windows下python3,LLaMA-Factory部署以及微调大模型,ollama运行对话,开放api,java,springboot项目调用
前提得有 英伟达的显卡
本文阐述的是windows下的微调,区别于linux,还是有些坑只有windows才有,需要特别注意,也是博主踩过花了大量时间解决的。
这里写目录标题
- windows下python3,LLaMA-Factory部署以及微调大模型,ollama运行对话,开放api,java,springboot项目调用
- 一级目录
-
- 二级目录
-
- 三级目录
- 1安装python
- 2安装CUDA和PyTorch安装
- 3安装LLaMA-Factory
- 4下载模型
- 5测试对话
- 5微调
- 6.Ollama运行
- [7.Postman调用 Ollama开放的接口](#7.Postman调用 Ollama开放的接口)
- 8.java代码请求示例
一级目录
二级目录
三级目录
1安装python
2安装CUDA和PyTorch安装
CUDA是,GPU的"驱动程序",NVIDIA推出的一种并行计算平台和编程模型。它本身不是软件,而是一个"桥梁"或"说明书",CUDA是让PyTorch等框架能够调用NVIDIA显卡进行高速计算的"桥梁"和"驱动"。
PyTorch是一个开源的机器学习框架,由Facebook(现Meta)的AI研究团队开发,让你能够用Python代码方便地定义、训练和测试你的AI模型。
相当于,一个是桥接显卡,使用其算力,一个是代码框架(类比util)
需要注意的是,这两个版本需要匹配。
2.1PyTorch安装
进入首页,直接往下拉,下载对应的版本,这里是windows就以这个为例子,我建议和博主保持一致。
bash
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118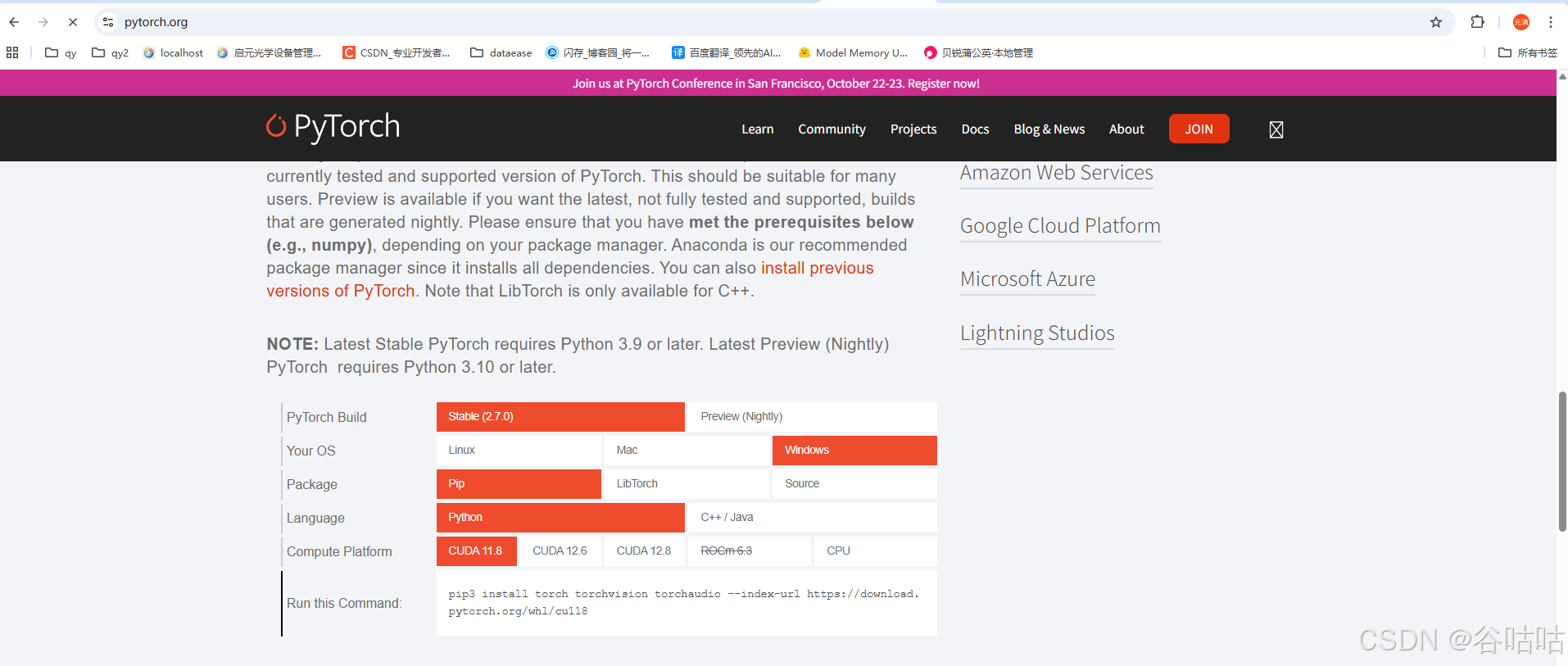
bash
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118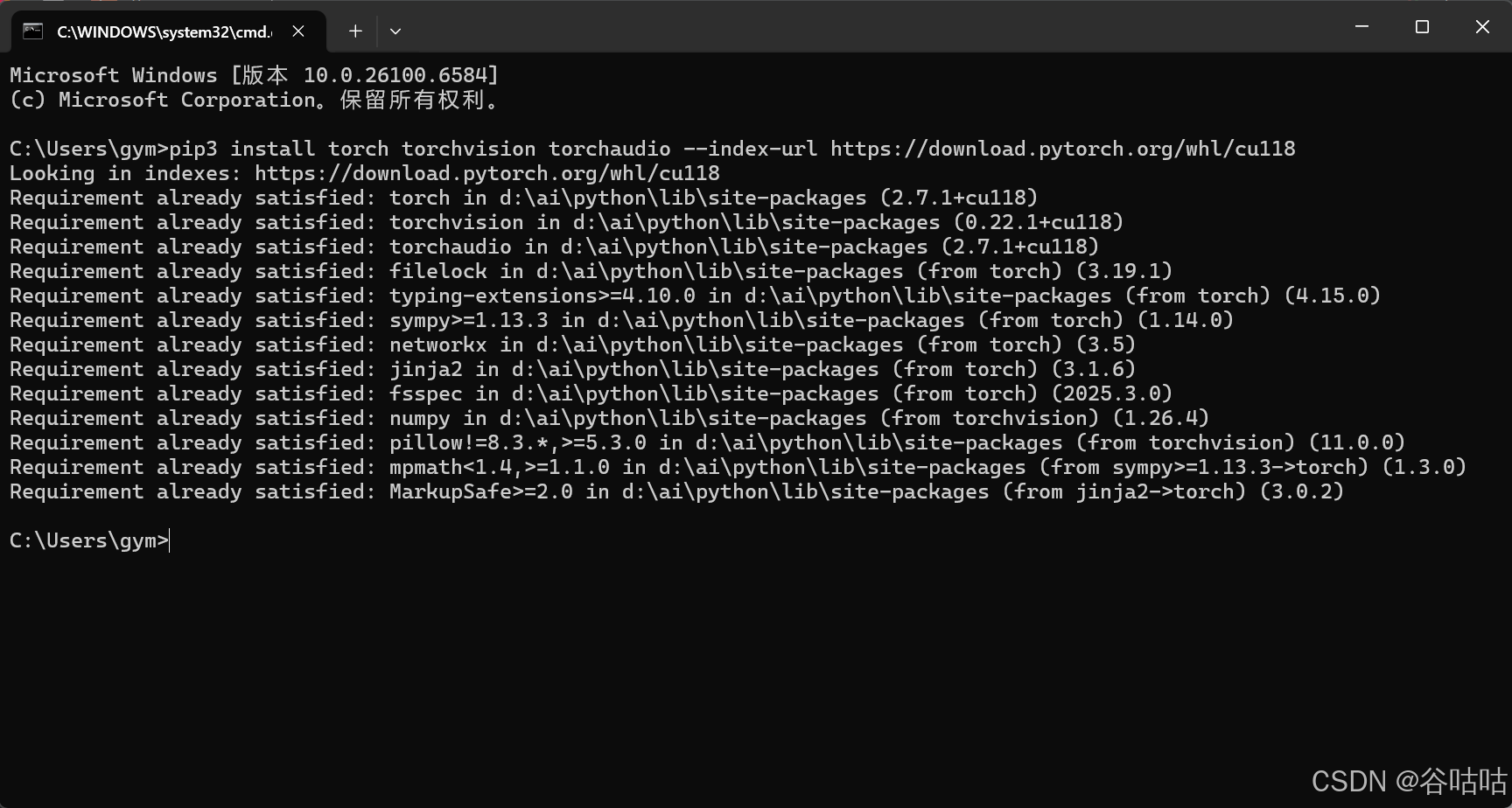
2.2安装CUDA
注意,我们上面的pytorch是安装的图上所示,所以我们cuda要安装对应的11.8的。这个很重要。
官网:https://developer.nvidia.com/cuda-toolkit-archive
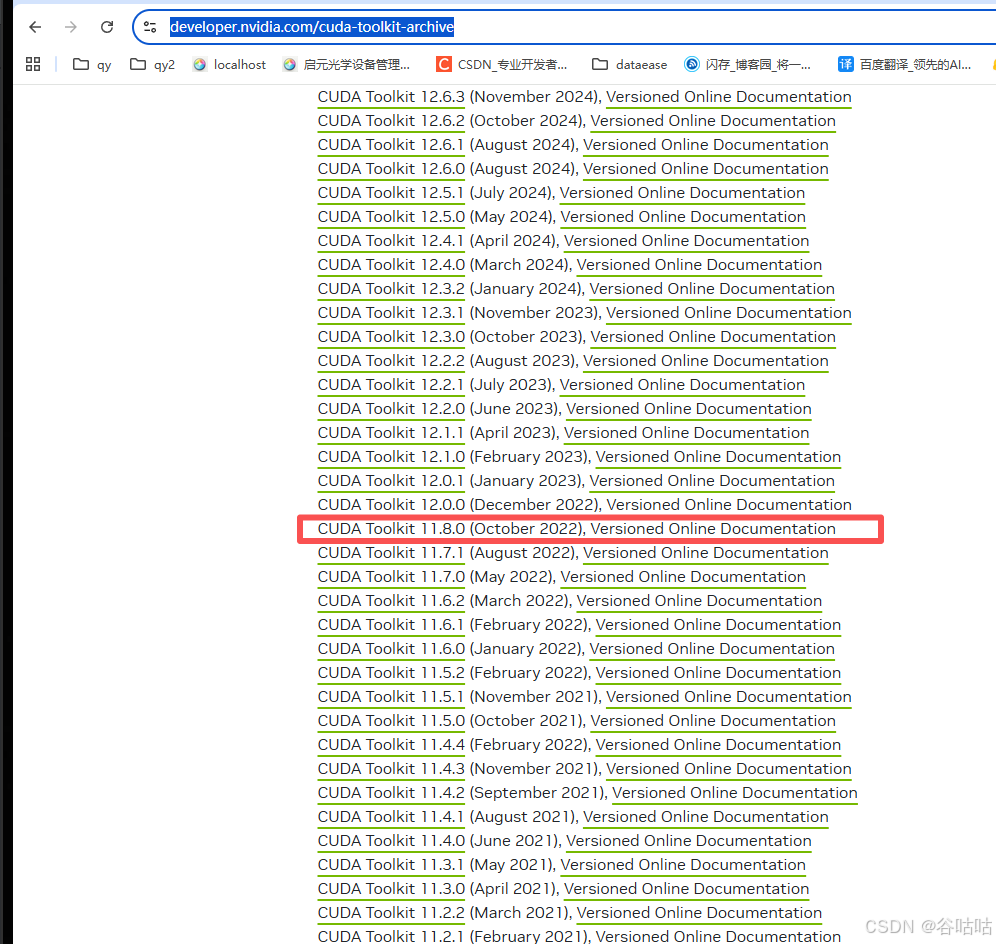
点进去下载就完事了。
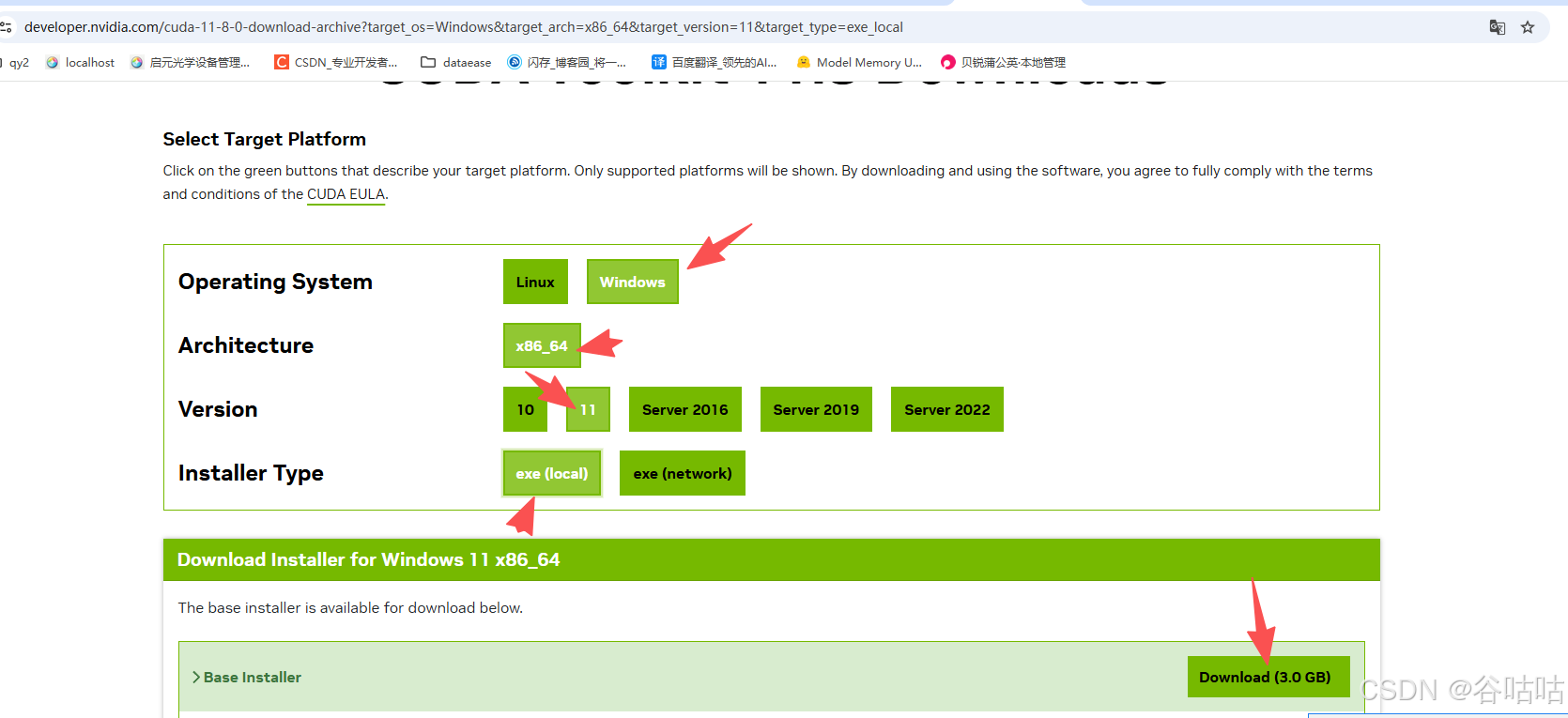
下载后点击安装就行了,傻瓜式安装。
安装完后,我们检查一下环境。
python
python
bash
import torch
bash
torch.cuda.current_device()
bash
torch.cuda.get_device_name(0)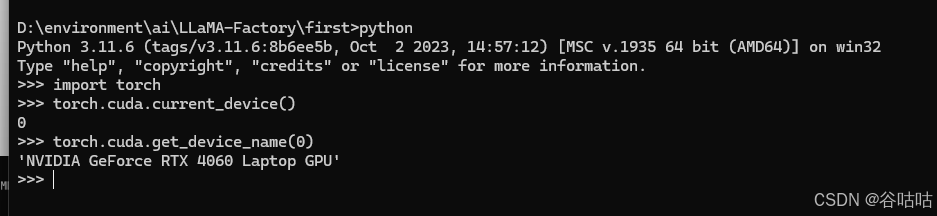
bash
torch.__version__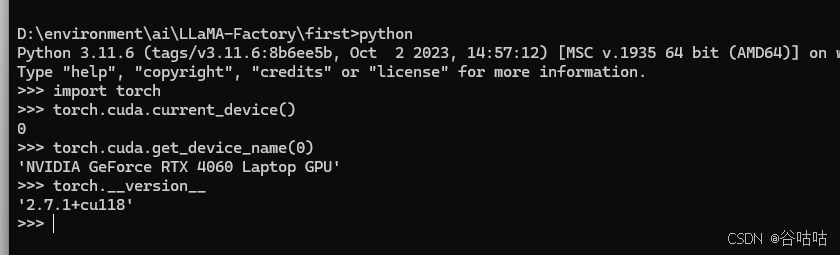
这样就行了,这里确保环境没有问题。
3安装LLaMA-Factory
使用git 下载
bash
git clone https://github.com/hiyouga/LLaMA-Factory.git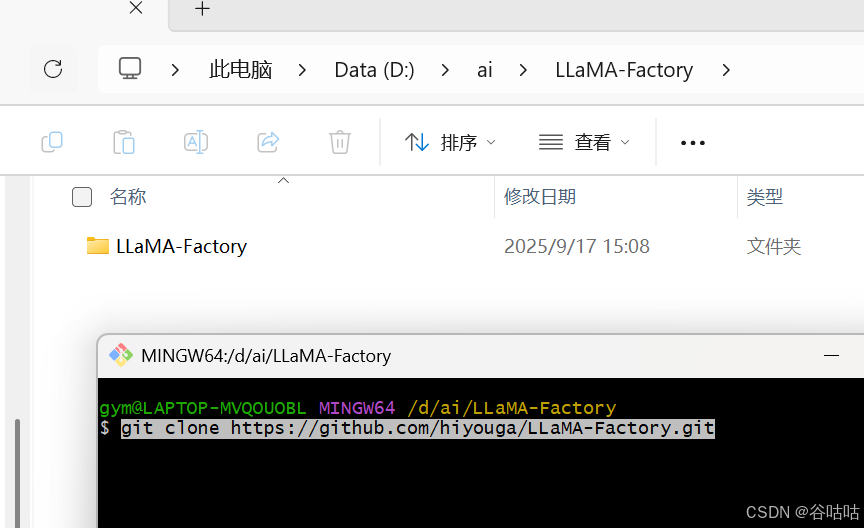
得到
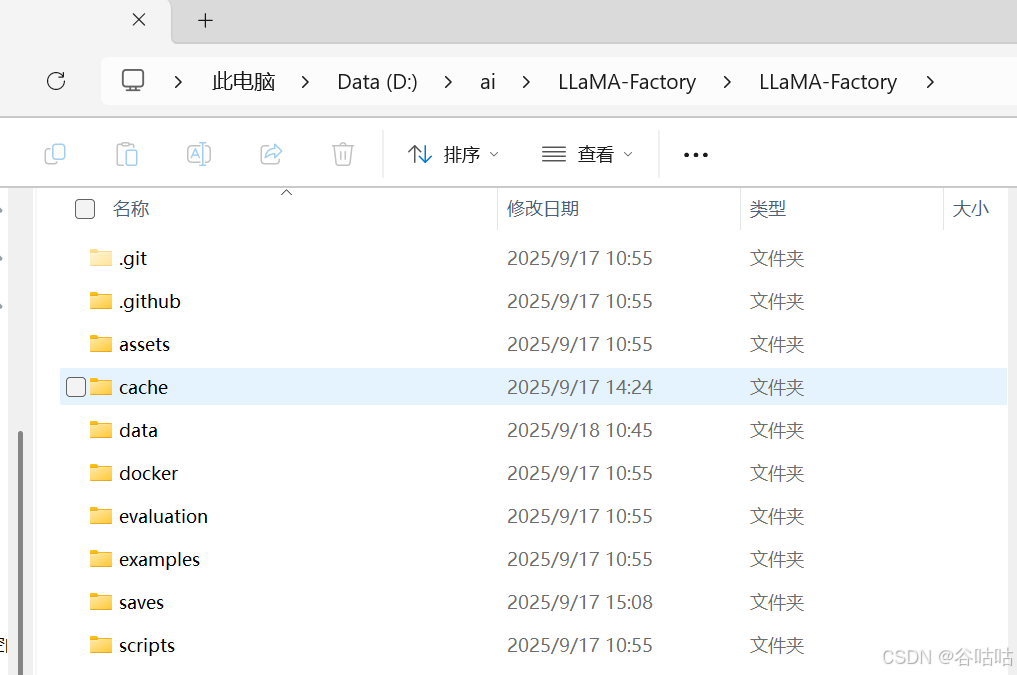
进去文件夹然后cmd打开终端,install一些必要信息,这个过程会比较慢,如果能够科学上网的话,会快很多。
bash
pip install -e '.[torch,metrics]'验证是否安装成功
bash
llamafactory-cli version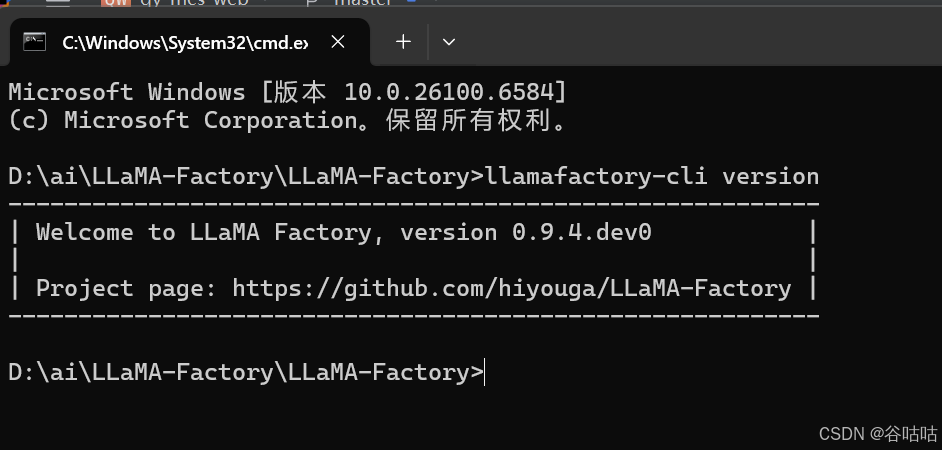
客户端安装成功后就可以启动了,注意这个命令必须,必须,必须在llamafactory的目录下执行。
否则,你就会遇到,找不到数据集的情况。
bash
llamafactory-cli webui
执行完后,程序就启动了。会弹出一个网页。终端不能关闭,关闭的话,程序就停止运行了。
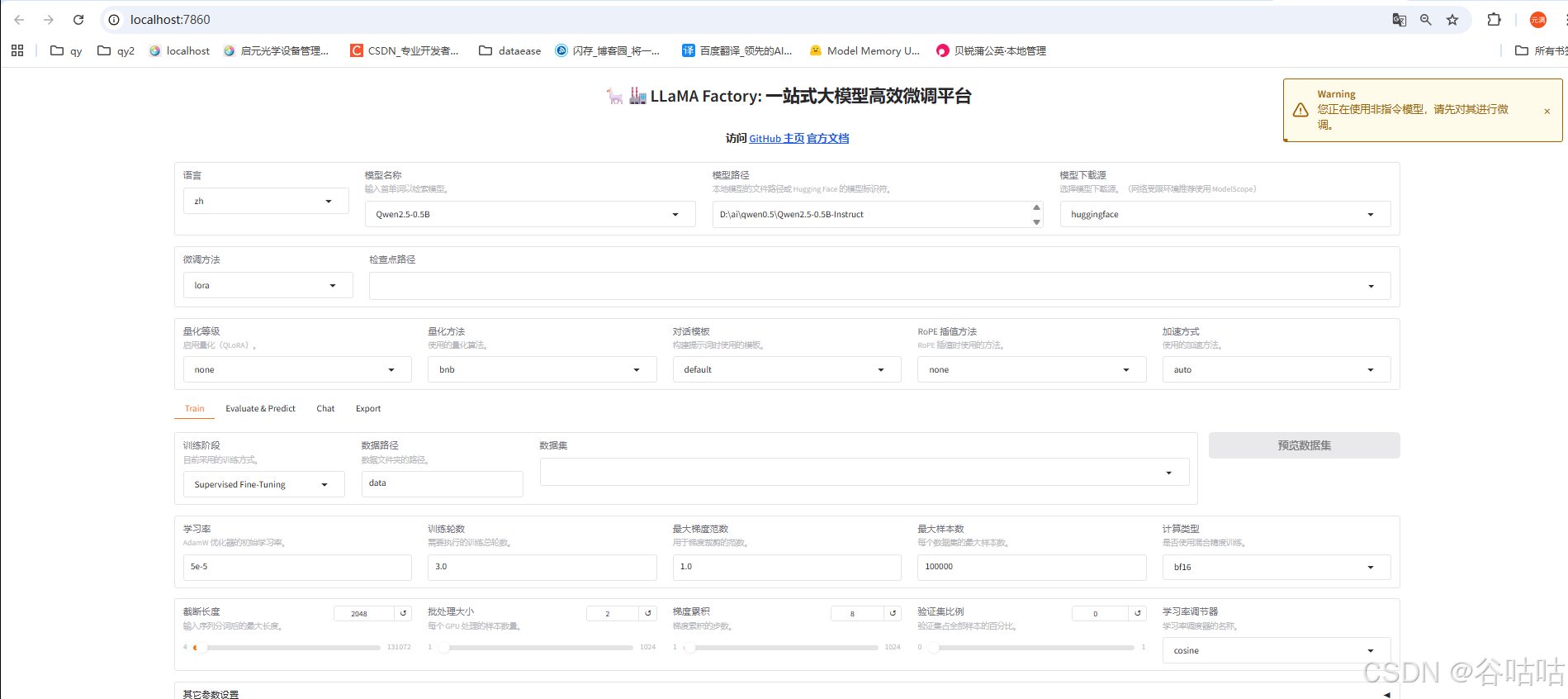
程序启动是不是安心很多了。
这里建议独显以外的显卡禁用掉。我这里只保留了,一张独显

4下载模型
下面要做的就是下载一个模型,进行微调。下载模型的途径有很多,这里用的是魔塔的。使用的是Qwen2.5-0.5B-Instruct,够了。
网址:https://modelscope.cn/models/Qwen/Qwen2.5-0.5B-Instruct
我这里选择使用git下载到我的d盘下。
bash
git clone https://www.modelscope.cn/Qwen/Qwen2.5-0.5B-Instruct.git
5测试对话
下载完之后你就可以在,LLaMA-Factory 中选择它,进行对话,和微调。
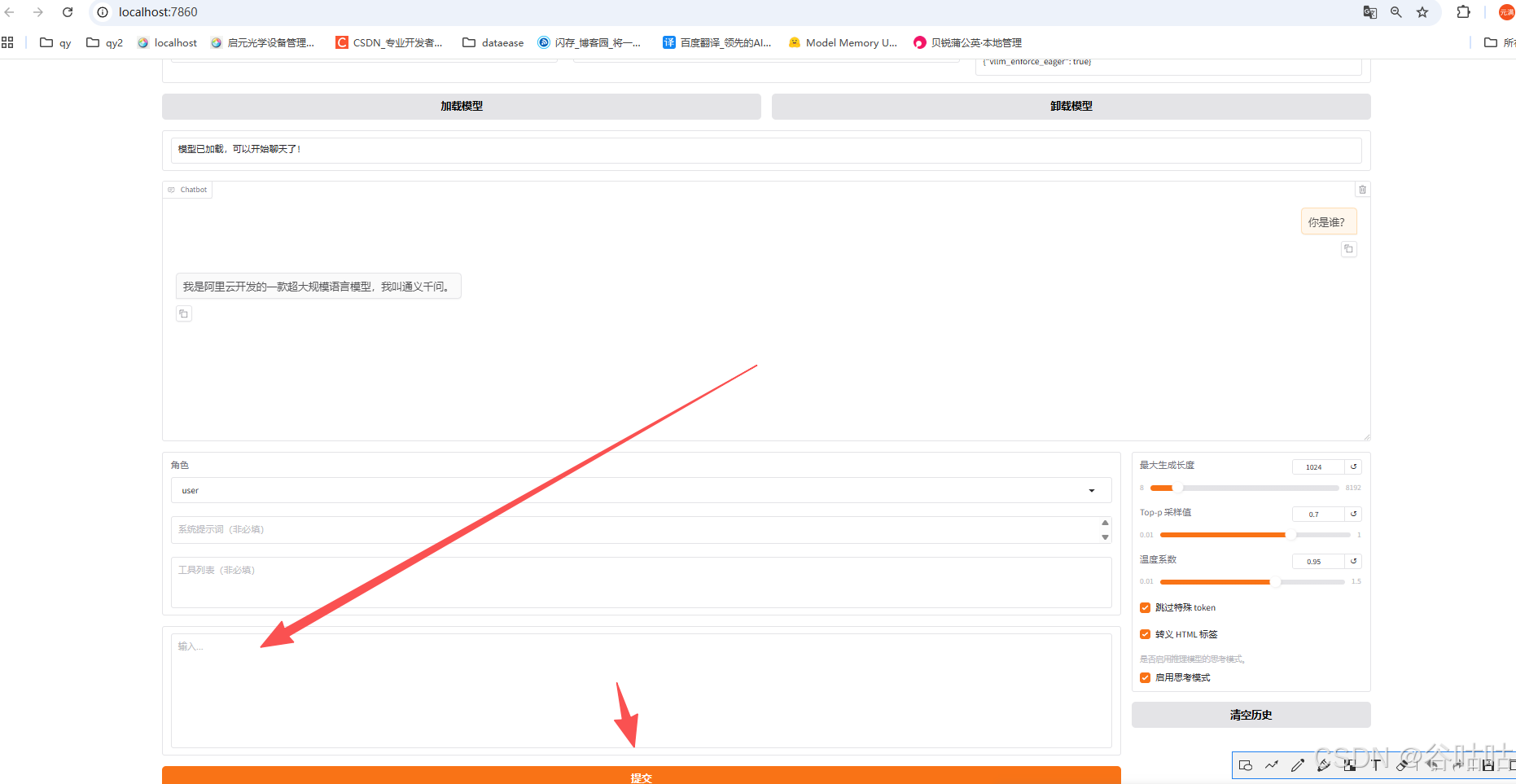
我们先测试一下对话。将路径复制进去,然后选择对应的名称,点击加载,然后拉到下面对话,测试一下。
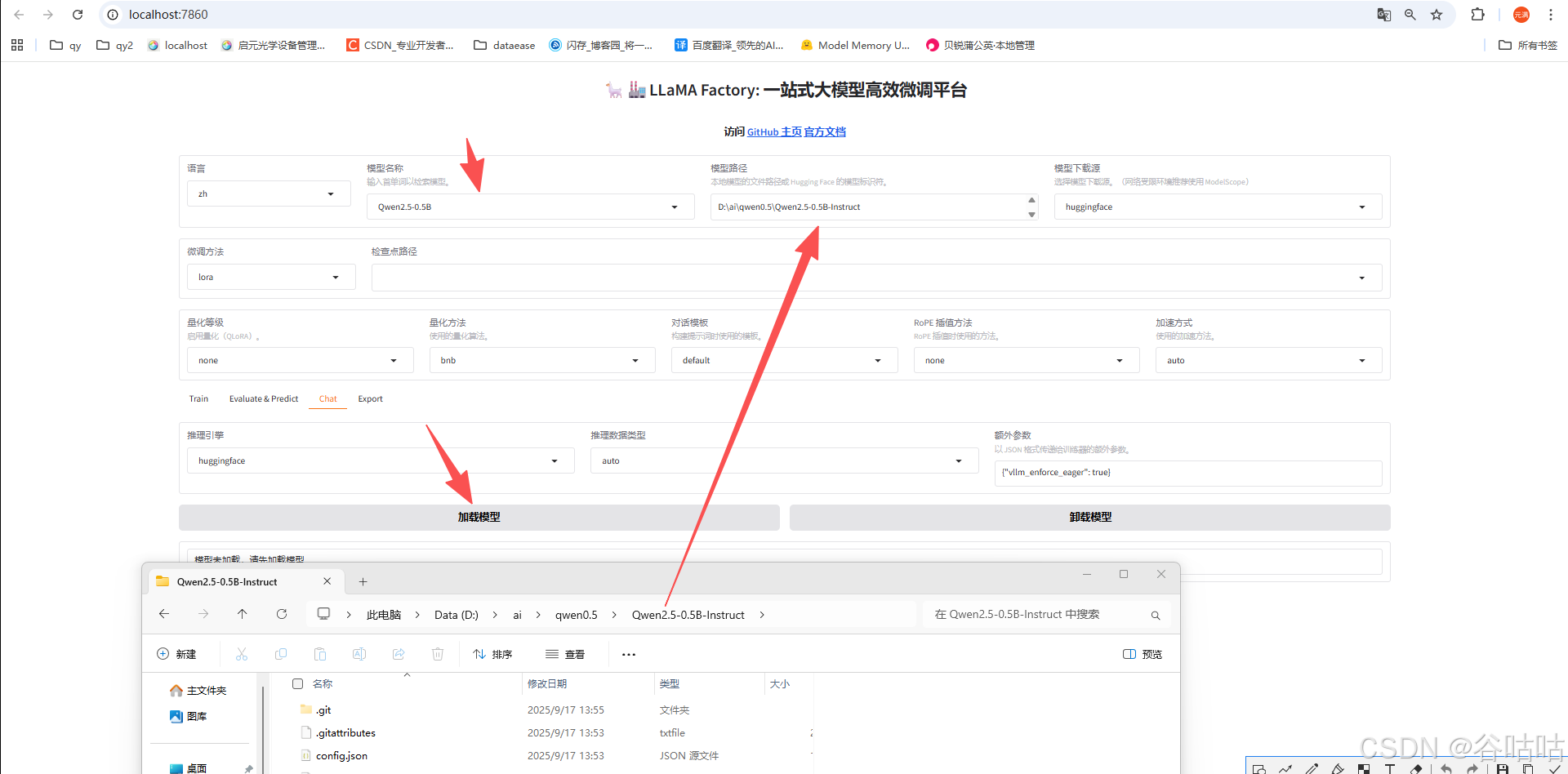
这里说明,我们的模型加载和使用也没问题。
5微调
5.1微调准备数据集
官方文档提供了多种,我这里选择一个常用的数据集格式。
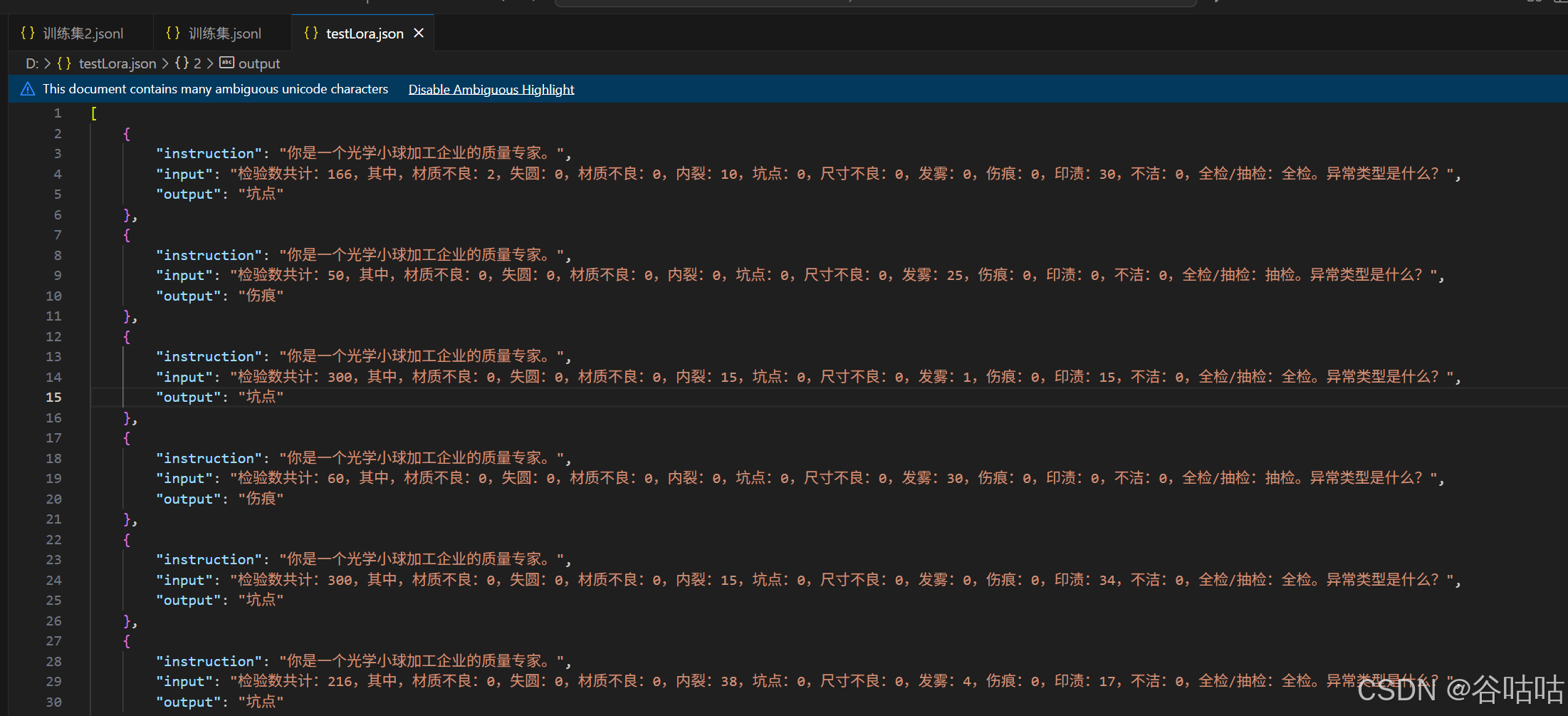
其实就是,角色,问题,答案。这样。
通过大量的数据,看看模型是否自己会内化规则。
数据集准备好了,我们需要让LLaMA-Factory可以应用它。
将这个文件,保存到data下
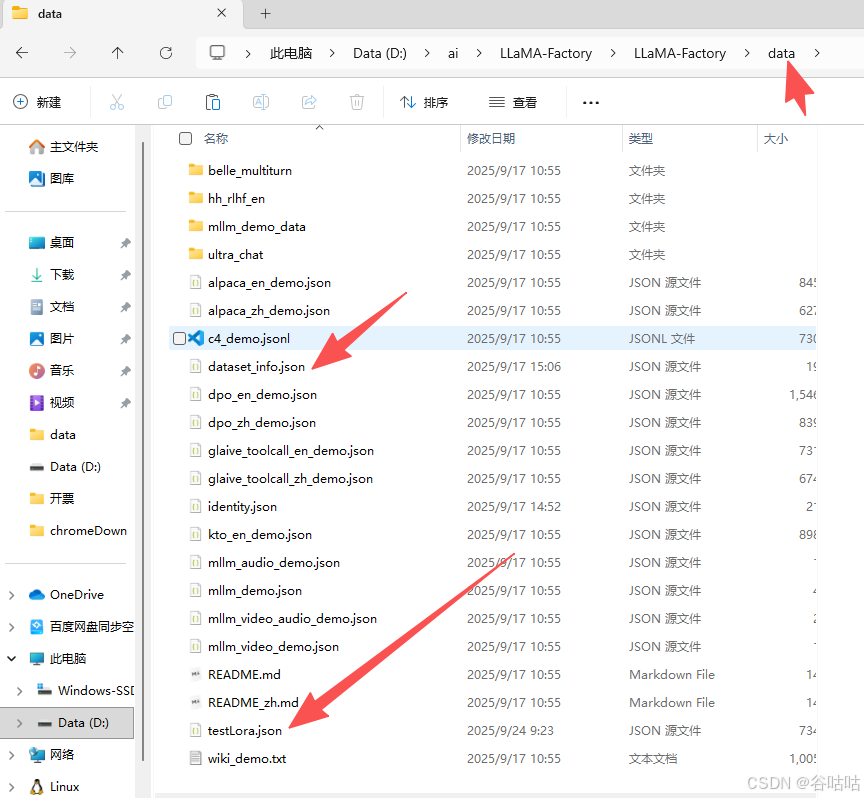
5.2修改配置文件
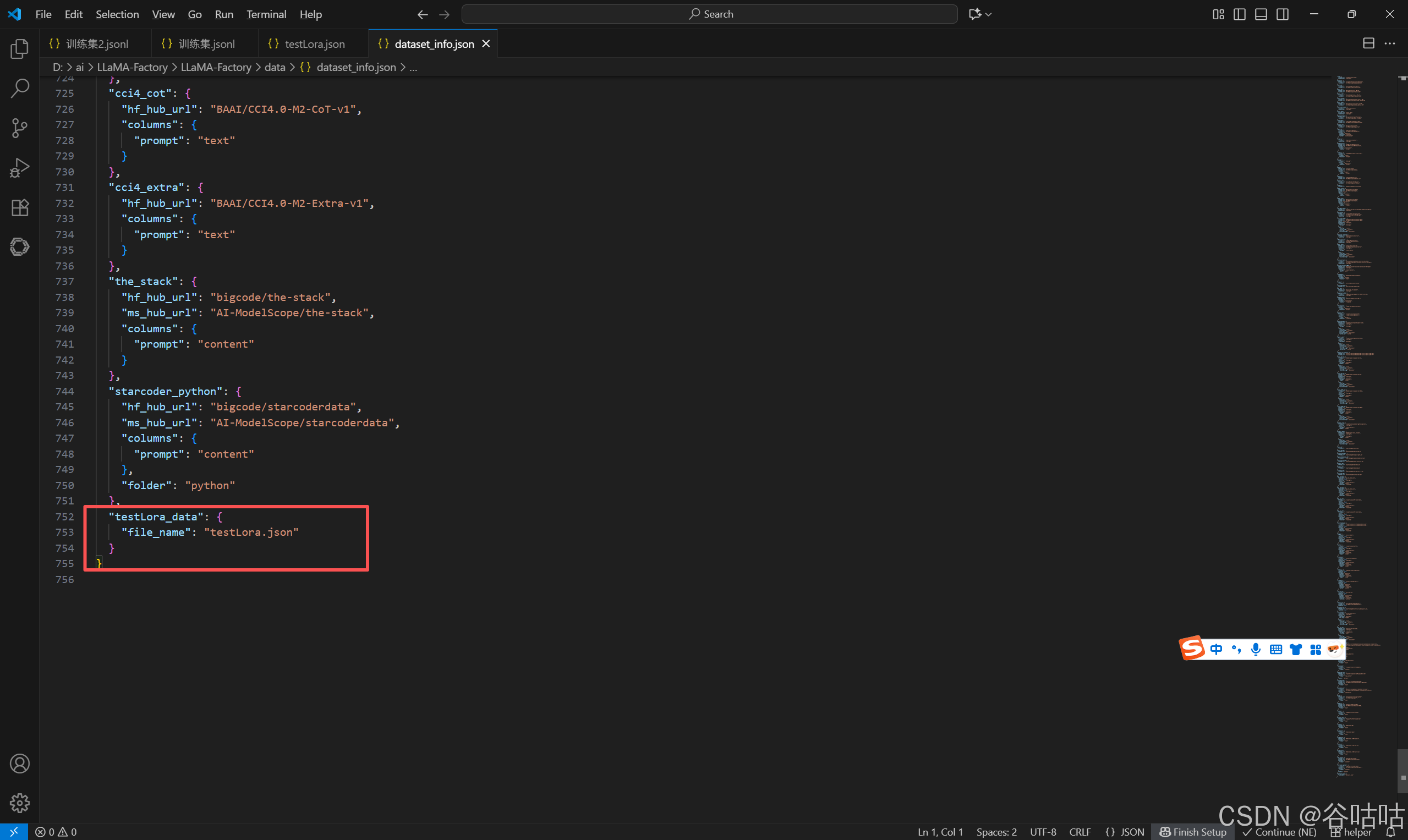
然后去修改,dataset_info.json 文件,加一个类似目录的东西。拉到最下面,增加一段。
bash
"testLora_data": {
"file_name": "testLora.json"
}
}
这样就可以选择开始训练了。
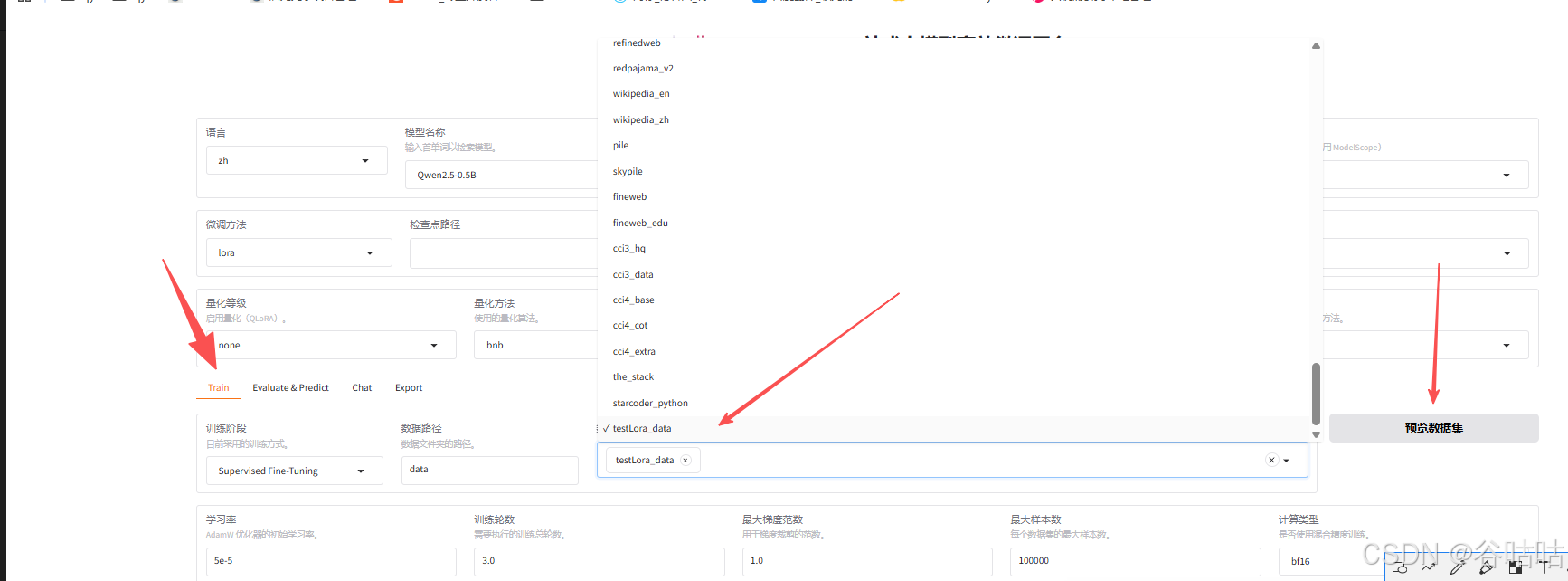
预览数据
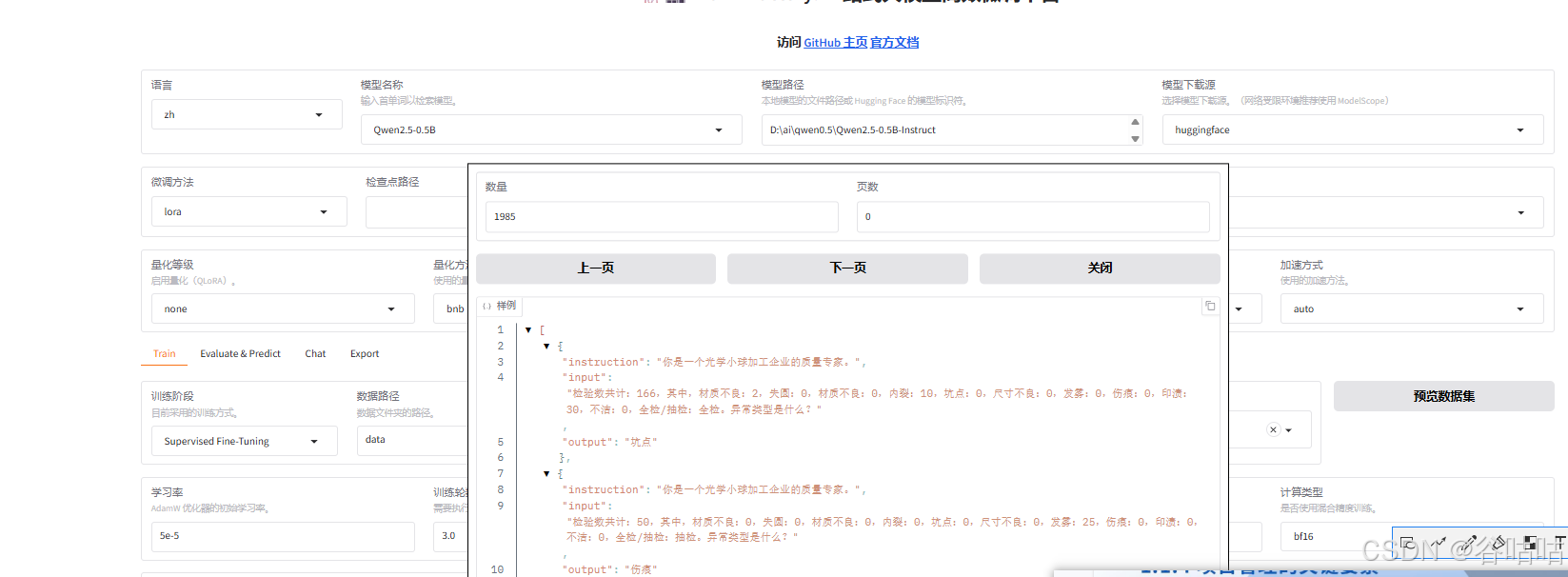
输出目录是默认的,点击开始训练即可。
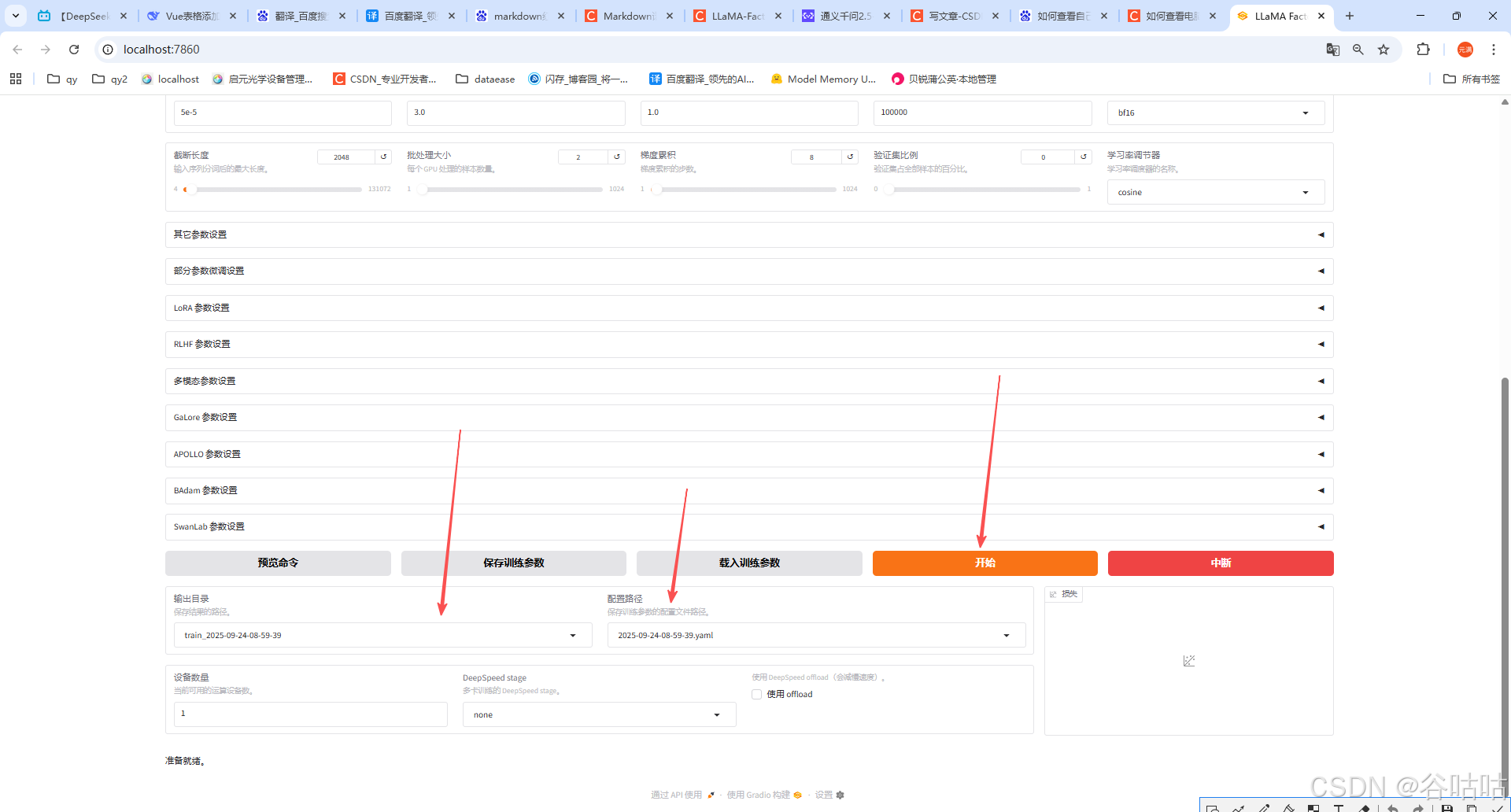
也可以点击预览命令,将命令复制到终端中执行。
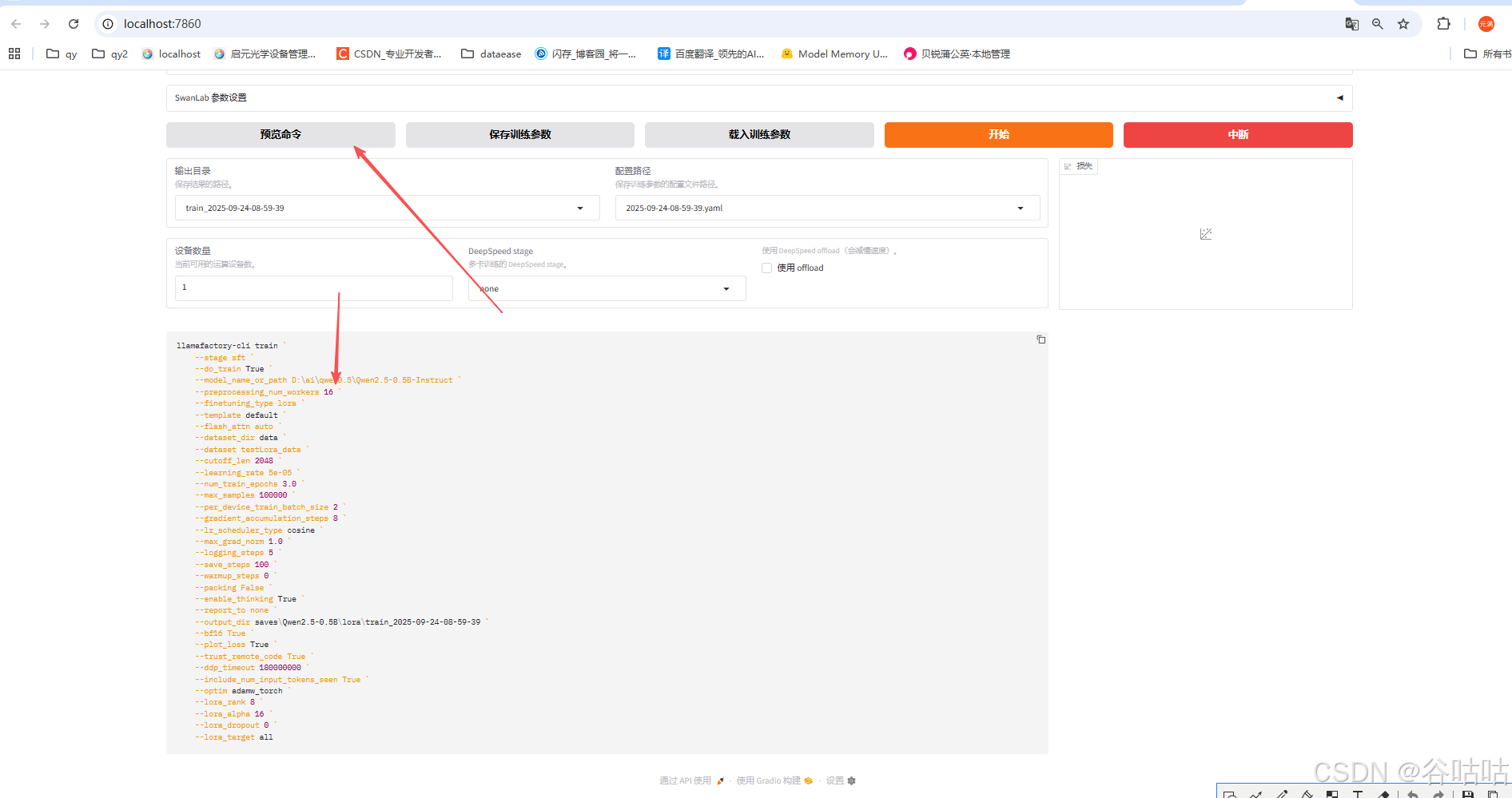
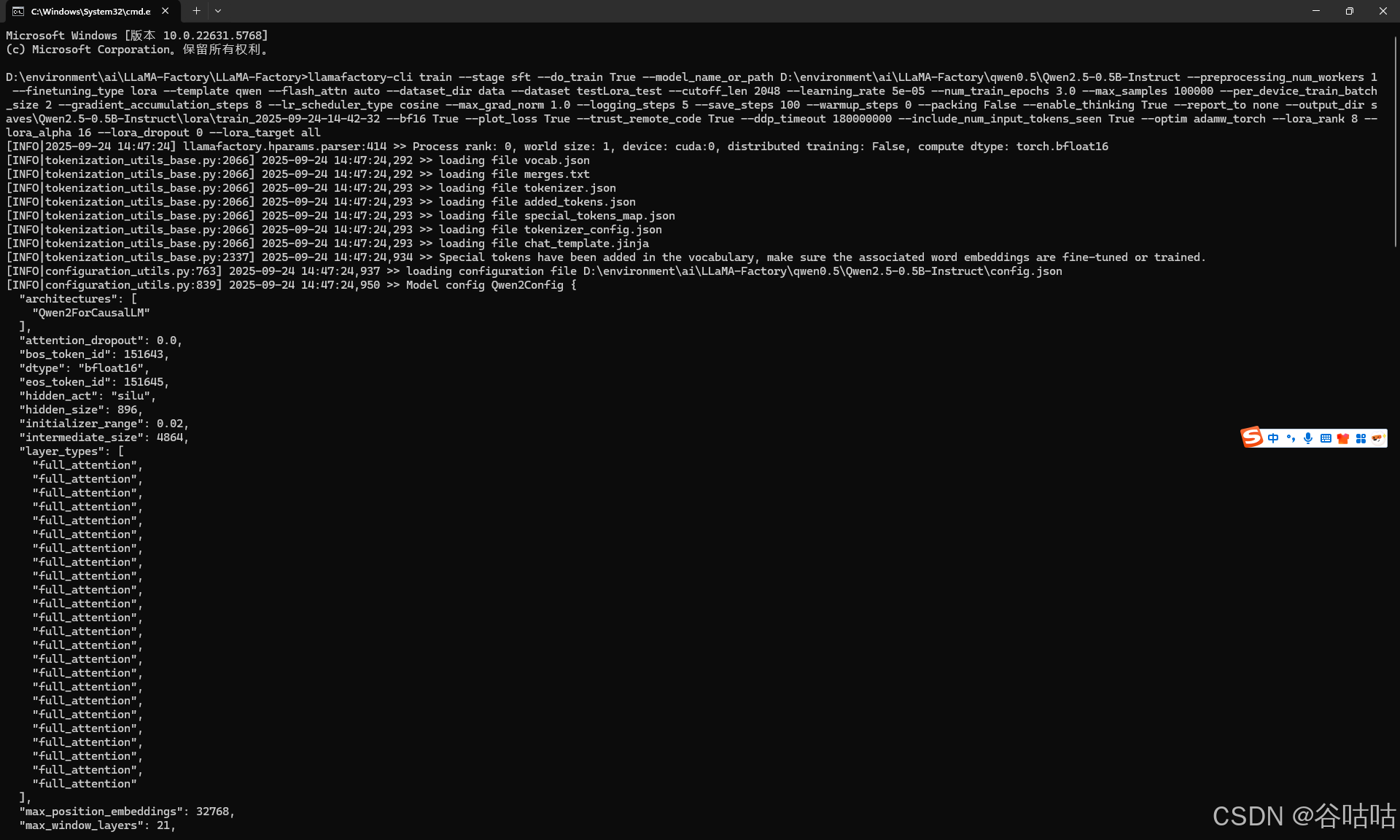
这里特别需要注意,如果直接点击开始。那么你的数据集只有10条左右的时候,没什么问题。但是如果数据多了,就会报错,提示训练失败,大概是内存溢出。我查阅了质料是,因为windows下执行用1条线程执行。
所以数据量多的话,你必须在终端中执行命令,并且将上面的16 改为1.然后运行。
(命令复制下来,你可以让deepseek,帮你把换行去掉,不然没法行,当然你自己手动放在一行也行,如果你不嫌麻烦的话。)
漫长等待
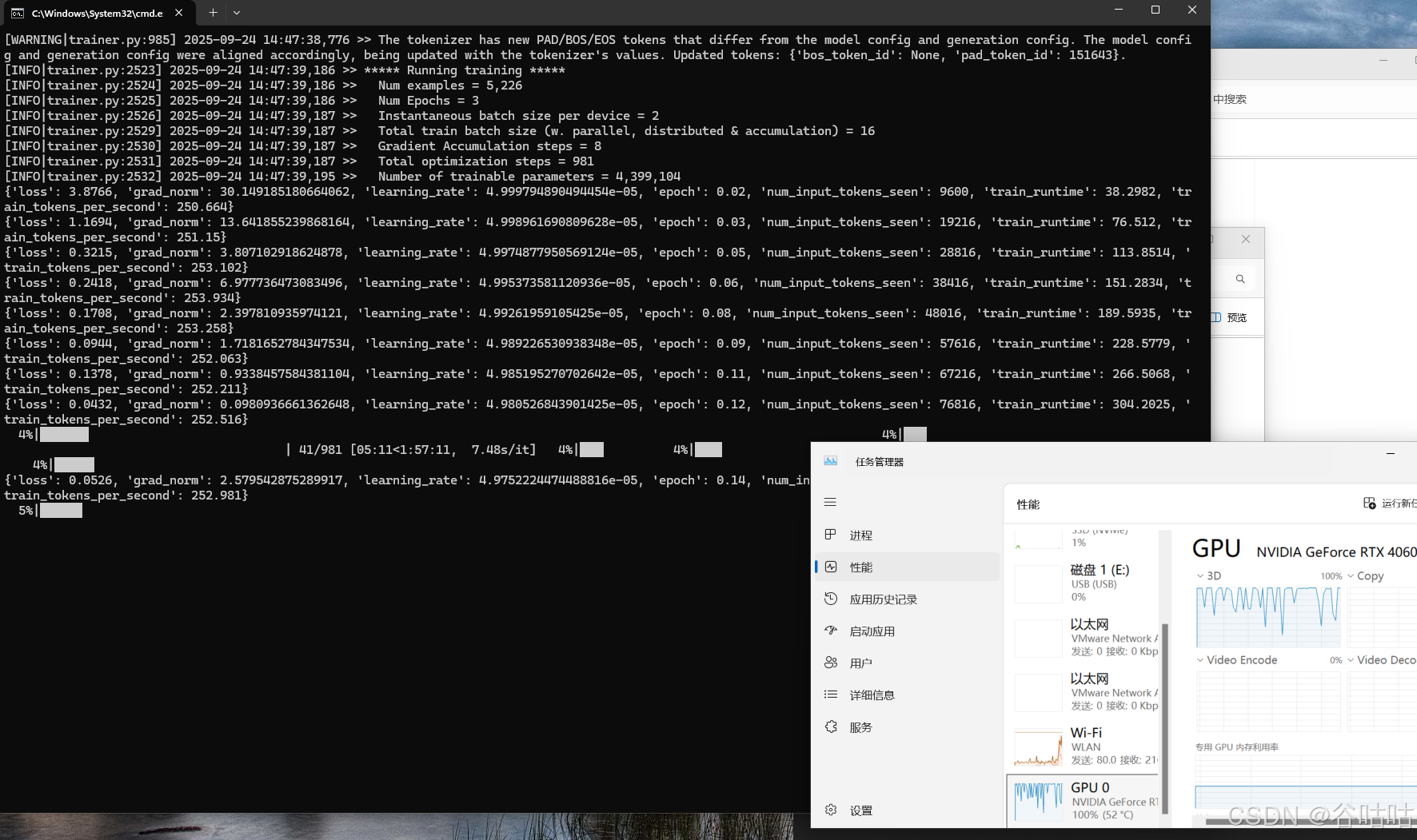
5.4导出模型
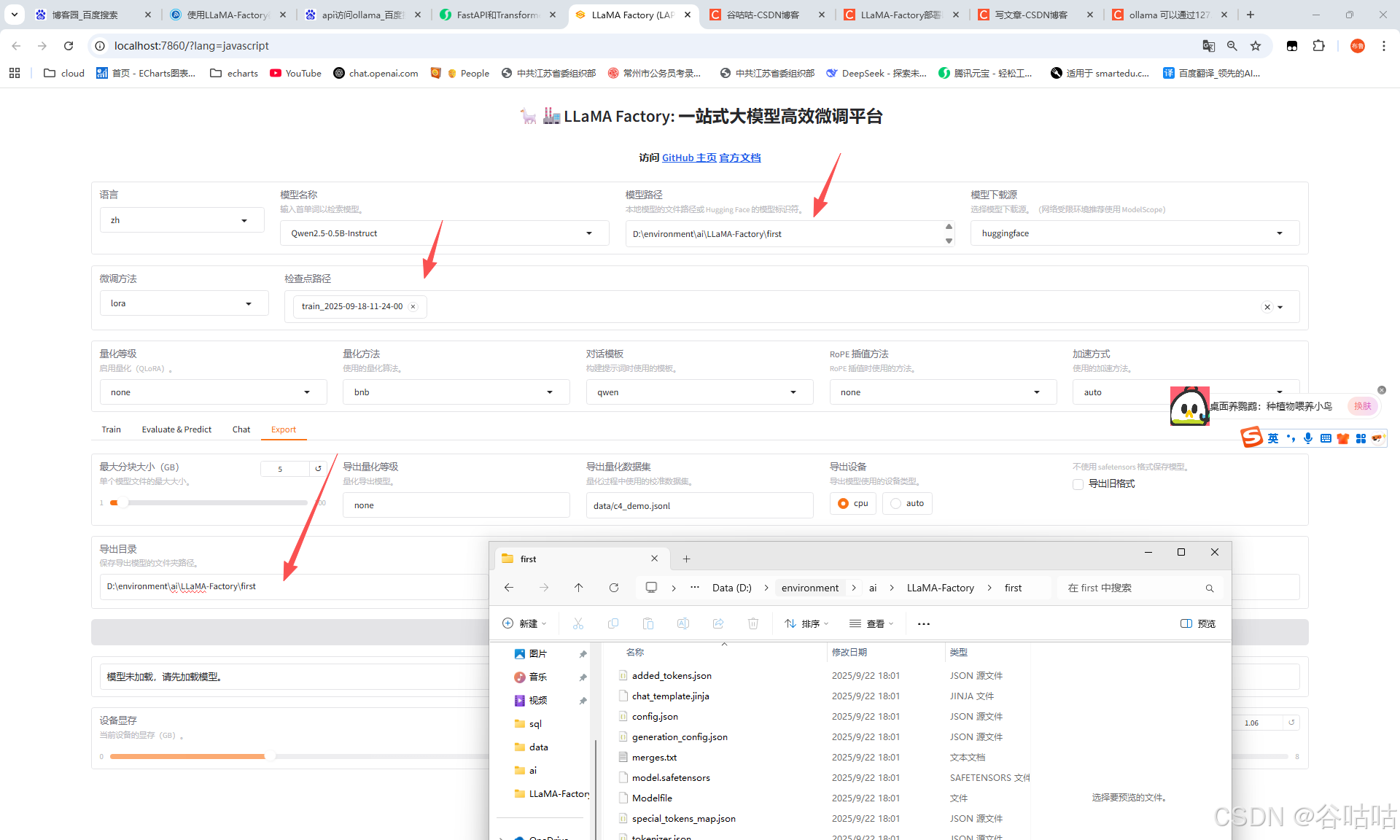
这里我换了台电脑,所以读者看可能,目录不一致了。 其实我们只需要选择检查点和导出目录。这样就可以导出模型了。我这里导出到了firs文件夹。
5.4对话测试
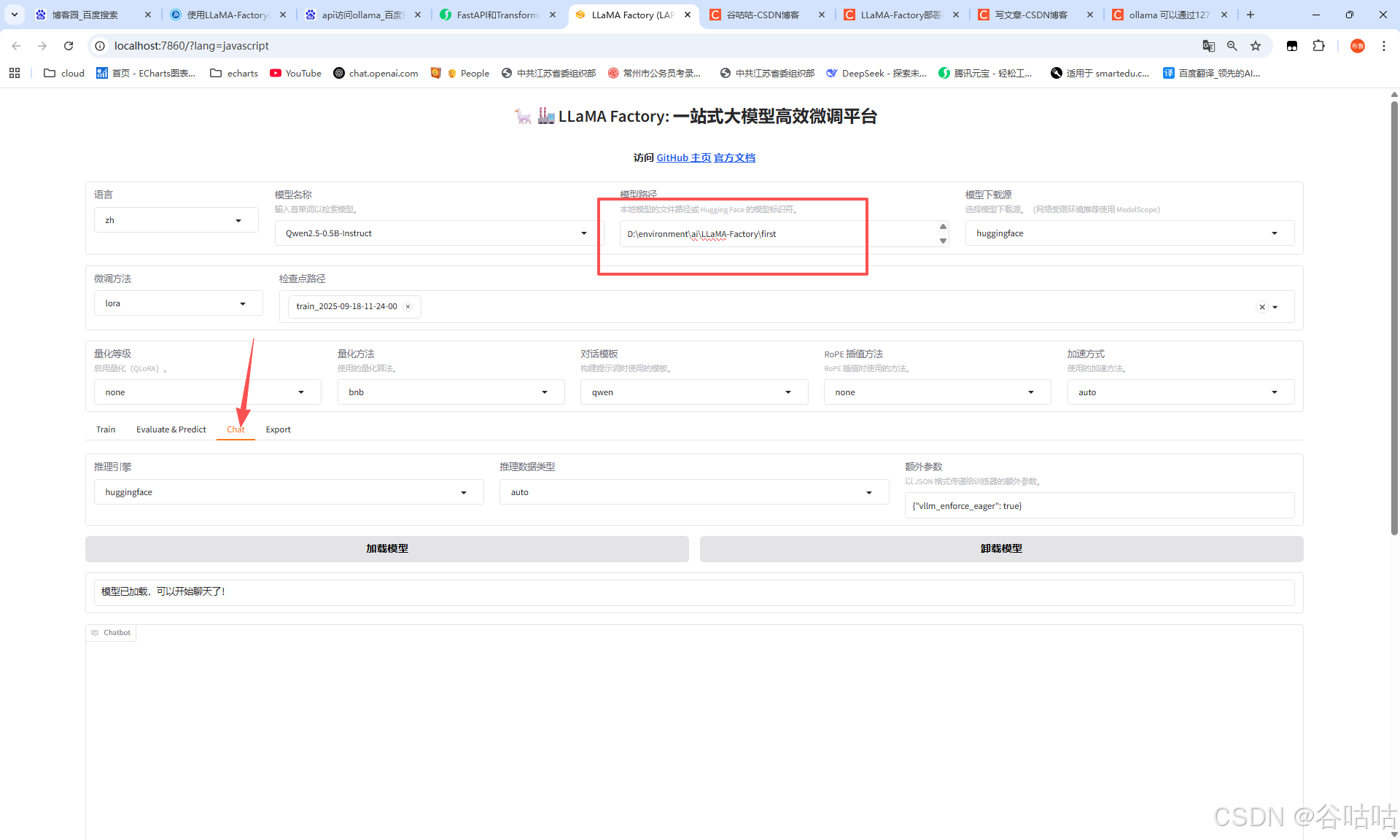
在线使用训练好的模型,我们在chat下,选择刚才导出的模型,就可以开始对话,微调后的模型
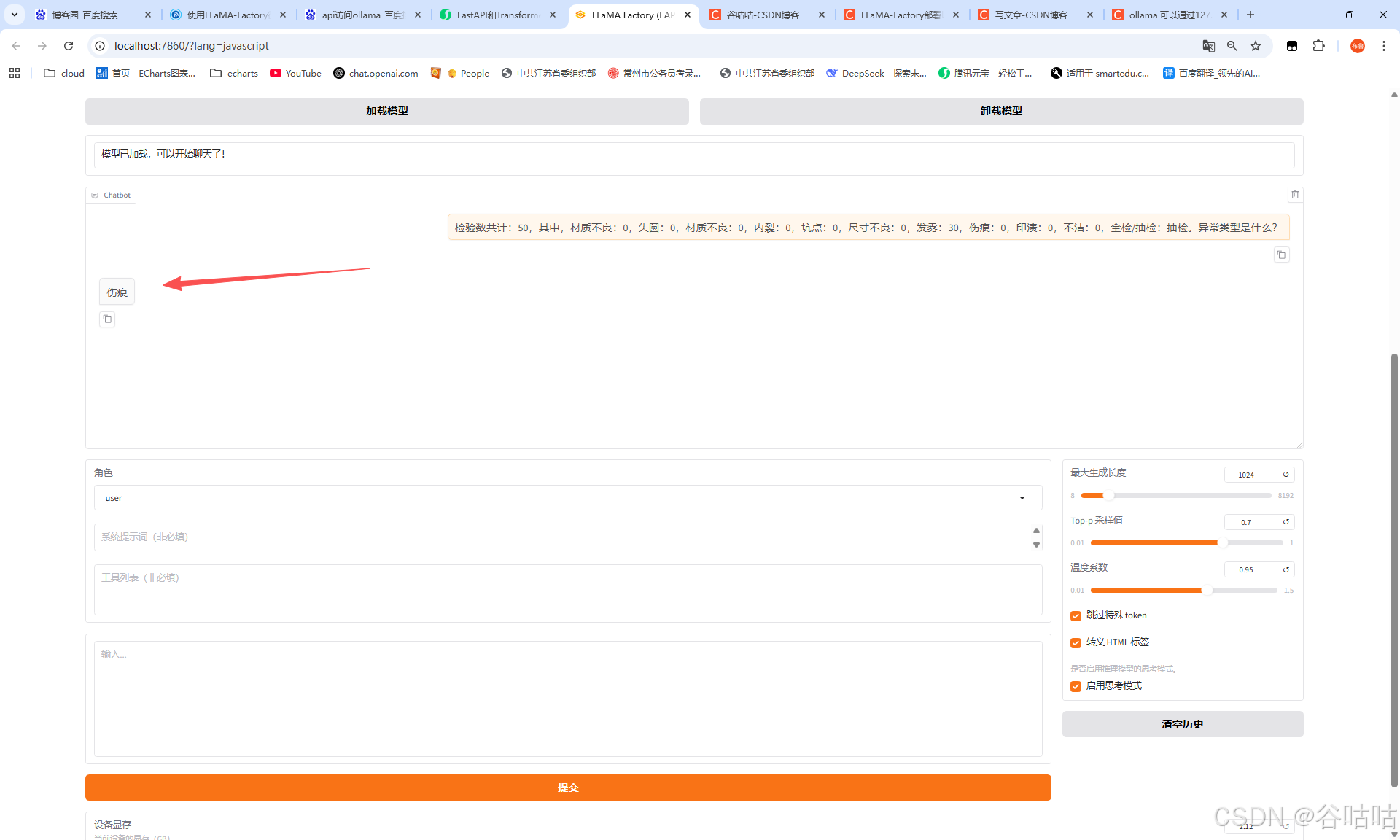
这样就显示它已经具备了特定行业的能力了。
6.Ollama运行
那么我们要将模型开发出api给,我们的其他系统程序调用。我这里用的是ollama,当然也可以用python有个fasapi,暴露出来。
ollama下载::https://ollama.com/download
ollama其实就是一个模型运行工具,客户端傻瓜式下载,然后在导出的文件夹firt下运行命令即可。
下载一个windows的,直接安装即可。
在first目录下进入cmd,执行下面的命令构建,和运行模型。
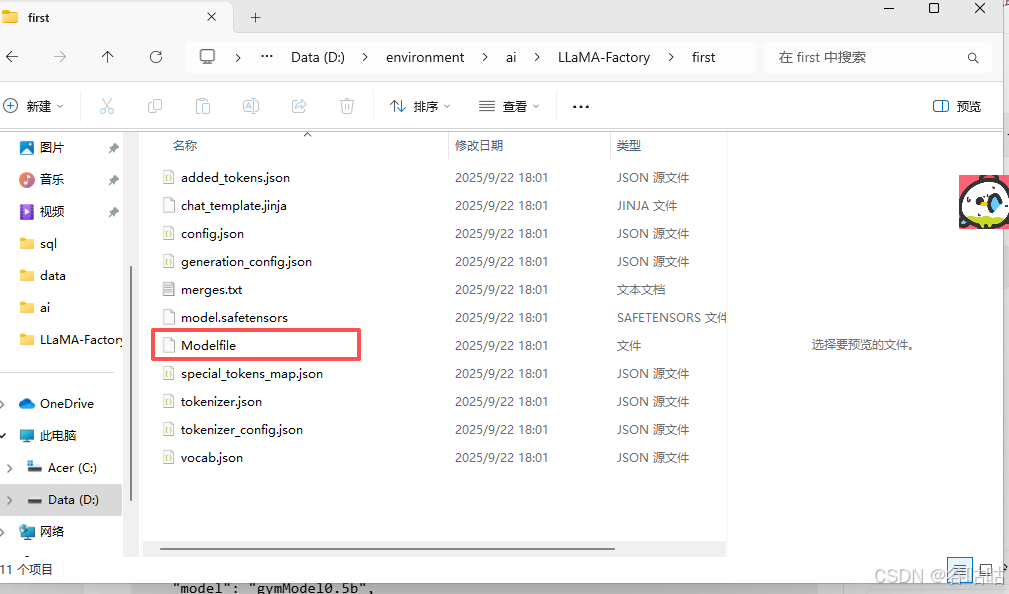
我这里构建过了,直接运行即可。
// 构建
ollama create gymModel0.5b -f Modelfile
// 运行
ollama run gymModel0.5b:latest这里使用Modelfile文件,我给模型取名gymModel0.5b,你也可以换成自己喜欢的。
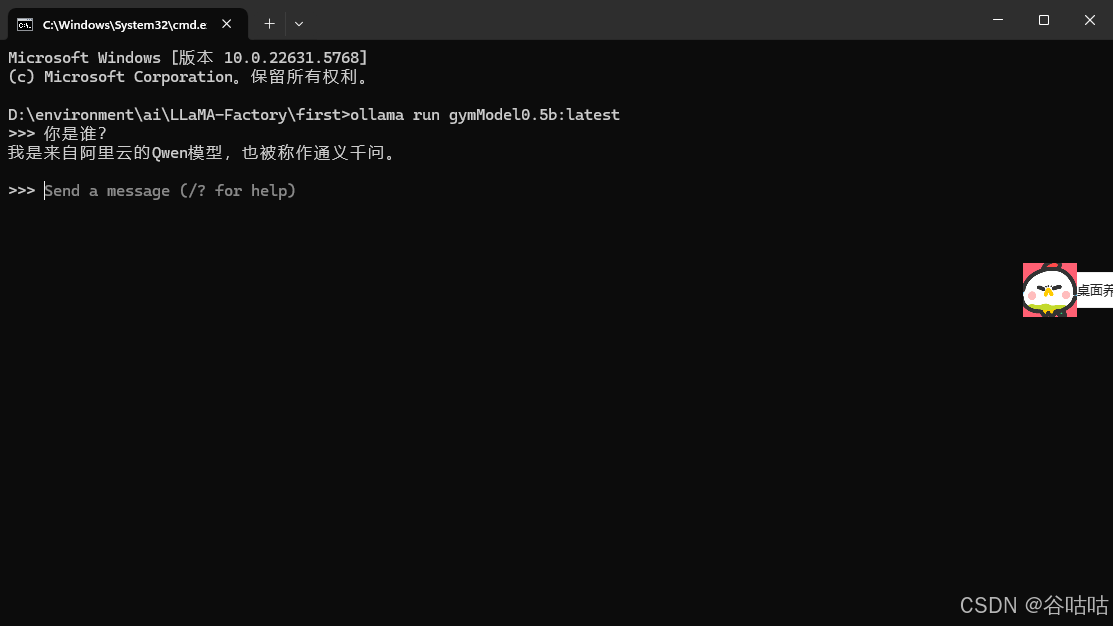
7.Postman调用 Ollama开放的接口
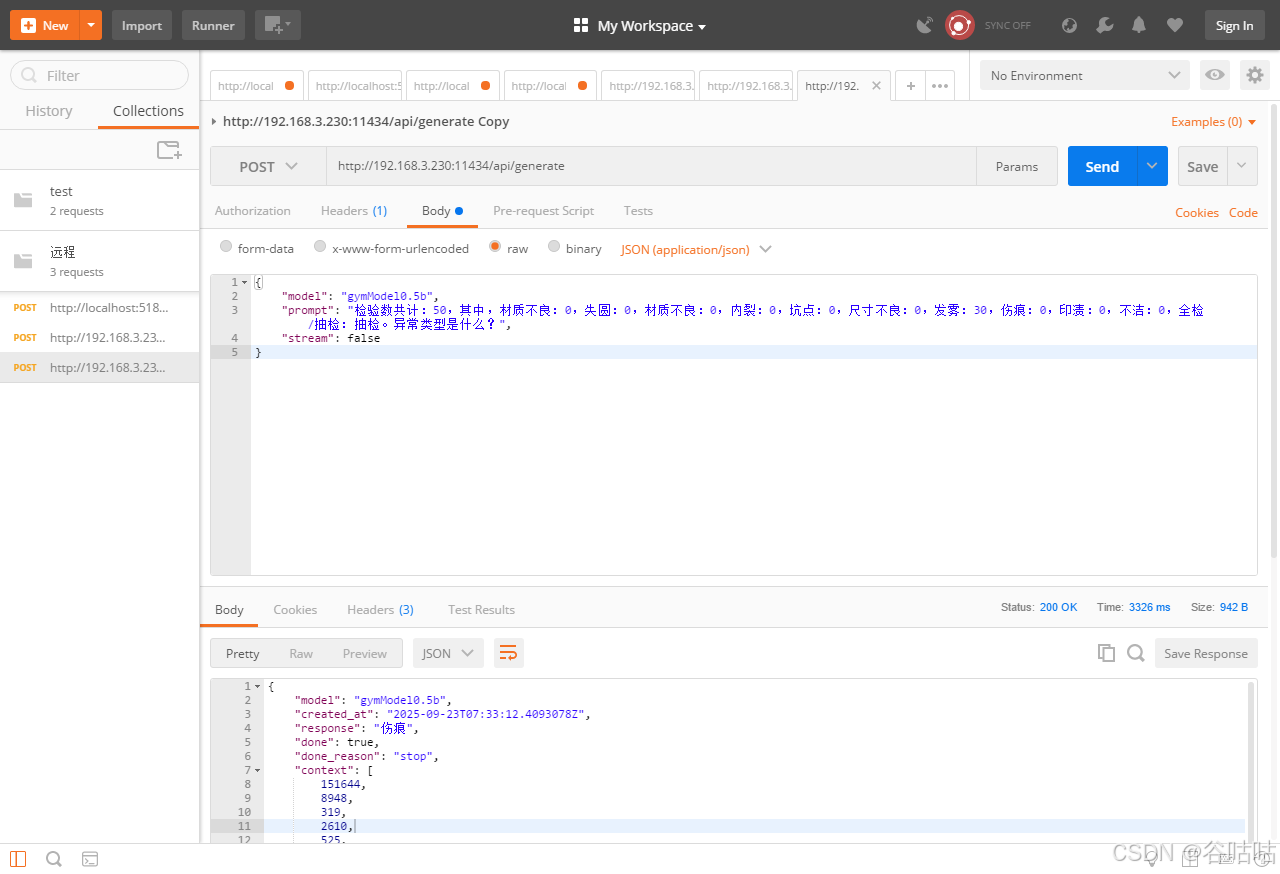
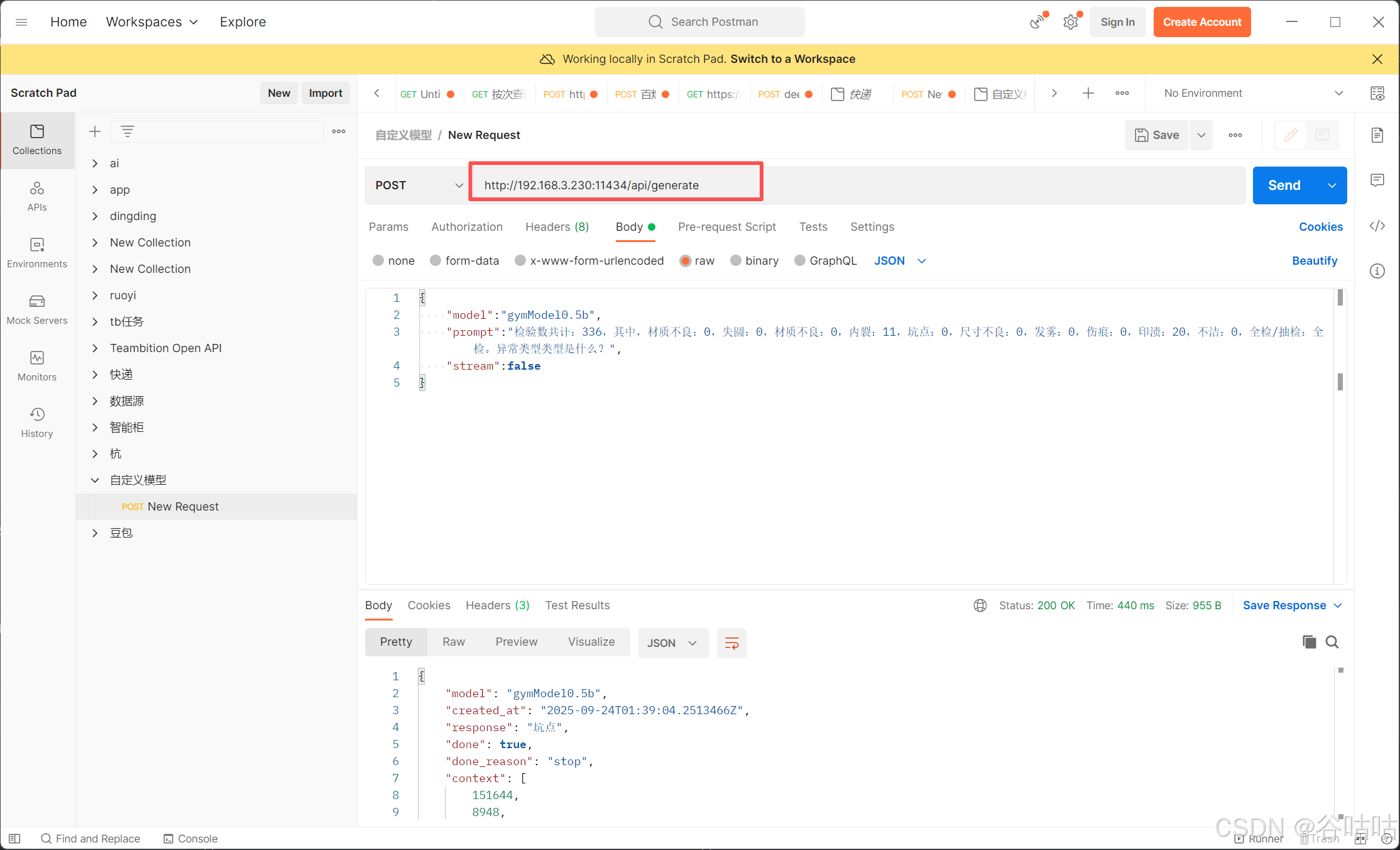
http://192.168.3.230:11434/api/generate
{
"model": "gymModel0.5b",
"prompt": "检验数共计:50,其中,材质不良:0,失圆:0,材质不良:0,内裂:0,坑点:0,尺寸不良:0,发雾:30,伤痕:0,印渍:0,不洁:0,全检/抽检:抽检。异常类型是什么?",
"stream": false
}
这里需要注意的是,ollama默认只能本机127.0.0.1访问,如果需要,内网其他电脑直接访问ip。需要配置环境变量。我这里是自己测试,开放了所以ip,也可以指定ip
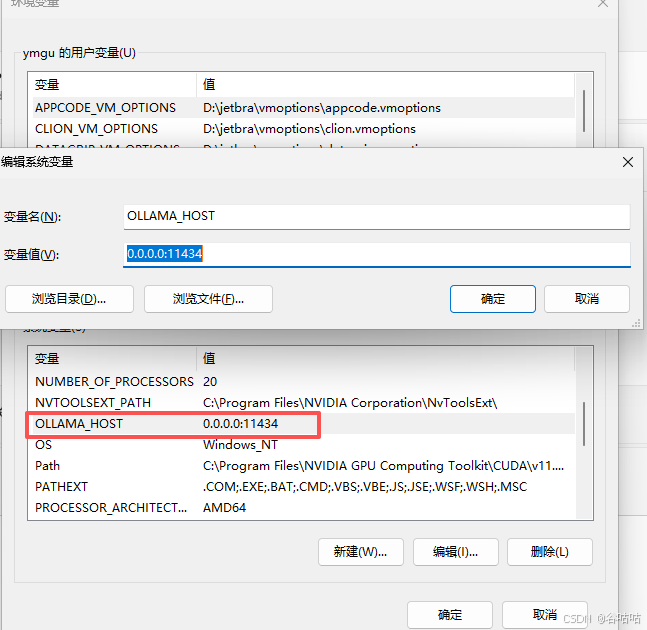
bash
http://192.168.3.230:11434/api/generate
bash
{
"model":"gymModel0.5b",
"prompt":"检验数共计:336,其中,材质不良:0,失圆:0,材质不良:0,内裂:11,坑点:0,尺寸不良:0,发雾:0,伤痕:0,印渍:20,不洁:0,全检/抽检:全检。异常类型类型是什么?",
"stream":false
}
8.java代码请求示例
嗯,这个response是我想要的。
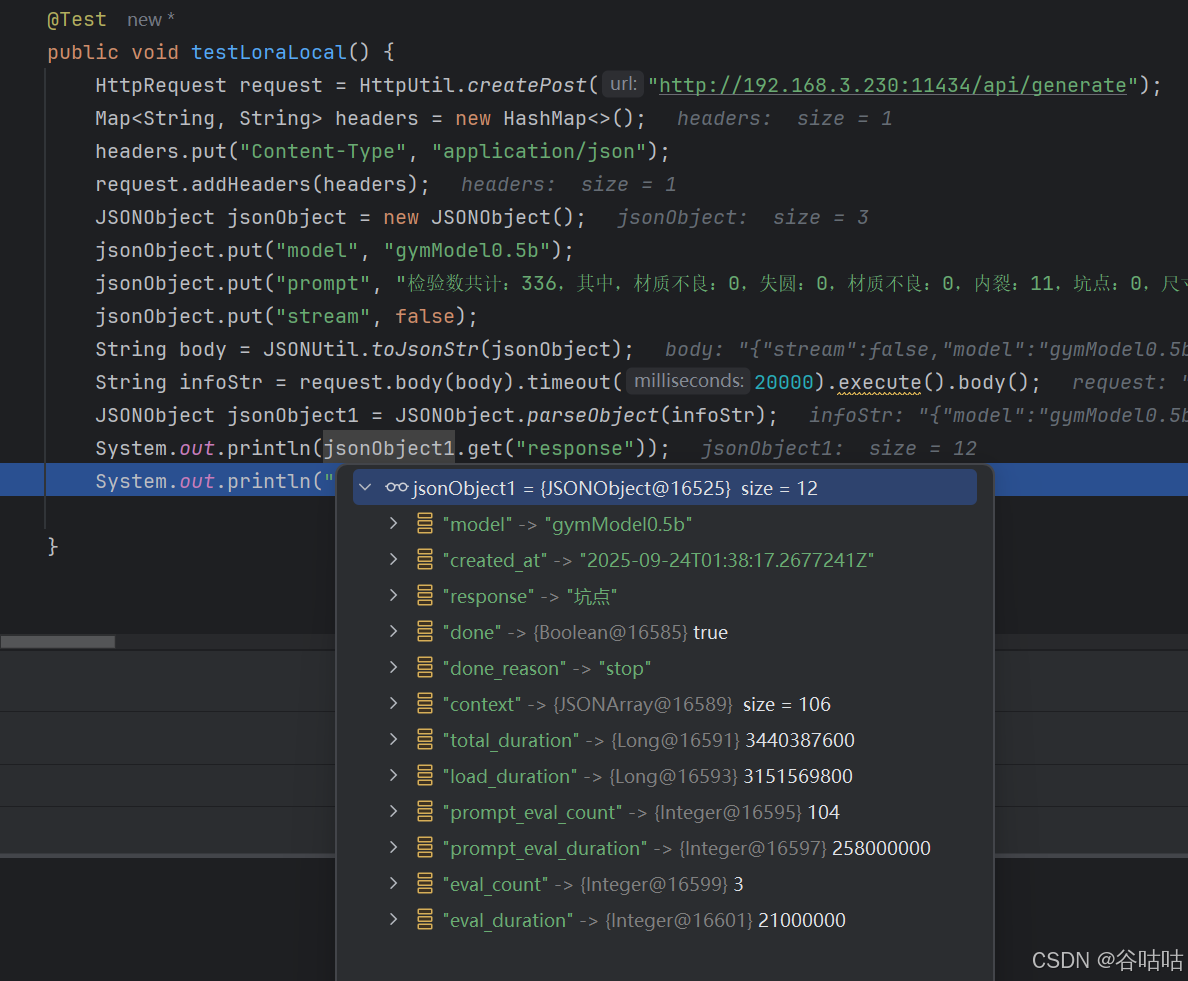
java
@Test
public void testLoraLocal() {
HttpRequest request = HttpUtil.createPost("http://192.168.3.230:11434/api/generate");
Map<String, String> headers = new HashMap<>();
headers.put("Content-Type", "application/json");
request.addHeaders(headers);
JSONObject jsonObject = new JSONObject();
jsonObject.put("model", "gymModel0.5b");
jsonObject.put("prompt", "检验数共计:336,其中,材质不良:0,失圆:0,材质不良:0,内裂:11,坑点:0,尺寸不良:0,发雾:0,伤痕:0,印渍:20,不洁:0,全检/抽检:全检。异常类型类型是什么?");
jsonObject.put("stream", false);
String body = JSONUtil.toJsonStr(jsonObject);
String infoStr = request.body(body).timeout(20000).execute().body();
JSONObject jsonObject1 = JSONObject.parseObject(infoStr);
System.out.println(jsonObject1.get("response"));
}到此结束,有什么不懂的,或者模糊的,欢迎评论区,留言,总结不易,也希望大家一键三连。