空间碎片的类型
MySQL 中的空间碎片主要分为两种类型:数据碎片 和索引碎片。
数据碎片
数据碎片是指表中的数据页(或数据块)中未被充分利用的空间。数据页是 MySQL 存储数据的基本单位,通常大小为 16 KB(对于 InnoDB 存储引擎)。
INSERT操作:插入数据时,如果插入的数据量较小,可能会导致数据页没有被完全填满,从而产生未使用的空间。DELETE操作 :删除数据时,被删除的数据行所占用的空间会变成未使用的空间。如果这些空间没有被后续的INSERT操作重新利用,就会形成碎片。UPDATE操作:如果更新操作导致数据行的大小发生变化(例如,从较短的字符串更新为较长的字符串),可能会导致数据行被移动到新的数据页,从而产生碎片。
索引碎片
索引碎片是指索引中的索引页(或索引块)中未被充分利用的空间。索引页是 MySQL 存储索引信息的基本单位,通常大小为 16 KB(对于 InnoDB 存储引擎)。
INSERT操作:插入数据时,如果插入的数据行导致索引页分裂,可能会产生未使用的空间。DELETE操作 :删除数据时,被删除的数据行所占用的索引空间会变成未使用的空间。如果这些空间没有被后续的INSERT操作重新利用,就会形成碎片。UPDATE操作:如果更新操作导致索引键值的变化,可能会导致索引页的重新组织,从而产生碎片。
碎片的危害
-
增加磁盘 I/O 操作:当存在存储碎片时,数据在磁盘上的存储位置变得分散。例如,一个查询原本只需要读取一个连续的数据块就能获取所需信息,但由于碎片的存在,数据可能分布在多个不连续的磁盘位置。这就导致数据库在执行查询操作时,需要多次进行磁盘 I/O 操作来读取分散的数据。对于频繁查询的数据库系统,大量的额外磁盘 I/O 会显著降低系统的整体性能。
-
降低存储效率:在 MySQL 中,缓冲池(如 InnoDB 缓冲池)用于缓存数据页和索引页,以减少磁盘 I/O。但是,碎片会使数据页和索引页在缓冲池中难以高效地缓存。由于碎片导致数据页不完整或部分空闲,缓冲池可能无法充分利用其空间来缓存完整的、经常使用的数据页。
-
造成磁盘空间浪费:存储碎片使得磁盘空间无法得到有效利用。这些碎片空间单个可能较小,但随着时间的推移和操作的积累,它们会占用大量的磁盘空间。例如,在一个数据库表空间中,由于数据的删除和更新操作产生了许多小碎片,这些碎片空间加起来可能占据了相当大的磁盘容量,但却无法被有效地用于存储新的数据。
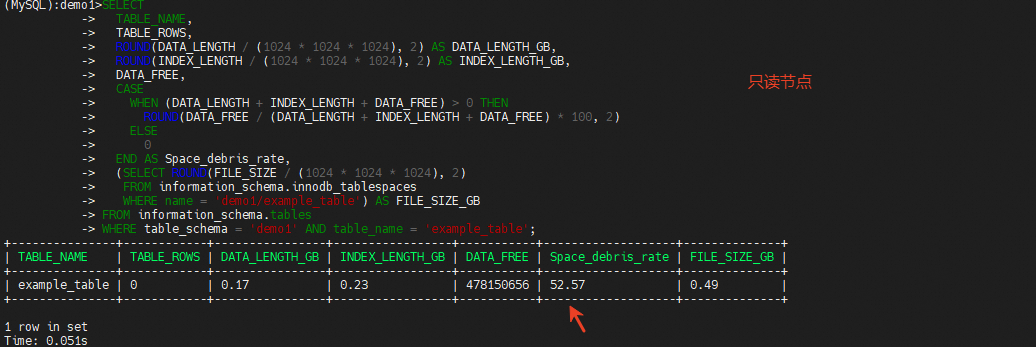
SELECT
TABLE_NAME,
TABLE_ROWS,
ROUND(DATA_LENGTH / (1024 * 1024 * 1024), 2) AS DATA_LENGTH_GB,
ROUND(INDEX_LENGTH / (1024 * 1024 * 1024), 2) AS INDEX_LENGTH_GB,
DATA_FREE,
CASE
WHEN (DATA_LENGTH + INDEX_LENGTH + DATA_FREE) > 0 THEN
ROUND(DATA_FREE / (DATA_LENGTH + INDEX_LENGTH + DATA_FREE) * 100, 2)
ELSE
0
END AS Space_debris_rate,
(SELECT ROUND(FILE_SIZE / (1024 * 1024 * 1024), 2)
FROM information_schema.innodb_tablespaces
WHERE name = 'demo1/example_table') AS FILE_SIZE_GB
FROM information_schema.tables
WHERE table_schema = 'demo1' AND table_name = 'example_table';
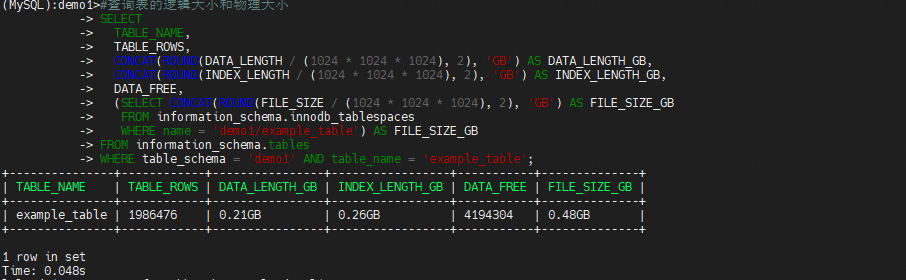
单个节点空间碎片率分析
创建example_table,然后使用存储过程插入2千万行数据
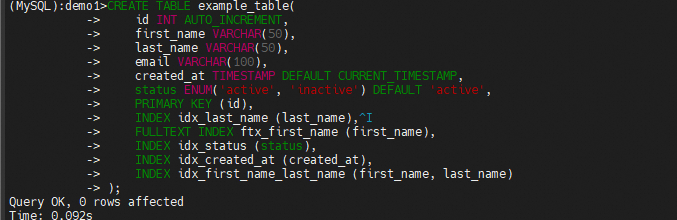
CREATE TABLE example_table(
id INT AUTO_INCREMENT,
first_name VARCHAR(50),
last_name VARCHAR(50),
email VARCHAR(100),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
status ENUM('active', 'inactive') DEFAULT 'active',
PRIMARY KEY (id),
INDEX idx_last_name (last_name),
FULLTEXT INDEX ftx_first_name (first_name),
INDEX idx_status (status),
INDEX idx_created_at (created_at),
INDEX idx_first_name_last_name (first_name, last_name)
);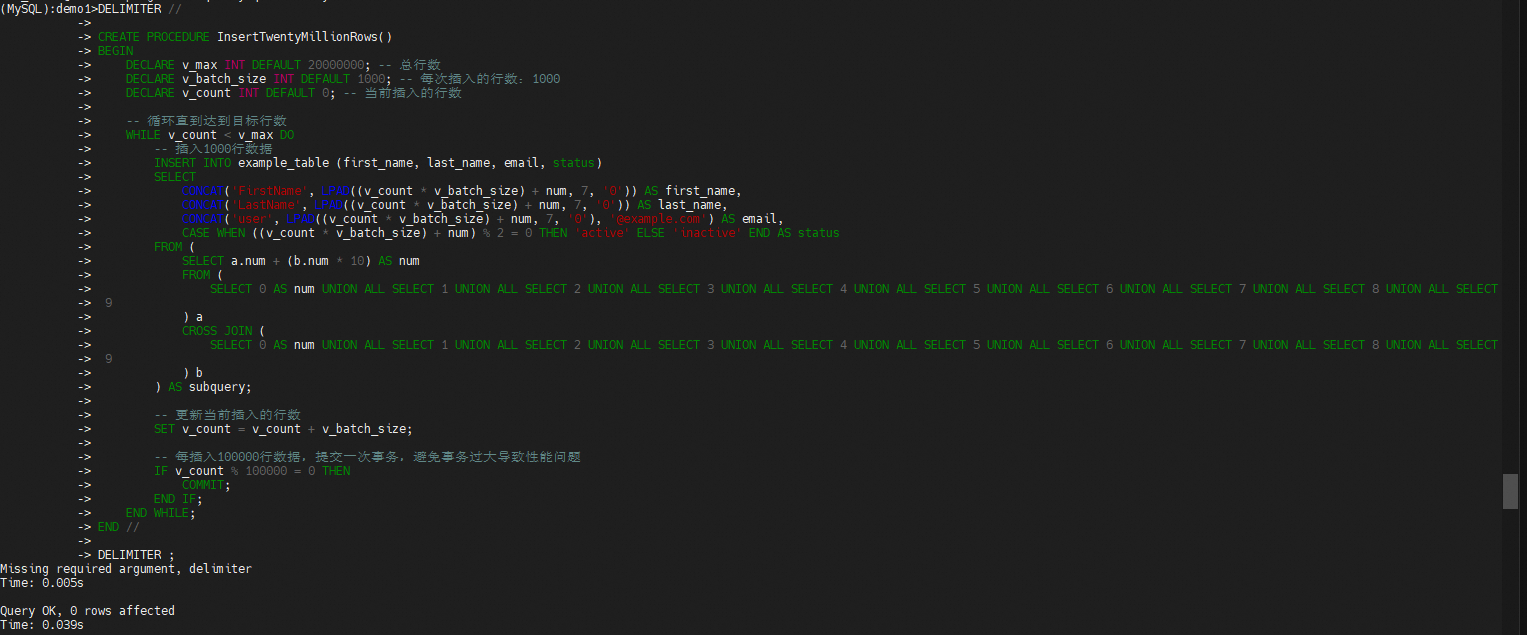
DELIMITER //
CREATE PROCEDURE InsertTwentyMillionRows()
BEGIN
DECLARE v_max INT DEFAULT 20000000; -- 总行数
DECLARE v_batch_size INT DEFAULT 1000; -- 每次插入的行数:1000
DECLARE v_count INT DEFAULT 0; -- 当前插入的行数
START TRANSACTION;
-- 循环直到达到目标行数
WHILE v_count < v_max DO
-- 插入1000行数据
INSERT INTO example_table (first_name, last_name, email, status)
SELECT
CONCAT('FirstName', LPAD((v_count * v_batch_size) + num, 7, '0')) AS first_name,
CONCAT('LastName', LPAD((v_count * v_batch_size) + num, 7, '0')) AS last_name,
CONCAT('user', LPAD((v_count * v_batch_size) + num, 7, '0'), '@example.com') AS email,
CASE WHEN ((v_count * v_batch_size) + num) % 2 = 0 THEN 'active' ELSE 'inactive' END AS status
FROM (
SELECT a.num + (b.num * 10) AS num
FROM (
SELECT 0 AS num UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9
) a
CROSS JOIN (
SELECT 0 AS num UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9
) b
) AS subquery;
-- 更新当前插入的行数
SET v_count = v_count + v_batch_size;
-- 每插入100000行数据,提交一次事务,避免事务过大导致性能问题
IF v_count % 100000 = 0 THEN
COMMIT;
START TRANSACTION;
END IF;
END WHILE;
COMMIT;
END //
DELIMITER ;
CALL InsertTwentyMillionRows();
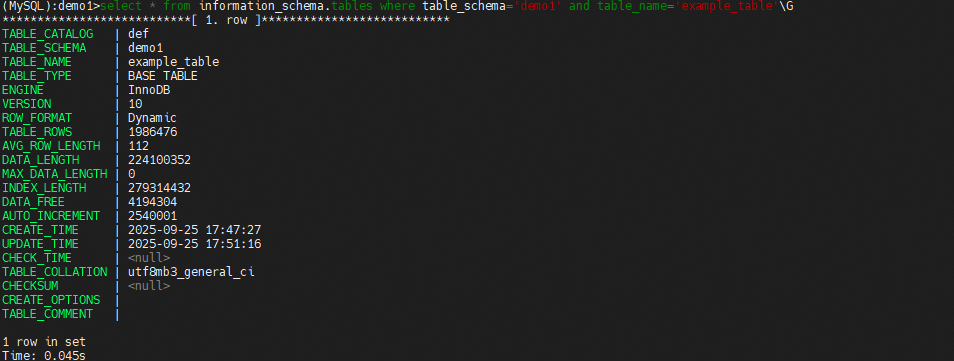
查看information_schema.tables表中的信息
delete删除表中的所有数据,并使用上述sql查看碎片率

再次查看information_schema.tables表中的统计信息,没有变化,使用analyze更新统计信息
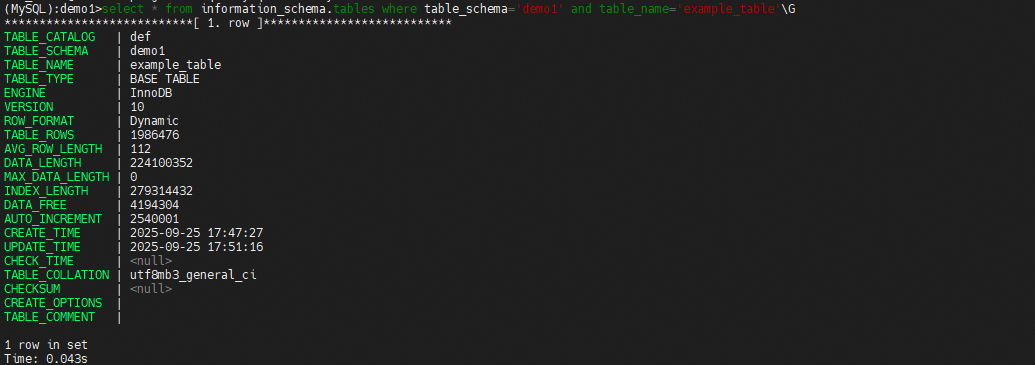

再次查看information_schema.tables表中的统计信息,发现已更新,这时在次使用上述sql查看碎片率,发现碎片率变到99.98%
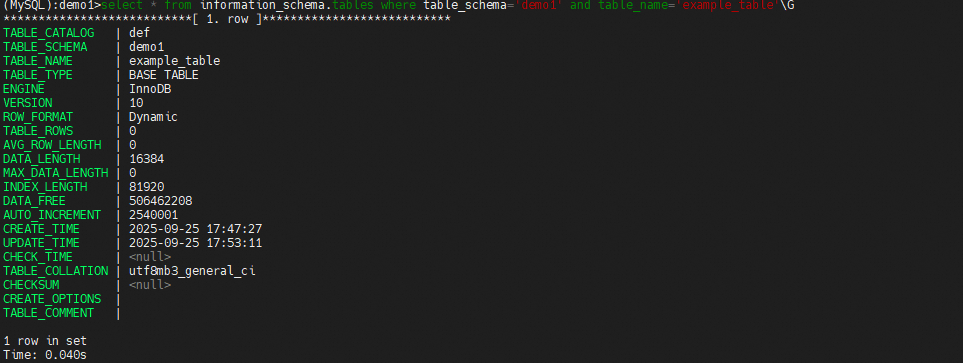
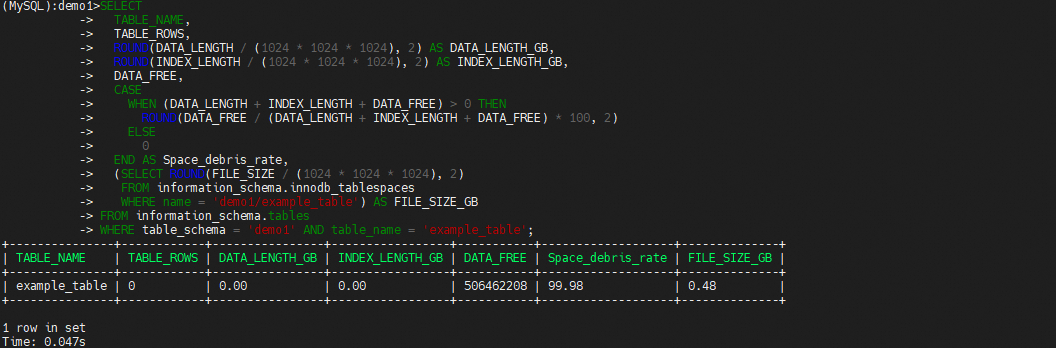
最后使用optimize重建表后发现碎片率归0

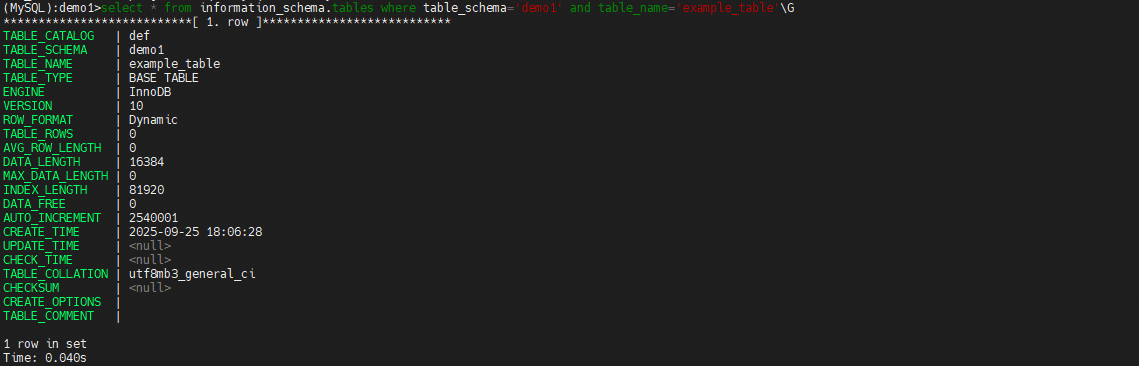
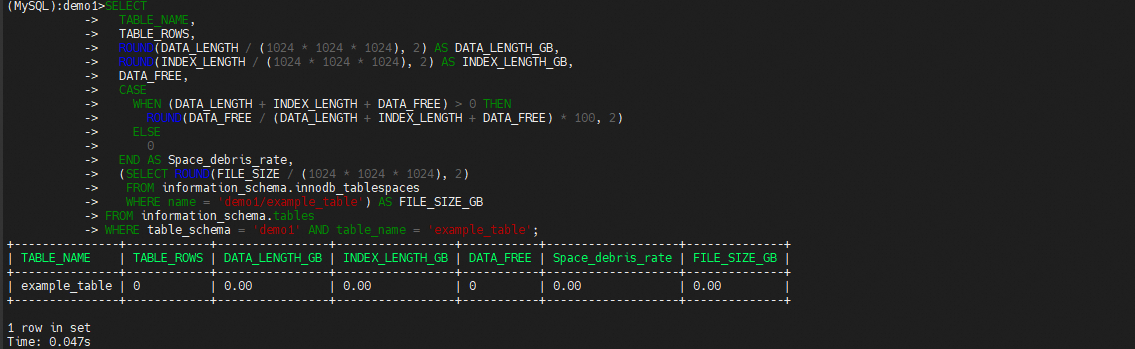
这里有时执行optimize后data_free并不会完全归零,这是因为InnoDB 存储引擎在表空间中预留了一部分空间,用于未来的插入操作。这是为了提高插入性能,避免频繁的页分裂。即使表空间被重新组织,InnoDB 也会保留这部分预留空间,因此 data_free 不会完全归零。当然除了预留空间外,还可能包括未使用的页、表空间的最小单位、并发操作以及存储引擎的限制。
表空间和页的概念
- 表空间(Tablespace) :InnoDB 使用表空间来存储数据和索引。表空间是由一个或多个文件组成的,这些文件可以是单个文件(如
ibdata1)或多文件表空间(如.ibd文件)。表空间是 InnoDB 存储数据和索引的基本单位。- 页(Page):页是表空间中存储数据和索引的基本单位,通常大小为 16 KB。每个页可以存储多行数据或索引条目。InnoDB 通过页来管理数据和索引的存储。
预留空间的目的
InnoDB 在表空间中预留一部分空间的主要目的是为了优化插入操作和减少碎片化。以下是具体原因:
提高插入性能
- 预留空间:当表中插入新数据时,InnoDB 会尝试将新数据插入到预留空间中。预留空间的存在减少了频繁分配新页的需要,从而提高了插入操作的效率。
- 减少页分裂:如果没有预留空间,插入操作可能会导致页分裂。页分裂是指一个页满了之后,InnoDB 会将页中的数据分成两部分,分别存储在两个新的页中。页分裂会增加碎片化,降低读写性能。预留空间可以减少页分裂的发生。
减少碎片化
- 减少未使用空间 :预留空间可以减少表空间中的未使用空间(
DATA_FREE)。通过预留一部分空间,InnoDB 可以更有效地利用表空间,减少碎片化的产生。- 优化存储管理:预留空间有助于优化表空间的存储管理,减少表空间的碎片化,提高存储效率。
主从节点空间碎片率分析
使用上述相同的方式插入2千万行数据,可以发现主节点和只读节点的空间碎片率和物理文件存在差异,
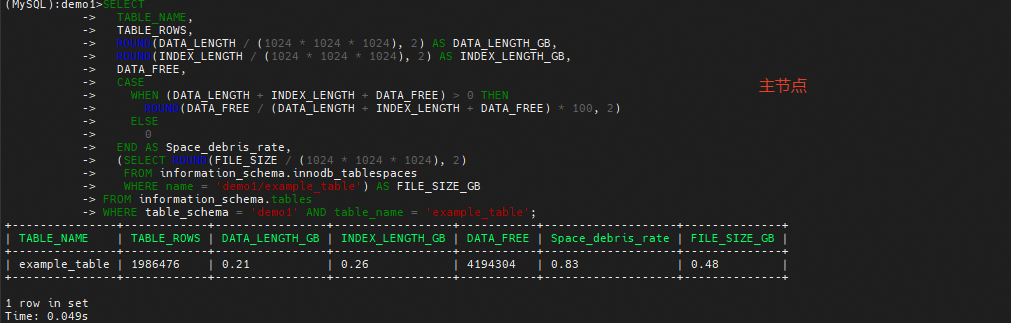
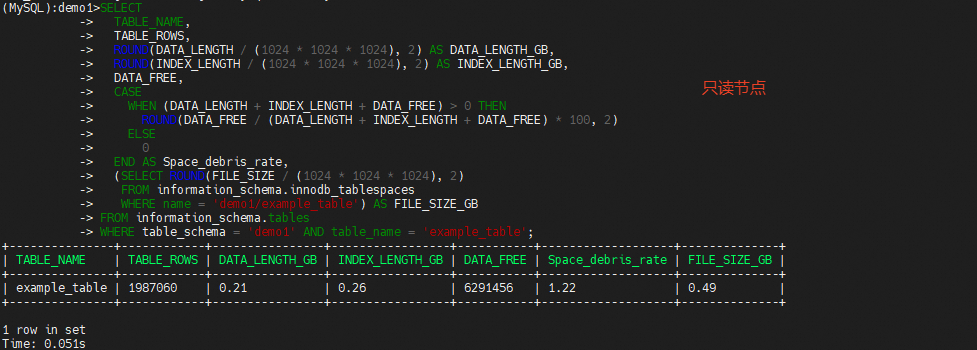
在主节点执行analyze更新统计信息

这时碎片率有所上升,但是主和只读还是不完全相等
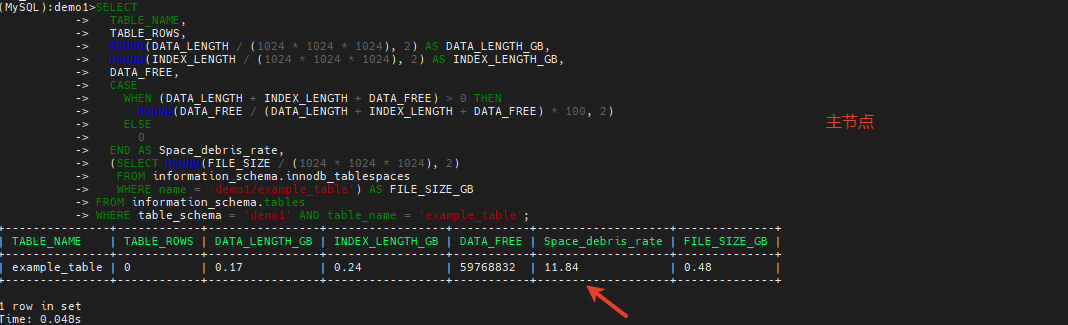
主库和只读实例的碎片率出现较大差异的原因分析
复制原理与多线程复制
- 逻辑复制原理:MySQL 的逻辑复制是基于二进制日志(binlog)的。主库将数据变更操作记录到 binlog 中,从库通过 I/O 线程读取主库的 binlog,并将其存储到本地的中继日志(relay log)中。然后,从库的 SQL 线程会读取 relay log 并应用这些变更。
- 多线程复制:为了提高复制效率,MySQL 支持多线程复制。在多线程复制中,从库可以使用多个 SQL 线程并行地应用 relay log 中的事件。这可以显著提高复制的性能,但也会引入一些复杂性。
多线程复制中的顺序问题
- 事务依赖性:在单线程复制中,SQL 线程会严格按照 binlog 中的顺序应用事件,确保数据的一致性。但在多线程复制中,多个 SQL 线程可能会并行地应用 relay log 中的事件。如果这些事件之间存在依赖关系(例如,一个
INSERT操作依赖于之前的某个DELETE操作),并行应用可能会导致顺序发生变化。 - 分组提交:MySQL 的多线程复制支持分组提交(Group Commit),即将多个事件分组后并行提交。虽然 MySQL 会尽量保证分组内的事件顺序,但不同分组之间的事件顺序可能会发生变化。
碎片率差异的原因
INSERT和DELETE操作顺序变化:如果只读实例的INSERT和DELETE操作顺序与主库不同,可能会导致数据分布和索引结构的变化。例如,主库中先执行了一个DELETE操作,然后执行了一个INSERT操作,而只读实例中这两个操作的顺序相反,这可能会导致只读实例中的数据碎片率增加。- 索引维护差异:
INSERT和DELETE操作会影响索引的维护。如果操作顺序不同,索引的分裂和合并操作也会不同,从而导致索引碎片率的差异。 - 并发写入和删除:在多线程复制中,多个线程可能会同时对同一个表进行写入和删除操作。如果这些操作的顺序不一致,可能会导致数据页的碎片化。例如,一个线程在某个数据页中插入了大量数据,而另一个线程在同一个数据页中删除了部分数据,这可能会导致数据页的碎片化。