
摘要
高峰需求预测涉及预测特定时期内的最大电力需求,对维持电力系统的效率和稳定性起着关键作用。 在先进的计量基础设施、电动汽车等本地能源应用以及间歇性可再生能源的日益采用的推动下,电力系统的快速发展带来了更大的随机性并降低了峰值需求的可预测性。 鉴于迫切需要满足不同环境下更多样化的实施要求,准确可靠的峰值需求预测变得越来越重要。 据我们所知,这项研究首次对峰值需求预测方法进行了全面概述。 它系统地回顾了 20 世纪 50 年代以来发表的 186 项研究,并根据这些方法的发展时间表将其分为三个阶段。在此基础上,该研究定义了峰值需求预测的统一框架,并提供了将这些方法与电力系统的实际需求联系起来的深入分析。 值得注意的是,它*强调了机器学习驱动的预测模型在解决现代能源环境日益复杂的问题方面日益重要 。 此外,这项研究还确定了关键的研究差距,并 指出了有潜力推动该领域创新的新兴趋势 。
本文符号表

引言
在可再生能源、高级计量基础设施 (AMI) 1 的整合以及对以数据为中心的解决方案的日益依赖的推动下,全球能源格局正在经历范式转变。 AMI 系统的核心是智能电表,它可以实现能源供应商和最终用户之间的实时数据交换。 据英国政府报告,截至 2024 年中期,已安装了 3620 万个智能电表,占英国所有电表的 63% 2。 智能电表为需求侧管理 (DSM) 等智能能源应用铺平了道路。 另一方面,高分辨率能耗数据与风能等分布式间歇性能源的集成,给电力需求带来了前所未有的多样性和复杂性3。
为了满足这些需求,发电厂采用了不同的发电机组。在所有机组中,高峰负荷发电厂因其经济低效和对环境的影响而脱颖而出,因为它们只在需求高峰期运行,而且往往是高污染的机组。Sheffrin等人。4建议将高峰负荷降低5%-15%可以产生实质性的好处,包括资源优化和更低的实时电价。然而,实现这些削减需要有效的策略来管理高峰需求。这些策略通常利用激励和惩罚机制,包括可中断负荷控制、需求侧竞价和紧急需求响应等项目5,6。这些战略的中心方面是准确预测未来的高峰需求,这将确保最佳的资源分配,并将不必要的成本和环境影响降至最低。
峰值需求预测不同于一般负荷需求预测。 一般负荷需求预测侧重于稳定系统条件下由可预测的每日或季节性趋势驱动的典型用电模式,而峰值需求预测则针对对电力系统施加最大压力的罕见和极端事件。 这些事件对极端因素高度敏感,例如恶劣的天气条件7,这可能导致电力需求突然过度激增,需要专门的预测方法来维持系统可靠性并有效管理资源。 此外,不断发展的电力系统,以风能和太阳能等分布式和间歇性能源的日益集成为标志,加上储能技术的进步,为峰值负荷预测带来了新的动力。 这些变化使得传统的预测方法往往不够充分,迫切需要能够应对这些动态挑战的先进技术。
为了满足这些需求,机器学习 (ML) 已成为现代电力系统峰值需求预测的变革性工具。 现代电力系统包含多种变量,包括可再生能源发电模式、储能动态和实时需求波动。 通过集成这些变量、利用高分辨率数据和自动特征提取,机器学习驱动的方法为高效的峰值需求预测提供动态和自适应功能8。 这些机器学习驱动的方法包括应用深度学习来捕获峰值需求中的复杂关系、先进的概率模型来量化预测的不确定性,以及将机器学习技术与传统方法相结合来提高精度和鲁棒性的混合方法9。 此外,通过这些机器学习驱动的技术实现准确的峰值需求预测对于实现环境和经济目标至关重要。 通过预测需求峰值,系统运营商可以启动需求方措施,优化低排放源的调度,并避免开启通常为紧急情况保留的碳密集型调峰发电厂。 更好的远见还可以更有效地整合间歇性可再生能源,减少弃风和平衡需求。 对于资源规划者来说,准确的预测可以通过确定真实的容量需求、防止过度建设和提高成本效率来为基础设施投资提供信息。 如表 1 所示,这些预测通过提供支持其运营和战略目标的定制效益,满足电力市场主要利益相关者(包括电网运营商、电力零售商、最终用户和政府)的具体需求和优先事项10-12。
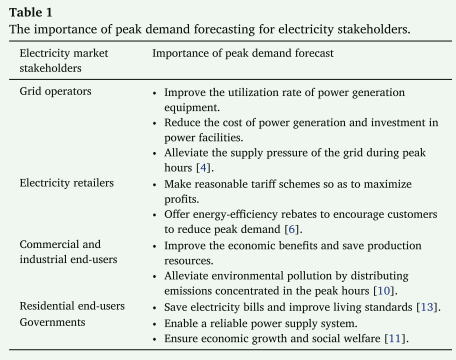
表1 峰值需求预测对电力利益相关者的重要性。
鉴于电力系统对机器学习的依赖日益增加及其对峰值需求预测的变革性影响,对其演变和现状进行系统回顾至关重要。 尽管人们对这一领域的兴趣日益浓厚,但尚未全面讨论这一特定领域。 认识到这一差距,本研究研究了峰值需求预测方法的发展,重点关注主要研究问题:峰值需求预测方法如何从统计方法演变为机器学习驱动的技术,以及这些机器学习的进步如何应对现代电力系统的挑战? 该评论强调了方法趋势,确定了现有挑战,并探索了峰值需求预测的未来创新途径。
与一般负荷预测不同,一般负荷预测已在现有研究和调查14-17中进行了广泛的审查,这次审查特别将其范围缩小到高峰需求预测。几篇相关的调查论文为这一领域提供了有价值的见解。例如,3讨论了各种灵活资源在微电网中的作用,强调了它们对运营战略和可再生能源整合的影响,这两者对于确保稳定和可靠的高峰需求预测至关重要。18研究了需求响应在管理预测不确定性方面的作用,揭示了影响高峰需求预测的因素。此外,19回顾了基于人工智能的负荷预测策略,强调了混合和集成技术在可持续能源规划中提高预测精度的潜力。本研究以高峰需求预测为研究重点,将高峰需求预测方法与现代电力系统的实际需求相结合,进行了深入的探索。在不断发展的电力系统背景下,该研究进一步强调了ML驱动的高峰需求预测模型在应对动态和多方面环境中遇到的日益复杂的挑战方面的变革性作用。
这项研究的贡献有四个方面。
- 首先,它对峰值需求预测方法的演变进行了全面分析,强调了机器学习在解决现代电力系统复杂性方面的变革性作用。
- 其次,它建立了一个统一的框架来定义高峰需求预测,综合了回顾的研究。 该框架可作为未来研究的参考,并为解决该领域的具体挑战提供基础。
- 第三,本研究深入分析了各种机器学习驱动的预测方法的应用背景、优点和局限性,为其实际用途提供了有价值的见解。
- 最后,它确定了整合新兴技术的尚未探索的机会,并为未来的研究提供了路线图。
本文的其余部分结构如下:第 2 节详细介绍了所使用的系统审查方法,并总结了文献中的主要发现,包括峰值需求预测的统一框架。 第 3 节强调了早期电力系统面临的挑战,并回顾了传统的峰值需求预测方法及其局限性。 第 4 节追溯了峰值需求预测方法的演变,并讨论了该领域的重大突破。 第五部分探讨了峰值需求预测方法的当代趋势。 本节还研究了各种应用环境中的这些方法,并反思了峰值需求预测的进步和当前的局限性。 第六节介绍了该领域的未来研究方向,确定当前的研究差距并指出新兴趋势。 第 7 节通过总结主要发现来总结本研究。
研究方法和主要发现
本研究的重点是机器学习在峰值需求预测中不断变化的作用,以应对电力系统中新出现的挑战。 与一般负荷预测侧重于预测稳定条件下的用电模式不同,峰值需求预测强调准确预测极值。这涉及考虑复杂因素的相互作用并解决不同预测背景下预测固有的不确定性。 这项研究将峰值需求预测定位为一般负荷预测的一个独特且不可或缺的组成部分,研究了该领域的发展以及机器学习如何通过提供更精确、可扩展和适应性强的预测方法来改变它。 为了实现这一目标,本次审查采用了系统策略,旨在获得对峰值需求预测方法的演变、其实际应用以及影响其有效性的因素的有意义的见解。 这种方法包括定义研究范围、选择和分析相关文献、将研究结果综合到一个统一的框架中、根据其发表日期将所选研究分为三个不同的阶段、对每个阶段进行深入分析,追踪机器学习在峰值需求预测中不断变化的作用,最后提供对未来研究方向的见解。
系统审查策略
表 2 详细介绍了检索和识别相关文献所采用的方法。 我们的搜索策略旨在系统地识别有关峰值需求预测的同行评审研究。 为了全面可靠的报道,文献检索在三个主要学术数据库中进行:Scopus、Web of Science 和 Google Scholar。 Scopus 因其广泛覆盖工程、能源和应用科学期刊和会议而被选中。 Web of Science 因其覆盖能源系统和运筹学领域的核心期刊而被纳入其中。 谷歌学术搜索通过提供跨学科和出版商最广泛的覆盖范围来补充这些来源。

搜索查询的重点是高峰需求预测,而不是一般的负荷预测。它们围绕该领域的三个核心概念进行组织:高峰("高峰"、"最大")、需求("需求"、"负荷"、"负荷需求")和预测("预测"、"估计"、"预测")。使用布尔运算符将这些术语组合在一起,形成查询('Peak' OR' Maximum') AND ('Demand' OR 'Load' OR' LoadDemand') AND ('Forecating' OR 'Estiments' OR'or'Forecast')。"负荷预测"或"电力需求预测"等更广泛的术语被刻意排除在外,因为它们往往检索本审查范围之外的研究。在搜索和筛选过程中考虑了词形变化,以确保措辞上的差异不会影响检索结果。例如,查询'峰值需求估计'也检索到包含'峰值需求估计'或'估计峰值需求'的结果。在检索记录后,我们采用了两个阶段的手动筛选过程。首先,我们过滤掉了不是用英语写的论文,或者没有在同行评议的场所发表的论文。其次,我们排除了那些没有集中于高峰需求预测方法或不同高峰需求预测方法的比较的论文。我们总共获得了自1950年以来发表的186篇论文。
我们还必须认识到,我们的分析可能没有反映能源部门专有高峰需求预测的最新发展,例如用于运营决策或交易的机密算法。这些进展不是公开的,很可能包括该领域的大量尖端知识。因此,本文提出的研究结果可能不能完全涵盖高峰需求预测的创新范围,特别是在私人和工业环境中。
调查结果概述
在应用初始筛选标准后,本次综述的核心数据集包括186项研究,所有这些研究都构成了未来分析的基础。
图1说明了总结高峰需求预测中使用的关键方法的字云。"人工神经网络"、"神经网络"和"回归"等关键词在词云中占据主导地位,反映出它们在传统和现代预测技术中的核心作用。LSTM(长期短期记忆网络)和CNN(卷积神经网络)等术语突出了ML模型在现代电力系统中越来越多的使用。同时,ARIMA(自回归综合移动平均)的出现突显了统计时间序列模型在分析历史数据趋势方面的持续意义。像"混合"和"模糊"这样的术语强调使用集成和自适应方法来提高预测的准确性和稳健性。此外,"聚类"和"整体"等术语反映了专门技术的应用,以完善预测模型。

对回顾研究的分析表明,直到1990年,出版活动缓慢上升,1991年至2010年期间显著增加,从2011年起稳步增长,突显了该领域日益增长的学术兴趣和持续的进步。基于这些观察,高峰需求预测的发展可以大致分为三个不同的阶段:
- 最大似然法前阶段(至1990年):其特点是研究数量有限,依赖于线性回归和基本时间序列模型等传统统计方法。
- 向ML过渡(1991-2010):以混合模型的集成、改进的计算工具和早期ML技术的引入为标志。
- ML阶段(自2011年起):定义为广泛使用ML和数据驱动的预测模型,以解决分散电力系统的复杂性和可再生能源日益增长的作用。
请注意,这三个阶段是按出版年份定义的启发式时间段。由于方法的逐渐扩散,一些边界附近的论文呈现出相邻阶段的特点。例如,统计模型在ML时代仍然被广泛使用,早期的ML和混合研究出现在20世纪90年代。为了管理重叠,我们在多个部分引用这些研究,但只在阶段层面对每篇论文进行一次计分。因此,阶段总数是描述性的,应该与跨阶段杂交模式一起考虑,表8进一步总结了这些模式。为了避免重复计算,我们按出版年份保留计数,并将我们的结论集中在方向趋势上,如ML使用的增长和杂交的增加,这些趋势不依赖于严格的边界选择。
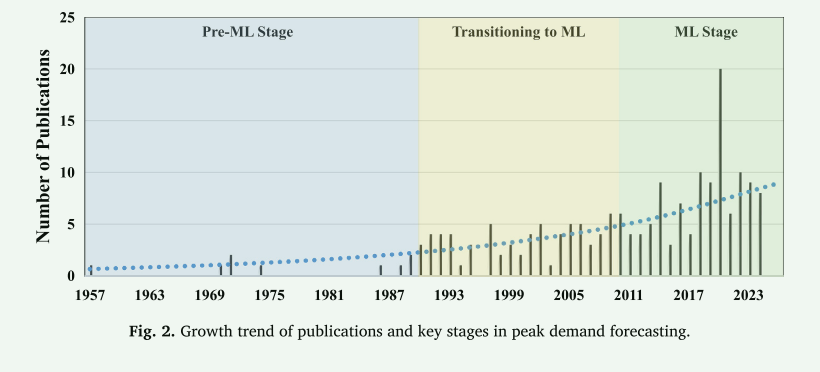
图2显示了高峰需求预测的这三个阶段的研究成果的出版趋势。具体地说,从1957年到1990年,研究贡献相对有限,主要集中在基本统计方法上。20世纪90年代是一个转折点,可能受到计算能力的提高和电力系统日益复杂的影响。在此期间,用于高峰需求预测的早期ML技术和混合模型开始出现。2010年代,研究产出稳步增长,可能受到全球对可持续能源的推动和可再生能源使用的增加的影响。在此期间,更多的ML技术,如LSTM和CNN获得了突出地位,反映出在准确性和可扩展性方面更适合于解决现代电力系统复杂性的模型的转变。随着这些方法和概念的转变,出版平台的种类也增加了。早期的研究主要发表在以工程为重点的期刊上,而最近的工作越来越多地出现在涵盖能源经济、政策和可持续发展的跨学科出版物上。这一范围更广的出版物意味着越来越多的人认识到,高峰需求预测超越了技术建模,在电力系统的战略决策中发挥着越来越重要的作用。
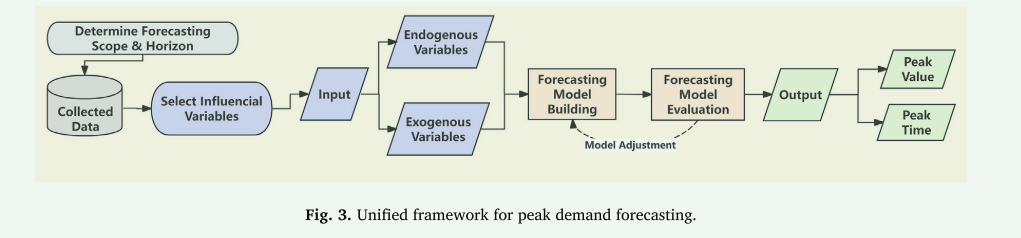
高峰需求预测的统一框架
根据回顾研究的分析,建立了高峰需求预测的统一框架,如图3所示。高峰需求预测从定义地理范围和时间范围开始。接下来,确定关键变量并将其分组为内生变量(例如,历史峰值负荷)和外生变量(例如,温度变化、公共事件和经济中断)。在构建模型之前,许多研究都强调专门的数据准备步骤。在高峰需求预测的背景下,这一步骤取决于数据的性质。来自智能电表和馈线的负荷记录通常包含间隙或传感器错误,这些错误已通过归罪或多源融合处理20,21。当变量大小不同时,特别是在家庭和建筑水平的研究中,归一化和标度经常用于稳定训练22,23。降噪和分解技术,如经验模式分解和小波被用来过滤波动性并揭示负荷序列中更清晰的结构24,25。特征选择方法,最著名的是主成分分析,已被用于降低维度并突出相关的天气或经济驱动因素26,27。诸如SOM或K-Means之类的聚类方法被应用于相似日期的选择,并捕捉具有相似行为的用户群28。在更罕见的情况下,基于极值理论(EVT)的数据增强被用来生成合成极值29,而稳健的回归框架明确地解释了异常30。此外,新兴的智能电表和物联网资源进一步增加了数据分辨率和可靠性的异构性,这就要求在数据预处理中采用融合和对齐策略。
然后使用统计方法或ML技术等方法开发预测模型。随后,通过迭代调整过程对模型进行评估,以确保可靠的性能31。最后,该过程提供输出,包括预测的峰值(最大负载)和/或峰值时间。在以下小节中,将详细讨论该框架的每个组件。
预测范围和水平
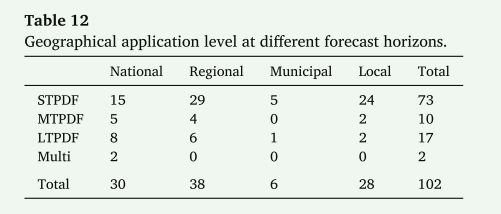
高峰需求预测跨多个范围运行,每个范围都针对电力市场中不同利益相关者的特定需求和目标(见表1)。这些范围在国家、地区、市政和地方各级各有不同,每个范围都解决了高峰需求管理的独特挑战。在国家一级,高峰需求预测支持大规模能源决策和基础设施发展,解决区域间能源转移问题,平衡国家电网。在地区层面,重点转向平衡州、省或公用事业地区内的电网运营,通常是将多个城市或地区的需求聚合在一起。市政一级的目标是城市能源需求,支持城市或城镇范围的需求管理,通常依赖于来自市政电网或城市范围的需求概况的汇总数据。在地方层面,预测侧重于规模较小的实体,如社区、微电网或配电馈线,这些实体需要更细粒度的数据输入(例如,使用时间数据)以优化运营效率。应当指出,地方和市政两级通常统称为"地方"级32,33。然而,它们在电力系统内的侧重点不同。地方一级强调较小的特定区域,捕捉高峰需求的细粒度变化,而市政一级考虑形成不同负荷使用模式的更广泛的因素,如城市密度和社会经济活动34。这种差异很重要,因为城市地区起着中介作用,将区域能源战略转化为本地化行动35。通过细化高峰需求预测中的地理范围,我们可以更准确地跟踪预测方法的趋势,探索不同地理级别的空间和社会经济差异,并更好地捕捉电力系统的层次结构。
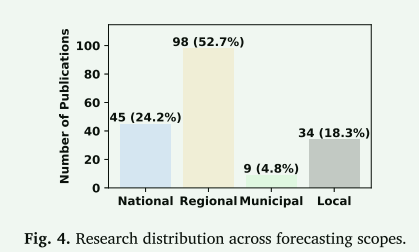
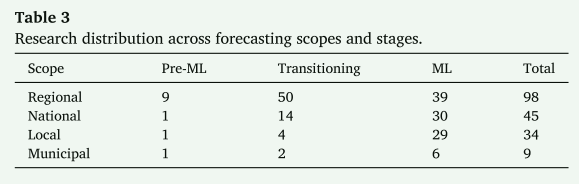
图4说明了回顾的研究在四个预测范围内的分布。总体而言,区域研究占比最大,为52.7%,强调了它们在网格管理中的关键作用。虽然市政工作很少,只有4.8%,但这反映出城市和城镇层面的研究有限。然而,这些数字是不同阶段的累积总和,随着该领域从早期阶段进入机器学习阶段,研究的重点已经转移。表3显示了不同范围、不同阶段的研究分布情况。在2011年前ML前和过渡阶段,地区性研究远远超过其他范围。自机器学习阶段以来,情况发生了变化。地区性、全国性和地方性研究的数字现在相似,市政研究总数为9项,其中6项处于本阶段。与早期相比,国家、地方和市政研究大幅增加,而地区研究减少。这一模式表明,大量的区域研究反映了早期阶段的重点,而不是目前的重点。这种转变可能源于对粒度数据访问的改进,以及更强大的建模工具包。尽管市政和地方研究的代表性仍然很低,但迁移学习、多任务学习和多智能体建模等先进ML技术的出现为在这些水平上改进高峰需求预测提供了有希望的途径。
除了范围之外,高峰需求预测在其时间范围内也是不同的。虽然一般负荷预测的预测范围是众所周知的,但对于高峰需求预测却没有这样的总结。因此,基于一般负荷预测研究中常用的定义14,36,并根据回顾文献中观察到的模式,我们将高峰需求预测的时间范围划分为以下几类:
- 短期高峰需求预测(STPDF),预测未来几个小时到几天(天数和7天)的高峰需求。
- 中期高峰需求预测(MTPDF),预测未来几周至几个月的高峰需求(12个月和12个月)。
- 长期高峰需求预测(LTPDF),以预测未来一年多的高峰需求。
在回顾文献的基础上,我们提出了每个预测期的主要关注点:
1)在STPDF中,日高峰需求预测是最常用的;
2)MTPDF主要关注周和月高峰需求;
3)LTPDF主要关注年度高峰需求预测。
高峰需求预测中的影响变量
准确的预测模型依赖于影响能源需求的内生和外生变量的组合。内生变量是直接代表系统行为和动态的内部因素,而外生变量是影响能源需求的外部因素,但本身并不是电力系统内部动态的一部分。
在高峰需求预测的背景下,内生变量主要由历史高峰负荷数据组成。具体地说,相似日期的高峰负荷数据是一种常用的内生变量,因为它允许预测算法识别和利用需求中的重复模式,例如每日或季节性波动,这些模式与对不同预测期的准确预测相关。例如,Yu等人。38提出了先识别相似日,然后利用这些天的高峰需求作为历史训练数据的算法,从而增强了模型准确预测未来日高峰的能力。
与一般负荷预测模型不同,一般负荷预测模型使用详细的、连续的数据集,例如每天的每小时数据点(即,每天24个数据点)或其他粒度间隔来预测总体负荷模式,而高峰需求预测模型专门关注峰值负荷值,例如每日峰值(即,每天单个数据点)或其他粒度间隔。高峰需求预测模型还可以包含高峰负荷时间(即每天的数据对)。通过只关注峰值负荷值和潜在的这些峰值的时间,高峰需求预测显著减少了数据点的数量。这种减少导致了更高的计算效率。Amjady39使用相同的历史数据比较了小时负荷预测和日高峰需求预测的输入特征数和计算时间。他们的统计分析显示,每日高峰需求预测只需要6个输入特征,而每小时负荷预测需要171个输入特征。
尽管历史峰值负荷等内生变量不可或缺,但仅依靠这些内生变量可能会忽视外生因素驱动的突发性冲击。例如,极端天气、日历事件和政策干预可能会引发不能仅从过去的峰值推断的突然偏离。此外,内生变量和外生变量之间的相互作用很少是线性或单向的。需求本身可以影响外生驱动因素,例如通过改变价格或激活需求响应,造成反馈循环,使模型设计复杂化。解决这些复杂性需要能够捕获非线性和双向关系的模型,在这些模型中,神经网络或递归体系结构等机器学习方法比静态回归框架具有明显的优势。
外生变量提供了额外的背景信息,提高了高峰需求预测模型的准确性和可靠性。在回顾研究的基础上,所使用的外生变量被分为四大类:天气、日历、经济和政策。表4突出显示了这些外部变量在三个开发阶段的高峰需求预测中的演变使用情况。据观察,天气变量在每个阶段都一直起着关键作用。另一方面,经济变量在ML阶段的影响显著增加。日历因素呈现出更复杂的趋势,最初在过渡阶段上升,然后在ML阶段略有下降。政策变量很少在所有阶段使用,一些研究选择排除外部变量。这一遗漏可能意味着合并不同变量的困难,或者表明,根据预测背景和现有数据,完全依赖内生变量的更简单的模型更实用或更有效。
表5总结了高峰需求预测模型中使用的外生变量,突出了在回顾研究中确定的常用变量。其中,最高和最低温度等天气变量很重要,因为它们捕捉到了直接影响能源需求模式的温度变化。还应该指出的是,一些变量是内部相关的,可能会相互影响。例如,康萨奇等人。40注意到具有明显季节性的月份(例如夏季或冬季)的高相对湿度会导致对制冷或供暖的需求增加,进而影响高峰需求预测的准确性。为了解决这个问题,作者建议根据相对湿度对温度波动的影响来量化相对湿度。通过将这种调整整合到模型中,他们能够修正不准确的输入变量,从而提高对高峰需求的预测精度。另一个限制来自对单一气象站测量的依赖。如果观测点和需求中心之间存在空间偏差,或者当工具中存在系统性偏差时,预测精度可能会受到影响。最近的研究通过整合多源气象数据集,包括再分析产品和卫星衍生指标,解决了这些挑战,从而增强了天气驱动的高峰需求预测的稳健性。
日历变量在有罕见特殊活动和常规节假日的地区有很大影响。在Saini和Soni26的研究中,考虑了埃及农历节日对高峰负荷的影响,并将斋月的影响量化为权重因子并输入到专家系统中。预测结果表明,考虑特殊节日因素的模型预测效果较好。此外,工商部门周末和假期的负荷消耗与工作日有很大差异,非工作日甚至可能不会出现需求高峰期。因此,一些评论作品基于这些日历因素单独对历史数据进行建模,以提高预测性能。Ramanathan等人。41分别为工作日和周末的每个小时训练模型,从而得到48个独立的模型来预测每日上午高峰和下午高峰。这种时分建模方法区分了工作日和非工作日,克服了传统模型在周末高峰需求预测中的不足。
国内生产总值(GDP)、家庭人口结构和市场价格等社会经济指标不仅提供了长期的背景趋势,还塑造了需求的结构构成。工业增长、城市化和家用电器拥有量的变化都会改变高峰负荷的大小和时间。纳入这些驱动因素有助于预测模型对消费模式的结构性变化保持敏感,并提高它们预测新兴需求压力的能力。
经济变量反映了在中长期范围内影响电力消费模式的更广泛的社会经济因素。经济变量的日益纳入,特别是在ML驱动的高峰需求预测阶段,表明了它们在考虑经济扩张、技术进步和消费者行为变化等因素方面的重要性。常用的经济指标包括国内生产总值指数、人口趋势和市场价格,它们提供了影响负荷需求的总体经济健康和人口变化的信息。此外,政策变量包括监管和政策驱动的因素,这些因素可以显著影响负荷消耗。例如,Jang等人。42计算需求侧管理措施对节约需求的影响,并将其整合到长期电力需求预测的概率框架中,有效地将需求侧管理视为缓解未来高峰电力负荷的关键因素。尽管与其他外生变量相比,政策变量的整合频率较低,但它们对于使预测模型与政府法规和战略能源举措保持一致至关重要。
高峰需求预测的评价指标
高峰需求预测模型的评价指标通常既依赖于标准的准确度衡量标准,也依赖于针对特定高峰情况而设计的专门指标。这些指标建立在将高峰需求正规化为在指定范围内观察到的最大负荷的基础上,反映了高峰条件下的系统压力和成本上升。常用的度量包括平均绝对误差(MAE)、均方误差(MSE)、均方根误差(RMSE)、平均绝对百分比误差(MAPE)和R2。虽然这些指标在一般负荷预测中已经很好地确立了43,但它们在高峰需求预测方面的含义值得进一步讨论。
一般误差指标。MAE已被广泛应用于早期的神经网络研究39,44,它提供了一种直观的以兆瓦为单位的平均误差大小的测量方法,很容易被操作员解释。然而,由于它对所有偏差都一视同仁,所以它不强调极端误差。均方误差和均方根误差对大偏差更敏感,当峰值误差在操作上非常关键时,通常更受欢迎45,46。然而,这种二次惩罚使RMSE对异常值特别敏感,如在非典型天气或极端天气条件下的研究47,48所示。在几十年的研究中,MAPE仍然是报告最多的指标8,49-51,因为它的标准化形式允许跨区域和数据集进行比较。然而,当实际负荷值很小时(例如,在供给者或家庭水平的研究中)22,52,它变得不稳定,并且它倾向于夸大非正态分布下的误差。R2在几个基于回归和建筑水平的工作中也有报道53,54,它是决定系数,提供了一种解释的差异度量。虽然R2对模型基准很有用,但在非平稳环境中可能会产生误导,因为高拟合度并不一定意味着准确的峰值捕获。为了避免乐观估计,研究通常采用区块或季节性交叉验证,并联合比较多个指标(例如,MAPE与RMSE和区间覆盖),特别是在数据有噪声或不平衡的情况下。
特定峰值指标。为了更好地捕捉极值时的性能,在混合模型中引入了峰值绝对百分比误差(PAPE)55,只量化每日或季节最大值的偏差。假设^y为预测峰值,y为实际峰值,n为训练样本数:
y^={y^1,y^2,...,y^n}\hat{y} = \{\hat{y}_1, \hat{y}_2, \dots, \hat{y}_n\}y^={y^1,y^2,...,y^n}
y={y1,y2,...,yn}y = \{y_1, y_2, \dots, y_n\}y={y1,y2,...,yn}
PAPE55的定义为:
PAPE=100%n∑i=1n∣y^i−yiyi∣\text{PAPE} = \frac{100\%}{n} \sum_{i=1}^{n} \left| \frac{\hat{y}_i - y_i}{y_i} \right|PAPE=n100%i=1∑n yiy^i−yi
PAPE的范围是[0,+∞)。PAPE等于0%表示经过完美训练的模型,而PAPE大于100%表示不可接受的模型。虽然PAPE专注于峰值精度,但它继承了MAPE在小分母下的不稳定性,并且不提供任何时间维度的误差。
峰值需求预测模型的时间精度通常通过命中率(HR)来评估,该命中率衡量预测的峰值是否出现在指定的容差窗口内55,56。假设t^\hat{t}t^为预测峰值时间,t为实际峰值时间,n为训练样本数:
t^={t^1,t^2,...,t^n}\hat{t} = \{\hat{t}_1, \hat{t}_2, \dots, \hat{t}_n\} t^={t^1,t^2,...,t^n}
t={t1,t2,...,tn}t = \{t_1, t_2, \dots, t_n\}t={t1,t2,...,tn}
通过使用ϵϵϵ表示峰值时间的容差残差,并使用hhh作为标志来表示预测时间是否落入容差区间ti−ϵt_i-ϵti−ϵ,ti+ϵt_i+ϵ]ti+ϵ],则我们具有如下定义的HR55。
HR=100%n∑i=1nhiHR = \frac{100\%}{n} \sum_{i=1}^{n} h_{i}HR=n100%i=1∑nhi
其中,
t^i∈ti−ϵ,ti+ϵ\hat{t}_i \in t_i - \\epsilon, t_i + \\epsilont^i∈ti−ϵ,ti+ϵ 时,hi=1h_i = 1hi=1
高峰时间预测通常用HR55,57来衡量,它将高峰需求发生之前和之后的一段时间指定为预测误差容限范围。只要预测的时间落在容差区间内,预测就被认为是正确的。在预测正确的时间段比预测准确的时间戳更有价值的操作环境中,HR特别有用。然而,它具有二元性质:恰好超出容差区间的预测与严重的错误预测同等受到惩罚,并且它忽略了计时误差的大小。
分类指标。在一些研究中,高峰需求预测是一个分类问题,而不是一个回归问题,例如,确定第二天是否会包含关键的高峰事件,或者预测的小时是否在高峰期间56,58-60。在这些情况下,使用准确度、精确度、召回率、F1分数或计算的曲线下面积(AUC)来报告评估,而不是使用连续错误度量。通常报告每日高峰出现的准确性58,但这些指标对类别不平衡很敏感,因为在典型数据集中,非高峰日远远多于高峰日。因此,Recall和AUC通常是优先的,以确保不会错过高峰事件,即使是以更高的错误警报为代价。
概率性和不确定性感知指标。与MAE或MAPE等基于点数的衡量标准只评估预测误差的平均幅度不同,概率指标评估整个预测分布的质量。它们同时具有区间或密度预测的可靠性和敏锐性,这在高峰需求预测中至关重要,因为运营商必须为极端负荷值的不确定性进行规划。预测区间的覆盖概率(PICP)衡量落入预测置信度区间内的观测值的比例61。较高的PICP表明,不确定度范围得到了很好的校准,尽管过宽的间隔可能很小程度上实现了高覆盖率,但提供的操作价值很小。连续排序概率得分(CRPS)评估预报的累积分布函数与实际观测之间的距离。它类似于MAE,但对于概率预测:较低的CRPS值表明预测分布分配的概率质量较高,接近实现的结果62,63。与PICP不同,CRPS同时奖励校准和清晰度,使其成为概率负荷和高峰需求预测中使用最广泛的评分规则之一。其他指标包括预测区间归一化平均宽度和预测区间覆盖概率偏差,它们共同评估区间清晰度和可靠性之间的权衡\[\]。这些指标共同提供了对模型表现的更清晰的一瞥,表明即使有像MAE这样的低点误差,如果间隔始终很窄,风险可能被低估。因此,对于高峰需求预测,概率评估对于防止预测不足的电力短缺和过度预测的额外成本至关重要。
高峰需求预测的有效评估策略取决于将指标选择与决策环境相一致,同时也反映了评估实践在文献中的演变。在回顾的研究中,MAPE是最常被报道的点数指标(通常与RMSE/MAE一起),而分类指标主要出现在峰值被框定为事件时。少数作品使用特定峰值指标(PAPE、HR)来强调极端情况下的表现。概率和不确定性感知分数(例如,PICP、CRPS)在较新的ML论文和长期设置中报告,其中校准的间隔对规划很重要。与其依赖任何单一指标,研究越来越多地报告一个小集合(例如,MAPE+RMSE+PICP/CRPS)以平衡平均准确度、尾部敏感度和不确定性。
高峰需求预测的产出
高峰需求预测通常旨在预测单个值(例如,高峰负荷)或一对值(例如,高峰负荷及其时间/日期)。尽管它们具有重要的意义,但现有的研究还没有建立一个统一的高峰需求预测产出的定义。通过查阅文献,可以确定用于高峰需求预测的以下关键产出类型:
- 高峰时间:预测高峰需求的时间。
- 峰值:预测需求峰值。
- 峰值和时间:预测需求峰值和峰值时间。
- 负荷分布:预测峰值(或与谷值一起)作为中间结果,作为产生负荷分布的输入。
根据利益攸关方的不同,这些产出类型中的每一种都具有明显的实际相关性。高峰时间预测对于需求响应计划的启动和负荷转移特别有价值。预测峰值有助于公用事业公司进行发电计划和基础设施压力测试。预测峰值和时间为系统运营商提供了更精细的控制,并促进了动态定价和运营规划65。与此同时,负荷分布预测对于长期基础设施投资、监管规划和电价设计特别有用,使它们与政策制定者更相关。消费者也间接受益,因为这些产出的准确预测有助于提高电网可靠性、更公平的定价机制,以及加强分布式能源资源的整合。
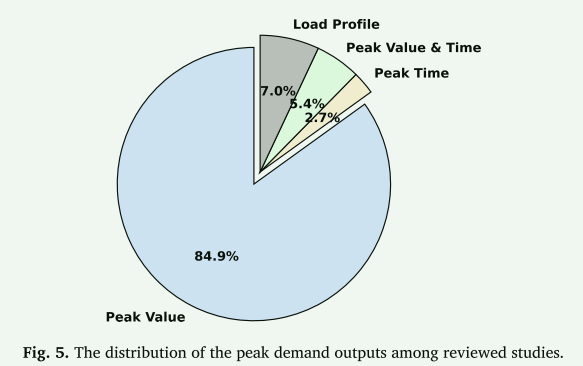
图5说明了这些预测产出在审查研究中的分布情况。可以看出,绝大多数研究侧重于峰值预测,而将预测峰值(有时是谷值)作为生成负荷剖面的中间结果的比例较小。与此同时,只有一小部分研究专门专注于预测高峰时间。此外,峰值和峰值时间的预测占回顾研究的5.4%,这些研究提供了更全面的预测,不仅涉及高峰需求的大小,而且还涉及其时间特征。虽然不太常见,但联合预测峰值、时间或负载分布的多输出模型可以利用输出之间的相关性,为利益相关者提供更丰富和更综合的见解,以进行运营和市场决策。
除了峰值和定时,捕获持续时间和变化性的输出还有重要的应用。预测高负荷期的持续时间可以告知系统灵活性和储备需求,而可变性措施与可再生能源一体化下的增长需求直接相关。这些产出还支持需求响应、存储调度和基于负荷持续时间曲线的长期规划21,29,66,突出了它们在可再生能源和分布式能源丰富的系统中的日益重要的意义。在这篇综述中,我们将重点放在峰值和时间上,因为这些仍然是文献中的主要输出,并且与系统操作最直接相关。虽然我们在这里没有对持续时间和变化意识到的产出进行系统的量化,但我们在可再生整合和DERS的背景下重新审视这些产出,在这些方面,坡度和持久性对业务和规划产生重大影响。
主要趋势和见解
在本节中,我们通过系统地将研究映射到先前定义的统一框架(如表6所示)来提供关于高峰需求预测模型的文献的全面总结。该框架作为一种结构化的方法来分类和比较不同的方法和结果,突出在高峰需求预测中考虑的关键趋势、模型和变量。应该指出的是,一些综述的研究采用混合模型,而不是依赖单一方法,表6中没有列出。这些研究将在本节后面讨论。
高峰需求预测洞察
在本节中,我们通过系统地将研究映射到先前定义的统一框架(如表6所示)来提供关于高峰需求预测模型的文献的全面总结。该框架作为一种结构化的方法来分类和比较不同的方法和结果,突出在高峰需求预测中考虑的关键趋势、模型和变量。
对高峰需求预测的回顾研究表明,预测框架的各个组成部分之间存在复杂的相互作用。采用了各种方法,从传统的统计方法到最大似然技术。值得注意的是,方法的选择似乎与具体的预测范围密切相关。对于STPDF,模型的设计是为了捕捉需求的即时波动,严重依赖于天气和日历数据等高频变量。常用的方法有回归法、随机时间序列法和人工神经网络模型。结合多个模型的集成学习方法也越来越多地被采用来增强鲁棒性。这一范围的重点涵盖所有类型的产出,主要侧重于预测峰值。此外,还考虑了高峰时间或峰值与时间的组合,以及作为中间环节的高峰需求预测,以辅助负荷分布的预测。在这个地平线上,数据通常是固定的和丰富的,允许模型利用细粒度的时间模式。轻量级和可解释的方法往往表现得很有竞争力,而主要的挑战是对快速需求可变性进行建模。
在中期预测框架内,投入和预测要求的复杂性增加。模型通常将经济变量与天气和日历数据结合在一起,以捕捉季节性模式和中期需求波动。随机时间序列模型和人工神经网络通常应用于MTPDF。时间序列分解技术也成为MTPDF的宝贵工具,有助于分离趋势和季节性成分。这些方法大多侧重于峰值预测,而将其范围扩展到峰值和时间预测的研究较少,一些研究集中在预测负荷曲线上。在这里,半平稳的情况很常见,要求模型既要处理短期波动,又要处理季节性影响。特征分解和混合方法变得更加重要,概率输出通常更倾向于反映中期不确定性。
长期可持续发展的特点是不确定性和波动性增加,投入变量范围更广,包括政策因素和长期经济趋势。常用的方法有回归模型、神经网络模型和灰色预测模型。这些长期方法通常主要侧重于预测峰值,很少有研究针对组合指标来预测峰值及其时间。LTPDF中的一个关键挑战是输入数据的非平稳性,这是随着时间的推移不断发展的政策、市场结构和技术采用的结果。为了缓解这种情况,模型必须处理结构变化和长期不确定性,通常依赖于先进的特征提取方法、适应性学习算法和可解释的建模框架。
表6还突出了预测研究涉及的地理范围的显著差异。在国家一级,科技发展基金和长期发展基金是最常见的重点,既要解决当前业务调整的需要,又要解决战略性的、政策驱动的规划问题。回归模型和随机时间序列等方法被频繁使用,神经网络和时间序列分解在处理复杂数据和长期趋势方面也发挥着越来越大的作用。在区域一级,STPDF占主导地位,而MTPDF和LTPDF几乎同样受到关注。人工神经网络被广泛使用,与回归和集成模型一起用于稳健和可靠的预测。市政层面的探索较少,研究主要集中在STPDF和LTPDF上。人工神经网络是这一领域中最常用的方法,其价值在于其处理局部数据的能力,而随机时间序列和贝叶斯网络偶尔被应用于捕捉时间模式和不确定性。地方范围比市政范围更频繁地被探索,重点是STPDF,以管理社区特定的需求波动。回归、神经网络和递归神经网络(RNN)模型经常被使用,因为它们能够处理细粒度的序列数据。在所有范围中,STPDF是最常见的,反映了它对运营规划的重要性。
产出的选择进一步影响预测方法的选择。鉴于峰值在业务规划中的重要作用,它仍然是最常见的预测产出。人们对更复杂的输出越来越感兴趣,包括预测峰值和时间,以及负荷分布,这需要灵活的技术,如灰色预测、模糊逻辑和集成学习方法。这些产出提供了对需求动态的更丰富的见解,但目前在综述的文献中较少提及。在报告中,PAPE和HR等特定峰值的指标证实了在捕获峰值时间方面的显著收益,而分类指标出现在最近的工作中,将峰值预测作为一个事件检测问题,将评估扩展到传统的误差指标之外。
这些因素之间的相互联系反映了高峰需求预测的复杂性,其中预测框架的各个方面必须一起考虑。预测视野定义了分析的范围,而分析的范围反过来又影响到输入变量的选择和地理尺度的分辨率。同样,产出的选择塑造了方法方法,确定模型是侧重于峰值等聚合指标,还是侧重于更复杂的指标,如预测峰值和时间。这突出表明,必须使预测技术适应不同地理区域、不同时间范围和不同利益相关者群体的具体目标的独特组合。在上述对比的基础上,我们进一步对高峰需求预测方法家族进行了详细的跨阶段性能评估,如表7所示,更清晰地展示了高峰需求预测实践的演变。
在ML前阶段,预测方法在很大程度上限于传统的回归和随机时间序列方法,总体误差率分别为3-10%67,69,76和4-8%的MAPE158,159。这些方法缺乏量身定做的特定峰值评估,不能适应分类或概率预测,限制了它们在处理不确定性或罕见峰值事件方面的适用性。
在向ML过渡的阶段,出现了一套更广泛的技术。回归和随机模型被保留,但有所改进,MAPE范围缩小(降至1-6%)39,41,61,70-72,78,79,88。值得注意的是,混合体系结构开始融合分解(例如,时间序列和灰色模型)、软计算(模糊逻辑、ANN)和进化技术(例如,遗传算法),提高了模型对高峰负荷行为的非线性的响应能力。ANN变得特别突出,MAPE低至1%160,161,PAPE低至2-3%39。模糊逻辑模型显示MAPE较低(1-3%)162,163,突出了将可解释性和基于规则的推理纳入高峰负荷预测的早期努力。虽然仍处于萌芽阶段,但概率预测是利用随机和基于EVT的方法出现的,报告了一些有意义的指标,如PICP和极端峰值的回报水平间隔。
在ML驱动阶段,模型的复杂性和多样性显著增加。ANN变体始终表现出高性能,总体MAPE低至0.5%131,峰值特定分类度量达到95%的召回率和0.97AUC58。集成学习和深层神经结构(RNN、CNN)能够改进时间和空间相关性的学习,实现高分类准确率(高达96%)148,155和高峰事件的HR(高达95%)150。概率预测变得更加稳健,特别是通过贝叶斯模型、高斯过程和集成,PICP值从85%到100%63,64,137,CRPS得分低到0.162,164,表明可靠的区间预测。此外,降维和分解策略(如小波、ICEEMDAN)越来越多地集成到ML管道中,以处理高维数据并保留与峰值相关的模式。
总体而言,演变揭示了一个明显的趋势:从早期阶段的以减少误差为中心的确定性模型,到ML阶段的更全面、更适应和更具不确定性意识的模型。向特定峰值、分类和概率指标的转变突显了人们越来越意识到,在不确定的情况下,峰值需求预测既需要准确性,也需要可解释性。
混合高峰需求预测洞察力
在对单个预测方法的分析结果的基础上,表8提供了在回顾的文献中使用的混合模型的摘要。特别是,指数平滑、卡尔曼滤波和专家系统等技术没有包括在先前的表6中的独立方法中,在混合模型中存在。混合模型在高峰需求预测的不同阶段集成了不同的方法。在该表中,我们特别强调了这些模型中的ML组件,以便更清楚地了解ML在推进高峰需求预测方面的作用和影响。

混合方法旨在通过利用它们的互补优势来解决独立技术的局限性,提高高峰需求预测模型的性能。可以看出,混合方法的提出符合高峰需求预测三个阶段的发展轨迹,表明了从传统统计方法向ML驱动模型的转变。
在前ML阶段,传统的统计方法是主要的研究重点。大多数研究探索了统计技术的组合,以提高预测精度并解决各种建模挑战。
后来,过渡阶段标志着ML方法与传统统计方法的逐步整合。在这个阶段,虽然大多数研究继续结合统计方法,但一些研究开始探索混合统计和最大似然技术的潜力。例如回归与模糊逻辑相结合,随机时间序列与人工神经网络相结合,展示了ML如何补充现有的统计模型。混合最大似然方法也开始获得吸引力,神经网络和模糊逻辑的结合成为一种流行的方法。这一阶段突出了研究方法的转变,其中统计方法仍然是核心,但ML方法因其增强高峰需求预测模型的潜力而日益得到认可。
在ML阶段,ML方法成为混合模型的关键组成部分。人工神经网络和遗传算法相结合的混合模型经常被使用208。此外,将统计方法与最大似然方法相结合的模型仍然很受欢迎,包括使用神经网络回归和时间序列分解与不同的最大似然方法的组合,如CNN、RNN、LSTM和GRU(GRU)。然而,仅结合统计技术的混合模型变得相对罕见。ML阶段标志着对ML驱动的混合模型的日益重视,反映了向高级ML技术的转变,以解决现代电力系统中的复杂研究问题。
混合方法在三个阶段的演变既表现出连续性,也表现出进步性。重要的是,各个阶段之间存在重叠:一些纯粹的统计杂交体在ML阶段继续得到很好的使用,而物理信息杂交体在特定的长期应用中出现得比预期更早。这种重叠表明,将分类分为三个阶段是一种简化,但它仍然有助于捕捉方法论发展的大致轨迹。此外,在文献中,可以观察到混合模型集成的三种主要策略。在ML捕获非线性残差之前,顺序混合模型对需求数据进行趋势分析或分解。并行混合模型独立地使用统计模型和ML模型生成预测,并通过平均或集成将它们组合在一起。对于物理启发模型混合将领域知识和物理约束直接嵌入到ML训练中。表9提供了所审查的、映射到统一高峰需求预测框架的混合模型的摘要,包括它们在水平上的分布、最常用的两个输入组合、输出以及它们报告的误差减少范围。
在此总结的基础上,关于每种方法的好处出现了明确的模式。顺序混合在STPDF中占据主导地位,其中预处理提高了稳健性,在保留一些可解释性的同时产生了高达45%的错误减少。并行混合,更均匀地分布在STPDF和MTPDF应用程序中,通过结合互补的错误模式,提供10%-30%的改进,在馈送器上提供更大的稳定性。物理启发的混合虽然较少,但集中在MTPDF和LTPDF中,除了天气和日历驱动因素外,还嵌入了经济或DSM因素。它们带来了最大的收益,并更好地概括了未知的情景。除了这些好处,在回顾的研究中还注意到了几个挑战。顺序杂交法虽然可以解释,但增加了预处理的复杂性,并严重依赖于分解质量。平行混合会降低透明度,并需要仔细校准权重以避免偏差。了解物理学的混合动力车需要更丰富的数据和更复杂的模型设计。
这些差异说明了复杂性、可解释性和准确性之间的权衡。 顺序混合系统平衡了简单性和鲁棒性,并行混合系统以牺牲清晰度为代价而注重准确性和稳定性,物理信息混合系统提高了规划任务的可靠性,但需要更大的建模工作,增加了设计复杂性和可解释性挑战,凸显了该领域面临的权衡。 因此,混合策略的选择与预测需求相一致:针对短期运营的连续策略、针对区域或支线稳定性的并行策略以及针对长期容量和政策规划的物理信息策略。 这一进展还表明,虽然机器学习组件日益主导混合模型,但传统统计方法仍然是互补的。 它们提供可解释的基线,在机器学习处理之前减少噪音,并且在许多情况下仍然作为基准或支持模块,突出了它们在峰值需求预测中的持久重要性。
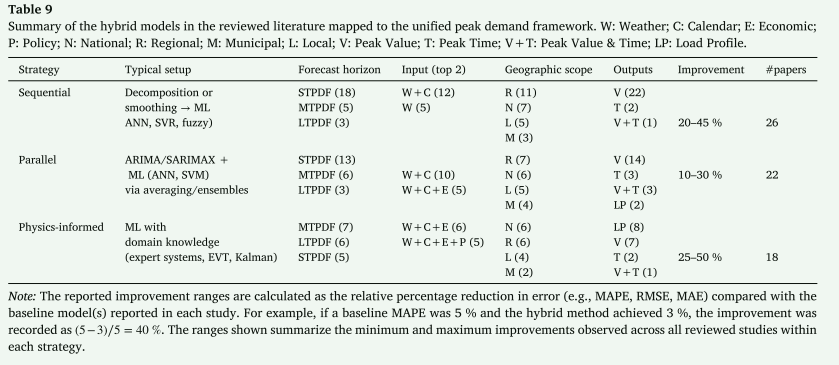
基本背景:机器学习前阶段
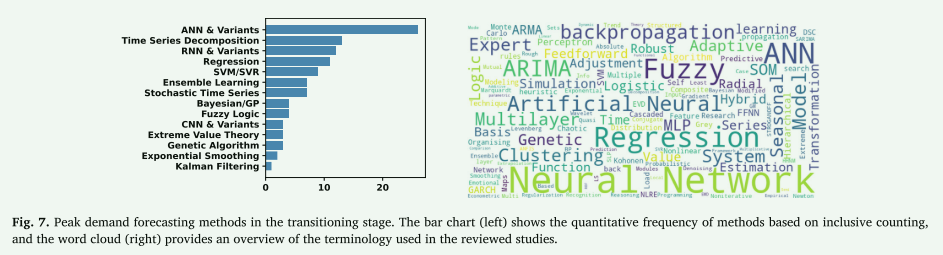
在预机器学习阶段,采用了各种统计方法来进行峰值需求预测。 图 6 显示了词云和包含计数条形图。 词云传达了文献中报告的方法的多样性,而条形图使用包容性计数报告了它们的频率,其中混合研究在每种构成方法下进行计数。 回归分析和随机时间序列模型是应用最广泛的技术。 分解方法和指数平滑也被广泛用于识别需求趋势和季节性模式。 机器学习前阶段的峰值需求预测模型提供了计算需求较低的可解释解决方案,符合早期电力系统的技术限制。 本节将首先研究这些限制,然后讨论旨在应对这些挑战的预测方法的开发。
早期电力系统面临的挑战
峰值需求预测是一项重要而复杂的任务,用于维持早期电力系统的可靠性、优化运营和支持长期规划。 在此期间,挑战与电力系统的运营和规划需求密切相关。 根据回顾的研究,早期系统的主要挑战可总结如下。
峰值需求预测的一个主要挑战是捕捉峰值需求模式的可变性和不规则性,这主要是由天气、经济活动和社会行为等外生变量驱动的。 极端天气条件,例如热浪或寒潮,通常会导致制冷或供暖用电量突然激增。 例如,El-Razaz 和 Al-Mohawes 81 预测了沙特阿拉伯的每周峰值需求,并强调夏季气温飙升可能导致用电量突然增加,从而使峰值需求预测变得复杂。 此外,工业活动和社会经济增长引入了不规则趋势,需要仔细建模,特别是对于快速增长的经济体158,165。 在早期的电力系统中,许多峰值需求预测模型难以捕捉这些突然的变化,通常需要额外的天气变量或二元事件指示器来检测异常。
高峰需求预测还面临着整合高峰需求的季节性和周期性性质的挑战,与总体需求相比,这对高峰的影响不成比例。 例如,在假期或特殊活动期间,总体能源需求可能会适度上升,但峰值需求可能会出现更显着的增长,导致能源使用量急剧上升,在预测中必须考虑到这一点。 高峰需求表现出可预测的每日、每周和季节性周期,受工作安排、假期和气候变化的影响。 然而,由公共假期、文化庆典或意外工业活动等不规则事件引起的偏差会带来额外的复杂性。 Papalexopoulos 69 证明了结合日历效应来解决这些异常的重要性,强调需要能够处理常规周期和意外中断的峰值需求预测模型。
需求高峰的时间是另一个关键焦点。 准确的计时对于电网稳定性至关重要,因为不一致的预测可能会导致高峰期资源过载或利用不足。 电网运营商需要准确预测高峰时间,以防止过载并优化可用基础设施的利用率。 Hsu 和 Ho 168 强调了将预测高峰时间与现实世界条件同步的困难,特别是在工业或城市活动快速变化的地区,这些地区的高峰需求变化很大。
另一个挑战是专门为峰值需求预测定制的数据的可用性有限。 在早期的电力系统中,随着快速发展地区的能源需求持续增长,预测峰值需求变得越来越具有挑战性。 Barakat 和 Eissa 158 强调了在快速增长地区捕获峰值需求数据的复杂性。 此外,早期电力系统通常无法获得高分辨率数据,例如详细的每小时消耗模式。 虽然一般需求预测模型可以依赖于每日或每周的负载曲线,但峰值需求预测需要关注特定时间间隔内的最高负载值。 缺乏此类详细数据通常会限制峰值需求预测模型的准确性和有效性。
最后,操作和计算的限制也限制了用于峰值需求预测的模型的复杂性。 早期的电力系统需要能够提供可操作预测来支持运营决策的模型。 虽然这一时期的许多峰值需求预测模型提供了可解释性和计算效率,但这些模型通常需要手动调整来处理数据集中的非线性和不规则事件69,81,86,158。
机器学习之前的峰值需求预测方法
早期电力系统固有的挑战催生了使用统计方法进行峰值需求预测。 在机器学习之前的阶段,回归模型是峰值需求预测的基础,因为它们在捕获峰值需求和解释变量之间的关系方面简单且灵活。 许多研究应用回归模型来预测高峰需求,结合了经济指标、天气条件和特殊事件等各种因素。 例如,Towill 76 利用 GDP 和温度数据的回归来预测英国 CEGB 西北地区的峰值需求。 Stetson 和 Stark 68 应用回归来预测美国堪萨斯州农村居民客户的峰值需求,考虑了巧合和非巧合的峰值需求。 此外,Papalexopoulos 69 采用结合假期和温度影响的回归模型来执行 STPDF。 尽管有其优点,回归模型通常假设变量之间的静态关系,限制了它们对非线性交互和突然需求峰值的适应性170。
随机时间序列模型被广泛用于捕捉高峰需求的趋势和季节性模式。 这些模型(例如 ARIMA、自回归模型和移动平均模型)对于建模和预测具有固有随机性的时间相关数据非常有效。 根据审查的研究,这些随机模型通常与其他技术相结合以提高预测准确性。 例如,El-Razaz 和 Al-Mohawes 81 利用分解和自回归模型来预测快速发展城市的每周峰值需求。 类似地,Elrazaz 和 Mazi 165 在混合模型中采用了分解技术,将 ARIMA 与指数平滑相结合来预测每周峰值需求。 随机时间序列模型可以有效地管理季节性和周期性变化,但受到平稳性假设的限制,并且需要广泛的参数调整,限制了它们在快速发展的电力系统中的应用。
时间序列分解方法通过分离各种成分,如趋势、季节、周期和不规则变化,进一步增强了高峰需求预测。例如,古普塔86的早期工作应用了傅里叶变换,这是一种特定类型的时间序列分解,用于稳定每月高峰需求预测的非平稳序列。此外,Barakat和Eissa158将分解与回归相结合,以解决快速增长地区的周期性和不规则成分。虽然分解方法通过分离不同的需求组成部分来提高预测的准确性,但它们往往依赖于聚合数据,将粒度和响应限制为短期不规则或实时变化。
指数平滑是早期电力系统中用于峰值需求预测的另一种常用方法,为较旧的数据分配指数递减的权重,同时强调较新的观测结果。 单指数平滑、双指数平滑和三指数平滑(Holt-Winters 方法)等变体可处理趋势日益复杂的数据。 例如,巴拉卡特等人。 166在快速开发的实用程序中应用了 STPDF 的指数平滑。 在回顾的研究中,指数平滑经常与随机时间序列模型结合使用在混合模型中以提高性能。 然而,由于指数平滑依赖于手动选择的平滑系数,因此它可能难以有效地适应高度波动的时间序列。
在机器学习之前的峰值需求预测中,还探索了结合多种统计技术的混合方法。 例如将ARIMA模型与分解和指数平滑相结合165,以及复合回归分解模型158。
上述方法构成了峰值需求预测的基础,解决了早期电力系统中的可变性、季节性和数据限制等挑战。 表 10 总结了分配给各自方法的研究,强调了它们所解决的挑战及其固有的局限性。 我们的审查确定了一系列激发后续发展的悬而未决的问题。 其中之一涉及回归框架如何在不依赖静态规范的情况下适应不断变化的非线性关系。 另一个问题涉及随机时间序列模型如何在结构断裂和快速状态转变的情况下保持稳健,同时减轻手动参数调整的负担。 进一步的挑战是特征选择是否可以通过嵌入天气、关税、需求方管理和政策等领域知识的方式实现自动化,从而减少过度拟合并提高可转移性。 另一个问题涉及哪种分解策略最适合捕获高分辨率、短暂的不规则性,而不是依赖于汇总的季节性模式。 指数平滑族还提出了如何使其适应波动性和峰值事件而无需重复手动重新校准的问题。 最后一个问题是如何设计可解释的统计混合,以平衡复杂性、概括性和透明度。 这些问题为以下各节中讨论的机器学习时代方法的过渡奠定了基础。
过渡到机器学习驱动的峰值需求预测
1991 年至 2010 年期间代表了峰值需求预测方法的重大转变,其特点是从传统统计方法向机器学习驱动技术的演变。 这个时代反映出电力系统日益复杂,并且需要更具适应性、可扩展的预测模型来满足不断增长的需求。 图7说明了过渡阶段采用的方法。 可以看出,这一时期的关键进步包括引入人工神经网络、模糊逻辑以及集成统计和机器学习方法的混合模型209。 虽然回归和 ARIMA 等统计方法仍然被广泛使用,但它们通常与这些更新的技术相结合以增强模型性能。 此外,数据驱动的方法变得越来越流行,结合了聚类、优化算法和概率预测方法等工具。 这些创新标志着向计算智能的转变,解决了现代电力系统日益严峻的挑战,并为未来的进步奠定了基础。
本节分为两个小节:关键进展和突破。 关键进展小节重点介绍了方法的发展,这些发展随着时间的推移提高了峰值需求预测模型的性能。 突破小节探讨了重塑该领域的变革性创新,引入新颖的方法和观点来解决峰值需求预测的复杂性。
关键进展
统计方法的演变
在此过渡阶段,预机器学习阶段的各种统计模型得到增强,以提高预测性能。 回归模型仍然是峰值需求预测的基础,而随机时间序列建模技术取得了重大进步。 巴拉卡特等人。 99使用季节性自回归综合移动平均线(SARIMA)对季节性负荷变化进行建模,有效捕获季节性模式。 然而,SARIMA 假定平稳性和线性动态较弱,在关税变化、非线性天气-负荷相互作用或突然的政权变化等结构性破坏下,其性能可能会恶化。 为了减轻这一时期的这些限制,探索了四种扩展:(i)通过卡尔曼滤波估计的时变参数的非平稳状态空间公式172; (ii) ARIMA 变体捕获波动性聚类 24; (iii)先分解管道(例如,经验模式分解),以在残差建模之前隔离非平稳分量94; (iv) SARIMAX 和动态回归结构,将外源驱动因素直接纳入线性框架39,161,167。
此外,还出现了一些补充方法,例如卡尔曼滤波和灰色预测,以解决不确定性和数据稀缺问题。 卡尔曼滤波通过预测校正过程迭代地细化预测,正如 Dash 等人的每日和每周预测的混合学习方案所示。 172。 其主要优点是在线纠错以及对丢失或噪声测量的鲁棒性。 主要限制包括对错误指定的过程和测量噪声的敏感性、对通常线性和高斯假设的依赖,以及捕捉长期趋势变化的能力有限,除非状态模型明确地随时间变化。 同时,灰色预测利用有限的历史数据来识别模式并优化峰值需求预测的模型。 例如,冉超云182利用灰色关联理论来分析气象变量与日峰值负荷之间的关系,这在历史数据不足的场景中特别有用。 杨正元等人。 57,183均利用混合灰色模型与ARIMA相结合,提高了月度和年度预测的准确性,其中灰色预测可以有效地使用最少的数据识别趋势,这补充了ARIMA管理非平稳数据的能力。 灰色预测在数据稀缺和平稳发展的环境中表现良好,但它对背景值选择敏感,并且在不稳定或政权转移的系统中往往会退化。 与 ARIMA 结合使用时,它可以恢复短期动态,同时仍保留小样本性能的优势。
人工神经网络的整合
以人脑结构和功能为模型的人工神经网络的出现,标志着峰值需求预测发展的一个重要里程碑。 这些模型于 20 世纪 90 年代初首次推出,将处理预测场景中复杂的非线性关系的适应性和能力提升到了新的水平。 人工神经网络由多层互连的人工神经元组成,以促进信息处理和通信。 典型的 ANN 架构包括输入层、一个或多个隐藏层以及输出层。 除输入层中的神经元外,每个神经元都通过加权连接接收来自前一层的输入。 然后,聚合输入由激活函数处理以产生输出。 20 世纪 90 年代初的研究证明了 ANN 在 STPDF 中的潜力。 例如,Saeed Madani 98 利用西雅图的每小时温度和负载数据开发了一个 ANN 模型来预测每日和每小时的峰值需求,与传统回归模型相比,精度显着提高。 Hsu 和 Chen 50 利用 ANN 模型来预测台湾的年度峰值需求,这证明了 ANN 模型对区域能源需求非线性依赖性的适应性。
多年来,人工神经网络随着各种架构的引入而不断发展,例如多层感知器 (MLP)、径向基函数网络 (RBFN) 和自组织映射 (SOM)。 例如,MLP 已被应用于使用经济、人口和天气变量来预测区域峰值需求,展示了它们在建模各种与峰值需求相关的外生变量方面的适应性50。 此外,RBFN 还被用来提高计算效率。 Nagasaka 和 Al Mamun 126 利用 RBFN 来预测商业建筑的每日峰值需求,证明 RBFN 在保持较高预测精度的同时需要更少的训练时间。 此外,事实证明,SOM 在集群负载配置文件和隔离类似的消耗模式方面非常有效。 例如,Hsu 和 Yang 95 使用 SOM 将负荷模式分类为日类型,证明了它们在识别 STPDF 具有相似小时负荷概况的组方面的实用性。 人工神经网络及其变体的灵活性和适应性使它们非常适合处理峰值需求模式的变化。 这些优点使 ANN 成为一种基本的机器学习方法,用于提高不断发展的电力系统中峰值需求预测的准确性和可靠性。 尽管有这些优点,基于人工神经网络的预测模型仍面临一些局限性。 过度拟合是一种经常出现的风险,特别是在稀疏的峰值事件数据下,模型可以记住噪声而不是捕获可概括的模式50。 局部极小值也会阻碍收敛,特别是在早期的训练算法中,尽管后来的优化方法(例如预测反向传播100和拟牛顿方案26)有助于缓解这一挑战。 超参数选择在基于 ANN 的预测模型中进一步发挥着关键作用:隐藏层的数量、神经元数量和学习率直接影响准确性和泛化性,而 sigmoid 或 ReLU 等激活函数则决定了对非线性负载-天气相互作用进行建模的能力。 正则化方法,包括贝叶斯正则化 110 和 dropout,已被证明对于增强泛化和减少过度拟合至关重要。 另一个重要问题是稳健性。 在数据分布变化、异常值或缺失值的情况下,人工神经网络的性能可能会恶化,这在峰值需求数据集中很常见。 一些研究通过应用滚动原点验证50、结合抗噪声激活函数、在训练前检测和过滤异常值126或使用模糊预处理来处理不完整的输入173来解决这个问题。 总体而言,人工神经网络在对峰值需求的变化进行建模方面具有明显的潜力,但其在实践中的性能受到架构设计方式以及在噪声或不完整数据下处理鲁棒性的强烈影响。
模糊逻辑系统简介
在过渡阶段,将模糊逻辑系统纳入峰值需求预测标志着一个重大进步。 传统的确定性模型假设温度等外生变量对电力需求具有固定的、可预测的影响。 然而,在现实场景中,负载数据通常包含不确定性和随机性,受到意外天气变化、人类行为或工业活动等因素的影响。 确定性模型很难捕捉这些变化,因为它们缺乏纳入随机性或适应意外事件的机制。 相比之下,模糊逻辑系统通过利用语言变量和基于规则的推理提供了一种更具适应性的方法210。
模糊逻辑在峰值需求预测中的早期应用经常涉及将其与神经网络相结合来开发混合模型。 例如,173开发的模糊神经网络展示了一种用于短期预测峰值和平均负载的两阶段方法。 在第一阶段,模糊规则被应用于预处理输入,如温度、降雨量、风速和季节变化,将这些输入转换为模糊语言变量。 然后将这些经过处理的输入数据输入到人工神经网络中,人工神经网络捕获模糊输入和预测负载之间的非线性关系。 事实证明,这种混合模型能够处理多种条件,包括周末、节假日和极端天气情况,实现了令人印象深刻的预测精度,平均每日误差低于 0.7%。 后来,Kiartzis 等人。 162引入了模糊逻辑专家系统,进一步凸显了模糊逻辑的适应性。 该系统利用一组从历史数据和专家知识中得出的规则来在不确定的条件下做出预测。 通过结合特定领域的启发式方法,模糊逻辑专家系统在峰值需求预测任务中显着优于传统的统计模型。
总体而言,模糊逻辑系统及其与人工神经网络相结合的混合模型增强了峰值需求预测的适应性和准确性,特别是在需求受到天气和运营变化等可变因素影响的环境中。 这些模型提供了一个强大的工具,通过有效处理模糊性并整合定量和定性数据来管理动态能源需求,从而在电力系统中做出更明智的决策。 然而,模糊逻辑系统的一个关键挑战在于隶属函数和规则集的选择,这可能是主观的并且对系统设计者的专业知识敏感。 在峰值需求预测中,三角或高斯隶属函数已被普遍使用,但研究表明,性能随函数形式的不同而变化,需要根据历史数据进行经验校准162,173。 基于规则的推理还取决于可靠启发法的可用性; 不完整或指定不明确的规则可能会导致预测不一致。 处理嘈杂或丢失的输入是另一个限制,因为天气或经济变量并不总是以所需的分辨率记录。 模糊系统通过容忍输入值的不精确来部分解决这个问题,而混合模糊人工神经网络或模糊专家设计在面对不完整信息时表现出了鲁棒性30,177。 然而,不准确或过于广泛的隶属函数可能会降低预测的准确性,这一风险持续存在,这凸显了系统验证的重要性。
混合建模方法
在过渡阶段,混合建模方法的出现是为了应对电力系统不断变化的复杂性。 一方面,对混合统计技术的关注仍然很流行,例如随机时间序列、回归和分解方法。 表 11 提供了过渡阶段混合模型与其基线的定量比较。 它表明峰值需求预测的统计混合通常会带来增量改进。 这些组合旨在通过利用统计方法的互补优势来处理需求数据的季节性、趋势和不规则性,从而提高预测的准确性和稳健性。 例如,Haida 和 Muto 49 利用基于回归的预测和变换来捕获非线性关系和季节性波动,特别是在过渡时期。 此外,指数平滑通常被用来与随机时间序列176或分解方法24相结合,稳定短期波动并改进对波动需求模式的预测。 这些统计组合构成了混合方法的基础,解决了独立统计模型的许多局限性,但仍限制了其管理非线性和不确定性的能力。
另一方面,过渡阶段的一个显着趋势是传统统计方法与新兴机器学习方法的结合。 这些组合旨在克服统计方法的静态假设,并增强预测模型对非线性和不确定的峰值需求模式的适应性。 如表 11 所示,这些混合动力被证明更加有效。 通过将人工神经网络、专家系统、模糊逻辑和灰色预测纳入时间序列模型,研究一致报告了比统计或机器学习基线更强的结果。 回归模型通常与模糊逻辑30,177、专家系统179和时间序列分解169,170等机器学习技术集成,从而改进对不确定性和非线性模式的处理,同时保持峰值需求预测模型的可解释性。 随机时间序列模型与 ANN 47、模糊逻辑 161、灰色预测 183 和专家系统 39 等 ML 方法配对,有效管理时间相关的变化并受益于 ML 的模式识别功能。 时间序列分解成为一种常见的桥梁,在应用支持向量机 182 和 ANN 25 等 ML 方法来增强模型性能之前,将需求数据分解为趋势和季节性等组件。 例如,戈米等人。 109采用傅立叶变换来提取季节性成分,然后将其输入到 STPDF 的神经网络中,有效捕获峰值需求数据中复杂的季节性变化。 事实证明,分解在这一时期特别有用,因为它允许模型更好地捕捉季节性并滤除噪音,从而提高了性能。 这凸显了峰值需求预测框架中预处理的重要性,并证明了两种方法的互补作用,其中统计方法提供了结构和清晰度,而机器学习则引入了灵活性并增强了模式识别。
此外,开发结合多种机器学习技术以进一步提高性能的高级混合模型的趋势不断增长。 例如,加夫里拉斯等人。 181将 ANN 与遗传算法相结合以优化模型参数,而 Amin-Naseri 和 Soroush 27将 ANN 与 SOM 相结合以改进峰值需求数据中的聚类和模式识别。 此外,将模糊逻辑与遗传算法相结合的混合模型163或将SOM和模糊逻辑相结合的专家系统28证明了结合不同的机器学习方法来解决不断发展的电力系统的复杂性的潜力。 表 11 中的定量比较还表明,混合机器学习的好处各不相同。 基于优化的混合仅产生了微小的改进,而使用聚类或模糊推理的混合则提供了最实质性的准确性改进。 这表明混合动力在引入表示或构建负载模式的新方法时增加了最大价值,而不仅仅是调整模型参数。
突破
特征工程和选择
随着电力系统的发展,峰值需求预测需要精心设计的方法来选择和构建模型输入,从而有效应对日益变化和极端的能源需求模式的挑战。 与通常优先考虑稳定条件下的平均趋势的一般预测方法不同,峰值需求预测模型侧重于识别和突出导致用电量突然大幅波动的关键变量。 对目标变量的强调凸显了特征工程的重要性,特征工程可以细化输入数据以提高模型的准确性。 此外,在转型期间,与天气相关的因素对于预测仍然很重要,但不断变化的能源格局也需要纳入更广泛的社会经济变量。
主成分分析 (PCA) 等技术通过识别和强调影响峰值负载的最关键变量,显着增强了特征工程过程,同时有效降低噪声并最大限度地减少不太相关因素的影响。 例如,Saini 和 Soni 26 使用 PCA 来预处理天气和负载相关变量,有效地最小化数据集中的冗余。 该方法从初始的 28 个变量集中提取了 11 个主要因素,实现了数据维数降低 96%。 精炼后的数据集不仅促进了更有效的神经网络训练,而且还通过突出显示与每日峰值负载最密切相关的天气变量来提高可解释性。 后来,Amin-Naseri 和 Soroush 27 在前馈神经网络框架中利用 PCA 进行降维,使模型能够专注于最相关的变量。 虽然 PCA 对于线性降维很有效,但它可能无法完全捕获高维负载数据中的非线性关系。 替代技术,例如 t 分布随机邻域嵌入、自动编码器和 Isomap,已在相关领域进行了探索,因为它们能够保留复杂的局部结构或揭示潜在表示。 未来的比较研究可以进一步评估这些方法在峰值需求应用中的可解释性、稳健性和预测性能方面的权衡。
随着电力系统向适应经济活动增加和城市发展的方向转变,在此阶段捕获更广泛的变量变得至关重要。 例如,Belzer 和 Kellogg 46 证明了整合 GDP 增长等经济指标的重要性,这些指标通过工业和商业能源使用的变化间接影响峰值负荷。 同样,Saini 和 Soni 26 纳入了经济因素,以反映影响电力消费模式的更广泛的社会经济背景。 此外,随着能源市场竞争变得更加激烈,关税结构更加复杂,了解定价机制和消费者行为之间的相互作用对于准确的峰值需求预测变得至关重要。 李等人。 163强调了电价结构在塑造高峰需求中的作用,整合电价相关变量以更好地模拟经济政策对能源消费模式的影响。 随着预测模型包含越来越多与社会经济、行为和气象变量相关的特征,解决高维输入空间带来的挑战变得尤为重要。 PCA 等特征工程技术与有针对性的选择策略相结合,可以通过减少噪声和共线性来缓解这个问题。 此外,稀疏表示技术(例如基于 Lasso 的选择)可以通过强制简约来支持模型泛化,尤其是在高维设置中。 流形学习方法,包括局部线性嵌入,也提供了揭示复杂负载数据中内在低维结构的潜力,尽管它们与运行预测的集成仍然有限。
优化算法的进步
先进的优化技术与传统和机器学习驱动的峰值需求预测方法的集成使得过渡阶段的模型更加准确和稳健。
一项显着的进步是遗传算法 (GA) 等进化算法的应用。 例如,加藤等人。 136引入了一种基于遗传算法的模型,该模型利用树结构和最小描述长度原理来有效地模拟每日峰值负荷。 这种方法巧妙地捕捉了天气条件和每日负荷模式的波动,从而显着提高了预测的准确性。 加夫里拉斯等人。 181进一步将人工神经网络与遗传编程相结合,用于配电系统中的峰值需求预测。 这种混合方法使用符号回归和相关过滤来生成分析表达式,匹配神经网络的预测准确性,同时提高可解释性和结构灵活性。 遗传算法成为峰值需求预测的优化器选择,因为它可以有效地处理混合变量优化问题,例如调整 ANN 权重或模糊隶属函数。 其全局搜索能力使其不易出现局部极小值,这在复杂的混合模型中很有价值。 模糊-遗传算法混合体提供了这一趋势的明显例子。 李等人。 163展示了遗传算法如何自动调整模糊隶属函数和规则权重,减少模糊设计的主观性并使系统适应不断变化的峰值需求条件。 这种集成提高了不确定场景中的准确性,但增加了计算成本并降低了透明度,因为模糊规则库和优化层都模糊了可解释性。 因此,模糊-遗传算法混合强调了预测能力和可解释性之间的权衡,这是业务预测应用中反复出现的主题。
尽管遗传算法在审查的研究中占主导地位,但这反映了它的早期采用及其对混合变量优化的适用性,而不是固有的优越性。 其他元启发法,例如粒子群优化和蚁群优化,已在相关能源预测任务中得到报道211-213,它们提供更快的收敛速度或需要更少的参数来调整。 后续研究可以从检查这些选项中受益,以提高峰值需求预测的计算效率或稳健性。
优化技术在训练复杂的神经网络架构中也很重要。 盛冈等人。 100引入了用于第二天峰值负载预测的预测反向传播,通过增量学习有效地处理动态时间序列数据。 Saini 和 Soni 26 采用 Levenberg-Marquardt 和拟牛顿方法来加速收敛并提高准确性,而 Saini 110 利用贝叶斯正则化来减轻过度拟合并增强泛化能力。 此外,分层和级联神经网络等结构进步补充了这些优化趋势。 卡平泰罗等人。 180提出了一种结合自组织映射和单层感知器的混合分层模型,以改进 LTPDF。 Broadwater 和 Sargent 70 设计了级联神经网络,利用多层输出,减少短期预测中的错误。
鲁棒回归技术和最小二乘法也被用来增强预测模型针对负载数据异常值的弹性。 海达等人。 170引入了LTPDF的非迭代最小绝对值估计,即使在存在异常数据点的情况下,也能有效地拒绝异常值并确保更稳定和准确的年度峰值负荷预测。 此外,金等人。 30将鲁棒回归与模糊聚类相结合,以管理异常值并对每日峰值负荷数据中的节气进行分类,增强模型处理极端天气条件和不规则负荷模式的能力。 在我们回顾的研究中,稳健回归最常以最小绝对值或分位数模型的形式出现。 对于峰值负载应用来说,这是一个务实的选择,因为它可以适应热浪或需求侧管理事件期间出现的不对称和重尾错误,并且可以通过具有稳定运行时间的线性编程例程来实现。 Huber 型 M 估计器 214 也可以在峰值需求预测中考虑,特别是对于异常情况轻微但频繁的滚动给料机操作,尽管它们在峰值需求文献中较少报道,因为它们的权重降低机制对于极端尾部不太有效。 因此,稳健回归的选择既取决于误差概况(是否由尾部风险或轻度污染主导),也取决于所需的更新节奏,区分定期计划和频繁在线更新。
支持向量机 (SVM) 和基于内核的优化方法也因其在峰值需求预测中处理非线性关系和高维数据的能力而得到探索。 王等人。 141将最小二乘SVM应用于STPDF,利用SVM对复杂的依赖关系进行建模,即使在具有极端负载消耗模式的特殊时期也能实现精确的预测。 埃尔-阿塔尔等人。 142将支持向量回归(SVR)与局部预测框架和基于相关维度的时间序列重建相结合,使用小波变换有效地对负载数据进行去噪,并捕获复杂的时间依赖性,以实现高度准确的峰值需求预测。
概率预测方法
概率预测方法由于能够量化不确定性并提供一系列可能的峰值需求预测,因此在峰值需求预测中获得了巨大的关注。 这些方法对于日益复杂和可变的电力系统中的风险管理、容量规划和决策特别有价值。
极值理论在极端负载事件的统计行为建模中发挥了关键作用,这对于 LTPDF 至关重要。 Belzer 和 Kellogg 46 将蒙特卡罗模拟与极值分布相结合来预测长期峰值需求。 还开发了概率模型来提供全面的预测,涵盖峰值需求的各种不确定性来源。 霍等人。 24将ARIMA与广义自回归条件异方差模型结合起来进行LTPDF。 这种混合方法可以对负载波动进行基于风险的分位数估计,提供捕获峰值负载值的变化和潜在极端值的概率预测。 此外,麦克沙里等人。 61利用随机时间序列模型与概率预测技术相结合来模拟天气变量并预测峰值负载大小和时间,生成一系列可能的峰值需求结果,有助于评估系统可靠性和制定应急计划。
虽然贝叶斯网络通过对各种影响因素之间的依赖关系进行建模,为概率预测提供了一个强大的框架,但它们在峰值需求预测中的应用在过渡阶段受到限制。 贝叶斯网络的基本原理在这一时期末得到了探索,为随后几年更广泛的采用奠定了基础。 Saini 110 在 ANN 中引入贝叶斯正则化,以纳入峰值需求预测中的不确定性。 通过利用贝叶斯原理,该模型能够更好地处理参数不确定性并提供更可靠的概率预测,为未来研究中更高效的概率建模技术奠定了基础。 此外,密度预测技术通过提供对峰值需求的全面概率洞察,进一步推进了概率预测。 Hyndman 和 Fan 79 利用半参数加性模型结合模拟技术来预测长期峰值需求的密度分布,结合温度模拟和残差自举来提供对峰值需求波动的详细了解。
除了贝叶斯网络之外,贝叶斯神经网络和高斯过程等其他先进的概率方法在这一时期也因其表示参数不确定性和非线性关系的能力而开始受到关注。 贝叶斯神经网络结合了权重的先验分布,并产生预测分布而不是点估计,这在数据稀疏或嘈杂时特别有价值,这是高峰需求场景中的常见情况110。 另一方面,高斯过程提供封闭式后验分布和不确定性带,使其具有高度可解释性并适合长期规划。 然而,这些方法也带来了实际挑战,包括高计算成本和难以扩展到高维输入,这限制了它们在过渡阶段的广泛使用。
当代趋势:机器学习驱动的峰值需求预测
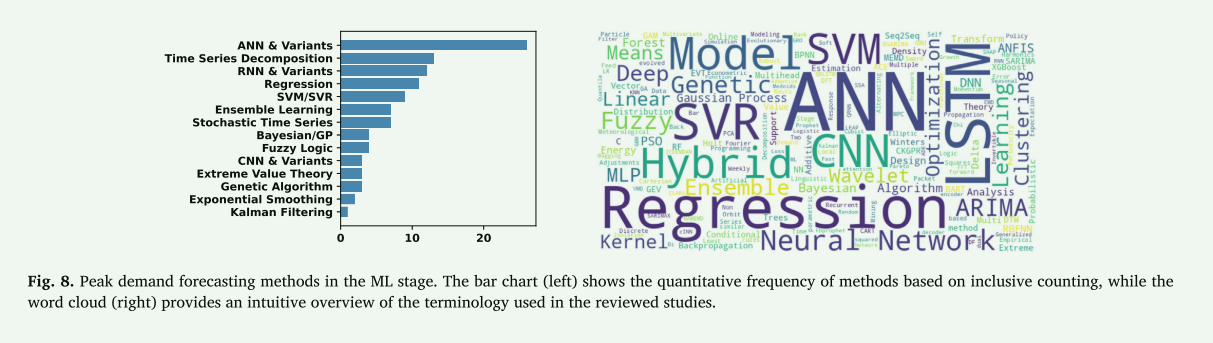
机器学习技术的出现彻底改变了峰值需求预测,标志着一个新时代的特点是能够对能源消耗数据中的复杂模式和交互进行建模。 这种转变的关键推动因素是智能电表生成的大型高分辨率数据集的可用性,这些数据集提供了精确建模和实时决策所必需的精细洞察215。 在机器学习阶段,峰值需求预测模型利用这些数据集、增强的计算能力和强大的算法来实现更好的预测性能。 如图8所示,还值得注意的是,一些统计方法,例如回归和随机时间序列模型,在这个时代仍然很流行。 当样本较短或强烈的季节和日历结构占主导地位时,它们特别有用。 这些模型产生明确的系数,通常作为混合系统的结构核心。 例如,分解或状态空间块解决趋势和季节性问题,而非线性学习器则对残差进行建模21,202。 非线性组件通常通过机器学习建模。 从理论角度来看,机器学习算法通过捕获经典模型无法轻易表示的非线性关系和变量交互来提高预测准确性。 神经网络通过激活函数的分层组合来近似任意非线性函数,并通过 dropout 和权重正则化等机制来防止过度拟合并提高泛化能力 216,217。 基于内核的方法(如 SVM/SVR)将输入数据投影到高维特征空间中,使非线性交互线性可分离 218。 集成方法通过结合不同的学习者来减少方差和偏差,从而稳定不同需求条件下的预测219,220。 这些方法有效地捕获了日益多样化和复杂的数据源中错综复杂的依赖关系,包括来自可再生能源、主动需求侧管理和分散式发电的数据源。 这个时代的方法还强调解决不确定性和可解释性的概率性和可解释的人工智能(AI)模型。 此外,先进的特征工程和转换技术还增强了机器学习驱动的峰值需求预测,以优化机器学习模型的输入表示。
根据上述观察,很明显,机器学习驱动的方法已成为现代峰值需求预测日益重要的方法。 高分辨率数据集的不断增加和计算能力的进步进一步扩大了在该领域利用这些方法的机会。 为了全面了解 ML 驱动方法在峰值需求预测中的演变和重要性,本节深入探讨了该领域最常用的 ML 技术,重点介绍了它们的技术复杂性、在不同环境中的应用以及对其性能的评估。 通过探索应用环境并评估这些方法,本节旨在揭示它们的变革潜力,并深入了解它们对克服现代电力系统峰值需求预测挑战的贡献。
技术和模型
深度学习架构
作为 ML 的子集,深度学习 (DL) 架构利用深度神经网络自动提取和表示复杂的高维模式。 这些架构通过有效地对电力负载数据中固有的复杂的时间和空间依赖性进行建模,显着改进了峰值需求预测。 通过利用多层处理,深度学习架构可以捕获复杂的模式和交互,从而提高跨不同应用程序和上下文的峰值需求预测模型的性能。 正如表 7 前面所总结的,该表对各个阶段的预测方法进行了基准测试,深度学习模型通常比 ARIMA 或 SARIMA 等经典统计方法(通常为 3-10%)实现更低的预测误差(0.5-5.7%)。 根据回顾的研究,峰值需求预测中使用的关键深度学习架构是 RNN、CNN 和集成多种深度学习技术的混合模型。
RNN 特别适合顺序数据处理,使其成为峰值需求预测的强大工具。 虽然传统 RNN 擅长捕获短期依赖性,但由于梯度消失,它们面临着长期依赖性的挑战。 LSTM 和 GRU 等高级变体通过引入增强记忆保留和选择性信息流的机制来解决这些限制。 LSTM 凭借其记忆单元和门控机制(输入门、遗忘门和输出门),擅长对长期依赖性和负载数据的突然峰值进行建模。 这些属性使得 LSTM 对于预测以突然变化为特征的峰值需求事件非常有价值。 例如,Mughees 等人。 155证明了深度序列到序列双向 LSTM 模型对于日前峰值需求预测的有效性,该模型利用输入序列的双向处理来捕获综合时间模式。 GRU 是 LSTM 的简化替代方案,通过使用更少的参数来降低计算复杂性,同时保持可比较的性能。 于等人。 38提出了一种与动态时间规整(DTW)相结合的GRU模型来增强每日峰值需求预测,从而改进模式识别并减少预测误差。 在审查的研究中,LSTM 和 GRU 架构通常使用滚动原点验证进行训练,并根据预测范围进行调整,使它们能够在负载变化的条件下进行泛化。 与传统的 RNN 相比,LSTM/GRU 变体持续提高了针对噪声、缺失值和分布漂移的鲁棒性,特别是与预处理或混合特征提取结合使用时。
CNN 擅长识别模式并从多维数据(例如负载曲线)中提取空间特征。 它们的分层学习能力能够检测可能指示或与峰值需求事件一致的详细负载模式。 CNN 在需要分解和分析负载数据的场景中特别有效。 例如,Liu 和 Brown 60 应用 CNN 模型来预测每日峰值负荷的时间,利用小波分解来增强时间模式的提取并实现更高的预测精度。
在峰值需求预测中,CNN 可能无法捕获长范围时间结构,而 RNN 则容易出现梯度消失。 混合 CNN-LSTM 架构和扩张时间卷积已被提出来解决这些限制,因为它们将局部模式提取与扩展感受野结合起来。 此外,残差和跳跃连接已被证明可以提高训练过程中的稳定性。 张等人。 164为LTPDF提出了一种具有编码器-解码器结构的CNN-LSTM混合模型,证明了基于CNN的特征提取和基于LSTM的时间学习之间的协同作用。 另一方面,Liu和Brown56研究了CNN和LSTM模型的应用来预测每日峰值负荷的发生时间。 他们的研究表明,LSTM 表现出捕获时间关系的能力,而 CNN 擅长从历史数据集中提取特征。
最近的进展包括包含更复杂架构的模型。 邓等人。 148引入了 CNN-Transformer 混合模型,该模型通过将天气相关因素集成到负载预测中来增强对极端天气条件的适应性。 此外,He 等人。 63将条件可逆神经网络(cINN)与 LSTM 变体结合使用,以包含不确定性量化,为峰值需求预测提供概率方法。
集成学习技术
在现代电力系统中,集成学习已成为一种强大的方法,通过训练多个学习器并汇总他们的预测来提高峰值需求预测的准确性和可靠性。 聚合是通过平均、投票和堆叠等策略来实现的221,这些策略利用了各个模型的互补优势。 根据其生成过程,集成方法可以大致分为顺序方法和并行方法。
Boosting 是一种顺序集成方法,专注于通过为先前错误分类的实例赋予更大的权重来迭代纠正早期模型的错误。 此过程持续进行,直到生成预定义数量的学习者或满足学习标准。 事实证明,自适应增强 (AdaBoost) 和梯度增强 (GB) 等增强算法在解决峰值能源需求的复杂动态方面特别有效。 Ahmad 和 Chen 222 强调了 AdaBoost 在预测不同时间范围(从一个月到一年)的负载曲线方面的优势。 这项研究表明,AdaBoost 可以有效捕获季节变化和动态负载模式,优于传统的 ML 模型。 此外,张等人。 223 展示了 GB 在南加州 STPDF 中的实用性。 他们的研究结果揭示了可再生能源整合的重要性,将太阳能容量确定为峰值需求的关键驱动因素。 此外,卢等人。 224将极限梯度提升(XGBoost)(GB的一种高级变体)与经验模式分解技术相结合来预测每日峰值负载,显着减少了预测误差。 在实践中,增强框架通常依赖于较小的学习率来保持稳定性,并调整树深度以平衡偏差和方差。 对行或特征进行二次采样有助于减少学习者之间的相关性,而提前停止通常用于防止过度拟合。 尽管 boosting 擅长捕获复杂的相互作用和处理不平衡的峰值事件,但它可能对错误标记的异常值和分布漂移敏感,需要仔细校准和正则化 20,225。
Bagging 是一种并行集成方法,它在训练数据集的不同引导样本上构建多个学习器,并结合它们的预测来减少方差并提高鲁棒性。 对于回归任务,装袋通常采用平均或中值聚合来最终确定预测。 Erick Meira 和 Fernando Luiz 226 利用 bagging 来预测处于不同发展阶段的国家的每月负荷需求。 他们将 bagging 与指数平滑和 SARIMA 创新结合,展示了所提出的方法在不同情况下的灵活性和有效性。 此外,他们引入了剩余筛引导作为装袋的变体,进一步提高了预测准确性,在不同的电力系统中产生了卓越的性能。 当特征强烈相关并且有时不适合尖锐的极端情况时,装袋方法可能会很困难148,150。 这些限制激发了诸如随机森林之类的改进,它通过随机特征选择来扩展装袋。
随机森林生成多个引导样本,为每个样本构建决策树,并使用投票进行分类或对回归任务进行平均221。 随着树数量的增加,与 bagging 相比,随机森林通常可以实现更低的泛化误差和更高的训练效率。 在实践中,随机森林通常配置有数百棵树,这在方差减少和计算成本之间提供了良好的平衡。 为了防止过度拟合,树的深度通常保持较浅,并强制执行最小叶子尺寸,而分组二次采样或主成分分析可用于去相关特征并进一步稳定预测。 范等人。 147利用随机森林进行峰值需求预测,通过遗传算法分配权重,并将随机森林确定为提高预测准确性的关键因素。 此外,王等人。 227应用随机森林来预测教育建筑的每小时负荷模式,其性能优于回归树和支持向量机,同时强调了不同学期特征的不同重要性。 此外,贝里施等人。 9开发了一种将随机森林与广义加性模型和深度神经网络相结合的集成方法,从而产生更稳健的峰值需求预测模型。
概率且可解释的人工智能模型
在机器学习驱动的峰值需求预测阶段,概率性和可解释的人工智能模型的进步通过解决电力系统固有的不确定性和提高可解释性,极大地影响了峰值需求预测。 在过渡阶段,概率方法的早期进步为当代方法奠定了基础。 在此基础上,这些方法已经从传统的概率技术发展到增强的混合和人工智能驱动的方法,提供增强的可靠性和决策支持。
随着计算资源和数据可用性的提高,概率预测的利用在 2010 年代及以后变得更加流行。 例如,Atsawathawichok 等人。 139利用具有多个内核设计的高斯过程来预测长期峰值需求,优化基于特征的内核以提高预测精度。 此外,沙比尔等人。 138采用贝叶斯加性回归树和条件核高斯过程回归与SVR结合来对意外参数进行建模,提供整合社会经济和环境不确定性的概率预测。 与通过核对平滑度和周期结构进行编码并在中小型数据集上提供分析校准间隔的高斯过程以及捕获天气-日历-经济混合输入中的状态变化和相互作用影响的贝叶斯加性回归树相比,我们观察到互补的优势和失败模式。 高斯过程可能无法充分代表尾部风险,除非使用非高斯似然或非平稳/异方差内核,并且它们的立方尺度限制了大型馈线级部署138,139。 相比之下,贝叶斯加性回归树对于非平稳性和分类驱动因素具有鲁棒性,但在极端情况下可能比较保守,并且在训练支持之外的推断效果很差138,201。 在审查的研究中,当关系平滑且协变量密集且高质量时,高斯过程往往会获得较低的分布分数(例如 CRPS),而贝叶斯加性回归树在结构性断裂(政策或关税转移)和以交互作用为主的异构供给者下表现更好 62,139,201。 这些互补的特性促使将核化基线与基于树的贝叶斯学习器相结合,以进行压力测试峰值场景138,201。
分位数回归神经网络 (QRNN) 也因其估计条件分位数的能力而受到关注,从而提供峰值负载变化的全面概率视图。 He等人。 64证明了将噪声辅助多元经验模式分解与 QRNN 相结合的混合模型产生概率密度预测的有效性。 这种方法可以有效分解高频噪声,从而实现更准确的峰值需求预测。 cINN 代表了概率预测的另一项进步。 海德里希等人。 125 为 MTPDF 引入了 cINN,利用特征生成和统计输入来量化峰值及其时间的不确定性。 通过提供概率分布而不是单个预测值,该方法增强了风险管理并为容量规划提供信息,从而为决策提供了更全面的框架。
近年来,人们越来越重视提高性能和确保高级 ML 驱动模型的可解释性。 可解释的人工智能技术旨在揭开这些模型决策过程的神秘面纱,增强信任并促进明智的决策。 张等人。 121将深度神经网络与 SHAP(SHapley Additive exPlanations)集成,以探索每日峰值需求预测中特征的重要性。 这种组合提高了模型透明度,使利益相关者能够更清楚地了解影响峰值需求预测的因素。 将概率方法与可解释的人工智能相结合的混合模型极大地受益于两种方法的综合优势。 索曼等人。 154引入了一种将 cINN 与传统神经网络集成的混合模型,以生成概率预测,同时保持峰值需求预测的可解释性。 此外,Fu 等人。 150采用了结合随机森林、梯度增强机和逻辑回归的集成机器学习方法来预测高峰日和高峰时段的概率。 所提出的方法结合了数据增强和特征工程,以提供概率预测并清楚地解释影响因素。 分布预测和通用解释工具之间仍然存在实际差距。 基于点的归因(例如应用于预期预测的 SHAP)可以隐藏特征影响在分位数之间的差异,这通常是操作员最关心尾部风险的地方 121。 概率模型的解释还继承了后验采样的蒙特卡洛变异性,这引发了有关再现性的问题,并且对于馈线规模的高斯过程和贝叶斯加性回归树来说,计算负担相当大。 为了应对这些挑战,文献描述了几种实践。 一种是报告分位数感知归因,以便特征效应伴随着可信的区间,另一种是将全局重要性度量与校准诊断(例如 PICP 或 CRPS)配对,确保解释反映不确定性估计的质量 61,62,64。 可以通过固定种子并报告后验抽签的解释方差来提高稳定性。 当解释与运营损失函数保持一致时,它们也更相关,例如,根据错过峰值的成本对贡献进行加权66,150。
高级特征工程和转换
高级特征工程在机器学习驱动的峰值需求预测中变得越来越重要,利用各种技术从不同的数据源中提取、选择和转换相关特征。 这些先进方法通过有效捕获和利用数据中的底层模式和依赖关系来提高预测模型的效率。
互信息(MI)是一种用于衡量变量之间依赖性的非参数方法,使其成为峰值需求预测中特征选择的有力工具。 例如,Abera 和 Khedkar 228 采用 CLARA(大型应用程序集群)与 MI 相结合来对设备使用模式进行集群。 这种方法能够从智能电表数据中提取与电器消耗和家庭人口统计相关的重要特征,从而提高预测准确性。 此外,哈克等人。 204在其结合了 SVM、ANN 和 K-Medoids 的混合模型中利用 MI 进行输入选择。 通过识别最相关的特征,该模型可以关注影响峰值需求的基本变量,例如家庭人口统计和电器使用情况。 尽管它很实用,但 MI 对数据集大小和维度很敏感,特别是在存在稀疏或噪声数据的情况下。 为了减轻这些限制,其他领域的研究探索了使用更适合小样本场景的条件互信息和基于内核的估计器。 此外,基于方差和基于熵的滤波技术已被用作预处理步骤,以增强 MI 计算的稳定性229,230。 未来的峰值需求预测模型可能会受益于合并这些策略,以提高在具有挑战性的数据条件下特征选择的鲁棒性。
递归特征消除 (RFE) 是另一种先进的特征选择技术,它根据模型性能迭代删除最不重要的特征。 Yang83将RFE与预测模型相结合,以提高次日建筑能耗和峰值需求预测的准确性。 通过系统地消除不相关或冗余的特征,模型仅保留那些对任务有显着贡献的变量,从而减少过度拟合并提高预测模型的泛化能力。 虽然 RFE 为静态特征选择提供了一个强大的框架,但很少有研究检验它删除的特征是否真正不相关。 此外,需要更先进的技术来解决时间序列和多变量数据集的复杂性。 一种有前途的方法是将 RFE 与底层模型中的 L1(Lasso)或 L2(Ridge)正则化相结合,以惩罚过于复杂的解决方案,帮助确保保留的特征既具有信息性又具有可推广性 231。
DTW 和灰色关系分析 (GRA) 通过关注数据的特定特征来扩展特征选择的概念。 DTW 通过测量序列之间的相似性来对齐时间序列数据,即使它们在时间上未对齐,也确保识别相关模式以进行预测。 于等人。 38在应用基于 GRU 的模型之前实施 DTW 来分析负载模式相似性,确保仅使用最相关的时间特征来预测每日峰值负载。 虽然 DTW 非常适合处理时间依赖性,但需要额外的技术来管理具有混合变量类型的不同数据集。 例如,仅 DTW 可能难以捕获复杂时间序列中的多个季节性和潜在趋势。 为了解决这些限制,它可以与季节趋势分解技术集成或与多尺度分解相结合,以在基于 DTW 的匹配之前增强时间对齐和趋势提取232。 GRA 通过评估变量和目标之间的相关性对这些方法进行补充,对特征进行排序以仅保留对预测影响最显着的特征。 郭等人。 202在其混合模型中结合了 GRA 进行变量选择,结合了 Fbprophet 和自适应卡尔曼滤波,有效地识别了影响每月峰值需求的最有影响力的天气和工业生产因素。
此外,先进的分解方法,例如经验模态分解及其变体,已被广泛用于增强特征提取。 黄等人。 190利用多元经验模态分解结合粒子群优化和SVR从负荷时间序列中提取特征,从而改进日前高峰需求预测。 此外,张等人。 21应用ICEEMDAN(带有自适应噪声的改进的完整集成经验模式分解)与LSTM结合来分解净负荷序列,通过隔离与峰谷预测相关的固有模式函数来促进更准确的短期净负荷预测。 然而,模式混合和对噪声的敏感性仍然是基于经验模式分解的方法中的重大挑战。 在峰值需求预测中,替代方法,例如变分模式分解或滤波器组方法,可以更好地控制频率带宽和分解分辨率,但在很大程度上仍未得到探索233。 未来的研究应该检验这些方法在增强特征提取和提高预测性能方面的潜力。
小波分解已有效应用于多项机器学习驱动的峰值需求预测研究中,以捕获负载数据中的高频和低频模式。 例如,Abdellah 和 Djamel 113 将小波分解与 ANN 和遗传优化相结合来预测每日高峰需求。 分解使模型能够准确地重建频率分量,从而增强其预测不同条件下峰值需求的能力。 同样,Panapakidis 等人。 51利用小波变换结合SVR来分解负荷序列,从而能够对希腊电力系统的日前峰值需求进行更精确的预测。 虽然小波分解对于从非平稳负荷时间序列中提取多尺度特征是有效的,但其性能对小波基和分解级别的选择高度敏感。 这些选择可以显着影响重建的质量和提取特征的一致性。 需要进一步的研究来开发在负荷预测的背景下选择小波参数的系统标准或自适应方法。
这些特征工程方法使大规模和高维数据集更容易处理。 MI 和 RFE 将宽协变量集减少为携带最强信号的变量。 DTW 会对齐负载历史记录,以便即使在时序出现差异时,可比较的模式仍然可见。 GRA 优先考虑外生驱动因素,仅保留信息最丰富的天气和工业因素。 分解方法,包括多元经验模式分解、ICEEMDAN 和小波,可以解开趋势、季节和高频分量,使模型能够摄取去噪通道而不是原始序列。 为了进一步增强非线性和非平稳条件下的预测,可以将多个分解器与深度嵌入网络相结合,从而实现针对峰值需求信号的结构复杂性定制的更自适应的表示。 在实践中,这些技术减少了内存和计算负载,同时保留了峰值相关结构,从而减轻了维数灾难并使模型能够处理流数据并支持实时部署138,207。
跨不同环境的应用
地理可扩展性
地理可扩展性定义了机器学习驱动的峰值需求预测方法在不同空间级别上的适应程度。 本小节根据审查的研究详细总结了特定方法在不同地理应用级别和预测范围内的分布。 该分析描绘了峰值需求预测方法在国家、区域、市和地方背景下以及短期、中期和长期预测范围内的流行和应用。 表 12 总结了不同预测范围内地理应用水平的研究分布。
在宏观层面上,国家层面的研究构成了第二重要的部分。 这些研究针对全国范围内的高峰需求情景,将 GDP、人口和工业数据等宏观经济指标与传统负荷和天气变量相结合。 这些外生变量通常包含在基于回归的混合框架或机器学习框架中,以捕获它们对峰值需求的影响。 例如,斯坦菲尔德等人。 80采用基于回归的方法关注澳大利亚悉尼的长期高峰需求特征,为削减高峰负荷提供政策建议。 同样,Atsawathawichok 等人。 139在泰国使用LTPDF的高斯过程模型,结合多个内核设计来提高预测精度。 对国家级研究的关注凸显了峰值需求预测在能源规划和政策制定中的重要性,其中汇总数据和更广泛的经济因素发挥着关键作用。 然而,尽管宏观经济因素的重要性得到承认,但目前国家层面的研究很少采用向量自回归或结构方程模型等先进的计量经济学方法。 相反,它们仍然以时间序列或机器学习范式为基础。 宏观经济因素与峰值需求之间复杂的相互依赖性尚未进行系统建模。 因此,未来的研究可以将计量经济学方法与现代机器学习相结合,以提高国家级预测的因果推理和可解释性。
与更广泛的国家级研究相比,区域级研究侧重于更具体的背景,构成了最大的部分,约占所审查研究总数的 37%。 这些研究通常侧重于国家内部的区域,例如省、市或州,利用本地化数据来解决独特的区域负荷消耗模式和基础设施特征。 例如,泰仁等人。 201在美国阿尔伯克基进行了STPDF,Huang等人。 190采用混合模型来预测澳大利亚新南威尔士州和维多利亚州的日前高峰需求,强调了负荷模式的区域变化。 对区域层面的关注允许更详细和针对具体情况的预测模型,这些模型可以解释区域经济活动、气候变化和基础设施差异。 虽然区域层面的研究为当地动态提供了宝贵的见解,但它们不能确保研究结果代表更广泛的区域条件。 研究中使用的数据集通常来自单一公用事业或服务领域,很少关注它们是否反映了更广泛的区域水平条件。 跨地理验证和汇总分析仍然很少,因此区域层面的研究结果通常不会超出其原始背景,从而揭示出实质性差距。 对于罕见的极端事件,合成情景生成和天气重采样可以帮助扩展稀疏的本地记录。 当模型应用于气候或需求结构截然不同的地区时,迁移学习或协变量转移调整可能会提高适应性。
放大到更精确的尺度,针对市级层面的研究较少,约占研究总数的 6%,侧重于结合市级政策和关税信息的全市范围预测。 Nguyen 和 Manuel 137 在美国奥斯汀演示了 STPDF 高斯过程模型的应用,集成贝叶斯更新以进行不确定性量化。 市政重点对于城市能源管理至关重要,地方治理和基础设施政策显着影响高峰需求模式。 市级数据的整合可以开发预测模型,支持特定城市的能源计划和可持续发展目标。 然而,目前的市级研究主要依赖于时间序列和具有天气和基本经济或关税投入的机器学习模型。 在里斯本,只有一项研究明确通过动态关税将政策杠杆纳入投入设置中118,而土地利用、密度和交通投资等城市规划的潜在影响尚未考虑在内。 将城市规划和政策决策纳入结构化外生变量可以通过将电力使用更直接地与土地使用模式、基础设施发展和政策干预联系起来,加强市级峰值需求预测。 在这种情况下,有两种潜在的方法特别有前途。 首先,空间计量经济学模型,例如空间滞后、空间误差和空间杜宾,可以捕获溢出效应并量化局部规划协变量如何传播到全市峰值。 其次,将多主体模型与预测框架相结合,可以代表不同规划场景下的异构家庭、商业和交通行为,产生更现实的需求轨迹,并提高市政预测的准确性和政策相关性。
此外,针对细粒度(例如配电馈线、微电网、个体建筑、校园或特定设施)的地方级研究约占研究的 27%。 这些研究通常需要高分辨率数据来准确反映负载变化并捕获局部电力系统的复杂运行动态。 例如,哈克等人。 204在日本大学校园的 STPDF 中采用了 ARIMA 和 K-Means 聚类,有效地捕获和分析了与教育机构相关的独特能源消耗行为。 同样,Waheed 和 Xu 207 将深度神经网络与智能电网系统中高分辨率峰值需求预测的特征选择相结合,强调了本地数据在提高预测粒度方面的关键作用。 鉴于对高分辨率输入的依赖,许多地方级研究特别强调预处理以提高数据质量。 常见的策略包括异常值检测和异常过滤(例如,小型行业预测中的隔离森林20、变电站研究中的DBSCAN(基于密度的噪声应用空间聚类)153)、聚类以平滑噪声负载模式或识别日期类型(例如,建筑和校园级别研究中的K均值85,195,197)以及降维以消除冗余 (例如,变电站和馈线研究中基于 PCA 的滤波105,192)。 一些工作进一步利用天气场景生成92或需求侧管理场景42来解决极端条件下的数据稀疏性。 地方峰值需求预测对于运营能源管理至关重要,因为它有助于实施精确的需求响应策略,并支持更精细规模的能源基础设施优化。
值得注意的是,一小部分研究涉及多层次的地理可扩展性,在单个预测模型中包含多个空间尺度。 这些研究通常采用复杂的方法来处理不同的数据源和空间层次结构。 例如,Bovornkeeratiroj 等人。 225提出了一个集成 LSTM、SVR 和 SARIMA 的多方法开源工具包,用于区域和国家层面的多水平峰值需求预测。 尽管多层次的研究强调了可跨地理和时间范围过渡的可扩展预测模型的潜力,但它们的探索仍然严重不足。 很少有研究采用迁移学习或元学习等先进技术来增强模型的可扩展性和适应性。 迁移学习允许知识从数据丰富的区域转移到数据稀缺的区域,从而提高资源匮乏环境中的预测准确性。 元学习更进一步,通过识别相关任务之间的共享结构,使模型能够快速适应新的位置或时间分辨率。 然而,多级预测尚未以一致且可扩展的方式充分利用这些技术。
预测范围
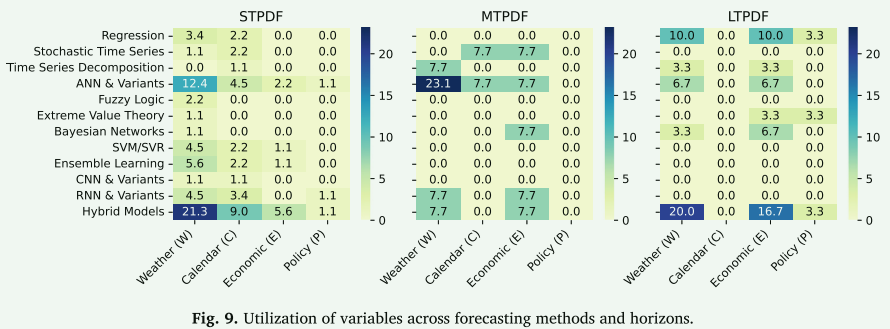
选择适当的预测方法与预测范围和外生变量的性质有着内在的联系,每个方法在准确预测峰值能源消耗方面都发挥着关键作用8,92,145。 图 9 说明了 STPDF、MTPDF 和 LTPDF 的回顾性研究中这些变量和方法之间的关系,突显了随着预测范围的扩展,变量的复杂性和多样性不断增加。
在 STPDF 中,与天气相关的变量成为多个建模类别中最具影响力的因素 73,143,155。 值得注意的是,混合模型表现出与温度、湿度或风速等气象输入的高度关联,证明了它们捕捉不稳定和动态天气模式的能力51,55,189。 人工神经网络模型还显示出与天气变量的紧密联系,反映了它们在短期范围内学习非线性关系的有效性111,115,185。 此外,与日历相关的变量(例如,星期几、假期)在这个时间尺度上具有很大的相关性134,195,特别是在使用整合周期性趋势和季节性影响的混合和神经网络模型时。 同时,贝叶斯网络或 RNN 等模型有时用于选择性短期应用,特别是在概率或顺序依赖性至关重要的情况下 133,153。
随着预测范围扩大到 MTPDF,外生变量的影响增加。 天气仍然是一个不可或缺的因素,但与经济相关的变量(例如 GDP、工业增长、人口变化)变得更加重要,反映了该预测范围内日益增加的复杂性 157,184,192。 ANN 和时间序列分解模型通常用于捕获 MTPDF 中气候条件的波动和周期性需求趋势89,92,93。 RNN 变体(包括 LSTM)也与中期天气和经济数据适度相关,因为它们在建模扩展时间依赖性方面具有优势 155,234。 日历和经济变量在随机时间序列模型中都发挥着重要作用85,114,而贝叶斯网络被认为可以捕获在几周到几个月内演变的经济驱动因素之间的概率依赖性138,206。
在 LTPDF 中,天气和经济相关变量变得更加占主导地位。 混合模型可以整合长期气候趋势、人口变化以及市场或政策因素,在利用这些输入方面特别有效8,139,140,164。 基于回归的模型,从简单的计量经济学方法到非线性或分位数回归,也表现出对这些变量的强烈依赖,突出了它们在捕捉长期线性和非线性趋势方面的能力53,80,203,235。 此外,概率或极值技术与长期规划场景特别相关,因为它们擅长处理罕见事件和峰值极值29,48。 尽管政策相关变量较少使用,但它们在回归和混合模型中仍然发挥着有意义的作用,特别是在可再生能源指令或需求响应计划等政策变化产生持久结构性影响的情况下42,66。
目前,只有非常有限的研究涉及多水平峰值需求预测,其目的是在不同时间尺度(例如每日、每月和每年的峰值)生成一致的预测。 例如,金等人。 206提出了一种混合LSTM-反向传播神经网络模型,该模型集成多源信息来联合预测中国广东的中长期峰值负荷。 这种方法利用神经序列学习和前馈结构来弥合时间尺度,同时还结合了天气、经济和政策相关变量。 尽管有这些初步贡献,多层面预测仍然没有得到充分的探索。 现有方法通常单独处理不同的范围,并且缺乏在时间尺度上保持一致的预测性能的机制。 未来的研究可以通过开发分层框架来推动这一领域的发展,这些框架明确地协调跨领域的预测,确保汇总的短期预测与长期规划结果相一致。 多任务学习代表了另一个有前途的方向,其中天气、经济活动和政策转变等变量的共享表示可以产生特定水平的输出,同时平衡短期变化与长期结构趋势。 此外,概率方法非常适合表示不确定性如何从短期波动传播到长期结构变化,这也可以提高预测模型处理多水平输入的能力。 结合这些方法将支持开发能够支持统一规划和运行控制的强大的多层面预报系统。
总之,在 STPDF 中,任务受到直接和不稳定因素的强烈影响,例如天气和日历变量,这些因素可以通过混合、ANN 和 DL 模型有效解决111,196。 随着视野延伸到中期,经济因素的影响力变得越来越大,促使MTPDF采用随机时间序列和人工神经网络等方法来跟踪不断变化的社会经济和季节性趋势85,157,236。 对于 LTPDF,天气和经济变量变得越来越重要,基于混合和回归的方法为捕获长期趋势提供了有效的解决方案 8,66,139,164。 另一方面,在 LTPDF 中,与中短期环境相比,深度学习模型的作用通常会减弱,这主要是由于输入数据稀疏且粗粒度、结构变化驱动的非平稳模式以及有限训练样本过度拟合的高风险,这凸显了设计能够处理不同输入并在长期预测范围内对复杂依赖关系进行建模的高级深度学习框架的必要性。
利益相关者和范围对应关系(这部分有意思,经济学)
有效的峰值需求预测支持多个利益相关者群体,每个利益相关者群体都有不同的实际需求和操作范围。 使预测方法与这些需求保持一致对于提供可操作的相关见解至关重要。 为了有效地捕捉这些不同的需求,必须在特征选择、时间分辨率和可解释性方面定制预测模型。 例如,住宅、商业和工业用户不仅消费模式不同,而且运营优先级也不同,因此需要针对利益相关者的输入、模型复杂性和性能指标进行特定配置。 本小节描述了主要的利益相关者类别,并说明了各种建模方法如何应对各自的挑战。
电网运营商和电力零售商通常管理国家或地区的预测任务。 他们关注的问题涵盖电网稳定性、资源分配和基础设施规划,因此需要高精度、可扩展的方法来适应广泛的外生变量。 集成学习、深度学习架构(例如 LSTM 和 GRU)以及混合模型经常出现在这种环境中。 Lee 和 Cho 8 描述了一种使用传统机器学习技术的国家级方法,而Zhang 等人。 21通过混合框架讨论西澳大利亚的全系统预测。 这些模型通过整合气象、运营和经济因素来支持短期和长期战略,使公用事业公司能够部署明智的峰值负载管理解决方案。
工业和商业实体的经营规模从市级到区域性不等,通常涵盖短期到长期。 他们的用例包括 DSM、运营调度和成本控制,并且倾向于采用混合模型、集成学习和深度学习来处理实时数据和运营约束。 在采矿业,Laayati 等人。 149引入了一种针对露天矿能源需求量身定制的快速森林分位数回归方法。 同样,机场航站楼能源系统受益于捕获非线性动态负载行为的 CNN-Transformer 混合模型 7。 此类设置有助于有效的预测和负载优化,从而降低能源成本和运营风险。 忽视这些参与者的操作优先级或约束可能会导致模型输出不准确或不切实际,从而导致成本高昂的低效率和未开发的灵活性潜力。
住宅建筑具有局部消耗和高可变性的特点,需要短期、高分辨率的预测解决方案。 数据通常源自智能电表和特定于设备的使用模式,指导深度学习架构(例如 CNN、LSTM)、模糊逻辑和集成学习的采用。 Ai 等人的进化 LSTM 集成。 22 重点关注家庭峰值需求预测,而 Alduailij 等人。 23使用先进的神经网络来评估智能建筑的峰值能耗。 这些改进的技术使建筑管理者和设施运营商能够优化能源使用、降低公用事业费用并保持系统稳定性。 然而,如果未能纳入居住视角,例如舒适度偏好或行为变异性,可能会阻碍需求响应计划的设计,并削弱公众对灵活性举措的参与。
政府机构和政策制定者需要捕捉概率和社会经济变量的国家长期预测。 他们的模型通常集成贝叶斯网络、高斯过程或可解释的人工智能框架,以捕获不确定性并为政策决策提供透明的见解。 普洛苏万等人。 140利用国家层面的高斯过程研究泰国发电部门的峰值需求预测。 同时,Lee 和 Cho 8 以及Zhang 等人的研究。 21强调将区域电力系统分析纳入战略决策的相关性。 这些模型提供了关于长期需求的概率观点,并适应经济和监管环境的变化,增强了它们对能源政策制定的价值。
为了支持更广泛的包容性并确保利益相关者的信任,未来的预测框架应纳入参与机制,例如协同设计研讨会、基于调查的建模优先级或根据利益相关者反馈进行迭代验证。 这些机制确保关键的建模假设(例如风险承受能力、预测粒度或变量优先级)不是自上而下强加的,而是根据现实世界的约束和优先级来确定的。 此外,由于利益相关者的目标可能会发生冲突,例如工业可靠性与家庭负担能力或公用事业级稳定性与分布式灵活性,因此预测模型必须嵌入多目标规划框架中。 分层建模、场景分析或帕累托优化等技术可以帮助平衡竞争需求,促进跨系统级别的公平和高效决策。
应用地点的经济趋势
经济趋势在影响不同地理区域峰值需求预测方法的采用和实施方面发挥着至关重要的作用。 经济发展、能源基础设施投资、技术进步和政策框架之间的相互作用显着影响不同地区使用的预测模型的重点和复杂程度。 图 10 展示了 ML 驱动的峰值需求预测方法的全球应用概况。
从广泛的层面来看,这些预测举措的分布表明先进的方法并不局限于单一大陆,而是遍布世界各地。 观察到的总体趋势是:在能源基础设施、数据分析和可再生能源整合方面大力投资的国家通常采用更先进的建模方法。 它们将尖端的机器学习技术(融合了统计和机器学习驱动的技术)与符合政策的框架相结合,凸显了经济趋势、监管激励和技术能力对确定方法偏好的重大影响。 然而,理清这些因素之间的因果关系仍然具有挑战性。 在许多情况下,能源基础设施的增长和预测能力与更广泛的经济发展共同发展。 未来的研究可以受益于更复杂的计量经济学框架,这些框架可以明确地模拟经济指标(例如 GDP、电气化率)、基础设施变量(例如电网扩张、智能电表普及率)和预测模型采用之间的动态和非线性相互作用。
在美国和加拿大等工业化程度较高的国家,对电网可靠性和成本控制的日益关注正在推动增强型预测系统的进步和实施56,119,150,195。 这些国家在强大的能源基础设施、可再生能源整合充足的政策激励措施以及资金充足的研究的支持下,经常采用机器学习驱动的混合方法,包括深度神经网络、集成方法和时间序列分解技术,以实现精确且可扩展的峰值需求预测60,121,154。 在这种情况下,标准方法通常利用从天气、日历和运营数据中提取特征以及基于注意力的框架来管理现代电力系统固有的复杂性。 通过利用能够解决短期波动和长期模式的尖端模型,系统运营商和政策制定者可以增强预测的稳健性、灵活性和可解释性,从而促进更有效的能源规划和电网管理。
与此同时,在中国、印度和伊朗等快速发展的国家,工业化和城市化推动的能源需求不断增加,鼓励使用先进的预测模型来捕捉经济扩张、不断变化的消费模式和可再生能源整合之间的相互作用。 混合模型184,192和集成模型147,148等技术越来越多地被采用来解决不确定性。 例如,在印度,基于 ANN 111 或非参数概率密度预测 92 的模型已被证明可以有效解决数据和复杂性快速变化的性质。 最近的多阶段框架通过集成中央邦的新颖架构进一步完善了中期电力负荷预测124。 这些方法可以在动态负荷行为和不同的外生因素下进行更稳健、灵活和准确的预测。 然而,在这些背景下,整合不同数据源的挑战仍然很大,特别是当数据质量或覆盖范围不均匀时。 人们越来越需要自适应模型来适应丢失、噪声或延迟的输入,而不影响预测的可靠性。
在其他地区的新兴市场中,主要关注点通常在于扩大电力供应、提高电网稳定性以及采用能够在这种条件下有效发挥作用的可靠预测技术。 当地公用事业公司越来越多地采用人工神经网络和模糊逻辑等方法,以及针对较小数据集和成本敏感环境定制的计量经济模型。 例如,在尼日利亚和津巴布韦,年度峰值需求预测利用基于回归或计量经济学模型53,131,而阿尔及利亚和印度尼西亚等国家则展示了自适应混合方法和极短期模糊逻辑在管理突发负荷变化方面的实用性93,134。 这些地区往往难以获得高质量、精细的数据,这限制了预测技术的选择和性能。 在这种情况下,鲁棒性变得至关重要,需要预测模型能够通过插补、集成平均和不确定性感知学习等技术来容忍不完美或不完整的输入。 忽略这些数据限制可能会导致峰值负载的系统性低估或高估,从而可能导致规划决策不理想或资源分配不当。 因此,开发轻量级、抗噪声模型对于在资源匮乏的环境中公平部署预测工具至关重要。 国际合作和有针对性的资金进一步促进了这些资源高效且可扩展的解决方案的采用,使运营商能够优化需求方资源,减少电力损耗,并以具有成本效益的方式指导容量规划48,113,135,191。
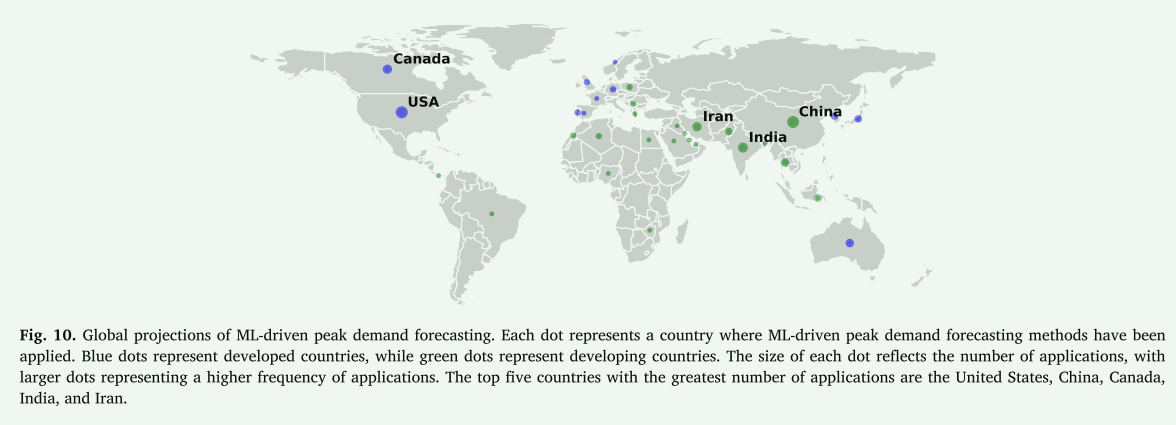
总之,观察到的模式揭示了经济增长、能源政策结构、技术投资和预测模型进步之间的强有力的相互作用。 投资数据收集系统、可再生能源整合和数字基础设施的地区创造了条件,使高级预测可以有效提高电网稳定性,为基础设施投资提供信息,并帮助实现可持续发展目标。 解决数据获取和预测能力的地区差异不仅是一个技术问题,也是一个能源公平问题。 未来的方向应考虑参与式设计流程,让当地利益相关者参与共同开发反映当地现实、需求和约束的预测框架。 另一方面,资源较为有限的地区往往采取分阶段的方式,逐步整合更先进、更复杂的模式来满足快速发展过程中出现的新需求。 这种动态凸显了需要将峰值需求预测方法的进步与经济现实、资源可用性和政策目标结合起来,从而确保这些方法在各种电力系统中保持有效和适应性。
与可再生能源整合
可再生能源,特别是太阳能光伏(PV)和风力涡轮机的整合,给峰值需求预测带来了复杂性和机遇。 与可以相对确定地安排发电量的传统发电不同,可再生能源由于天气条件和季节性模式的波动而表现出间歇性行为。 即使太阳辐照度或风速的微小偏差也会导致净负荷的显着波动,从而使传统的负荷预测技术变得复杂。 因此,电网运营商在努力实现可持续发展目标的同时,面临着平衡供需、避免过载和保持可靠性的更大压力。 这些挑战强调需要强大且适应性强的预测模型,能够管理可再生能源输出的快速、短期变化和长期趋势21,132。
为了应对这些挑战,研究人员和公用事业公司探索了一系列针对可再生能源丰富的环境量身定制的先进峰值需求预测模型。 例如,法拉吉等人。 132开发了结合太阳能光伏和风力涡轮机的多年负荷增长模型,以捕获净需求的时间变化并指导德黑兰并网微电网的优化规划。 在西澳大利亚,EVT 已用于评估光伏发电容量如何影响长期变电站最大需求,使公用事业公司能够识别各种太阳能采用率下的高需求场景 29。 一些短期净负荷预测将 LSTM 网络与经验模式分解相结合,以捕获屋顶光伏引入的粒度波动 21,而 cINN 已被提出来对负荷曲线、气候变量和高可再生能源采用之间的复杂相互作用进行建模 125。 与此同时,关注 DSM 的研究表明,结合调峰策略和存储解决方案(例如电池系统)可以帮助减轻间歇性可再生能源带来的波动性 42,66。 这些工作共同映射了将可再生能源变化纳入峰值需求预测的几种理论途径。 一些通过 DSM 和存储明确模拟需求方行为,而另一些则通过结合负荷和可再生能源发电预测来关注净需求。 EVT 和 cINN 等概率框架量化了不确定性,以聚合形式进行预测或在馈线级别进行独立预测之间的选择决定了变异性是平滑还是保留。 这些维度强调了在高可再生能源渗透率下预测框架中表示可变性和不确定性的不同方式。
在此基础上,多种方法还将预测重点扩展到单个峰值幅度之外。 例如,张等人。 21明确预测了净负载的峰值和谷值,提供了每日变化的测量。 以 DSM 为导向的研究 42,66 展示了负荷转移策略如何重塑负荷持续时间曲线,强调了持续性和峰值大小的重要性。 同样,光伏渗透率下变电站需求的 EVT 分析29将峰值估计与回报水平联系起来,有效捕获持续极端的概率。 这些研究表明,反映持续时间和可变性的产出已经在可再生能源丰富的环境中出现,并且它们提供了对灵活性和不断增长的需求的见解,而这些需求不能仅从峰值得出。 证据共同表明,可再生能源丰富的系统中的峰值需求预测越来越需要关注峰值的大小及其时间特征,例如持续时间和变化性。
尽管取得了这些进展,但严峻的挑战仍然存在。 其中一个困难是捕捉太阳能和风力发电的随机性和天气依赖性,其中短期波动可能导致净负荷的快速波动,即使是先进的模型也难以预测。 最近的研究已经开始通过将极端天气信息纳入集合模型148或通过提供明确量化不确定性的概率预测63来解决这个问题,但快速间歇性的问题仍未解决。
除了方法论方面之外,政策和经济驱动因素在塑造可再生能源与峰值负荷的相互作用方面也发挥着重要作用。 对分布式能源的激励措施,如屋顶光伏发电,以及对绿色能源的推动,重塑了负荷曲线,有时会导致午后净负荷谷值(Azemena 等人237引入的"鸭子曲线")或晚间峰值。 准确的预测模型现在必须考虑这些不断变化的消费和发电模式,以及维持电网稳定性所需的爬坡能力。 具有前瞻性的公用事业公司和政策制定者正在整合需求响应计划、实时定价和容量市场机制,以鼓励消费者围绕可再生能源的可用性调整能源使用42,66。 随着可再生能源在全球电力系统中的不断扩展,方法论的进步和政策努力的结合确保峰值需求预测不仅支持即时的运营效率,而且支持长期的可持续性、弹性和经济可行性。
先进的网格技术
在现代电力系统中,智能电表、物联网 (IoT) 设备和实时通信网络等先进电网技术重新定义了峰值需求的测量、分析和预测方式。 这些技术提供了家庭、建筑物和配电馈线级别的高频、精细的能源消耗数据204,228,揭示了以前被传统计量的粗分辨率所掩盖的详细负载模式。 通过利用公用事业和最终用户之间的双向通信,系统操作员不仅可以监控近乎实时的负载状况,还可以实施更具响应性和针对性的干预措施。 通过这种方式,先进的网格技术成为数据丰富环境的支柱,其中机器学习驱动的峰值需求预测模型可以不断完善,以适应不断变化的需求模式和天气、假期或定价信号等外生变量236。
这些创新的核心优势在于能够开发动态、高度响应的预测模型。 通过访问流消耗数据,公用事业公司可以集成机器学习算法来预测和响应每小时或每分钟的峰值负载23,155。 在某些情况下,集成和混合方法结合了时间序列分解、特征提取和实时异常检测来捕获负载的突变20。 例如,在商业和工业设施中推出物联网传感器使 DSM 程序能够近乎实时地卸载或转移负载,从而减轻峰值并提高电网可靠性 20,42,66。 此外,在公用事业或城市规模上,强大的数据流有助于地理空间负载分析和预测性维护,进一步降低意外中断和波动峰值条件的风险236。
然而,先进网格技术生成的数据量和速度给可扩展管理带来了重大挑战。 一个重要的问题是互操作性,因为物联网设备和传感器网络通常使用异构协议和数据格式运行,需要通过标准化接口和元数据方案进行协调。 数据质量是另一个问题,尽管许多研究已经通过清理、过滤和分解来减轻缺失值、噪声和错位。 在可再生能源和物联网丰富的环境中,数据流的高频和分散特征使这些问题变得更加尖锐,而强大的预处理成为集成到预测模型中的先决条件。 新兴解决方案包括边缘计算和分层数据架构(允许在源附近进行初始处理以减少带宽和延迟)以及联合学习(在保护隐私的同时实现去中心化训练)。 除了这些技术之外,存储基础设施和流处理框架的进步对于确保大规模预测保持准确和及时至关重要。
展望未来,基于物联网的框架和智能电网创新将重塑峰值需求预测模型。 通过从广泛的传感器网络提供高频、精细的数据,这些系统可以减少数据延迟并提高预测分析的速度和准确性。 将机器学习算法与实时物联网数据相集成,有助于近乎即时的态势感知、提高电网可靠性和经济高效的负载管理。 例如,智能电表部署可实现动态的设备级监控20, 228,而地区级的汇总短期预测技术则利用高分辨率消耗数据来完善峰值预测236。 随着峰值预测模型越来越依赖于海量、高频数据集,对可扩展流处理框架和智能数据管道的投资将变得越来越重要。 在线学习和自适应特征选择等技术可以进一步确保机器学习模型在实时设置中保持准确且计算可行。 这些先进的数字架构和自适应预测方法为公用事业和政策制定者提供了前所未有的洞察力和对电网运营的控制,最终提供更具弹性和可持续的能源解决方案207。
批判性评价
机器学习驱动的峰值需求预测的优势
机器学习驱动的方法引入了多项进步,专门解决峰值需求预测的独特特征,这需要处理峰值需求数据中的极端变化和非线性。
建模非线性需求关系。 机器学习驱动的峰值需求预测模型特别擅长捕获传统统计模型通常无法解决的变量之间的非线性关系。 最近开发的用于集成多种机器学习算法的框架进一步利用了这种能力来捕获不同的非线性。 例如,Gajowniczek 等人。 59 演示了 CART、K-NN 和 ANN 的集成如何利用每种算法的优势来处理能源消耗的周期性变化,从而改进季节性峰值的分类。 同样,Liu和Brown56提出了一种结合朴素贝叶斯、SVM、随机森林、AdaBoost、CNN和LSTM的多算法框架,使模型能够隔离复杂的需求模式并在不同场景下提供准确的预测。 此外,Bovornkeeratiroj 等人开发的 PeakTK 等开源工具。 225引入了将不同预测方法和数据集集成到单个框架中的平台。 通过提供用于评估和基准化预测方法的标准化工具,此类平台促进了模型开发和应用的进步。
对不同变量的适应性。 峰值需求预测必须考虑高度动态和特定环境的驱动因素,例如极端天气事件和大型公众集会。 这些瞬态事件会造成能源消耗的突然变化,因此需要能够动态调整以适应这种变化的模型。 先进的特征提取技术(包括 RFE 和 PCA)通过隔离最重要的变量同时减少噪声来发挥关键作用,确保模型始终专注于有影响力的预测变量 26,148。 此外,事实证明,集成多种算法对于适应异构能源消耗模式是有效的。 例如,Bellahsen 和 Dagdougui 236 证明,结合 LSTM、随机森林和 K-NN,可以利用每种方法的优势,实现准确的建筑级峰值需求预测。 LSTM 网络擅长对时间序列数据中的顺序依赖关系进行建模,而随机森林可以稳健地处理分类和数值数据,而 K-NN 可以捕获局部变化。 在预测不同建筑类型和使用模式的需求时,这种组合有助于提高性能。
处理极端事件和概率。 热浪和工业激增等罕见但有影响的事件由于偏离典型的需求模式,给峰值需求预测带来了重大挑战。 EVT 和贝叶斯网络等概率方法非常适合对此类异常值进行建模。 EVT 专注于极端需求事件的统计特性,能够准确预测罕见事件期间的峰值概率 46。 另一方面,贝叶斯网络对变量之间的概率关系进行建模,提供对驱动峰值负载的依赖性的见解138。 将这些方法纳入更广泛的机器学习框架可以增强其预测能力,特别是对于极端事件可能产生不成比例影响的长期预测。 例如,将 EVT 与 ML 驱动模型相结合可以提高涉及高影响需求波动场景的可靠性 235。 除了 EVT 和贝叶斯网络之外,集成方法也可以作为不确定性量化的实用工具。 通过聚合不同学习者的预测,集成提供结果分布而不是点估计,从而允许决策者评估峰值预测的置信区间。 这通过解决操作环境中的认知和任意不确定性来补充贝叶斯方法。
用于增强季节性动态的混合建模。 混合建模提供了解决不同环境中的不同需求模式的灵活性。 值得注意的是,根据已审查的研究,事实证明,将机器学习与传统分解技术相结合对于解决峰值需求预测中季节性动态的复杂性非常有效。 例如,小波分析与人工神经网络的结合可以将数据分解为不同的频率分量196。 这种方法提高了模型捕捉季节性变化和长期趋势的能力,从而实现更精确的峰值需求预测。 此外,Amara-Ouali 等人。 238探索了多分辨率建模,它集成了广义加性模型和人工神经网络,强调了分解时间序列数据如何隔离峰值变化的周期性驱动因素,使模型能够动态适应消费模式的变化。 这些分解-ML 混合函数充当自适应平滑方案,通过学习时变季节性结构和非线性交叉效应来减轻固定系数指数平滑的局限性。
使用时间模型进行动态预测。 动态预测需要能够捕获能源消耗模式中固有的时间依赖性的模型。 事实证明,RNN 和 LSTM 等深度学习模型在该领域特别有效。 例如,Yu 等人。 38 证明了 RNN 在 STPDF 中的有效性,通过对时间变化进行建模并结合最新的负载数据来实现高精度。 类似地,Ibrahim 和 Rabelo 234 对 MTPDF 采用了深度架构,包括 CNN、CNN-LSTM 和多头 CNN。 这些模型捕获了多个时间尺度的负载曲线中的复杂行为,进一步强调了时间适应性在处理动态需求场景中的重要性。
实时数据集成。 机器学习驱动的方法在集成来自智能电网的连续实时数据流方面非常有效,从而实现更具适应性和响应性的峰值需求预测。 可再生能源发电水平、电池存储容量和消耗数据等实时输入使预测模型能够根据不断变化的电网条件进行动态调整,从而支持峰值负载管理的及时决策。 通过先进的特征工程和转换,实时数据被简化为一组紧凑的去噪信号,从而实现高效、低延迟的预测。 例如,沙比尔等人。 138强调了在合并来自智能电网的实时数据时概率模型的准确性的提高,展示了动态更新在管理波动的需求场景中的价值。 同样,Waheed 和 Xu 207 演示了深度学习模型如何从实时能源消耗数据中增量学习,从而提高预测对需求模式突然变化的适应性。
限制和挑战
尽管有这些优势,机器学习方法仍面临着高峰需求预测的性质所带来的特定挑战。
短期极端变化的复杂性。 虽然机器学习驱动的峰值需求预测框架在捕获非线性关系和多样化模式方面表现出显着进步,但短期极端变化(例如需求突然激增)由于其不可预测的性质和高频动态,仍然具有挑战性。 传统的机器学习框架,即使是通过深度学习或混合方法增强的框架,也可能缺乏此类高频变化所需的响应能力。 为短期范围设计的模型(例如 CNN-LSTM 架构)展示了捕获时间模式的优势,但在应用于具有意外需求峰值的场景时会遇到困难,正如动态峰值负载行为研究中所强调的那样 56,234。 这些变化固有的复杂性不仅需要先进的时间建模,还需要一个强大的机制来合并实时数据以适应快速变化。
高峰场景下过度拟合。 过度拟合给机器学习驱动的峰值需求预测带来了重大挑战,可以通过两种形式广泛观察到。 第一种类型源于数据稀疏性,特别是对于罕见和极端的峰值事件。 在这种情况下,模型过度依赖有限的历史模式,这限制了它们推广到新条件的能力。 例如,邓等人。 148 指出,基于提升的学习器需要仔细正则化,以避免过度关注特定的过去事件,而 Hsu 和 Chen 50 发现,人工神经网络虽然能够有效捕获非线性关系,但在稀疏峰值数据下难以泛化。 小波-人工神经网络模型等混合方法也因过分强调分解的季节性特征而存在过度拟合的风险196。 这里的缓解策略需要诸如正则化(例如,L1/L2 或 dropout)、稳健的交叉验证以及通过合成事件生成来增强数据等策略 148。 这些方法可确保更好的泛化,从而增强动态和不断发展的电力系统的机器学习模型的可靠性。 此外,解决峰值需求预测中的过度拟合问题需要仔细控制输入维度,因为高维数据会加剧记忆噪声的风险。 贝叶斯正则化110、递归特征消除83和级联或分层神经网络70,180等技术减少了输入空间的有效维度并提高了泛化性,从而保持了建模过程的透明度。 第二种类型的过度拟合与设计相关,出现在结构复杂的混合体中。 当组合多个组件时,例如 ANN 模糊混合或基于深度学习的混合,增加的容量和大量的超参数可能会导致记住噪音,而不是捕获可概括的模式。 研究通过进化优化(例如,用于增强季节性动态的遗传算法或混合建模)181,190、仔细的参数和超参数调整47,200以及嵌入物理或经济约束作为正则化器42,202解决了这个问题。 这两种形式的过度拟合表明模型设计必须适应可用数据的特征和预测范围的长度。 操作限制也会影响建模策略的选择。 由于预测设置差异很大,因此没有任何单一架构或训练程序能够在所有条件下都表现良好。 因此,在峰值需求预测中,有效的模型选择依赖于跨代表性用例的基准测试、测试结果对模型复杂性的敏感性以及确保输出与下游决策的需求保持一致。 最近的研究越来越多地使用模块化混合设计,平衡预测准确性与可解释性和计算成本,指出针对特定环境而不是通用解决方案量身定制的方法的价值。
数据差距和罕见事件采样。 峰值需求预测的一个反复出现的限制是高质量数据的不完整或不一致,这可以从三个主要方面考虑。 首先,负载数据的粒度经常会出现问题。 不同研究的分辨率和聚合水平各不相同,从每小时的系统级数据到细粒度的智能电表或馈线测量,并且地理覆盖范围并不总是一致的。 在粗略或聚合数据上训练的模型很难捕获局部峰值或短期波动68,201。 解决这一限制需要改进对高分辨率负载测量的访问199,207、分层预测方法和转移学习技术来弥合跨区域的差距。 其次,许多模型严重依赖外部驱动因素,例如精确的天气观测、日历效应和详细的经济指标。 然而,这些外生变量并不总是统一或以相同的分辨率记录122,145。 缺少天气数据、未记录的日历事件或不完整的社会经济记录可能会导致训练数据集出现空白,从而降低模型的准确性和可靠性。 因此,对详细外部数据的依赖是峰值需求预测研究的一个常见缺点,因为许多公用事业公司无法保证统一的可用性。 文献中探讨的解决方案包括稳健插补、多源数据融合和缺失输入的概率处理20,118。 第三,极端高峰事件的罕见性带来了重大挑战,例如严重热浪或突然的经济变化引起的峰值。 这些事件每年可能只发生几次(或更少),从而限制了模型可用的样本数量。 机器学习驱动的峰值需求预测模型可能会难以应对这种不平衡的数据,因为它们往往会使预测偏向更频繁观察到的条件21,42,48。 因此,捕捉罕见峰值需求极端情况的细微差别需要采用专门的方法,例如高级过采样、合成数据生成或前面提到的 EVT,以确保预测模型能够解释推动系统压力和资源规划决策的少数但重要的情况。
极端事件不确定性量化。 EVT 和贝叶斯网络等极端事件建模技术对于量化与罕见但有影响的峰值负载事件相关的风险是必不可少的。 然而,这些方法的计算量很大,主要是因为它们依赖于参数估计、概率计算和基于模拟的验证。 Belzer 和 Kellogg 46 强调了为每日峰值需求建模实施 EVT 带来的计算负担,其中蒙特卡洛模拟对于处理极端需求事件的概率性质至关重要。 虽然这些模拟提高了预测可靠性,但它们显着增加了处理时间和资源需求,使得它们难以集成到实时应用程序中。 同样,集成方法通常结合多个模型来提高准确性,但会在训练和推理阶段增加计算成本225,236。 这些方法需要处理高维数据、频繁更新和迭代优化,进一步加剧了资源需求。 除了计算方面之外,极端事件建模还引起了一些实际问题。 首先,EVT 性能对独立性假设和阈值选择高度敏感。 多日热浪和需求方干预通常会引起依赖性和非平稳性,这使得去聚类、阈值诊断和协变量驱动的非平稳 EVT 成为可取的29,42,48。 其次,在评估重合峰值时,贝叶斯网络可以实现数据高效、政策感知的"假设"分析,但可以低估联合尾部共同运动。 Copula(包括 vine copula)可以更有效地捕获尾部依赖性,但需要更大的数据集并且更难以解释。 第三,密度预测还需要通过上述 PICP 和 CRPS 等措施进行系统审计。 它们最好通过 90-99% 范围内的峰值分位数进行沟通,并结合阻塞或季节性交叉验证来解决峰值需求预测中的类别不平衡问题 62,64。 最后,在适应气候变化的规划中,包含温度、电气化趋势、关税结构和 DSM 变量的情景条件后验使得不确定性估计能够与运营决策更紧密地结合起来 8,66,139,140。
与分散式电力系统集成。 随着屋顶光伏板、风力涡轮机和家用电池存储等分布式能源渗透率的增加,电网运营商和公用事业公司在准确预测峰值需求方面面临着新的挑战22,132。 传统的峰值需求预测方法通常假设集中生成负载曲线,但分散系统会带来更多的可变性和不确定性。 例如,由于云层覆盖或电池存储系统的协调放电而导致的太阳能突然减少可能会以传统模型无法捕获的方式转移或压平负载峰值。 此外,可变的可再生能源发电、存储单元和消费模式之间依赖时间的相互作用需要能够动态适应网络约束和局部微电网调度的模型21。 因此,在这种环境中进行有效的预测需要增强的方法来捕获本地消费模式,整合间歇性可再生能源生产,并纳入电池充电计划或需求响应信号等运营约束。 去中心化环境中的另一个相关限制是数据的异构性。 智能电表、屋顶光伏逆变器、物联网传感器和气象站提供不同时间分辨率和不同可靠性的信息。 协调这些异构输入仍然具有挑战性,需要先进的预处理、多源融合和分层建模策略。
可解释性和利益相关者的信任。 随着用于峰值需求预测的更复杂的深度学习和集成算法的兴起,可解释性问题变得非常重要74。 公用事业公司、政策制定者和最终用户不仅必须了解预测的负荷值,还必须了解影响这些预测的潜在驱动因素,例如天气波动、日历效应、经济趋势或消费者行为的变化。 在内部决策过程不透明的黑盒模型中,向监管机构证明预测的合理性或根据模型见解调整运营策略变得具有挑战性。 缺乏可解释性可能会削弱利益相关者的信心,并减缓尖端预测技术的采用。 面向决策的解释可以通过澄清哪些变量对预测峰值有贡献以及预测对这些输入变化的敏感程度来帮助解决这一差距。 对于公用事业公司来说,这些信息支持采购和需求响应调度。 对于政策制定者来说,它为关税设定和有针对性的干预措施提供了基础。 对于消费者来说,它使高峰司机更加透明,并鼓励参与需求方计划。 最近的工作已经开始引入可解释的人工智能技术和与模型无关的方法,例如 SHAP、部分依赖图和基于规则的决策可视化 121。 这些方法揭示了不同输入变量的贡献,突出风险较高的时期,并允许操作员跟踪模型如何以及为何达到特定的峰值预测。 应该指出的是,可解释性是必要的,但对于利益相关者的信任来说还不够。 预测还取决于可靠的数据、监管协调和可行的系统集成。 在数据不一致的情况下,例如智能电表覆盖范围或可变传感器分辨率的差距122,145,即使是透明的模型也可能产生不可行的见解。 监管框架同样期望决策是合理的,而如果没有额外的解释层,许多机器学习模型尚无法提供这一点53,121。 与 SCADA(监控和数据采集)、能源管理系统和费率设定系统的集成提出了进一步的挑战,因为这些基础设施并非旨在处理复杂或概率学习模型的输出42,236。 进一步的问题是输入变量之间的相关性。 天气、日历和经济因素经常重叠,从而产生多重共线性,从而削弱模型的可靠性。 PCA、正则化和集成学习等技术有助于通过限制冗余来降低这种风险。 在发展中地区,外源数据的稀缺使问题变得更加严重,研究人员转向迁移学习和数据增强来补偿缺失的信息239,240。 然而,即使采用这些方法,模型仍然受到理论限制,因为捕获复杂的非线性需要代表性数据和足够的样本量,否则很难实现泛化。
未来方向
当今的能源行业受到新技术快速集成的影响,例如基于区块链的点对点交易、物联网驱动的智能计量和先进的深度学习架构,这些技术引入了新形式的需求变化和高分辨率数据流。 与此同时,边缘计算、联邦学习和多智能体系统的兴起为去中心化和扩展预测框架提供了新的机会,同时尊重隐私和系统异构性。 然而,这些进步也带来了紧迫的挑战,包括需要可解释的模型、地理通用性以及与分布式能源的无缝集成。 因此,峰值需求预测的未来在于开发自适应、可解释和弹性的系统,能够从多样化的实时数据中学习,同时支持在日益复杂的网格环境中进行决策。 本节重点介绍了需要进行更深入研究以解决当前局限性的现有研究差距,以及正在塑造该领域发展的新兴趋势。
研究差距
数据高效泛化
峰值需求预测中的一个持续挑战是如何在数据稀缺、噪声或碎片的情况下构建准确的模型。 这个问题在新开发的城市地区、微电网或计量基础设施有限的地区尤其严重,这些地区的历史记录不足以支持复杂的机器学习模型。 迁移学习提供了解决这些限制的一种潜在途径。 它是指将模型或学习到的表示从一个领域或数据集应用到另一个领域或数据集的实践,从而减少对大量目标数据的需求。 这种方法的可行性在于观察到峰值需求模式通常是由常见的驱动因素决定的,例如温度、日历效应和日常活动节奏,这些驱动因素往往在不同的情况下重复。 例如,蔡等人。 239证明,迁移学习可以通过迁移从数据丰富区域学习到的深度神经网络特征来改善数据稀缺区域的短期负载预测。 同样,李等人。 240提出了一种多源迁移学习集成LSTM方法,该方法选择相似的源建筑物并整合其知识,以提高数据有限的目标建筑物的多负载预测精度。 这些研究凸显了迁移学习在减少数据需求同时保持准确性方面的潜力,使先进的机器学习方法更容易为资源有限的地区所使用。
与此同时,地理多样性给泛化带来了额外的挑战。 大多数峰值需求预测研究都是在北美、欧洲和澳大利亚等发达地区进行的,这些地区受益于长期可靠的数据集、完善的计量基础设施和相对稳定的电网运行。 相比之下,亚洲和非洲的发展中地区经常面临数据稀缺、报告标准不一致以及独特的电网基础设施限制先进预测技术的应用48,53,131,191。 在这些背景下,由于历史数据不足以及缺乏综合经济指标或实时传感器测量等基本解释变量,深度学习和混合模型的应用较少66,135,235。 此外,各国政策授权和监管框架的差异可能会阻碍系统性数据收集和开放数据共享,从而对复杂预测方法的更广泛应用构成挑战73,234。
解决这些限制需要跨建模、数据治理和部署的协调策略。 在建模方面,需要数据高效且稳健的方法,例如在可比区域借用力量的分层学习或迁移学习,并辅之以捕捉短暂且嘈杂的需求历史中的不确定性的概率公式。 在数据方面,匿名数据集共享、建立统一质量标准以及对当地从业者进行培训等举措可以提高覆盖范围、可比性和结果的可信度113,125。 最后,部署框架必须通过采用保护隐私的协作学习和尊重带宽、计算和数据共享规范限制的轻量级边缘实现来反映区域限制235。
情境感知且可解释的预测
峰值需求预测的一个核心挑战不仅是准确预测极端负载,而且还要确保预测透明、
基于上下文并可用于运营决策。 将结构化领域知识纳入机器学习模型可以带来巨大的好处,特别是在捕获难以仅从数据中学习的特定于上下文的异常和系统行为方面。 例如,计划维护、大型公共活动或需求响应激活可能会破坏常规负载模式,但这些很少被编码在历史数据集中。 米勒等人。 例如,241将宏观经济趋势和温度相关因素结合在一个基于模糊逻辑的系统中,以改进长期预测。 然而,将这些知识形式化为结构化输入非常耗时,并且需要跨学科协作,同时必须仔细设计模型以平衡领域驱动和数据驱动的信号。
除了结构化知识之外,多源数据流进一步增强了预测能力。 自然语言处理可以从政策公告、新闻和社交媒体中提取语义特征,这些特征表明需求变化,并已被证明可以改善日前预测242,243。 同样,计算机视觉可以捕获峰值的结构驱动因素,例如建筑密度、屋顶太阳能或电动汽车充电基础设施244,245,尽管其在峰值预测中的应用仍未得到探索。 在相关能源研究中,这些文本和视觉信号已被用来追踪政策变化、监测基础设施增长并检测突然的需求冲击。 可解释性确保丰富的输入转化为可操作的输出。 操作员必须了解导致超标风险的因素、干预激活的原因以及诊断不可预见峰值的方法。 最近的进展,例如 Jang 等人的 RAID 框架。 121,通过突出显示过去的峰值负载和温度等关键变量,展示了 SHAP 值的使用来提高深度学习模型的透明度。 然而,在性能和透明度之间实现最佳平衡仍然是一个挑战。 虽然 RAID 提高了可解释性,但它仍然依赖于利益相关者难以完全理解的复杂神经网络。 除了 RAID 之外,其他混合模型也显示出了前景 200。 这些方法旨在阐明高峰需求驱动因素(例如天气模式和历史负荷数据)之间的关系。 然而,它们的应用通常缺乏通用性,使得它们对于不同的能源预测场景不太实用。 在当前的峰值需求预测实践中,几种有前景的方法仍未得到充分探索。 例如,本地可解释的与模型无关的解释可以隔离单个预测背后的特定驱动因素,从而提供对模型行为的本地化洞察。 同样,神经加性模型学习每个特征响应曲线,可以对其进行审核或约束以反映合理的需求-驱动因素关系246,247。 通过明确揭示预测峰值如何随可控输入变化,这种本质上可解释的模型比单独的事后归因提供了更多可操作的见解。 为了应对这些挑战,未来的研究应侧重于开发可解释的框架,在不牺牲预测准确性的情况下提供一致且可操作的见解,以确保更广泛的可扩展性和利益相关者的信任。 此外,未来的工作还应侧重于综合管道,其中领域知识、文本和视觉信号与可解释的框架相结合,产生对异常情况稳健且对利益相关者透明的预测。
系统级架构
用于峰值需求预测的系统级架构越来越依赖去中心化和分布式智能,其中代理、边缘设备和区块链基础设施协作处理数据并实时生成预测。 这些方法超越了集中式管道,更好地反映了现代电力系统的异构性和自主性。 多代理系统是指由多个自主代理组成的去中心化架构,这些代理通过交互、协作或竞争来实现个人或集体目标。 多代理系统可以容纳来自智能电表、物联网设备和分布式资源的异构数据流,将峰值需求预测中的异构性转变为建模功能而不是限制。 传统的预测模型虽然对于模式识别有效,但往往无法捕捉由不同消费者的同步行为驱动的突发峰值。 相比之下,多代理系统可以代表具有决策能力和随机可变性的家庭、电器和分布式资源。 例如,阿里等人。 248演示了电动汽车电池管理器和负载代理如何在多代理系统中交互以优化调度并有助于调峰,而点对点需求响应系统在没有集中控制的情况下协调灵活负载249。 这些示例展示了多代理系统如何模拟导致峰值的局部负载行为和交互,从而深入了解需求激增背后的机制并增强可解释性。 此外,多代理系统框架支持关税变化、电动汽车普及率或需求响应计划的场景分析,并且可以生成合成数据或集成自适应学习代理,以将行为现实性与预测精度联系起来。
边缘计算通过使数据处理更接近源来增强实时处理,从而减少延迟并提高安全性。 有前景的技术包括基于聚类的预处理方法,例如边缘设备上的 K-Medoids,以降低数据维度 204,以及适应约束环境以进行高精度负载预测的神经网络 207。 然而,一些限制阻碍了大规模采用。 跨区域数据的多样性和数量对集成提出了挑战,而设备限制限制了模型的复杂性并在准确性和响应能力之间进行权衡164,199。 另一个困难是缺乏标准化协议,这使得跨基础设施的互操作性变得复杂206,234。 最近的工作表明,分布式数据库和流处理框架可以通过实现高频异构数据流的可扩展摄取和同步来补充边缘节点225,238。 在实践中,边缘设备最适合本地过滤和降维,而分布式系统则在更大范围内保持一致性。 有前途的方向包括模型压缩(修剪、量化、知识蒸馏)和自适应在线学习,这使得模型在边缘环境中保持高效、响应灵敏和隐私保护。
去中心化的点对点能源交易引入了不稳定的消费模式和新的负荷变量,显着扩大了预测框架的复杂性。 虽然将实时交易、共识机制和分布式账本数据集成到峰值负载模型中提供了大量的理论和实践机会,但当前的方法尚未全面解决这一问题。 现有的峰值需求预测模型经常忽视区块链驱动的需求变化。 传统的基于回归的方法,例如应用于区域系统的方法,侧重于静态历史变量,无法捕获去中心化交易80。 集成特征转换的混合深度学习模型通过聚类消费模式并动态适应区块链交易,在这种条件下提供更准确的预测73,185。 未来的研究可能会将区块链与边缘计算结合起来,其中交易数据的本地聚合可以减少与分布式账本同步之前的延迟。 将预测模型直接嵌入智能合约或共识机制中可以进一步提高自主性,允许预测随着新交易的发生而动态更新。 为了确保可扩展性和信任,可以结合轻量级隐私保护方法和联邦学习,同时预测输出的链上记录增强了可审计性、可重复性和透明度。 通过将可解释性和可追溯性嵌入到区块链工作流程中,去中心化系统可以支持产消者、公用事业和监管机构之间更加负责任和参与性的决策。 总之,多代理系统、边缘计算和基于区块链的交易可以被视为系统级预测的补充策略。 当结合起来时,它们支持结构分散、适应不断变化的运营条件并且市场互动透明的预测框架。 这种设计将预测能力直接与电网管理的运营要求以及最终用户在未来电力系统中的参与作用联系起来。
与先进的 DER 集成
虽然某些研究考察了可再生能源和存储的整合21,238,但仍然有必要对电动汽车、分布式发电和电池系统的建模进行全面分析。 这些灵活的资源作为动态元素,通过呈现各种多样化和可变的消费行为来增加预测的复杂性22,205。 此外,现代分布式能源需要整合各种数据源,例如智能电表读数、可再生能源发电输出和电动汽车充电模式,增加了数据预处理和特征工程的复杂性150,225。 Waheed 和 Xu 207 以及 Heidrich 等人的研究。 125强调了处理和集成太阳能光伏系统和电池存储数据的困难,这对于精确的峰值需求预测至关重要。 此外,在从住宅到工业的各个应用级别部署分布式能源需要可扩展的预测模型,以适应不同的操作环境并确保分布式节点之间的数据一致性20,125。 可扩展性挑战在不同地理和基础设施环境的研究中得到了强调,例如智能电网系统207和工业实施149。 因此,未来的研究需要关注可扩展的框架,将数据融合与算法优化相结合,使电动汽车、分布式光伏和存储能够以集成的方式进行建模,并更可靠地捕捉它们对峰值需求的影响。
新兴趋势
先进的深度学习技术
基于 Transformer 的架构和注意力机制已成为捕获峰值需求预测中的远程依赖性和复杂时间模式的强大工具。 混合模型,例如 CNN-Transformer 组合 7 和双注意力 LSTM 编码器 156,展示了长期和多尺度需求预测的增强功能。 此外,越来越多地采用序列到序列模型155和混合CNN-RNN架构164来提取空间和时间特征,从而提高峰值需求的预测精度。 另一个值得注意的趋势是将概率预测方法与深度学习模型63相结合,以解决不确定性并提供更稳健的峰值负载预测,利用 cINN 125 等模型生成峰值负载的概率密度函数。 此外,轻量级深度学习架构的进步,包括模型修剪和高效神经网络变体(例如 GRU 38),对于在资源受限的边缘计算基础设施上部署实时预测模型非常重要。 通过优化可扩展性和效率的算法,这些技术能够无缝集成来自分布式能源和智能电表的异构数据,从而增强峰值需求预测系统的弹性和适应性20,235。
联邦和分布式学习
随着住宅智能电表数据等高分辨率负荷数据的可用性不断增加,数据隐私已成为峰值需求预测中的一个主要问题。 使用私有加密算法保护消费者数据是数字时代研究人员的一项重要任务250。 与电力数据传输、存储合规性、安全性和隐私保护相关的挑战继续阻碍数据的有效利用251。 此外,数据的大小和质量显着影响机器学习模型的训练质量。 然而,准确预测所需的相关数据通常分布在不同的组织中,每个组织所持有的数据都受到限制完全数据共享的隐私法的约束。 将所有数据聚合到集中的第三方数据库可以促进稳健预测模型的构建,但由于敏感信息的集中化,它引入了重大的安全风险252。
联邦学习等隐私保护策略提供了一种解决方案,允许对分散数据进行模型训练,而不需要集中存储原始数据151。 这种方法对于在遵守数据隐私、安全和监管要求的同时寻求跨多个公用事业或区域机构协作的电网运营商特别有利。 通过利用联邦学习,可以组合来自不同组织的不同数据源来构建准确的预测模型,而不会损害数据隐私。 这是通过现场训练本地模型并仅与中央服务器共享模型更新(而不是原始数据)来实现的,允许跨公用事业公司进行协作学习,同时保留机密性,确保遵守数据法规,并通过并行训练保持可扩展性。 因此,设计包含联邦学习等隐私保护技术的预测框架代表了改进峰值需求预测的一个有前途的未来研究方向253-255。
强化学习和自适应系统
通过强化学习 (RL) 进行动态决策,使模型能够根据不断变化的电网条件进行实时调整,为峰值需求预测提供了一种有前景的途径。 尽管仍处于起步阶段,但基于强化学习的方法可以潜在地增强预测系统的适应性和响应能力。 将进化算法与神经网络相结合的研究已经证明了开发更有效和适应性框架的基础性进步22,55。 这些研究强调了结合自适应优化技术的可行性,这对于管理峰值负载预测固有的复杂性和不确定性非常重要。
新兴趋势还强调自适应系统超越传统机器学习模型的集成。 将集成学习与自适应特征选择相结合的混合模型20,238在研究中越来越受到关注,在预测中提供了更高的鲁棒性和灵活性。 此外,在自适应框架中使用异常检测方法21,149允许模型识别和响应不规则的消费模式,进一步提高预测的准确性。 随着研究的进展,预计强化学习与这些自适应方法的融合将促进更具弹性和更高效的峰值需求预测系统,能够利用实时数据并适应动态能源景观64。 此外,图神经网络因其对电网拓扑和空间关系进行建模的能力而受到越来越多的探索。 通过将变电站、馈线和消费者视为图中的节点,图神经网络可以捕获影响峰值负载传播的空间依赖性和互连模式。 虽然它们在峰值需求预测中的应用仍处于起步阶段,但最近对一般负载预测的研究256,257表明图神经网络有望实现局部预测,特别是在分布式网格环境中。
与智能电网技术集成
物联网和实时数据,包括智能仪表读数和传感器网络,大大提高了预测的响应能力204,207。 一种最佳策略是部署基于边缘的预处理和局部异常过滤,这可以减少数据传输负载并增强实时响应能力,同时保留关键负载特征。 虽然异构物联网系统之间的互操作性仍然是一个重大挑战,但解决这个问题对于实现可直接支持需求响应策略和电网运营的实时预测至关重要。 例如,智能电表数据可以分解家庭能源消耗,使模型能够识别特定的电器使用模式并更准确地预测峰值需求85,228。 此外,工业和商业建筑内传感器网络的集成有助于收集详细的运营数据,这些数据可用于增强 STPDF 20,117。 为了确保可扩展性,基于云或模块化的流架构允许实时数据管道水平扩展,同时保持低延迟。 此外,可以通过自动验证层来提高数据质量,这些验证层可以在模型摄取之前过滤掉传感器故障、通信错误和时间不一致。 这些进步不仅提高了预测精度,而且支持太阳能光伏和电池存储系统等分布式能源的集成,从而培育更具弹性和可持续的能源网络21,64。
可持续性和复原力重点
气候适应正在日益影响峰值需求预测的目标和方法,特别是在热浪或严重风暴等极端事件的建模中29,48。 结合概率方法或极值理论的模型可以更好地洞察风险和系统弹性。 通过捕获负荷分布的尾部行为,这些方法使预报员能够量化不确定性,并为低概率、高影响的事件做好准备,这些事件预计在气候变化情景下会增加。 随着电力系统采用更大比例的可再生能源,这些方法还为有关能源存储和分配的运营决策提供信息,即使在气候引起的供需波动下也能确保电网稳定性21,207。 最近的研究表明,通过将概率预测框架与政策导向变量相结合,例如 DSM 参与和可再生能源渗透率,人们越来越重视可持续性42,66。 通过模拟不同的政策或技术采用场景,电网运营商可以评估可能的弹性措施,并在高风险时期发生之前识别它们125。 这些方法可以通过模拟不同的外部场景(例如政策变化或环境条件)如何影响系统性能来支持自适应规划,从而为灵活资源部署的战略决策提供信息。
此外,多分辨率模型可以捕捉局部天气影响和更广泛的系统趋势,提供对电网脆弱性和资源充足性的全面见解199,238。 此外,多视野框架正在获得关注,因为它们解决了短期、中期和长期规划视野中重叠的预测需求8,225。 这些综合模型集成了每日、每周甚至每年的预测,为调度、运营控制和战略投资决策提供统一的平台157,207。 为了进一步增强气候适应能力,预测框架应发展为将概率预测与基于情景的规划工具联系起来的综合平台。 这使得系统运营商能够评估运行可靠性、存储部署和减排目标之间的权衡。 这些以可持续发展为重点的努力不仅提高了正常条件下预测的准确性,而且还增强了电网抵御极端天气事件和从极端天气事件中恢复的能力,使峰值需求预测与更广泛的绿色能源目标和气候适应策略保持一致52,131。
结论
此外,多分辨率模型可以捕捉局部天气影响和更广泛的系统趋势,提供对电网脆弱性和资源充足性的全面见解199,238。 此外,多视野框架正在获得关注,因为它们解决了短期、中期和长期规划视野中重叠的预测需求8,225。 这些综合模型集成了每日、每周甚至每年的预测,为调度、运营控制和战略投资决策提供统一的平台157,207。 为了进一步增强气候适应能力,预测框架应发展为将概率预测与基于情景的规划工具联系起来的综合平台。 这使得系统运营商能够评估运行可靠性、存储部署和减排目标之间的权衡。 这些以可持续发展为重点的努力不仅提高了正常条件下预测的准确性,而且还增强了电网抵御极端天气事件和从极端天气事件中恢复的能力,使峰值需求预测与更广泛的绿色能源目标和气候适应策略保持一致52,131。 对 186 项研究的回顾追踪了峰值需求预测从统计基线到机器学习和混合方法的进展,重点关注在实践中提高预测性能的要素。 它汇总了已发表的证据,不包括新的案例研究、专有方法或访谈。 这些对于跟踪特定实用程序中的组织流程和部署详细信息的未来工作非常有价值。 为了在不收集新数据的情况下保留上下文的细微差别,我们根据预测范围、地理规模和数据制度对综合进行分层,并报告跨研究集群的一致和分歧领域。 因此,我们的结论受到文献基础的限制,并被框架为跨方法、视野和区域重复出现的模式。 统计模型继续发挥核心作用,因为它们使趋势和季节性变得明确并提供透明的基准。 机器学习方法增加了捕捉非线性效应和相互作用的能力,当数据经过精心策划和严格验证时,这些效应和相互作用会推动峰值。 预测输出还需要超越单一峰值,因为持续时间和可变性决定了具有高可再生和分布式资源的系统的储备、爬坡和灵活性。 方法的选择取决于操作任务。 短期峰值预测受益于顺序混合,其中去噪或分解准备信号,非线性学习器捕获每小时或每小时范围内的残余峰值。 馈线和区域稳定性任务由并行混合系统支持,该混合系统结合了跨位置的互补错误模式,同时保留了局部变异性。 长期规划需要基于物理的设计,其中包含容量裕度、需求响应约束和关税规则,以便在政策和网络限制下,多年峰值风险仍然可行。 机器学习扩展了预测工具包,但其在高峰事件中的使用面临着明显的局限性,这些局限性仍有待未来的研究。 极端情况很少见,这使得泛化变得困难,并增加了复杂混合体中过度拟合的可能性。 智能仪表和进料器数据通常包含间隙、噪声和错位,除非进行适当清理,否则可能会掩盖峰形和时序。 当预测必须根据新的天气和分布式能源信号不断更新时,实时应用程序会受到延迟和计算负载的限制。 透明度也仍然参差不齐。 事后解释提供了部分见解,但运营商和监管机构需要以峰值为中心的理由,以确定给定提前期内超额风险的驱动因素,并阐明不确定性如何影响储备采购或需求响应等决策。
根据这些观察,可以概述未来研究和实践的重点路线图。 有四个优先事项突出。 首先,方法必须通过解决数据差距、噪声和罕见的极端事件而变得更加稳健,并得到量化不确定性的概率预测的支持。 其次,需要通过将峰值风险归因于特定驱动因素并使用本质上可解释的组件来加强可解释性。 第三,应提高可扩展性,例如通过边缘预处理、质量门和联合学习,使高频数据可用而不损害隐私或及时性。 最后,评估实践必须标准化,在缺失数据下进行压力测试,并针对历史极端情况进行回溯测试,跨视野和区域保持一致。 与十年前相比,峰值需求预测现在拥有更广泛的工具集,但其价值取决于方法与运营决策的协调程度。 当混合策略与范围和规模相匹配时,当输出捕获持续时间和可变性时,当峰值风险的不确定性被量化时,当解释根据操作员的需求定制时,机器学习方法可以提高准确性和可靠性,同时仍然对系统操作员、规划者和监管者可用。