概要
NeurIPS 2025 于 2025 年 12 月 2--7 日在圣迭戈会展中心举办,并设置墨西哥城等地的平行活动;大会继续覆盖从机器学习方法论到跨学科应用的全谱系议题,同时延续数据集与基准等分轨传统与政策更新(如 LLM 使用指引)。NeurIPS 2025 主会投稿 21,575 篇,接收 5,290 篇,录用率约 24.5%;海报 4,525、Spotlight 688、Oral 77。从已上线的论文来看,今年的系统与基础设施类成果密集:面向大规模训练的并行与调度、拓扑感知通信;面向推理的 Serving/SLO 管理、推测解码与 KV-cache 体系;以及编译器/内核共设计与自动调优,形成"更低延迟、更高吞吐、更优能效、更强可运维"的清晰趋势。

San Diego Convention Center and Mexico City
在模型规模持续扩张、上下文长度与并发访问不断攀升的当下,NeurIPS 2025 的诸多亮点都直接指向"系统边界"的再定义:训练侧的调度/并行与拓扑感知通信(如 FlowMoE、StarTrail)回答了如何把 1000+ GPU 的算力变成"有效吞吐";推理侧的 Serving/SLO、推测解码与 KV-cache 压缩/复用(如 HyGen、Yggdrasil)则回答了如何在相同资源下"生成更多、更快、更稳"。这些工作共同勾勒出两条分析主线:
-
AI infrastructure(训练/通信/资源编排)------以并行维度设计、通信对齐、系统级调度与能效约束为核心,面向端到端训练吞吐与成本最优化。
-
ML systems(推理/服务化/编译器与运行时)------以时延与尾延迟控制、推理时计算扩展、缓存与内存足迹治理、编译器/内核共设为核心,面向高并发、低成本的在线与离线服务。
接下来,把今年相关论文(已上线的论文)逐一展开泛读(一张图,一句话)。
论文列表
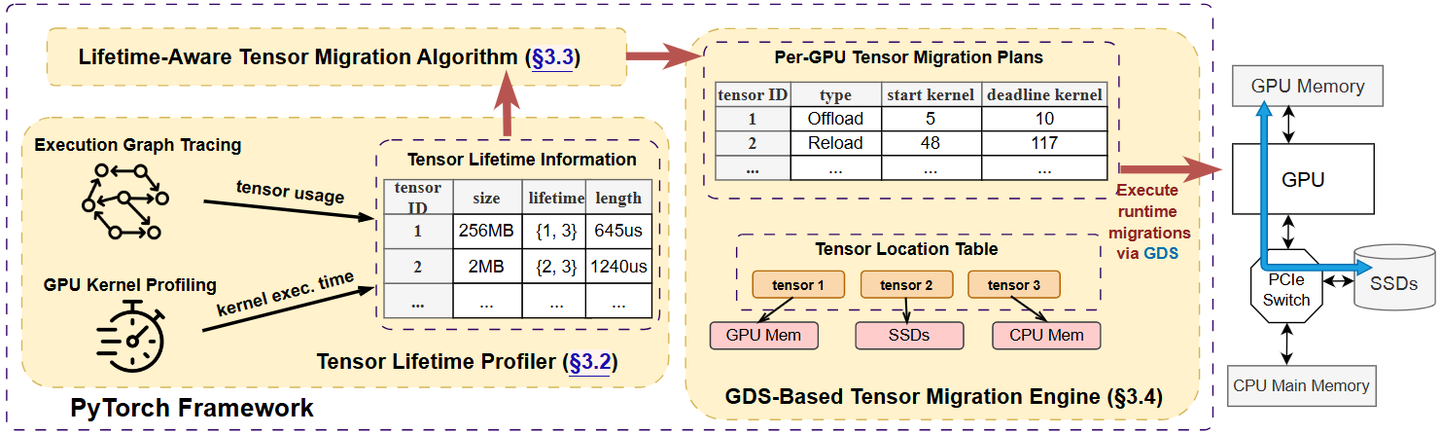
System overview of Teraio
这篇论文提出并实现了一个用于大模型训练的"按生命周期感知(lifetime-aware)张量换入/换出"框架 Teraio,核心目的是用廉价的PCIe SSD + GPUDirect Storage 扩展GPU显存、在尽量不牺牲吞吐的前提下降本增效。
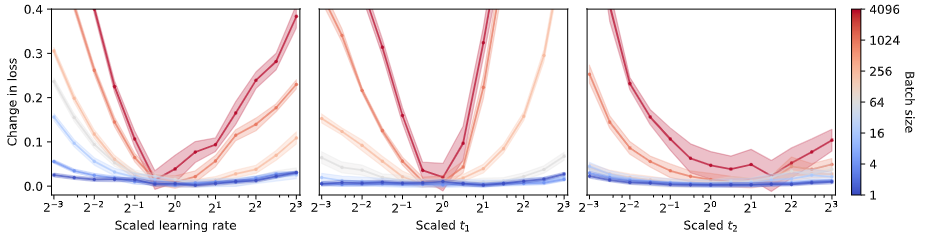
Small batch sizes are robust to hyperparameter misspecification
小批量(甚至 batch size = 1)训练大语言模型完全可行,而且往往更稳、更省显存,并不需要梯度累积或复杂优化器。作者系统给出一套在小批量下调参的原则,并用从 30M 到 1.3B 参数的实验验证。
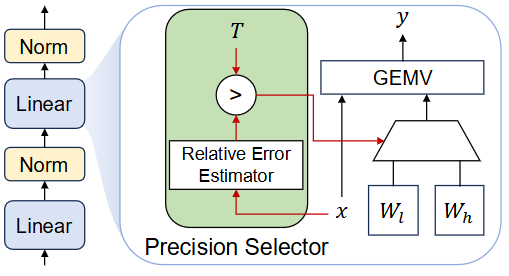
Overview of DP-LLM
这篇论文提出 DP-LLM:一种在推理时按层动态分配量化精度的机制,用来在终端/本地设备上根据实时的延迟/精度约束自适应运行 LLM。核心思想是:不同层对量化误差的敏感度会随解码迭代(逐 token)动态变化,因此不应把每一层的比特数固定,而应在每一步为每一层选择"高比特 or 低比特"。
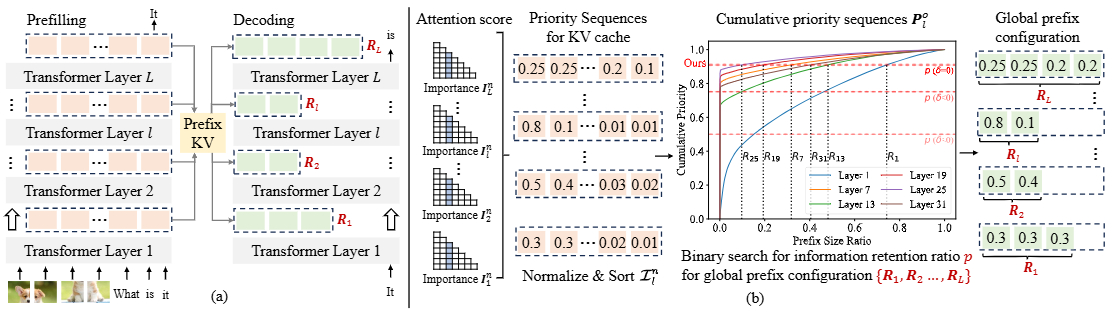
a) The inference process of LVLMs, (b) The overview of PrefixKV.
作者提出 PrefixKV:把"每层留多少 KV"统一改写成"全局前缀配置"搜索问题(把每层 KV 的重要度(用注意力得分聚合而成)排序成"优先级序列"),在给定总压缩预算下,按层自适应地保留各自最有信息量的前缀 KV,从而以相同的显存预算换来更少的精度损失与更高的生成质量。
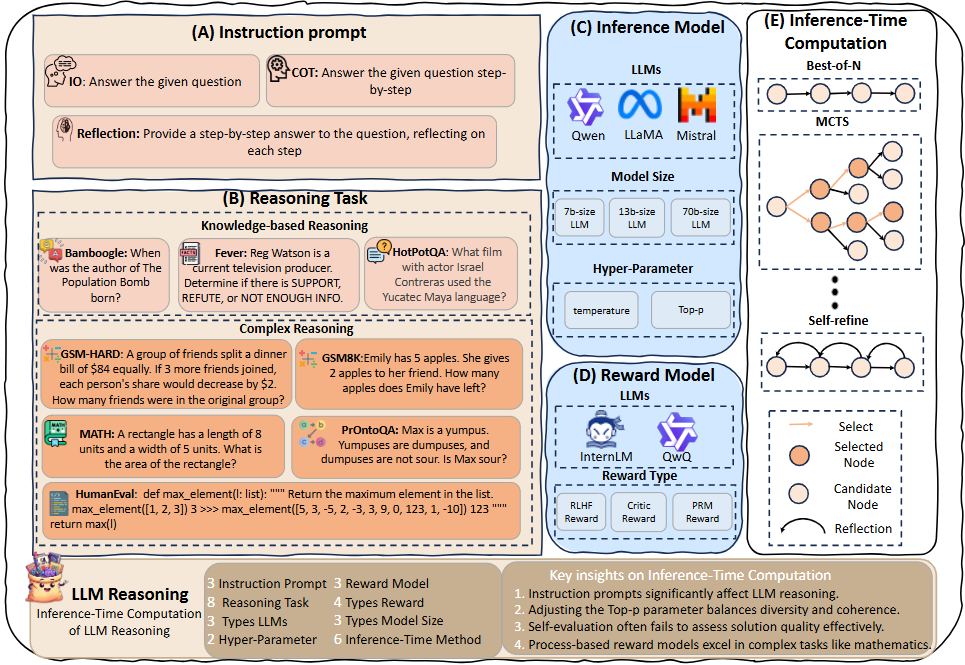
Overview of Decoding Inference-Time Computation for LLM Reasoning
作者把常见的 ITC (Inference-time Computation)方法(Best-of-N、Step-level Best-of-N、Self-Consistency、Beam Search、MCTS、Self-Refine)放到同一套设置里,在八类推理任务上系统做了上千组对比(累计 >2万 A100-80G GPU 小时),重点不改模型也不再训练,而是通过采样与选择环节的"小技巧"获得更高正确率/Pass@1。
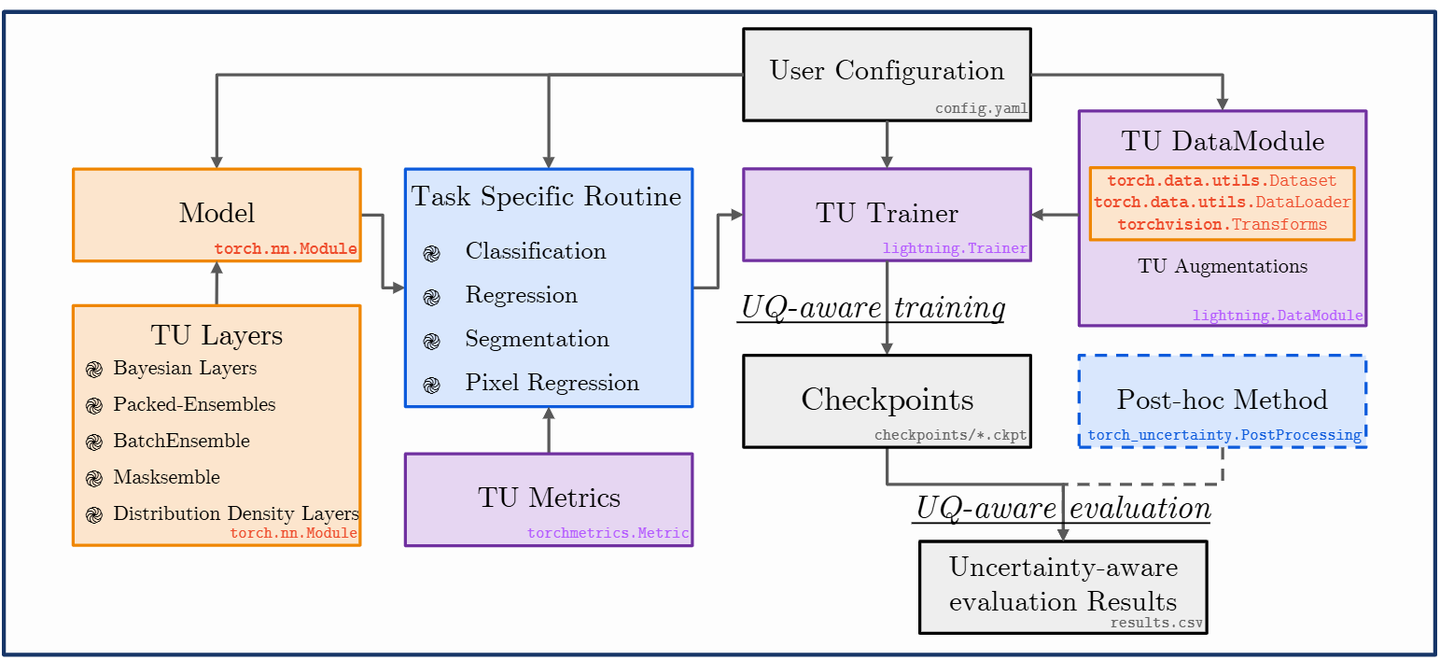
Overview of Torch-Uncertainty's usage for model training and evaluation
对 Torch-Uncertainty 的介绍与评测:一个基于 PyTorch + Lightning 的深度学习不确定性量化(UQ,Uncertainty Quantification)框架,主打"统一、模块化、以评测为中心"。
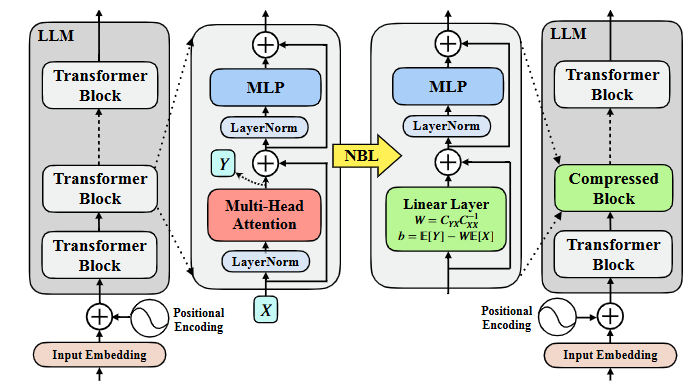
Illustration of Neural Block Linearization (NBL)
这篇提出一种不改训练、直接替换算子来加速 LLM 推理的方法------Neural Block Linearization (NBL)。做法是:对每一层自注意力,用校准数据收集其输入 X 和输出 Y,然后用线性最小均方估计(LMMSE,Linear Minimum Mean Squared Error )闭式解学出一个线性层 Y^=WX+b 来近似原注意力;再用 典型相关分析(CCA,Canonical Correlation Analysis ) 给出一个可计算的线性化误差上界,据此只替换那些最"线性"、误差上界最低的层。不需要微调或再训练。
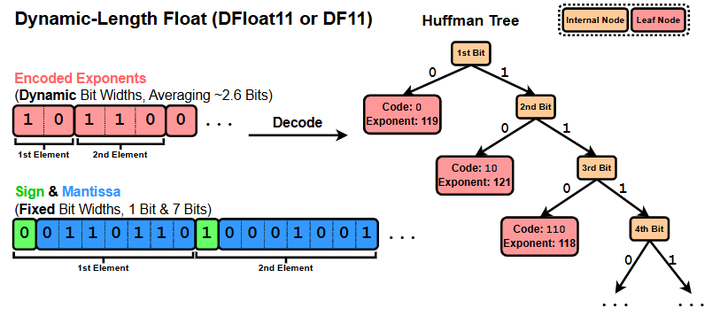
Dynamic-Length Float for compressing BFloat16 weights of LLMs losslessly down to 11 bits
主要提出一种无损压缩格式 DFloat11,用来把 BF16 (Brain Float16)权重按信息熵重新编码,在不改变任何推理结果(bit-exact)的前提下,把大模型/扩散模型的体积压到约 70%,并配套了面向 GPU 的高效在线解压内核以支撑推理。
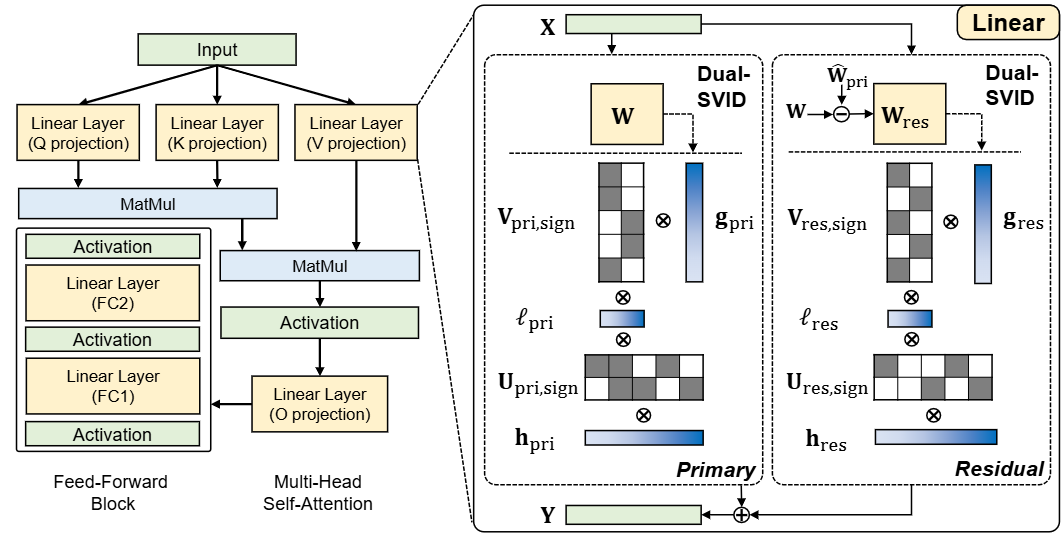
Comparison of a standard Transformer layer (left) and the LittleBit architecture (right)
提出 LittleBit:把 LLM 的线性层先做低秩分解W≈UV⊤,再把因子 U、V 二值化(±1),并配上三重可学习缩放(行 h、列 g、潜在秩维度 ℓ:在把权重做低秩二值分解之后,分别在三个互相独立的轴上放入可学习的尺度参数,用来补偿二值化带来的幅度信息丢失。),实现亚1比特(甚至 0.1 BPW)的极限量化,同时尽量稳住精度。
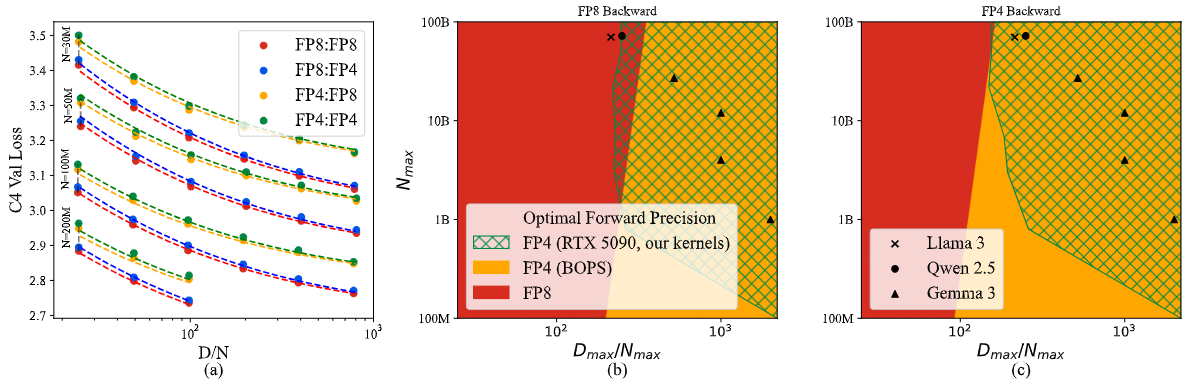
Analysis of Quartet
Quartet 证明了在 Blackwell 上全流程 FP4 训练不仅能跑、还常常是精度-速度最优;并用一套低精度Scaling law把"前向误差 vs 反向偏差"的权衡量化清楚,给出何时选 FP4/FP8 的可计算判据与高效实现。
Architecture overview of Arnold
在上万卡规模(9600+ GPU)上,如何把大模型预训练的通信模式与数据中心拓扑"对齐",用更聪明的调度拿到真实端到端加速。作者提出了一个面向 LLM 预训练作业(LPJ)的拓扑感知调度系统 Arnold,在生产训练中把吞吐提升到 +10.6%,并在仿真里把通信组的"跨机架/跨小仓(minipod)扩散度"最多降到 1.67×。
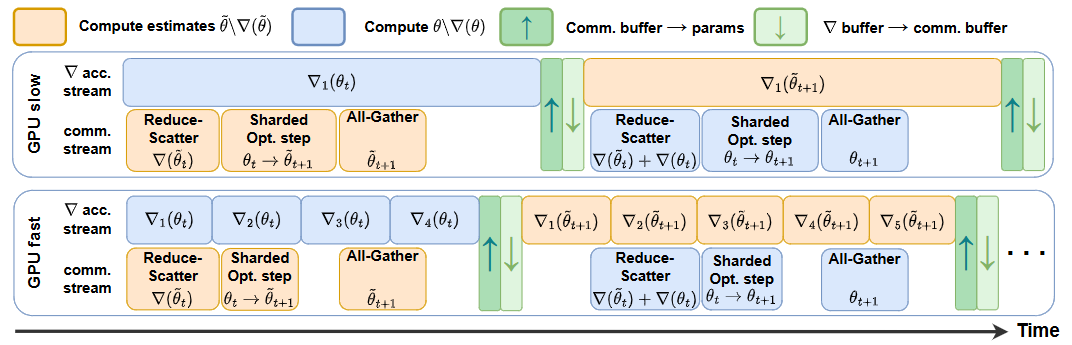
ACCO with a slow and a fast worker running in parallel, showing no idle time on both and hiding communications
提出 ACCO(Accumulate while you COmmunicate):一种在分片优化器(如 ZeRO-1/FSDP)场景下,把梯度通信与计算重叠起来、同时不牺牲收敛的分布式训练方法,专为大模型(LLM)设计。
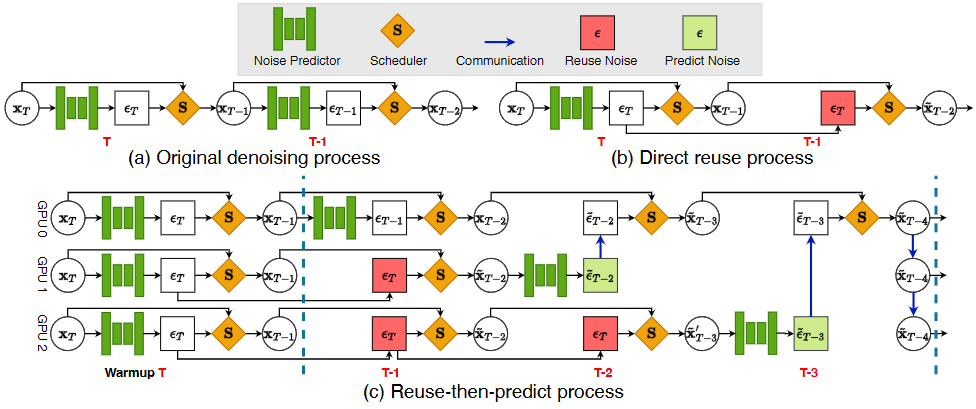
Illustration of the computation process of a diffusion model
提出 ParaStep:一种面向扩散/Flow Matching 生成模型推理的"复用-再预测(reuse-then-predict)"并行化方法。它利用相邻降噪步之间噪声/样本高度相似这一事实,把最耗时的"噪声预测器"前向在多卡之间按时间步并行,且每步只通信一次(传噪声与样本),显著降低通信开销,在低带宽(PCIe Gen3)也能稳定加速。
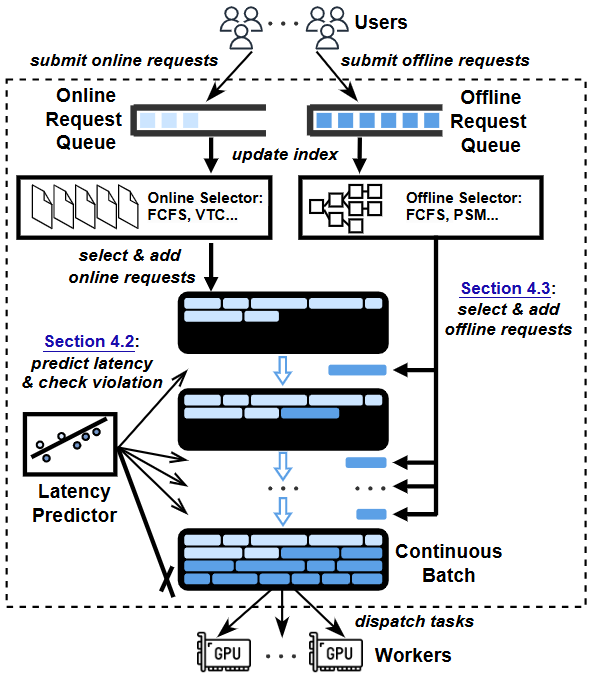
HyGen overview
提出 HyGen:一个让在线(低时延)与离线(高吞吐)两类 LLM 请求可以同机共置的推理服务系统,在不违反在线请求时延 SLO的前提下,把离线任务"弹性填充"进空隙里,从而显著提升整体吞吐。
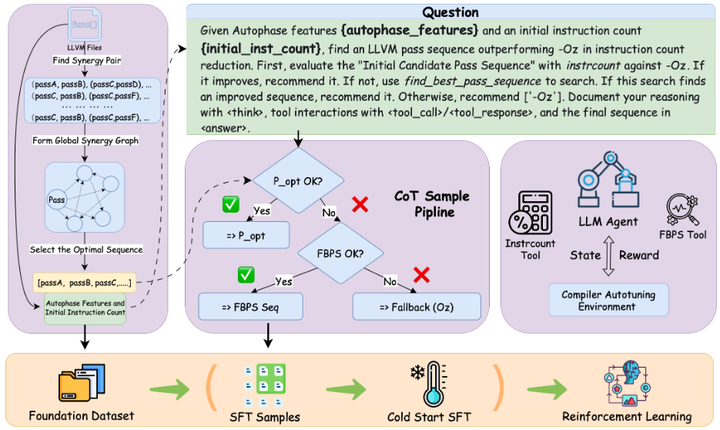
Compiler-R1
提出 Compiler-R1:一个用强化学习(RL)训练的大语言模型代理,来做 LLVM 编译优化序列(pass sequence)自动调参。它解决了以往"只有SFT、缺少高质量推理数据、与编译环境互动不足"的痛点。Compiler-R1 把"LLM+工具"的交互式编译调参做成可强化学习的问题,在多套基准上显著降IR指令数、提效率、强泛化,证明 RL 驱动的代理式编译自动调参切实可行。
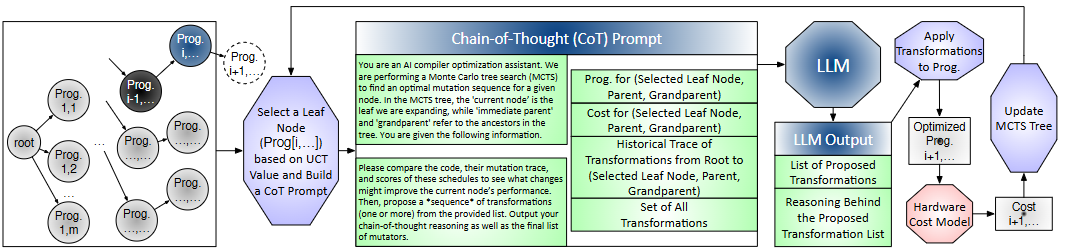
optimization workflow
把LLM 的"推理/规划能力"融进编译器自动优化里,做成一个无需微调的大模型+MCTS(蒙特卡洛树搜索)的"推理式编译框架"。目标是给模型服务(LLM/扩散等)的算子/层自动找出高效的编译变换序列(如 tile、fusion、vectorization、并行化、布局变换),在很少的采样预算下就拿到可观提速。
An overview of KEYDIFF
提出 KEYDIFF:一种不看注意力分数、只用"Key 向量相似度"来做 KV 缓存淘汰的长上下文推理方法(用"key 几何多样性"替代"注意力重权"做淘汰,在严格内存上限与分块预填充下仍能保住关键信息,兼顾精度与时延。),专为资源受限场景(如分块预填充、边端设备)设计。
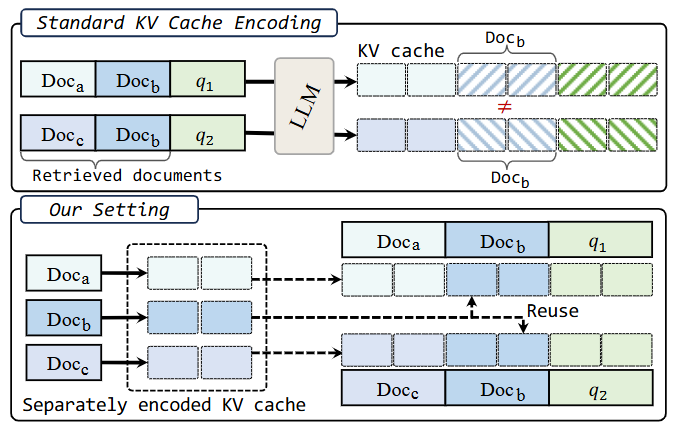
KV Cache Reuse
提出 KVLINK:把文档的 KV 缓存预先独立编码并复用,在 RAG、多段上下文等场景里避免对相同文档反复预填充;推理时把命中的文档 KV 直接拼接,只需少量额外计算即可生成答案。
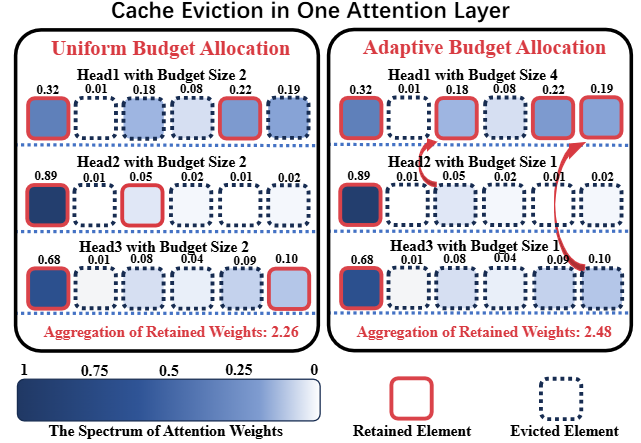
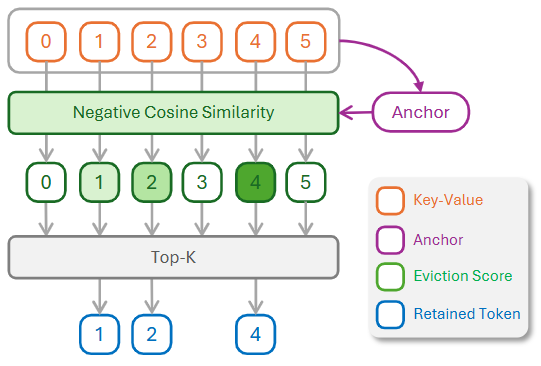
From Uniform to Adaptive Budget Allocation
提出 Ada-KV:在做 KV 缓存淘汰(Top-k/保留最重要的KV)时,不再给每个注意力头均分预算,而是按头自适应分配预算,从而在同样的总缓存上限下把精度损失更小、生成质量更高。

Dynamic Memory Sparsification (DMS)
提出"推理时超扩展(inference-time hyper-scaling)":通过压缩/稀疏化 KV 缓存,在相同算力与显存预算下让模型"想得更久或并行更多条推理链",从而把推理正确率再往上拧。为此作者给出一个轻量可训练的方法 DMS(Dynamic Memory Sparsification)。
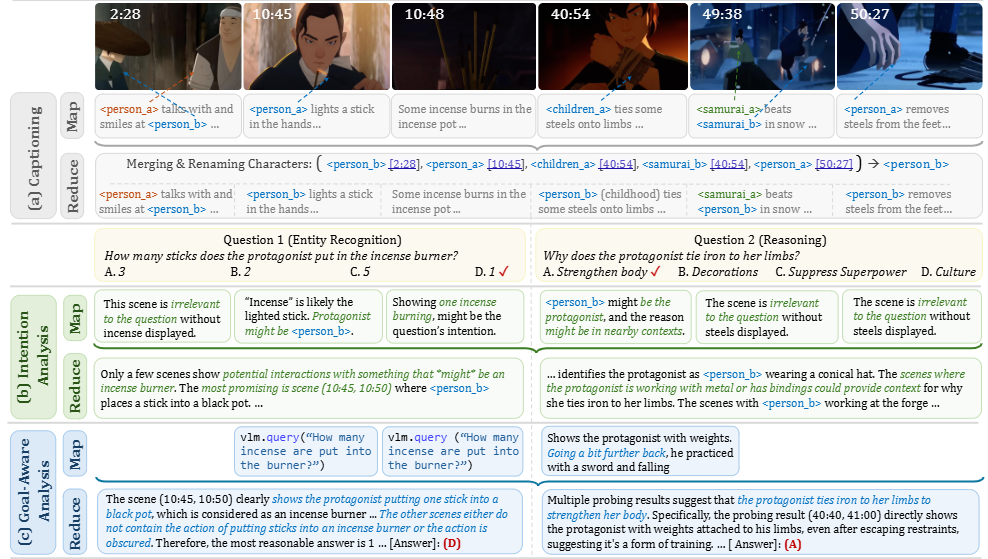
Overview. MR. Video validates the effectiveness of "MapReduce" principle with an LLM agent framework
这篇提出用"MapReduce 原理"做长视频理解的代理式框架 MR. Video:先把长视频切成许多短片段各自感知(Map),再把所有片段的信息全局汇总推理(Reduce),从而兼顾局部细节与全局上下文,避开 VLM 的上下文长度瓶颈,也比"逐轮检索关键片段"的视频代理更易并行、更全面。
- StreamBridge: Turning Your Offline Video Large Language Model into a Proactive Streaming Assistant
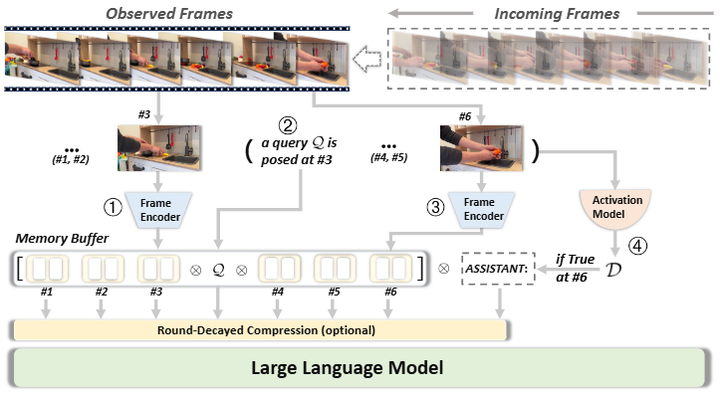
Overview of StreamBridge
提出 StreamBridge:把离线式 Video-LLM(StreamBridge=缓冲记忆 + 递减压缩 + 外置激活器 )无缝改造成"可串流、可多轮、会主动说话"的视频助理的通用框架,并配套了面向串流理解的大规模数据集 Stream-IT。
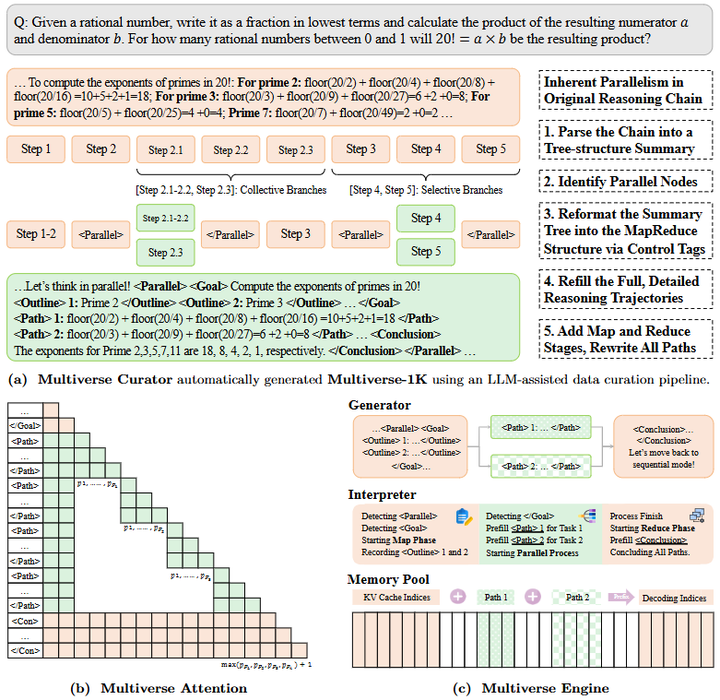
Instantiation Overview. Multiverse co-design data (Multiverse Curator), algorithm (Multiverse Attention),and system (Multiverse Engine) to enable real-world reasoning abilities through a rapid and seamless shift from AR-LLMs.
提出 Multiverse:一种把 MapReduce 思想内化语言模型(把"并行思考"的权力交回给模型本身; 让 LLM 在生成时自适应地并行拆解与无损合并,在不牺牲推理质量的同时获得更好的时延---性能扩展性。)、支持原生并行生成的新框架。模型在一次生成里由模型自己决定何时"拆分---并行---合并",从而在不丢失中间状态的前提下,加速长链式推理。
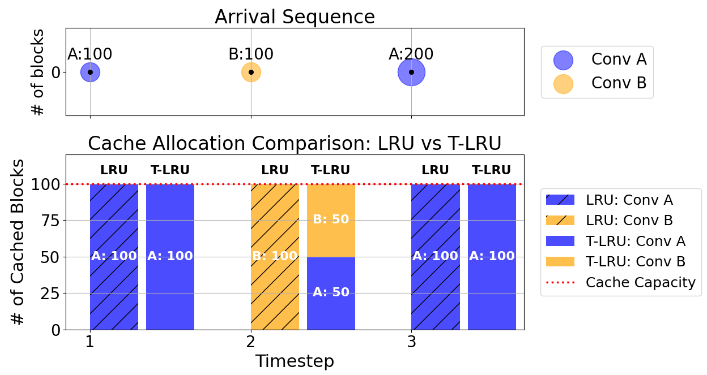
Difference between LRU and T-LRU
如何用更聪明的提示/前缀缓存(prompt/KV cache)策略降低 LLM 推理的"尾部时延"(tail latency)。作者提出 Tail-Optimized LRU(T-LRU):在常用 LRU 基础上加两行逻辑,优先从对下一轮时延无益的会话里"免费"裁掉多余的 KV,然后再按 LRU 逐出,目标是降低 P90/P95 的 TTFT。
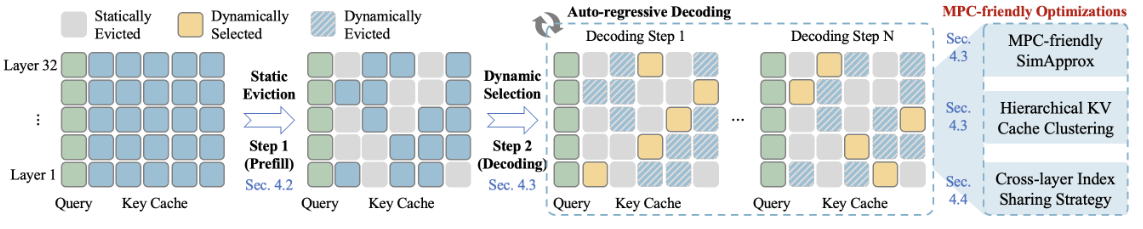
Overview of our proposed MPCache
把 KV 缓存淘汰(KV cache eviction)专门改造成"适合 MPC 私有推理"的版本,框架叫 MPCache。它面向用安全多方计算(MPC,multi-party computation)做 LLM 推理时的超高时延与通信开销,提出"一次静态淘汰 + 步进式动态挑选"的组合,并用多项"MPC 友好"技巧把常见瓶颈(相似度计算、top-k、按索引聚簇取数)大幅降开销。