DeepSeek重磅归来!这次,新模型重新定义了数学推理的本质。
在沉寂数月后,一条简短的"鲸鱼回来了"让DeepSeek再次成为焦点。
昨晚,DeepSeek发布新一代数学模型DeepSeekMath-V2,该模型在IMO 2025数学奥林匹克竞赛中达到金牌水平,标志着AI在复杂推理领域迈出了关键一步。

DeepSeekMath-V2最引人注目的突破在于其创新的自我验证框架。传统的AI数学解题依赖于最终答案的正确性,而新模型构建了一个类似"学生-老师-督导"的三重验证机制:
-
证明生成器在解题过程中必须进行自我评价,诚实地承认可能的错误;
-
证明验证器则像专业教师那样,将证明过程区分为完美、有小瑕疵和有根本错误三个等级;
-
元验证机制进一步确保评估的可靠性,形成完整的质量闭环。
这种架构转变带来了显著的性能提升。在IMO-ProofBench基准测试中,DeepSeekMath-V2以约10个百分点的优势超越了谷歌的DeepThink模型。
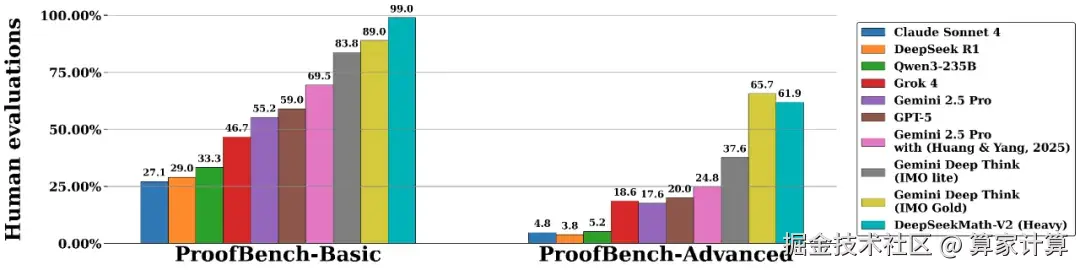
更为难得的是,该模型在普特南大学生数学竞赛中取得了118分的接近满分成绩,展现出与传统数学专家相媲美的解题能力。
从技术层面看,DeepSeekMath-V2的深远意义不仅在于模型架构的创新,更在于其对数学推理本质的重新定义:从依赖最终答案的奖励机制,转向对推理过程严谨性的深度追求。
这种转变使得AI能够更好地处理需要多步骤逻辑推理的复杂问题,为后续的研究方向提供了重要参考。
而对于广大开发者和企业用户而言,DeepSeekMath-V2的开源发布降低了高质量数学推理模型的使用门槛,未来可能加速AI在教育科技、科研辅助等领域的应用落地。
当然,DeepSeekMath-V2的复杂推理架构对计算资源提出了更高要求,特别是在处理长序列推理任务时,需要充足的内存和高效的计算调度。
DeepSeekMath-V2的发布,体现的是一种研究思路的革新,它代表了AI从结果导向向过程导向的重要转变。
并且这种自我验证框架的价值不仅限于数学领域,未来有望扩展到法律推理、代码分析、科学发现等需要严谨逻辑的更多场景。这种范式转变将重新定义AI在专业领域的应用边界。
它证明通过改进学习范式而非单纯扩大规模,AI仍然存在巨大的进步空间。对于整个AI社区而言,这或许预示着新一轮创新浪潮的开始。
在这个过程中,稳定可靠的算力基础设施将成为创新应用快速落地的重要保障。
如果您正在使用DeepSeek系列等前沿大模型进行AI领域的创业或研究,却受困于高昂的算力成本或高并发下的推理稳定性等问题,欢迎留言或私信我们,找到您的降本增效突破口~