awr快照默认每小时抓取1次,生成awr报告则通常时间跨度为1小时,如果想看1天的每小时的awr则需要手工一个个生成,选择开始快照号和截止快照号,可考虑用以下方法批量生成。
先查看当前有哪些时间的快照
sql
set linesize 300
col snap_id for 99999999
col dbid for 99999999999
col startup_time for a20
col begin_interval_time for a20
col end_interval_time for a25
alter session set NLS_TIMESTAMP_FORMAT='yyyy-mm-dd hh24:mi:ss';
select dbid,instance_number inst_id,snap_id,begin_interval_time,end_interval_time,startup_time
from dba_hist_snapshot order by 1,2,3;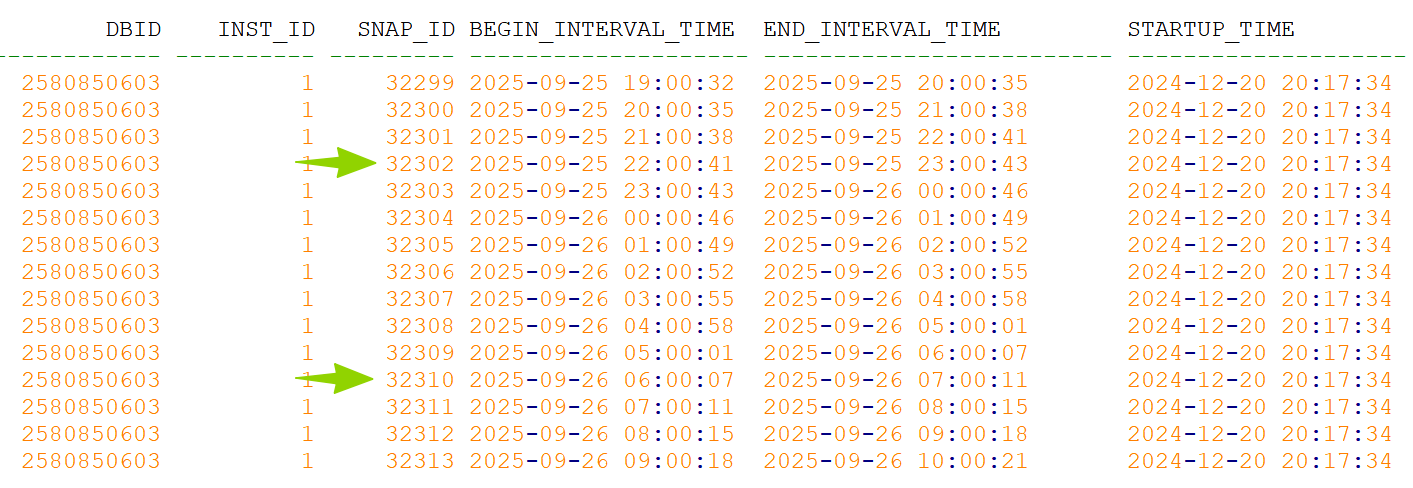
脚本内容如下:
sql
--------------------------------------------------------------------------------
/*
set linesize 300
col snap_id for 99999999
col dbid for 99999999999
col startup_time for a20
col begin_interval_time for a20
col end_interval_time for a25
alter session set NLS_TIMESTAMP_FORMAT='yyyy-mm-dd hh24:mi:ss';
select dbid,instance_number inst_id,snap_id,begin_interval_time,end_interval_time,startup_time
from dba_hist_snapshot order by 1,2,3;
*/
-- 用法:
-- @awrbatch <dbid> <instance_num> <start_snap> <end_snap>
--
-- 示例:
-- @awrbatch 2580850603 1 32302 32310
--
--------------------------------------------------------------------------------
set serveroutput on
set feedback off
declare
v_dbid number;
v_instance number;
v_b_id number;
v_e_id number;
v_code number;
v_errm varchar2(300);
v_sql varchar2(300);
v_html varchar2(20000);
cur_awrrpt_html SYS_REFCURSOR;
cur_snapshot SYS_REFCURSOR;
fileID utl_file.file_type;
v_filename varchar2(30);
v_snap_id number;
v_startup_time timestamp(3);
v_begin_snap_time timestamp(3);
v_end_snap_time timestamp(3);
v_dpath varchar2(60);
begin
v_dbid := &1;
v_instance := &2;
v_b_id := &3;
v_e_id := &4;
dbms_output.put_line(chr(13) || chr(10) || 'awrrpt report files:');
for k in v_b_id .. v_e_id - 1 loop
v_filename := 'awr_' || v_instance || '_' || k || '_' || (k + 1) ||'.html';
fileID := utl_file.fopen('DATA_PUMP_DIR', v_filename, 'a', 32767);
v_sql := 'select output from table(dbms_workload_repository.awr_report_html(' ||
v_dbid || ',' || v_instance || ',' || k || ',' || (k + 1) ||',8))';
open cur_awrrpt_html for v_sql;
loop
exit when cur_awrrpt_html%notfound;
fetch cur_awrrpt_html into v_html;
utl_file.put_line(fileID, v_html);
end loop;
utl_file.fclose(fileID);
execute immediate 'select directory_path from dba_directories where directory_name=:dname' into v_dpath using 'DATA_PUMP_DIR';
dbms_output.put_line(v_dpath || v_filename);
end loop;
exception
when others then
v_code := SQLCODE;
v_errm := SQLERRM;
dbms_output.put_line('ERROR CODE ' || v_code || ':' || v_errm);
end;
/生成的报告会输出到目录下
sql
select directory_path from dba_directories where directory_name='DATA_PUMP_DIR';