写在文章开头
这篇文章原本是关于软中断的讲解,本着知识的关联性,笔者基于这篇文章拓展补充的网卡接收数据的完整流程以保证读者可以对于网络传输流程有一个直观的认知。
我是 SharkChili ,Java 开发者,Java Guide 开源项目维护者。欢迎关注我的公众号:写代码的SharkChili ,也欢迎您了解我的开源项目 mini-redis:github.com/shark-ctrl/...
为方便与读者交流,现已创建读者群。关注上方公众号获取我的联系方式,添加时备注加群即可加入。
网卡获取数据包
网络数据本质上是通过物理介质(如RJ-45网线接口)进行传输的,这意味着网卡收到的二进制数据通过电信号进行传输,这就存在很多不可抗力因素,例如二进制数据包的1变成0或者0变成1,所以网络数据包就必须经过完整性校验,这也就是为什么网络数据包的后面会有一个帧校验序列FCS,即网络数据包的完整性就是通过CRC算法重新计算并与FCS序列比对一致性以确定是否因为波动等因素使其完整性受到影响。
完整性校验后,网卡取出最外层的以太网帧格式,比对数据包的目的mac地址和自己的mac地址是否一致,若一致或者是广播包则向上层协议栈传递,反之直接丢弃:

net-base-4.drawio
DMA数据传输
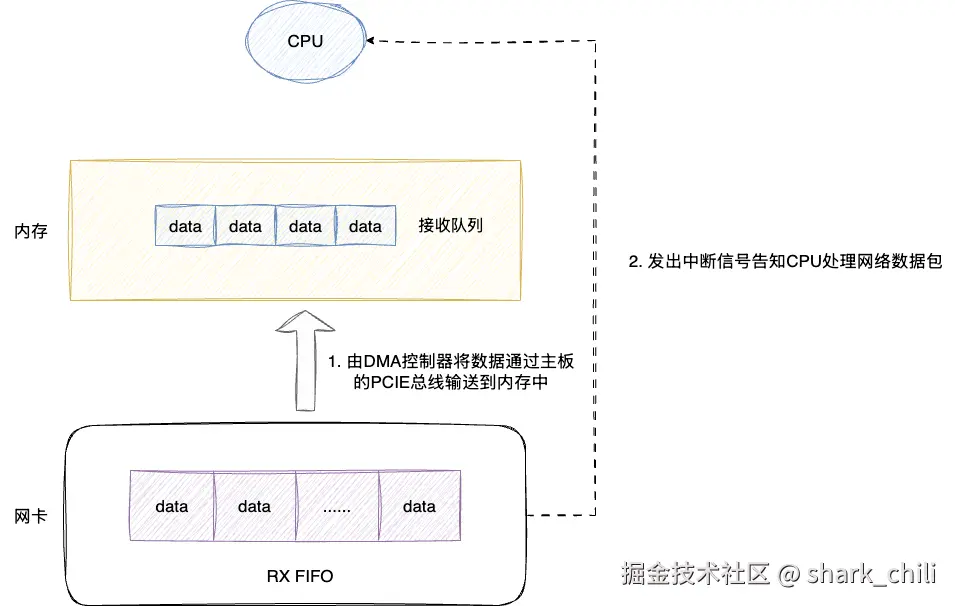
随后,网卡会将相应的网络数据包存入自己的RX FIFO缓冲队列,然后网卡驱动程序通知DMA(Direct Memory Access)控制器,DMA控制器会直接将数据从网卡的PCIE总线缓冲区批量拷贝到内存中的接收队列中,然后网卡发送中断信号告知CPU数据已就位,而这个硬件发起的中断信号的过程就叫做硬中断。
对此可能很多读者会有疑问,为什么不让CPU全程参与网络数据包的拷贝呢?原因如下:
- CPU处理速度远高于网络数据到达速度,如果CPU直接参与每个数据包的拷贝会浪费大量CPU资源
- CPU除了网络IO以外,还有很多其他运算任务需要处理,不能因为网络数据包拷贝而长期占用CPU资源
net-base-5.drawio
软中断响应
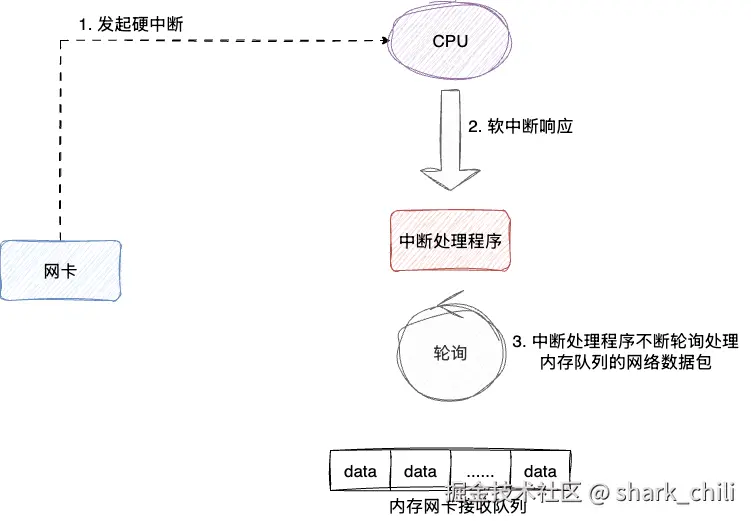
在高并发、海量网络数据处理的场景下,如果每个网络数据包都触发硬中断,CPU会因为频繁处理中断而严重影响系统性能。为了解决这个问题,Linux采用了NAPI(New Application Program Interface)机制,整体思路为:
- 网卡发起硬中断(但此时只处理紧急任务,不进行大量数据包处理)
- CPU触发软中断响应,暂时关闭网卡的硬中断
- 软中断处理函数调用网卡驱动进行轮询收包(批量处理数据包)
- 当数据包处理完毕或达到一定数量后,重新开启硬中断
通过这种中断与轮询相结合的解决方案,既避免了频繁中断的开销,也能高效地处理网络数据包。处理完的数据包会继续在网络协议栈中流转,通过网络层、传输层解析后,根据端口号送到对应的应用程序上。
net-base-6.drawio
系统中有哪些中断
查看硬中断
bash
cat /proc/interrupts查看软中断
bash
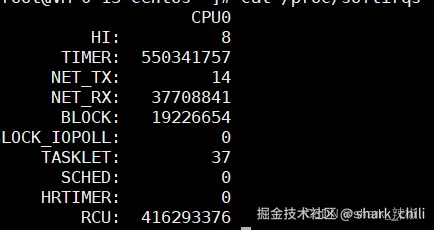
cat /proc/softirqs就以笔者为例,可以看到在系统中软中断对应中断次数统计如下,第一列对应的中断类型分别是:
NET_RX表示网络接收中断NET_TX表示网络发送中断TIMER表示定时器中断RCU表示 RCU(Read-Copy-Update)同步中断SCHED表示内核调度中断
在这里插入图片描述
当然,我们也可以通过来看看软中断的实时变化速率
bash
watch -d cat /proc/softirqs实际上,软中断的处理在现代Linux内核中是交由专门的内核线程处理的(这种机制称为ksoftirqd),我们可以通过以下命令查看
perl
ps aux |grep softirq如下图所示,对于多核系统,每个CPU核心都有一个对应的软中断处理线程,命名格式为[ksoftirqd/N](N为CPU编号)

在这里插入图片描述
网络数据包处理优化机制
现代操作系统和网卡为了提高网络性能,实现了很多优化机制:
RPS (Receive Packet Steering)
RPS是一种软件层面的负载均衡技术,它将网络数据包分发到不同的CPU核心上进行处理,以充分利用多核性能。RPS通过计算数据包的一致性哈希值来决定由哪个CPU核心处理,确保同一连接的数据包总是被同一个CPU核心处理。
RSS (Receive Side Scaling)
RSS是网卡硬件支持的负载均衡技术,它通过多个接收队列将网络数据包分配到不同的CPU核心上进行处理。与RPS不同,RSS由网卡硬件直接完成数据包的分发。
RFS (Receive Flow Steering)
RFS是对RPS的增强,它根据应用程序的CPU亲和性将数据包定向到处理该数据的CPU核心上,减少缓存未命中的情况,提高处理效率。
GRO (Generic Receive Offload)
GRO是NAPI机制中的一种优化技术,它允许网卡驱动程序合并多个相同流向的数据包(例如TCP流),减少协议栈的处理次数,提高吞吐量。
这些优化机制在高并发网络场景下对系统性能有着重要影响。
协议栈处理
当数据包通过DMA传输到内存后,它会进入内核的网络协议栈进行处理:
- 链路层处理:解析以太网帧头,确认目标MAC地址
- 网络层处理:根据帧类型字段,将数据传递给IP层进行路由判断
- 传输层处理:根据协议类型(TCP/UDP),传递给相应的传输层协议处理
- 应用层交付:根据端口号将数据传递给对应的应用程序
整个过程确保了从物理层接收到的应用层交付的完整数据流转。
(实践)用一个网络问题来实践定位软中段CPU使用率过高
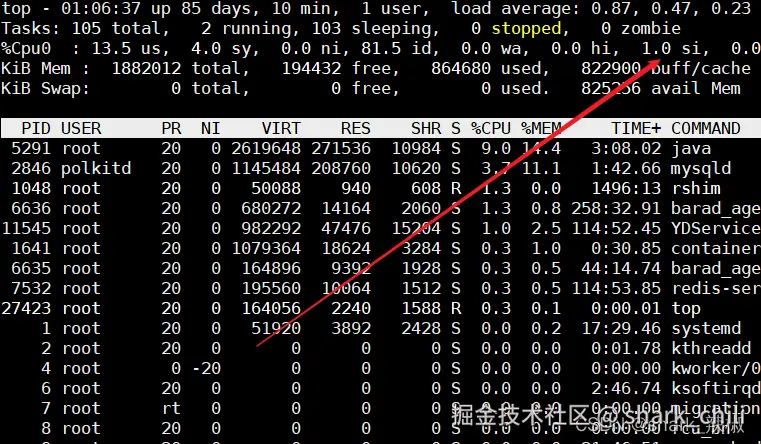
使用top命令查看cpu使用情况
按住1即可显示所有cpu核心的使用情况
css
top由于笔者服务还算稳定,用了压测工具还是百分之1,我们就假设他使用率很高
在这里插入图片描述
查看软中断速率
bash
watch -d cat /proc/softirqs由于笔者用压测工具,可以看到NET_RX的软中断次数增加了
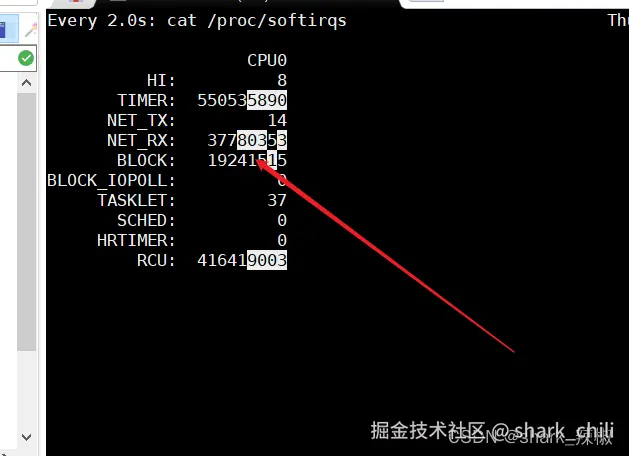
在这里插入图片描述
使用sar命令查看是哪个网卡被打爆了
sar -n DEV 1可以看出笔者eth 0每秒接受的数据不断增大
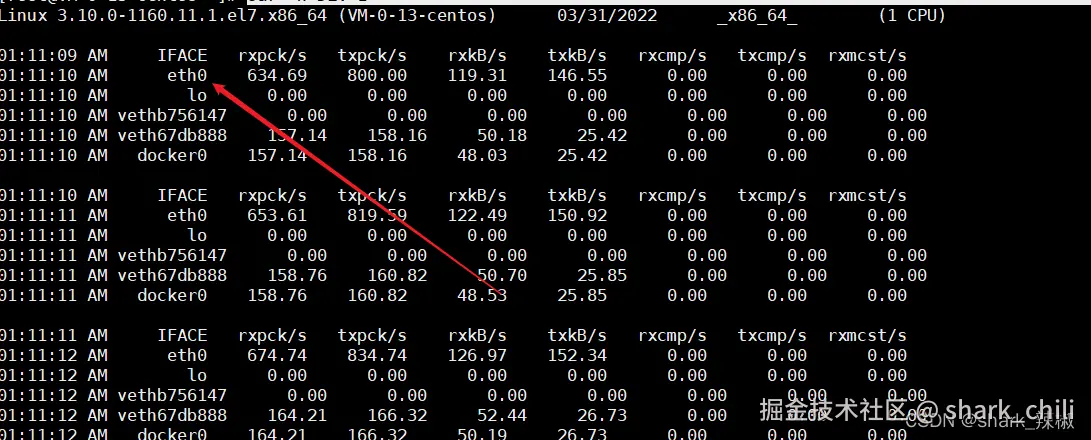
在这里插入图片描述
关于sar的使用可以参考这篇文章 使用 sar 查看网卡的流量
使用tcpdump查看具体源头
由于笔者使用jmeter压测http请求所以我们使用命令,可以看到笔者的公网地址疯狂在在请求,所以我们可以在服务器把这个ip拉黑即可解决问题
tcpdump -vnn关于tcpdump可以参照这篇文档 zhuanlan.zhihu.com/p/74812069
小结
本文详细讲述了网卡如何接收并校验网络数据包,通过DMA传输到内存并触发硬中断,随后CPU通过软中断响应并使用NAPI机制轮询处理网络数据包,最终将数据包传递到对应端口号的应用程序。同时,文章还提供了软中断问题的排查步骤:
- 服务器卡顿时,使用top命令查看CPU使用情况,关注si(softirq)指标
- 查看软中断速率(/proc/softirqs),重点关注NET_RX计数变化
- 使用sar命令查看哪个网卡流量异常
- 使用tcpdump抓包分析具体是哪些数据包导致的问题
我是 SharkChili ,Java 开发者,Java Guide 开源项目维护者。欢迎关注我的公众号:写代码的SharkChili ,也欢迎您了解我的开源项目 mini-redis:github.com/shark-ctrl/...。
为方便与读者交流,现已创建读者群。关注上方公众号获取我的联系方式,添加时备注加群即可加入。
参考
《趣话计算机底层技术》
本文使用 markdown.com.cn 排版