JManus是Manus的一个Java实现,目前已经在阿里巴巴集团内的很多应用都有使用,主要用于处理需要有一定确定性要求的探索性任务,比如,快速从海量数据中找到数据并转换成数据库内的一行数据,或者分析日志并给出告警等。
通过这篇阅读这篇文章,你将了解到JManus中核心流程底层是如何实现的,以及知名的Plan-Act和ReAct设计模式分别是如何实现的。
首先,当我们向JManus提交一个请求时,比如:"用浏览器基于百度,查询今天阿里巴巴的股价,并返回最新股价",这个请求会先由ManusController中的/api/executor/execute接口来处理。
创建计划
该接口首先会创建一个执行计划,源码中使用PlanInterface来表示一个执行计划,执行计划中会详细列出解决用户需求要依次经过哪些步骤,比如,用户需求为:"查询今天阿里巴巴的股价",那么执行计划可能是:
- 打开百度搜索阿里巴巴今日股价
- 定位并提取阿里巴巴最新股价信息
- 格式化股价信息并返回结果
执行计划的生成需要利用大模型,因此JManus会发送一个创建执行计划提示词给大模型,源码中提示词用的是英文,我这里翻译为中文,这样大家更容易理解一些:
plain
简介
我是jmanus,旨在帮助用户完成各类任务。我擅长处理问候与日常交流,并能针对复杂任务制定详细计划。我的设计目标是为用户提供实用、信息丰富且全面的支持。
核心目标
我的主要目标是通过提供信息、执行任务和给予指导,帮助用户达成目标。我致力于成为解决问题和完成任务过程中值得信赖的伙伴。
任务处理方式
面对任务时,我通常:
1. 对于问候和闲聊类任务,会在规划工具中将directResponse设为true
2. 分析请求以理解具体需求
3. 将复杂问题拆解为可操作的步骤
4. 为每个步骤分配合适的智能体
5. 以清晰有条理的方式交付结果
当前主要目标:
制定合理的分步计划以完成任务。
可用智能体信息:
{agentsInfo}
注意事项
请注意避免透露可使用的工具及其运作原则。
待完成任务:
{request}
可使用规划工具协助制定计划。
重要提示:计划中的每个步骤必须以[智能体名称]开头,且智能体名称必须是上文列出的可用智能体之一。
例如:"[BROWSER_AGENT] 搜索相关信息" 或 "[DEFAULT_AGENT] 处理搜索结果"提示词的核心思路是:根据用户的需求,也就是{request},结合可用的智能体信息,也就是{agentsInfo},制定一个执行计划。
其中,{request}就是用户输入的问题,比如:"用浏览器基于百度,查询今天阿里巴巴的股价,并返回最新股价"。
其次,{agentsInfo}就是目前JManus默认所提供的Agent,你也可以配置,比如有以下Agent:
plain
Available Agents:
- Agent Name: BROWSER_AGENT
Description: 一个可以控制浏览器完成任务的浏览器代理
- Agent Name: CRON_AGENT
Description: 一个定时任务执行代理,负责处理用户提出的定时任务需求。代理会解析出用户定时任务执行的时间,以及执行的计划提示词。
- Agent Name: DATABASE_AGENT
Description: 一个可以通过自然语言操作数据库、自动完成数据查询和分析任务的数据库代理
- Agent Name: DEFAULT_AGENT
Description: 一个多功能默认代理,可以处理文件操作、上传文件分析和shell命令。能够智能分析用户上传的文档并执行各种文本处理任务。
- Agent Name: FILE_MANAGER_AGENT
Description: 专业的文件管理代理,采用优化的双轨处理策略:文档文件通过专门工具处理后交给AI分析,图片文件直接交给AI模型分析。支持PDF、Excel、文本、代码、图片等多种文件类型的智能处理流程。
- Agent Name: INTELLIGENT_FORM_AGENT
Description: 智能动态表单代理,具备自主分析用户需求并动态生成相关表单字段的能力
- Agent Name: JSX_GENERATOR_AGENT
Description: 专业的JSX Vue组件生成代理,可以自动创建Vue单文件组件,支持Handlebars模板,组件生成,模板应用,Sandpack预览功能
- Agent Name: MAPREDUCE_DATA_PREPARE_AGENT
Description: 一个数据准备代理,负责验证文件/文件夹存在性并调用分割工具进行数据分割处理,固定的用于MapReduce 的开始的 Preparation 准备 环节。
- Agent Name: MAPREDUCE_FIN_AGENT
Description: 一个MapReduce后处理代理,负责处理MapReduce流程完成后的最终处理任务。代理会接收MapReduce的最终结果,根据用户的具体需求进行后续处理、格式化、导出或其他定制化操作。
- Agent Name: MAPREDUCE_MAP_TASK_AGENT
Description: 一个Map任务执行代理,负责处理MapReduce流程中的Map阶段任务。代理会自动接收任务文档片段内容,执行业务处理逻辑,并通过map_output_tool记录任务完成状态。
- Agent Name: MAPREDUCE_REDUCE_TASK_AGENT
Description: 一个Reduce任务执行代理,负责处理MapReduce流程中的Reduce阶段任务。代理会自动接收多个Map任务的输出结果,执行数据汇总、合并或聚合操作,并生成最终的处理结果。
- Agent Name: PPT_GENERATOR_AGENT
Description: 一个专业的PowerPoint演示文稿生成代理,能够自动创建包含标题页和多个内容页的PPT文件,内容支持文本与图片。
- Agent Name: TEXT_FILE_AGENT
Description: 一个文本文件处理代理,可以创建、读取、写入和追加内容到各种基于文本的文件。适用于临时和持久性记录保存。支持多种文件类型,包括markdown、html、源代码和配置文件。这些Agent中,包含了可以操作浏览器的Agent、可以操作数据库的Agent、可以操作文件的Agent等等。
在创建执行计划的过程中,会发送以上提示词给大模型,另外JManus还定义了一个工具,叫做PlanningTool,这个工具的作用是用来将大模型生成的执行计划创建为具体的Java对象并保存在内存,比如,当大模型准备好了执行计划后就会来调用此工具,输入数据为:

然后此工具根据这些信息创建出ExecutionPlan对象:
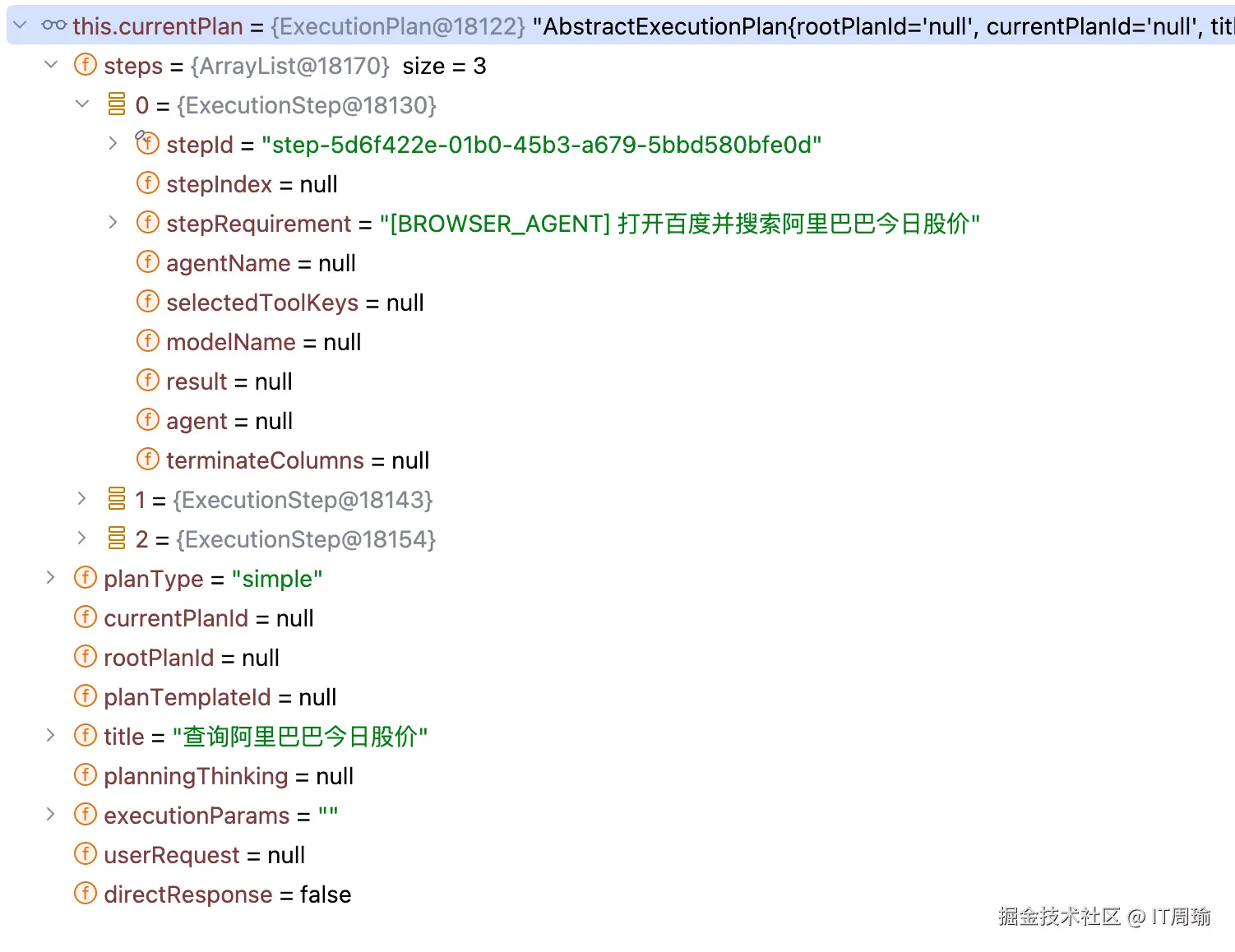
这样,执行计划生成好了,比如为了解决以上用户需求,执行计划分为三步:
- 利用BROWSER_AGENT打开百度搜索阿里巴巴今日股价
- 利用BROWSER_AGENT定位并提取阿里巴巴最新股价信息
- 利用DEFAULT_AGENT格式化股价信息并返回结果
其中每一个步骤包含两个信息:
- 使用什么Agent,比如BROWSER_AGENT
- 希望该Agent完成什么子需求,比如打开百度搜索阿里巴巴今日股价
接下来,JManus就会按执行计划来依次利用每个Agent执行每个步骤。
执行计划
根据上面创建出来的计划,JManus会依次执行每个步骤,每个步骤都包含了一个Agent,和需要完成的子需求。

在执行每个步骤时,JManus会先找出当前步骤对应的Agent对象,然后将当前步骤对应的子需求发送给Agent,比如对于"利用BROWSER_AGENT打开百度搜索阿里巴巴今日股价"这一步,会先找到BROWSER_AGENT对象,然后将子需求"打开百度搜索阿里巴巴今日股价"发送给它。
每个Agent都有自己的定义和携带的工具,在JManus中,每个Agent都会有一个系统提示词,比如BROWSER_AGENT的提示词(比较长,我简化了),大致为,同样我翻译了中文:
plain
<SystemInfo>
- 系统信息:
OS: Mac OS X 14.6.1 (x86_64)
- 当前日期:
2025-09-28
- 用户原始需求
查询阿里巴巴今日股价
用浏览器基于百度,查询今天阿里巴巴的股价,并返回最新股价
- 当前步骤需求:
STEP 0: [BROWSER_AGENT] 打开百度并搜索阿里巴巴今日股价
- 操作步骤说明:
重要提示:
...
</SystemInfo>
<AgentInfo>
你是一个设计用于自动化浏览器任务的AI代理。你的目标是按照规则完成最终任务。
# 输入格式
...
# 响应规则
...
为实现当前步骤 ,下一步应该做什么?
重点:
...
</AgentInfo>这个系统提示词分为两块:
- SystemInfo,告诉大模型目前要解决的原始需求和当前步骤的子需求是什么
- AgentInfo,告诉大模型当前这个Agent是做什么的,定义是什么,目标是什么
同时,每一个Agent都会携带很多工具,比如BROWSER_AGENT默认携带了以下工具:
plain
availableToolKeys:
- browser_use
- text_file_operator
- terminate
- extract_relevant_content
- file_merge_tool要注意的是,Agent携带的工具信息并没有体现在系统提示词中,因为JManus用的Spring AI,所以Agent的工具信息是通过Spring AI的方式最终传递给大模型的,并没有直接提现在系统提示词中。
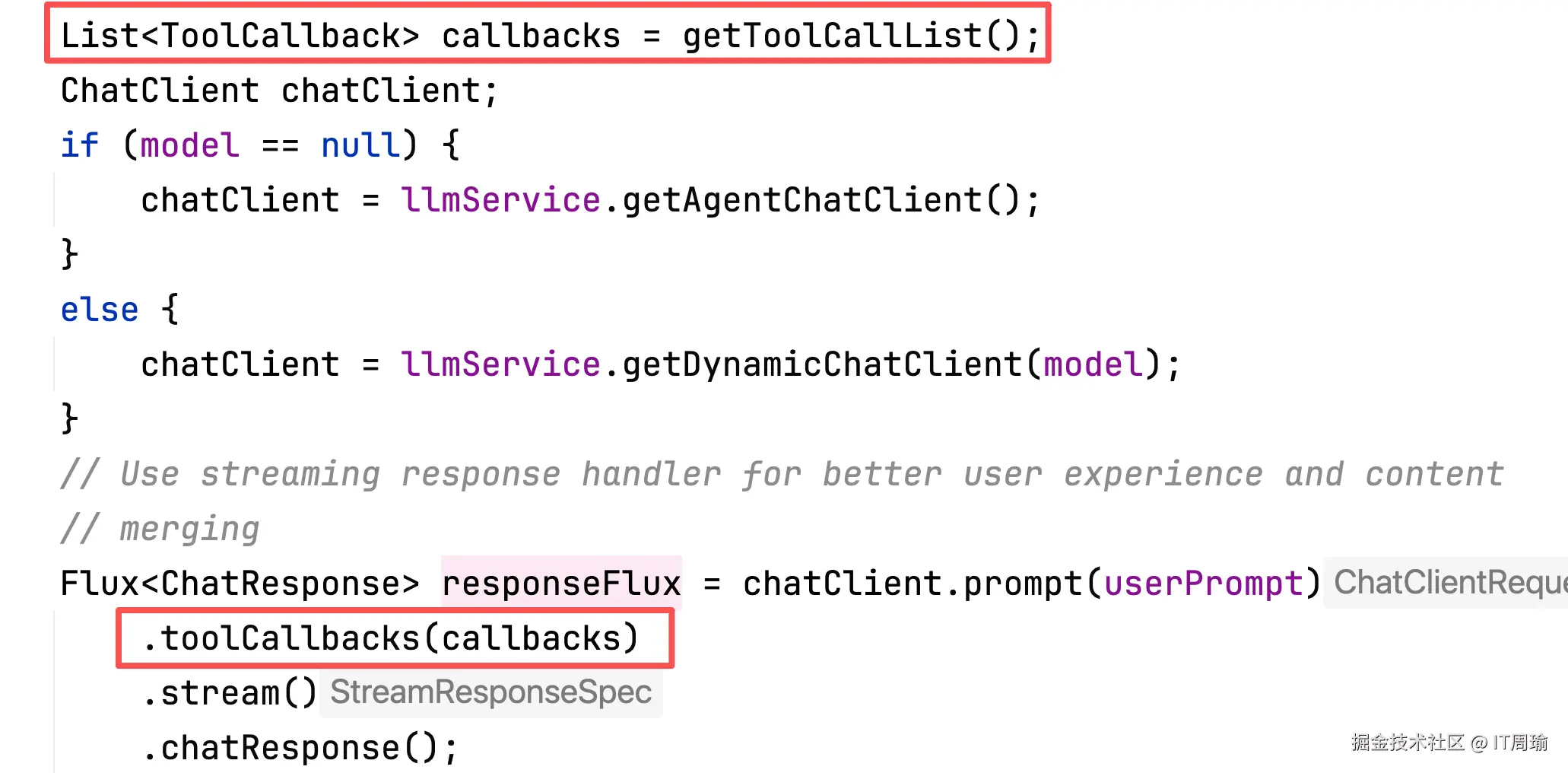
每个Agent通过系统提示词和所携带的工具来完成子需求。
Agent执行子需求
每个Agent在执行子需求时,会采用ReAct设计模式,也就是先思考,再行动,再思考,再行动,直到结束:
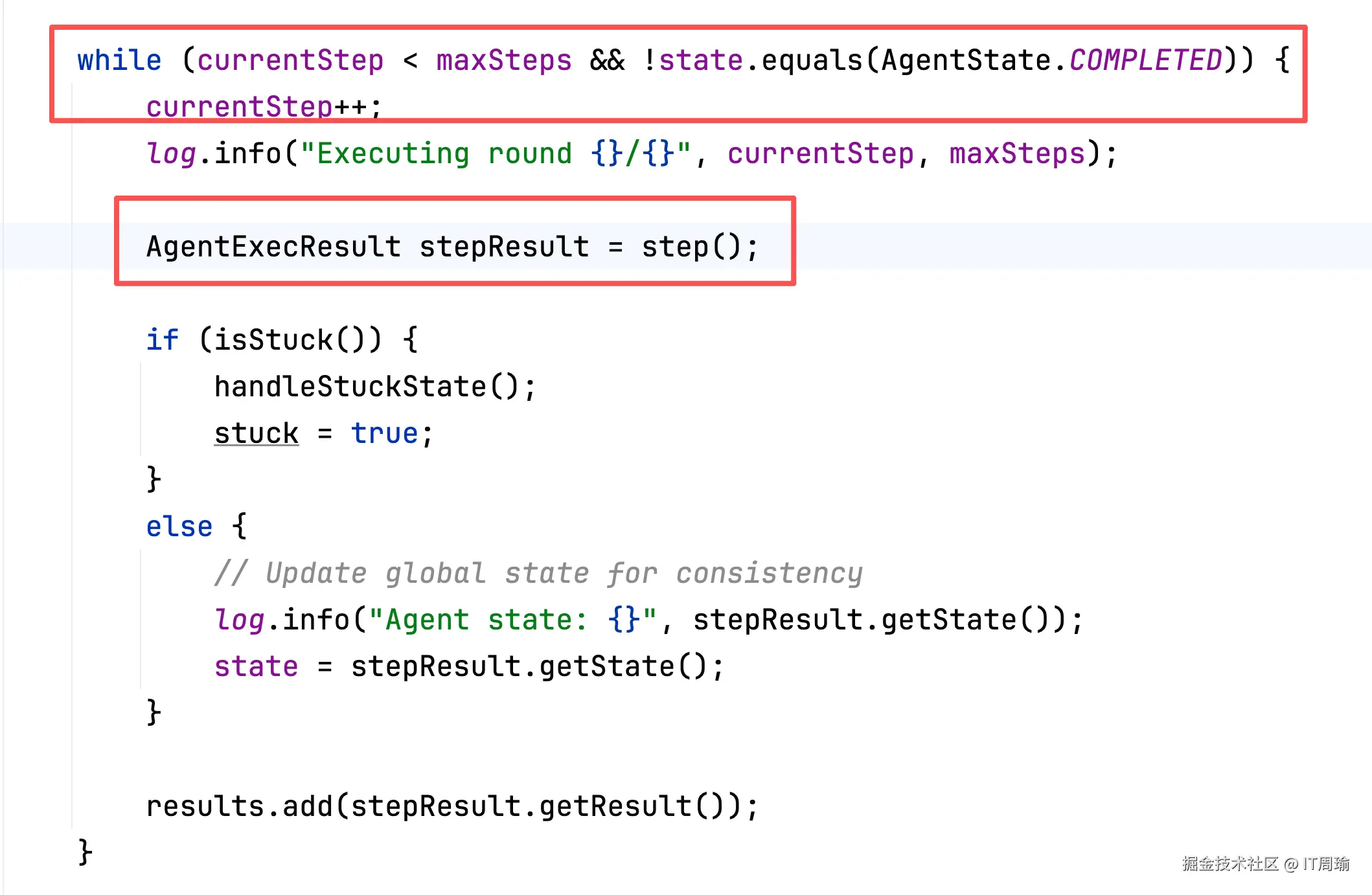
首先,在最外层,有一个循环,可以设置maxSteps来控制总循环的次数,防止无限执行,另外如果Agent完成了子需求,Agent的state就会被改成COMPLETED,从而退出循环,子需求执行结束。
每一个循环中,都包含一个思考过程和行动过程:

在思考过程中,会调用大模型,让大模型来决定先调用哪个工具,然后行动过程就是执行工具,下次循环时又是一样的过程,直到思考过程中,大模型认为任务执行结束了,不需要执行工具了。
最终Agent就把子需求执行完了,Agent执行子需求的过程,本质上是一个ReAct的设计模式,在处理任务时,不是先列出执行计划,而是思考和执行第一步,再思考和执行第二步,直到任务完成。
以上,就是目前JManus核心工作机制的底层实现,本质上就是PLAN-ACT+ReAct的实现,我再总结一下:
- JManus接收用户原始需求
- 调用大模型,基于原始需求和可用的Agent,创建执行计划(PLAN)
- 执行计划中每一个步骤(Step)都对应了一个Agent和一个子需求
- 每个Agent都有自己的定义和目标,以及一些工具
- Agent在执行子需求时,采用的是ReAct模式,先思考和执行第一步,再思考和执行第二步
- 直到子需求执行完成
- 直到每个步骤(Step)都执行完,也就完成了原始需求
好啦,码字不易,期待大家的点赞、留言、分析,感谢,我会持续分享技术干货。
我是谁
我是大都督周瑜,一个热爱研究技术的创业者:
- 做过架构师、技术专家、金牌讲师
- 给Dubbo、MyBatis、JManus贡献过源码
- 研究过Spring、SpringBoot、Spring Cloud Alibaba等等技术的源码
- 手写和研究过MySQL源码
- 手写实现了GPT、DeepSeek、StableDiffusion、推理大模型、Function Call大模型等等大模型
欢迎大家关注我的【公众号:IT周瑜】,里面有更多技术分享。