (192.168.200.181): icmp_seq=1 ttl=64 time=0.584 ms
64 bytes from cluster-endpoint (192.168.200.181): icmp_seq=2 ttl=64 time=0.422 ms
# 上传镜像,并运行对应的shell 脚本,完成镜像导入!3.6 主节点初始化
bash
# 主节点初始化
# --image-repository 使用阿里云的镜像仓库
# 192.168.200.131 : 主节点的IP
# k8s-cluster : 跟3.5步骤的域名映射一致
# 192.168.0.0 : 网络插件IP,如果你的电脑网段是192.168.xxx.xxx,那么这个IP需要更换
kubeadm init \
--apiserver-advertise-address=192.168.200.131 \
--control-plane-endpoint=k8s-master \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.20.9 \
--service-cidr=10.96.0.0/16 \
--pod-network-cidr=172.32.0.0/16
# 命令注释:
# 这是一个用于初始化Kubernetes集群的命令,具体参数的含义如下:
--apiserver-advertise-address: 指定API服务器的公网IP地址。
--control-plane-endpoint: 指定控制平面节点的域名或IP地址。
--image-repository: 指定镜像仓库的地址。
--kubernetes-version: 指定要安装的Kubernetes版本。
--service-cidr: 指定服务网络的CIDR块,定义kubernetes服务的虚拟IP地址段,所有Service的ClusterIP将从该网段分配。
--pod-network-cidr: 指定Pod网络的CIDR块,定义Pod所在的网络地址,需与后续部署的网络查看配置的网段一致,否则Pod之间无法通信。
#所有网络范围不重叠
# 常见问题: /proc/sys/net/ipv4/ip_forward contents are not set to 1z
# 将master节点-work节点都执行
echo "1" > /proc/sys/net/ipv4/ip_forward
# 常见问题: modprobe: FATAL: Module nf_conntrack_ipv4 not found
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- br_netfilter
EOF
# 所有网络范围不重叠
# 操作成功日志(保存好日志)
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join k8s-cluster:6443 --token llqz9p.qbgs9kmckdv3bem4 \
--discovery-token-ca-cert-hash sha256:7d486d205dbe6c7a7463c5c4954dcb36afd092befcbd480b9b1bf92199081948 \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join k8s-cluster:6443 --token llqz9p.qbgs9kmckdv3bem4 \
--discovery-token-ca-cert-hash sha256:7d486d205dbe6c7a7463c5c4954dcb36afd092befcbd480b9b1bf92199081948 保存好上面的启动成功的日志
3.7 部署网络插件
bash
curl https://docs.projectcalico.org/v3.20/manifests/calico.yaml -O
# 注意,主节点初始时,如果修改 --pod-network-cidr=192.168.0.0/16
# 原有配置是注释掉的 3888 3889
# - name: CALICO_IPV4POOL_CIDR
# value: "192.168.0.0/16"
# calico.yaml ip 也需要修改
- name: CALICO_IPV4POOL_CIDR
value: "172.32.0.0/16"
#应用这个配置文件
kubectl apply -f calico.yaml3.8 创建worker节点
使用上面保存的日志(不要用我的,连不上的)
bash
kubeadm join k8s-cluster:6443 --token llqz9p.qbgs9kmckdv3bem4 \
--discovery-token-ca-cert-hash sha256:7d486d205dbe6c7a7463c5c4954dcb36afd092befcbd480b9b1bf92199081948 问题解决:
bash
# 如果出现这个错误,解决方案
[ERROR DirAvailable--etc-kubernetes-manifests]: /etc/kubernetes/manifests is not empty
[ERROR FileAvailable--etc-kubernetes-kubelet.conf]: /etc/kubernetes/kubelet.conf already exists
[ERROR Port-10250]: Port 10250 is in use
[ERROR FileAvailable--etc-kubernetes-pki-ca.crt]: /etc/kubernetes/pki/ca.crt already exists
kubeadm reset令牌过期:
bash
[root@localhost ~]# kubeadm token create --print-join-command
kubeadm join cluster-kubendpoint:6443 --token k3z6hm.7dptca591imod2mn --discovery-token-ca-cert-hash sha256:d66cffb305f0274c9984ef1fe1447245655d3094922cbcb61dbd64ada619455f 3.9 验证集群状态
bash
[root@k8s-master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane,master 104m v1.20.9
k8s-worker1 Ready <none> 101m v1.20.9
k8s-worker2 Ready <none> 101m v1.20.9
bash
kubectl get node # 查询节点状态
kubectl get pod -A #查询K8S部署的所有pod
kubectl get pod -A -o wide #打印详细信息,查看pod在哪个节点部署
kubectl apply -f 部署文件.yaml # 向K8S中部署资源
kubectl version # K8S版本3.10 部署k8s的可视化界面(deshboard)
在浏览器访问:
https://raw.githubusercontent.com/kubernetes/dashboard/v2.3.1/aio/deploy/recommended.yaml
vi recommended.yaml #复制粘贴上述配置文件
bash
将配置文件中的这两个镜像
image: kubernetesui/dashboard:v2.3.1
image: kubernetesui/metrics-scraper:v1.0.6
替换为下面的两个
image: registry.cn-hangzhou.aliyuncs.com/google_containers/dashboard:v2.3.1
image: registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-scraper:v1.0.6kubectl apply -f recommended.yaml
修改服务网络 root@localhost \~# kubectl edit svc kubernetes-
bash
# 修改服务网络
[root@localhost ~]# kubectl edit svc kubernetes-dashboard -n kubernetes-dashboard
# 文件第29行 type: ClusterIP 改为 type: NodePort
# 查询对外暴露的端口
[root@localhost ~]# kubectl get svc -A |grep kubernetes-dashboard
kubernetes-dashboard dashboard-metrics-scraper ClusterIP 10.96.22.70 <none> 8000/TCP 31m
kubernetes-dashboard kubernetes-dashboard NodePort 10.96.61.107 <none> 443:30282/TCP 31m记住这里的443:30282/TCP,咱们肯定不一样
测试访问:
https://192.168.200.131:30282 #端口改为上面的端口号
创建访问账号 才能访问
bash
#创建访问账号,准备一个yaml文件; vi dash-user.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard·应用文件
bash
kubectl apply -f dash-user.yaml获取令牌
bash
#获取访问令牌
kubectl -n kubernetes-dashboard get secret $(kubectl -n kubernetes-dashboard get sa/admin-user -o jsonpath="{.secrets[0].name}") -o go-template="{{.data.token | base64decode}}"将令牌粘贴到输入框中点击登录
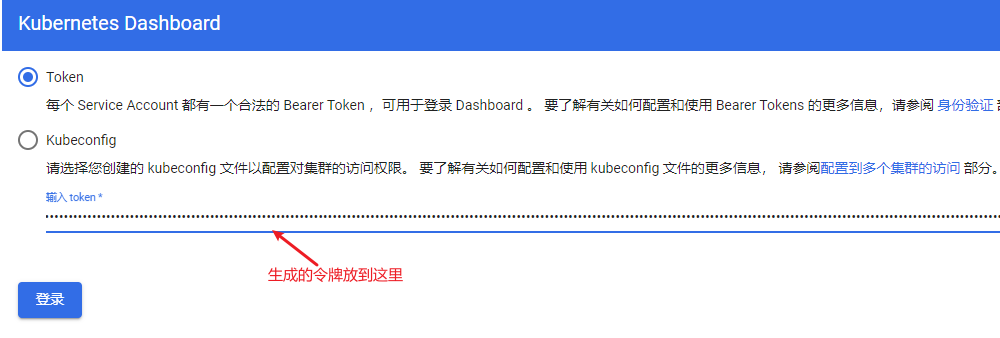
登录后界面
bash
开机自启动:
systemctl enable kubelet
systemctl enable docker
systemctl disable firewalld核心实战
4.1 资源创建方式
在Kubernetes(k8s)中,所有的内容都被抽象为资源,用户通过操作这些资源来管理Kubernetes集群。
- Pod资源
- Service资源
- Volume资源
4.1.1 命令行
使用以下语法从终端窗口运行 kubectl 命令:
bash
kubectl [command] [TYPE] [NAME] [flags]其中 command、 TYPE、 NAME 和 flags 分别是:
- command:指定要对一个或多个资源执行的操作 ,例如 create、get、describe、delete。
- TYPE:指定资源类型。资源类型不区分大小写, 可以指定单数、复数或缩写形式。
- NAME:指定资源的名称 。名称区分大小写。 如果省略名称,则显示所有资源的详细信息。例如:kubectl get pods。
- flags: 指定可选的参数。例如,使用 -s 或 --server 参数指定 Kubernetes API 服务器的地址和端口。
常用命令
bash
# 创建 命名空间
kubectl create ns dev
# 创建 Nginx 服务器
kubectl run pod --image=nginx -n dev
# 查询default命名空间中pod
kubectl get pod
# 查询所有命名空间中pod
kubectl get pod -A
# 查询指定命名空间中pod
kubectl get pod -n dev
# 删除 pod
kubectl delete pod pod -n dev 4.1.2 YAML
bash
# 创建YAML文件
vim nginx.yaml
# 编辑文件
apiVersion: v1
kind: Namespace
metadata:
name: dev
---
apiVersion: v1
kind: Pod
metadata:
name: mynginx
namespace: dev
spec:
containers:
- name: nginx-containers
image: nginx
# 创建 pod
kubectl apply -f nginx.yaml
# 删除 pod
kubectl delete -f nginx.yaml 4.2 Namespace
Namespace是K8S中的一种非常重要资源,它的主要作用是用来实现 资源隔离。可以隔离不同用户、项目或环境之间的资源,以确保资源的合理使用和安全性。Namespace可以用于区分不同的用户、租户、环境和项目,以便更好地管理集群资源。在创建pod时,可以指定pod到特定的Namespace。
K8S提供了几个默认的Namespace,例如default、kube-system和kube-public。default命名空间用于未指定Namespace的对象,kube-system主要用于运行系统级资源,存放Kubernetes一些组件的。
命令方式操作命名空间
bash
kubectl get ns
kubectl create ns hello
kubectl delete ns helloYAML方式操作命令空间
bash
# 创建YAML文件
vim ns-dev.yaml
# 编辑文件
apiVersion: v1 # 版本信息
kind: Namespace # 资源类型
metadata: # 元数据的意思
name: dev
# 创建命名空间
kubectl apply -f ns-dev.yaml
# 删除命名空间
kubectl delete -f ns-dev.yaml 注意:删除命名空间时,该命名空间下的所有资源都会被删除
4.3 Pod
Pod 是可以在 K8S中创建和管理的、最小的可部署的计算单元。我们可以理解Pod就是容器的封装,一个Pod中可以有 多个容器。
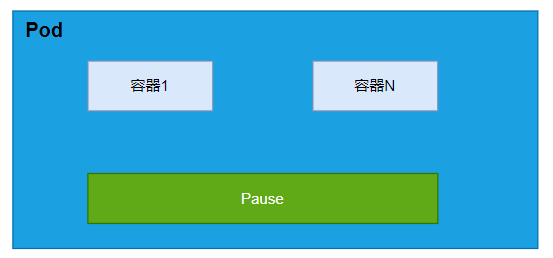
4.3.1 Pod基本操作
bash
# 创建 Pod
kubectl run mynginx --image=nginx
# 查看default名称空间的Pod ,指定-A属性查询所有名称空间下的Pod
kubectl get pod
# 描述
kubectl describe pod 你自己的Pod名字
# 删除
kubectl delete pod Pod名字
# 查看Pod的运行日志
kubectl logs Pod名字
# 每个Pod - k8s都会分配一个ip
kubectl get pod -owide集群中的任意一个机器以及任意的应用都能通过Pod分配的IP来访问这个Pod,截止目前,我们创建的Pod还不能外部访问
4.3.2 创建多容器Pod
创建单容器Yaml示例
bash
# 单个容器描述文件 vi mynginx.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: mynginx
name: mynginx
# namespace: default
spec:
containers:
- image: nginx
name: mynginx创建多容器Yaml示例
bash
apiVersion: v1
kind: Pod
metadata:
labels:
run: myapp
name: myapp
spec:
containers:
- image: nginx
name: nginx
- image: tomcat:8.5.68
name: tomcat使用命令查看会发现有两个容器被创建
root@k8s-master \~# kubectl describe pod myapp
4.3.3 Pod内部原理
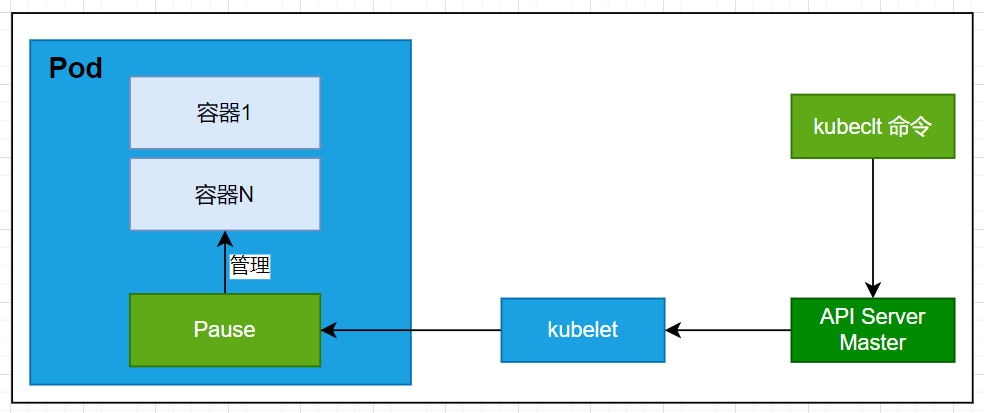
4.3.4 Pod自我恢复演示
了解 ,其实我们通过停止或者删除的方式模拟容器崩溃,K8S会帮我们修复容器
4.3.5 Pod资源配置
容器中的程序在运行时需要占用一定的资源,如CPU和内存等。如果不限制某个容器的资源使用,它可能会消耗大量的资源,导致其他容器无法正常运行。为了解决这个问题,Kubernetes提供了资源配额机制,主要通过"resources"选项来实现。该机制包含两个子选项:
- limits:用于限制容器运行时的最大资源占用。当容器的资源使用超过这个限制时,容器将被终止并重新启动。
- requests:用于设置容器所需的最小资源。如果环境中提供的资源不足,容器将无法启动。
bash
apiVersion: v1
kind: Pod
metadata:
name: pod-test
spec:
containers:
- name: nginx
image: nginx
resources: # 资源配额
limits: # 限制上限
cpu: "1"
memory: "1Gi"
requests: # 限制下限
cpu: "1"
memory: "100Mi" 4.4 Deployment
Deployment代表执行一次部署, 可以部署多个pod 、 控制Pod,使Pod拥有多副本、自愈、扩缩容等能力
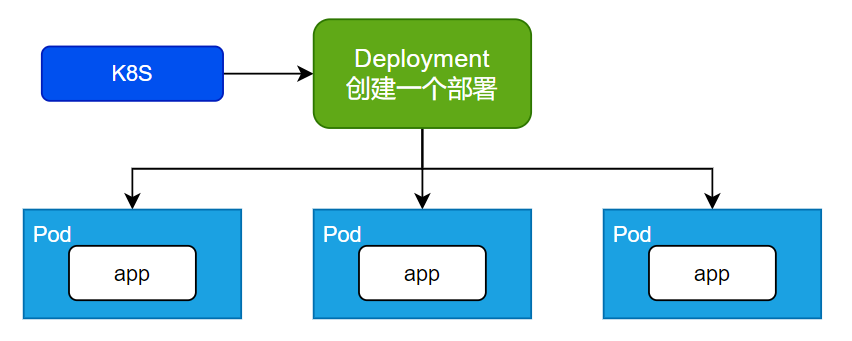
4.4.1 常规操作
bash
# 创建一次部署
kubectl create deployment mytomcat --image=tomcat:8.5.68
# 创建一个3个副本的部署
kubectl create deployment my-dep --image=nginx --replicas=3
# 获取部署信息
kubectl get deployment
kubectl get deploy
# 删除部署
kubectl delete deployment mytomcatYaml创建部署
vi mynginxapp.yaml
bash
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: mynginx
name: mynginxapp
spec:
replicas: 1
selector:
matchLabels:
app: mynginx
template:
metadata:
labels:
app: mynginx
spec:
containers:
- image: nginx
name: nginx4.4.2 自愈&故障转移
自愈是指k8s帮我们修复应用,比如我们pod内部容器,宕机了,这时候k8s感知到会尝试重启。
故障转移,是指我们k8s集群可能有一台机器宕机了,这个时候,k8s帮我们把宕机节点应用重新部署到其他worker节点上。
bash
# 演示pod、deployment 区别
# deployment 部署一个tomcat
kubectl create deployment mytomcat1 --image=tomcat:8.5.68
# pod
kubectl run mynginx --image=nginx
[root@k8s-master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
mynginx 1/1 Running 0 34s
mytomcat1-7c9898f454-pl9kz 1/1 Running 0 3m59s
kubectl delete pod mynginx
kubectl delete pod mytomcat1-7c9898f454-pl9kz
4.4.3 多副本
bash
kubectl create deployment my-dep --image=nginx --replicas=3
# 通过yaml文件可以指定多副本
replicas: 3
# 监控pod -删除一个pod的时候,会自动创建一个pod
watch -n 1 kubectl get pod4.4.4 扩缩容pod
kubectl scale --replicas=5 deployment/my-dep
4.4.5 滚动更新
灰度发布:
bash
kubectl set image deployment/my-dep nginx=nginx:1.16.1 --record
kubectl rollout status deployment/my-dep4.4.6 版本回退
bash
#历史记录
kubectl rollout history deployment/my-dep
#查看某个历史详情
kubectl rollout history deployment/my-dep --revision=2
#回滚(回到上次)
kubectl rollout undo deployment/my-dep
#回滚(回到指定版本)
kubectl rollout undo deployment/my-dep --to-revision=24.5 Service
在Kubernetes中,Pod是运行应用程序的容器,然而,由于Pod的 IP地址是动态分配的,因此直接使用Pod的IP地址进行服务访问并不方便。为了解决这个问题,Kubernetes引入了Service资源。
Service资源可以聚合提供相同服务的多个Pod,并为它们提供一个统一的入口地址。这样,通过访问Service的入口地址,就可以访问到后台的Pod服务,而无需关心每个Pod的IP地址的变化。这使得服务的访问更加稳定和可靠,同时也提供了更好的可扩展性,因为可以轻松地增加或减少提供服务的Pod数量。
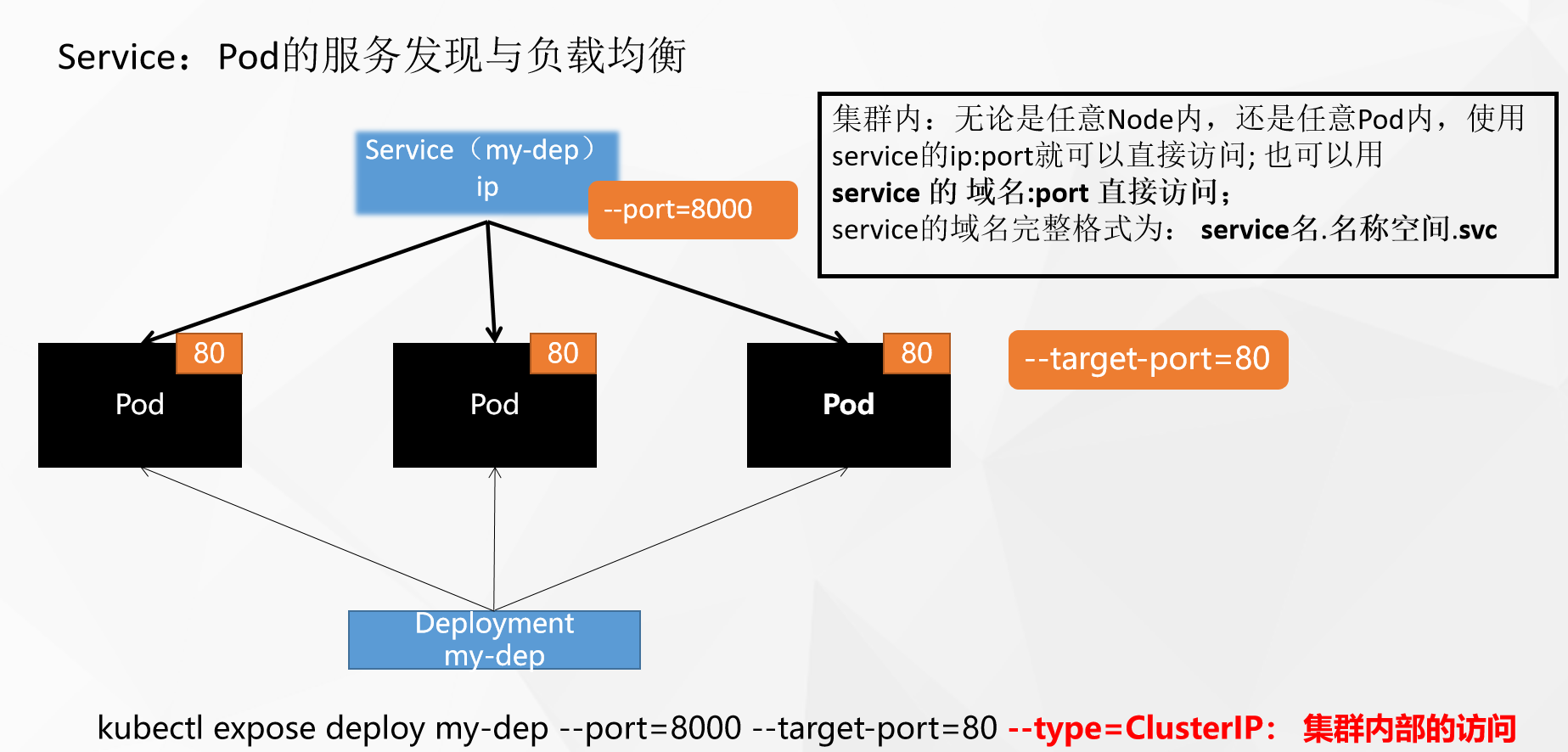
4.5.1 ClusterIP
bash
# 等同于没有--type的
kubectl expose deployment my-dep --port=8000 --target-port=80 --type=ClusterIP
# 查看创建的service
kubectl get svc
# 访问
curl 10.96.226.54:8000 #ip为service的ip 能够看到负载均衡效果了
curl my-dep.default.svc:8000 # 必须在pod中访问!
# 部署一个tomat服务,在它的内部访问nginx
curl 10.96.226.54:8000
# Yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: my-dep
name: my-dep
spec:
ports:
- port: 8000
protocol: TCP
targetPort: 80
selector:
app: my-dep
type: ClusterIP4.5.2 NodePort
暴露服务,集群外部可以访问,NodePort范围在 30000-32767 之间
bash
# 暴露服务
kubectl expose deployment my-dep --port=8000 --target-port=80 --type=NodePort
#Yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: my-dep
name: my-dep
spec:
ports:
- port: 8000
nodeport: 30088 #指定绑定的node的端口
targetPort: 80
selector:
app: my-dep
type: NodePort
bash
[root@k8s-master ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 46h
my-dep NodePort 10.96.226.54 <none> 8000:32615/TCP 33m
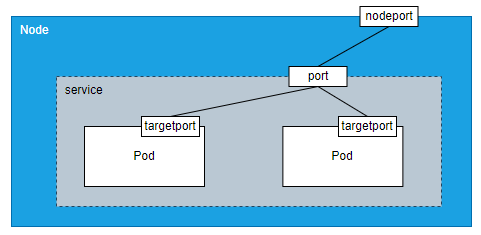
浏览器访问:192.168.200.131:32615port、targetPort、nodeport区别
node: 服务器
nodeport: node节点的端口
port: service的端口
taggetport:容器的端口
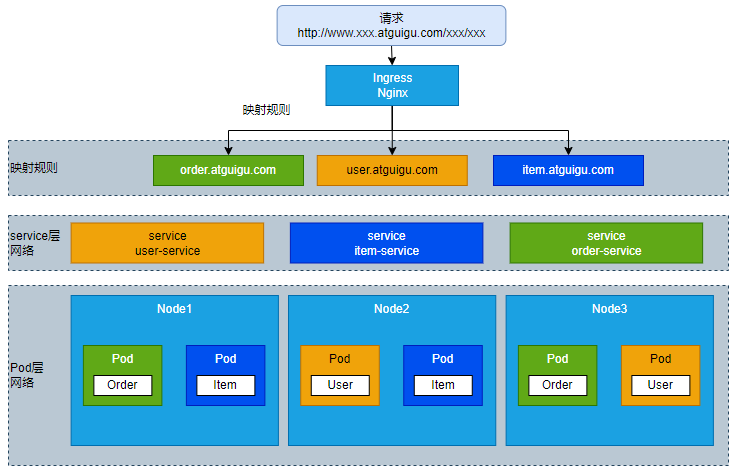
4.6 Ingress
Ingress是一个资源类型,用于实现用域名的方式访问K8S集群内部的应用。类似微服务的网关功能,提供请求路由、流量控制等功能
API: https://kubernetes.github.io/ingress-nginx/
4.6.1 Ingress安装
参考资料Yaml中ingress.yaml
bash
[root@k8s-master ~]# kubectl apply -f ingress.yaml
namespace/ingress-nginx created
serviceaccount/ingress-nginx created
configmap/ingress-nginx-controller created
clusterrole.rbac.authorization.k8s.io/ingress-nginx created
clusterrolebinding.rbac.authorization.k8s.io/ingress-nginx created
role.rbac.authorization.k8s.io/ingress-nginx created
rolebinding.rbac.authorization.k8s.io/ingress-nginx created
service/ingress-nginx-controller-admission created
service/ingress-nginx-controller created
deployment.apps/ingress-nginx-controller created
validatingwebhookconfiguration.admissionregistration.k8s.io/ingress-nginx-admission created
serviceaccount/ingress-nginx-admission created
clusterrole.rbac.authorization.k8s.io/ingress-nginx-admission created
clusterrolebinding.rbac.authorization.k8s.io/ingress-nginx-admission created
role.rbac.authorization.k8s.io/ingress-nginx-admission created
rolebinding.rbac.authorization.k8s.io/ingress-nginx-admission created
job.batch/ingress-nginx-admission-create created
job.batch/ingress-nginx-admission-patch created
# 查询是否安装成功
[root@k8s-master ~]# kubectl get svc -A
NAME TYPE CLUSTER-IP PORT(S)
kubernetes ClusterIP 10.96.0.1 443/TCP
ingress-nginx-controller NodePort 10.96.255.50 80:32653/TCP,443:31308/TCP
ingress-nginx-controller-admission ClusterIP 10.96.95.128 443/TCP
kube-dns ClusterIP 10.96.0.10 53/UDP,53/TCP,9153/TCP 4.6.2 测试案例
创建命令空间
bash
apiVersion: v1
kind: Namespace
metadata:
name: dev创建服务
vim ingress-demo.yaml
bash
# Order 服务部署
apiVersion: apps/v1
kind: Deployment
metadata:
name: order-deployment
namespace: dev
spec:
replicas: 2
selector:
matchLabels:
app: order
template:
metadata:
labels:
app: order
spec:
containers:
- image: nginx
name: nginx
---
# User服务部署
apiVersion: apps/v1
kind: Deployment
metadata:
name: user-deployment
namespace: dev
spec:
replicas: 2
selector:
matchLabels:
app: user
template:
metadata:
labels:
app: user
spec:
containers:
- image: nginx
name: nginx
---
# Item服务部署
apiVersion: apps/v1
kind: Deployment
metadata:
name: item-deployment
namespace: dev
spec:
replicas: 2
selector:
matchLabels:
app: item
template:
metadata:
labels:
app: item
spec:
containers:
- image: nginx
name: nginx
---
apiVersion: v1
kind: Service
metadata:
name: order-service
namespace: dev
spec:
selector:
app: order
type: ClusterIP
ports:
- port: 8201
targetPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: user-service
namespace: dev
spec:
selector:
app: user
type: ClusterIP
ports:
- port: 8202
targetPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: item-service
namespace: dev
spec:
selector:
app: item
type: ClusterIP
ports:
- port: 8203
targetPort: 804.6.3 域名访问
vi ingress-rule.yaml
bash
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-domain
namespace: dev
spec:
ingressClassName: nginx
rules:
- host: "order.llyb.com"
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: order-service
port:
number: 8201
- host: "user.llyb.com"
http:
paths:
- pathType: Prefix
path: "/" # 把请求会转给下面的服务,下面的服务一定要能处理这个路径,不能处理就是404
backend:
service:
name: user-service
port:
number: 8202
- host: "item.llyb.com"
http:
paths:
- pathType: Prefix
path: "/" # 把请求会转给下面的服务,下面的服务一定要能处理这个路径,不能处理就是404
backend:
service:
name: item-service
port:
number: 8203kubectl get pods -A
item1 :kubectl exec -it item-deployment-fd5ddbd57-4nbkd /bin/bash -n dev
item2: kubectl exec -it item-deployment-fd5ddbd57-6zkjn /bin/bash -n dev
echo 'item1' > /usr/share/nginx/html/index.html
echo 'item2' > /usr/share/nginx/html/index.html
echo 'order1' > /usr/share/nginx/html/index.html
echo 'order2' > /usr/share/nginx/html/index.html
echo 'user1' > /usr/share/nginx/html/index.html
echo 'user2' > /usr/share/nginx/html/index.html
配置host文件
C:\Windows\System32\drivers\etc
192.168.200.131 order.llyb.com user.llyb.com item.llyb.com
测试
访问不同的域名,进入不同的服务,并且支持负载均衡
端口号通过 kubectl get svc -A 找ingress-nginx-controller 服务80对应的端口号
item.llyb .com:32592 就会出现item1 或item2
4.6.4 路径重写
Ingress 路径重写是指在 Kubernetes 的 Ingress 资源中,通过修改或映射原始的路径,使其指向一个特定的服务。路径重写可以帮助您自定义 URL 结构,使其更具有可读性、可维护性和搜索引擎优化(SEO)友好性。
在 Ingress 资源中,您可以使用 rules 字段来定义路径重写规则。每个规则都包含一个主机和一组路径,这些路径将根据特定的规则映射到后端服务。
示例代码
vi ingress-rule.yaml
http://item.llyb.com:32592/api/hello
@GetMapping("hello")
bash
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
# nginx的ingress控制器使用这个注解来修改URL重写规则,会将请求路径中的第二个斜杠及其后面的部分重写到目标路径的开始位置
nginx.ingress.kubernetes.io/rewrite-target: /$2
name: ingress-rewrite
namespace: dev
spec:
ingressClassName: nginx
rules:
- host: "item.llyb.com"
http:
paths:
- pathType: Prefix
path: "/api(/|$)(.*)"
backend:
service:
name: item-service
port:
number: 82034.6.5 流量控制
Ingress流量控制是K8S集群中用于保护后端服务的重要技术之一。通过合理配置Ingress流量控制,您可以确保服务的稳定性和可用性,并避免过载或拒绝服务攻击。
bash
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
# 限制每秒只允许一个请求访问
nginx.ingress.kubernetes.io/limit-rps: "1"
name: ingress-rps
namespace: dev
spec:
ingressClassName: nginx
rules:
- host: "index.llyb.com"
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: item-service
port:
number: 82034.7 Storage
容器中的文件在磁盘上是临时存放的,这给在容器中运行较重要的应用带来一些问题。 当容器崩溃或停止时会出现一个问题。此时容器状态未保存, 因此在容器生命周期内创建或修改的所有文件都将丢失。 在崩溃期间,kubelet 会以干净的状态重新启动容器。 当多个容器在一个 Pod 中运行并且需要共享文件时,会出现另一个问题。 跨所有容器设置和访问共享文件系统具有一定的挑战性。
Kubernetes 卷(Volume) 这一抽象概念能够解决这两个问题。
4.7.1 NFS安装
NFS(Network File System)是一种用于在网络上共享文件系统的协议和文件系统协议族。它最初由Sun Microsystems开发,用于在操作系统之间共享文件和目录。NFS允许计算机之间通过网络透明地访问和操作远程文件系统,就像它们是本地文件一样。
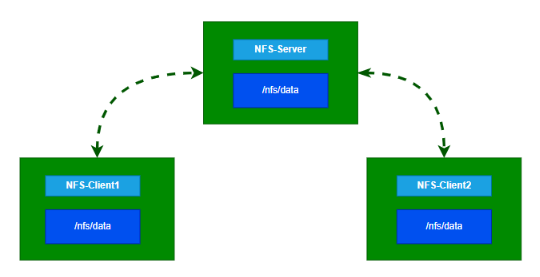
具体安装步骤:
三台机器都要执行命令
yum install -y nfs-utils
主节点执行命令
bash
#nfs主节点 配置共享规则
echo "/nfs/data/ *(insecure,rw,sync,no_root_squash)" > /etc/exports
mkdir -p /nfs/data
systemctl enable rpcbind --now
systemctl enable nfs-server --now
#配置生效
exportfs -r工作节点执行命令
bash
# 查看远程主机上可用的NFS
showmount -e 192.168.200.131
# 执行以下命令挂载 nfs 服务器上的共享目录到本机路径 /root/nfsmount
mkdir -p /nfs/data
# 挂载一个远程的NFS(Network File System)共享目录
mount -t nfs 192.168.200.131:/nfs/data /nfs/data测试效果
写入一个测试文件,如果其他的机器能访问到我们创建的文件表示配置成功。
bash
echo "hello nfs server" > /nfs/data/test.txt4.7.2 PV & PVC
PV:持久卷( Persistent Volume),将应用需要持久化的数据保存到指定位置
PVC:持久卷申明( Persistent Volume Claim),申明需要使用的持久卷规格
PV是集群中配置的存储资源,它是对底层的共享存储的一种抽象。PV可以被多个PVC所使用,而PVC必须与对应的PV建立关系。PV和PVC是Kubernetes抽象出来的一种存储资源,它们为容器提供了持久化的存储空间。
PVC是用户存储的请求,它是一种持久卷请求于存储需求的一种声明。PVC的使用逻辑是:在pod中定义一个存储卷(该存储卷类型为PVC),定义的时候直接指定大小,pvc必须与对应的pv建立关系,pvc会根据定义去pv申请,而pv是由存储空间创建出来的。
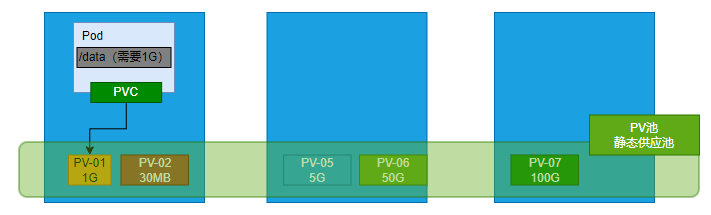
创建PV池
bash
#nfs主节点
mkdir -p /nfs/data/01
mkdir -p /nfs/data/02
mkdir -p /nfs/data/03创建PV
vi volume-pv.yaml
bash
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv01-10m
spec:
capacity:
storage: 10M
accessModes:
- ReadWriteMany
storageClassName: nfs
nfs:
path: /nfs/data/01
server: 192.168.200.131
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv02-1gi
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteMany
storageClassName: nfs
nfs:
path: /nfs/data/02
server: 192.168.200.131
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv03-3gi
spec:
capacity:
storage: 3Gi
accessModes:
- ReadWriteMany
storageClassName: nfs
nfs:
path: /nfs/data/03
server: 192.168.200.131查看节点:
kubectl get pv
原生方式数据挂载
mkdir -p /nfs/data/nginx-pv
vi nginx-pv-demo.yaml
bash
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx-pv-demo
name: nginx-pv-demo
spec:
replicas: 2
selector:
matchLabels:
app: nginx-pv-demo
template:
metadata:
labels:
app: nginx-pv-demo
spec:
containers:
- image: nginx
name: nginx
volumeMounts:
- name: html
mountPath: /usr/share/nginx/html
volumes:
- name: html
nfs:
server: 192.168.200.131
path: /nfs/data/nginx-pv在这个目录 /nfs/data/nginx-pv 创建 index.html 随便写点内容 !
kubectl get pods -A -owide
curl 172.32.126.29 就可以看到当前写的数据了!说明挂载成功!
使用PVC方式数据挂载
创建PVC
vi pvc.yaml
bash
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nginx-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 200Mi
storageClassName: nfs部署绑定PVC
vi nginx-deploy-pvc.yaml
bash
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx-deploy-pvc
name: nginx-deploy-pvc
spec:
replicas: 2
selector:
matchLabels:
app: nginx-deploy-pvc
template:
metadata:
labels:
app: nginx-deploy-pvc
spec:
containers:
- image: nginx
name: nginx
volumeMounts:
- name: html
mountPath: /usr/share/nginx/html
volumes:
- name: html
persistentVolumeClaim:
claimName: nginx-pvc
bash
[root@k8s-master ~]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv01-10m 10M RWX Retain Available nfs 44m
pv02-1gi 1Gi RWX Retain Bound default/nginx-pvc nfs 44m
pv03-3gi 3Gi RWX Retain Available nfs 44m
[root@k8s-master ~]# PV状态说明
- Pending:表示目前该 PV 在后端存储系统中还没创建完成。
- Available:表示可用状态,还未被任何 PVC 绑定。
- Bound:表示 PVC 已经被 PVC 绑定。
- Released:表示已经绑定的 PVC 已经被删掉了,但资源还未被集群重新声明。
- Failed:表示回收失败。
4.7.3 ConfigMap
抽取应用配置,并且可以自动更新。用来存储一些配置信息,比如配置文件的内容、环境变量、命令参数等。在 Pod 运行时,ConfigMap 中的数据可以被挂载到 Pod 中,供容器内的应用使用。
示例Nginx使用ConfigMap
bash
# 创建一个nginx
kubectl run mynginx --image=nginx
# 进入容器内部
kubectl exec -it mynginx /bin/bash -n default
# 创建一个文件夹 /root/config/yaml
mkdir -p /root/config/yaml
# 在root目录下创建configmap
[root@k8s-master ~]# kubectl create configmap my-nginx-conf --from-file=config/yaml/
# 查看
kubectl get cm
# 删除
kubectl delete cm my-nginx-config
# 查看详细信息
kubectl get cm -oyaml
# 创建configmap的yaml文件
vi my-nginx-conf.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: my-nginx-conf
namespace: default
data:
default.conf: |+
server {
listen 80;
listen [::]:80;
server_name localhost;
#access_log /var/log/nginx/host.access.log main;
location / {
root /usr/share/nginx/html;
index index.html index.htm;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/share/nginx/html;
}
# proxy the PHP scripts to Apache listening on 127.0.0.1:80
#
#location ~ \.php$ {
# proxy_pass http://127.0.0.1;
#}
# pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000
#
#location ~ \.php$ {
# root html;
# fastcgi_pass 127.0.0.1:9000;
# fastcgi_index index.php;
# fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name;
# include fastcgi_params;
#}
# deny access to .htaccess files, if Apache's document root
# concurs with nginx's one
#
#location ~ /\.ht {
# deny all;
#}
}
mycustom.conf: |
# haha
# 创建pod关联configmap
vi myconfigmap.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-cm
spec:
containers:
- image: nginx
name: mynginx
volumeMounts:
- name: conf
mountPath: /etc/nginx/conf.d
volumes:
- name: conf
configMap:
name: my-nginx-conf
# 进入容器测试配置文件格式
root@nginx-cm:/etc/nginx/conf.d# ls
default.conf mycustom.conf
# 修改配置文件实时更新
kubectl edit cm my-nginx-conf
root@nginx-cm:/etc/nginx/conf.d# cat mycustom.conf
# haha
# update 1111114.7.4 Secret
Secret 对象类型用来保存敏感信息,例如密码、OAuth 令牌和 SSH 密钥。 将这些信息放在 secret 中比放在 Pod 的定义或者 容器镜像 中来说更加安全和灵活。
创建secret
bash
##命令格式
kubectl create secret docker-registry regcred \
--docker-server=<你的镜像仓库服务器> \
--docker-username=<你的用户名> \
--docker-password=<你的密码> \
--docker-email=<你的邮箱地址>
kubectl create secret docker-registry mqx-docker \
--docker-server=registry.cn-hangzhou.aliyuncs.com \
--docker-username=243620922@qq.com \
--docker-password=Ts123456 \
--docker-email=243620922@qq.com创建Pod使用私有镜像
bash
##命令格式
kubectl create secret docker-registry regcred \
--docker-server=<你的镜像仓库服务器> \
--docker-username=<你的用户名> \
--docker-password=<你的密码> \
--docker-email=<你的邮箱地址>
kubectl create secret docker-registry mqx-docker \
--docker-server=registry.cn-hangzhou.aliyuncs.com \
--docker-username=243620922@qq.com \
--docker-password=Ts123456 \
--docker-email=243620922@qq.com测试访问
curl 192.168.126.43:8080/hello?name=111
总结:
bash
相关命令:
kubectl get nodes -A
kubectl get pods -A -o wide
kubectl apply -f xxx.yaml
kubectl delete -f xxx.yaml
namespace: 操作
kubectl create ns hello
kubectl delete ns hello
pod:操作 默认是在default 命名空间下
kubectl run mynginx --image=nginx -n dev
kubectl delete pod [pod_name] -n dev[命名空间]
deployment:操作 自我修复扩缩容pod
kubectl create deployment mytomcat --image=tomcat:8.5.68
kubectl delete deployment mytomcat
kubectl delete deployment my-dep
灰度发布:
kubectl rollout history deployment/my-dep
1:没有指定nginx 版本:
2:指定1.16.1
3: 指定1.18.1
kubectl rollout undo deployment/my-dep --to-revision=2
service:主要负载均衡pod,还可以对外暴露地址和端口
--type:ClusterIP (只能内部访问)
--type:NodePort (通过浏览器访问)
kubectl expose deployment my-dep --port=8000 --target-port=80 --type=NodePort
Ingress:使用域名的形式访问集群内部; 还可以限流
kubectl apply -f ingress.yaml;
kubectl apply -f ingress-rule.yaml;
kubectl delete -f ingress-rule.yaml;
kubectl get ingress -A -n
kubectl delete ingress ingress_name;
Storage: 数据存储与挂载(共享文件与目录)
NFS: 共享文件或目录
PV/PVC 挂载磁盘位置
configMap 动态更新配置信息 与 Pod 挂载
secret 保存个人敏感信息 与 Pod 挂载 结论:
- 以后项目部署的时候,不应该单独使用pod,应该使用deployment多节点部署!
项目部署到K8S 上:
bash
1. 上传target目录下的jar 到 worker1 节点中的/root/build目录下
2. 进入到/root/build目录下执行:
docker build -f DockerFile -t demo:1.0 .
测试:
docker run -P --rm demo:1.0
docker ps | grep demo 查看端口号
3. 将worker1节点的镜像打包
docker save demo:1.0 |gzip > demo.tar.gz
4. 在worker1 节点执行
scp demo.tar.gz root@192.168.200.133:/root
5. 到 192.168.200.133 执行加载镜像
docker load -i demo.tar.gz
6. 在master节点编写 demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-demo
spec:
replicas: 3
selector:
matchLabels:
app: my-demo
template:
metadata:
labels:
app: my-demo
spec:
containers:
- name: demo
image: demo:1.0
---
apiVersion: v1
kind: Service
metadata:
managedFields:
- apiVersion: v1
name: my-demo
namespace: default
spec:
ports:
port: 8080
protocol: TCP
targetPort: 8080
selector:
app: my-demo
type: NodePort
执行文件:
kubectl apply -f demo.yaml
7.确认pod正常运行
kubectl get pod
8.查看svc端口
kubectl get svc
9.访问
curl http://192.168.200.132:32586/hello