
🔥草莓熊Lotso: 个人主页
❄️个人专栏: 《C++知识分享》 《Linux 入门到实践:零基础也能懂》
✨生活是默默的坚持,毅力是永久的享受!
🎬 博主简介:

文章目录
- 前言:
- [一. 自动化测试前置:明确测试范围与测试用例设计](#一. 自动化测试前置:明确测试范围与测试用例设计)
- [二. 自动化测试脚本开发:Python+Selenium 实现](#二. 自动化测试脚本开发:Python+Selenium 实现)
-
- [2.1 通用工具类:common/Utils.py](#2.1 通用工具类:common/Utils.py)
- [2.2. 登录模块测试:cases/BlogLogin.py](#2.2. 登录模块测试:cases/BlogLogin.py)
- [2.3. 博客列表与详情页测试:cases/BlogList.py & BlogDetail.py](#2.3. 博客列表与详情页测试:cases/BlogList.py & BlogDetail.py)
-
- [2.3.1. 列表页测试(BlogList.py)](#2.3.1. 列表页测试(BlogList.py))
- [2.3.2. 详情页测试(BlogDetail.py)](#2.3.2. 详情页测试(BlogDetail.py))
- [2.4 用例执行入口:cases/RunCases.py](#2.4 用例执行入口:cases/RunCases.py)
- [三. 自动化测试收尾:测试报告整合与结果分析](#三. 自动化测试收尾:测试报告整合与结果分析)
- 结语:
前言:
在 C++ 后端开发场景中,Web 系统的功能稳定性直接影响用户体验,而自动化测试是保障系统质量、减少重复人力成本的关键手段。本文将以博客系统为实战载体,详细拆解 Web 自动化测试的完整实施流程 ------ 从测试用例设计,到 Python+Selenium 脚本开发,再到测试报告整合,带你掌握可落地的自动化测试方案
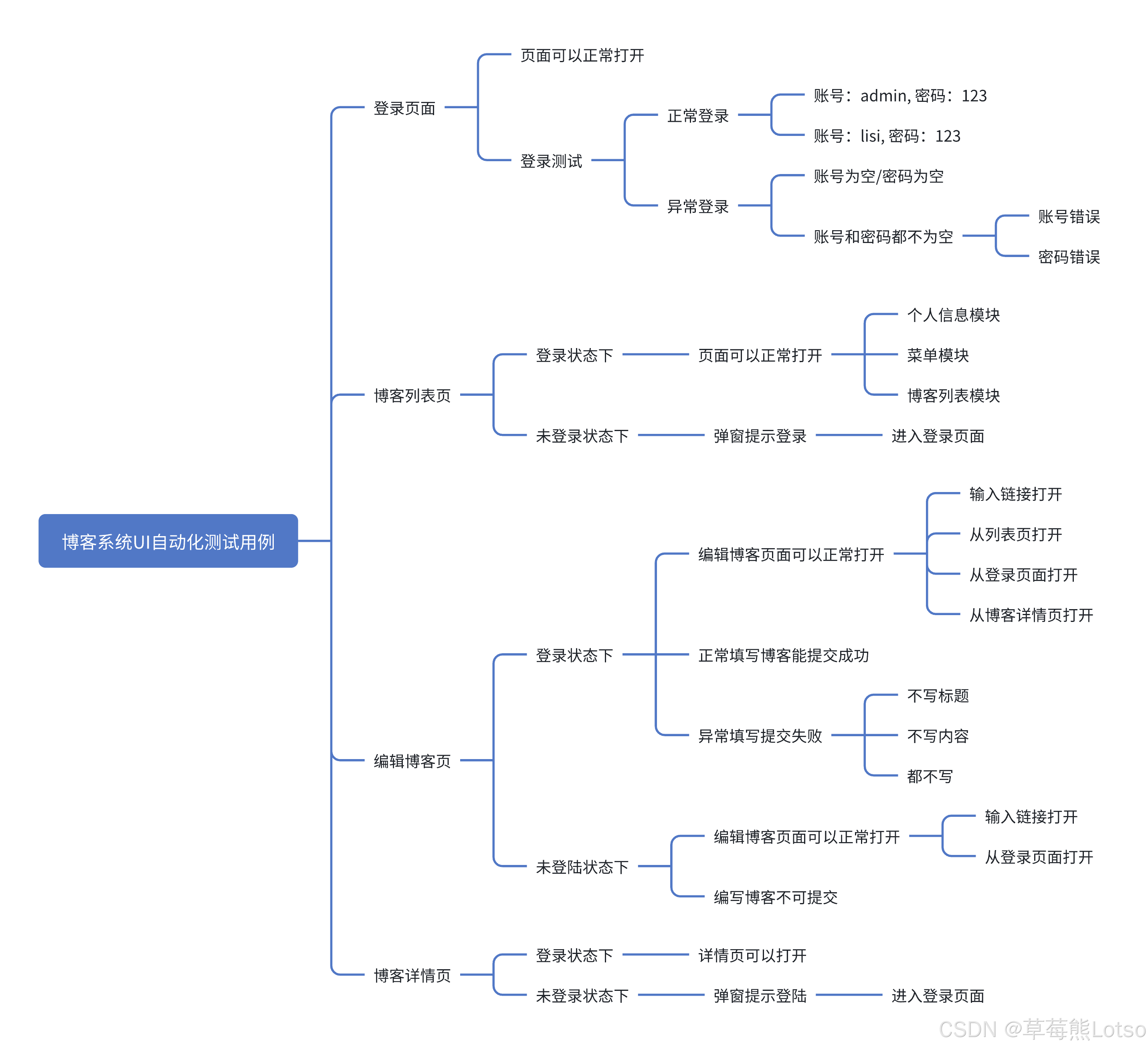
一. 自动化测试前置:明确测试范围与测试用例设计
自动化测试的核心是 "用代码验证重复场景",因此需先梳理博客系统的核心模块与关键场景,避免无意义的自动化覆盖。本次实战聚焦 登录、博客列表、博客详情、博客编辑 四大核心模块,按 "正常场景 + 异常场景" 设计用例,确保覆盖用户高频操作路径。
二. 自动化测试脚本开发:Python+Selenium 实现
本次脚本开发基于Python 3.x与Selenium 4.x------ 将驱动创建、截图等通用功能抽离到Utils.py,各模块测试用例单独编写(如BlogLogin.py、BlogList.py),确保代码可复用、易维护。
2.1 通用工具类:common/Utils.py
该文件负责创建 Chrome 驱动、生成测试截图(截图按 "日期 + 用例名" 命名,便于定位问题),避免重复代码。
python
# 导入日期时间处理模块,用于生成截图文件名中的日期时间
import datetime
# 导入文件路径处理模块,用于判断和创建截图目录
import os.path
# 导入系统相关模块,用于获取调用截图方法的函数名
import sys
# 导入selenium的webdriver模块,用于控制浏览器
from selenium import webdriver
# 导入Chrome驱动服务管理类,用于启动和管理ChromeDriver
from selenium.webdriver.chrome.service import Service
# 导入ChromeDriver自动管理工具,用于自动下载和匹配ChromeDriver版本
from webdriver_manager.chrome import ChromeDriverManager
# 定义驱动类,封装浏览器驱动的创建和截图功能
class Driver:
# 类属性,用于存储驱动对象
driver = ""
# 类的初始化方法,创建浏览器驱动实例
def __init__(self):
# 创建Chrome浏览器的配置选项对象
options = webdriver.ChromeOptions()
# 可选配置:设置页面加载策略为'eager'(仅等待DOM加载完成),默认注释
# options.page_load_strategy = 'eager'
# 初始化Chrome浏览器驱动:
# 通过ChromeDriverManager自动安装匹配的驱动,结合配置选项创建驱动对象
self.driver = webdriver.Chrome(
service=Service(ChromeDriverManager().install()),
options=options
)
# 定义截图方法,用于保存测试过程中的页面截图
def getScreenShot(self):
# 生成当前日期字符串(格式:年-月-日),作为截图目录名
dirname = datetime.datetime.now().strftime('%Y-%m-%d')
# 判断截图目录是否存在,不存在则创建
if not os.path.exists("../images/" + dirname):
os.mkdir("../images/" + dirname)
# 生成截图文件名:调用该方法的函数名 + 当前时间戳(精确到秒) + .png
filename = sys._getframe().f_back.f_code.co_name + "-" + datetime.datetime.now().strftime(
'%Y-%m-%d-%H%M%S') + ".png"
# 保存截图到指定目录
self.driver.save_screenshot(f'../images/{dirname}/' + filename)
# 创建Driver类的实例,作为全局驱动对象供测试用例使用
BlogDriver = Driver()2.2. 登录模块测试:cases/BlogLogin.py
聚焦登录模块的 "正常登录" 与 "异常登录" 场景,通过 CSS 选择器定位元素,用assert断言验证结果(如登录成功跳转、失败提示文案)
python
# 导入时间模块,用于添加等待时间(等待页面元素加载)
import time
# 从selenium导入By类,用于指定元素定位方式(如CSS选择器)
from selenium.webdriver.common.by import By
# 导入自定义的工具类中的全局驱动对象(已初始化的Chrome浏览器驱动)
from common.Utils import BlogDriver
# 定义博客登录测试类,封装登录相关的测试用例
class BlogLogin:
# 类属性:存储登录页URL和驱动对象(后续通过实例属性赋值)
url = ""
driver = ""
# 初始化方法:设置登录页URL、关联驱动并打开登录页
def __init__(self):
# 登录页面的URL地址(根据实际项目部署地址修改)
self.url = "http://192.168.47.135:8653/blog_system/blog_login.html"
# 关联全局驱动对象(复用已创建的浏览器实例)
self.driver = BlogDriver.driver
# 打开登录页面
self.driver.get(self.url)
# 测试正常登录场景(admin账号正确密码)
def loginSucTest(self):
# 等待2秒,确保页面元素加载完成(简单等待方式,实际可优化为显式等待)
time.sleep(2)
# 清空用户名输入框(避免残留数据影响测试)
self.driver.find_element(By.CSS_SELECTOR, "#username").clear()
# 清空密码输入框
self.driver.find_element(By.CSS_SELECTOR, "#password").clear()
# 输入正确的用户名(admin)
self.driver.find_element(By.CSS_SELECTOR, "#username").send_keys("admin")
# 输入正确的密码(123)
self.driver.find_element(By.CSS_SELECTOR, "#password").send_keys("123")
# 点击登录按钮
self.driver.find_element(By.CSS_SELECTOR, "#submit").click()
# 验证登录成功:通过定位列表页的用户头像元素(仅登录后可见)
# 若元素不存在,会抛出异常,提示登录失败
self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.left > div > img")
# 调用截图方法,保存登录成功的页面截图
BlogDriver.getScreenShot()
# 退回登录页,为后续测试用例(如失败登录)准备环境
self.driver.back()
# 测试登录失败场景(admin账号错误密码)
def loginFailTest(self):
# 清空用户名输入框
self.driver.find_element(By.CSS_SELECTOR, "#username").clear()
# 清空密码输入框
self.driver.find_element(By.CSS_SELECTOR, "#password").clear()
# 输入正确的用户名(admin)
self.driver.find_element(By.CSS_SELECTOR, "#username").send_keys("admin")
# 输入错误的密码(111)
self.driver.find_element(By.CSS_SELECTOR, "#password").send_keys("111")
# 点击登录按钮
self.driver.find_element(By.CSS_SELECTOR, "#submit").click()
# 预期的失败提示文本(与前端错误提示保持一致)
expect = "用户名或密码错误!"
# 实际获取的页面文本(通过body元素提取,需确保无其他干扰文本)
actual = self.driver.find_element(By.CSS_SELECTOR, "body").text
# 打印实际获取的文本,方便调试
print(actual)
# 调用截图方法,保存登录失败的页面截图
BlogDriver.getScreenShot()
# 断言:验证实际提示与预期一致,不一致则抛出异常
assert expect == actual
# 退回登录页,为下一次测试准备
self.driver.back()2.3. 博客列表与详情页测试:cases/BlogList.py & BlogDetail.py
2.3.1. 列表页测试(BlogList.py)
验证登录状态下的列表页元素完整性,以及 "点击文章进入详情页" 的功能正常性。
python
# 从selenium导入By类,用于指定元素定位方式(如CSS选择器)
from selenium.webdriver.common.by import By
# 导入自定义工具类中的全局驱动对象,复用已初始化的浏览器实例
from common.Utils import BlogDriver
# 定义博客列表页测试类,封装列表页相关的测试逻辑
class BlogList:
# 类属性:存储列表页URL和驱动对象(后续通过实例属性赋值)
url = ""
driver = ""
# 初始化方法:关联驱动、设置列表页URL并打开页面
def __init__(self):
# 关联全局驱动对象(与登录页共用同一浏览器实例)
self.driver = BlogDriver.driver
# 列表页的URL地址(根据实际项目部署地址修改)
self.url = "http://192.168.47.135:8653/blog_system/blog_list.html"
# 打开博客列表页
self.driver.get(self.url)
# 测试列表页功能(前提:需处于登录状态)
def ListTest(self):
# 验证登录状态:通过定位左侧用户头像元素(仅登录后可见)
# 若元素不存在,会抛出异常,说明未登录或登录状态失效
self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.left > div > img")
# 验证列表页第一篇博客链接存在(确保列表有内容可点击)
self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.right > div:nth-child(1) > a")
# 获取列表页所有博客文章元素(通过CSS选择器定位文章容器)
articles = self.driver.find_elements(By.CSS_SELECTOR, "body > div.container > div.right > div")
# 断言:验证列表页博客数量超过10篇(根据业务需求设定的数量阈值)
assert len(articles) > 10
# 操作:点击第一篇博客的链接,进入详情页
self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.right > div:nth-child(1) > a").click()
# 获取当前页面标题(用于验证跳转结果)
title = self.driver.title
# 断言:验证页面标题为"博客详情页",确认成功跳转至详情页
assert title == "博客详情页"
# 调用截图方法,保存列表页跳转详情页的结果截图
BlogDriver.getScreenShot()2.3.2. 详情页测试(BlogDetail.py)
验证详情页的核心元素(标题、日期、正文)是否正常显示。
python
# 从selenium导入By类,用于指定元素定位的方式(如CSS选择器)
from selenium.webdriver.common.by import By
# 导入自定义工具类中的全局驱动对象,复用已创建的浏览器实例
from common.Utils import BlogDriver
# 定义博客详情页测试类,封装详情页的验证逻辑
class BlogDetail:
# 类属性:存储详情页URL和驱动对象(后续通过实例属性赋值)
url = " "
driver = ""
# 初始化方法:设置详情页URL、关联驱动,并根据当前页面状态决定是否跳转
def __init__(self):
# 详情页的URL地址(指定blogId=15,测试特定博客的详情)
self.url = "http://192.168.47.135:8653/blog_system/blog_detail.html?blogId=15"
# 关联全局驱动对象(与列表页、登录页共用同一浏览器)
self.driver = BlogDriver.driver
# 获取当前页面的标题(用于判断是否从列表页跳转而来)
title = self.driver.title
# 逻辑判断:
# 如果当前页面不是列表页(说明未从列表页点击进入详情页),则手动跳转到详情页
# 目的:兼容直接访问详情页的场景,确保测试环境正确
if not title == "博客列表页":
self.driver.get(self.url)
# 验证详情页核心元素是否存在
def DetailCheck(self):
# 调用截图方法,保存详情页的页面状态
BlogDriver.getScreenShot()
# 验证详情页标题元素存在(通过CSS选择器定位h3标签)
self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.right > div > h3")
# 验证详情页发布日期元素存在(通过CSS选择器定位.date类)
self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.right > div > div.date")
# 验证详情页正文内容元素存在(通过CSS选择器定位id为content的元素)
self.driver.find_element(By.CSS_SELECTOR, "#content")2.4 用例执行入口:cases/RunCases.py
整合所有测试用例,按 "登录→列表页→详情页" 的顺序执行,避免依赖问题。
python
# 导入全局驱动对象(用于统一管理浏览器实例和最后关闭浏览器)
from common.Utils import BlogDriver
# 导入登录测试类(登录模块测试逻辑)
from tests import BlogLogin
# 导入博客列表页测试类(列表页功能测试逻辑)
from tests import BlogList
# 导入博客详情详情页测试类(详情页元素验证逻辑)
from tests import BlogDetail
# 主程序入口:当脚本直接运行时执行以下测试流程
if __name__ == "__main__":
# 1. 执行登录成功测试:
# 实例化BlogLogin类并调用loginSucTest方法,完成admin账号正确登录
BlogLogin.BlogLogin().loginSucTest()
# 2. 执行博客列表页测试:
# 实例化BlogList类并调用ListTest方法,验证登录状态下列表页功能(元素展示、跳转等)
BlogList.BlogList().ListTest()
# 3. 执行博客详情页测试:
# 实例化BlogDetail类并调用DetailCheck方法,验证详情页核心元素(标题、日期、正文)存在
BlogDetail.BlogDetail().DetailCheck()
# 4. 测试完成后关闭浏览器:
# 调用全局驱动的quit()方法,释放浏览器资源
BlogDriver.driver.quit()三. 自动化测试收尾:测试报告整合与结果分析
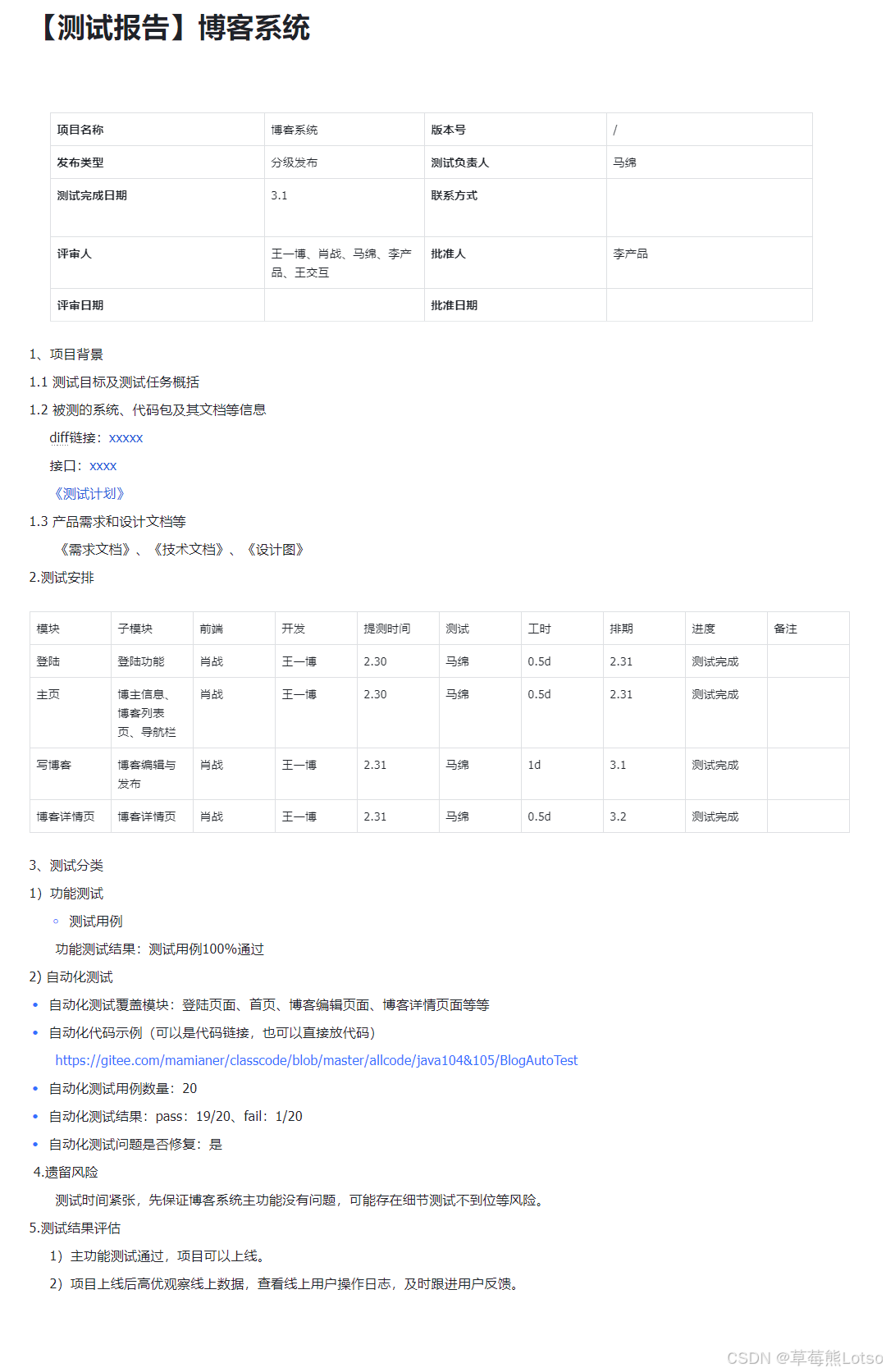
自动化测试的价值需通过 "可视化报告" 呈现 ,便于团队快速了解测试情况。以下为博客系统自动化测试报告模板。

测试报告模板:
结语:
html
🍓 我是草莓熊 Lotso!若这篇技术干货帮你打通了学习中的卡点:
👀 【关注】跟我一起深耕技术领域,从基础到进阶,见证每一次成长
❤️ 【点赞】让优质内容被更多人看见,让知识传递更有力量
⭐ 【收藏】把核心知识点、实战技巧存好,需要时直接查、随时用
💬 【评论】分享你的经验或疑问(比如曾踩过的技术坑?),一起交流避坑
🗳️ 【投票】用你的选择助力社区内容方向,告诉大家哪个技术点最该重点拆解
技术之路难免有困惑,但同行的人会让前进更有方向~愿我们都能在自己专注的领域里,一步步靠近心中的技术目标!结语:本次博客系统自动化测试实战,从用例设计到脚本串联,完整落地了 Web 自动化核心流程 ------ 用模块化封装减少重复工作,以贴合用户操作的链路保障测试有效性,靠截图与断言留存可追溯的测试依据。自动化测试的价值不止于替代手工,更在于用稳定逻辑持续守护系统质量。后续可结合框架优化、报告可视化等方向迭代,但 "贴合业务、解决实际问题" 始终是核心。希望这份实战能为你的 C++ Web 项目测试提供可复用的思路,助力高效保障项目质量。
✨把这些内容吃透超牛的!放松下吧✨ ʕ˘ᴥ˘ʔ づきらど
