一、RVC 介绍
Retrieval-based-Voice-Conversion-WebUI 是一个基于深度学习的声音转换框架,它通过检索技术实现源声音特征到训练集特征的转换,从而减少音调泄露问题,该项目提供了一个易于使用的Web界面,用户可以方便地进行声音模型的训练和实时声音转换。

二、安装指南
本文操作系统 Ubuntu 24.04
bash
git clone https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI.git
N卡驱动:575.64.03
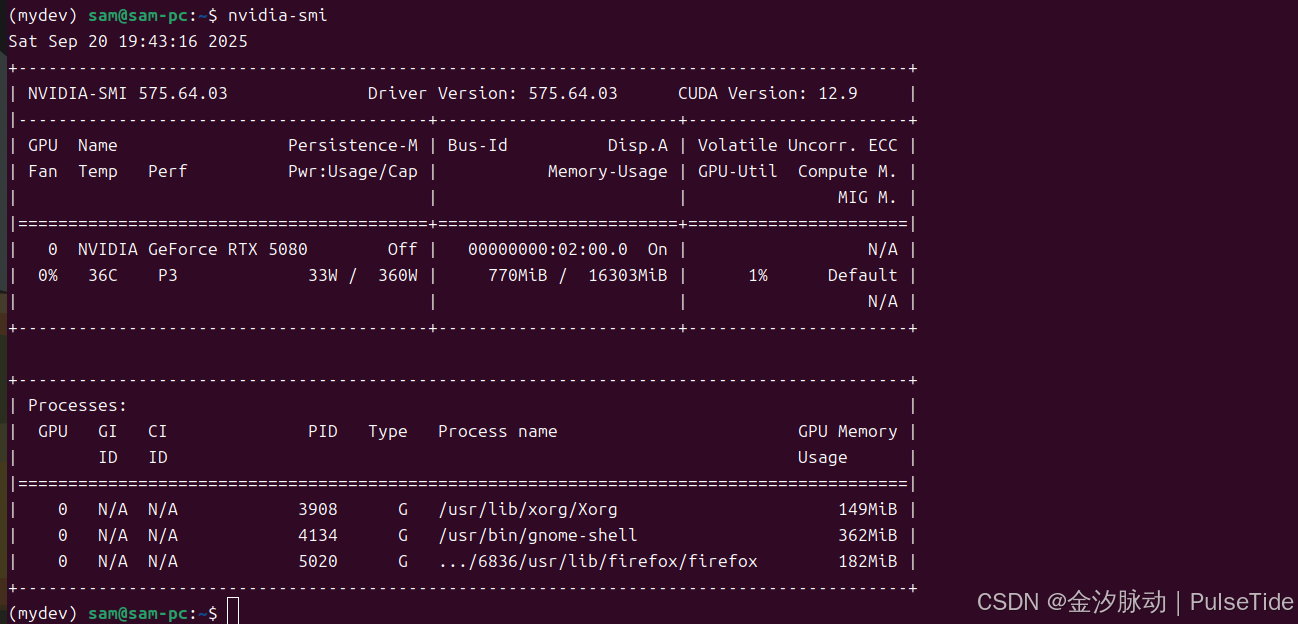
创建一个 python3.8 环境(环境要求:3.7-3.11):
bash
conda create -n rvc python=3.8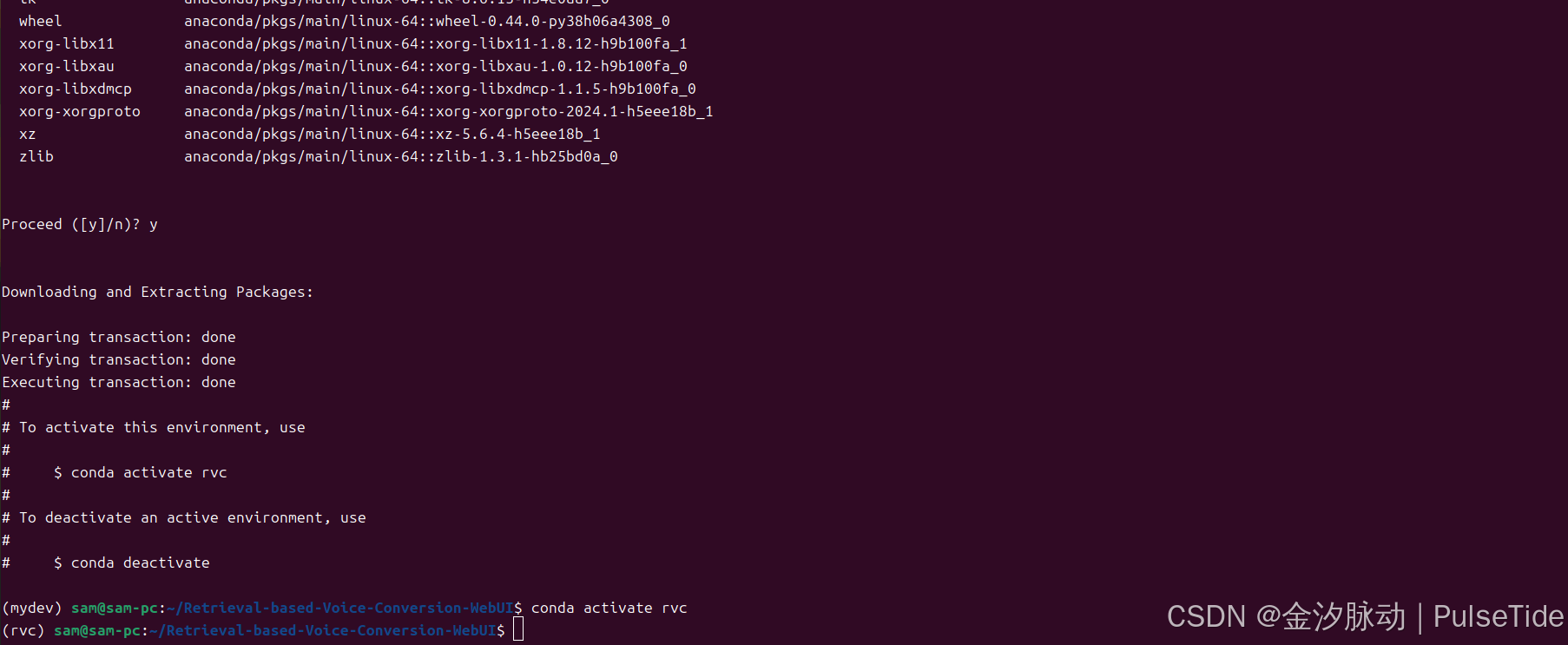
安装 torch 依赖:
bash
pip install torch torchvision torchaudio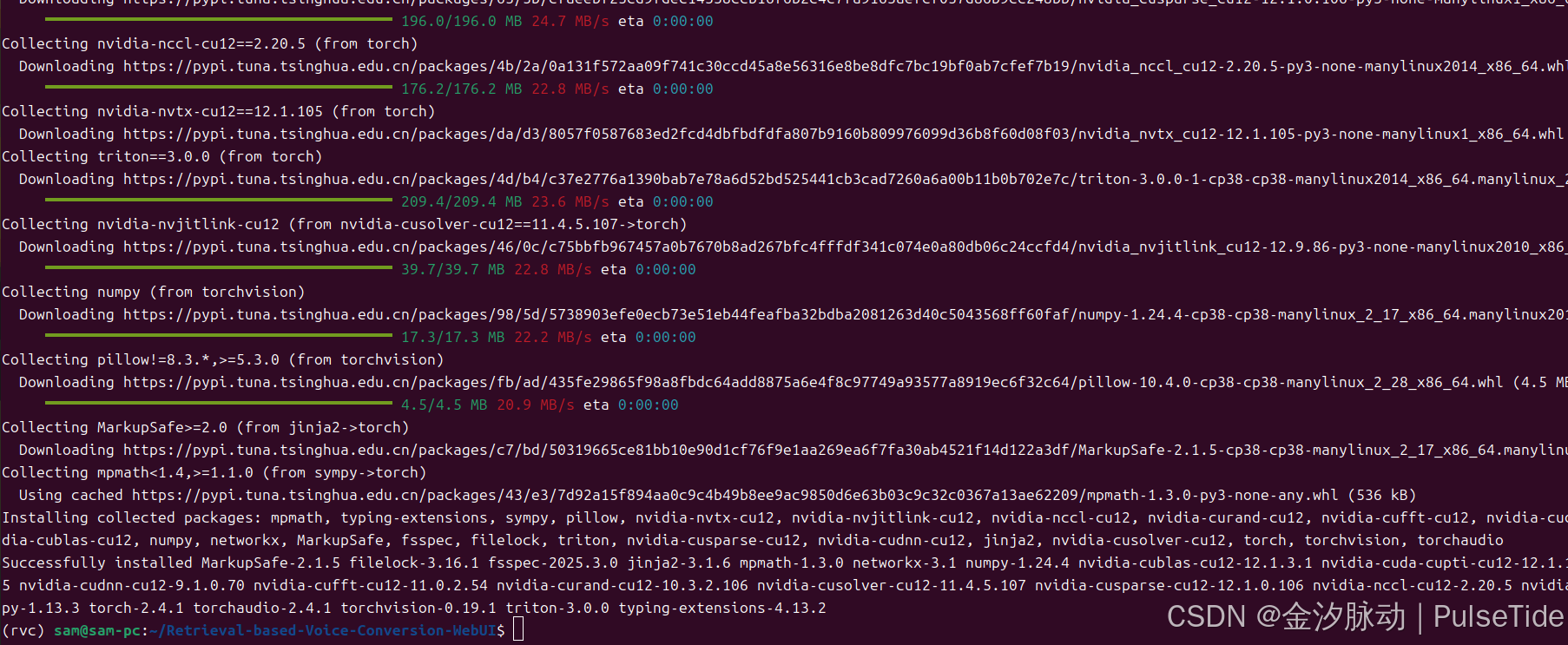
安装 N 卡依赖:
bash
# N卡依赖
pip install -r requirements.txt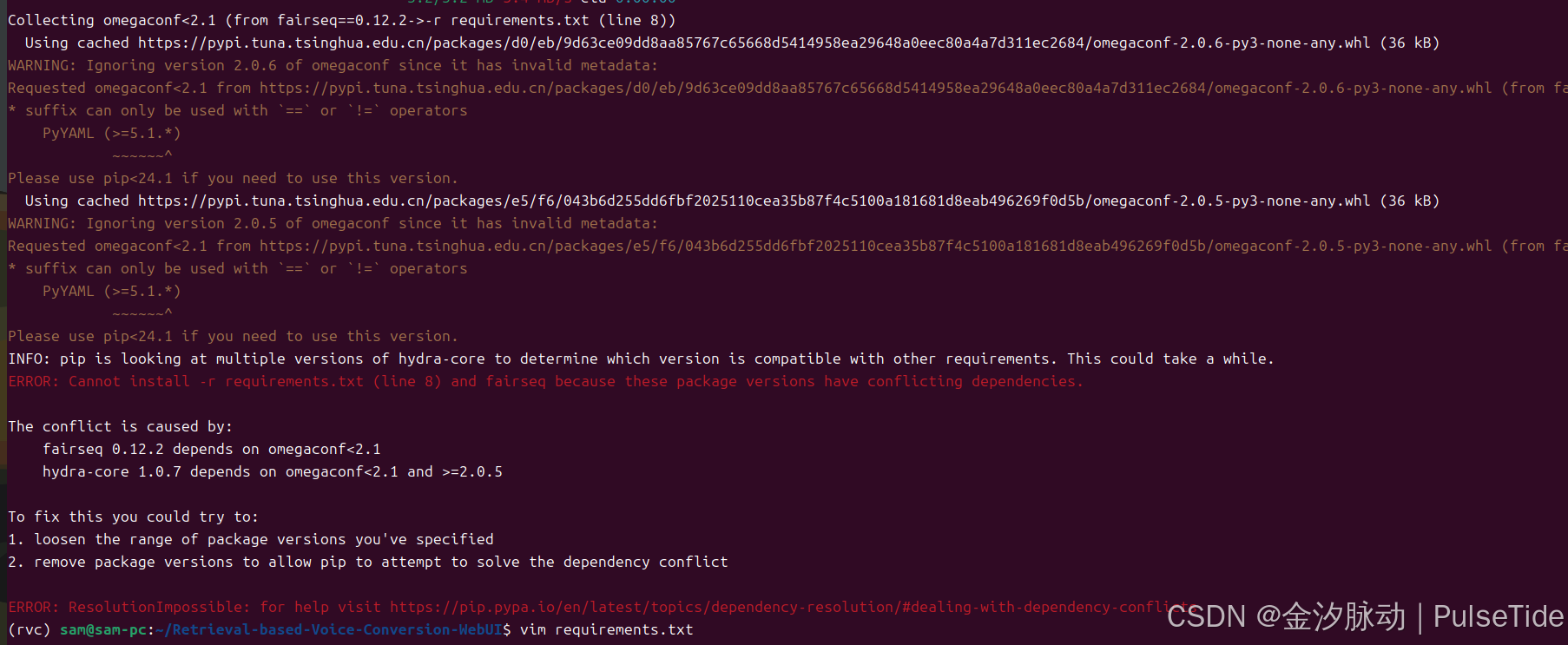
遇到报错:
ERROR: Cannot install -r requirements.txt (line 8) and fairseq because these package versions have conflicting dependencies.
The conflict is caused by:
fairseq 0.12.2 depends on omegaconf<2.1
hydra-core 1.0.7 depends on omegaconf<2.1 and >=2.0.5
To fix this you could try to:
1. loosen the range of package versions you've specified
2. remove package versions to allow pip to attempt to solve the dependency conflict依赖冲突,只需要去掉一个依赖的版本号即可(或降级pip工具亦可:pip install --upgrade pip==24.0):
安装 ffmpeg :
bash
sudo apt install ffmpeg
三、下载模型
仓库根目录下执行脚本(需要魔法):
bash
# 下载 assets
./tools/dlmodels.sh
如果下载超时,请注意脚本是从 https://huggingface.co/ 下载的文件,可以修改为 https://hf-mirror.com:
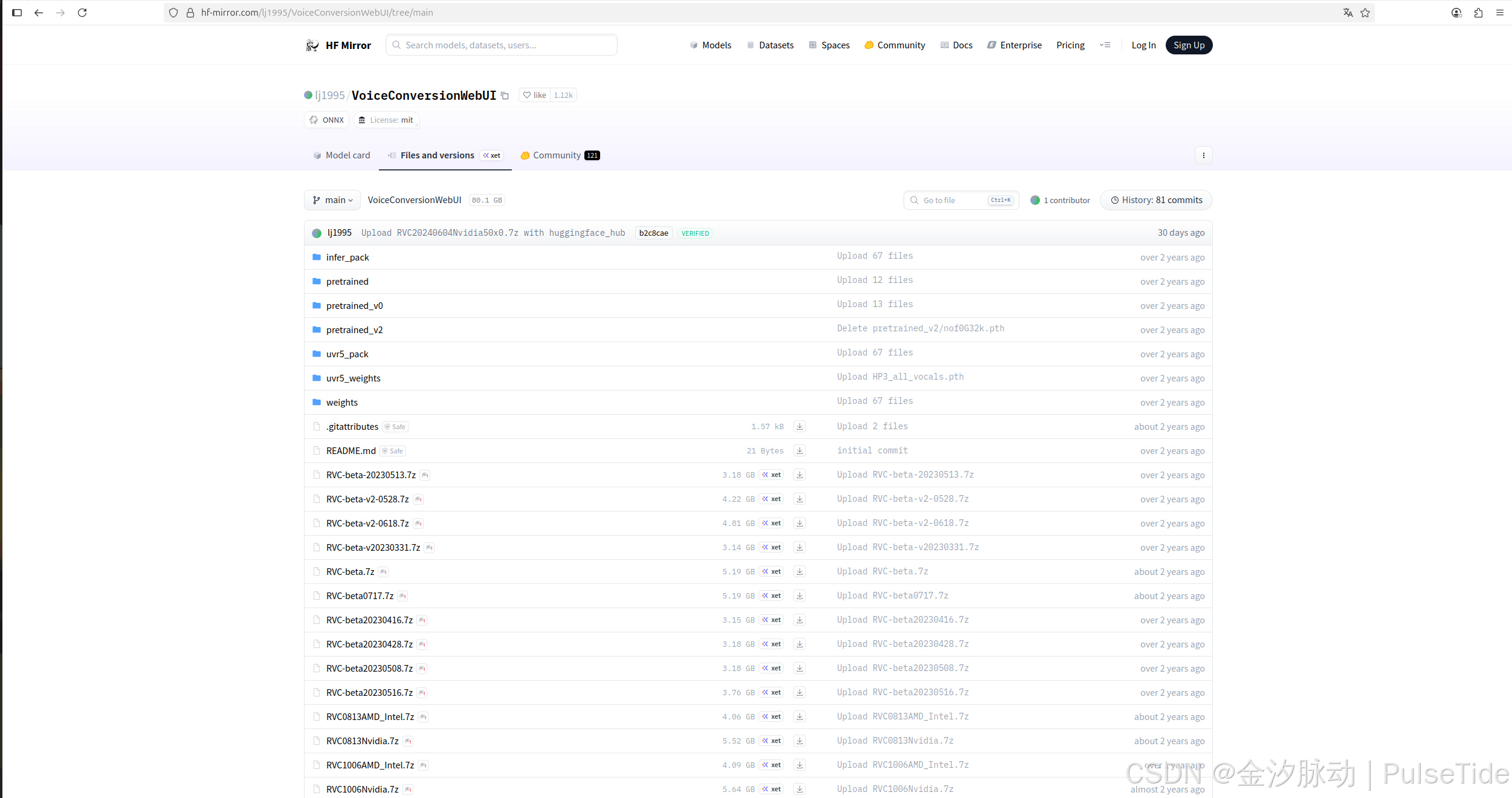
修改效果:
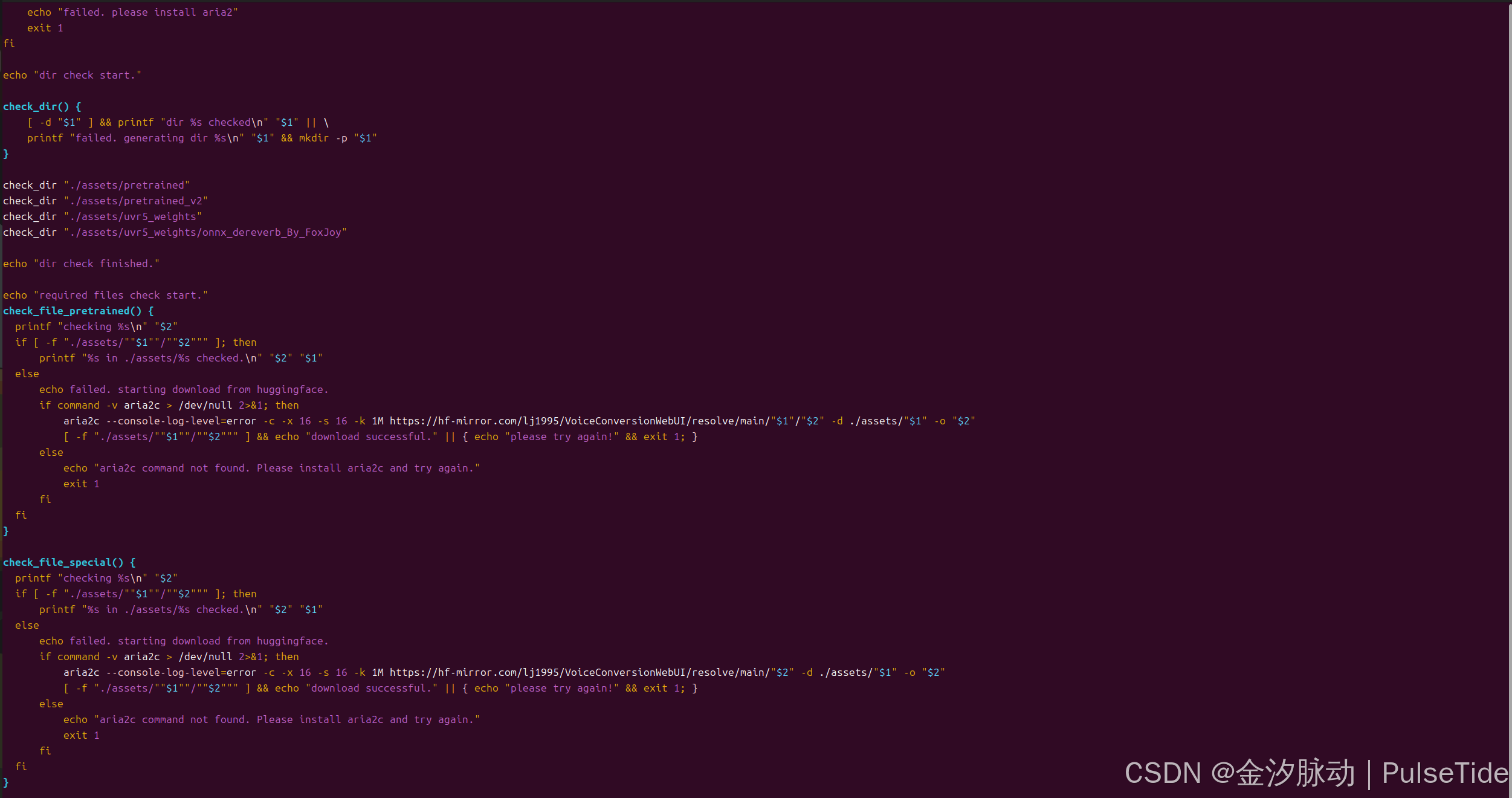
下载加速效果:
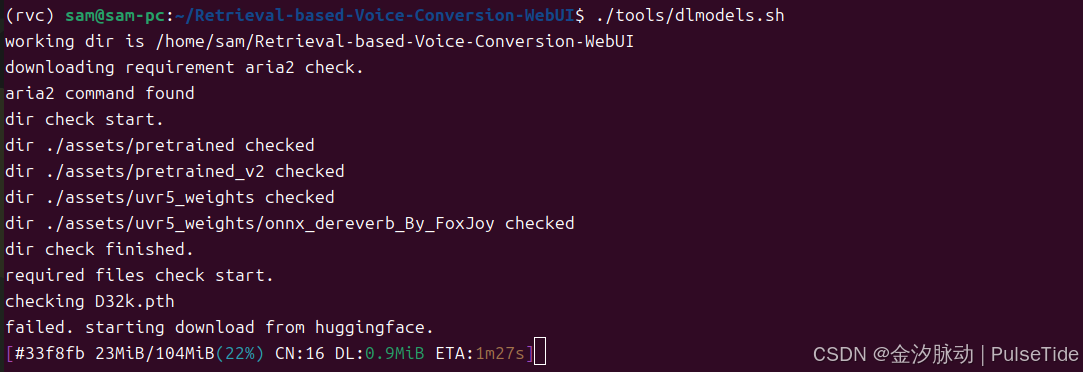
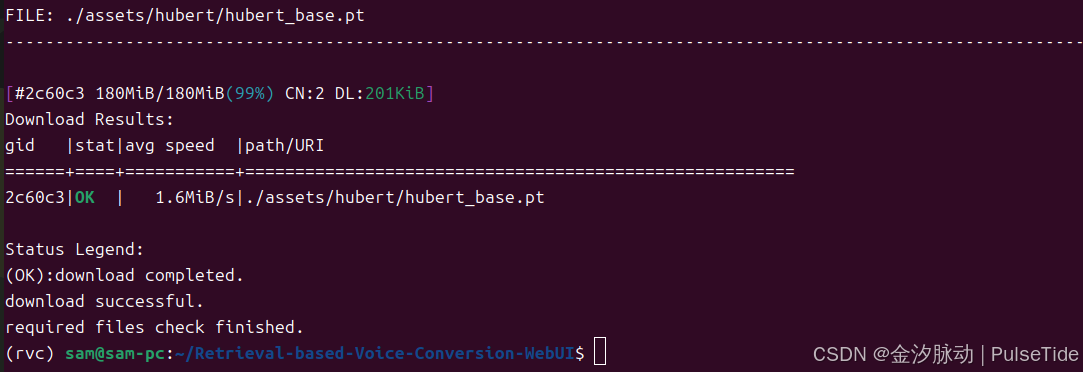
下载完成:
下载优化模型(可选):rmvpe.pt
bash
# (可选)下载 rmvpe.pt,放到 rvc 根目录
# wget https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.pt
wget https://hf-mirror.com/lj1995/VoiceConversionWebUI/blob/main/rmvpe.pt四、启动 UI
bash
# 启动
python infer-web.py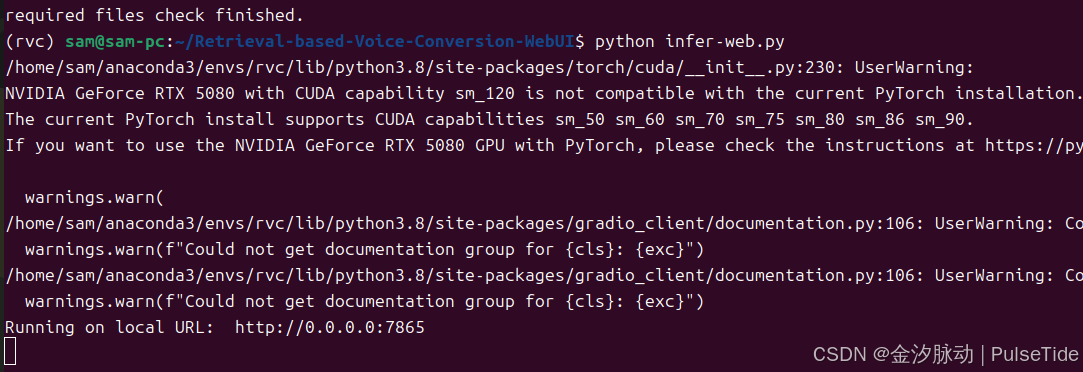
打开 URL 访问 UI :
http://localhost:7865/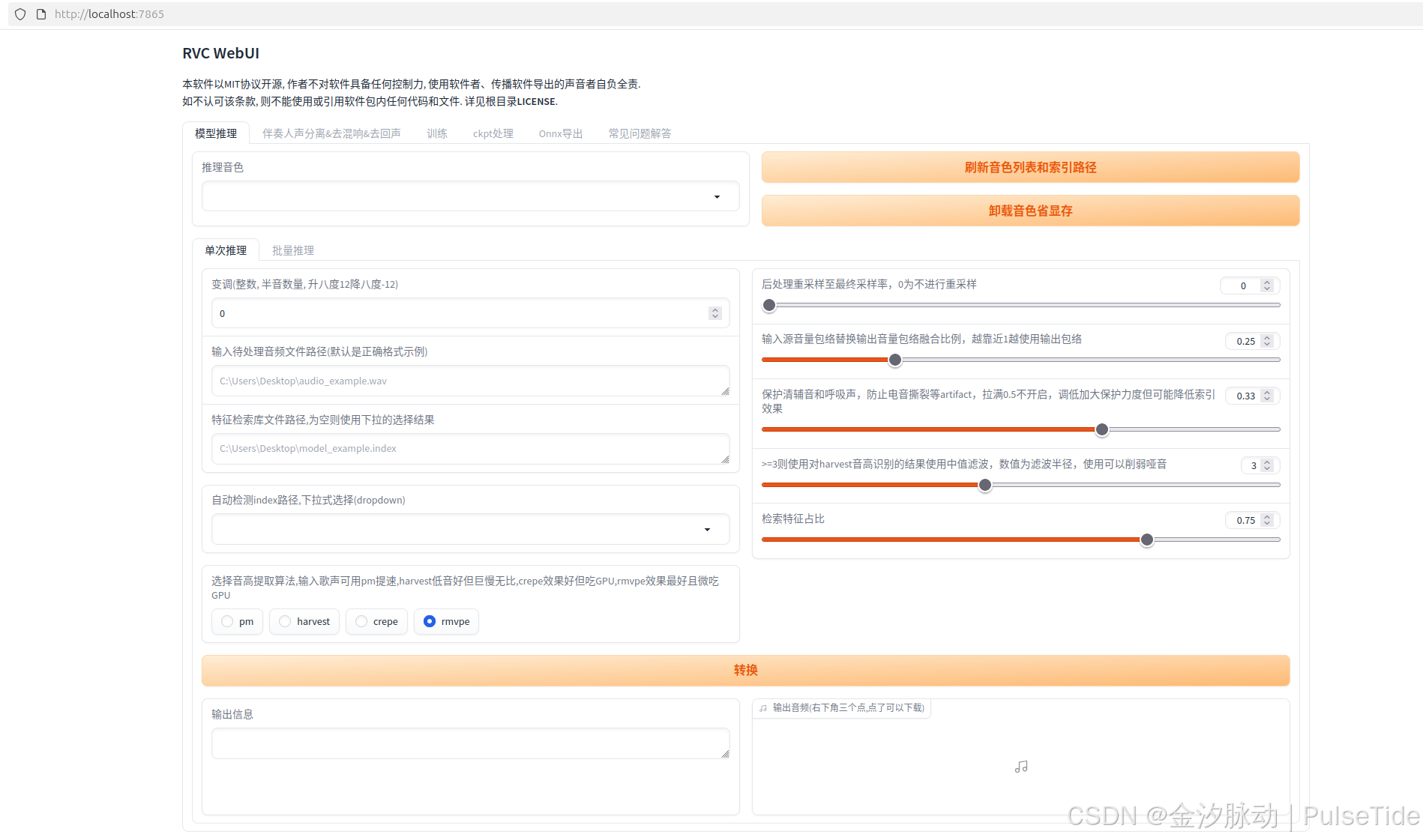
五、使用教程
1、推理音色训练
通过优质干声素材进行训练,我们可以提取特定音色特征并加以模拟,最终生成对应的音色包,在此过程中,适当调整参数可优化音色特征的提取效果。
举例:提取游戏角色或者动漫人物角色的说话音频,就可以进行该角色的音色训练,例如当前火爆的懒羊羊、猴哥、麦克阿瑟音色。
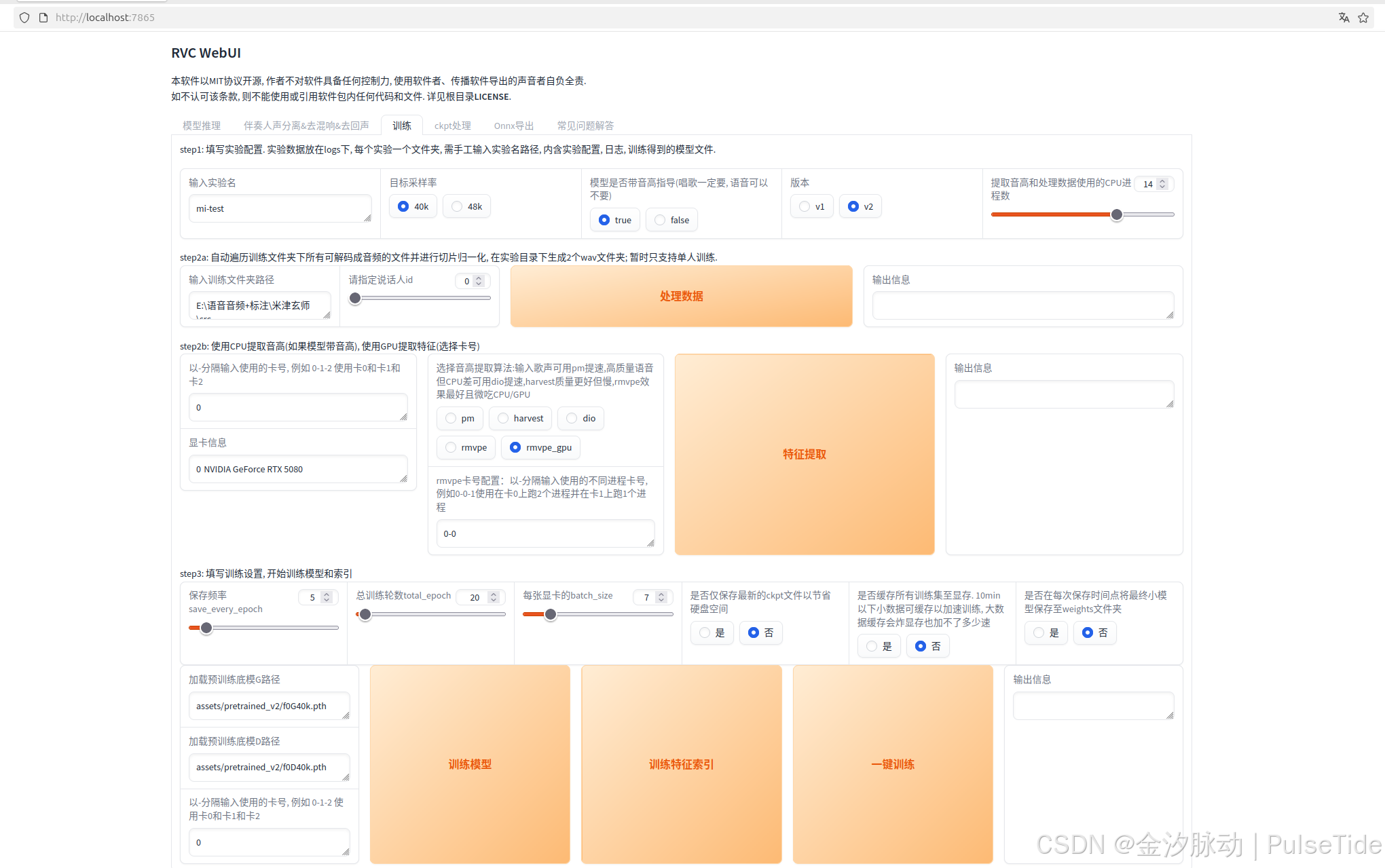
建议准备3-7分钟的优质干声素材,这个时长范围效果最佳,录制时长需控制在3-50分钟之间。从上往下按界面引导的step进行操作,注意点击"训练模型 "和"训练特征索引"!
界面参数说明:
- 实验名称:最终生成的音色包名称
- 目标采样率:干声素材采样率设置,默认40k效果良好,可根据性能需求调整
- 启用音高指导:歌唱类素材必须开启(true),其他类型可自由选择
- 模型版本:推荐使用稳定版V1,V2版本尚存部分问题
- CPU进程数:音高提取与数据处理使用的核心数,默认16,最低要求2个
- 训练素材路径:包含干声素材的文件夹路径(注意:单文件夹仅限单人音色素材)
- 显卡配置:自动检测本机显卡,多显卡可指定卡号
- 音高提取算法:
- pm:适合歌声,处理速度快
- dio:适合高质量语音,CPU占用低
- harvest:质量最优但速度较慢
- 保存频率:每n轮保存一次模型(推荐20轮)
- 训练总轮数:
- 基础设置:200轮(推荐)
- 优质素材:可降至50轮
- 上限:1000轮(注意可能过拟合)
- batch_size:默认自动适配显卡,可手动调整
- 模型保存选项:
- 仅保存最终模型:节省存储空间
- 按频率保存:保留中间结果
- 显存缓存:
- 小数据集(<10min):建议开启加速
- 大数据集:可能引发显存溢出
- 模型导出:建议开启"保存至weights文件夹"选项
训练结果(音色)文件夹:assets/weights 文件夹

利用这个音色包文件 pth 就可以进行音色推理了。

训练音色特征结果:logs 文件夹

训练报错:matplotlib 版本问题
File ".../infer/lib/train/utils.py", line 238, in plot_spectrogram_to_numpy
data = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8, sep="")
AttributeError: 'FigureCanvasAgg' object has no attribute 'tostring_rgb'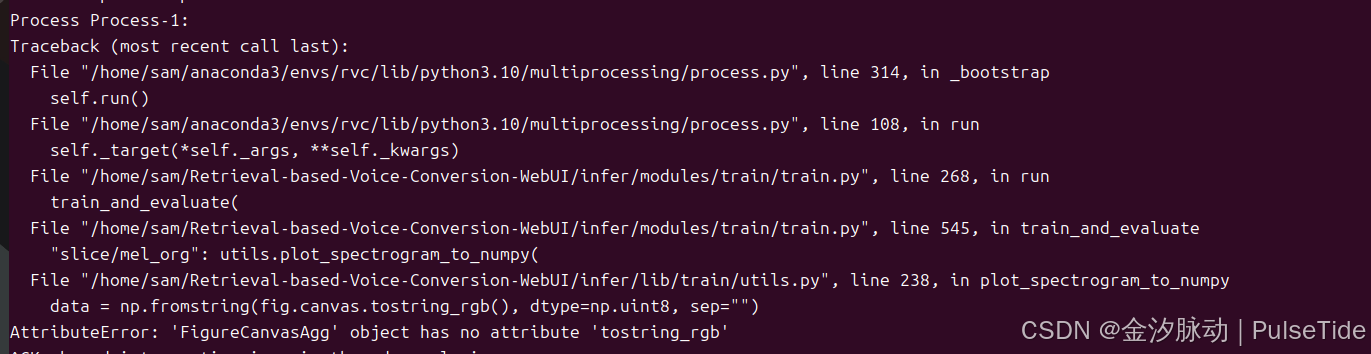
解决:matplotlib 降版本
bash
pip install matplotlib==3.5.3训练效果:
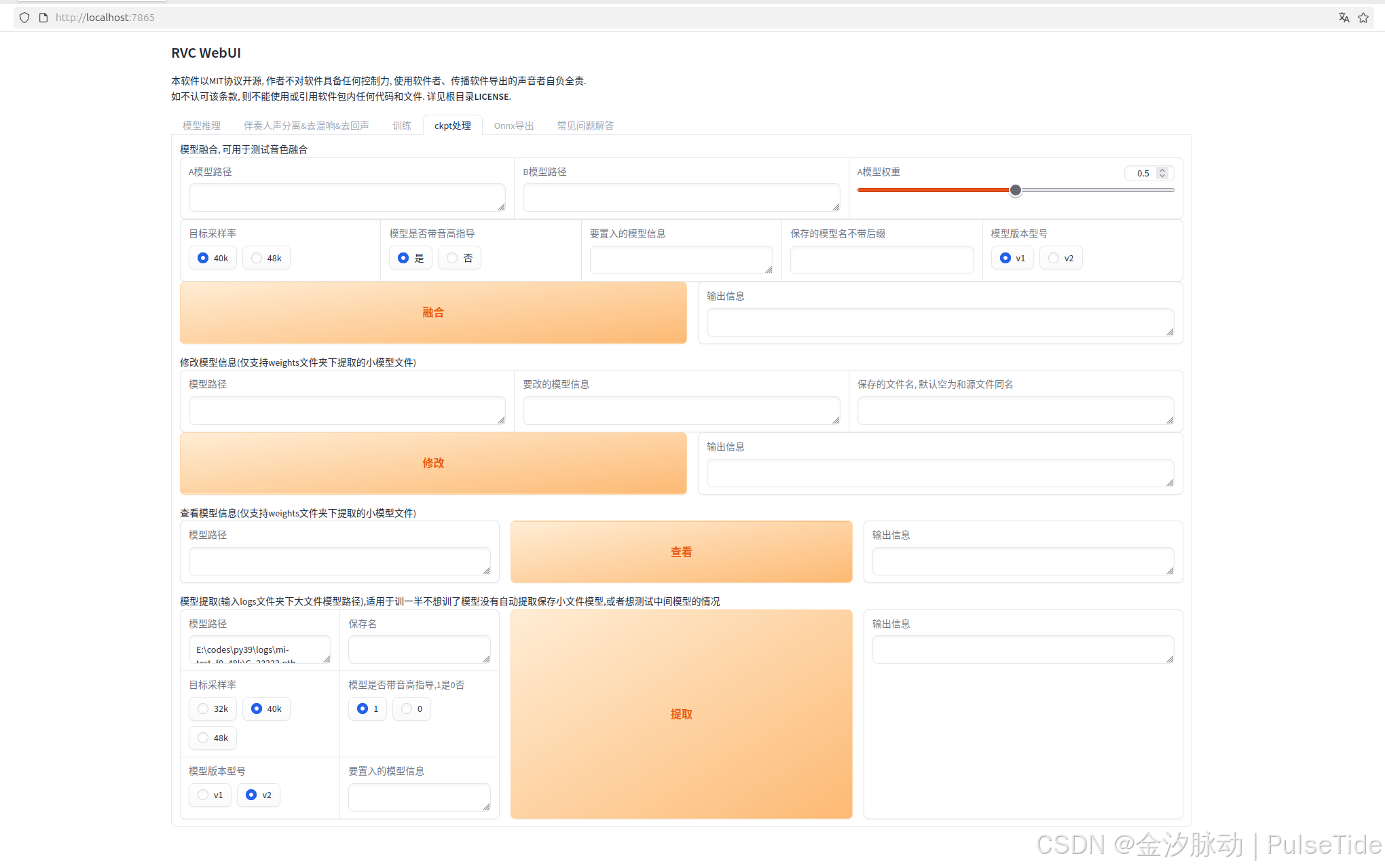
2、音色融合
音色融合是通过将已训练的音色包进行组合来实现的,同性别音色的融合效果通常更理想,这项技术不仅能创造出全新的音色包,还能有效降低爆音风险,例如,当A音色音质出色但易爆音,B音色虽普通但稳定性好时,可以采取高权重A模型与低权重B模型融合的方式,合理调整权重比例后,融合后的音色将兼具两者的优势,为音源素材创作提供更多可能性。
3、干声分离
人声分离(即从音频中提取干声)属于预处理步骤,主要用于获得更纯净的音频素材。虽然可以使用本模型的一键训练包完成,但并非必需,市面上也有其他更简单易用的专业工具可供选择。
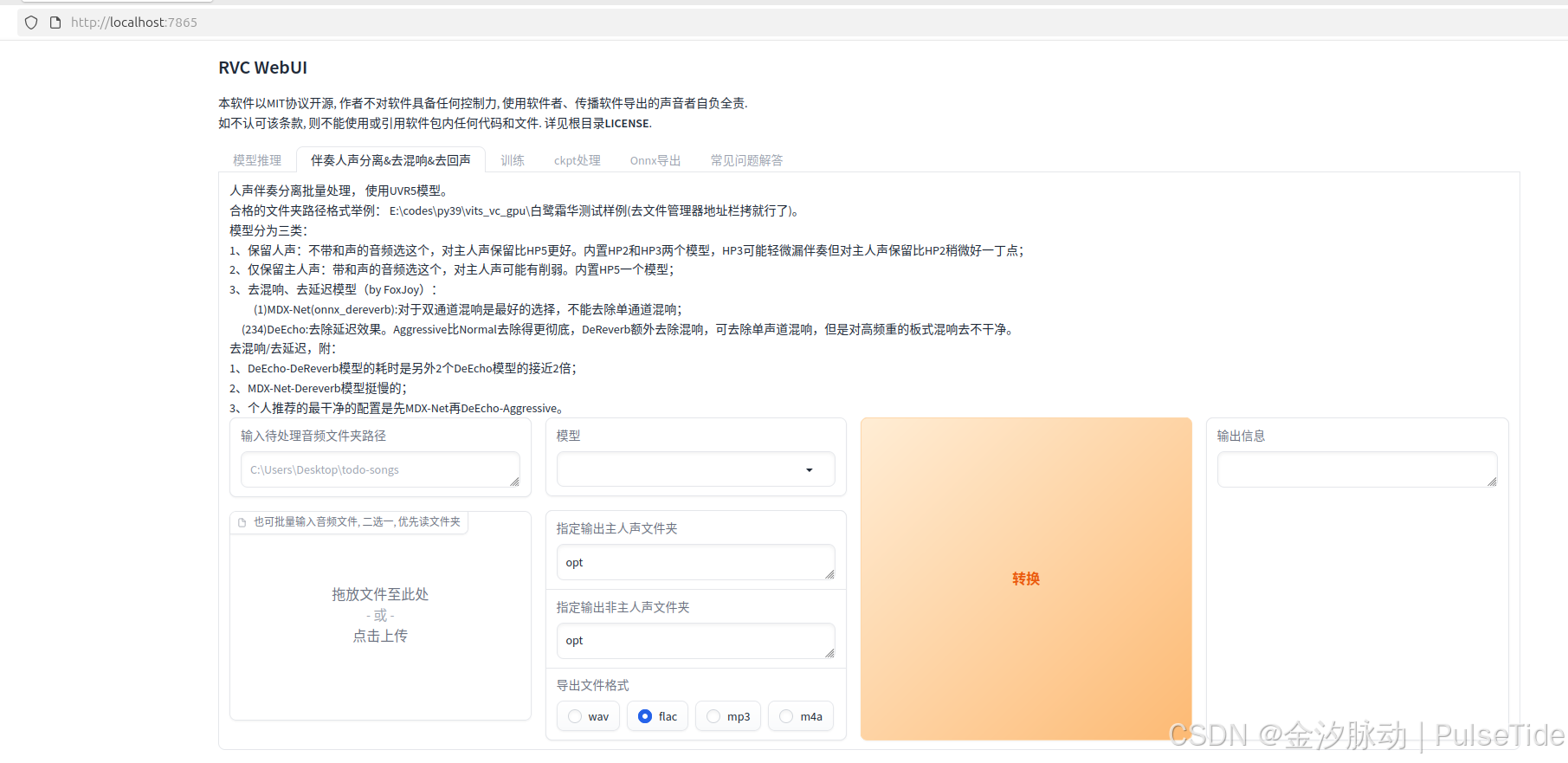
界面参数说明:
- 待处理音频路径:请指定包含待处理音频的文件夹路径(需确保每个音频文件单独存放于一个文件夹中,以防止文件过多导致训练时间过长)。
- 分离模型选择 :
- HP2 人声:适用于仅含背景音和人声的音频
- HP5 人声:适用于含背景音与人声叠加等复杂效果的音频
- 人声输出目录 :默认输出路径为
./opt - 乐器文件夹 :背景音存储路径,默认为
./opt

4、音色推理
步骤1中得到了推理音色,例如懒羊羊,这就是主体的音色,步骤3得到了干声,此时就可以指定用懒羊羊的音色进行干声推理。
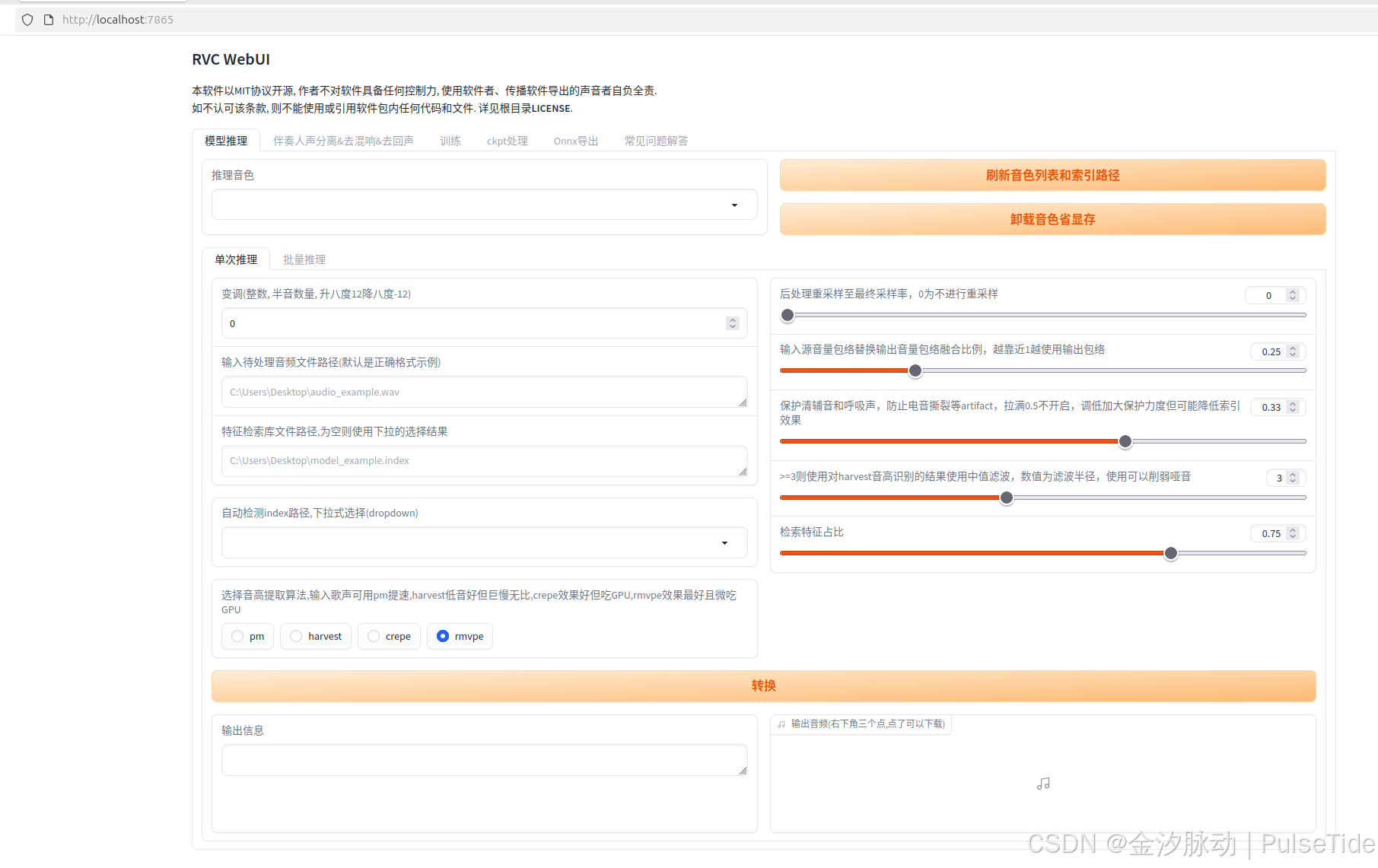
界面参数说明:
- 推理音色:最终生成的合成音色效果
- 待处理音频:需要合成的原始音频(支持主流音频格式)
- index路径:与推理音色匹配的特征索引文件(以.index结尾)
- 变调设置 (半音单位,整数调节):
- 男声转女声建议:+12key
- 女声转男声建议:-12key
- 若出现音域失真,可手动调整至合适范围
- 音色管理 :
- 刷新列表:加载新增音色及索引文件(训练新音色后需重新加载)
- 卸载音色:释放已加载音色,优化显存占用
- 音高提取算法 :
- PM:适合歌声处理(速度较快)
- Harvest:低音表现优异(处理速度较慢)
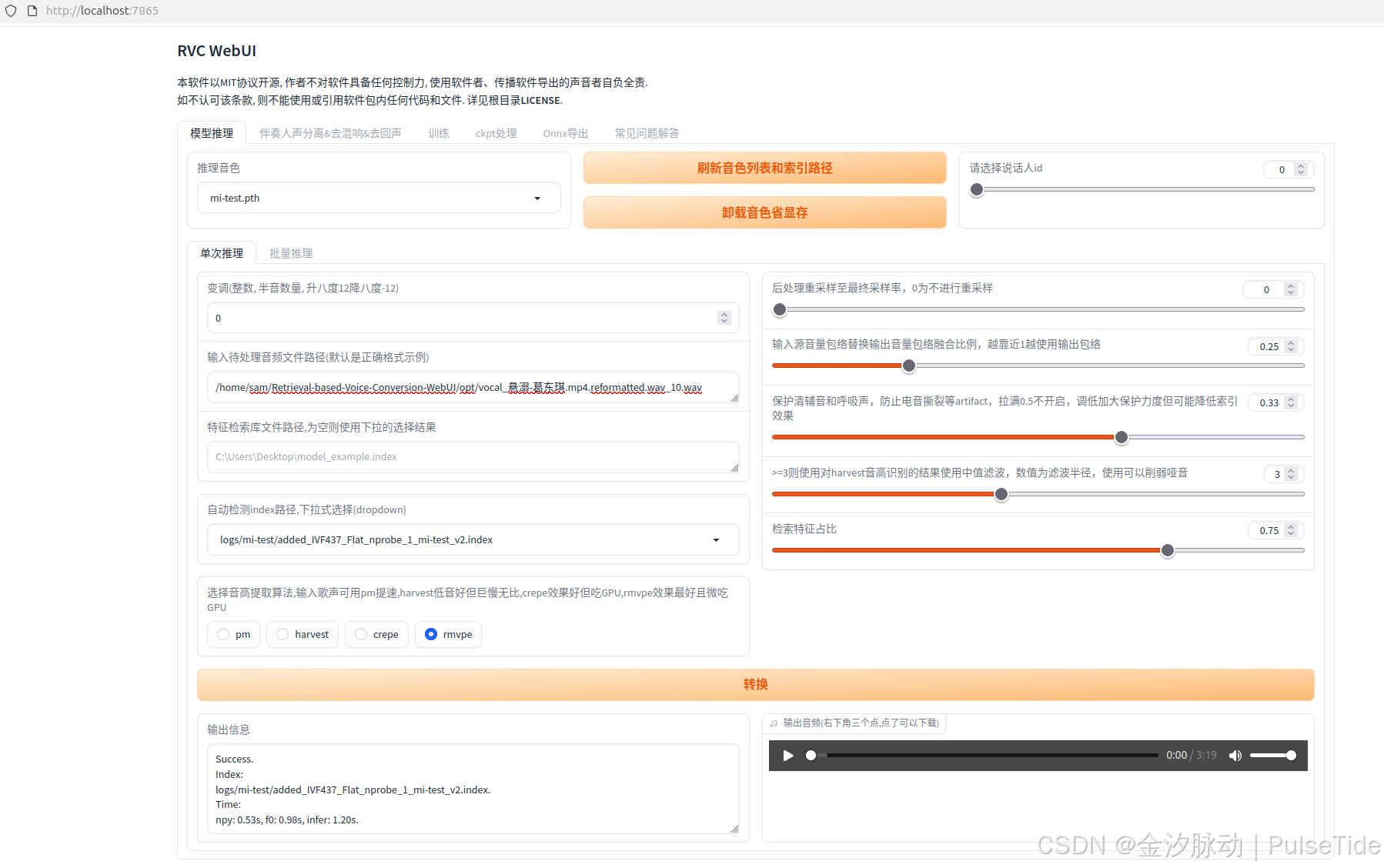
补充:50系列N卡推理
需要:Python 3.10,Pytorch 版本 2.8。
推理过程遇到报错:PyTorch 版本默认值问题
2025-09-21 14:51:55 | WARNING | infer.modules.vc.modules | Traceback (most recent call last):
File "/home/sam/Retrieval-based-Voice-Conversion-WebUI/infer/modules/vc/modules.py", line 172, in vc_single
self.hubert_model = load_hubert(self.config)
File "/home/sam/Retrieval-based-Voice-Conversion-WebUI/infer/modules/vc/utils.py", line 23, in load_hubert
models, _, _ = checkpoint_utils.load_model_ensemble_and_task(
File "/home/sam/anaconda3/envs/rvc/lib/python3.10/site-packages/fairseq/checkpoint_utils.py", line 425, in load_model_ensemble_and_task
state = load_checkpoint_to_cpu(filename, arg_overrides)
File "/home/sam/anaconda3/envs/rvc/lib/python3.10/site-packages/fairseq/checkpoint_utils.py", line 315, in load_checkpoint_to_cpu
state = torch.load(f, map_location=torch.device("cpu"))
File "/home/sam/anaconda3/envs/rvc/lib/python3.10/site-packages/torch/serialization.py", line 1529, in load
raise pickle.UnpicklingError(_get_wo_message(str(e))) from None
_pickle.UnpicklingError: Weights only load failed. This file can still be loaded, to do so you have two options, do those steps only if you trust the source of the checkpoint.
(1) In PyTorch 2.6, we changed the default value of the `weights_only` argument in `torch.load` from `False` to `True`. Re-running `torch.load` with `weights_only` set to `False` will likely succeed, but it can result in arbitrary code execution. Do it only if you got the file from a trusted source.
(2) Alternatively, to load with `weights_only=True` please check the recommended steps in the following error message.
WeightsUnpickler error: Unsupported global: GLOBAL fairseq.data.dictionary.Dictionary was not an allowed global by default. Please use `torch.serialization.add_safe_globals([fairseq.data.dictionary.Dictionary])` or the `torch.serialization.safe_globals([fairseq.data.dictionary.Dictionary])` context manager to allowlist this global if you trust this class/function.
Check the documentation of torch.load to learn more about types accepted by default with weights_only https://pytorch.org/docs/stable/generated/torch.load.html.
Traceback (most recent call last):
File "/home/sam/anaconda3/envs/rvc/lib/python3.10/site-packages/gradio/routes.py", line 437, in run_predict
output = await app.get_blocks().process_api(
File "/home/sam/anaconda3/envs/rvc/lib/python3.10/site-packages/gradio/blocks.py", line 1349, in process_api
data = self.postprocess_data(fn_index, result["prediction"], state)
File "/home/sam/anaconda3/envs/rvc/lib/python3.10/site-packages/gradio/blocks.py", line 1283, in postprocess_data
prediction_value = block.postprocess(prediction_value)
File "/home/sam/anaconda3/envs/rvc/lib/python3.10/site-packages/gradio/components.py", line 2586, in postprocess
file_path = self.audio_to_temp_file(
File "/home/sam/anaconda3/envs/rvc/lib/python3.10/site-packages/gradio/components.py", line 360, in audio_to_temp_file
temp_dir = Path(dir) / self.hash_bytes(data.tobytes())
AttributeError: 'NoneType' object has no attribute 'tobytes'解决:手动设置 weights_only=False,修改报错路径源码即可:
File "/home/sam/anaconda3/envs/rvc/lib/python3.10/site-packages/fairseq/checkpoint_utils.py", line 315, in load_checkpoint_to_cpu
state = torch.load(f, map_location=torch.device("cpu"))修改如下:
python
state = torch.load(f, map_location=torch.device("cpu"), weights_only=False)免责声明
请负责任地使用!技术无罪,请勿滥用,请对自己的行为负责。