文章目录
负载均衡介绍
简单实现
问题描述
观察上篇文章的远程调用代码
java
List<ServiceInstance> instances = discoveryClient.getInstances("product-service");
// 服务可能有多个,获取第一个
EurekaServiceInstance instance = (EurekaServiceInstance) instances.get(0);- 根据应用名称获取了服务实例列表
- 从列表中选择了一个服务实例
思考 :如果一个服务对应多个实例呢?流量是否可以合理的分配到多个实例?
现象观察:
- 我们再启动 2 个
product-service实例 - 选中要启动的服务,右键选择
Copy Configuration...
在弹出的框中,选择 Modify options -> Add VM options
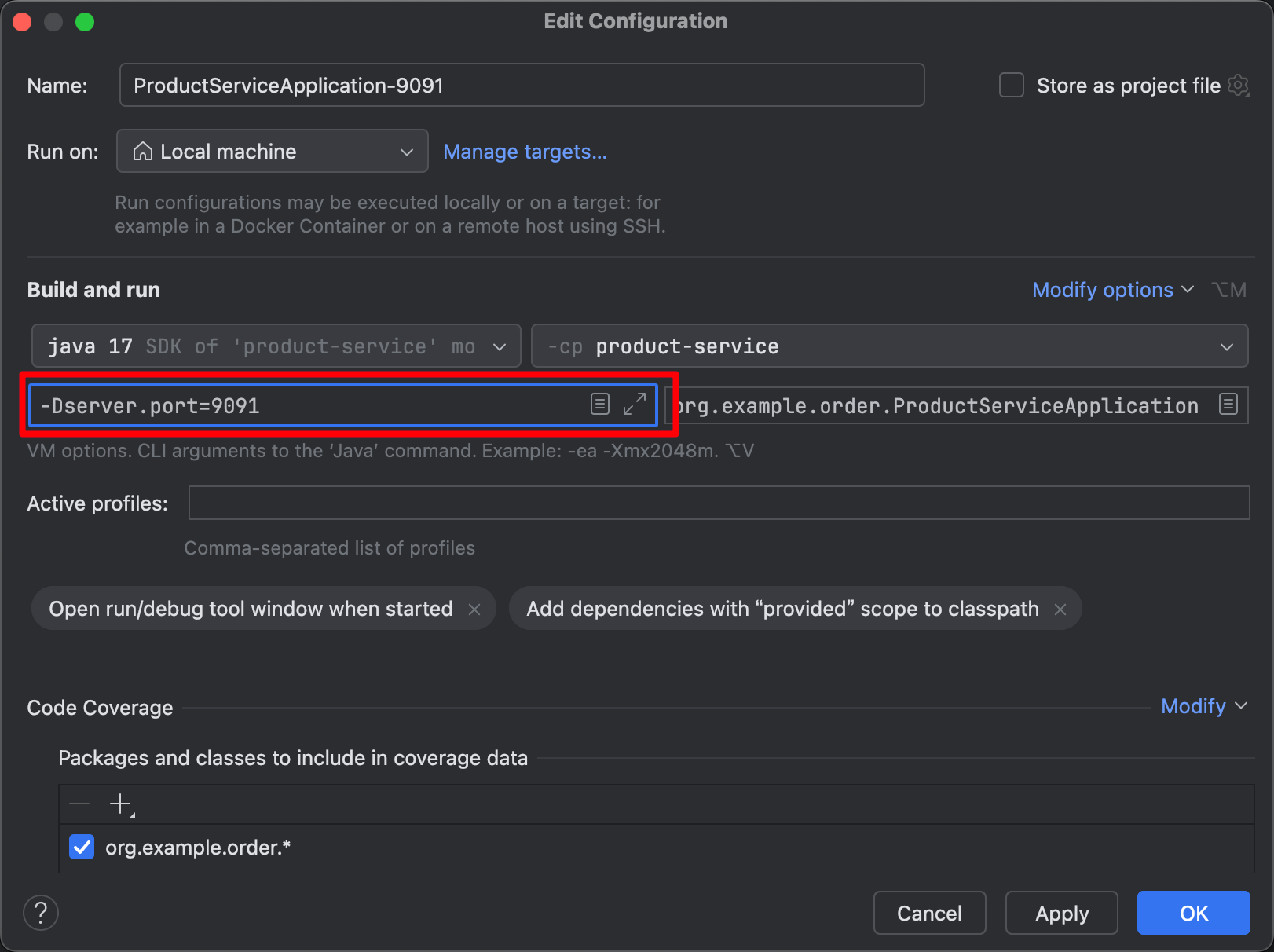
添加 VM options:-Dserver.port=9091
9091为服务启动的端口号,根据自己的情况可修改
现在 IDEA 的 Service 窗口就会多出一个启动配置,右键启动服务就可以了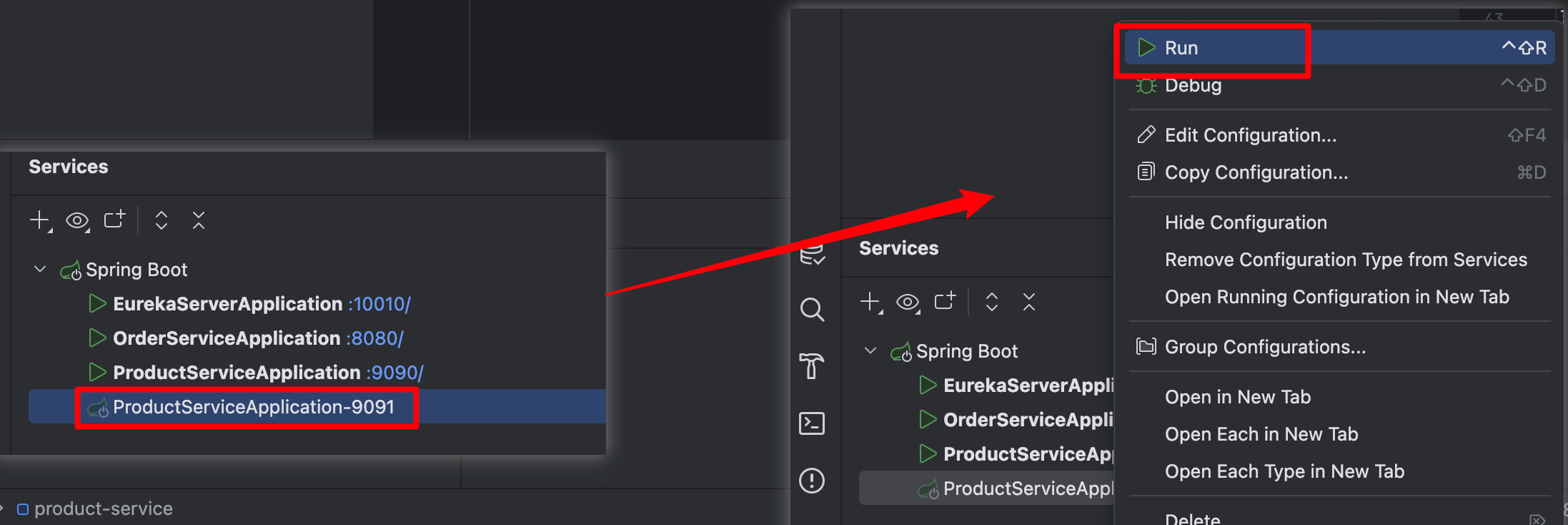
同样的操作,再启动一个实例,共启动三个服务器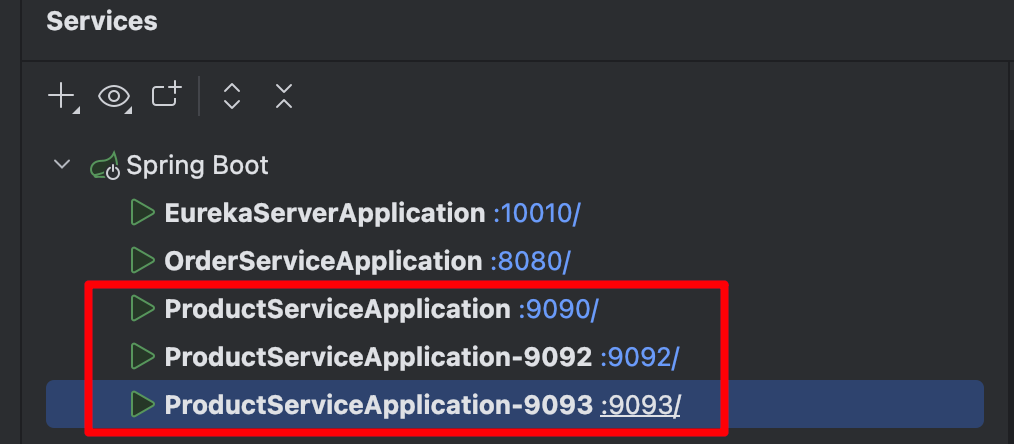
观察 Eureka,可以看到 product-service 下有三个实例: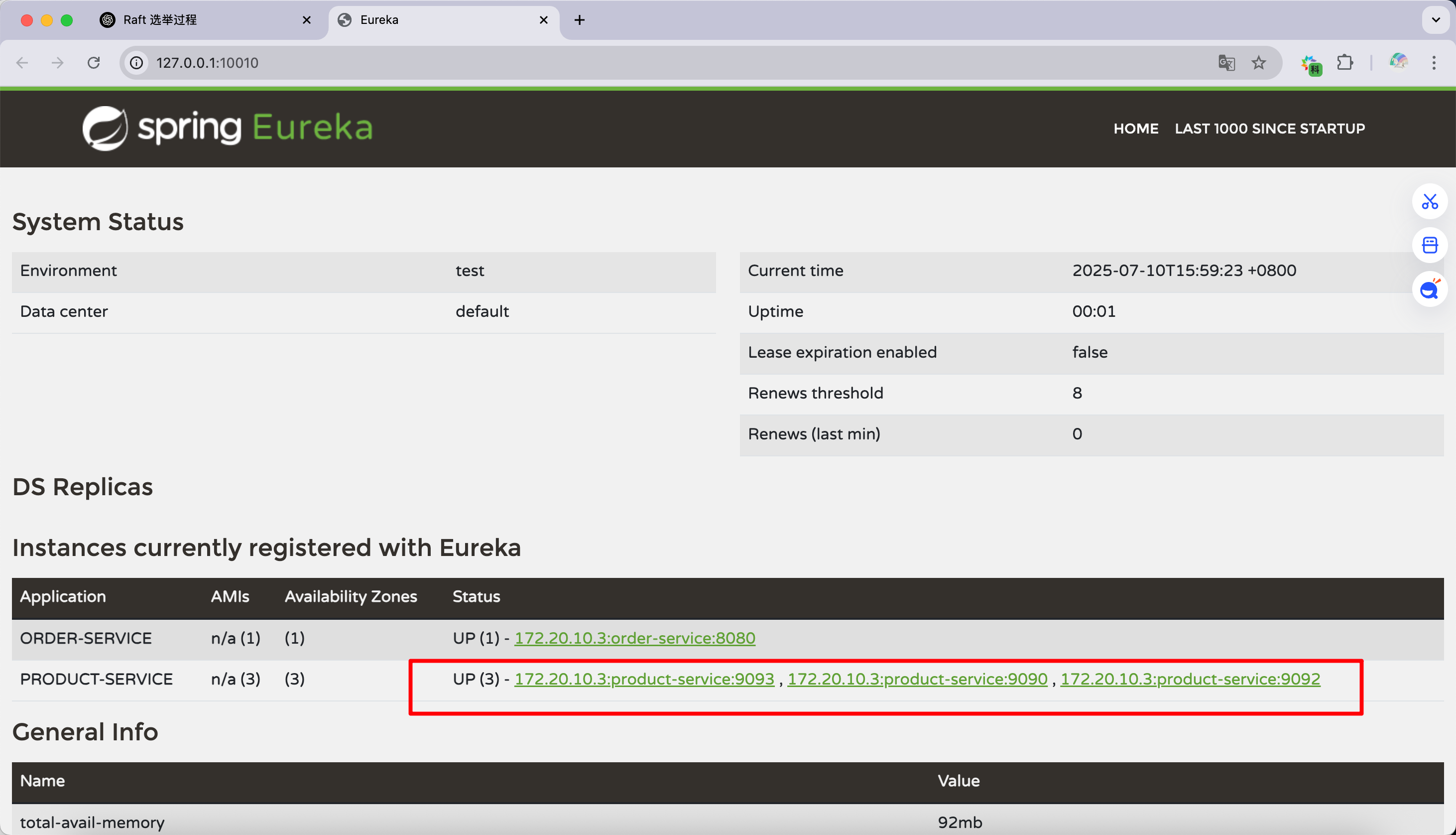
访问结果 :
访问: http://127.0.0.1:8080/order/1
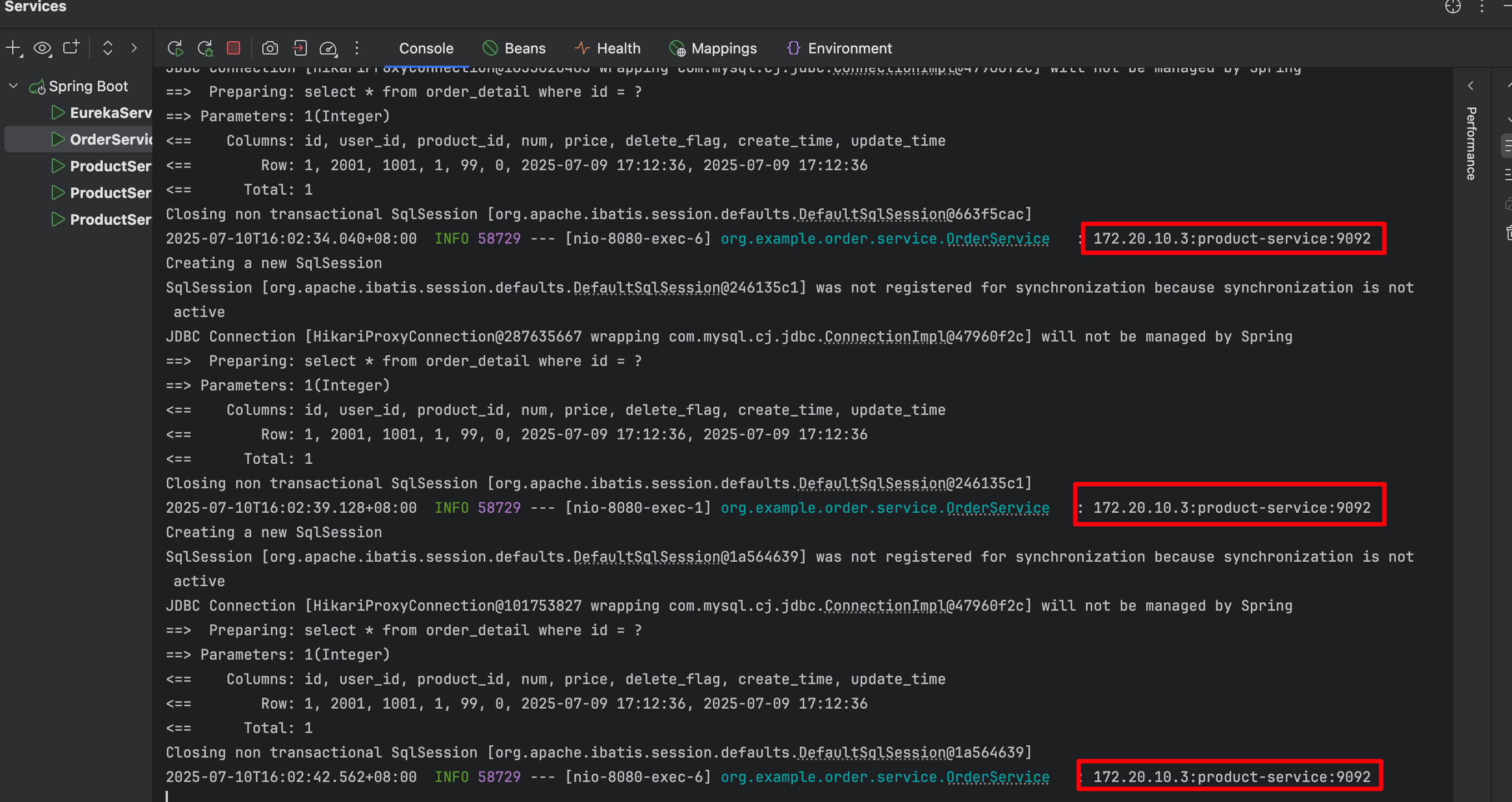
- 通过日志可以发现,请求多次访问,都是同一台机器
问题解决
这肯定不是我们想要的结果,我们启动多个实例,是希望可以分担其他机器的符合,那么如何实现呢?
我们可以针对上述代码简单修改:
java
package org.example.order.service;
import jakarta.annotation.PostConstruct;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.example.order.mapper.OrderMapper;
import org.example.order.model.OrderInfo;
import org.example.order.model.ProductInfo;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cloud.client.ServiceInstance;
import org.springframework.cloud.client.discovery.DiscoveryClient;
import org.springframework.cloud.netflix.eureka.EurekaServiceInstance;
import org.springframework.stereotype.Service;
import org.springframework.web.client.RestTemplate;
import java.util.List;
import java.util.concurrent.atomic.AtomicInteger;
@Slf4j
@Service
public class OrderService {
@Autowired
private OrderMapper orderMapper;
@Resource
private DiscoveryClient discoveryClient;
@Autowired
private RestTemplate restTemplate;
private static AtomicInteger atomicInteger = new AtomicInteger(1);
private static List<ServiceInstance> instances;
@PostConstruct
public void init() {
// 根据应用名称获取服务器列表
instances = discoveryClient.getInstances("product-service");
}
public OrderInfo selectOrderById(Integer orderId) {
OrderInfo orderInfo = orderMapper.selectOrderById(orderId);
//String url = "http://127.0.0.1:9090/product/" + orderInfo.getProductId();
// 服务可能有多个,轮询获取实例
int index = atomicInteger.getAndIncrement() % instances.size();
ServiceInstance instance = instances.get(index);
log.info(instance.getInstanceId());
// 拼接 URL
String url = instance.getUri() + "/product/" + orderInfo.getProductId();
ProductInfo productInfo = restTemplate.getForObject(url, ProductInfo.class);
orderInfo.setProductInfo(productInfo);
return orderInfo;
}
}-
@PostConstruct:在Spring容器完成 依赖注入(DI) 后,自动调用标注了@PostConstruct的方法,用于执行初始化逻辑。- 就是当这个
Bean创建完成并注入完需要的依赖后,Spring会自动调用我标注的方法一次,用来做一些初始化的操作。
- 就是当这个
-
discoveryClient.getInstances()可以返回当前所有可用的product-service实例。instances列表包含了所有可用的product-service实例,每个实例包含了服务的URI和其他元数据
-
int index = atomicInteger.getAndIncrement() % instances.size():该逻辑基于递增的计数器来决定访问哪个实例。每次访问时,计数器会递增,并且通过index % instances.size()确保能够在实例列表中轮询(即循环访问所有实例)。- 例如,如果有 3 个实例,当
atomicInteger的值为 1、2、3、4 时,它会依次访问
- 例如,如果有 3 个实例,当
观察日志: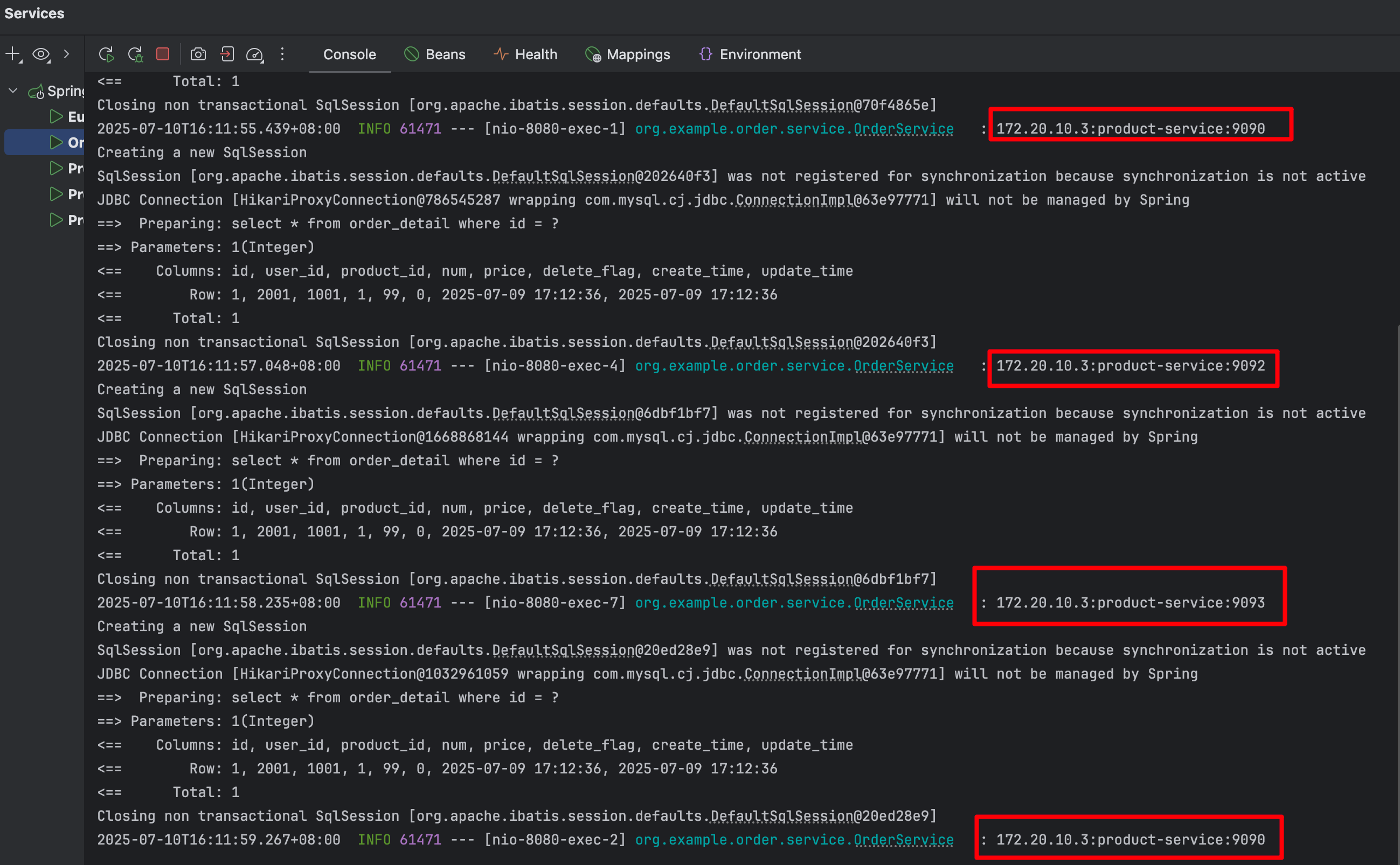
- 通过日志可以看到,请求被均衡的分配在了不同的实例上,这就是负载均衡
通过使用
DiscoveryClient获取product-service的所有实例,并结合AtomicInteger实现轮询负载均衡,将请求均匀地分发到product-service的各个实例上,从而有效地进行负载均衡。
什么是负载均衡
负载均衡(Load Balance,简称 LB),是高并发,高可用系统必不可少的关键组件
当服务流量增大时,通常会采用增加机器的方式进行扩容,负载均衡就是用来在多个机器或者其他资源中,按照一定规则合理分配负载
- 一个团队最开始只有一个人,后来随着工作量的增加,公司又招聘了几个人,负载均衡就是:如何把工作量均衡的分配到这几个人身上,以提高整个团队的效率
负载均衡的一些实现
上面的例子中,我们只是简单的对实例进行了轮询,但真是的业务场景会更加复杂。比如根据机器的配置进行负载分配,配置高的分配的流量高,配置低的分配流量低等
- 类似企业员工:能力强的员工可以多承担一些工作
服务多机部署时,开发人员都需要考虑负载均衡的实现,所以也出现了一些负载均衡器,来帮助我们实现负载均衡
- 负载均衡分为服务端负载均衡 和客户端负载均衡
服务端负载均衡
在服务端进行负载均衡的算法分配
比较有名的服务端负载均衡器是 Nginx。请求先到达 Nginx 负载均衡器,然后通过负载均衡算法,在多个服务器之间选择一个进行访问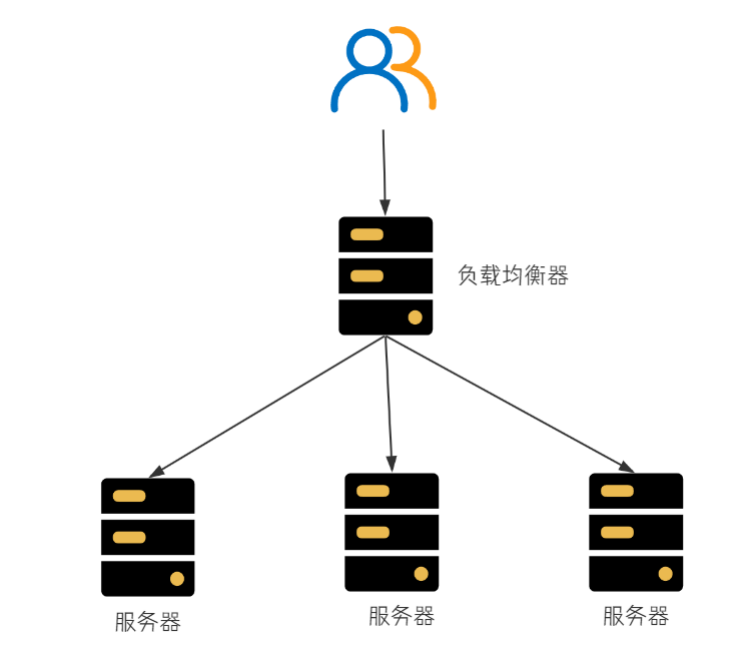
客户端负载均衡
在客户端进行负载均衡的算法分配
把负载均衡的功能以库的方式集成到客户端,而不再是由一台指定的负载均衡设备集中提供
比如 Spring Cloud 的 Ribbon,请求发送到客户端,客户端从注册中心(比如 Eureka)获取到服务列表,在发送请求前通过负载均衡算法选择一个服务器,然后再进行访问
Ribbon 是 Spring Cloud 早期的默认实现,由于不维护了,所以最新版本的 Spring Cloud 负载均衡集成的是 Spring CloudBalancer(Spring Cloud 官方维护)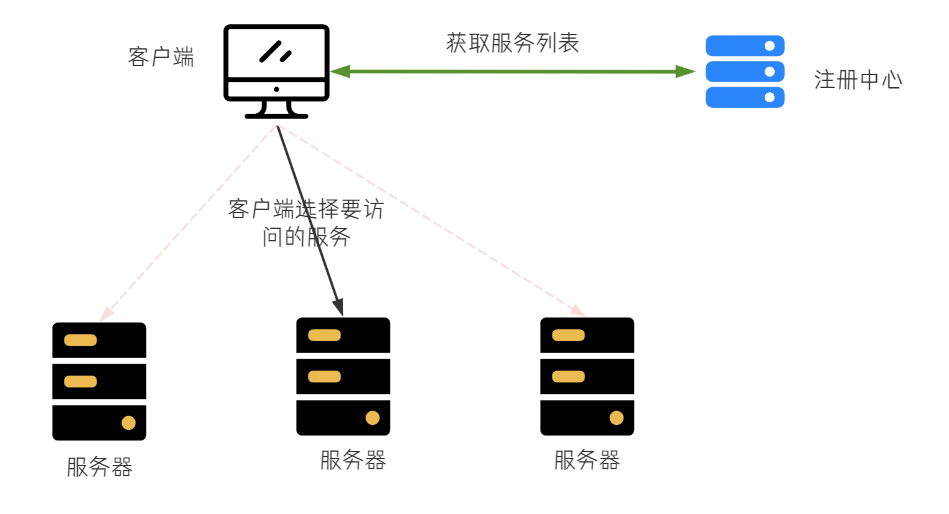
客户端负载均衡和服务端负载均衡最大的区别在于服务清单所存储的位置