目录
思考:向模型中传递数据时,需要提前处理好数据
1、目标:将评论内容转换为词向量,即使用Embedding层将文本中的字符转换为固定维度的词向量
2、每个词/字转换为词向量长度(维度)200 (因为项目我们使用腾讯训练好的Embedding权重 4762*200)
3、每一次传入的词/字的个数是否就是评论的长度? 应该是固定长度,每次传入数据与图像相似。 例如选择长度为70。则传入的数据为70*200
4、一条评论如果超过70个词/字怎么处理? 直接删除后面的内容
5、一条评论如果没有70个词/字怎么处理? 缺少的内容,统一使用一个数字(非词/字的数字)替代。
- 针对文本长度不足的情况,使用Padding填充;对超出长度的文本,删除多余部分。
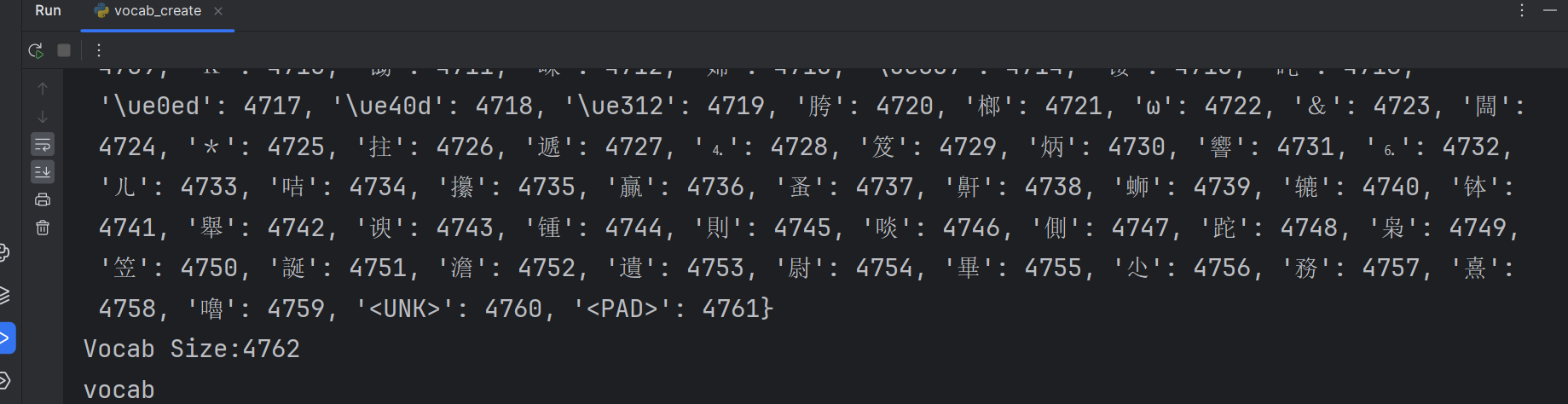
6、如果语料库中的词/字太多是否可以压缩? 可以,某些词/字出现的频率比较低,可能训练不出特征。因此可以选择频率比较高的词来训练。例如选择4760个。(ps:剩下两个一个是'PAD',一个是'UNK')
7、被压缩的词/字如何处理? 可以统一使用一个数字(非词/字的数字)替代。
一.构建词汇表
1.定义最大词汇单词表个数和UNK,PAD
python
from tqdm import tqdm
import pickle as pkl
MAX_VOCAB_SIZE=4760
UNK,PAD='<UNK>','<PAD>'tqdm用于显示后续for循环进程
pkl用于保存后续的词汇表字典文件
2.定义创建字典的函数
file_path是微博评论文件地址
max_size即为字典最大词汇数
min_freq是词的最小出现次数
python
def build_vocab(file_path,max_size,min_freq):
tokenizer=lambda x:[y for y in x]
vocab_dic={}tokenizer是一个函数,用于后续的将评论切割成每个单词
vocab_dic用于保存单词的字典
3.初步构建词汇表
python
with open(file_path) as f:
i=0
for line in tqdm(f):
if i==0:
i+=1
continue#跳过第一行表头
lin=line[2:].strip()
if not lin:#检查line中有没有内容
continue
for word in tokenizer(lin):
vocab_dic[word]=vocab_dic.get(word,0)+1#统计每个字出现的次数,字典保存打开评论文件,使用for循环一行一行读取(不用pandas读取的原因,评论中存在很多逗号,而csv文件就是以逗号来分隔开的)
i=0时是表头,直接跳过

line2:切片即提取评论正文部分,strip()去除末尾空格
tokenizer()会先将lin中的这一行评论内容分词
for word in tokenizer(lin):
vocab_dic[word]=vocab_dic.get(word,0)+1统计每个单词出现的次数,可以看见初步构建的单词表有10026个单词 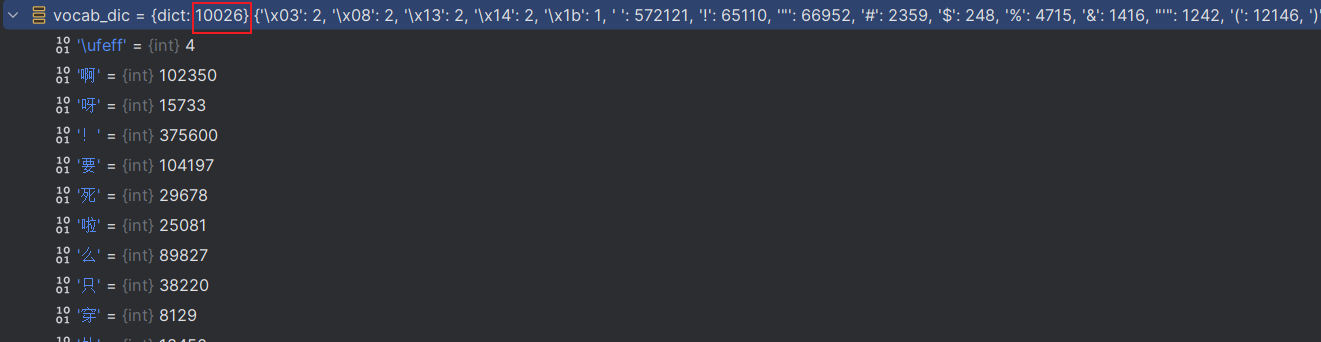
4.词汇表排序(4760)
先判断出现次数是否大于最小值,再根据出现的次数从大到小排序,提取前4760个
python
vocal_list=sorted([_ for _ in vocab_dic.items() if _[1]>min_freq],key=lambda x:x[1],reverse=True)[:max_size]#先判断出现次数是否大于最小值,再根据出现的次数从大到小排序,提取前4760个获取排序之后的字典,值即为该单词的独热编码
python
vocab_dic={ word_count[0]:idx for idx,word_count in enumerate(vocal_list) }#获取排序之后的字典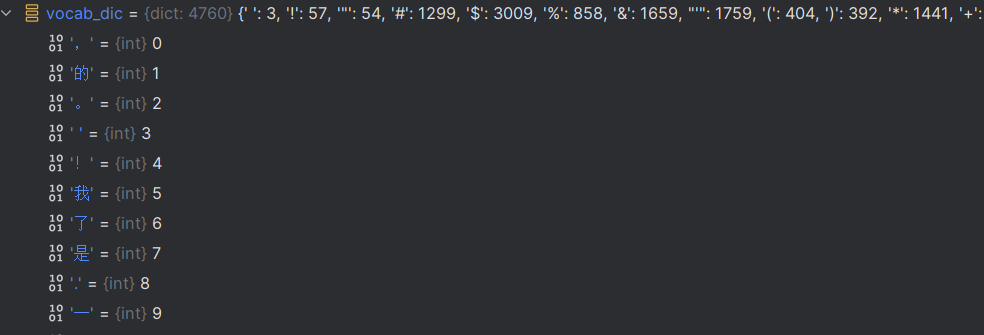
5.将UNK和PAD加入字典(4762)
python
vocab_dic.update({UNK:len(vocab_dic),PAD:len(vocab_dic)+1})#增加UNK和PAD
print(vocab_dic)6.保存独热编码的字典文件
python
pkl.dump(vocab_dic,open('simplifyweibo_4_moods.pkl','wb'))
print(f"Vocab Size:{len(vocab_dic)}")
return vocab_dicpkl保存之后再以load()打开,返回的是原文件类型
7.调用函数
python
if __name__=='__main__':
vocab=build_vocab('simplifyweibo_4_moods.csv',MAX_VOCAB_SIZE,3)
print('vocab')