物理内存中的伙伴
虚拟内存分配是以内存块为单位,但是,物理内存被划分成一个一个大小一致的物理页(4kb), 所以,物理内存分配是以 "物理页" 为单位
Linux操作系统同样使用"分离空闲链表"数据结构,来搞物理内存的分配与释放。
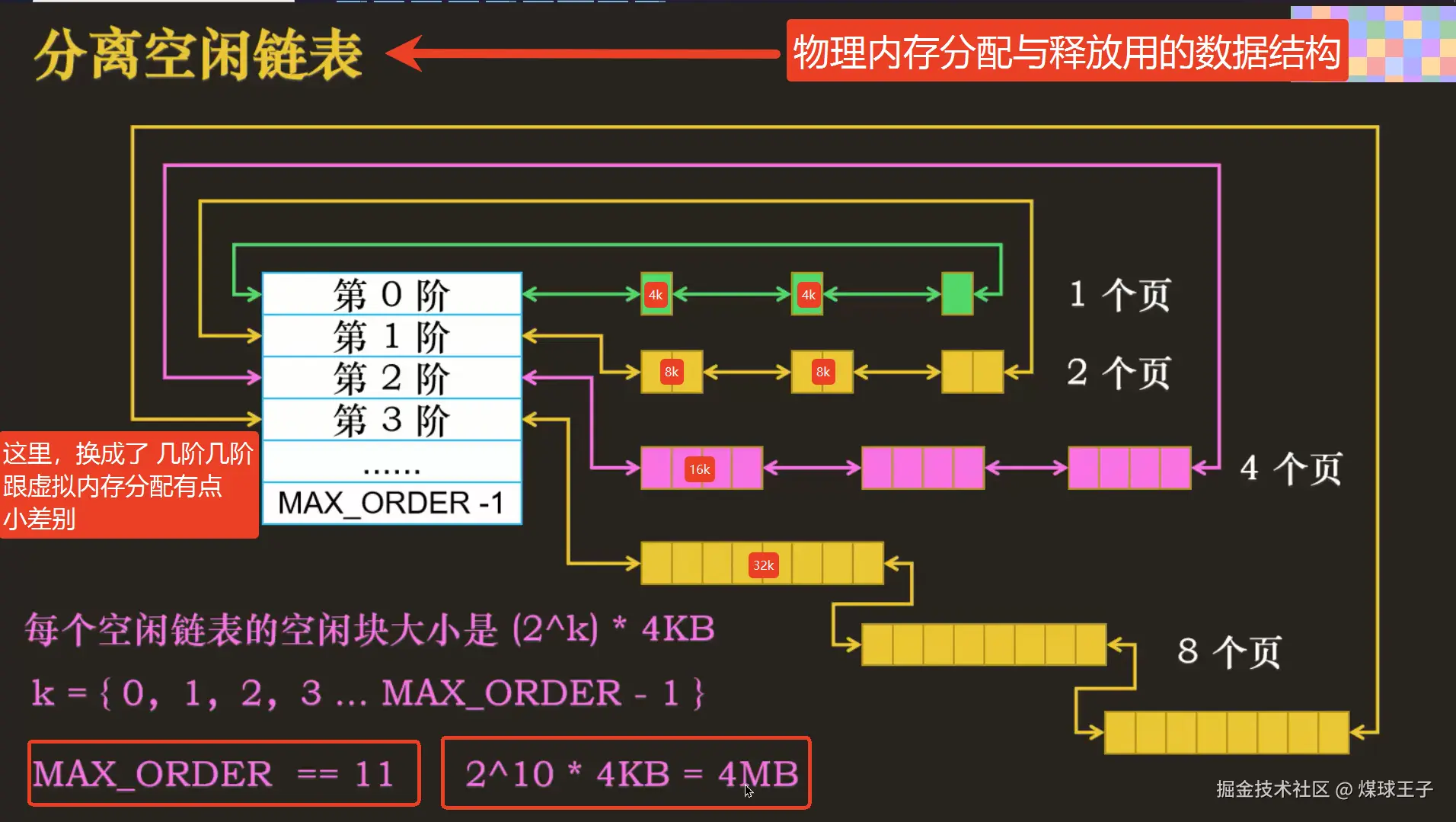 从上图我们看到:(你要注意的是,这里后边画的是三个三个的,其实后边有很多很多哈,只不过是没画出来了而已......)
从上图我们看到:(你要注意的是,这里后边画的是三个三个的,其实后边有很多很多哈,只不过是没画出来了而已......)
第0阶中------都是------1个物理页------串起来
第1阶中------都是------2个物理页------串起来
第2阶中------都是------4个物理页------串起来
第3阶中------都是------8个物理页------串起来
伙伴
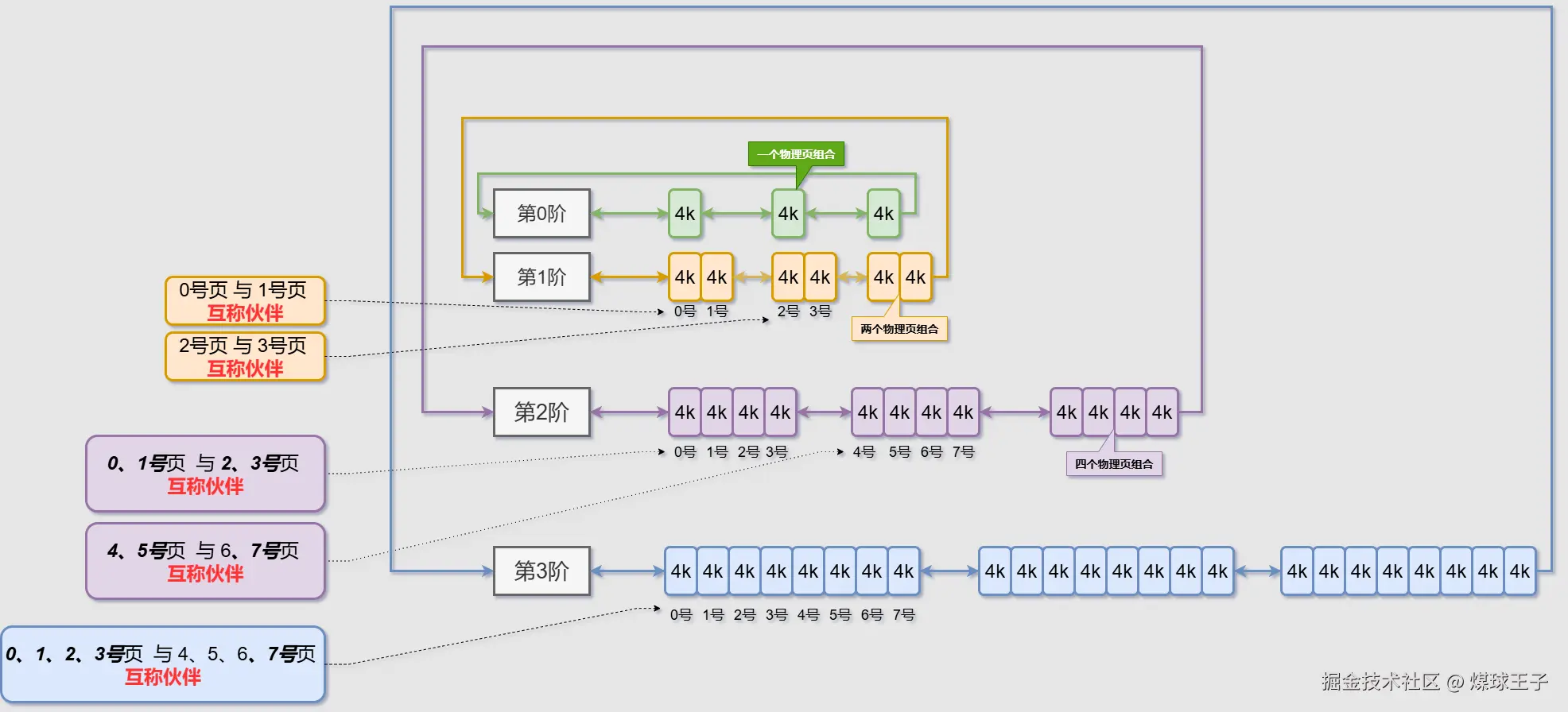 你要注意的是,这里后边画的是三个三个的,其实后边有很多很多哈,我就不画出来了
你要注意的是,这里后边画的是三个三个的,其实后边有很多很多哈,我就不画出来了
指定阶(order)、指定物理页号,通过计算,很快能得到只当物理页的伙伴是谁
使用伙伴算法模拟物理页分配
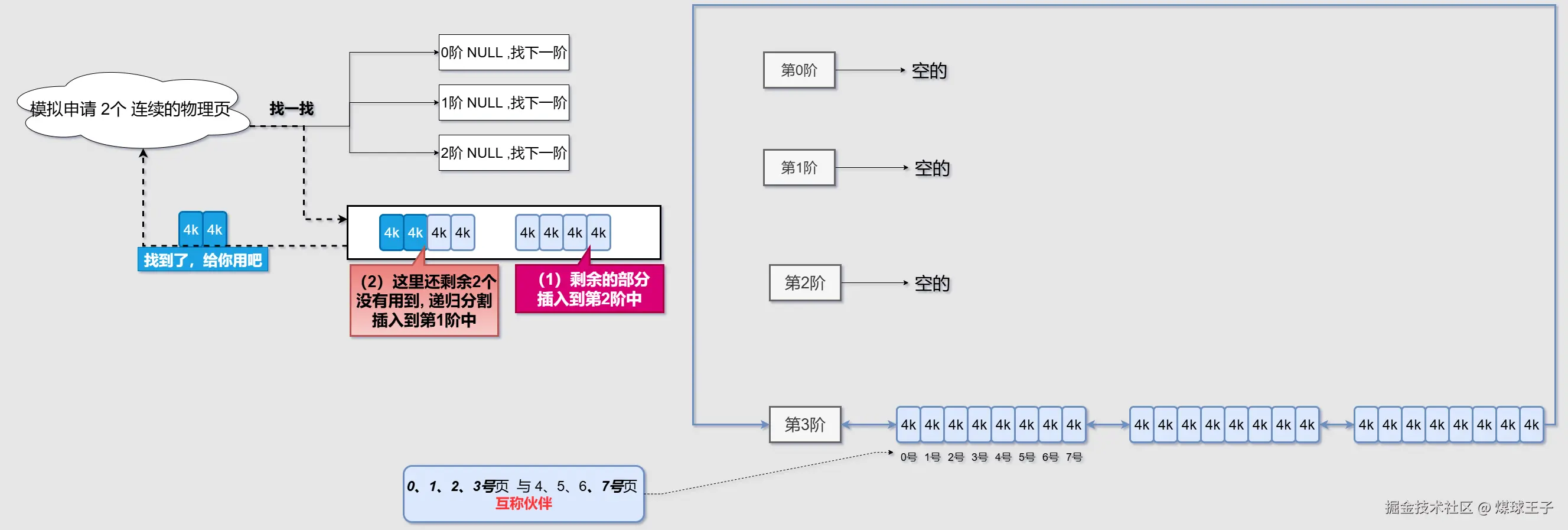
(1)剩余的部分插入到第2阶中(小伙伴分开了) 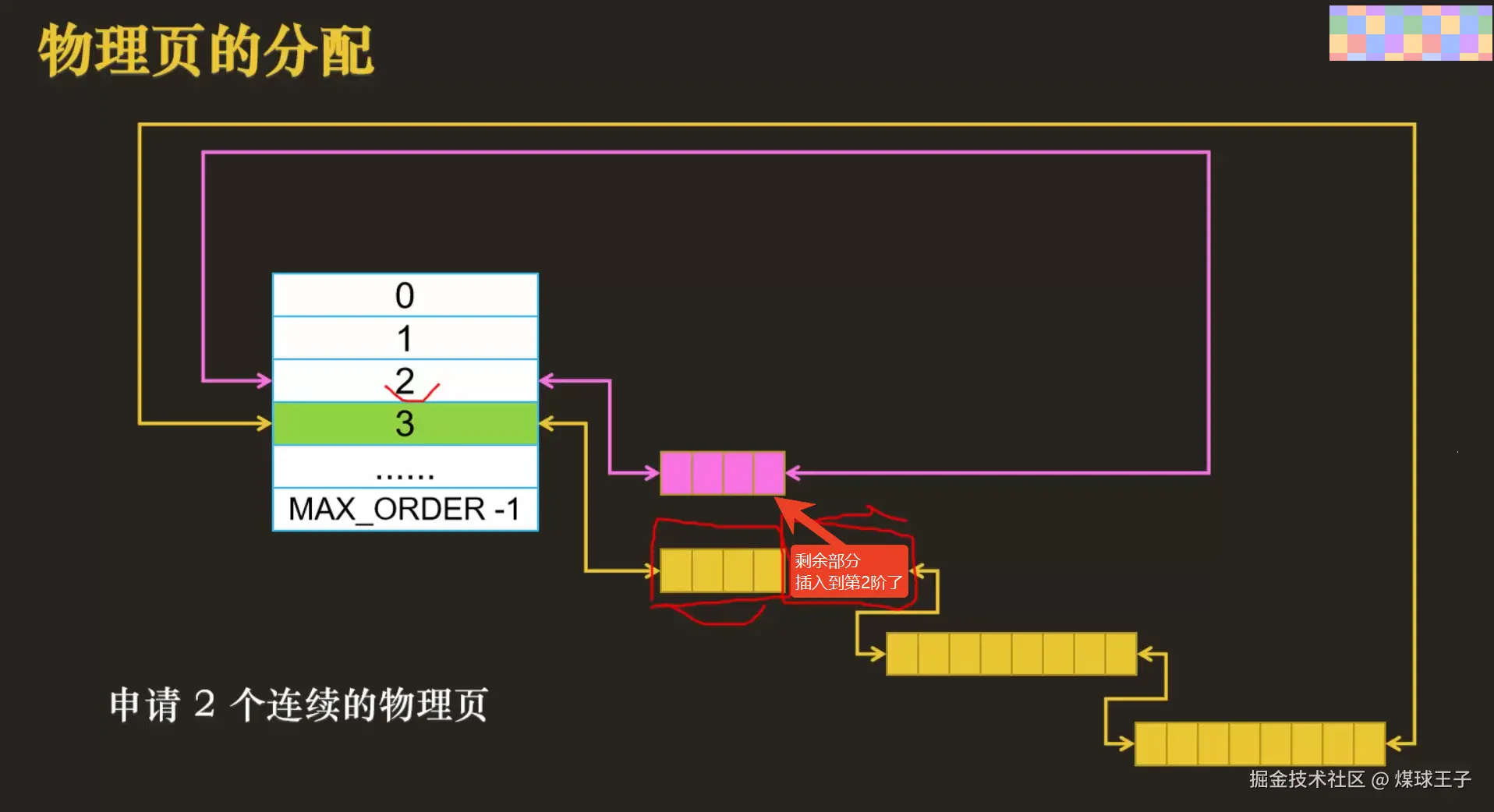 (2)剩余的部分递归分割插入到第1阶中(小伙伴分开了)
(2)剩余的部分递归分割插入到第1阶中(小伙伴分开了) 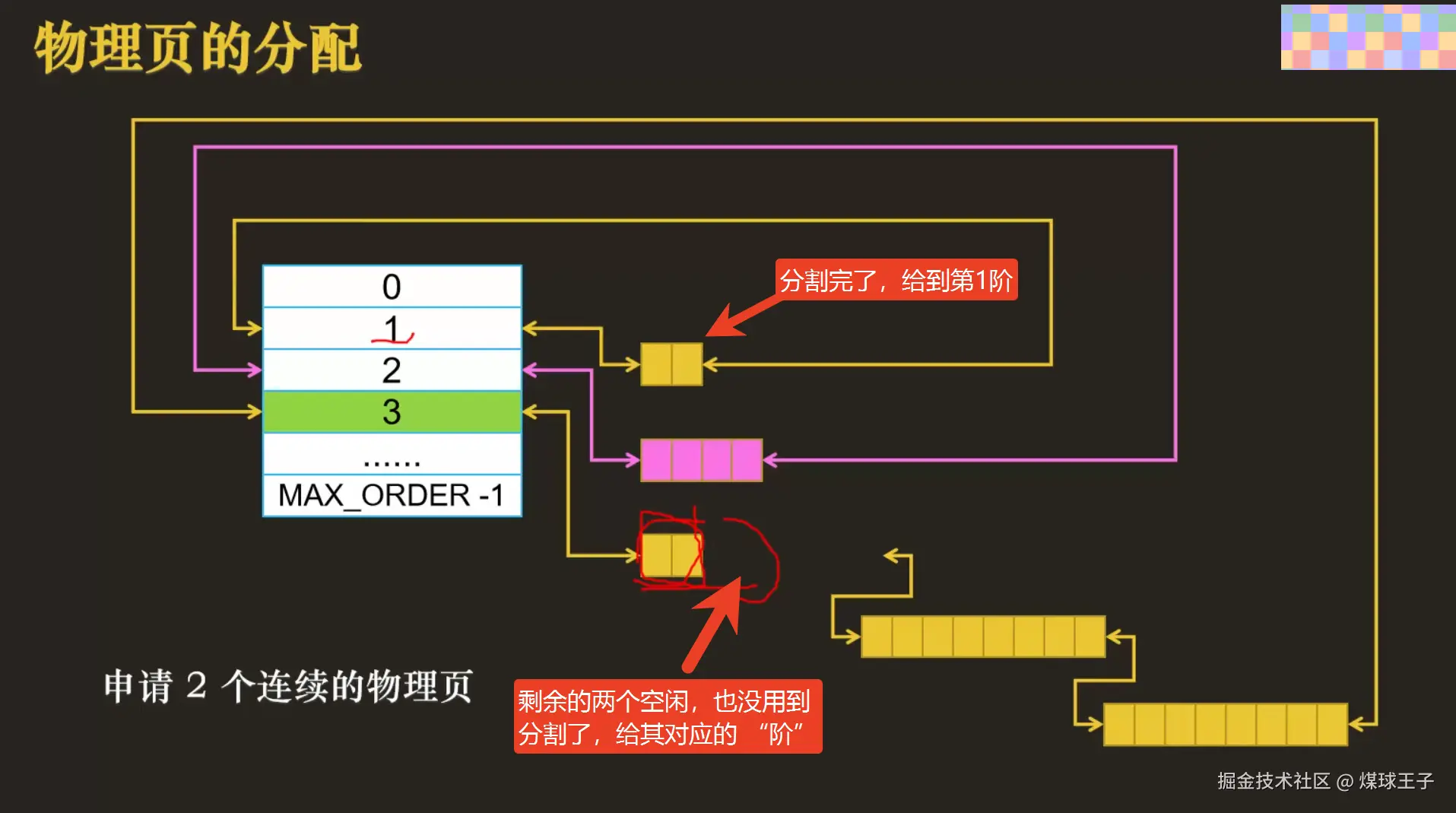 物理内存对NUMA架构和稀疏内存模型(64位操作系统)中的再次细化展示
物理内存对NUMA架构和稀疏内存模型(64位操作系统)中的再次细化展示 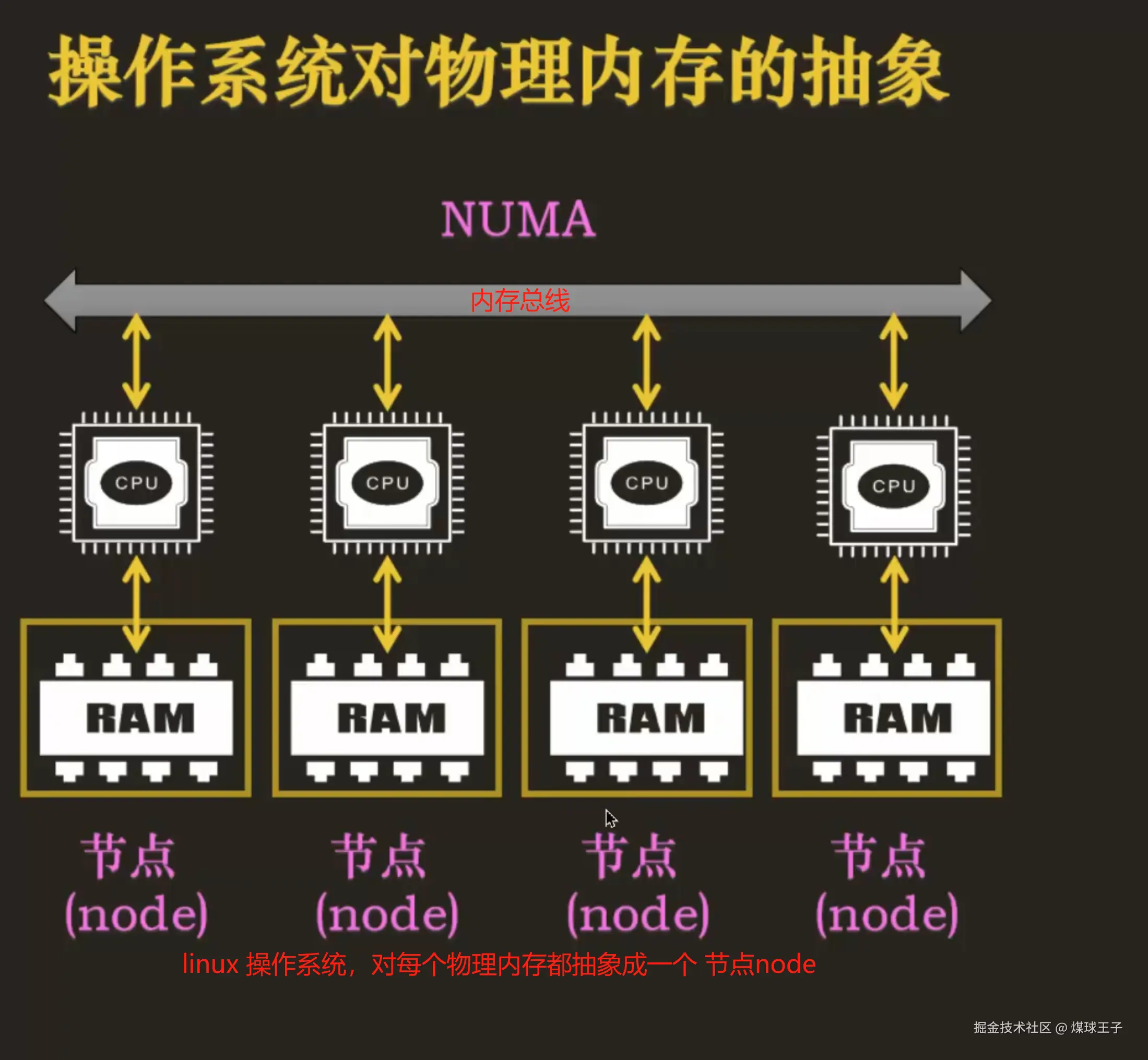
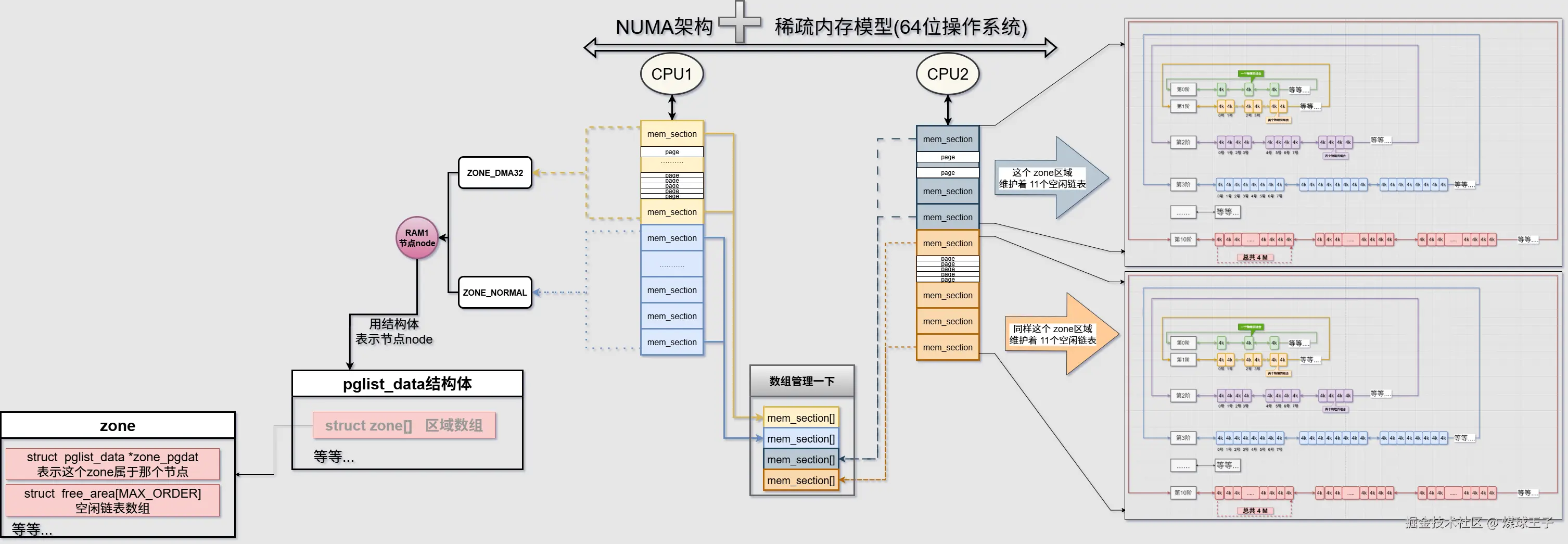 区域:(Zone): 不同区域的内存有不同的用途,便于管理。
区域:(Zone): 不同区域的内存有不同的用途,便于管理。
| 分区名称 | 适用架构 | 物理地址范围(典型值) | 内核虚拟地址映射方式 | 主要用途 / 使用限制 | 伙伴系统水线标记 | 常见标志位 |
|---|---|---|---|---|---|---|
| ZONE_DMA | 32 位 x86 / 部分嵌入式 | 0 ~ 16 MiB | 线性映射(直接映射区) | 兼容早期 ISA 设备,只能访问低 16 MiB;DMA 掩码 24 bit | min/low/high + DMA 水线 | GFP_DMA |
| ZONE_DMA32 | 64 位 x86_64 / arm64 | 0 ~ 4 GiB(x86_64 为 0-1 GiB) | 线性映射 | 给 32 位 DMA 设备(AHCI USB3 NIC 等)提供内存,掩码 32 bit | min/low/high + DMA32 水线 | GFP_DMA32 |
| ZONE_NORMAL | 32/64 通用 | 16 MiB ~ 896 MiB(32 位) 1 GiB ~ 64 GiB(64 位,与 DRAM 大小有关) | 线性映射(永久映射) | 内核直接访问的"普通"页,绝大多数 slab、kmalloc、进程匿名页 | 标准水线 | 0(默认) |
| ZONE_HIGHMEM | 仅 32 位 x86 | 896 MiB ~ 最大物理内存 | 动态映射(kmap/highmem 映射) | 用户进程页缓存、匿名页;内核需临时映射才能访问 | 高水线更早触发回收 | GFP_HIGHUSER |
| ZONE_MOVABLE | 任意架构 | 人为划定区域,与上述分区重叠 | 线性映射 | 供可迁移页使用,防止内存碎片;可热插拔内存主要落在此区 | 无水线,仅作迁移目标 | __GFP_MOVABLE |
| ZONE_DEVICE | 任意架构 | 任意地址(通过 HMM / PCIe BAR) | 设备 MMIO 映射 | 持久内存(PMEM)、GPU 显存、RDMA 网卡内存,支持 DMA-buf / P2P | 无水线,由驱动自行管理 | GFP_TRANSHUGE_LIGHT |
伙伴系统(算法)对外提供的物理内存分配或释放API
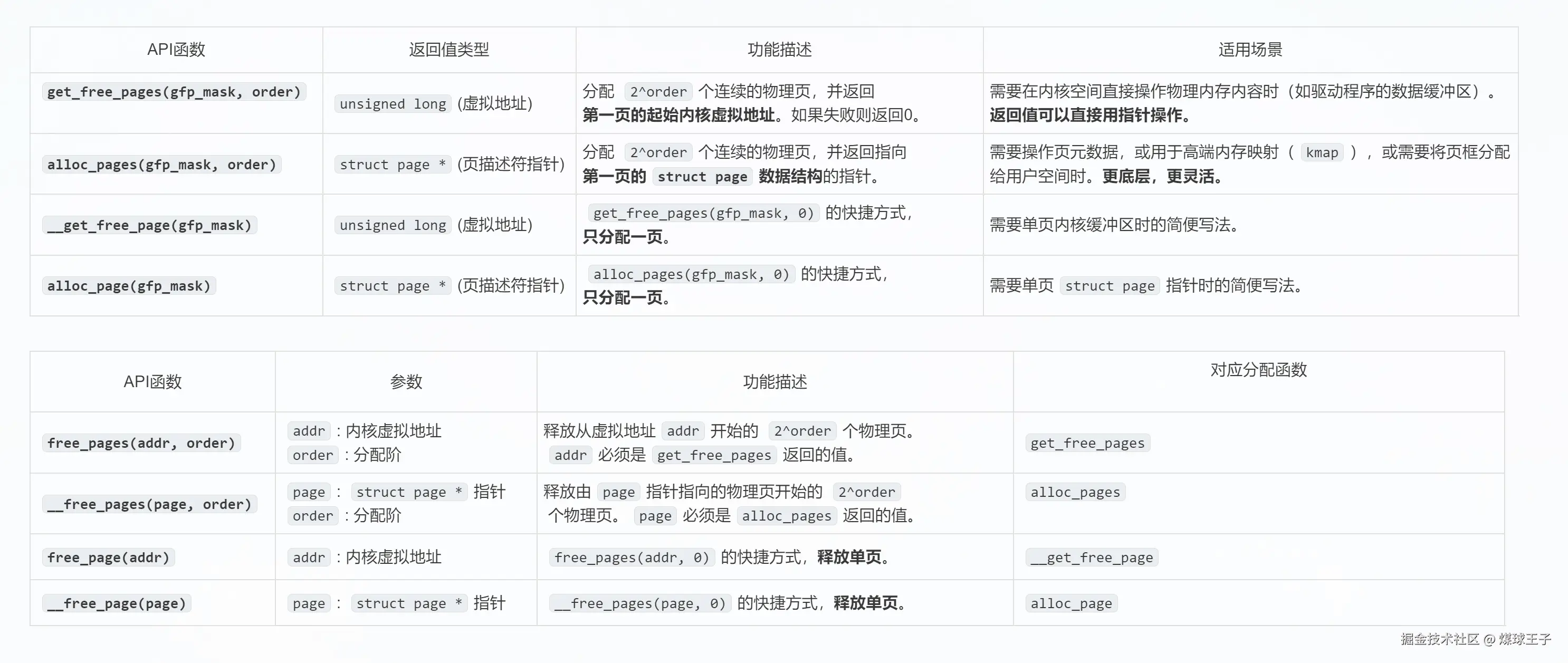 gfp: 表示希望在哪个区域分配内存
gfp: 表示希望在哪个区域分配内存
- GFP_USER 用于分配一个页 映射 到用户进程的虚拟地址空间,并且希望直接被内核或硬件访问,主要用于一个用户进程希望通过内存映射的方式,访问某些硬件的缓存,例如显卡缓存
- GFP_KERNEL 用于内核中分配页,主要分配ZONE_NORMAL区域,也就是直接映射区
- GFP_HIGHMEM 顾名思义就是主要分配高端区域的内存
order: 表示分配2的order次方个页
内核态下虚拟内存的分配
Slab分配器
功能:为内核程序分配小对象内存,降低内部内存碎片的产生 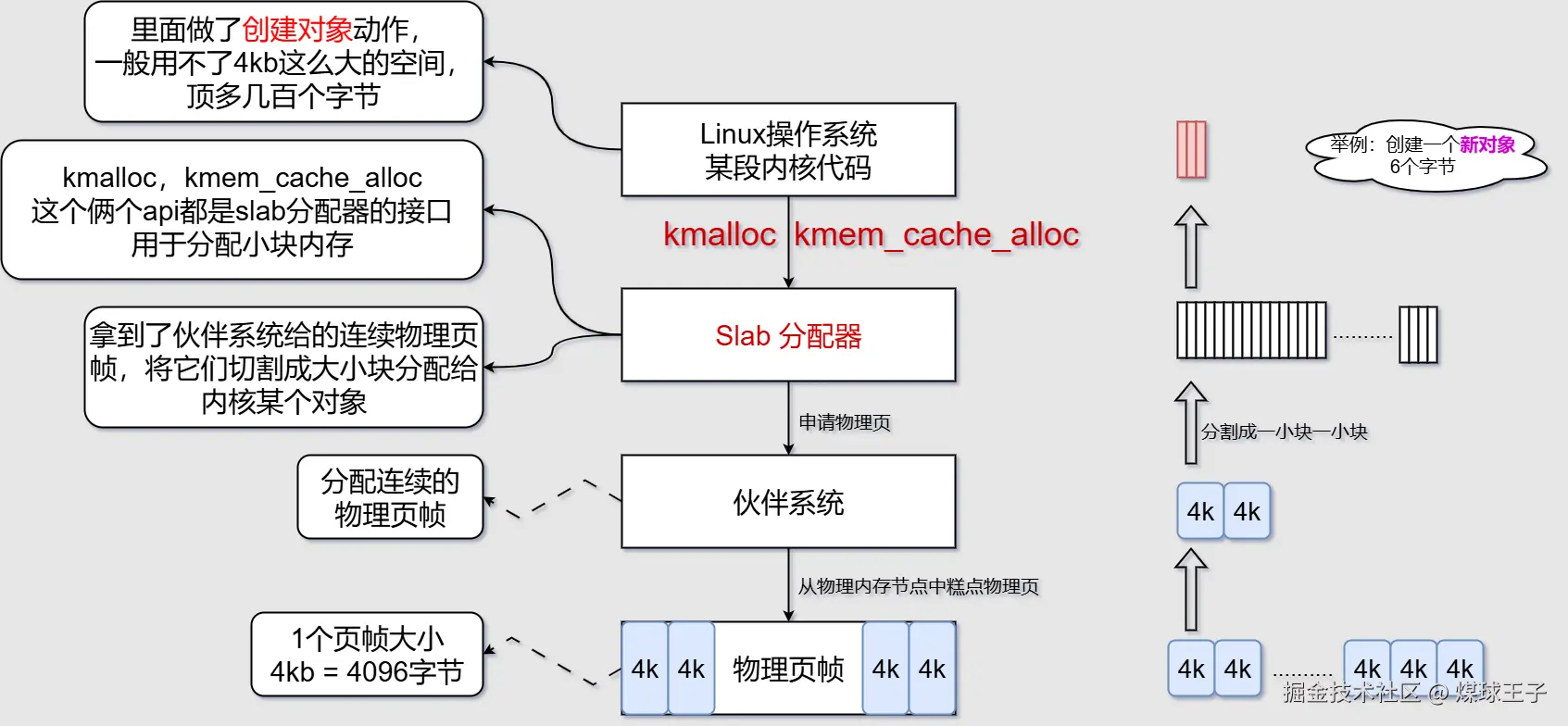 通用:将连续页帧划分成通用大小的小块(比如:8字节)
通用:将连续页帧划分成通用大小的小块(比如:8字节)  专用:按照指定对象大小来划分
专用:按照指定对象大小来划分 
Slab分配器中的数据结构
slab :(石、木等硬质材料的)厚板;(蛋糕、面包、巧克力等的)厚块;(烹饪食品时所用的)厚桌面,砧板;
一个slab中包含了若干个物理页帧(这些连续的物理页帧是分配器一次性从伙伴系统申请过来的噢!它们就组成了一个slab)
存储相同大小的多个slab,由数据结构kmem_cache 来管理 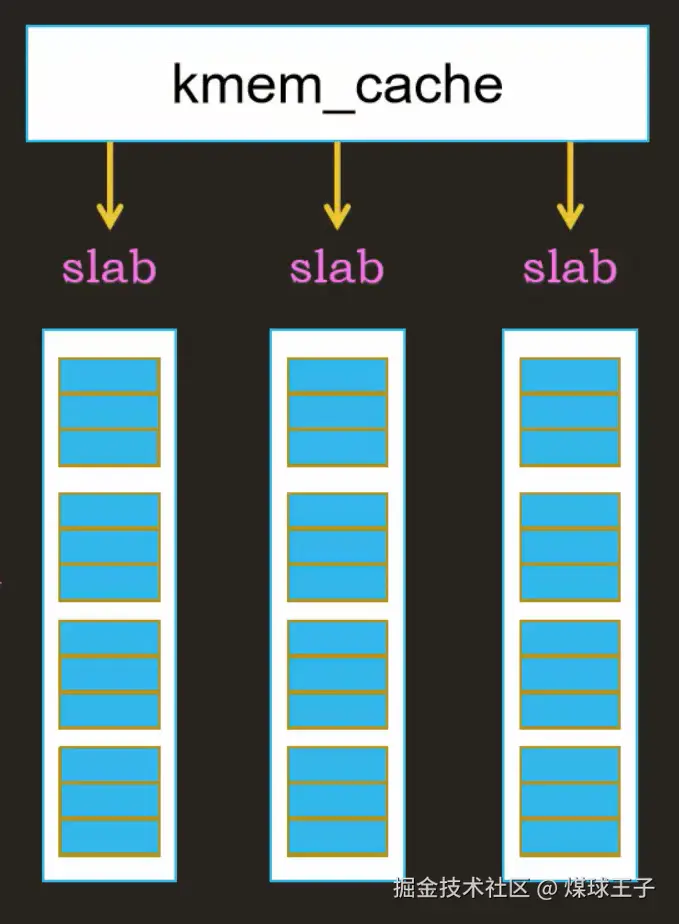
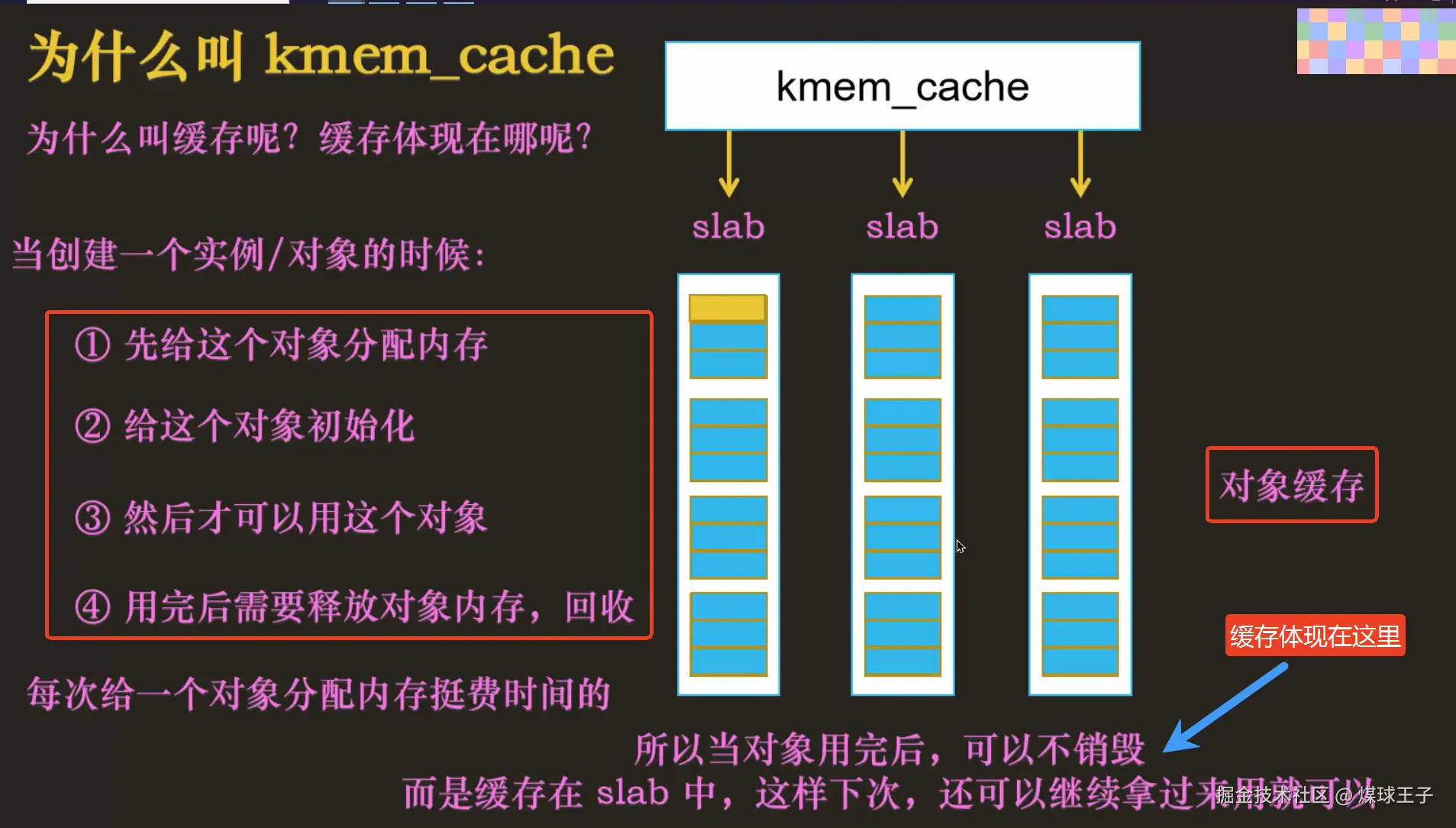
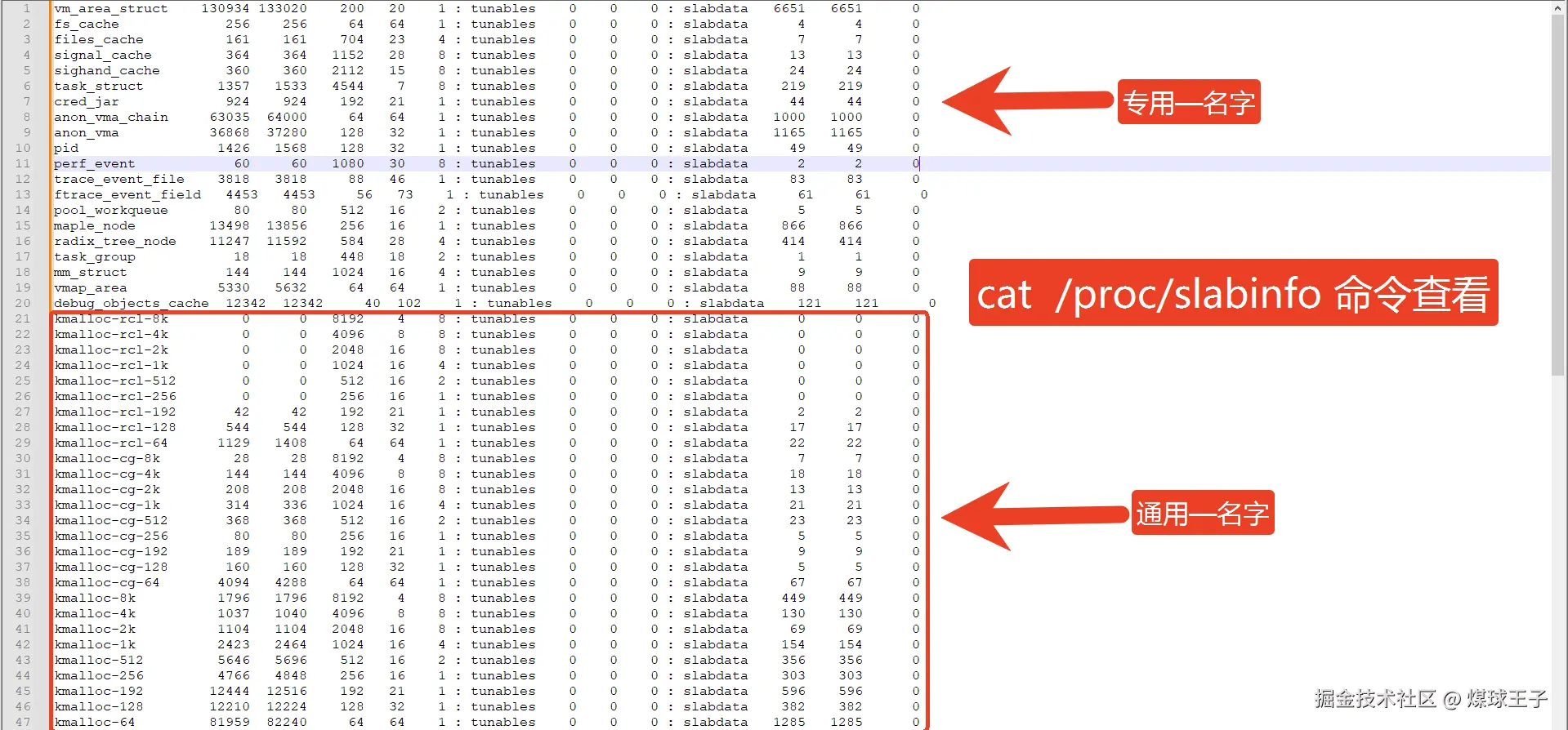
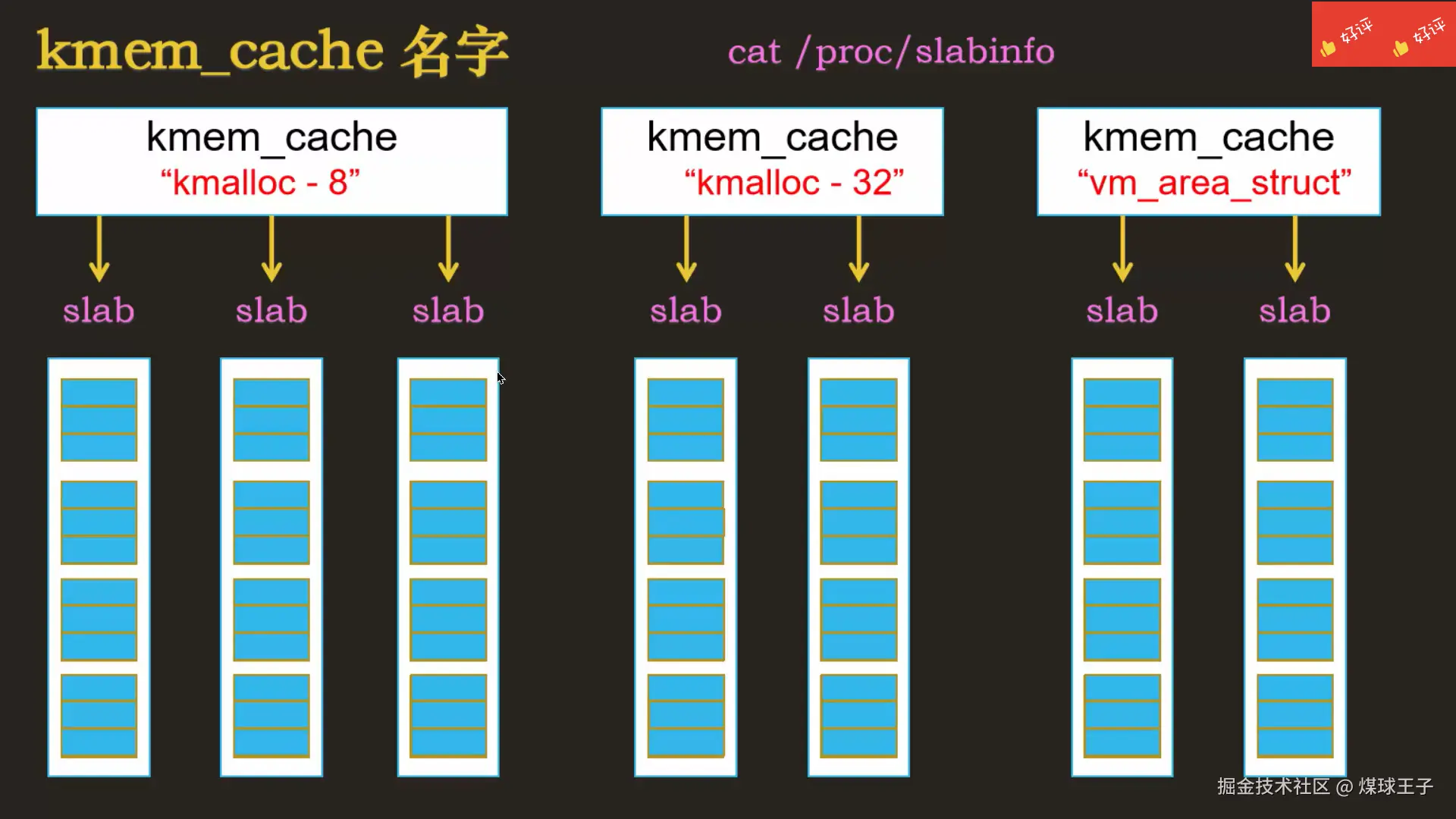 A. 通用的名字
A. 通用的名字
kmalloc-8, 里面每个小块都是8字节,你的对象申请小于等于8,分配器都从这里给你。
kmalloc-32, 里面每个小块都是32字节,你的对象申请小于等于32,分配器都从这里给你。
B. 专用的名字
如:vm_area_struct , 每个小块都是存vm_area_struct对象的,216个字节
再次细化展示一下kmem_cache结构体中的内容: 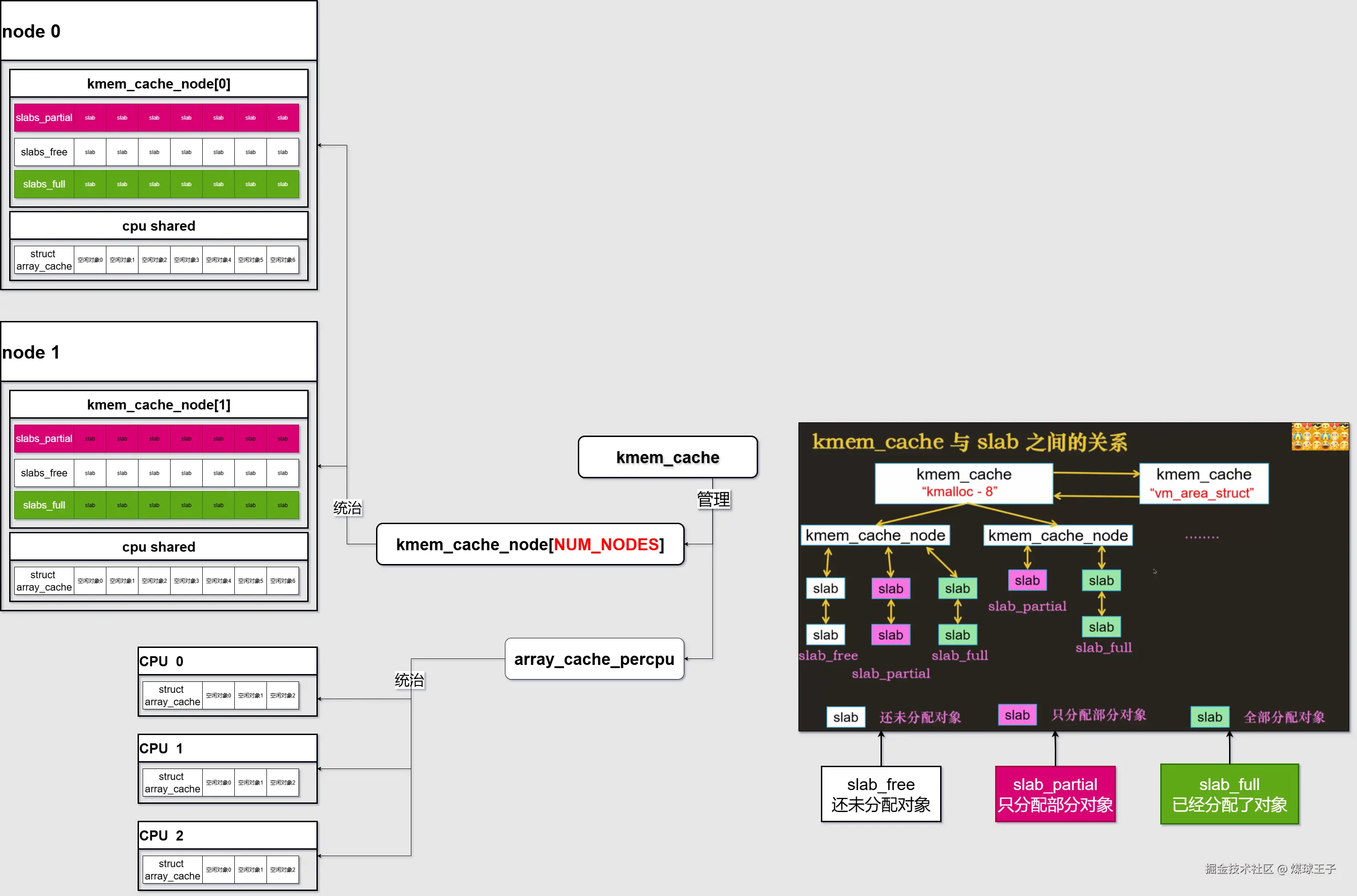
kmem_cache中的变量数据结构体,只列举了部分结构体,更详细的请AI或查看源码
✅ 1. kmem_cache_nodeNUM_NODES 这是 每个内存节点(NUMA node) 的缓存信息数组。
- 作用:在 NUMA 架构下,每个节点(node)有自己的内存,Linux 的 slab 分配器会为每个节点维护一个
kmem_cache_node 结构,用于管理该节点上的 slab 缓存。
✅ 2. array_cache_percpu 这是 每 CPU 的缓存数组,用于 减少锁竞争。
- 作用:每个 CPU 都有一个本地的对象缓存(array cache),用于快速分配和释放对象,避免频繁访问全局的 slab 链表。
内核的内存分配
内核中的程序可以通过kmalloc分配连续的物理页帧 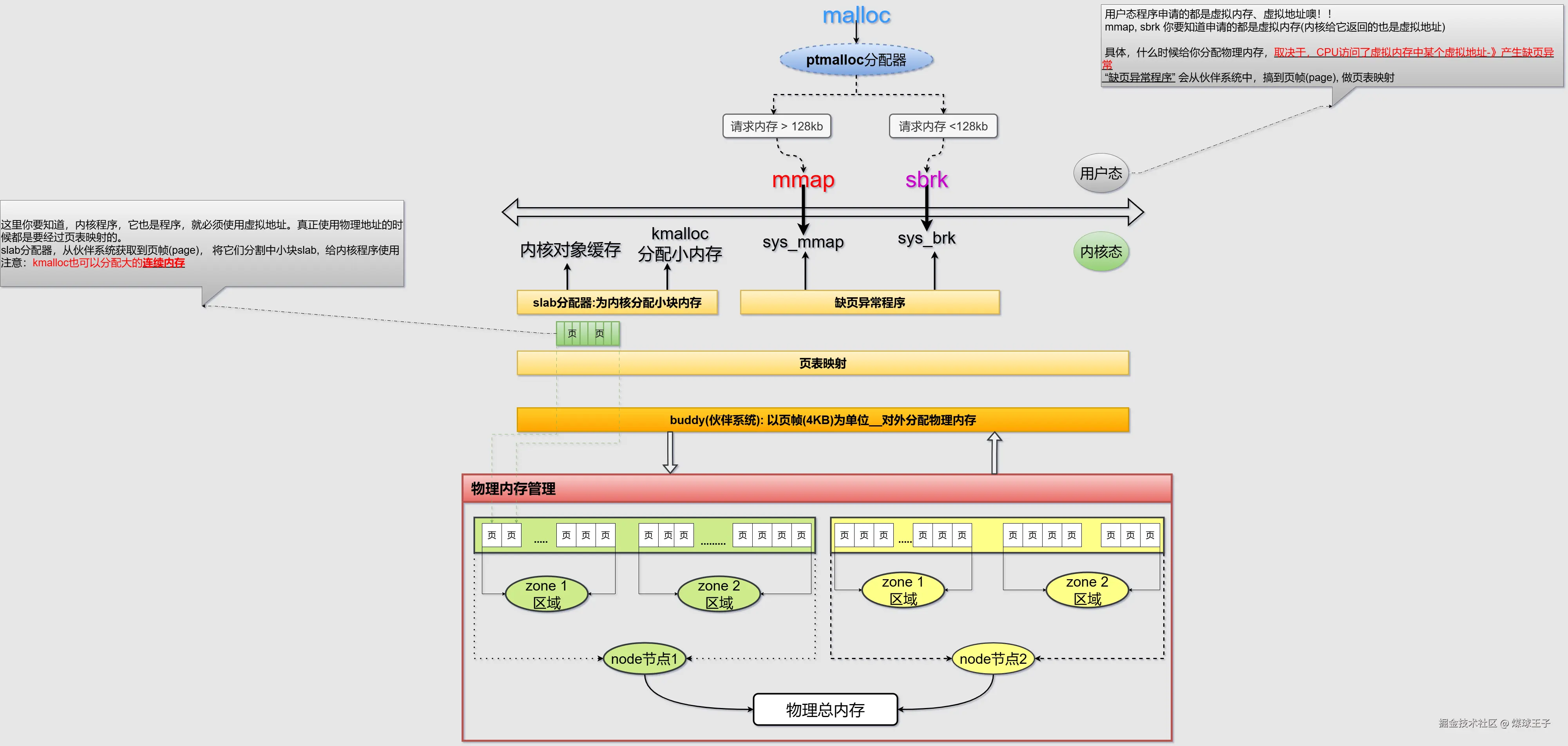
内核中的程序可以通过vmalloc分配非连续的物理页帧 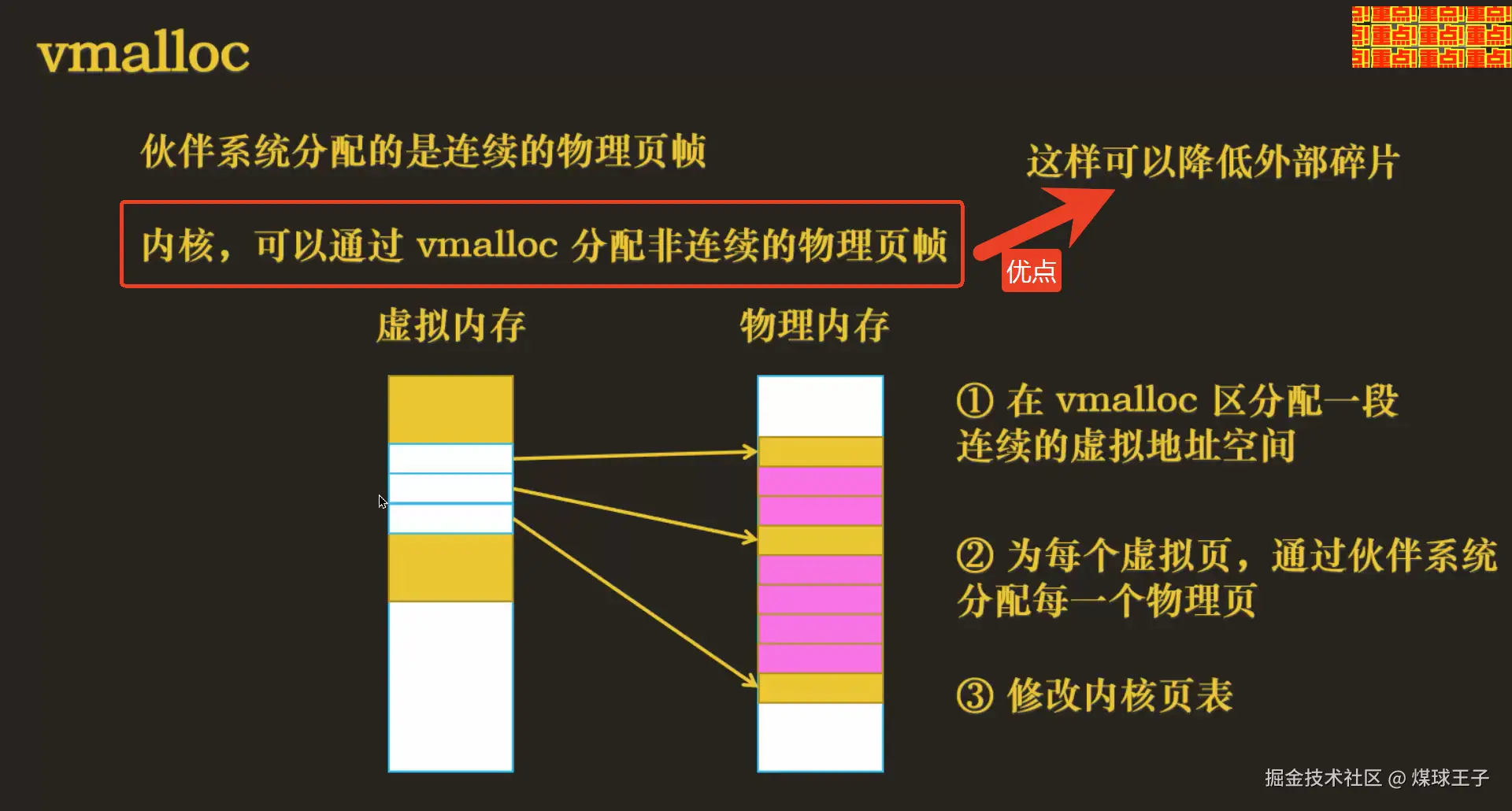
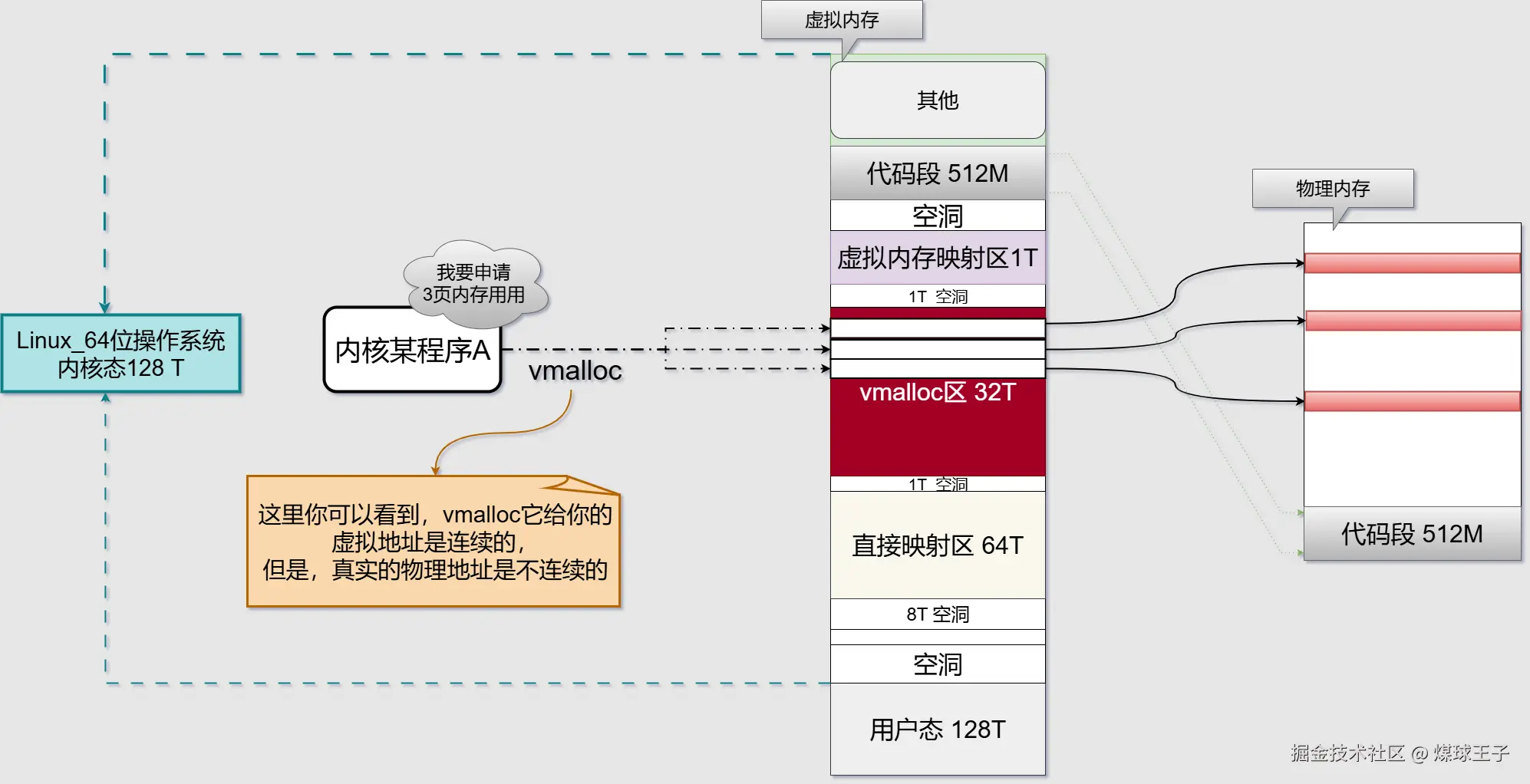
| 特性 | kmalloc |
vmalloc |
|---|---|---|
| 分配内存类型 | 物理连续,虚拟也连续 | 仅虚拟连续,物理不连续 |
| 最大单块大小 | 通常 ≤ 128 KB(受限于连续物理页) | 仅受限于内核虚拟地址空间(可 MB/GB 级) |
| 释放函数 | kfree() |
vfree() |
| 物理地址 | 可获取,满足 DMA 需求 | 物理地址不连续,不可用于 DMA |