目录
[JVM 垃圾回收](#JVM 垃圾回收)
[一. 如何判断对象可以回收](#一. 如何判断对象可以回收)
[1. 引用计数法](#1. 引用计数法)
[2. 可达性分析算法](#2. 可达性分析算法)
[3. 四种引用](#3. 四种引用)
[二. 垃圾回收算法](#二. 垃圾回收算法)
[1. 标记清除算法](#1. 标记清除算法)
[2. 标记整理算法](#2. 标记整理算法)
[3. 复制算法](#3. 复制算法)
[三. 分代回收](#三. 分代回收)
[VM 相关参数](#VM 相关参数)
[四. 垃圾回收器](#四. 垃圾回收器)
[1. 串行垃圾回收器 (Serial GC)](#1. 串行垃圾回收器 (Serial GC))
[(1) 工作原理](#(1) 工作原理)
[(2) 优缺点](#(2) 优缺点)
[(3) 适用场景](#(3) 适用场景)
[2. 并行垃圾回收器 (Parallel GC)](#2. 并行垃圾回收器 (Parallel GC))
[(1) 工作原理](#(1) 工作原理)
[(2) 优缺点](#(2) 优缺点)
[(3) 适用场景](#(3) 适用场景)
[3. 并发垃圾回收器 (Concurrent GC)](#3. 并发垃圾回收器 (Concurrent GC))
[① CMS 垃圾收集器](#① CMS 垃圾收集器)
[(1) 工作原理](#(1) 工作原理)
[(2) 优缺点](#(2) 优缺点)
[(3) 适用场景](#(3) 适用场景)
[② G1 垃圾回收器](#② G1 垃圾回收器)
[(1) Region 分区](#(1) Region 分区)
[(2) 回收过程](#(2) 回收过程)
[4. 小结](#4. 小结)
[五. GC 调优](#五. GC 调优)
JVM 垃圾回收
一. 如何判断对象可以回收
1. 引用计数法
只要一个对象被引用一次, 则它的计数+1 (一个对象被引用多少次, 计数就是多少).
当一个对象的引用计数 == 0 时, 该对象就会被回收.
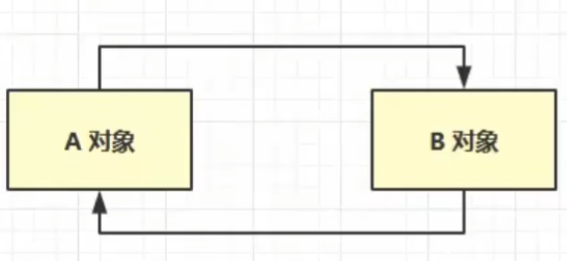
- 问题: 会出现循环引用.
如下图: A对象引用B对象, 同时B对象也引用A对象. 那么: A对象的引用计数 == 1 同时 B对象的引用计数也 == 1. 那么这两个对象永远不会被回收, 从而导致内存溢出问题.
2. 可达性分析算法
根对象 (GC Root): 肯定不能被当成垃圾 被回收 的对象, 就是根对象.
在垃圾回收之前, 会先对堆内存中所有对象进行一次扫描, 看每个对象是否被 GC Root 直接或间接引用 (能够沿着 GC Root 为起点的引用链找到该对象). 如果是, 这个对象就不能被回收 ; 如果不是, 这个对象就会被回收.
Memory Analyzer (MAT)
3. 四种引用
-
强引用
只有所有 GC Roots 对象都不通过【强引用】引用该对象, 该对象才能被垃圾回收.
-
软引用 (SoftReference)
仅有软引用引用该对象时,在垃圾回收后,内存仍不足时会再次触发垃圾回收,回收软引用对象
可以配合引用队列来释放软引用自身
-
弱引用 (WeakReference)
仅有弱引用引用该对象时,在垃圾回收时,无论内存是否充足,都会回收弱引用对象
可以配合引用队列来释放弱引用自身
-
虚引用 (PhantomReference)
必须配合引用队列使用,主要配合 ByteBuffer 使用,被引用对象回收时,会将虚引用入队,由 Reference Handler 线程调用虚引用相关方法释放直接内存
-
终结器引用 (FinalReference)
无需手动编码,但其内部配合引用队列使用,在垃圾回收时,终结器引用入队(被引用对象暂时没有被回收),再由 Finalizer 线程通过终结器引用找到被引用对象并调用它的 finalize 方法,第二次 GC 时才能回收被引用对象
二. 垃圾回收算法
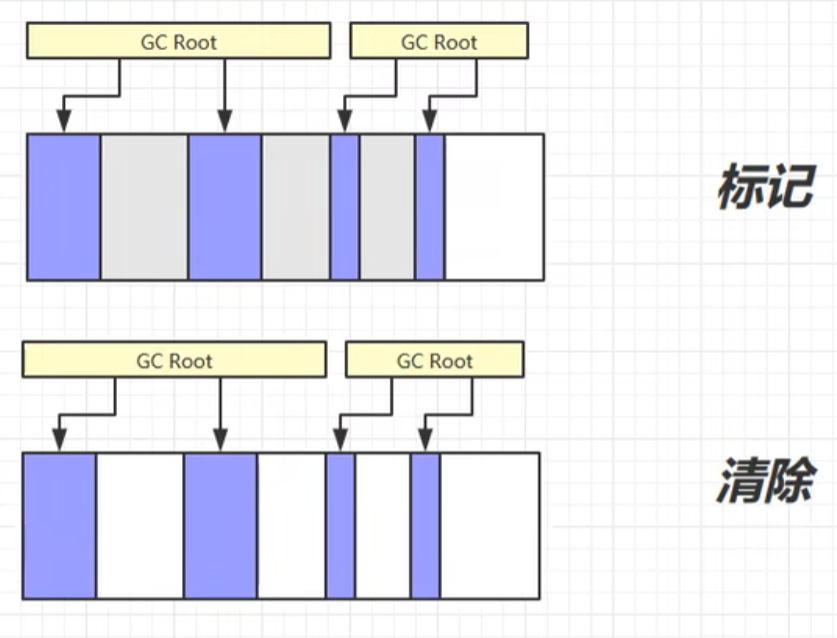
1. 标记清除算法
是最基础的垃圾回收算法, 分为 "标记" 和 "清除" 两个阶段, 用于识别并回收内存中的垃圾对象.
两个阶段:
- 标记出存活对象 --> 释放垃圾对象所占用的空间.
(1) 标记 : 将 能被 GC Roots 直接或间接引用到的对象 标记为 "存活对象", 剩余没有被标记到的对象就是 "垃圾对象".
(2) 清除: 遍历整个堆内存区域, 找到所有 "垃圾对象", 并将其内存块标记为 "空闲内存", 并更新空闲内存链表.
-
优点: 实现简单, 速度快.
-
缺点: 容易产生内存碎片 (很多不连续的内存空间).
2. 标记整理算法
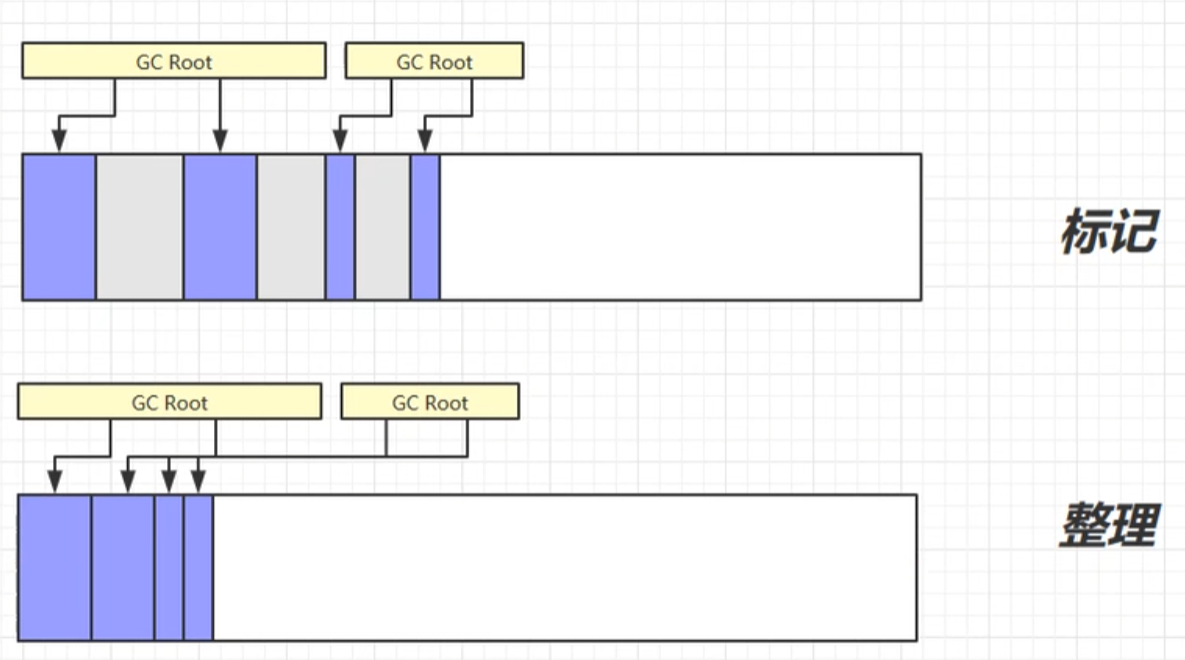
是在标记清除算法的基础上, ++针对其内存碎片化问题进行改进++ 的一种垃圾回收算法. 其核心过程分为 标记, 整理, 清除 三个阶段.
三个阶段:
- 标记出存活对象 --> 将存活对象移动到内存的一端, 避免内存碎片化 --> 释放垃圾对象占用的内存空间
(1) 标记 : 将 能被 GC Roots 直接或间接引用到的对象 标记为 "存活对象".
(2) 整理: 将所有存活对象移动到内存的一端, 另一端则是连续的空闲内存区域.
(3) 清除 : 直接将 ++除存活对象外的其他内存区域++ 标记为空闲.
-
优点: 解决了内存碎片问题.
-
缺点: 实现复杂, 速度慢, 在整理阶段要移动大量存活对象, 可能会导致程序暂停时间较长.
3. 复制算法
++复制算法++ 将可用内存按容量划分为大小相等的两块, 每次只使用其中的一块. 当这一块内存用完了, 就将还存活着的对象复制到另外一块上面, 然后再把已使用过的内存空间全部释放掉.
(1) 内存分区 : 将堆内存划分为两块大小相等的区域 (From 区 和 To 区). 其中, To 区 是空闲的.
(2) 标记: 标记出所有存活对象
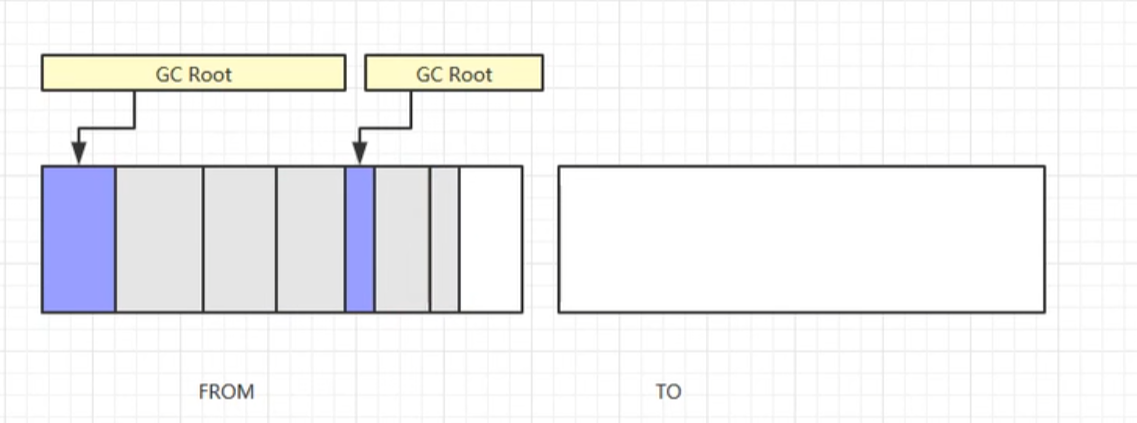
(3) 复制: 将所有存活对象复制到 To 区中.
(4) 清除: 清空 From 区.
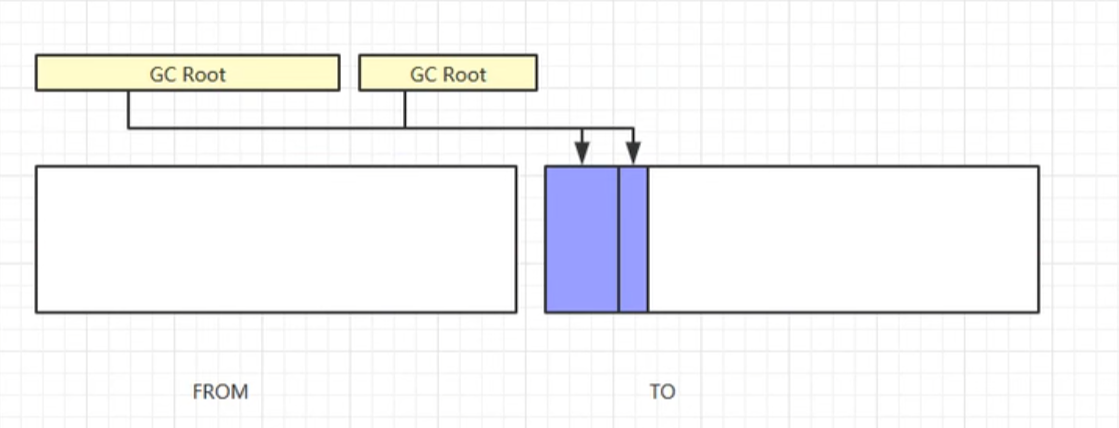
(5) 空间切换: 将 From 区 和 To 区 进行角色互换.
-
优点: 效率高, 速度快 且 无内存碎片问题.
-
缺点: 内存利用率低, 始终只有一半的内存空间可用, 造成了内存的浪费.
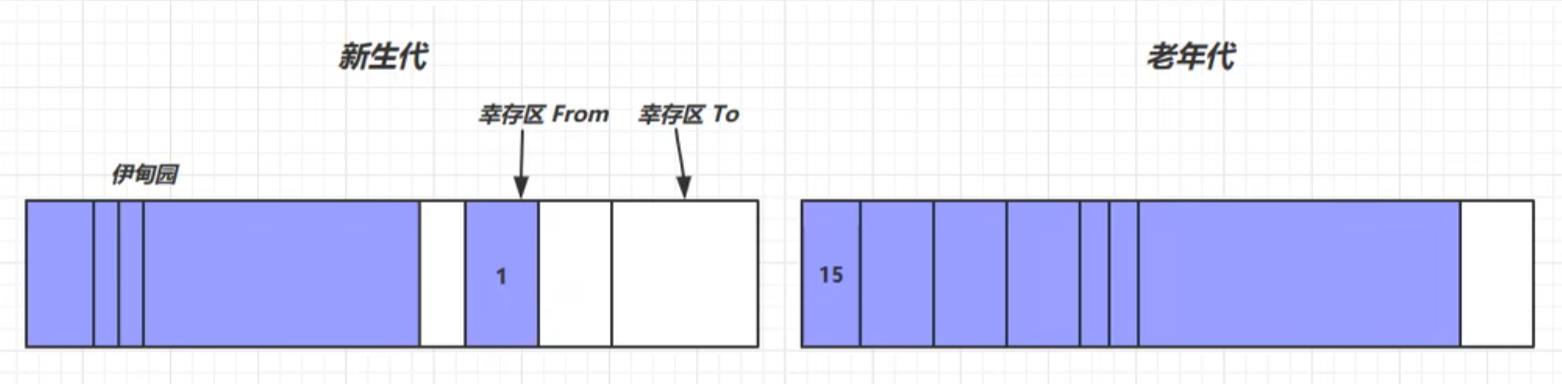
三. 分代回收
堆空间分为 新生代 和 老年代, 其中新生代又分为 伊甸园区, 幸存区 From 和 幸存区 To.
-
新创建的对象都分配在伊甸园区.
-
随着对象的增多, 新生代空间不足时, 就会触发 新生代垃圾回收 Minor GC (采用复制算法), 伊甸园区 和 From 区的存活对象会被复制到 To 区 (同时清空 from 区 和 伊甸园区). 然后 存活对象年龄+1, 并且 交换 From 区 和 To 区.
-
当新生代中存活对象的年龄达到一定阈值 (默认是15 (4bit 最大就能表示15)) 就会晋升到老年代中.
-
当老年代的内存空间不足时, 会先尝试触发一次 Minor GC. 如果 Minor GC 之后 空间仍不足, 就会触发 老年代垃圾回收 Full GC (采用标记清除法 或 标记整理法).
-
Minor GC 和 *Full GC 都会触发 STW (Stop The World): 暂停其它用户的线程, 等垃圾回收结束, 用户线程才恢复运行. 但是 Minor GC 的 STW 时间更短, Full GC 的 STW 时间更长.
注 : 为什么要先触发一次 Minor GC ? --> Minor GC 回收新生代垃圾后, 能减少 "新生代对象晋升到老年代" 的压力, 可能原本要晋升的对象被回收掉了, 这样要晋升到老年代的对象就少了, 间接缓解了老年代的内存压力.
注 : 为什么要 STW 暂停用户线程 ? --> 为了避免 GC 线程与用户线程同时操作对象, 从而导致引用关系混乱, 引发内存安全问题.
注 : 为什么 Full GC 的 STW 时间比 Minor GC 更长? --> ① 新生代的存活对象少, 采用复制算法复制这些存活对象时效率很高 ; 而老年代存活对象很多, 标记耗时很长. ② 老年代的空间通常是新生代的 2~3 倍, Full GC 要扫描的空间比 Minor GC 更大, 所以更慢.
注 : 大对象直晋升机制 --> 如果一个对象占用的内存空间很大, 超过了新生代的空间大小 (例如 大对象9M, 新生代空间8M), 那么此时这个大对象就会直接不经过新生代, 直接进入老年代.
VM 相关参数
| 含义 | 参数 |
|---|---|
| 堆初始大小 | -Xms |
| 堆最大大小 | -Xmx 或 -XX:MaxHeapSize=size |
| 新生代大小 | -Xmn 或 (-XX:NewSize=size + -XX:MaxNewSize=size) |
| 动态调整幸存区比例 | -XX:InitialSurvivorRatio=ratio 和 -XX:+UseAdaptiveSizePolicy |
| 幸存区比例 | -XX:SurvivorRatio=ratio |
| 晋升阈值 | -XX:MaxTenuringThreshold=threshold |
| 晋升详情 | -XX:+PrintTenuringDistribution |
| GC详情 | -XX:+PrintGCDetails -verbose:gc |
| FullGC 前 MinorGC | -XX:+ScavengeBeforeFullGC |
四. 垃圾回收器
1. 串行垃圾回收器 (Serial GC)
-XX:+UseSerialGC = Serial + SerialOld
(1) 工作原理
-
单线程执行: 仅使用一个 GC 线程完成所有垃圾回收工作.
-
全程 STW: 在垃圾回收期间, 所有应用线程 (用户线程) 都会被暂停, 直到 GC 完成后才恢复运行.
-
算法选择 : 年轻代用 ++复制算法++ , 老年代用 ++标记整理算法++ .
(2) 优缺点
-
优点: 单线程无竞争, 在单核 CPU 下效率较高.
-
缺点: STW 时间长, 应用暂停时间长, 影响响应速度.
(3) 适用场景
-
内存较小的设备 (如个人电脑).
-
单 CPU 环境.
-
对 吞吐量 和 响应时间 要求不高.
2. 并行垃圾回收器 (Parallel GC)
-XX:+UseParallelGC ~ -XX:+UseParallelOldGC
-XX:+UseAdaptiveSizePolicy
-XX:GCTimeRatio=ratio
-XX:MaxGCPauseMillis=ms
-XX:ParallelGCThreads=n
(1) 工作原理
++并行垃圾回收器++ 本质上就是 ++串行垃圾回收器++ 的 多线程版本. (也采用 复制算法 + 标记整理算法)
-
多线程并行: 启动多个 GC 线程 (数量通常与 CPU 核心数相同, 也可手动设置) 同时执行垃圾回收.
-
仍有 STW: 回收期间应用线程依然会被暂停, 但由于多线程并行处理, 相同工作量下的 STW 时间比串行 GC 短得多。
-
优化目标 :提高吞吐量
(2) 优缺点
-
优点: 充分利用多核 CPU: 多线程并行进行垃圾回收, 大幅缩短 STW 时间, 提高了吞吐量.
-
缺点: 仍存在 STW. 在高并发场景下, 短暂的 STW 仍会使得响应延迟.
(3) 适用场景
- 对吞吐量要求高, 对响应时间 (延迟) 要求不高的服务器应用.
3. 并发垃圾回收器 (Concurrent GC)
① CMS 垃圾收集器
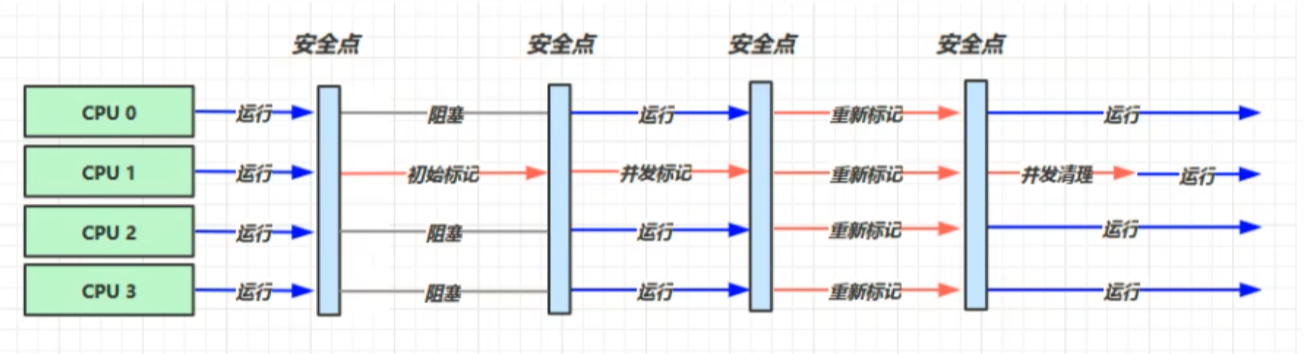
初始标记 --> 并发标记 --> 重新标记 (用于修正对象引用) --> 并发清理
-
初始标记: 触发 STW. 标记根对象 GC Roots.
-
并发标记: 无 STW. 从初始标记的根对象出发, 遍历整个堆空间, 标记所有存活对象.
-
重新标记: 触发 STW. 处理并发标记期间 引用发生修改 的对象.
-
并发清理: 无 STW, 用户线程正常执行, 垃圾回收线程清理所有标记好的垃圾.
-XX:+UseConcMarkSweepGC ~ -XX:+UseParNewGC ~ SerialOld
-XX:ParallelGCThreads=n ~ -XX:ConcGCThreads=threads
-XX:CMSInitiatingOccupancyFraction=percent
-XX:+CMSScavengeBeforeRemark
(1) 工作原理
-
分多阶段执行: 将垃圾回收拆分为多个阶段. 大部分阶段 (并发标记, 并发清除) 与用户线程同时执行. 仅初始标记, 重新标记等少数阶段需要短暂 STW.
-
并发协调: 由于 GC 线程与用户线程同时执行, 会存在 "对象引用动态变化" 的问题 (如用户线程修改对象引用导致 GC 标记结果失效). 因此需要更复杂的算法来解决此问题.
(2) 优缺点
-
优点: STW 时间极短, 仅在关键阶段暂停用户线程.
-
缺点:
-
CPU 开销高, GC 线程与应用线程共享 CPU 资源, 可能导致应用运行速度变慢 (吞吐量下降)
-
实现复杂:需要处理并发场景下的对象引用一致性,算法复杂(如 CMS 的并发标记 - 清除、G1 的并发标记)。
-
(3) 适用场景
- 对响应时间 (延迟) 要求严格的高并发应用. 如: 电商网站, 金融交易系统.
注: 什么是吞吐量? --> 指 应用运行时间 占总时间 (应用运行时间 + 垃圾回收时间) 的比例. 也可以说是"运行效率", "运行速度".
② G1 垃圾回收器
G1 ("Garbage First")
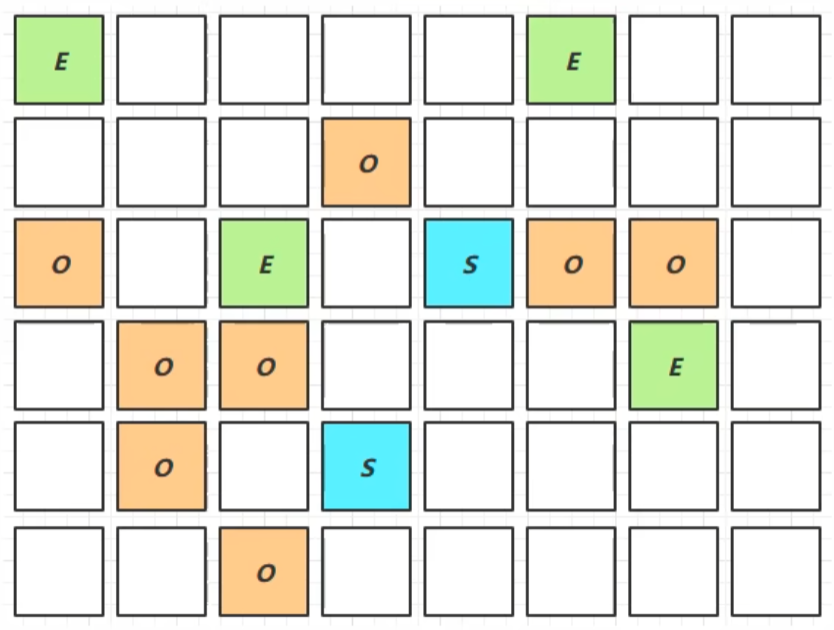
(1) Region 分区
传统 GC 将堆划分为年轻代 (Eden + Survivor) 和 老年代, 而 G1 将堆划分为 多个大小相等的独立区域 (Region). Region 的类型如下:
-
Eden Region: 伊甸园区
-
Survivor Region: 幸存区
-
Old Region: 老年代区
-
Humongous Region : H区 (是O区的一种). 大对象不经过新生代, 直接存进老年代的H区. (大小超过 Region 的 1/2 就可以算作大对象).
(2) 回收过程
G1 的垃圾回收分为 Young GC 和 Full GC.
① Young GC:
年轻代垃圾回收.
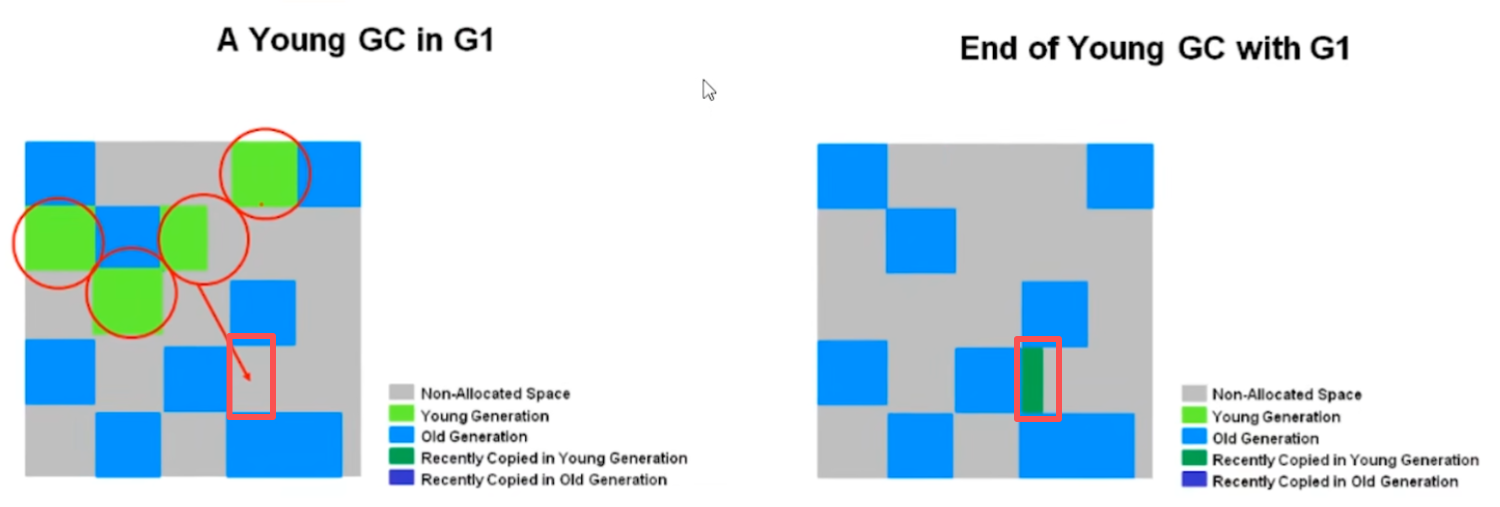
当 Eden 区域占满时触发年轻代回收 (Young GC) 仅回收年轻代的 Region.
++执行过程++:
标记 Eden 区和 幸存区 中的存活对象 (通过 GC Roots 遍历寻找). 将 Eden 区 和 幸存区 中的存活对象复制到另一块 幸存区中. 同时清空 Eden 区 和 已被回收的 幸存区, 变为空闲 Region. 同时 年龄达到阈值的对象晋升至老年代.
注: Young GC 期间, 会触发 STW, 暂停所有用户线程.
② Mixed GC:
混合垃圾回收.
MixedGC 的过程 和 CMS 极为相似.
-
初始标记: 触发 STW. 标记根对象 GC Roots.
-
并发标记: 无 STW. 从初始标记的根对象出发, 遍历整个堆空间, 标记所有存活对象.
-
重新标记: 触发 STW. 处理并发标记期间 引用发生修改 的对象.
-
垃圾清理: 触发 STW. 为了保证 STW 的时间不会太长, G1 只筛选出回收价值高 (垃圾对象多)的 Region 进行清理, 而不是将所有垃圾全部清理.
4. 小结
-
串行垃圾回收器: 适合内存小的个人电脑.
-
并行垃圾回收器: 最大化系统吞吐量, 适用于对吞吐量要求较高的系统.
-
并发垃圾回收器: 最小化响应时间, 适用于对延迟要求较高的系统.
五. GC 调优
-
掌握 GC 相关的 VM 参数, 熟悉基本的空间调整.
-
掌握调优相关工具.
-
明白一点: 调优跟应用环境有关. 没有放之四海而皆准的法则.